 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models
Feb 20, 2024
In recent years, large language models have achieved significant success in generative tasks (e.g., speech cloning and audio generation) related to speech, audio, music, and other signal domains. A crucial element of these models is the discrete acoustic codecs, which serves as an intermediate representation replacing the mel-spectrogram. However, there exist several gaps between discrete codecs and downstream speech language models. Specifically, 1) most codec models are trained on only 1,000 hours of data, whereas most speech language models are trained on 60,000 hours; 2) Achieving good reconstruction performance requires the utilization of numerous codebooks, which increases the burden on downstream speech language models; 3) The initial channel of the codebooks contains excessive information, making it challenging to directly generate acoustic tokens from weakly supervised signals such as text in downstream tasks. Consequently, leveraging the characteristics of speech language models, we propose Language-Codec. In the Language-Codec, we introduce a Mask Channel Residual Vector Quantization (MCRVQ) mechanism along with improved Fourier transform structures and larger training datasets to address the aforementioned gaps. We compare our method with competing audio compression algorithms and observe significant outperformance across extensive evaluations. Furthermore, we also validate the efficiency of the Language-Codec on downstream speech language models. The source code and pre-trained models can be accessed at https://github.com/jishengpeng/languagecodec .
Graph Expansion in Pruned Recurrent Neural Network Layers Preserve Performance
Mar 17, 2024
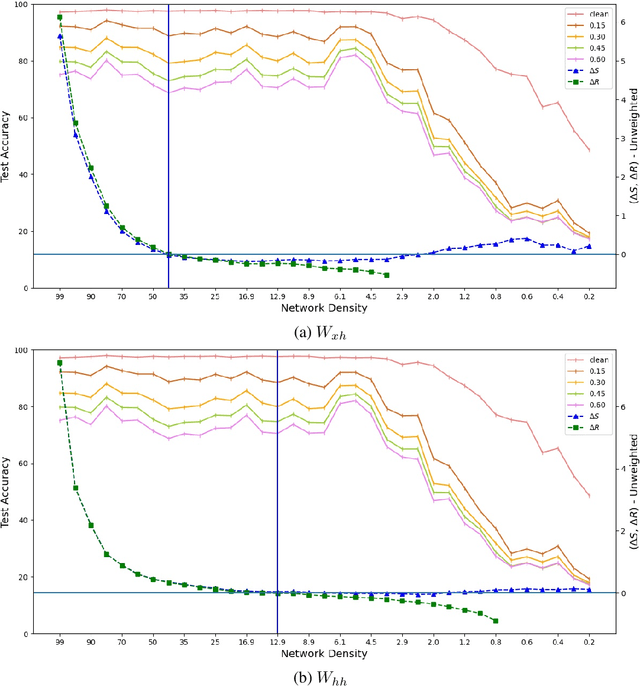
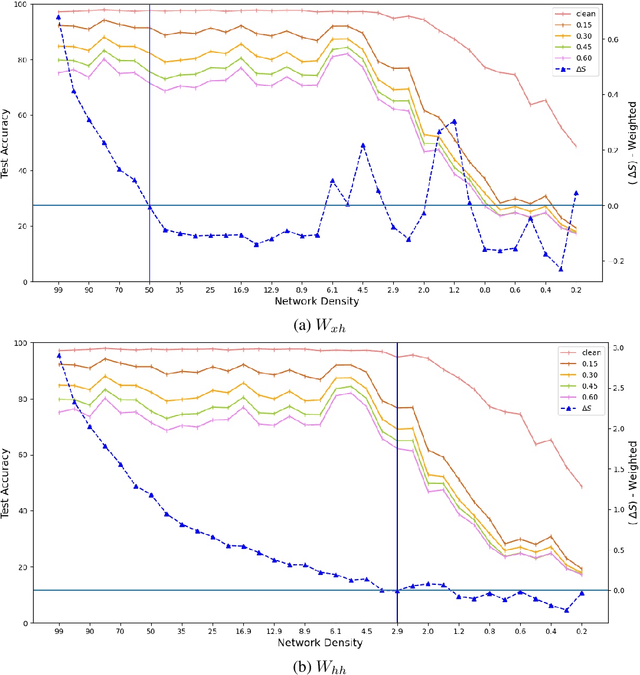
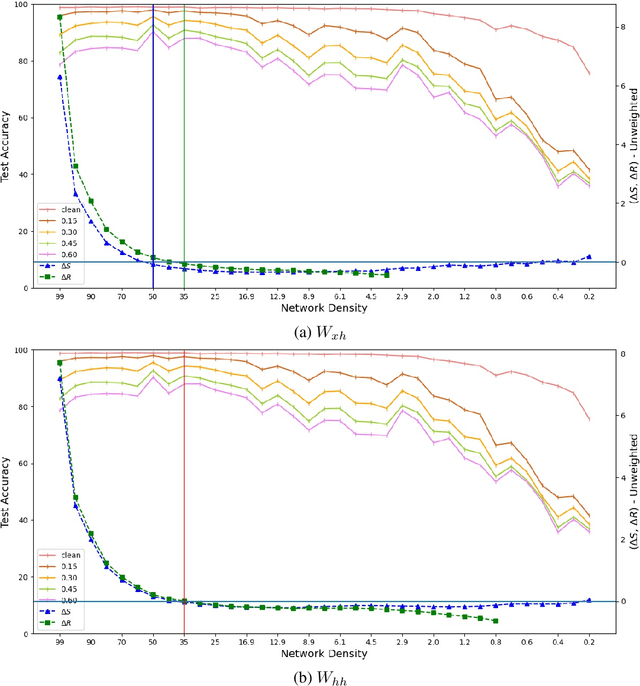
Expansion property of a graph refers to its strong connectivity as well as sparseness. It has been reported that deep neural networks can be pruned to a high degree of sparsity while maintaining their performance. Such pruning is essential for performing real time sequence learning tasks using recurrent neural networks in resource constrained platforms. We prune recurrent networks such as RNNs and LSTMs, maintaining a large spectral gap of the underlying graphs and ensuring their layerwise expansion properties. We also study the time unfolded recurrent network graphs in terms of the properties of their bipartite layers. Experimental results for the benchmark sequence MNIST, CIFAR-10, and Google speech command data show that expander graph properties are key to preserving classification accuracy of RNN and LSTM.
Multimodal Human-Autonomous Agents Interaction Using Pre-Trained Language and Visual Foundation Models
Mar 18, 2024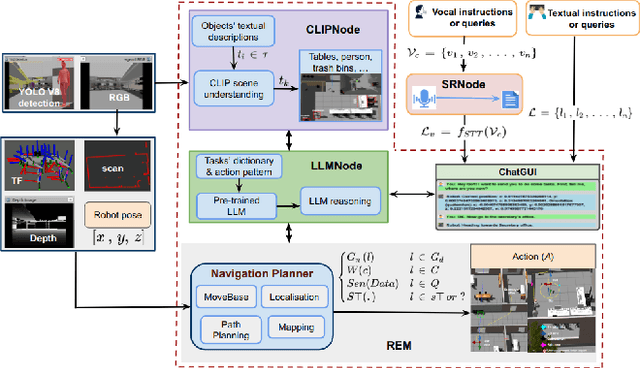
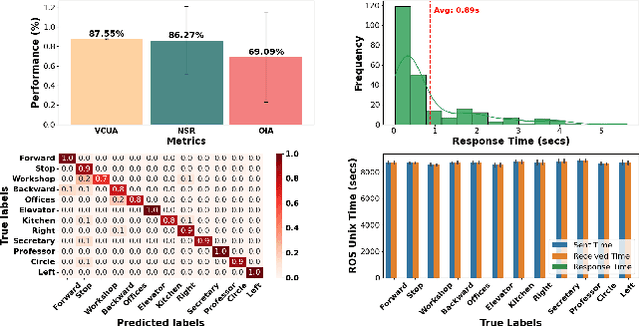
In this paper, we extended the method proposed in [17] to enable humans to interact naturally with autonomous agents through vocal and textual conversations. Our extended method exploits the inherent capabilities of pre-trained large language models (LLMs), multimodal visual language models (VLMs), and speech recognition (SR) models to decode the high-level natural language conversations and semantic understanding of the robot's task environment, and abstract them to the robot's actionable commands or queries. We performed a quantitative evaluation of our framework's natural vocal conversation understanding with participants from different racial backgrounds and English language accents. The participants interacted with the robot using both spoken and textual instructional commands. Based on the logged interaction data, our framework achieved 87.55% vocal commands decoding accuracy, 86.27% commands execution success, and an average latency of 0.89 seconds from receiving the participants' vocal chat commands to initiating the robot's actual physical action. The video demonstrations of this paper can be found at https://linusnep.github.io/MTCC-IRoNL/.
ScanTalk: 3D Talking Heads from Unregistered Scans
Mar 19, 2024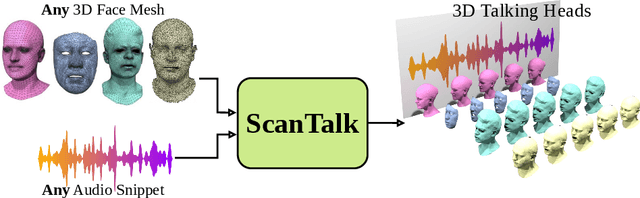

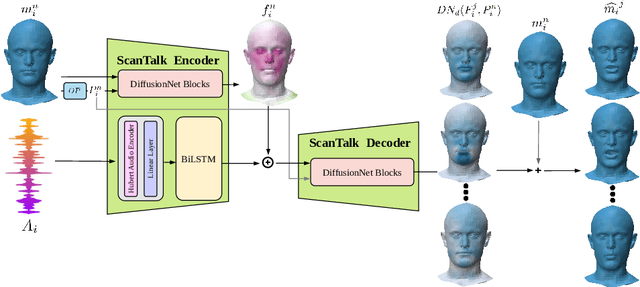

Speech-driven 3D talking heads generation has emerged as a significant area of interest among researchers, presenting numerous challenges. Existing methods are constrained by animating faces with fixed topologies, wherein point-wise correspondence is established, and the number and order of points remains consistent across all identities the model can animate. In this work, we present ScanTalk, a novel framework capable of animating 3D faces in arbitrary topologies including scanned data. Our approach relies on the DiffusionNet architecture to overcome the fixed topology constraint, offering promising avenues for more flexible and realistic 3D animations. By leveraging the power of DiffusionNet, ScanTalk not only adapts to diverse facial structures but also maintains fidelity when dealing with scanned data, thereby enhancing the authenticity and versatility of generated 3D talking heads. Through comprehensive comparisons with state-of-the-art methods, we validate the efficacy of our approach, demonstrating its capacity to generate realistic talking heads comparable to existing techniques. While our primary objective is to develop a generic method free from topological constraints, all state-of-the-art methodologies are bound by such limitations. Code for reproducing our results, and the pre-trained model will be made available.
HateCOT: An Explanation-Enhanced Dataset for Generalizable Offensive Speech Detection via Large Language Models
Mar 18, 2024
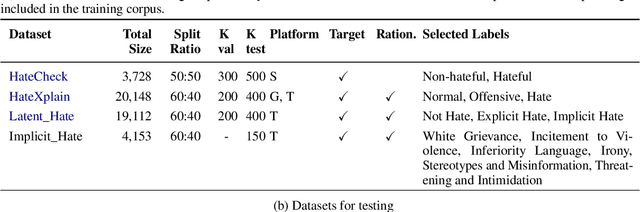
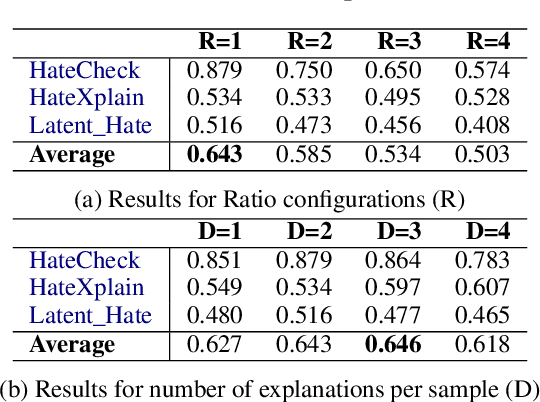
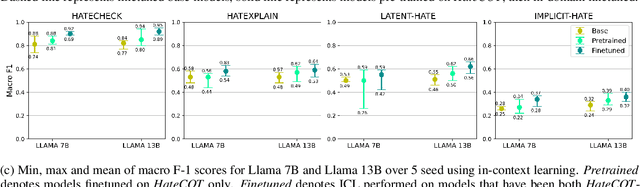
The ubiquitousness of social media has led to the need for reliable and efficient detection of offensive content to limit harmful effects. This has led to a proliferation of datasets and models related to detecting offensive content. While sophisticated models have attained strong performance on individual datasets, these models often do not generalize due to differences between how "offensive content" is conceptualized, and the resulting differences in how these datasets are labeled. In this paper, we introduce HateCOT, a dataset of 52,000 samples drawn from diverse existing sources with explanations generated by GPT-3.5-Turbo and human-curated. We show that pre-training models for the detection of offensive content on HateCOT significantly boots open-sourced Language Models on three benchmark datasets in both zero and few-shot settings, despite differences in domain and task.} We further find that HateCOT enables effective K-shot fine-tuning in the low-resource settings.
Don't Go To Extremes: Revealing the Excessive Sensitivity and Calibration Limitations of LLMs in Implicit Hate Speech Detection
Feb 26, 2024The fairness and trustworthiness of Large Language Models (LLMs) are receiving increasing attention. Implicit hate speech, which employs indirect language to convey hateful intentions, occupies a significant portion of practice. However, the extent to which LLMs effectively address this issue remains insufficiently examined. This paper delves into the capability of LLMs to detect implicit hate speech (Classification Task) and express confidence in their responses (Calibration Task). Our evaluation meticulously considers various prompt patterns and mainstream uncertainty estimation methods. Our findings highlight that LLMs exhibit two extremes: (1) LLMs display excessive sensitivity towards groups or topics that may cause fairness issues, resulting in misclassifying benign statements as hate speech. (2) LLMs' confidence scores for each method excessively concentrate on a fixed range, remaining unchanged regardless of the dataset's complexity. Consequently, the calibration performance is heavily reliant on primary classification accuracy. These discoveries unveil new limitations of LLMs, underscoring the need for caution when optimizing models to ensure they do not veer towards extremes. This serves as a reminder to carefully consider sensitivity and confidence in the pursuit of model fairness.
Analysis of Self-Supervised Speech Models on Children's Speech and Infant Vocalizations
Feb 10, 2024To understand why self-supervised learning (SSL) models have empirically achieved strong performances on several speech-processing downstream tasks, numerous studies have focused on analyzing the encoded information of the SSL layer representations in adult speech. Limited work has investigated how pre-training and fine-tuning affect SSL models encoding children's speech and vocalizations. In this study, we aim to bridge this gap by probing SSL models on two relevant downstream tasks: (1) phoneme recognition (PR) on the speech of adults, older children (8-10 years old), and younger children (1-4 years old), and (2) vocalization classification (VC) distinguishing cry, fuss, and babble for infants under 14 months old. For younger children's PR, the superiority of fine-tuned SSL models is largely due to their ability to learn features that represent older children's speech and then adapt those features to the speech of younger children. For infant VC, SSL models pre-trained on large-scale home recordings learn to leverage phonetic representations at middle layers, and thereby enhance the performance of this task.
The Effect of Batch Size on Contrastive Self-Supervised Speech Representation Learning
Feb 21, 2024Foundation models in speech are often trained using many GPUs, which implicitly leads to large effective batch sizes. In this paper we study the effect of batch size on pre-training, both in terms of statistics that can be monitored during training, and in the effect on the performance of a downstream fine-tuning task. By using batch sizes varying from 87.5 seconds to 80 minutes of speech we show that, for a fixed amount of iterations, larger batch sizes result in better pre-trained models. However, there is lower limit for stability, and an upper limit for effectiveness. We then show that the quality of the pre-trained model depends mainly on the amount of speech data seen during training, i.e., on the product of batch size and number of iterations. All results are produced with an independent implementation of the wav2vec 2.0 architecture, which to a large extent reproduces the results of the original work (arXiv:2006.11477). Our extensions can help researchers choose effective operating conditions when studying self-supervised learning in speech, and hints towards benchmarking self-supervision with a fixed amount of seen data. Code and model checkpoints are available at https://github.com/nikvaessen/w2v2-batch-size.
Automatic Speech Recognition using Advanced Deep Learning Approaches: A survey
Mar 02, 2024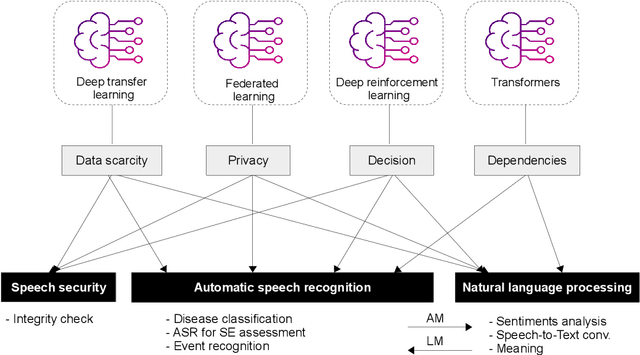
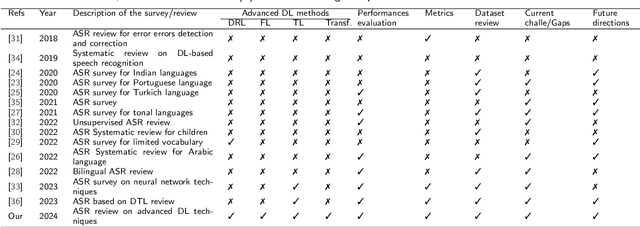
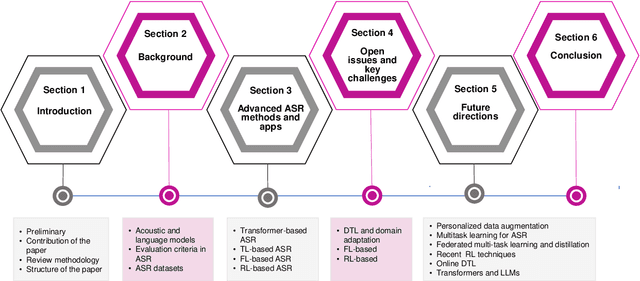
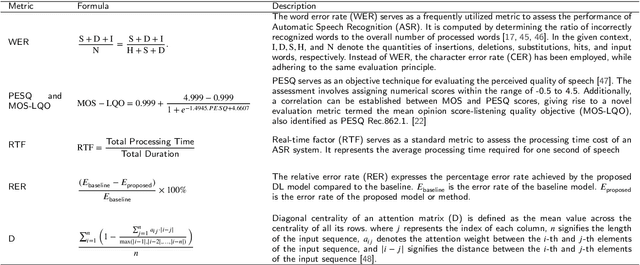
Recent advancements in deep learning (DL) have posed a significant challenge for automatic speech recognition (ASR). ASR relies on extensive training datasets, including confidential ones, and demands substantial computational and storage resources. Enabling adaptive systems improves ASR performance in dynamic environments. DL techniques assume training and testing data originate from the same domain, which is not always true. Advanced DL techniques like deep transfer learning (DTL), federated learning (FL), and reinforcement learning (RL) address these issues. DTL allows high-performance models using small yet related datasets, FL enables training on confidential data without dataset possession, and RL optimizes decision-making in dynamic environments, reducing computation costs. This survey offers a comprehensive review of DTL, FL, and RL-based ASR frameworks, aiming to provide insights into the latest developments and aid researchers and professionals in understanding the current challenges. Additionally, transformers, which are advanced DL techniques heavily used in proposed ASR frameworks, are considered in this survey for their ability to capture extensive dependencies in the input ASR sequence. The paper starts by presenting the background of DTL, FL, RL, and Transformers and then adopts a well-designed taxonomy to outline the state-of-the-art approaches. Subsequently, a critical analysis is conducted to identify the strengths and weaknesses of each framework. Additionally, a comparative study is presented to highlight the existing challenges, paving the way for future research opportunities.
Beyond Hate Speech: NLP's Challenges and Opportunities in Uncovering Dehumanizing Language
Feb 21, 2024Dehumanization, characterized as a subtle yet harmful manifestation of hate speech, involves denying individuals of their human qualities and often results in violence against marginalized groups. Despite significant progress in Natural Language Processing across various domains, its application in detecting dehumanizing language is limited, largely due to the scarcity of publicly available annotated data for this domain. This paper evaluates the performance of cutting-edge NLP models, including GPT-4, GPT-3.5, and LLAMA-2, in identifying dehumanizing language. Our findings reveal that while these models demonstrate potential, achieving a 70\% accuracy rate in distinguishing dehumanizing language from broader hate speech, they also display biases. They are over-sensitive in classifying other forms of hate speech as dehumanization for a specific subset of target groups, while more frequently failing to identify clear cases of dehumanization for other target groups. Moreover, leveraging one of the best-performing models, we automatically annotated a larger dataset for training more accessible models. However, our findings indicate that these models currently do not meet the high-quality data generation threshold necessary for this task.