 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
3D Neural Beamforming for Multi-channel Speech Separation Against Location Uncertainty
Feb 27, 2023
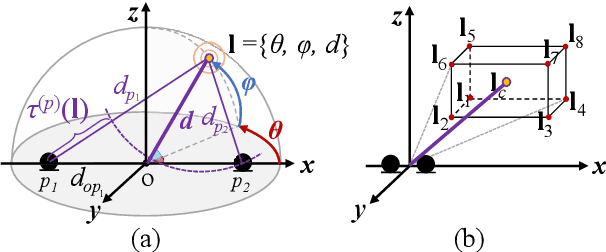
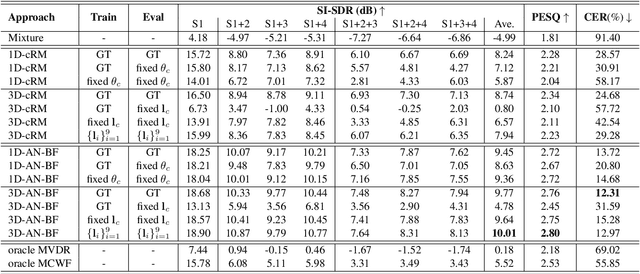
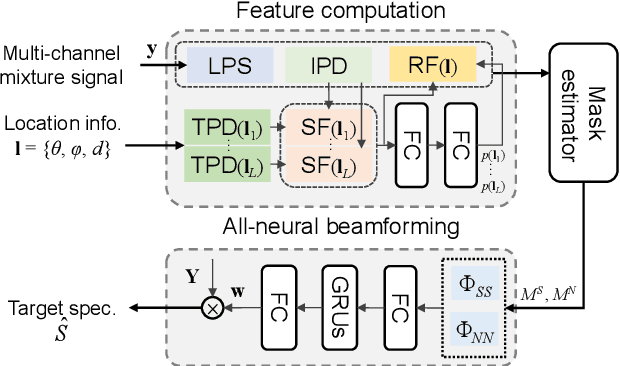

Multi-channel speech separation using speaker's directional information has demonstrated significant gains over blind speech separation. However, it has two limitations. First, substantial performance degradation is observed when the coming directions of two sounds are close. Second, the result highly relies on the precise estimation of the speaker's direction. To overcome these issues, this paper proposes 3D features and an associated 3D neural beamformer for multi-channel speech separation. Previous works in this area are extended in two important directions. First, the traditional 1D directional beam patterns are generalized to 3D. This enables the model to extract speech from any target region in the 3D space. Thus, speakers with similar directions but different elevations or distances become separable. Second, to handle the speaker location uncertainty, previously proposed spatial feature is extended to a new 3D region feature. The proposed 3D region feature and 3D neural beamformer are evaluated under an in-car scenario. Experimental results demonstrated that the combination of 3D feature and 3D beamformer can achieve comparable performance to the separation model with ground truth speaker location as input.
New Challenges for Content Privacy in Speech and Audio
Jan 21, 2023
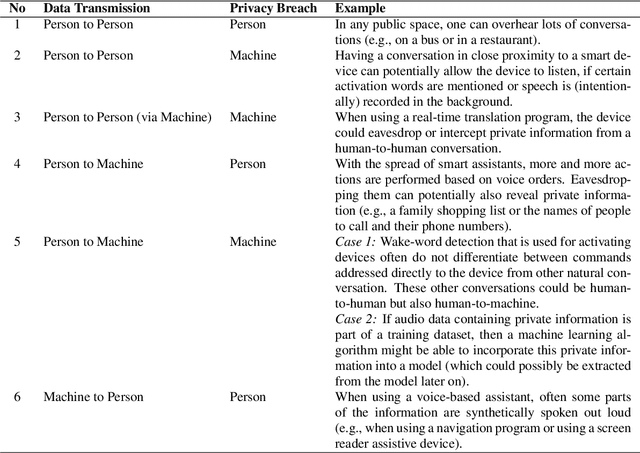
Privacy in speech and audio has many facets. A particularly under-developed area of privacy in this domain involves consideration for information related to content and context. Speech content can include words and their meaning or even stylistic markers, pathological speech, intonation patterns, or emotion. More generally, audio captured in-the-wild may contain background speech or reveal contextual information such as markers of location, room characteristics, paralinguistic sounds, or other audible events. Audio recording devices and speech technologies are becoming increasingly commonplace in everyday life. At the same time, commercialised speech and audio technologies do not provide consumers with a range of privacy choices. Even where privacy is regulated or protected by law, technical solutions to privacy assurance and enforcement fall short. This position paper introduces three important and timely research challenges for content privacy in speech and audio. We highlight current gaps and opportunities, and identify focus areas, that could have significant implications for developing ethical and safer speech technologies.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Apr 02, 2023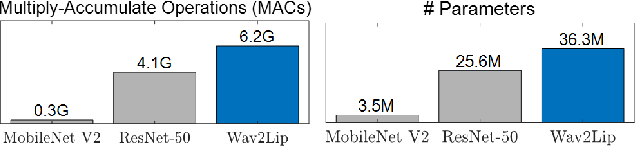
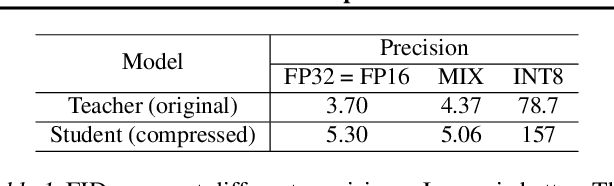
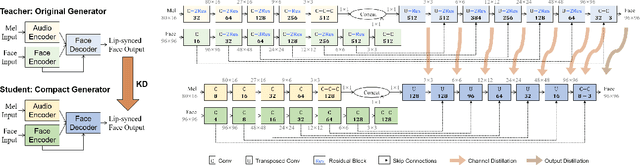
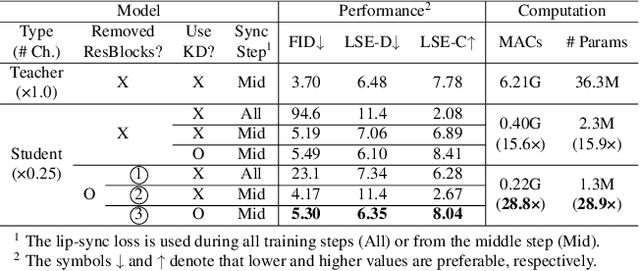
Virtual humans have gained considerable attention in numerous industries, e.g., entertainment and e-commerce. As a core technology, synthesizing photorealistic face frames from target speech and facial identity has been actively studied with generative adversarial networks. Despite remarkable results of modern talking-face generation models, they often entail high computational burdens, which limit their efficient deployment. This study aims to develop a lightweight model for speech-driven talking-face synthesis. We build a compact generator by removing the residual blocks and reducing the channel width from Wav2Lip, a popular talking-face generator. We also present a knowledge distillation scheme to stably yet effectively train the small-capacity generator without adversarial learning. We reduce the number of parameters and MACs by 28$\times$ while retaining the performance of the original model. Moreover, to alleviate a severe performance drop when converting the whole generator to INT8 precision, we adopt a selective quantization method that uses FP16 for the quantization-sensitive layers and INT8 for the other layers. Using this mixed precision, we achieve up to a 19$\times$ speedup on edge GPUs without noticeably compromising the generation quality.
Cost-effective Models for Detecting Depression from Speech
Feb 18, 2023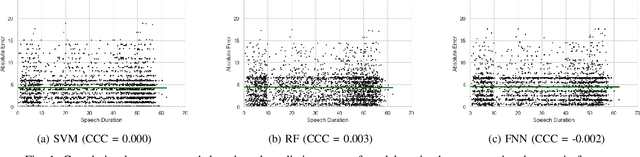
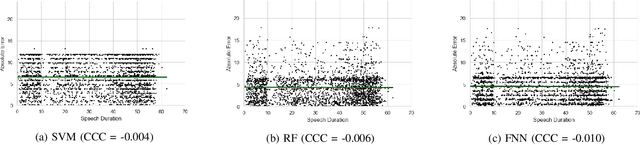
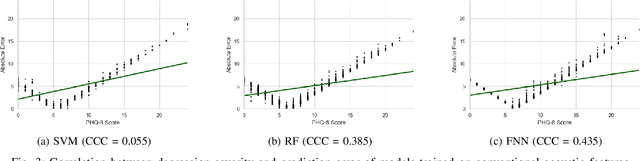
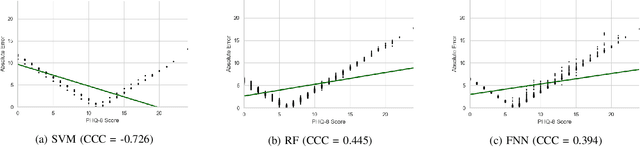
Depression is the most common psychological disorder and is considered as a leading cause of disability and suicide worldwide. An automated system capable of detecting signs of depression in human speech can contribute to ensuring timely and effective mental health care for individuals suffering from the disorder. Developing such automated system requires accurate machine learning models, capable of capturing signs of depression. However, state-of-the-art models based on deep acoustic representations require abundant data, meticulous selection of features, and rigorous training; the procedure involves enormous computational resources. In this work, we explore the effectiveness of two different acoustic feature groups - conventional hand-curated and deep representation features, for predicting the severity of depression from speech. We explore the relevance of possible contributing factors to the models' performance, including gender of the individual, severity of the disorder, content and length of speech. Our findings suggest that models trained on conventional acoustic features perform equally well or better than the ones trained on deep representation features at significantly lower computational cost, irrespective of other factors, e.g. content and length of speech, gender of the speaker and severity of the disorder. This makes such models a better fit for deployment where availability of computational resources is restricted, such as real time depression monitoring applications in smart devices.
Detecting post-stroke aphasia using EEG-based neural envelope tracking of natural speech
Mar 14, 2023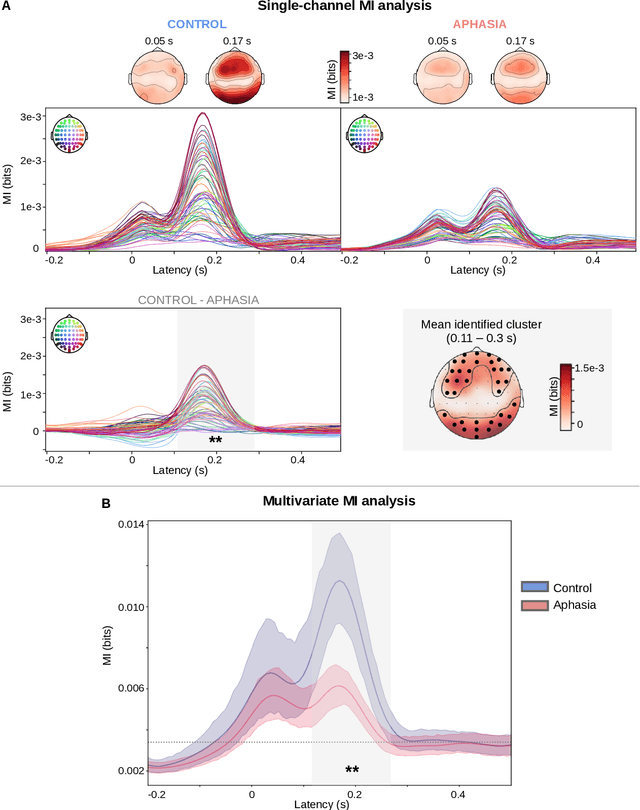
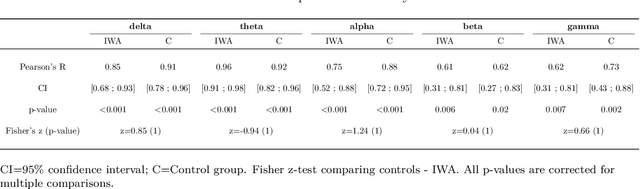
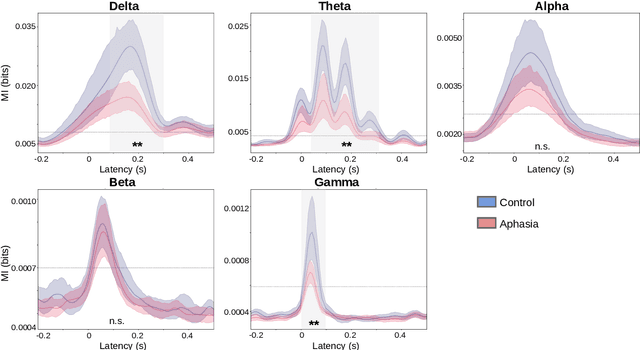
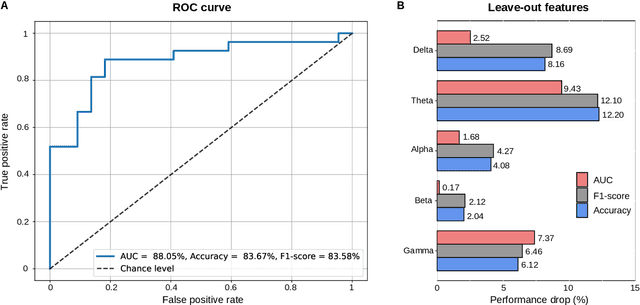
[Objective]. After a stroke, one-third of patients suffer from aphasia, a language disorder that impairs communication ability. The standard behavioral tests used to diagnose aphasia are time-consuming and have low ecological validity. Neural tracking of the speech envelope is a promising tool for investigating brain responses to natural speech. The speech envelope is crucial for speech understanding, encompassing cues for processing linguistic units. In this study, we aimed to test the potential of the neural envelope tracking technique for detecting language impairments in individuals with aphasia (IWA). [Approach]. We recorded EEG from 27 IWA in the chronic phase after stroke and 22 controls while they listened to a story. We quantified neural envelope tracking in a broadband frequency range as well as in the delta, theta, alpha, beta, and gamma frequency bands using mutual information analysis. Besides group differences in neural tracking measures, we also tested its suitability for detecting aphasia using a Support Vector Machine (SVM) classifier. We further investigated the required recording length for the SVM to detect aphasia and to obtain reliable outcomes. [Results]. IWA displayed decreased neural envelope tracking compared to controls in the broad, delta, theta, and gamma band. Neural tracking in these frequency bands effectively captured aphasia at the individual level (SVM accuracy 84%, AUC 88%). High-accuracy and reliable detection could be obtained with 5-7 minutes of recording time. [Significance]. Our study shows that neural tracking of speech is an effective biomarker for aphasia. We demonstrated its potential as a diagnostic tool with high reliability, individual-level detection of aphasia, and time-efficient assessment. This work represents a significant step towards more automatic, objective, and ecologically valid assessments of language impairments in aphasia.
Cognitive performance in open-plan office acoustic simulations: Effects of room acoustics and semantics but not spatial separation of sound sources
Jun 13, 2023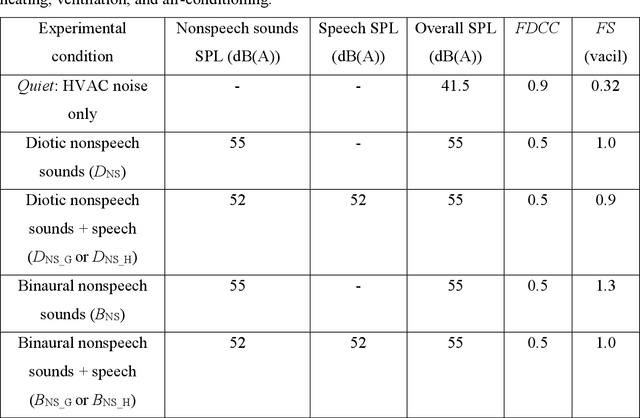
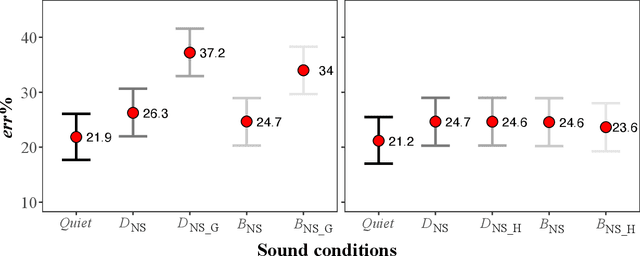
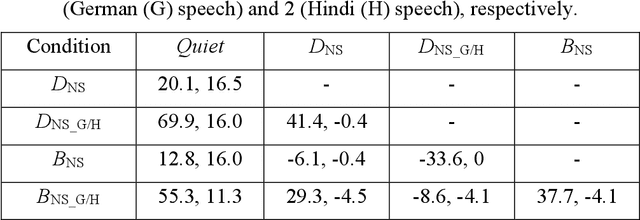
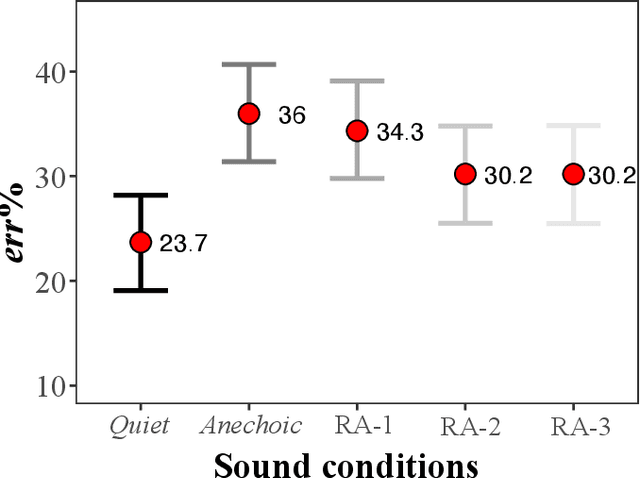
The irrelevant sound effect (ISE) characterizes short-term memory performance impairment during irrelevant sounds relative to quiet. Irrelevant sound presentation in most ISE studies has been rather limited to represent complex scenarios including open-plan offices (OPOs) and not many studies have considered serial recall of heard information. This paper investigates ISE using an auditory-verbal serial recall task, wherein performance was evaluated for relevant factors for simulating OPO acoustics: the irrelevant sounds including speech semanticity, reproduction methods over headphones, and room acoustics. Results (Experiments 1 and 2) show that ISE was exhibited in most conditions with anechoic (irrelevant) nonspeech sounds with/without speech, but the effect was substantially higher with meaningful speech compared to foreign speech, suggesting a semantic effect. Performance differences in conditions with diotic and binaural reproductions were not statistically robust, suggesting limited role of spatial separation of sources. In Experiment 3, statistically robust ISE were exhibited for binaural room acoustic conditions with mid-frequency reverberation times, T30 (s) = 0.4, 0.8, 1.1, suggesting cognitive impairment regardless of sound absorption representative of OPOs. Performance differences in T30 = 0.4 s relative to T30 = 0.8 and 1.1 s conditions were statistically robust, but not between the latter two conditions. These results suggest that certain findings from ISE studies with idiosyncratic acoustics may not translate well to complex OPO acoustic environments.
Enhancing conversational quality in language learning chatbots: An evaluation of GPT4 for ASR error correction
Jul 19, 2023
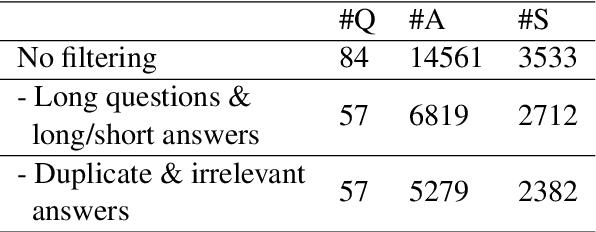


The integration of natural language processing (NLP) technologies into educational applications has shown promising results, particularly in the language learning domain. Recently, many spoken open-domain chatbots have been used as speaking partners, helping language learners improve their language skills. However, one of the significant challenges is the high word-error-rate (WER) when recognizing non-native/non-fluent speech, which interrupts conversation flow and leads to disappointment for learners. This paper explores the use of GPT4 for ASR error correction in conversational settings. In addition to WER, we propose to use semantic textual similarity (STS) and next response sensibility (NRS) metrics to evaluate the impact of error correction models on the quality of the conversation. We find that transcriptions corrected by GPT4 lead to higher conversation quality, despite an increase in WER. GPT4 also outperforms standard error correction methods without the need for in-domain training data.
UnDiff: Unsupervised Voice Restoration with Unconditional Diffusion Model
Jun 01, 2023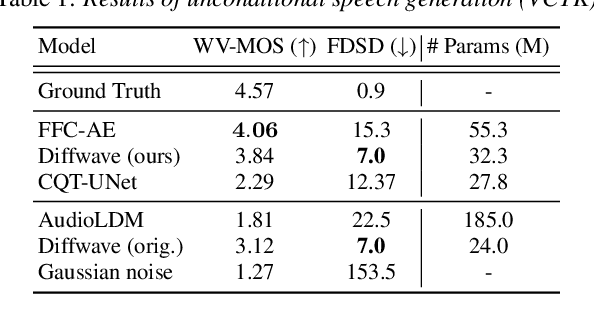
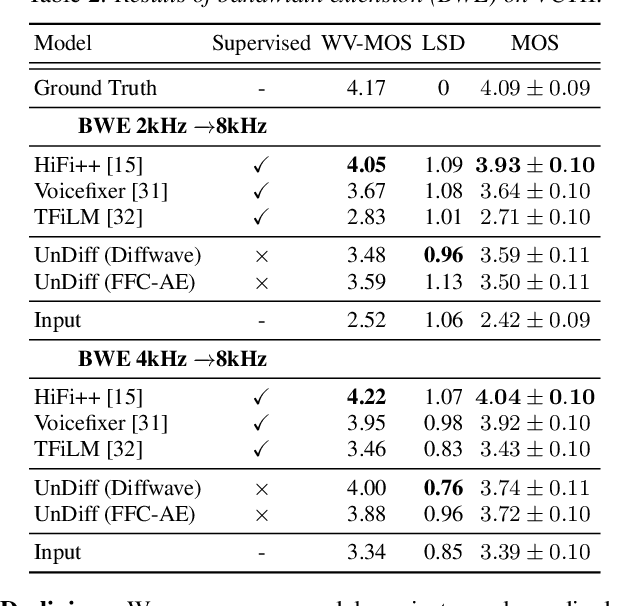
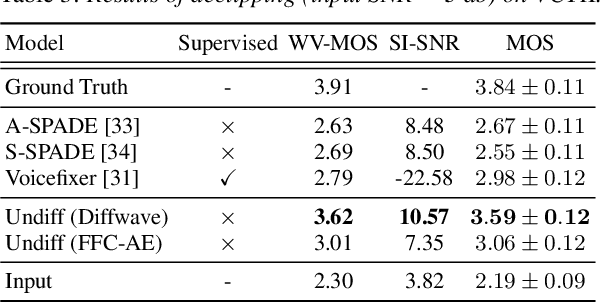
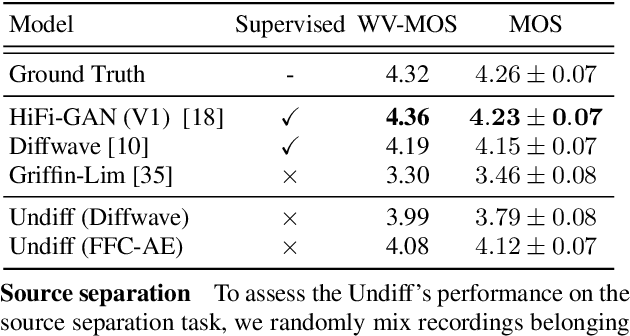
This paper introduces UnDiff, a diffusion probabilistic model capable of solving various speech inverse tasks. Being once trained for speech waveform generation in an unconditional manner, it can be adapted to different tasks including degradation inversion, neural vocoding, and source separation. In this paper, we, first, tackle the challenging problem of unconditional waveform generation by comparing different neural architectures and preconditioning domains. After that, we demonstrate how the trained unconditional diffusion could be adapted to different tasks of speech processing by the means of recent developments in post-training conditioning of diffusion models. Finally, we demonstrate the performance of the proposed technique on the tasks of bandwidth extension, declipping, vocoding, and speech source separation and compare it to the baselines. The codes will be released soon.
Zero-Shot End-to-End Spoken Language Understanding via Cross-Modal Selective Self-Training
May 22, 2023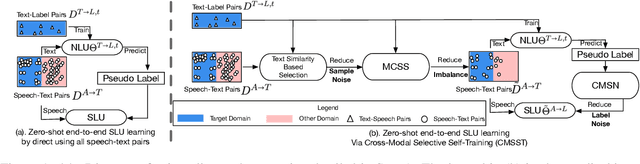
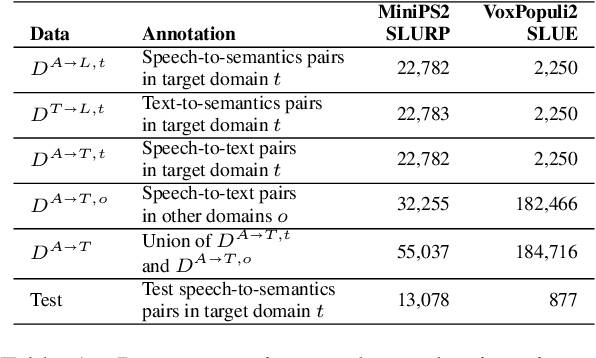
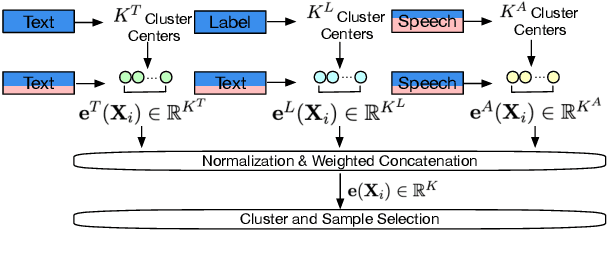
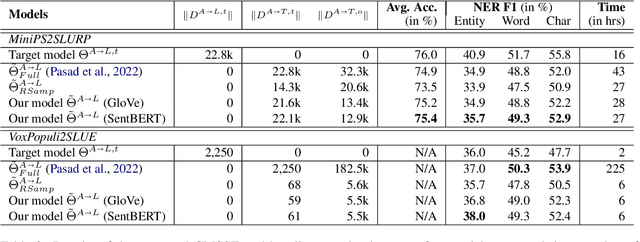
End-to-end (E2E) spoken language understanding (SLU) is constrained by the cost of collecting speech-semantics pairs, especially when label domains change. Hence, we explore \textit{zero-shot} E2E SLU, which learns E2E SLU without speech-semantics pairs, instead using only speech-text and text-semantics pairs. Previous work achieved zero-shot by pseudolabeling all speech-text transcripts with a natural language understanding (NLU) model learned on text-semantics corpora. However, this method requires the domains of speech-text and text-semantics to match, which often mismatch due to separate collections. Furthermore, using the entire speech-text corpus from any domains leads to \textit{imbalance} and \textit{noise} issues. To address these, we propose \textit{cross-modal selective self-training} (CMSST). CMSST tackles imbalance by clustering in a joint space of the three modalities (speech, text, and semantics) and handles label noise with a selection network. We also introduce two benchmarks for zero-shot E2E SLU, covering matched and found speech (mismatched) settings. Experiments show that CMSST improves performance in both two settings, with significantly reduced sample sizes and training time.
ReVISE: Self-Supervised Speech Resynthesis with Visual Input for Universal and Generalized Speech Enhancement
Dec 21, 2022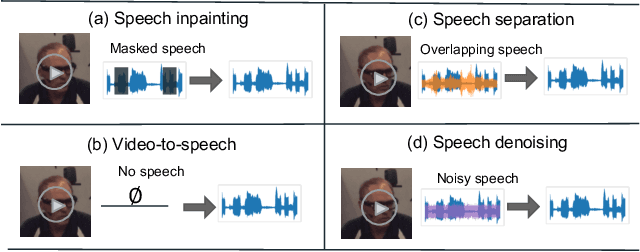
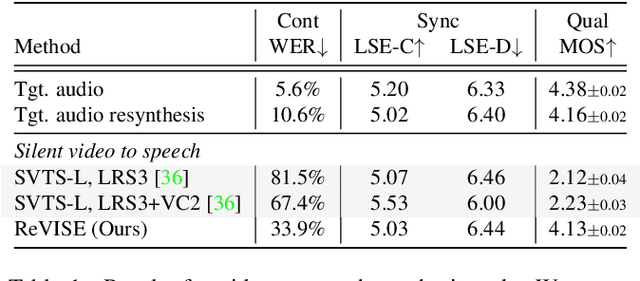
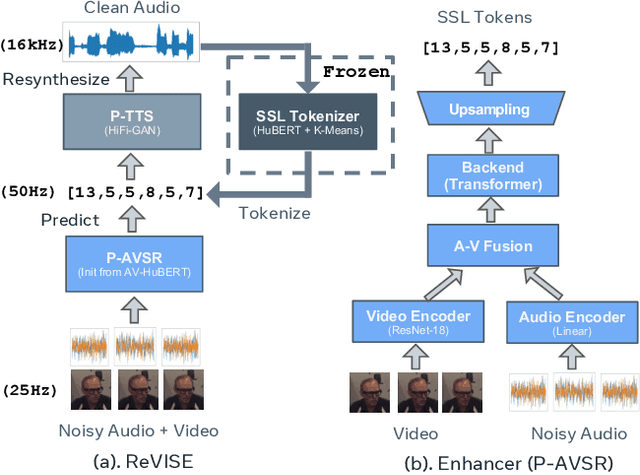
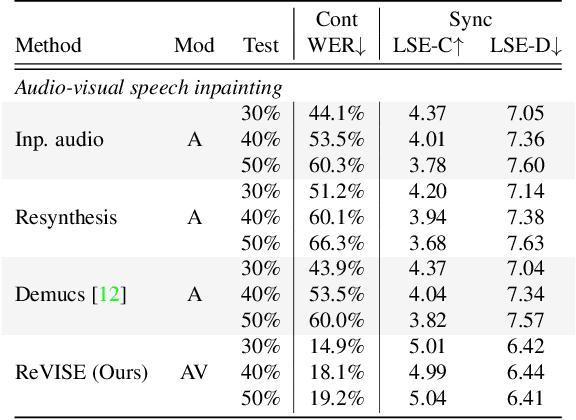
Prior works on improving speech quality with visual input typically study each type of auditory distortion separately (e.g., separation, inpainting, video-to-speech) and present tailored algorithms. This paper proposes to unify these subjects and study Generalized Speech Enhancement, where the goal is not to reconstruct the exact reference clean signal, but to focus on improving certain aspects of speech. In particular, this paper concerns intelligibility, quality, and video synchronization. We cast the problem as audio-visual speech resynthesis, which is composed of two steps: pseudo audio-visual speech recognition (P-AVSR) and pseudo text-to-speech synthesis (P-TTS). P-AVSR and P-TTS are connected by discrete units derived from a self-supervised speech model. Moreover, we utilize self-supervised audio-visual speech model to initialize P-AVSR. The proposed model is coined ReVISE. ReVISE is the first high-quality model for in-the-wild video-to-speech synthesis and achieves superior performance on all LRS3 audio-visual enhancement tasks with a single model. To demonstrates its applicability in the real world, ReVISE is also evaluated on EasyCom, an audio-visual benchmark collected under challenging acoustic conditions with only 1.6 hours of training data. Similarly, ReVISE greatly suppresses noise and improves quality. Project page: https://wnhsu.github.io/ReVISE.