 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023
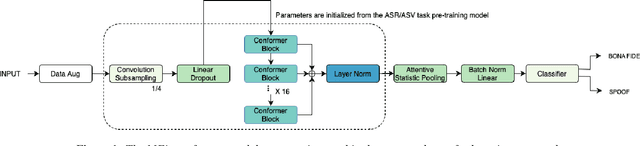
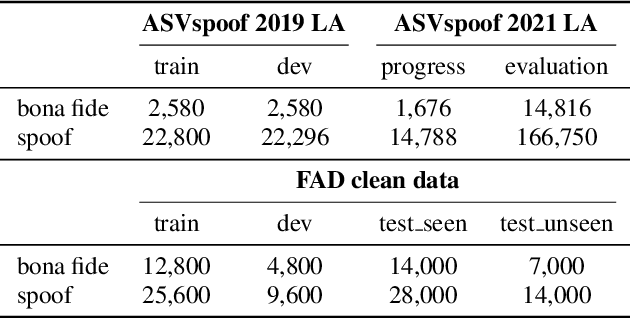
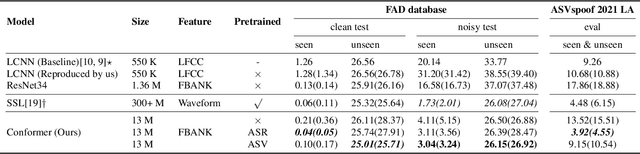
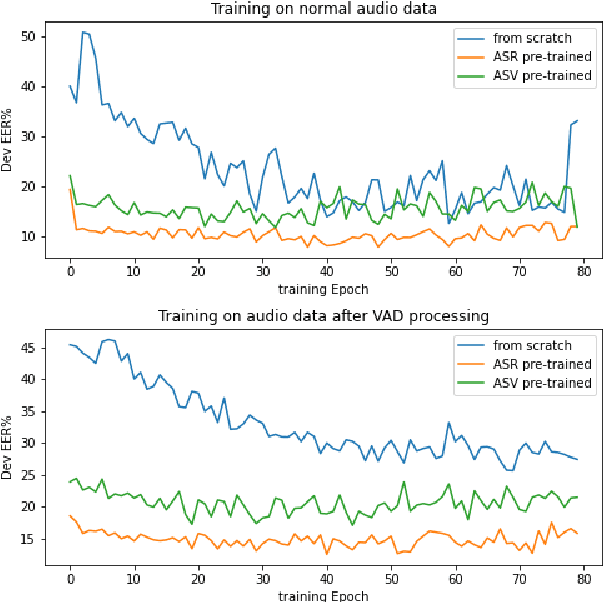
This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.
DIVERSIFY: A General Framework for Time Series Out-of-distribution Detection and Generalization
Aug 04, 2023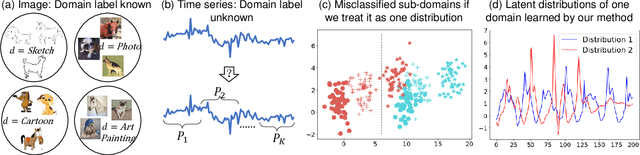
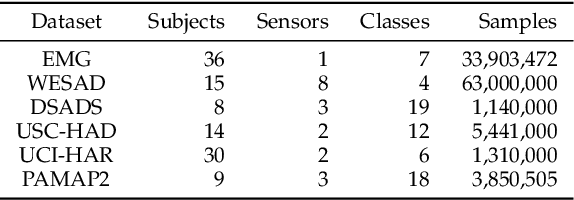

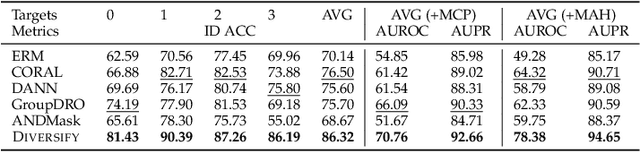
Time series remains one of the most challenging modalities in machine learning research. The out-of-distribution (OOD) detection and generalization on time series tend to suffer due to its non-stationary property, i.e., the distribution changes over time. The dynamic distributions inside time series pose great challenges to existing algorithms to identify invariant distributions since they mainly focus on the scenario where the domain information is given as prior knowledge. In this paper, we attempt to exploit subdomains within a whole dataset to counteract issues induced by non-stationary for generalized representation learning. We propose DIVERSIFY, a general framework, for OOD detection and generalization on dynamic distributions of time series. DIVERSIFY takes an iterative process: it first obtains the "worst-case" latent distribution scenario via adversarial training, then reduces the gap between these latent distributions. We implement DIVERSIFY via combining existing OOD detection methods according to either extracted features or outputs of models for detection while we also directly utilize outputs for classification. In addition, theoretical insights illustrate that DIVERSIFY is theoretically supported. Extensive experiments are conducted on seven datasets with different OOD settings across gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition. Qualitative and quantitative results demonstrate that DIVERSIFY learns more generalized features and significantly outperforms other baselines.
DSARSR: Deep Stacked Auto-encoders Enhanced Robust Speaker Recognition
Jul 06, 2023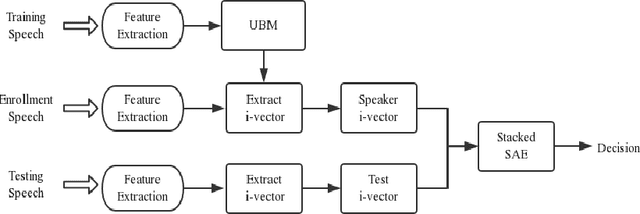

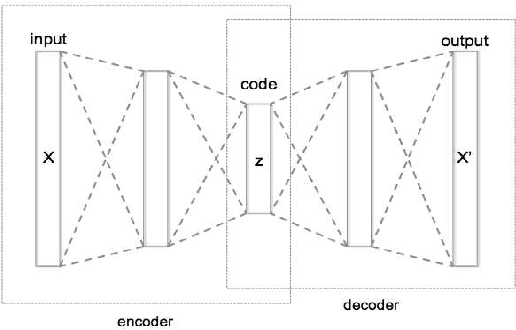
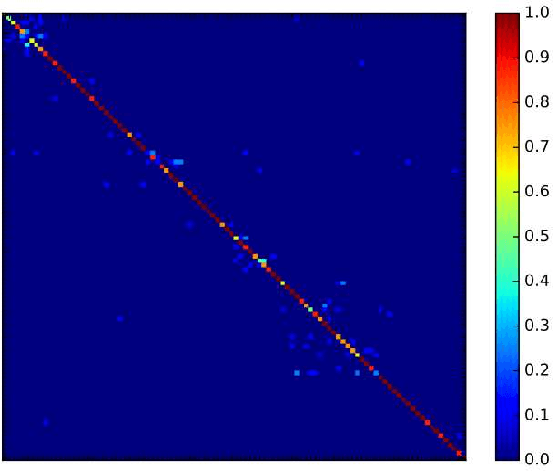
Speaker recognition is a biometric modality that utilizes the speaker's speech segments to recognize the identity, determining whether the test speaker belongs to one of the enrolled speakers. In order to improve the robustness of the i-vector framework on cross-channel conditions and explore the nova method for applying deep learning to speaker recognition, the Stacked Auto-encoders are used to get the abstract extraction of the i-vector instead of applying PLDA. After pre-processing and feature extraction, the speaker and channel-independent speeches are employed for UBM training. The UBM is then used to extract the i-vector of the enrollment and test speech. Unlike the traditional i-vector framework, which uses linear discriminant analysis (LDA) to reduce dimension and increase the discrimination between speaker subspaces, this research use stacked auto-encoders to reconstruct the i-vector with lower dimension and different classifiers can be chosen to achieve final classification. The experimental results show that the proposed method achieves better performance than the state-of-the-art method.
On the Audio-visual Synchronization for Lip-to-Speech Synthesis
Mar 01, 2023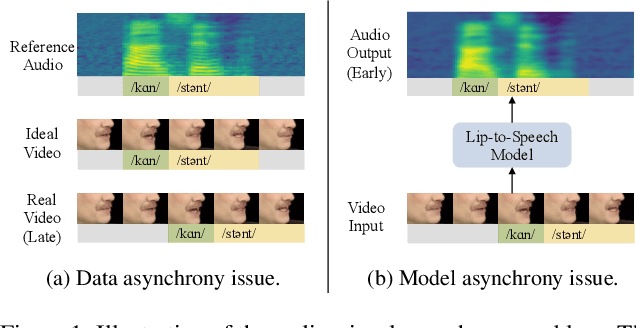

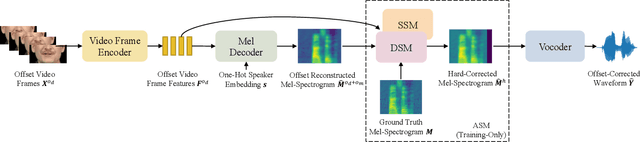

Most lip-to-speech (LTS) synthesis models are trained and evaluated under the assumption that the audio-video pairs in the dataset are perfectly synchronized. In this work, we show that the commonly used audio-visual datasets, such as GRID, TCD-TIMIT, and Lip2Wav, can have data asynchrony issues. Training lip-to-speech with such datasets may further cause the model asynchrony issue -- that is, the generated speech and the input video are out of sync. To address these asynchrony issues, we propose a synchronized lip-to-speech (SLTS) model with an automatic synchronization mechanism (ASM) to correct data asynchrony and penalize model asynchrony. We further demonstrate the limitation of the commonly adopted evaluation metrics for LTS with asynchronous test data and introduce an audio alignment frontend before the metrics sensitive to time alignment for better evaluation. We compare our method with state-of-the-art approaches on conventional and time-aligned metrics to show the benefits of synchronization training.
Factual Consistency Oriented Speech Recognition
Feb 24, 2023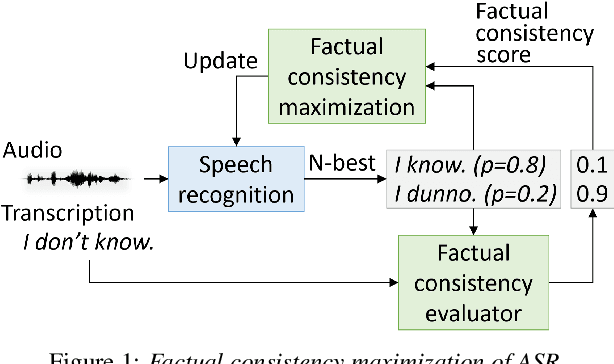
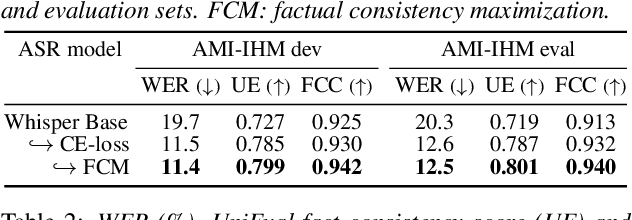
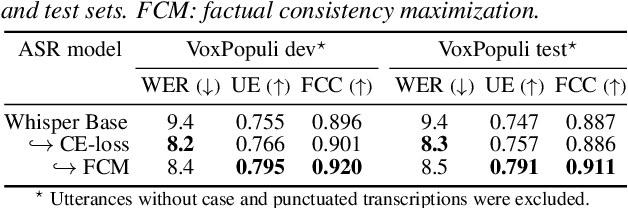

This paper presents a novel optimization framework for automatic speech recognition (ASR) with the aim of reducing hallucinations produced by an ASR model. The proposed framework optimizes the ASR model to maximize an expected factual consistency score between ASR hypotheses and ground-truth transcriptions, where the factual consistency score is computed by a separately trained estimator. Experimental results using the AMI meeting corpus and the VoxPopuli corpus show that the ASR model trained with the proposed framework generates ASR hypotheses that have significantly higher consistency scores with ground-truth transcriptions while maintaining the word error rates close to those of cross entropy-trained ASR models. Furthermore, it is shown that training the ASR models with the proposed framework improves the speech summarization quality as measured by the factual consistency of meeting conversation summaries generated by a large language model.
SpokenWOZ: A Large-Scale Speech-Text Benchmark for Spoken Task-Oriented Dialogue in Multiple Domains
May 22, 2023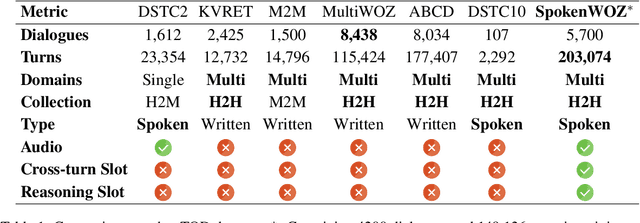

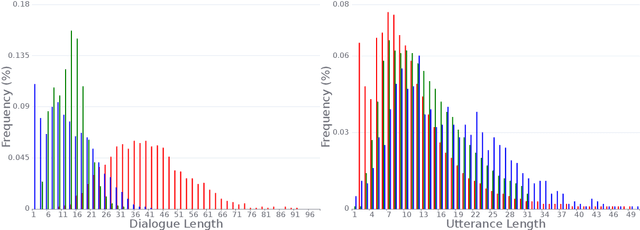
Task-oriented dialogue (TOD) models have great progress in the past few years. However, these studies primarily focus on datasets written by annotators, which has resulted in a gap between academic research and more realistic spoken conversation scenarios. While a few small-scale spoken TOD datasets are proposed to address robustness issues, e.g., ASR errors, they fail to identify the unique challenges in spoken conversation. To tackle the limitations, we introduce SpokenWOZ, a large-scale speech-text dataset for spoken TOD, which consists of 8 domains, 203k turns, 5.7k dialogues and 249 hours of audios from human-to-human spoken conversations. SpokenWOZ incorporates common spoken characteristics such as word-by-word processing and commonsense reasoning. We also present cross-turn slot and reasoning slot detection as new challenges based on the spoken linguistic phenomena. We conduct comprehensive experiments on various models, including text-modal baselines, newly proposed dual-modal baselines and LLMs. The results show the current models still has substantial areas for improvement in spoken conversation, including fine-tuned models and LLMs, i.e., ChatGPT.
Speech Corpora Divergence Based Unsupervised Data Selection for ASR
Feb 26, 2023
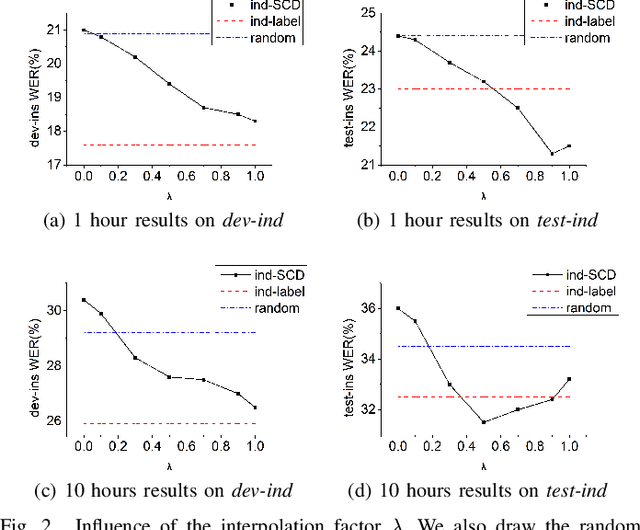
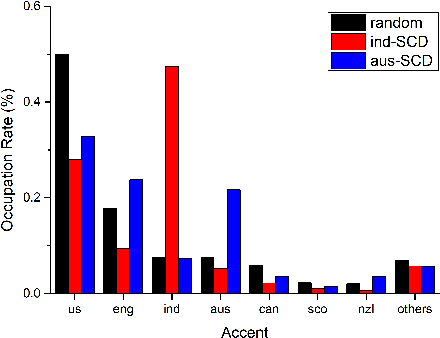
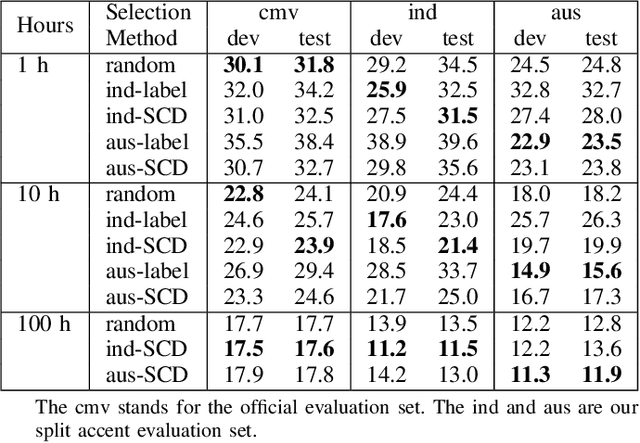
Selecting application scenarios matching data is important for the automatic speech recognition (ASR) training, but it is difficult to measure the matching degree of the training corpus. This study proposes a unsupervised target-aware data selection method based on speech corpora divergence (SCD), which can measure the similarity between two speech corpora. We first use the self-supervised Hubert model to discretize the speech corpora into label sequence and calculate the N-gram probability distribution. Then we calculate the Kullback-Leibler divergence between the N-grams as the SCD. Finally, we can choose the subset which has minimum SCD to the target corpus for annotation and training. Compared to previous data selection method, the SCD data selection method can focus on more acoustic details and guarantee the diversity of the selected set. We evaluate our method on different accents from Common Voice. Experiments show that the proposed SCD data selection can realize 14.8% relative improvements to the random selection, comparable or even superior to the result of supervised selection.
Improving Meeting Inclusiveness using Speech Interruption Analysis
Apr 02, 2023

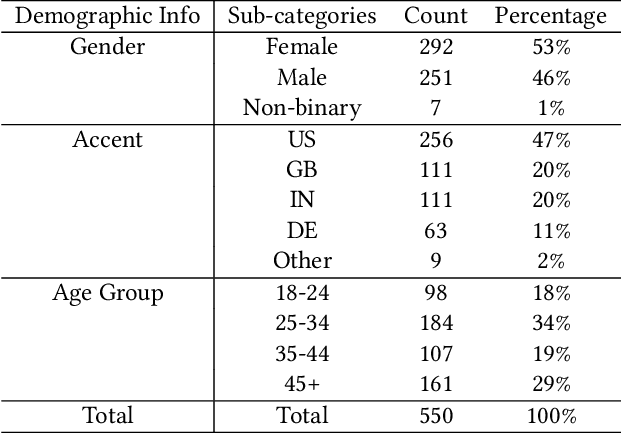
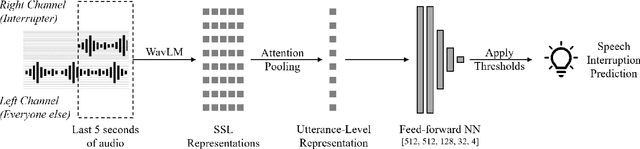
Meetings are a pervasive method of communication within all types of companies and organizations, and using remote collaboration systems to conduct meetings has increased dramatically since the COVID-19 pandemic. However, not all meetings are inclusive, especially in terms of the participation rates among attendees. In a recent large-scale survey conducted at Microsoft, the top suggestion given by meeting participants for improving inclusiveness is to improve the ability of remote participants to interrupt and acquire the floor during meetings. We show that the use of the virtual raise hand (VRH) feature can lead to an increase in predicted meeting inclusiveness at Microsoft. One challenge is that VRH is used in less than 1% of all meetings. In order to drive adoption of its usage to improve inclusiveness (and participation), we present a machine learning-based system that predicts when a meeting participant attempts to obtain the floor, but fails to interrupt (termed a `failed interruption'). This prediction can be used to nudge the user to raise their virtual hand within the meeting. We believe this is the first failed speech interruption detector, and the performance on a realistic test set has an area under curve (AUC) of 0.95 with a true positive rate (TPR) of 50% at a false positive rate (FPR) of <1%. To our knowledge, this is also the first dataset of interruption categories (including the failed interruption category) for remote meetings. Finally, we believe this is the first such system designed to improve meeting inclusiveness through speech interruption analysis and active intervention.
CrossSpeech: Speaker-independent Acoustic Representation for Cross-lingual Speech Synthesis
Feb 28, 2023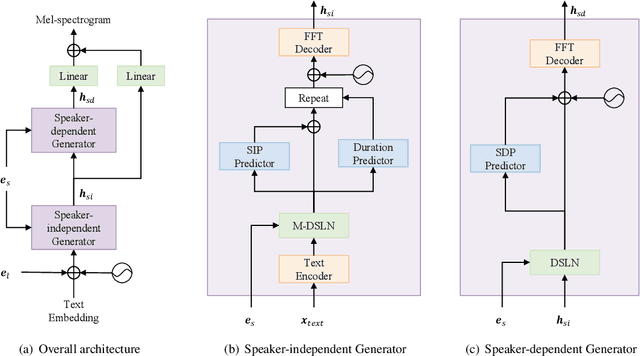
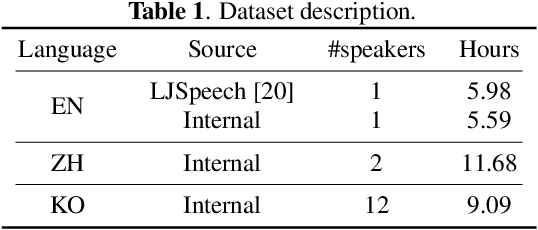
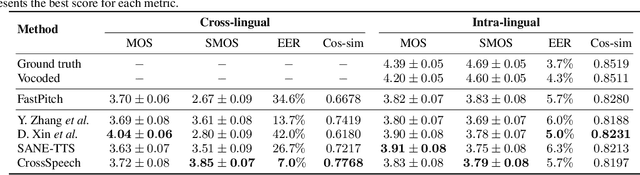
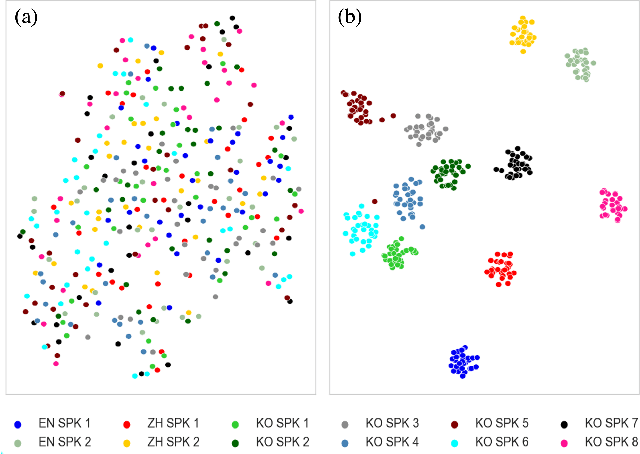
While recent text-to-speech (TTS) systems have made remarkable strides toward human-level quality, the performance of cross-lingual TTS lags behind that of intra-lingual TTS. This gap is mainly rooted from the speaker-language entanglement problem in cross-lingual TTS. In this paper, we propose CrossSpeech which improves the quality of cross-lingual speech by effectively disentangling speaker and language information in the level of acoustic feature space. Specifically, CrossSpeech decomposes the speech generation pipeline into the speaker-independent generator (SIG) and speaker-dependent generator (SDG). The SIG produces the speaker-independent acoustic representation which is not biased to specific speaker distributions. On the other hand, the SDG models speaker-dependent speech variation that characterizes speaker attributes. By handling each information separately, CrossSpeech can obtain disentangled speaker and language representations. From the experiments, we verify that CrossSpeech achieves significant improvements in cross-lingual TTS, especially in terms of speaker similarity to the target speaker.
Developmental Bootstrapping of AIs
Aug 08, 2023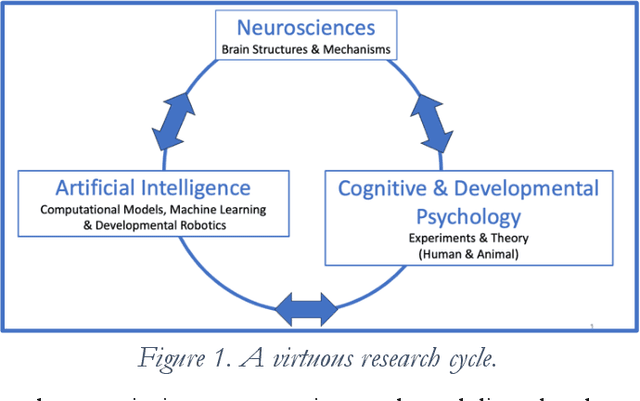

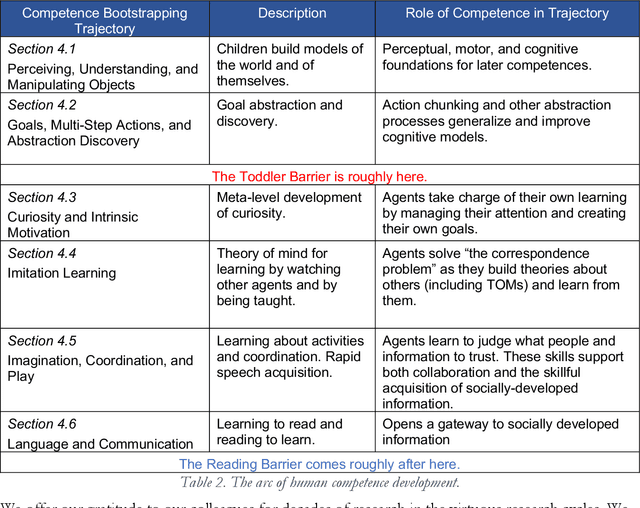
Although some current AIs surpass human abilities especially in closed worlds such as board games, their performance in the messy real world is limited. They make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. They do not make good collaborators. Neither systems built using the traditional manually-constructed symbolic AI approach nor systems built using generative and deep learning AI approaches including large language models (LLMs) can meet the challenges. They are not well suited for creating robust and trustworthy AIs. Although it is outside of mainstream AI approaches, developmental bootstrapping shows promise. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. Like humans, they interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. Following a bootstrapping process, they acquire the competences that they need. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped at the Toddler Barrier corresponding to human infant development at about two years of age, before speech is fluent. They also do not bridge the Reading Barrier, where they can skillfully and skeptically tap into the vast socially developed recorded information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to create robust and resilient AIs.