 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Can Generative Large Language Models Perform ASR Error Correction?
Jul 09, 2023
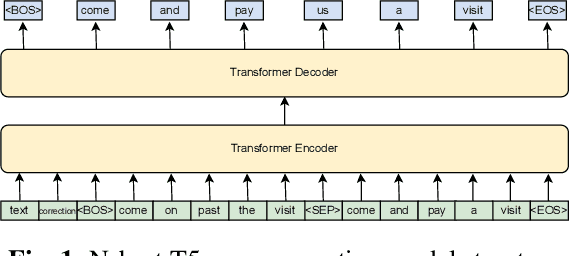
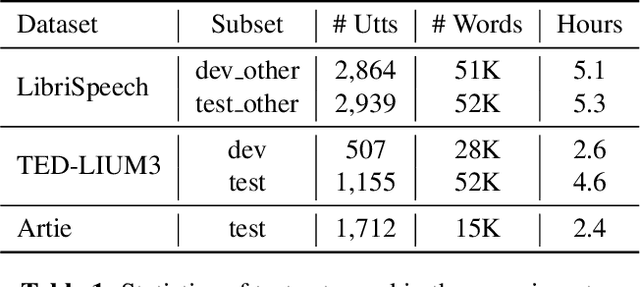
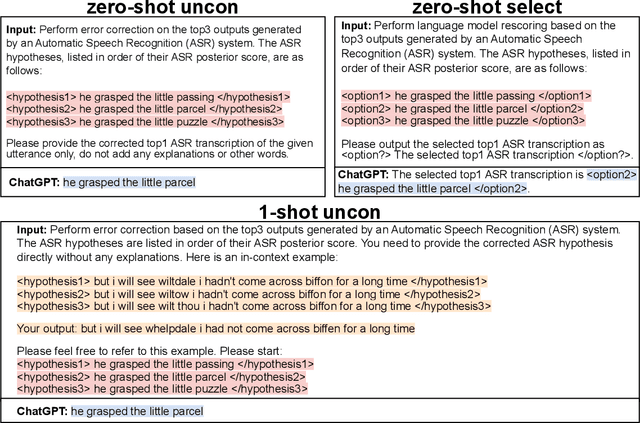
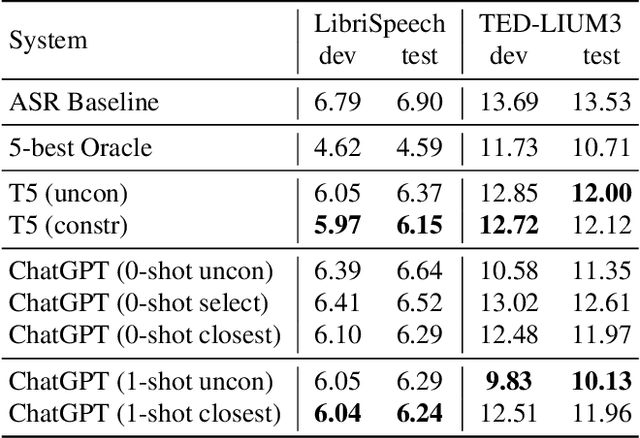
ASR error correction continues to serve as an important part of post-processing for speech recognition systems. Traditionally, these models are trained with supervised training using the decoding results of the underlying ASR system and the reference text. This approach is computationally intensive and the model needs to be re-trained when switching the underlying ASR model. Recent years have seen the development of large language models and their ability to perform natural language processing tasks in a zero-shot manner. In this paper, we take ChatGPT as an example to examine its ability to perform ASR error correction in the zero-shot or 1-shot settings. We use the ASR N-best list as model input and propose unconstrained error correction and N-best constrained error correction methods. Results on a Conformer-Transducer model and the pre-trained Whisper model show that we can largely improve the ASR system performance with error correction using the powerful ChatGPT model.
Synthesizing audio from tongue motion during speech using tagged MRI via transformer
Feb 14, 2023
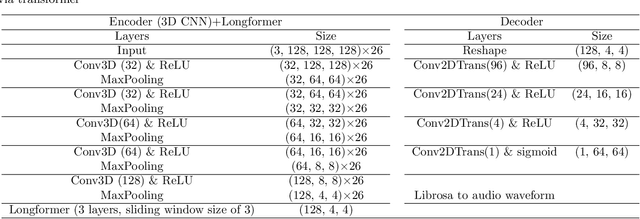

Investigating the relationship between internal tissue point motion of the tongue and oropharyngeal muscle deformation measured from tagged MRI and intelligible speech can aid in advancing speech motor control theories and developing novel treatment methods for speech related-disorders. However, elucidating the relationship between these two sources of information is challenging, due in part to the disparity in data structure between spatiotemporal motion fields (i.e., 4D motion fields) and one-dimensional audio waveforms. In this work, we present an efficient encoder-decoder translation network for exploring the predictive information inherent in 4D motion fields via 2D spectrograms as a surrogate of the audio data. Specifically, our encoder is based on 3D convolutional spatial modeling and transformer-based temporal modeling. The extracted features are processed by an asymmetric 2D convolution decoder to generate spectrograms that correspond to 4D motion fields. Furthermore, we incorporate a generative adversarial training approach into our framework to further improve synthesis quality on our generated spectrograms. We experiment on 63 paired motion field sequences and speech waveforms, demonstrating that our framework enables the generation of clear audio waveforms from a sequence of motion fields. Thus, our framework has the potential to improve our understanding of the relationship between these two modalities and inform the development of treatments for speech disorders.
Gradient Remedy for Multi-Task Learning in End-to-End Noise-Robust Speech Recognition
Feb 22, 2023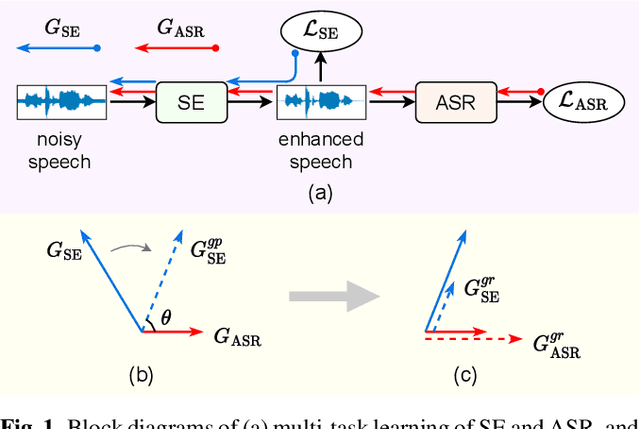

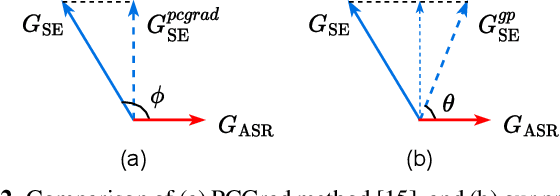
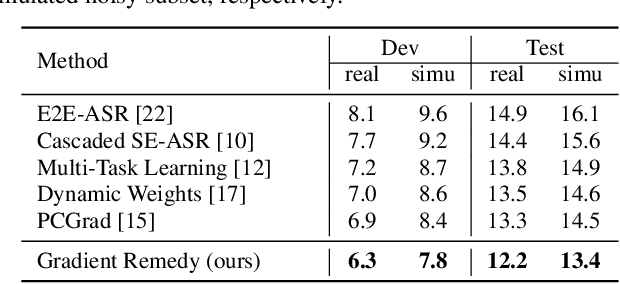
Speech enhancement (SE) is proved effective in reducing noise from noisy speech signals for downstream automatic speech recognition (ASR), where multi-task learning strategy is employed to jointly optimize these two tasks. However, the enhanced speech learned by SE objective may not always yield good ASR results. From the optimization view, there sometimes exists interference between the gradients of SE and ASR tasks, which could hinder the multi-task learning and finally lead to sub-optimal ASR performance. In this paper, we propose a simple yet effective approach called gradient remedy (GR) to solve interference between task gradients in noise-robust speech recognition, from perspectives of both angle and magnitude. Specifically, we first project the SE task's gradient onto a dynamic surface that is at acute angle to ASR gradient, in order to remove the conflict between them and assist in ASR optimization. Furthermore, we adaptively rescale the magnitude of two gradients to prevent the dominant ASR task from being misled by SE gradient. Experimental results show that the proposed approach well resolves the gradient interference and achieves relative word error rate (WER) reductions of 9.3% and 11.1% over multi-task learning baseline, on RATS and CHiME-4 datasets, respectively. Our code is available at GitHub.
Time out of Mind: Generating Rate of Speech conditioned on emotion and speaker
Jan 31, 2023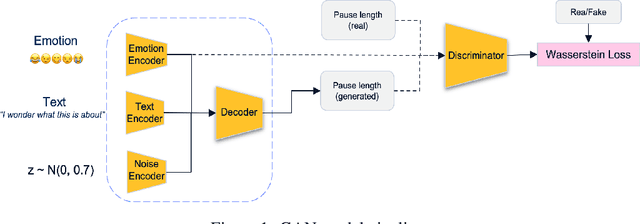
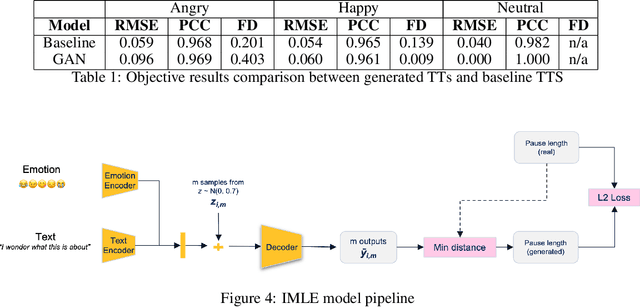
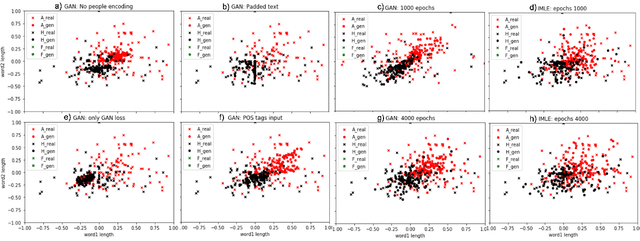
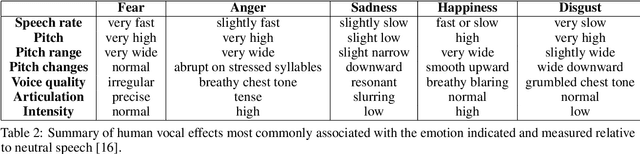
Voice synthesis has seen significant improvements in the past decade resulting in highly intelligible voices. Further investigations have resulted in models that can produce variable speech, including conditional emotional expression. The problem lies, however, in a focus on phrase-level modifications and prosodic vocal features. Using the CREMA-D dataset we have trained a GAN conditioned on emotion to generate worth lengths for a given input text. These word lengths are relative to neutral speech and can be provided, through speech synthesis markup language (SSML) to a text-to-speech (TTS) system to generate more expressive speech. Additionally, a generative model is also trained using implicit maximum likelihood estimation (IMLE) and a comparative analysis with GANs is included. We were able to achieve better performances on objective measures for neutral speech, and better time alignment for happy speech when compared to an out-of-box model. However, further investigation of subjective evaluation is required.
Cross-Lingual Transfer Learning for Alzheimer's Detection From Spontaneous Speech
Mar 06, 2023Alzheimer's disease (AD) is a progressive neurodegenerative disease most often associated with memory deficits and cognitive decline. With the aging population, there has been much interest in automated methods for cognitive impairment detection. One approach that has attracted attention in recent years is AD detection through spontaneous speech. While the results are promising, it is not certain whether the learned speech features can be generalized across languages. To fill this gap, the ADReSS-M challenge was organized. This paper presents our submission to this ICASSP-2023 Signal Processing Grand Challenge (SPGC). The model was trained on 228 English samples of a picture description task and was transferred to Greek using only 8 samples. We obtained an accuracy of 82.6% for AD detection, a root-mean-square error of 4.345 for cognitive score prediction, and ranked 2nd place in the competition out of 24 competitors.
Evaluating Automatic Speech Recognition in an Incremental Setting
Feb 23, 2023
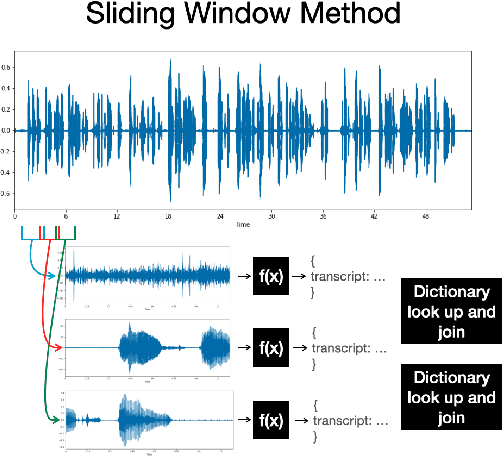
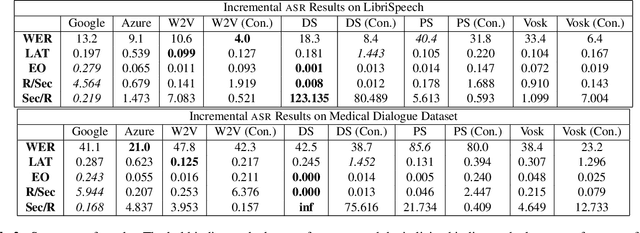
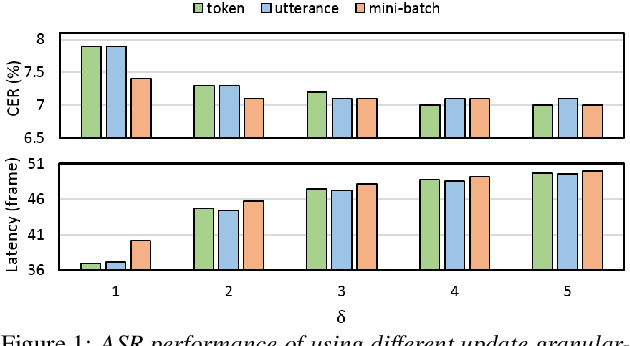
The increasing reliability of automatic speech recognition has proliferated its everyday use. However, for research purposes, it is often unclear which model one should choose for a task, particularly if there is a requirement for speed as well as accuracy. In this paper, we systematically evaluate six speech recognizers using metrics including word error rate, latency, and the number of updates to already recognized words on English test data, as well as propose and compare two methods for streaming audio into recognizers for incremental recognition. We further propose Revokes per Second as a new metric for evaluating incremental recognition and demonstrate that it provides insights into overall model performance. We find that, generally, local recognizers are faster and require fewer updates than cloud-based recognizers. Finally, we find Meta's Wav2Vec model to be the fastest, and find Mozilla's DeepSpeech model to be the most stable in its predictions.
Improving Isochronous Machine Translation with Target Factors and Auxiliary Counters
May 22, 2023
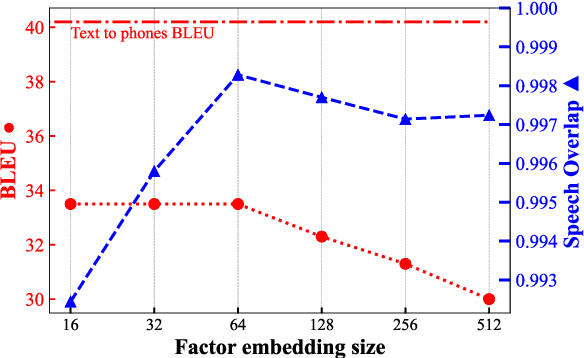
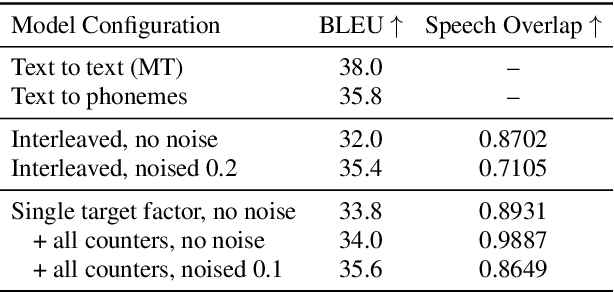
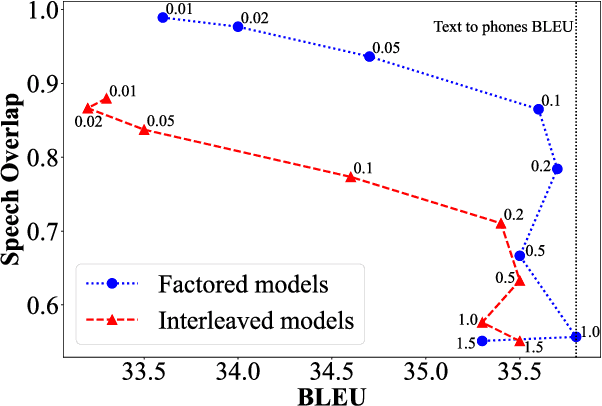
To translate speech for automatic dubbing, machine translation needs to be isochronous, i.e. translated speech needs to be aligned with the source in terms of speech durations. We introduce target factors in a transformer model to predict durations jointly with target language phoneme sequences. We also introduce auxiliary counters to help the decoder to keep track of the timing information while generating target phonemes. We show that our model improves translation quality and isochrony compared to previous work where the translation model is instead trained to predict interleaved sequences of phonemes and durations.
Self-regularised Minimum Latency Training for Streaming Transformer-based Speech Recognition
Apr 24, 2023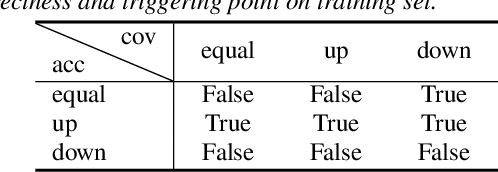
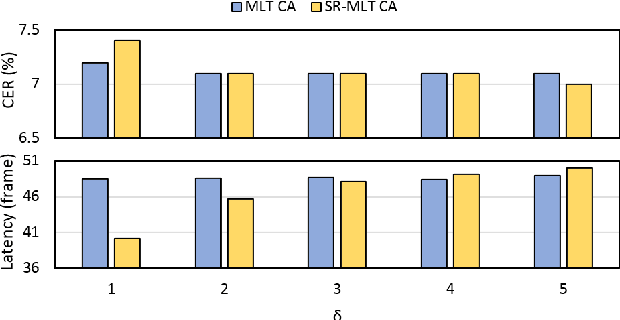
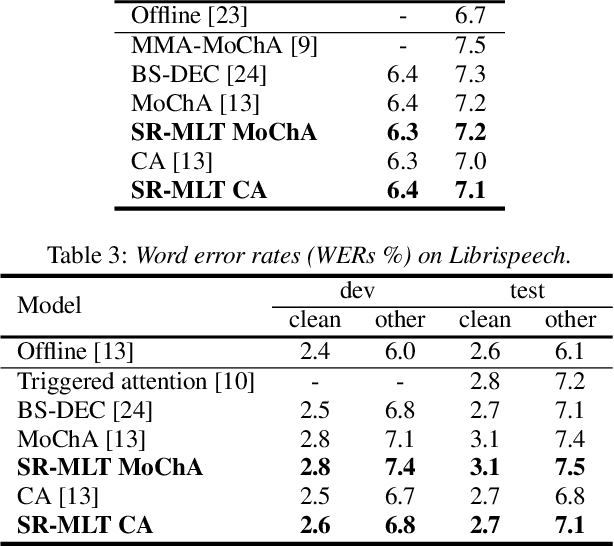
This paper proposes a self-regularised minimum latency training (SR-MLT) method for streaming Transformer-based automatic speech recognition (ASR) systems. In previous works, latency was optimised by truncating the online attention weights based on the hard alignments obtained from conventional ASR models, without taking into account the potential loss of ASR accuracy. On the contrary, here we present a strategy to obtain the alignments as a part of the model training without external supervision. The alignments produced by the proposed method are dynamically regularised on the training data, such that the latency reduction does not result in the loss of ASR accuracy. SR-MLT is applied as a fine-tuning step on the pre-trained Transformer models that are based on either monotonic chunkwise attention (MoChA) or cumulative attention (CA) algorithms for online decoding. ASR experiments on the AIShell-1 and Librispeech datasets show that when applied on a decent pre-trained MoChA or CA baseline model, SR-MLT can effectively reduce the latency with the relative gains ranging from 11.8% to 39.5%. Furthermore, we also demonstrate that under certain accuracy levels, the models trained with SR-MLT can achieve lower latency when compared to those supervised using external hard alignments.
SelfTalk: A Self-Supervised Commutative Training Diagram to Comprehend 3D Talking Faces
Jun 19, 2023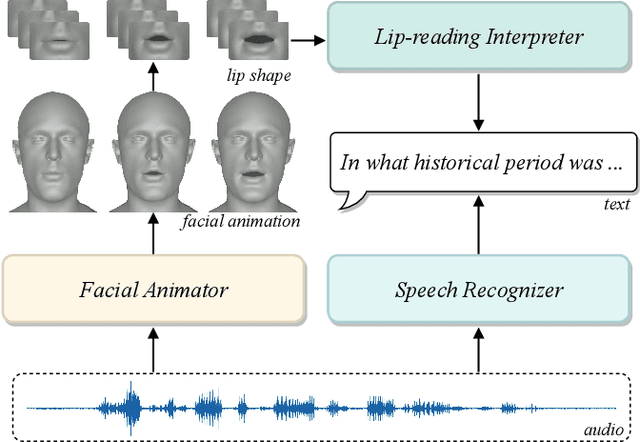
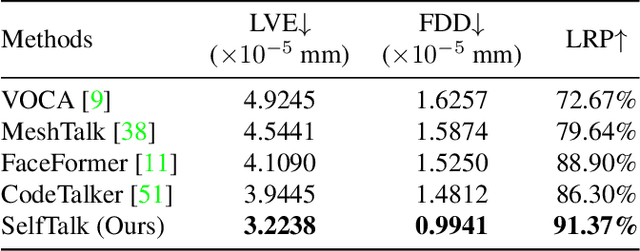
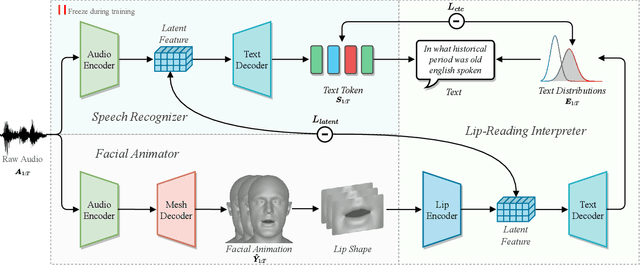
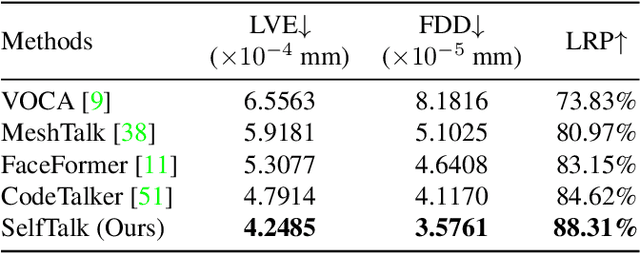
Speech-driven 3D face animation technique, extending its applications to various multimedia fields. Previous research has generated promising realistic lip movements and facial expressions from audio signals. However, traditional regression models solely driven by data face several essential problems, such as difficulties in accessing precise labels and domain gaps between different modalities, leading to unsatisfactory results lacking precision and coherence. To enhance the visual accuracy of generated lip movement while reducing the dependence on labeled data, we propose a novel framework SelfTalk, by involving self-supervision in a cross-modals network system to learn 3D talking faces. The framework constructs a network system consisting of three modules: facial animator, speech recognizer, and lip-reading interpreter. The core of SelfTalk is a commutative training diagram that facilitates compatible features exchange among audio, text, and lip shape, enabling our models to learn the intricate connection between these factors. The proposed framework leverages the knowledge learned from the lip-reading interpreter to generate more plausible lip shapes. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. We recommend watching the supplementary video.
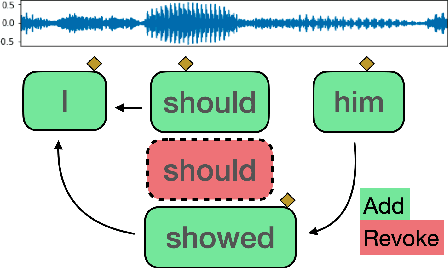
Toward Interactive Dictation
Jul 08, 2023
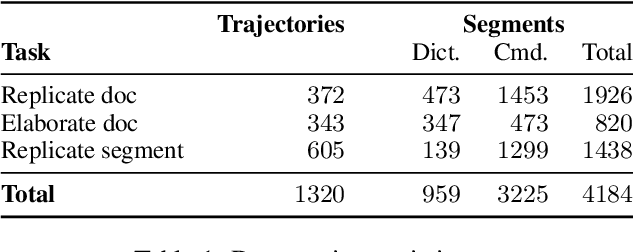
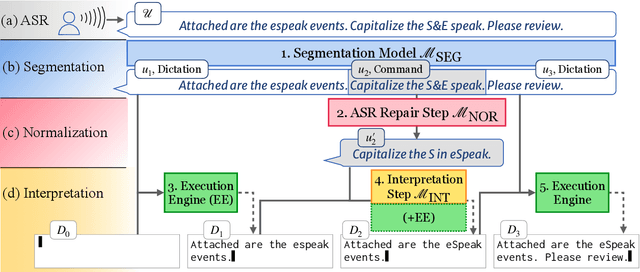
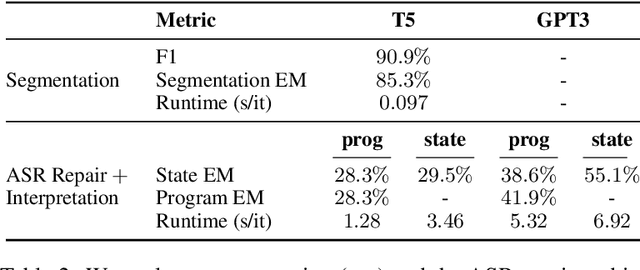
Voice dictation is an increasingly important text input modality. Existing systems that allow both dictation and editing-by-voice restrict their command language to flat templates invoked by trigger words. In this work, we study the feasibility of allowing users to interrupt their dictation with spoken editing commands in open-ended natural language. We introduce a new task and dataset, TERTiUS, to experiment with such systems. To support this flexibility in real-time, a system must incrementally segment and classify spans of speech as either dictation or command, and interpret the spans that are commands. We experiment with using large pre-trained language models to predict the edited text, or alternatively, to predict a small text-editing program. Experiments show a natural trade-off between model accuracy and latency: a smaller model achieves 30% end-state accuracy with 1.3 seconds of latency, while a larger model achieves 55% end-state accuracy with 7 seconds of latency.