 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CoSyn: Detecting Implicit Hate Speech in Online Conversations Using a Context Synergized Hyperbolic Network
Mar 10, 2023

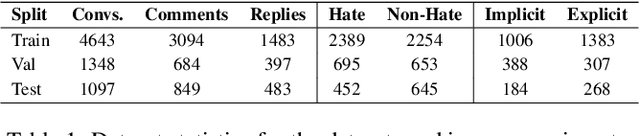
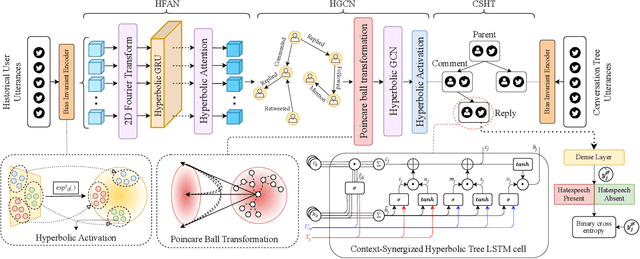
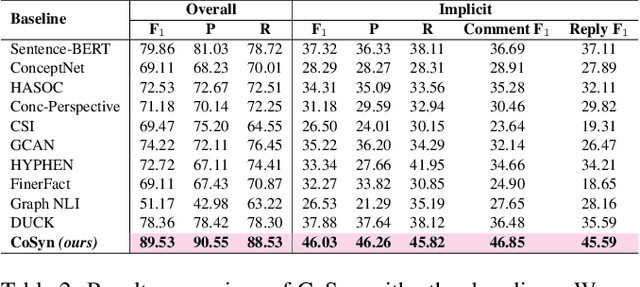
The tremendous growth of social media users interacting in online conversations has also led to significant growth in hate speech. Most of the prior works focus on detecting explicit hate speech, which is overt and leverages hateful phrases, with very little work focusing on detecting hate speech that is implicit or denotes hatred through indirect or coded language. In this paper, we present CoSyn, a user- and conversational-context synergized network for detecting implicit hate speech in online conversation trees. CoSyn first models the user's personal historical and social context using a novel hyperbolic Fourier attention mechanism and hyperbolic graph convolution network. Next, we jointly model the user's personal context and the conversational context using a novel context interaction mechanism in the hyperbolic space that clearly captures the interplay between the two and makes independent assessments on the amounts of information to be retrieved from both contexts. CoSyn performs all operations in the hyperbolic space to account for the scale-free dynamics of social media. We demonstrate the effectiveness of CoSyn both qualitatively and quantitatively on an open-source hate speech dataset with Twitter conversations and show that CoSyn outperforms all our baselines in detecting implicit hate speech with absolute improvements in the range of 8.15% - 19.50%.
Real-time speech enhancement with dynamic attention span
Feb 21, 2023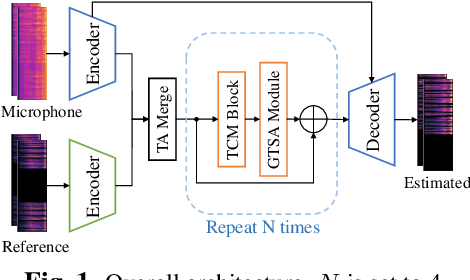
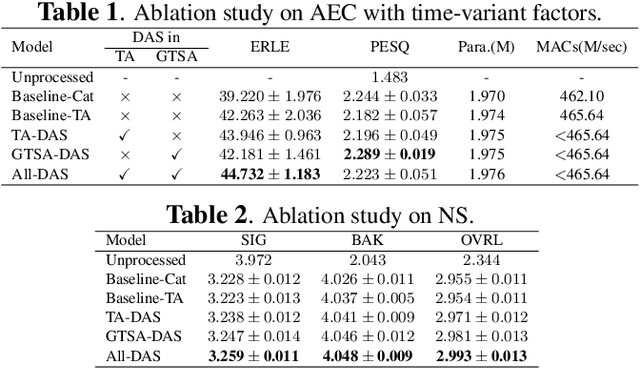
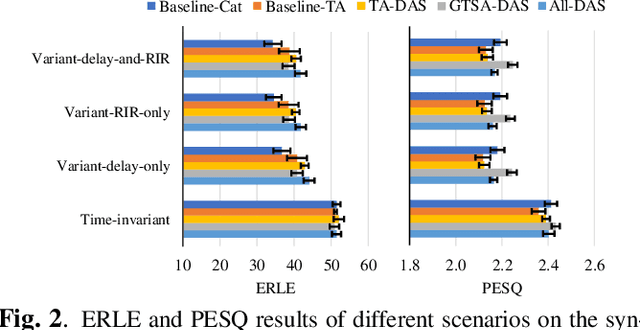
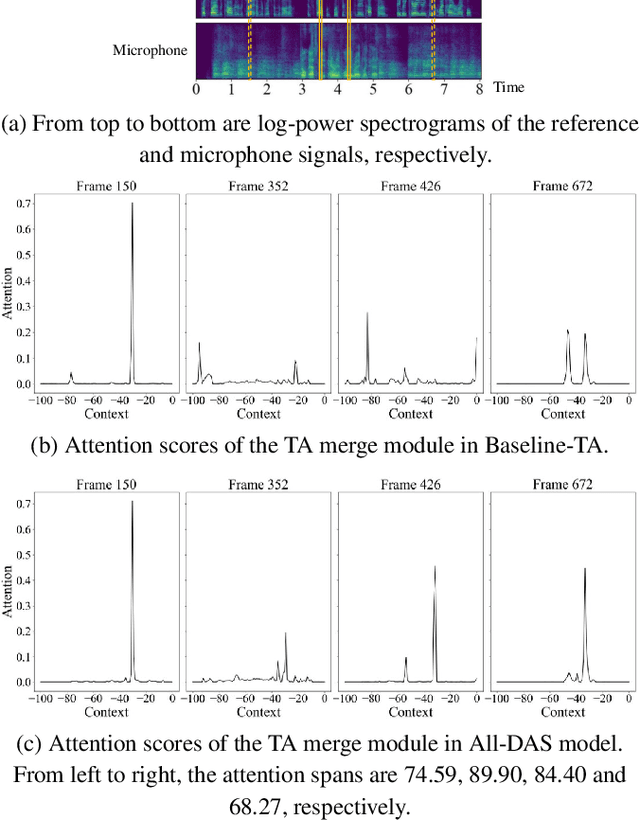
For real-time speech enhancement (SE) including noise suppression, dereverberation and acoustic echo cancellation, the time-variance of the audio signals becomes a severe challenge. The causality and memory usage limit that only the historical information can be used for the system to capture the time-variant characteristics. We propose to adaptively change the receptive field according to the input signal in deep neural network based SE model. Specifically, in an encoder-decoder framework, a dynamic attention span mechanism is introduced to all the attention modules for controlling the size of historical content used for processing the current frame. Experimental results verify that this dynamic mechanism can better track time-variant factors and capture speech-related characteristics, benefiting to both interference removing and speech quality retaining.
Developmental Bootstrapping of AIs
Aug 08, 2023

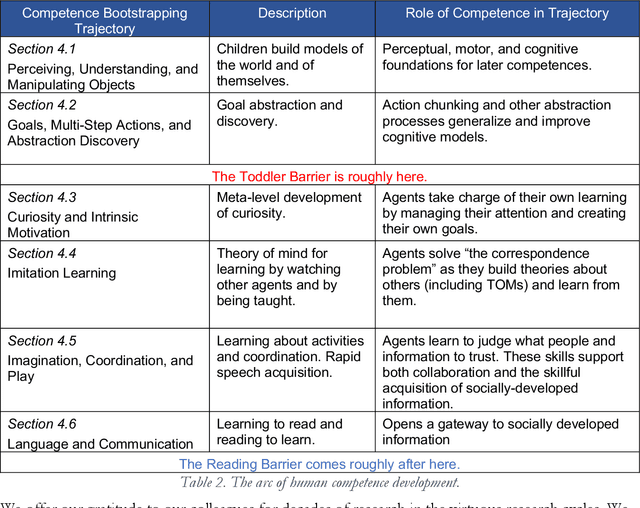
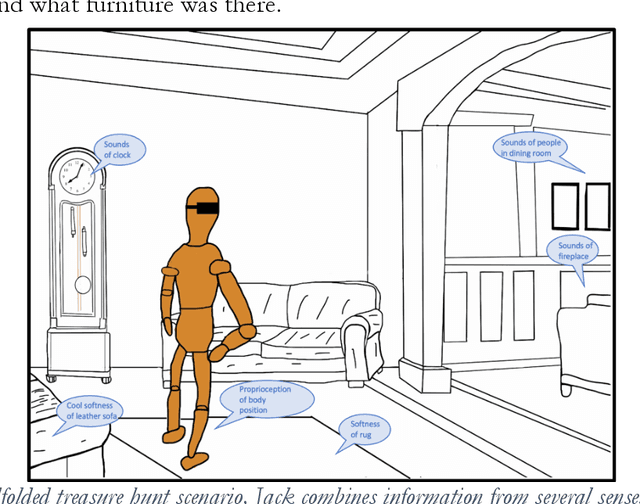
Although some current AIs surpass human abilities especially in closed worlds such as board games, their performance in the messy real world is limited. They make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. They do not make good collaborators. Neither systems built using the traditional manually-constructed symbolic AI approach nor systems built using generative and deep learning AI approaches including large language models (LLMs) can meet the challenges. They are not well suited for creating robust and trustworthy AIs. Although it is outside of mainstream AI approaches, developmental bootstrapping shows promise. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. Like humans, they interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. Following a bootstrapping process, they acquire the competences that they need. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped at the Toddler Barrier corresponding to human infant development at about two years of age, before speech is fluent. They also do not bridge the Reading Barrier, where they can skillfully and skeptically tap into the vast socially developed recorded information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to create robust and resilient AIs.
A Time-Frequency Generative Adversarial based method for Audio Packet Loss Concealment
Jul 28, 2023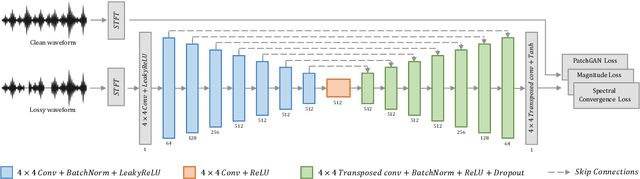
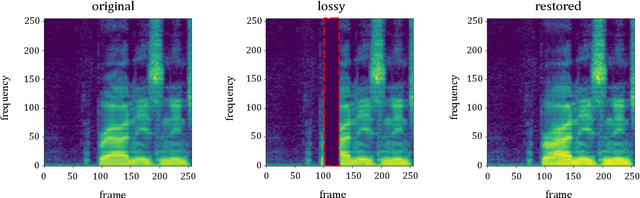
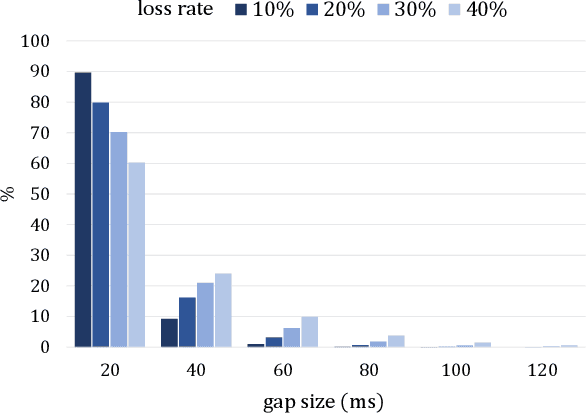
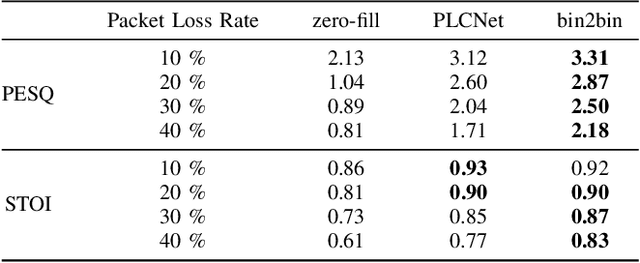
Packet loss is a major cause of voice quality degradation in VoIP transmissions with serious impact on intelligibility and user experience. This paper describes a system based on a generative adversarial approach, which aims to repair the lost fragments during the transmission of audio streams. Inspired by the powerful image-to-image translation capability of Generative Adversarial Networks (GANs), we propose bin2bin, an improved pix2pix framework to achieve the translation task from magnitude spectrograms of audio frames with lost packets, to noncorrupted speech spectrograms. In order to better maintain the structural information after spectrogram translation, this paper introduces the combination of two STFT-based loss functions, mixed with the traditional GAN objective. Furthermore, we employ a modified PatchGAN structure as discriminator and we lower the concealment time by a proper initialization of the phase reconstruction algorithm. Experimental results show that the proposed method has obvious advantages when compared with the current state-of-the-art methods, as it can better handle both high packet loss rates and large gaps.
Signal Reconstruction from Mel-spectrogram Based on Bi-level Consistency of Full-band Magnitude and Phase
Jul 23, 2023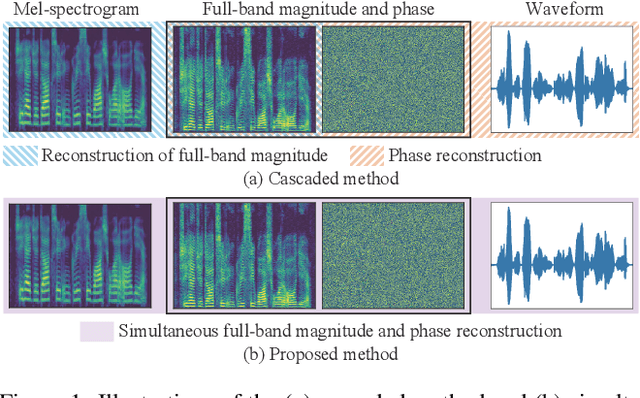
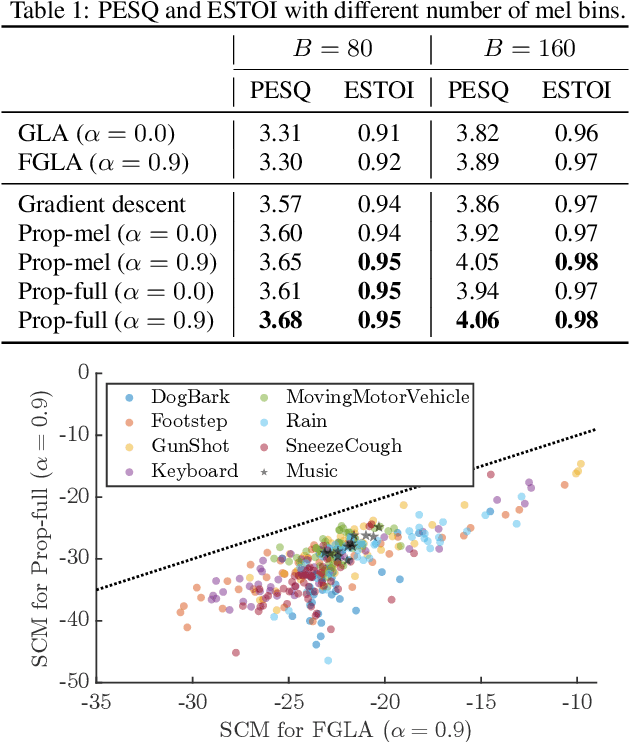
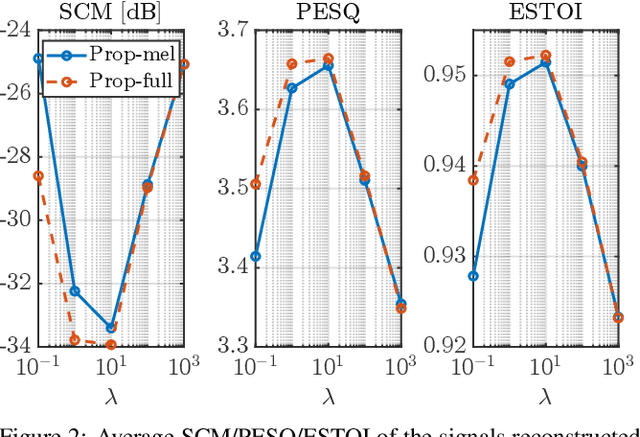
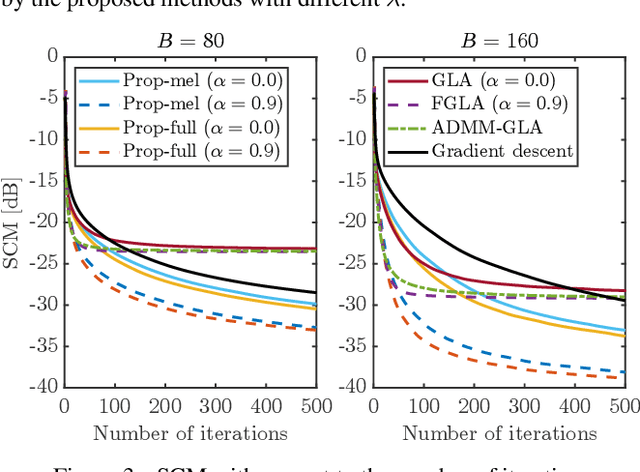
We propose an optimization-based method for reconstructing a time-domain signal from a low-dimensional spectral representation such as a mel-spectrogram. Phase reconstruction has been studied to reconstruct a time-domain signal from the full-band short-time Fourier transform (STFT) magnitude. The Griffin-Lim algorithm (GLA) has been widely used because it relies only on the redundancy of STFT and is applicable to various audio signals. In this paper, we jointly reconstruct the full-band magnitude and phase by considering the bi-level relationships among the time-domain signal, its STFT coefficients, and its mel-spectrogram. The proposed method is formulated as a rigorous optimization problem and estimates the full-band magnitude based on the criterion used in GLA. Our experiments demonstrate the effectiveness of the proposed method on speech, music, and environmental signals.
A Model for Every User and Budget: Label-Free and Personalized Mixed-Precision Quantization
Jul 24, 2023Recent advancement in Automatic Speech Recognition (ASR) has produced large AI models, which become impractical for deployment in mobile devices. Model quantization is effective to produce compressed general-purpose models, however such models may only be deployed to a restricted sub-domain of interest. We show that ASR models can be personalized during quantization while relying on just a small set of unlabelled samples from the target domain. To this end, we propose myQASR, a mixed-precision quantization method that generates tailored quantization schemes for diverse users under any memory requirement with no fine-tuning. myQASR automatically evaluates the quantization sensitivity of network layers by analysing the full-precision activation values. We are then able to generate a personalised mixed-precision quantization scheme for any pre-determined memory budget. Results for large-scale ASR models show how myQASR improves performance for specific genders, languages, and speakers.
Online Continual Learning in Keyword Spotting for Low-Resource Devices via Pooling High-Order Temporal Statistics
Jul 24, 2023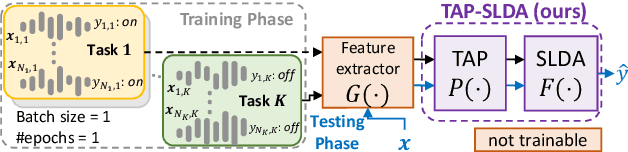
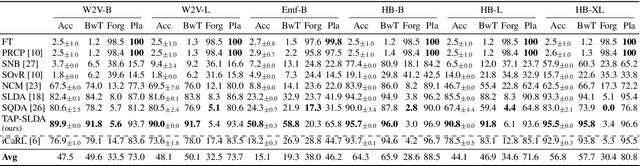
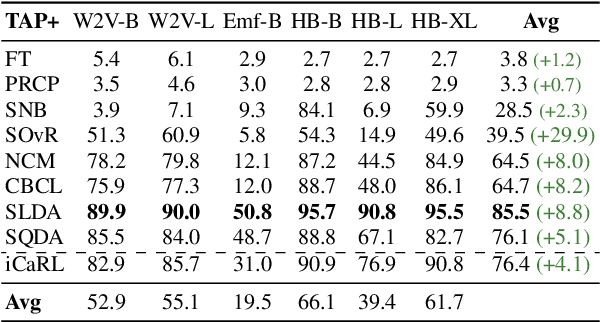
Keyword Spotting (KWS) models on embedded devices should adapt fast to new user-defined words without forgetting previous ones. Embedded devices have limited storage and computational resources, thus, they cannot save samples or update large models. We consider the setup of embedded online continual learning (EOCL), where KWS models with frozen backbone are trained to incrementally recognize new words from a non-repeated stream of samples, seen one at a time. To this end, we propose Temporal Aware Pooling (TAP) which constructs an enriched feature space computing high-order moments of speech features extracted by a pre-trained backbone. Our method, TAP-SLDA, updates a Gaussian model for each class on the enriched feature space to effectively use audio representations. In experimental analyses, TAP-SLDA outperforms competitors on several setups, backbones, and baselines, bringing a relative average gain of 11.3% on the GSC dataset.
WhisperX: Time-Accurate Speech Transcription of Long-Form Audio
Mar 01, 2023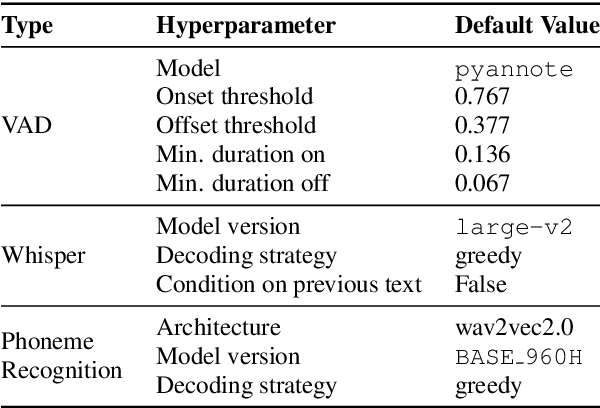

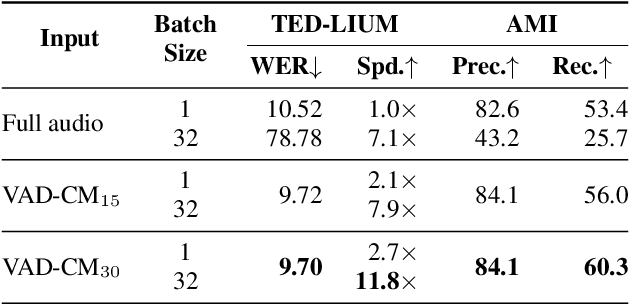
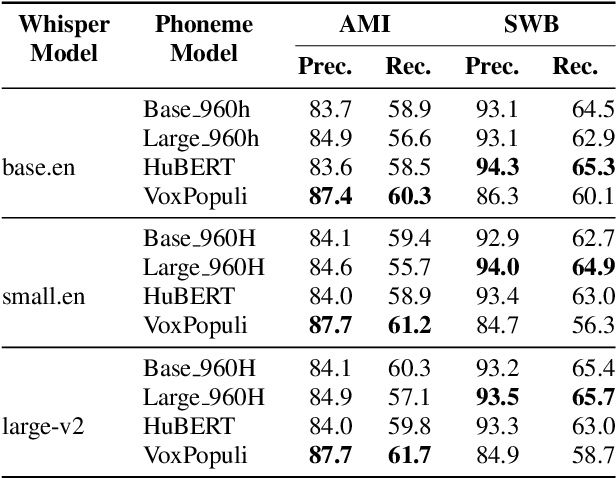
Large-scale, weakly-supervised speech recognition models, such as Whisper, have demonstrated impressive results on speech recognition across domains and languages. However, their application to long audio transcription via buffered or sliding window approaches is prone to drifting, hallucination & repetition; and prohibits batched transcription due to their sequential nature. Further, timestamps corresponding each utterance are prone to inaccuracies and word-level timestamps are not available out-of-the-box. To overcome these challenges, we present WhisperX, a time-accurate speech recognition system with word-level timestamps utilising voice activity detection and forced phoneme alignment. In doing so, we demonstrate state-of-the-art performance on long-form transcription and word segmentation benchmarks. Additionally, we show that pre-segmenting audio with our proposed VAD Cut & Merge strategy improves transcription quality and enables a twelve-fold transcription speedup via batched inference.
Factors Affecting the Performance of Automated Speaker Verification in Alzheimer's Disease Clinical Trials
Jun 20, 2023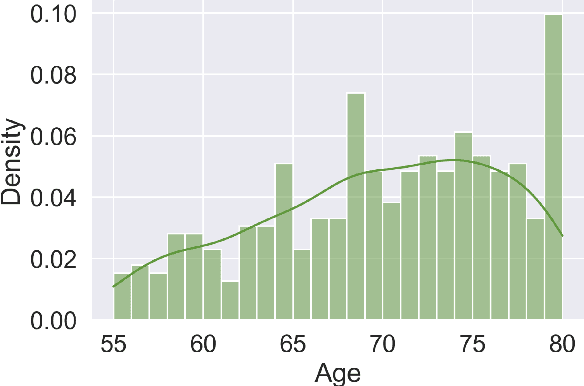

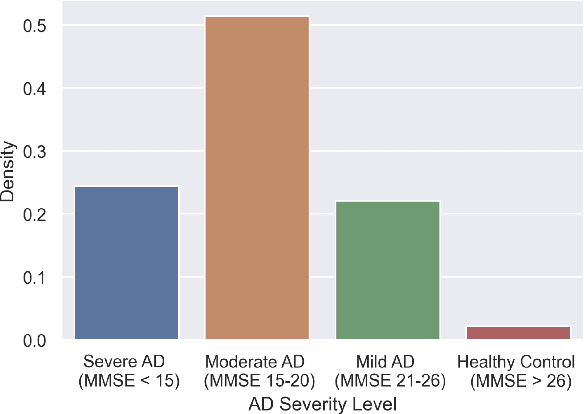

Detecting duplicate patient participation in clinical trials is a major challenge because repeated patients can undermine the credibility and accuracy of the trial's findings and result in significant health and financial risks. Developing accurate automated speaker verification (ASV) models is crucial to verify the identity of enrolled individuals and remove duplicates, but the size and quality of data influence ASV performance. However, there has been limited investigation into the factors that can affect ASV capabilities in clinical environments. In this paper, we bridge the gap by conducting analysis of how participant demographic characteristics, audio quality criteria, and severity level of Alzheimer's disease (AD) impact the performance of ASV utilizing a dataset of speech recordings from 659 participants with varying levels of AD, obtained through multiple speech tasks. Our results indicate that ASV performance: 1) is slightly better on male speakers than on female speakers; 2) degrades for individuals who are above 70 years old; 3) is comparatively better for non-native English speakers than for native English speakers; 4) is negatively affected by clinician interference, noisy background, and unclear participant speech; 5) tends to decrease with an increase in the severity level of AD. Our study finds that voice biometrics raise fairness concerns as certain subgroups exhibit different ASV performances owing to their inherent voice characteristics. Moreover, the performance of ASV is influenced by the quality of speech recordings, which underscores the importance of improving the data collection settings in clinical trials.
Generative Emotional AI for Speech Emotion Recognition: The Case for Synthetic Emotional Speech Augmentation
Jan 10, 2023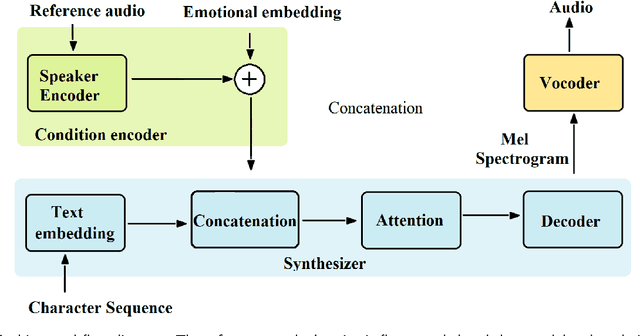
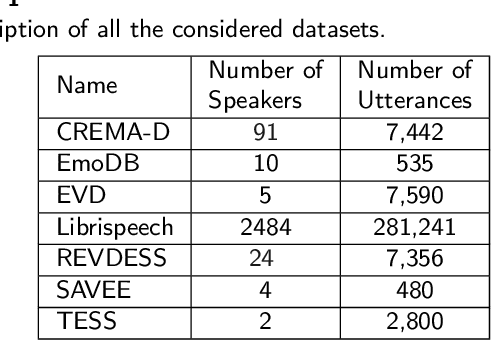
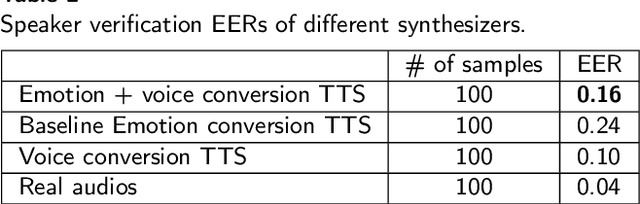
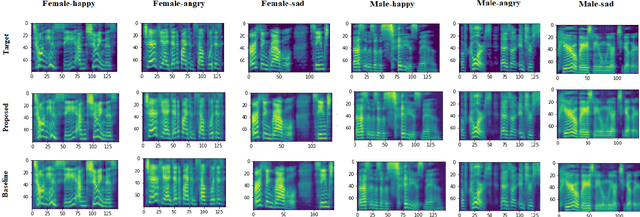
Despite advances in deep learning, current state-of-the-art speech emotion recognition (SER) systems still have poor performance due to a lack of speech emotion datasets. This paper proposes augmenting SER systems with synthetic emotional speech generated by an end-to-end text-to-speech (TTS) system based on an extended Tacotron architecture. The proposed TTS system includes encoders for speaker and emotion embeddings, a sequence-to-sequence text generator for creating Mel-spectrograms, and a WaveRNN to generate audio from the Mel-spectrograms. Extensive experiments show that the quality of the generated emotional speech can significantly improve SER performance on multiple datasets, as demonstrated by a higher mean opinion score (MOS) compared to the baseline. The generated samples were also effective at augmenting SER performance.