 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Evaluating Parameter-Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding
Mar 02, 2023
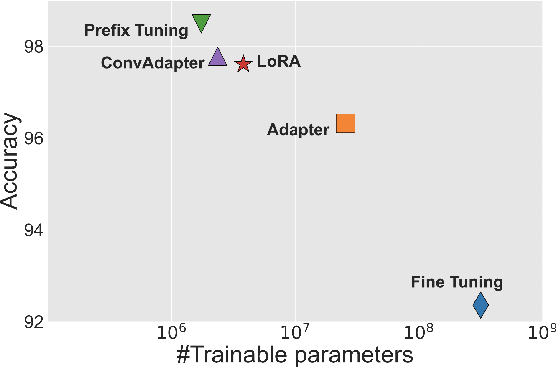

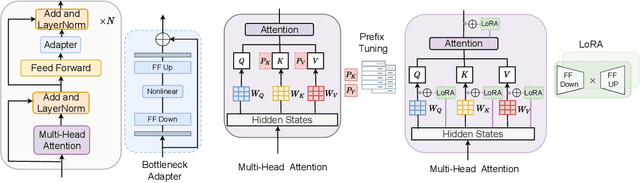

Fine-tuning is widely used as the default algorithm for transfer learning from pre-trained models. Parameter inefficiency can however arise when, during transfer learning, all the parameters of a large pre-trained model need to be updated for individual downstream tasks. As the number of parameters grows, fine-tuning is prone to overfitting and catastrophic forgetting. In addition, full fine-tuning can become prohibitively expensive when the model is used for many tasks. To mitigate this issue, parameter-efficient transfer learning algorithms, such as adapters and prefix tuning, have been proposed as a way to introduce a few trainable parameters that can be plugged into large pre-trained language models such as BERT, and HuBERT. In this paper, we introduce the Speech UndeRstanding Evaluation (SURE) benchmark for parameter-efficient learning for various speech-processing tasks. Additionally, we introduce a new adapter, ConvAdapter, based on 1D convolution. We show that ConvAdapter outperforms the standard adapters while showing comparable performance against prefix tuning and LoRA with only 0.94% of trainable parameters on some of the task in SURE. We further explore the effectiveness of parameter efficient transfer learning for speech synthesis task such as Text-to-Speech (TTS).
On the Impact of Voice Anonymization on Speech-Based COVID-19 Detection
Apr 05, 2023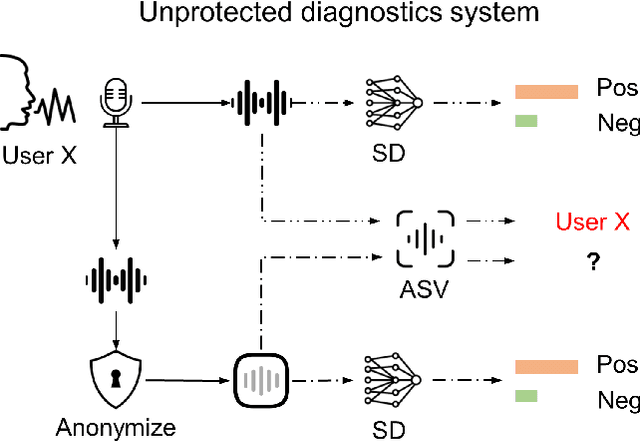
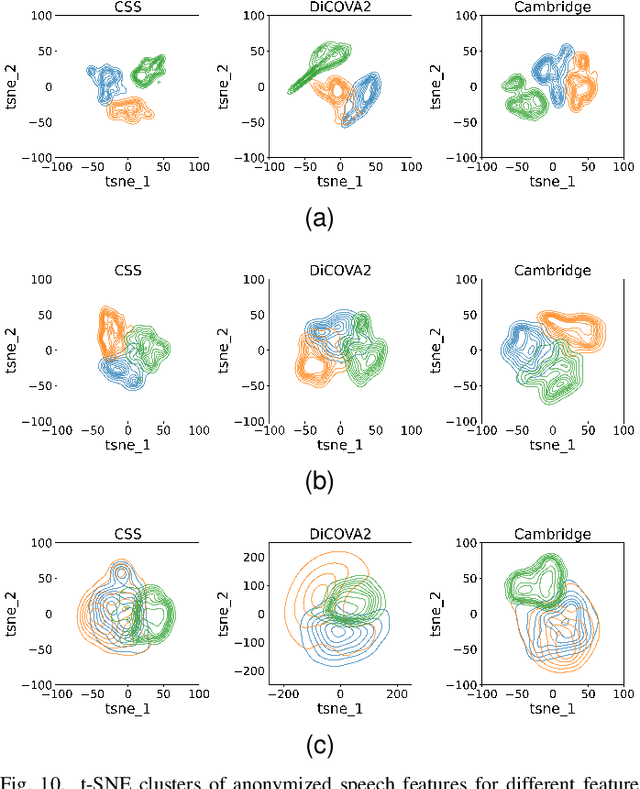
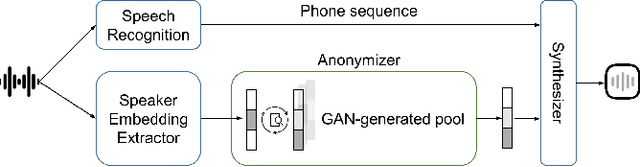
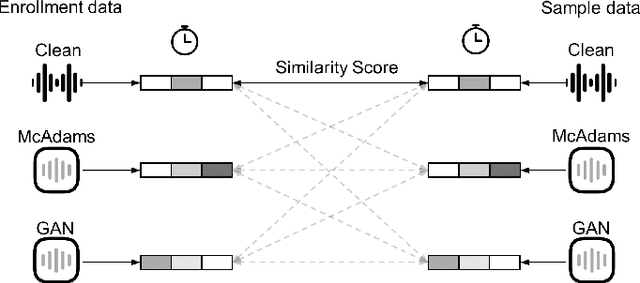
With advances seen in deep learning, voice-based applications are burgeoning, ranging from personal assistants, affective computing, to remote disease diagnostics. As the voice contains both linguistic and paralinguistic information (e.g., vocal pitch, intonation, speech rate, loudness), there is growing interest in voice anonymization to preserve speaker privacy and identity. Voice privacy challenges have emerged over the last few years and focus has been placed on removing speaker identity while keeping linguistic content intact. For affective computing and disease monitoring applications, however, the paralinguistic content may be more critical. Unfortunately, the effects that anonymization may have on these systems are still largely unknown. In this paper, we fill this gap and focus on one particular health monitoring application: speech-based COVID-19 diagnosis. We test two popular anonymization methods and their impact on five different state-of-the-art COVID-19 diagnostic systems using three public datasets. We validate the effectiveness of the anonymization methods, compare their computational complexity, and quantify the impact across different testing scenarios for both within- and across-dataset conditions. Lastly, we show the benefits of anonymization as a data augmentation tool to help recover some of the COVID-19 diagnostic accuracy loss seen with anonymized data.
Personalized speech enhancement combining band-split RNN and speaker attentive module
Feb 20, 2023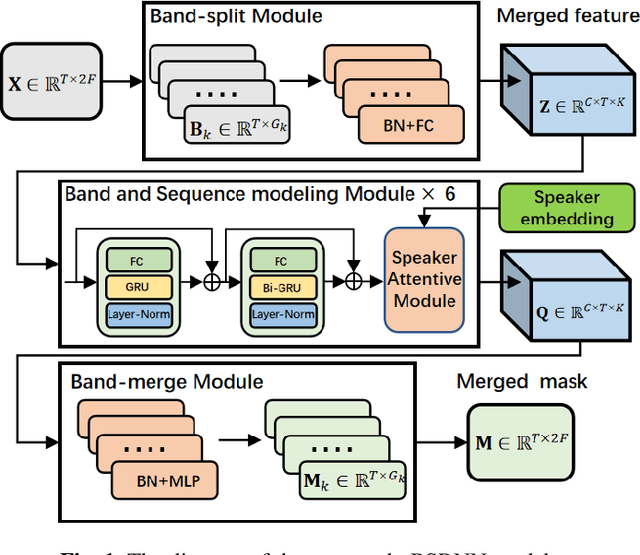
Target speaker information can be utilized in speech enhancement (SE) models to more effectively extract the desired speech. Previous works introduce the speaker embedding into speech enhancement models by means of concatenation or affine transformation. In this paper, we propose a speaker attentive module to calculate the attention scores between the speaker embedding and the intermediate features, which are used to rescale the features. By merging this module in the state-of-the-art SE model, we construct the personalized SE model for ICASSP Signal Processing Grand Challenge: DNS Challenge 5 (2023). Our system achieves a final score of 0.529 on the blind test set of track1 and 0.549 on track2.
LipLearner: Customizable Silent Speech Interactions on Mobile Devices
Feb 14, 2023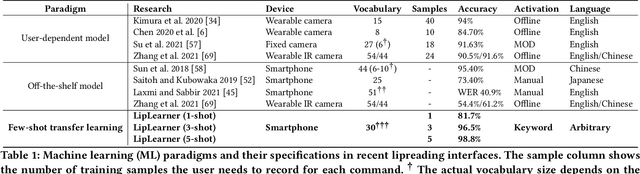

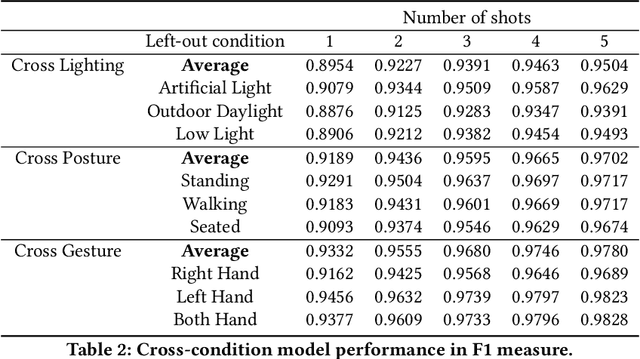

Silent speech interface is a promising technology that enables private communications in natural language. However, previous approaches only support a small and inflexible vocabulary, which leads to limited expressiveness. We leverage contrastive learning to learn efficient lipreading representations, enabling few-shot command customization with minimal user effort. Our model exhibits high robustness to different lighting, posture, and gesture conditions on an in-the-wild dataset. For 25-command classification, an F1-score of 0.8947 is achievable only using one shot, and its performance can be further boosted by adaptively learning from more data. This generalizability allowed us to develop a mobile silent speech interface empowered with on-device fine-tuning and visual keyword spotting. A user study demonstrated that with LipLearner, users could define their own commands with high reliability guaranteed by an online incremental learning scheme. Subjective feedback indicated that our system provides essential functionalities for customizable silent speech interactions with high usability and learnability.
Frequency bin-wise single channel speech presence probability estimation using multiple DNNs
Feb 23, 2023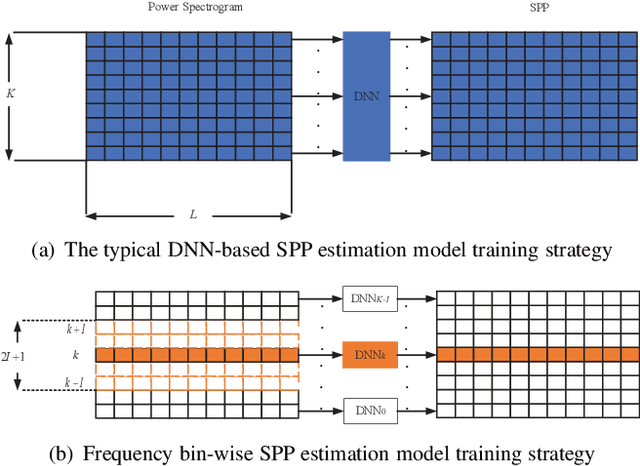
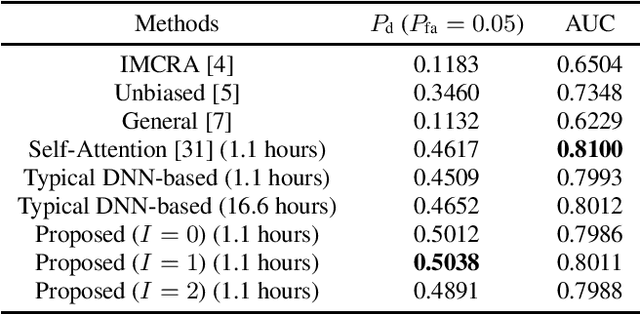
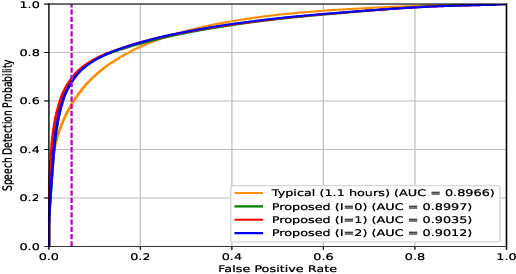
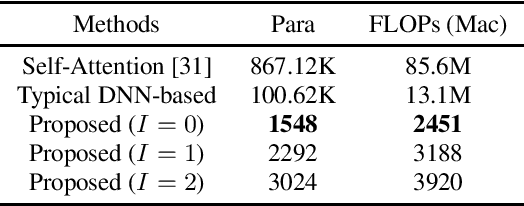
In this work, we propose a frequency bin-wise method to estimate the single-channel speech presence probability (SPP) with multiple deep neural networks (DNNs) in the short-time Fourier transform domain. Since all frequency bins are typically considered simultaneously as input features for conventional DNN-based SPP estimators, high model complexity is inevitable. To reduce the model complexity and the requirements on the training data, we take a single frequency bin and some of its neighboring frequency bins into account to train separate gate recurrent units. In addition, the noisy speech and the a posteriori probability SPP representation are used to train our model. The experiments were performed on the Deep Noise Suppression challenge dataset. The experimental results show that the speech detection accuracy can be improved when we employ the frequency bin-wise model. Finally, we also demonstrate that our proposed method outperforms most of the state-of-the-art SPP estimation methods in terms of speech detection accuracy and model complexity.
Robust Acoustic and Semantic Contextual Biasing in Neural Transducers for Speech Recognition
May 09, 2023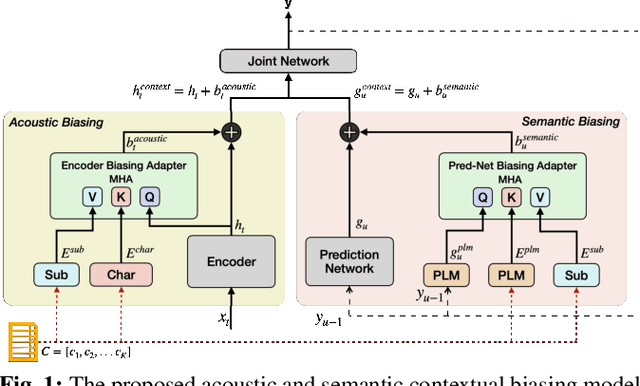
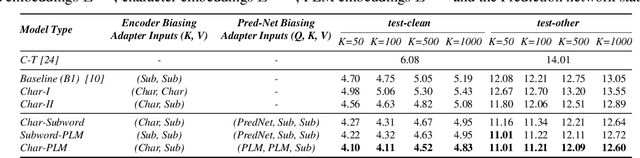

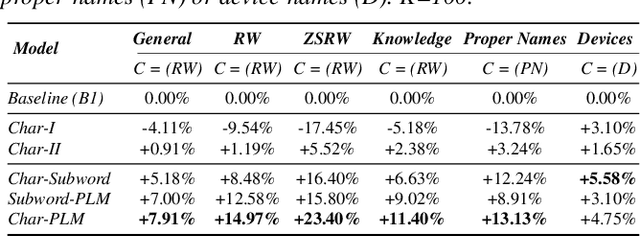
Attention-based contextual biasing approaches have shown significant improvements in the recognition of generic and/or personal rare-words in End-to-End Automatic Speech Recognition (E2E ASR) systems like neural transducers. These approaches employ cross-attention to bias the model towards specific contextual entities injected as bias-phrases to the model. Prior approaches typically relied on subword encoders for encoding the bias phrases. However, subword tokenizations are coarse and fail to capture granular pronunciation information which is crucial for biasing based on acoustic similarity. In this work, we propose to use lightweight character representations to encode fine-grained pronunciation features to improve contextual biasing guided by acoustic similarity between the audio and the contextual entities (termed acoustic biasing). We further integrate pretrained neural language model (NLM) based encoders to encode the utterance's semantic context along with contextual entities to perform biasing informed by the utterance's semantic context (termed semantic biasing). Experiments using a Conformer Transducer model on the Librispeech dataset show a 4.62% - 9.26% relative WER improvement on different biasing list sizes over the baseline contextual model when incorporating our proposed acoustic and semantic biasing approach. On a large-scale in-house dataset, we observe 7.91% relative WER improvement compared to our baseline model. On tail utterances, the improvements are even more pronounced with 36.80% and 23.40% relative WER improvements on Librispeech rare words and an in-house testset respectively.
Parmesan: mathematical concept extraction for education
Jul 17, 2023
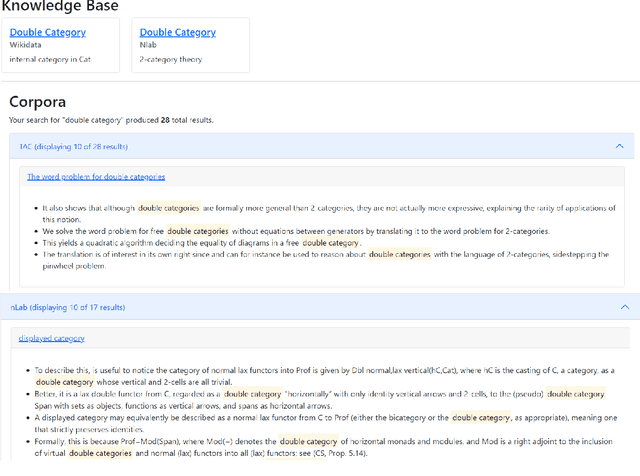
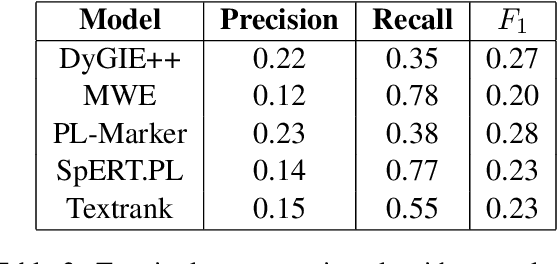
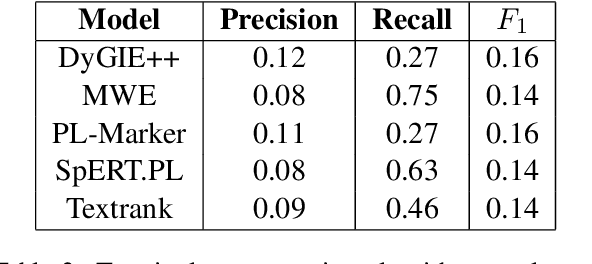
Mathematics is a highly specialized domain with its own unique set of challenges that has seen limited study in natural language processing. However, mathematics is used in a wide variety of fields and multidisciplinary research in many different domains often relies on an understanding of mathematical concepts. To aid researchers coming from other fields, we develop a prototype system for searching for and defining mathematical concepts in context, focusing on the field of category theory. This system, Parmesan, depends on natural language processing components including concept extraction, relation extraction, definition extraction, and entity linking. In developing this system, we show that existing techniques cannot be applied directly to the category theory domain, and suggest hybrid techniques that do perform well, though we expect the system to evolve over time. We also provide two cleaned mathematical corpora that power the prototype system, which are based on journal articles and wiki pages, respectively. The corpora have been annotated with dependency trees, lemmas, and part-of-speech tags.
End-to-End Integration of Speech Separation and Voice Activity Detection for Low-Latency Diarization of Telephone Conversations
Mar 21, 2023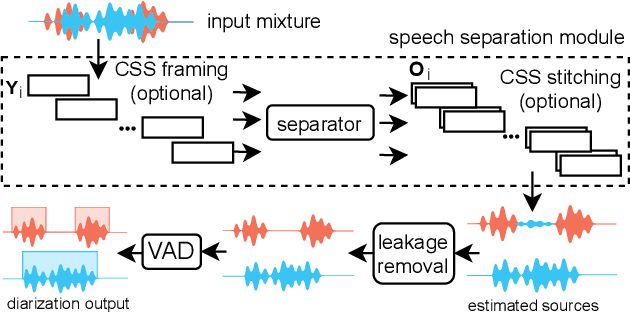
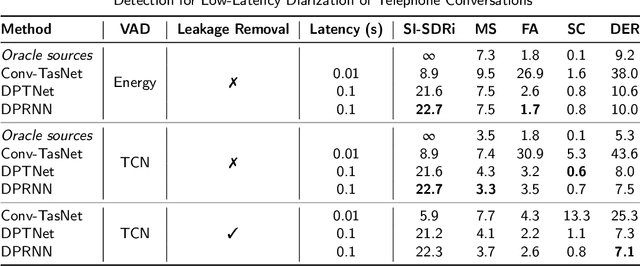
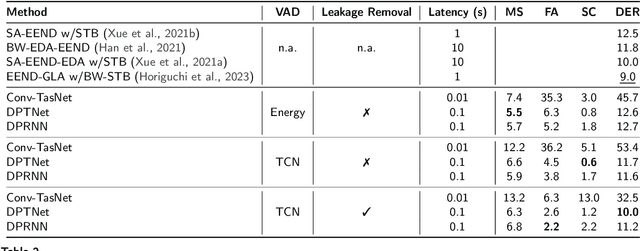

Recent works show that speech separation guided diarization (SSGD) is an increasingly promising direction, mainly thanks to the recent progress in speech separation. It performs diarization by first separating the speakers and then applying voice activity detection (VAD) on each separated stream. In this work we conduct an in-depth study of SSGD in the conversational telephone speech (CTS) domain, focusing mainly on low-latency streaming diarization applications. We consider three state-of-the-art speech separation (SSep) algorithms and study their performance both in online and offline scenarios, considering non-causal and causal implementations as well as continuous SSep (CSS) windowed inference. We compare different SSGD algorithms on two widely used CTS datasets: CALLHOME and Fisher Corpus (Part 1 and 2) and evaluate both separation and diarization performance. To improve performance, a novel, causal and computationally efficient leakage removal algorithm is proposed, which significantly decreases false alarms. We also explore, for the first time, fully end-to-end SSGD integration between SSep and VAD modules. Crucially, this enables fine-tuning on real-world data for which oracle speakers sources are not available. In particular, our best model achieves 8.8% DER on CALLHOME, which outperforms the current state-of-the-art end-to-end neural diarization model, despite being trained on an order of magnitude less data and having significantly lower latency, i.e., 0.1 vs. 1 seconds. Finally, we also show that the separated signals can be readily used also for automatic speech recognition, reaching performance close to using oracle sources in some configurations.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jun 23, 2023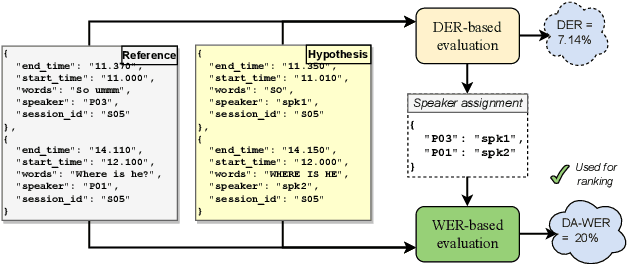
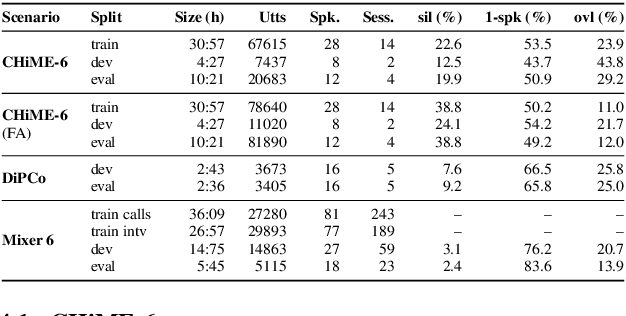
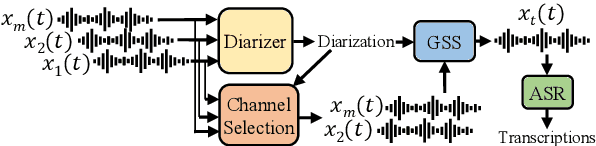
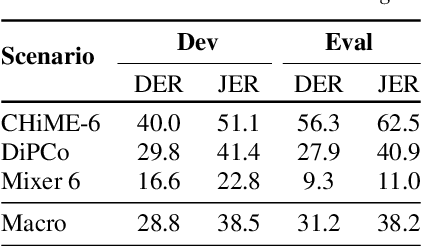
The CHiME challenges have played a significant role in the development and evaluation of robust speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
Ed-Fed: A generic federated learning framework with resource-aware client selection for edge devices
Jul 14, 2023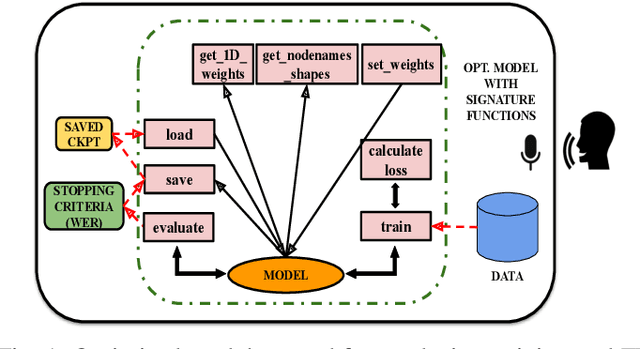
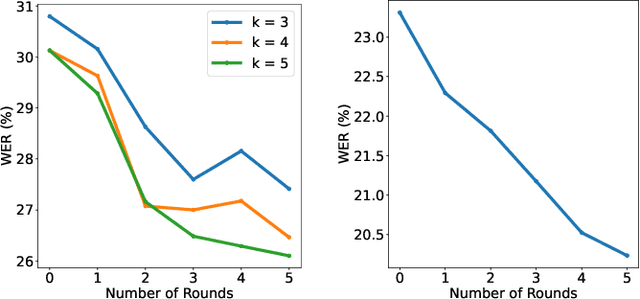
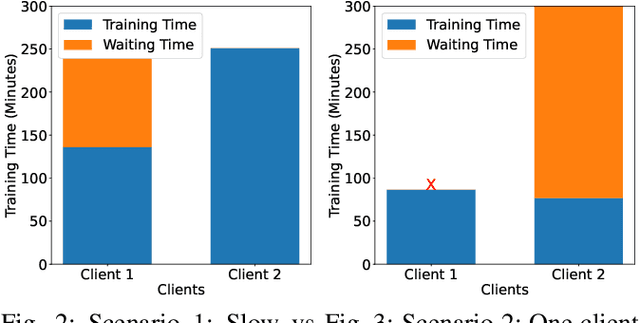
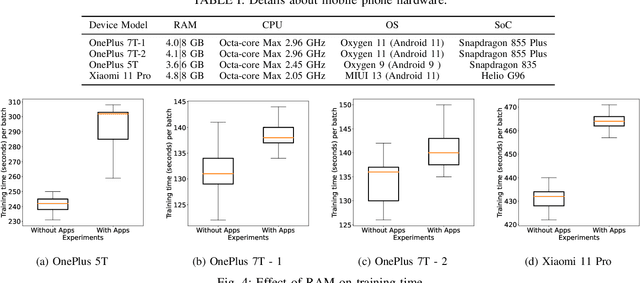
Federated learning (FL) has evolved as a prominent method for edge devices to cooperatively create a unified prediction model while securing their sensitive training data local to the device. Despite the existence of numerous research frameworks for simulating FL algorithms, they do not facilitate comprehensive deployment for automatic speech recognition tasks on heterogeneous edge devices. This is where Ed-Fed, a comprehensive and generic FL framework, comes in as a foundation for future practical FL system research. We also propose a novel resource-aware client selection algorithm to optimise the waiting time in the FL settings. We show that our approach can handle the straggler devices and dynamically set the training time for the selected devices in a round. Our evaluation has shown that the proposed approach significantly optimises waiting time in FL compared to conventional random client selection methods.