 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech Enhancement for Virtual Meetings on Cellular Networks
Feb 02, 2023
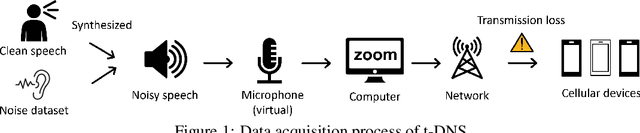
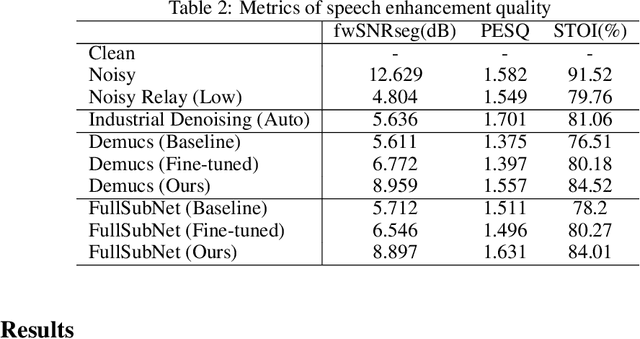
We study speech enhancement using deep learning (DL) for virtual meetings on cellular devices, where transmitted speech has background noise and transmission loss that affects speech quality. Since the Deep Noise Suppression (DNS) Challenge dataset does not contain practical disturbance, we collect a transmitted DNS (t-DNS) dataset using Zoom Meetings over T-Mobile network. We select two baseline models: Demucs and FullSubNet. The Demucs is an end-to-end model that takes time-domain inputs and outputs time-domain denoised speech, and the FullSubNet takes time-frequency-domain inputs and outputs the energy ratio of the target speech in the inputs. The goal of this project is to enhance the speech transmitted over the cellular networks using deep learning models.
Factors Affecting the Performance of Automated Speaker Verification in Alzheimer's Disease Clinical Trials
Jun 20, 2023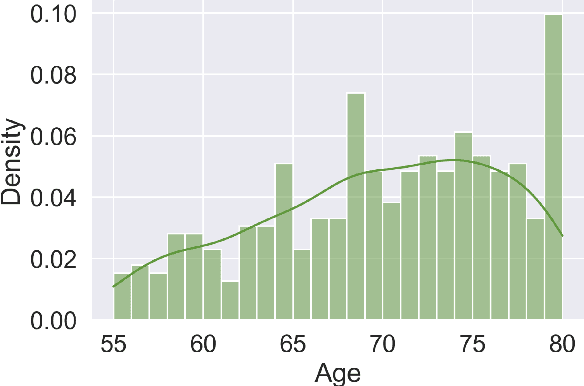

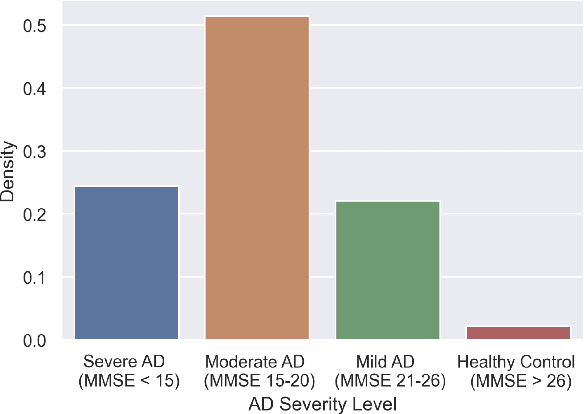

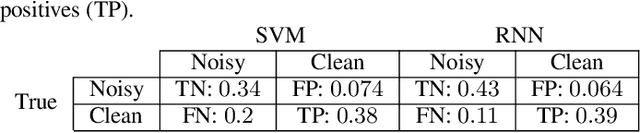
Detecting duplicate patient participation in clinical trials is a major challenge because repeated patients can undermine the credibility and accuracy of the trial's findings and result in significant health and financial risks. Developing accurate automated speaker verification (ASV) models is crucial to verify the identity of enrolled individuals and remove duplicates, but the size and quality of data influence ASV performance. However, there has been limited investigation into the factors that can affect ASV capabilities in clinical environments. In this paper, we bridge the gap by conducting analysis of how participant demographic characteristics, audio quality criteria, and severity level of Alzheimer's disease (AD) impact the performance of ASV utilizing a dataset of speech recordings from 659 participants with varying levels of AD, obtained through multiple speech tasks. Our results indicate that ASV performance: 1) is slightly better on male speakers than on female speakers; 2) degrades for individuals who are above 70 years old; 3) is comparatively better for non-native English speakers than for native English speakers; 4) is negatively affected by clinician interference, noisy background, and unclear participant speech; 5) tends to decrease with an increase in the severity level of AD. Our study finds that voice biometrics raise fairness concerns as certain subgroups exhibit different ASV performances owing to their inherent voice characteristics. Moreover, the performance of ASV is influenced by the quality of speech recordings, which underscores the importance of improving the data collection settings in clinical trials.
A processing framework to access large quantities of whispered speech found in ASMR
Mar 13, 2023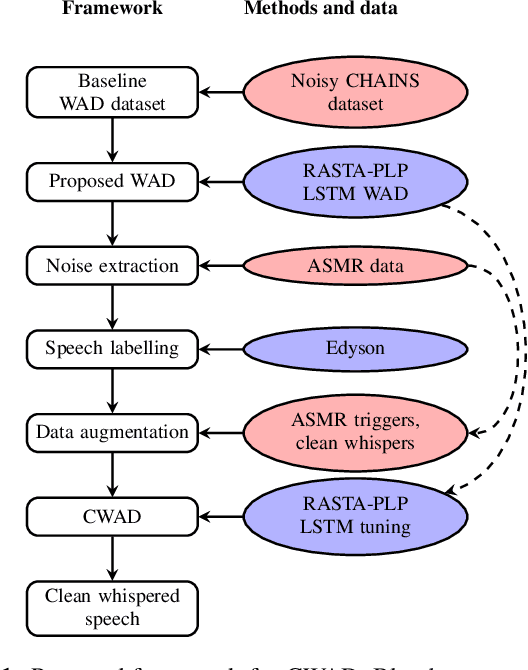
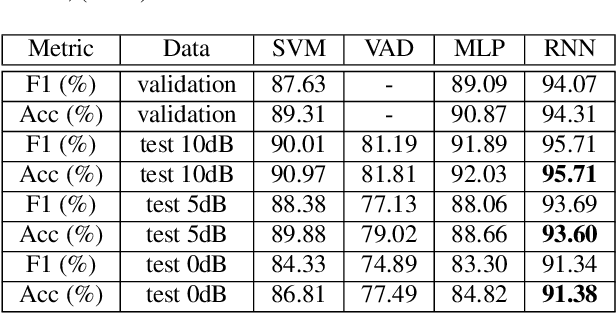
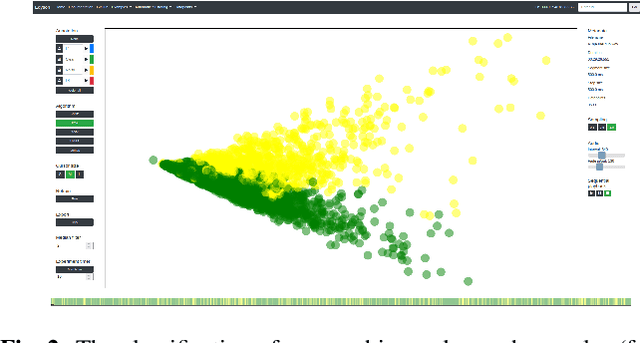
Whispering is a ubiquitous mode of communication that humans use daily. Despite this, whispered speech has been poorly served by existing speech technology due to a shortage of resources and processing methodology. To remedy this, this paper provides a processing framework that enables access to large and unique data of high-quality whispered speech. We obtain the data from recordings submitted to online platforms as part of the ASMR media-cultural phenomenon. We describe our processing pipeline and a method for improved whispered activity detection (WAD) in the ASMR data. To efficiently obtain labelled, clean whispered speech, we complement the automatic WAD by using Edyson, a bulk audio-annotation tool with human-in-the-loop. We also tackle a problem particular to ASMR: separation of whisper from other acoustic triggers present in the genre. We show that the proposed WAD and the efficient labelling allows to build extensively augmented data and train a classifier that extracts clean whisper segments from ASMR audio. Our large and growing dataset enables whisper-capable, data-driven speech technology and linguistic analysis. It also opens opportunities in e.g. HCI as a resource that may elicit emotional, psychological and neuro-physiological responses in the listener.
Multi-Dimensional and Multi-Scale Modeling for Speech Separation Optimized by Discriminative Learning
Mar 07, 2023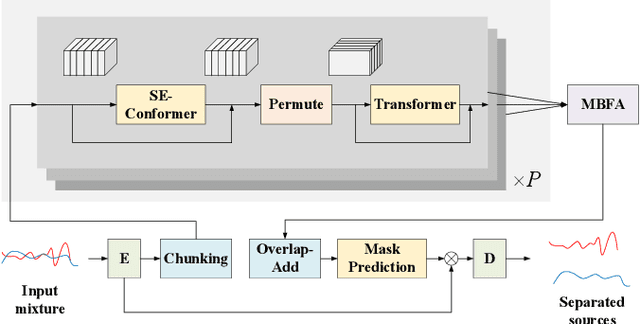
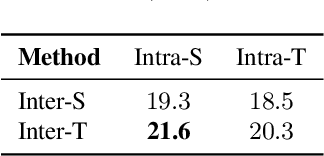

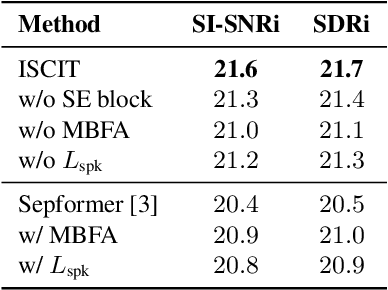
Transformer has shown advanced performance in speech separation, benefiting from its ability to capture global features. However, capturing local features and channel information of audio sequences in speech separation is equally important. In this paper, we present a novel approach named Intra-SE-Conformer and Inter-Transformer (ISCIT) for speech separation. Specifically, we design a new network SE-Conformer that can model audio sequences in multiple dimensions and scales, and apply it to the dual-path speech separation framework. Furthermore, we propose Multi-Block Feature Aggregation to improve the separation effect by selectively utilizing information from the intermediate blocks of the separation network. Meanwhile, we propose a speaker similarity discriminative loss to optimize the speech separation model to address the problem of poor performance when speakers have similar voices. Experimental results on the benchmark datasets WSJ0-2mix and WHAM! show that ISCIT can achieve state-of-the-art results.
VoxWatch: An open-set speaker recognition benchmark on VoxCeleb
Jun 30, 2023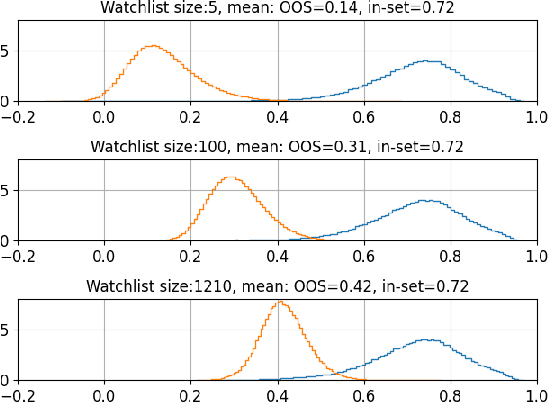
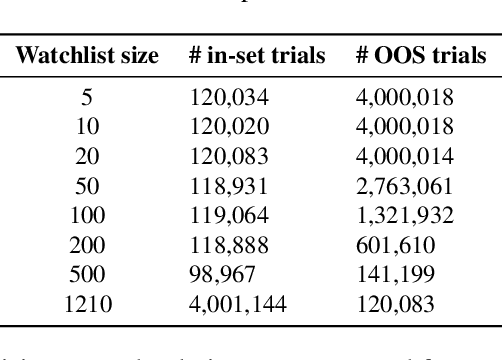
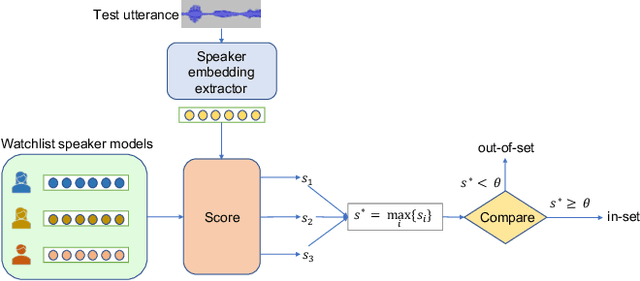
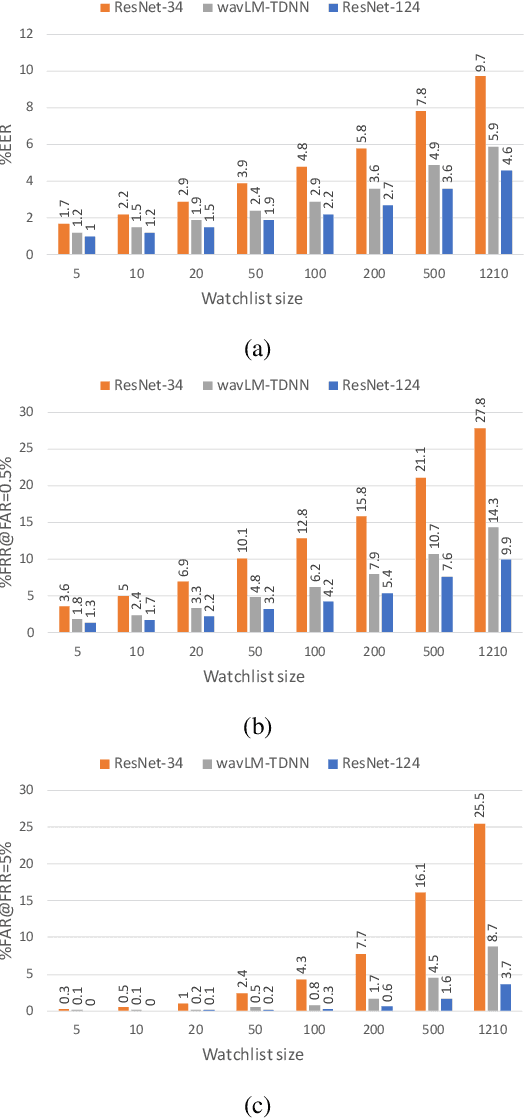
Despite its broad practical applications such as in fraud prevention, open-set speaker identification (OSI) has received less attention in the speaker recognition community compared to speaker verification (SV). OSI deals with determining if a test speech sample belongs to a speaker from a set of pre-enrolled individuals (in-set) or if it is from an out-of-set speaker. In addition to the typical challenges associated with speech variability, OSI is prone to the "false-alarm problem"; as the size of the in-set speaker population (a.k.a watchlist) grows, the out-of-set scores become larger, leading to increased false alarm rates. This is in particular challenging for applications in financial institutions and border security where the watchlist size is typically of the order of several thousand speakers. Therefore, it is important to systematically quantify the false-alarm problem, and develop techniques that alleviate the impact of watchlist size on detection performance. Prior studies on this problem are sparse, and lack a common benchmark for systematic evaluations. In this paper, we present the first public benchmark for OSI, developed using the VoxCeleb dataset. We quantify the effect of the watchlist size and speech duration on the watchlist-based speaker detection task using three strong neural network based systems. In contrast to the findings from prior research, we show that the commonly adopted adaptive score normalization is not guaranteed to improve the performance for this task. On the other hand, we show that score calibration and score fusion, two other commonly used techniques in SV, result in significant improvements in OSI performance.
Automatic Identification of Alzheimer's Disease using Lexical Features extracted from Language Samples
Jul 16, 2023
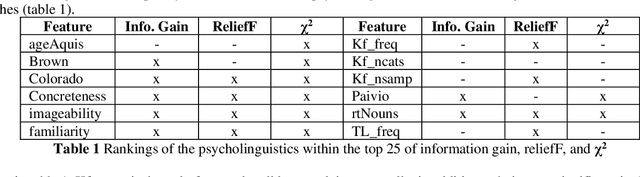
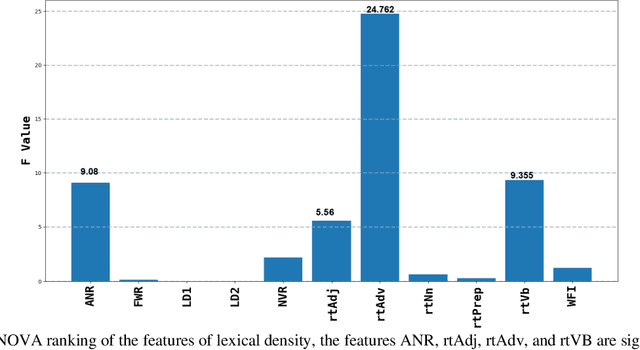
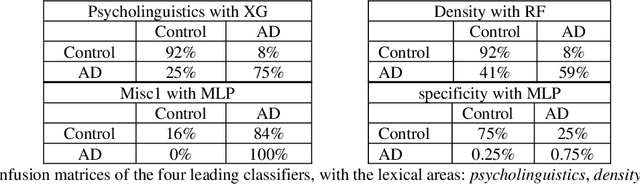
Objective: this study has a twofold goal. First, it aims to improve the understanding of the impact of Dementia of type Alzheimer's Disease (AD) on different aspects of the lexicon. Second, it aims to demonstrate that such aspects of the lexicon, when used as features of a machine learning classifier, can help achieve state-of-the-art performance in automatically identifying language samples produced by patients with AD. Methods: data is derived from the ADDreSS challenge, which is a part of the DementiaBank corpus. The used dataset consists of transcripts of Cookie Theft picture descriptions, produced by 54 subjects in the training part and 24 subjects in the test part. The number of narrative samples is 108 in the training set and 48 in the test set. First, the impact of AD on 99 selected lexical features is studied using both the training and testing parts of the dataset. Then some machine learning experiments were conducted on the task of classifying transcribed speech samples with text samples that were produced by people with AD from those produced by normal subjects. Several experiments were conducted to compare the different areas of lexical complexity, identify the subset of features that help achieve optimal performance, and study the impact of the size of the input on the classification. To evaluate the generalization of the models built on narrative speech, two generalization tests were conducted using written data from two British authors, Iris Murdoch and Agatha Christie, and the transcription of some speeches by former President Ronald Reagan. Results: using lexical features only, state-of-the-art classification, F1 and accuracies, of over 91% were achieved in categorizing language samples produced by individuals with AD from the ones produced by healthy control subjects. This confirms the substantial impact of AD on lexicon processing.
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Feb 27, 2023

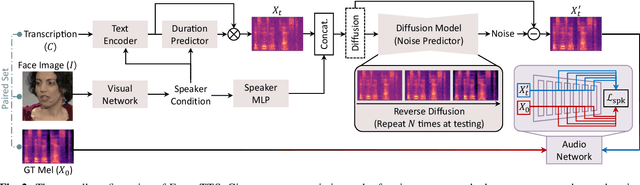
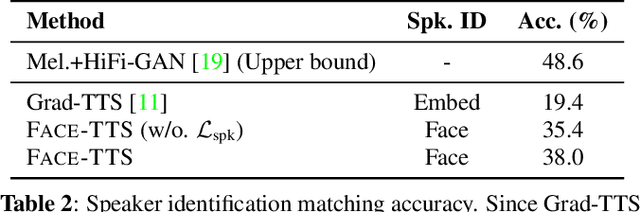
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.
A Holistic Cascade System, benchmark, and Human Evaluation Protocol for Expressive Speech-to-Speech Translation
Jan 25, 2023
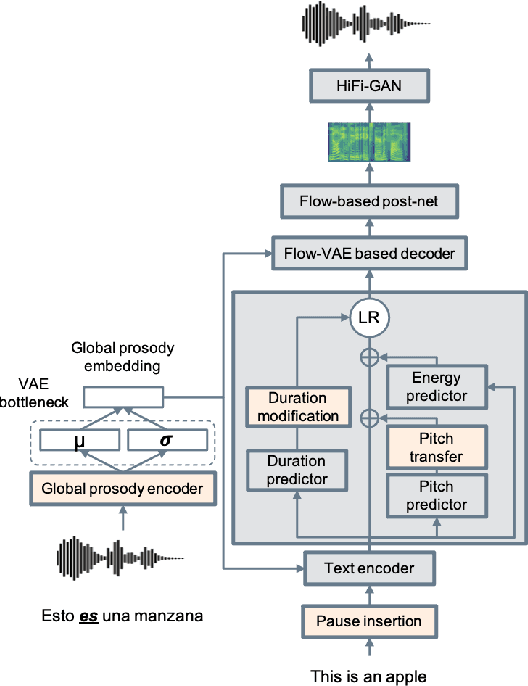

Expressive speech-to-speech translation (S2ST) aims to transfer prosodic attributes of source speech to target speech while maintaining translation accuracy. Existing research in expressive S2ST is limited, typically focusing on a single expressivity aspect at a time. Likewise, this research area lacks standard evaluation protocols and well-curated benchmark datasets. In this work, we propose a holistic cascade system for expressive S2ST, combining multiple prosody transfer techniques previously considered only in isolation. We curate a benchmark expressivity test set in the TV series domain and explored a second dataset in the audiobook domain. Finally, we present a human evaluation protocol to assess multiple expressive dimensions across speech pairs. Experimental results indicate that bi-lingual annotators can assess the quality of expressive preservation in S2ST systems, and the holistic modeling approach outperforms single-aspect systems. Audio samples can be accessed through our demo webpage: https://facebookresearch.github.io/speech_translation/cascade_expressive_s2st.
Improving Meeting Inclusiveness using Speech Interruption Analysis
Apr 02, 2023

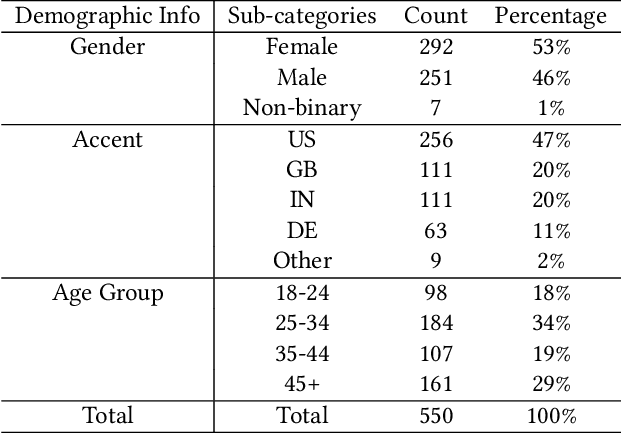
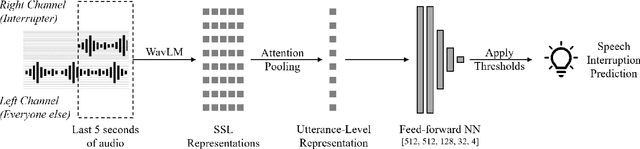
Meetings are a pervasive method of communication within all types of companies and organizations, and using remote collaboration systems to conduct meetings has increased dramatically since the COVID-19 pandemic. However, not all meetings are inclusive, especially in terms of the participation rates among attendees. In a recent large-scale survey conducted at Microsoft, the top suggestion given by meeting participants for improving inclusiveness is to improve the ability of remote participants to interrupt and acquire the floor during meetings. We show that the use of the virtual raise hand (VRH) feature can lead to an increase in predicted meeting inclusiveness at Microsoft. One challenge is that VRH is used in less than 1% of all meetings. In order to drive adoption of its usage to improve inclusiveness (and participation), we present a machine learning-based system that predicts when a meeting participant attempts to obtain the floor, but fails to interrupt (termed a `failed interruption'). This prediction can be used to nudge the user to raise their virtual hand within the meeting. We believe this is the first failed speech interruption detector, and the performance on a realistic test set has an area under curve (AUC) of 0.95 with a true positive rate (TPR) of 50% at a false positive rate (FPR) of <1%. To our knowledge, this is also the first dataset of interruption categories (including the failed interruption category) for remote meetings. Finally, we believe this is the first such system designed to improve meeting inclusiveness through speech interruption analysis and active intervention.
Transcribing Educational Videos Using Whisper: A preliminary study on using AI for transcribing educational videos
Jul 04, 2023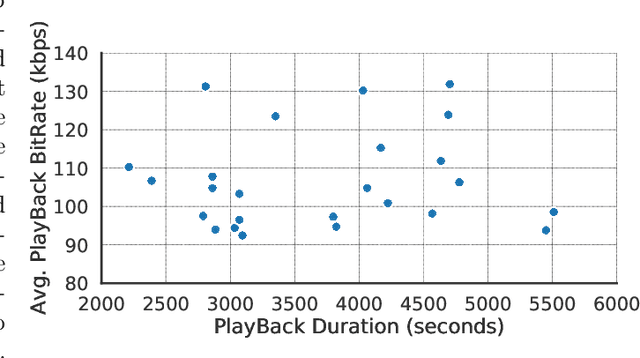

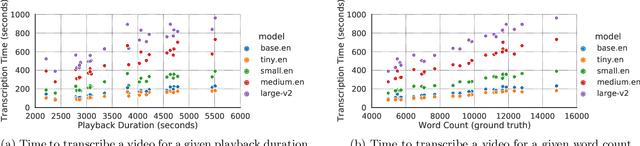
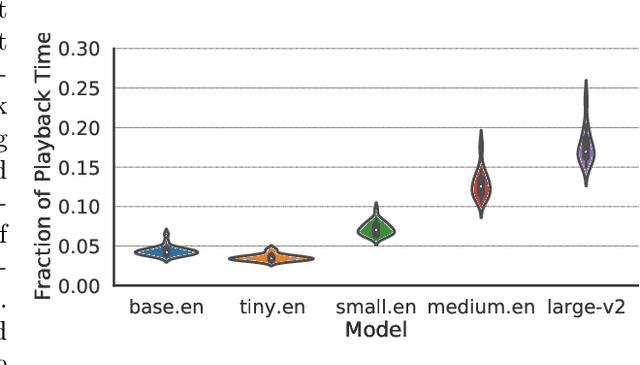
Videos are increasingly being used for e-learning, and transcripts are vital to enhance the learning experience. The costs and delays of generating transcripts can be alleviated by automatic speech recognition (ASR) systems. In this article, we quantify the transcripts generated by whisper for 25 educational videos and identify some open avenues of research when leveraging ASR for transcribing educational videos.