 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Two-Stage Voice Anonymization for Enhanced Privacy
Jun 28, 2023
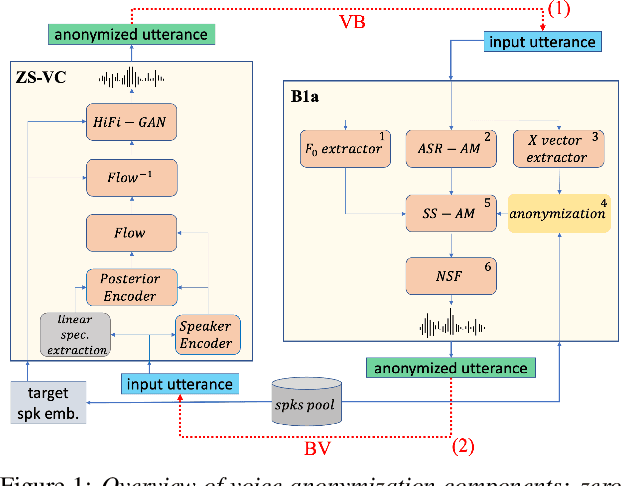
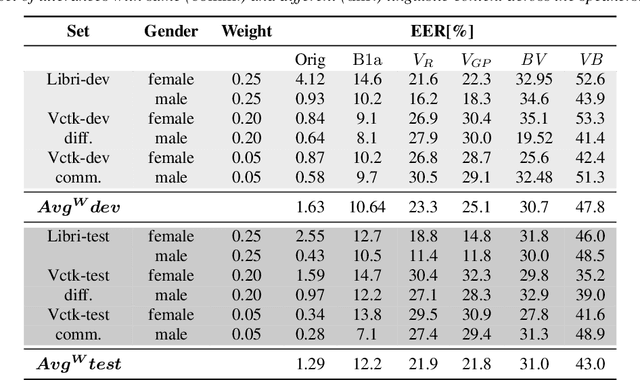
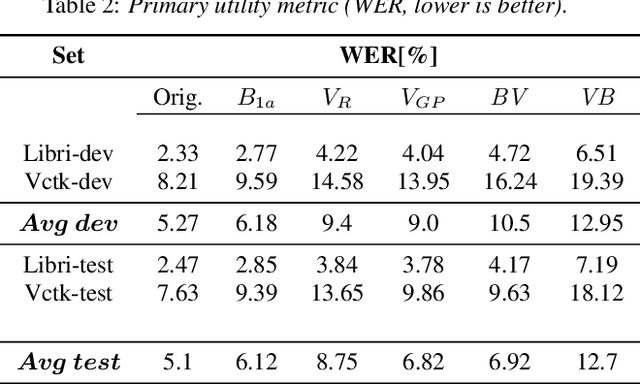
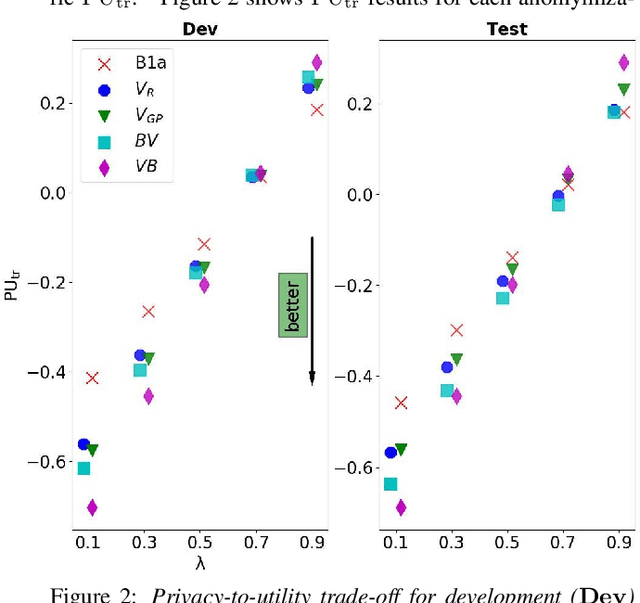
In recent years, the need for privacy preservation when manipulating or storing personal data, including speech , has become a major issue. In this paper, we present a system addressing the speaker-level anonymization problem. We propose and evaluate a two-stage anonymization pipeline exploiting a state-of-the-art anonymization model described in the Voice Privacy Challenge 2022 in combination with a zero-shot voice conversion architecture able to capture speaker characteristics from a few seconds of speech. We show this architecture can lead to strong privacy preservation while preserving pitch information. Finally, we propose a new compressed metric to evaluate anonymization systems in privacy scenarios with different constraints on privacy and utility.
TAPLoss: A Temporal Acoustic Parameter Loss for Speech Enhancement
Feb 16, 2023
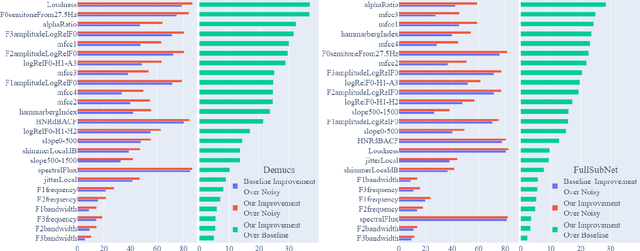

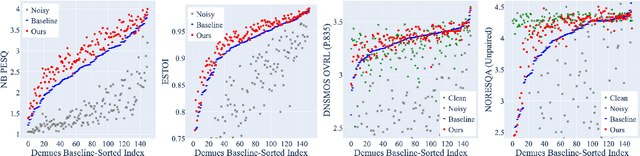
Speech enhancement models have greatly progressed in recent years, but still show limits in perceptual quality of their speech outputs. We propose an objective for perceptual quality based on temporal acoustic parameters. These are fundamental speech features that play an essential role in various applications, including speaker recognition and paralinguistic analysis. We provide a differentiable estimator for four categories of low-level acoustic descriptors involving: frequency-related parameters, energy or amplitude-related parameters, spectral balance parameters, and temporal features. Unlike prior work that looks at aggregated acoustic parameters or a few categories of acoustic parameters, our temporal acoustic parameter (TAP) loss enables auxiliary optimization and improvement of many fine-grain speech characteristics in enhancement workflows. We show that adding TAPLoss as an auxiliary objective in speech enhancement produces speech with improved perceptual quality and intelligibility. We use data from the Deep Noise Suppression 2020 Challenge to demonstrate that both time-domain models and time-frequency domain models can benefit from our method.
Developmental Bootstrapping of AIs
Aug 08, 2023

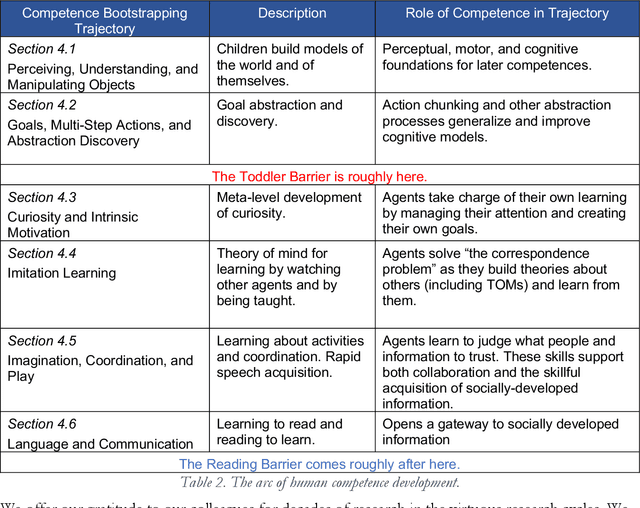
Although some current AIs surpass human abilities especially in closed worlds such as board games, their performance in the messy real world is limited. They make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. They do not make good collaborators. Neither systems built using the traditional manually-constructed symbolic AI approach nor systems built using generative and deep learning AI approaches including large language models (LLMs) can meet the challenges. They are not well suited for creating robust and trustworthy AIs. Although it is outside of mainstream AI approaches, developmental bootstrapping shows promise. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. Like humans, they interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. Following a bootstrapping process, they acquire the competences that they need. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped at the Toddler Barrier corresponding to human infant development at about two years of age, before speech is fluent. They also do not bridge the Reading Barrier, where they can skillfully and skeptically tap into the vast socially developed recorded information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to create robust and resilient AIs.
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023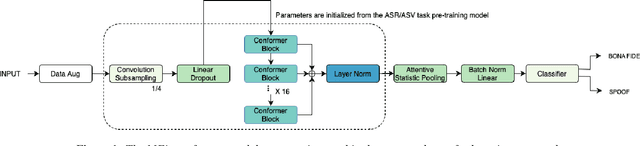
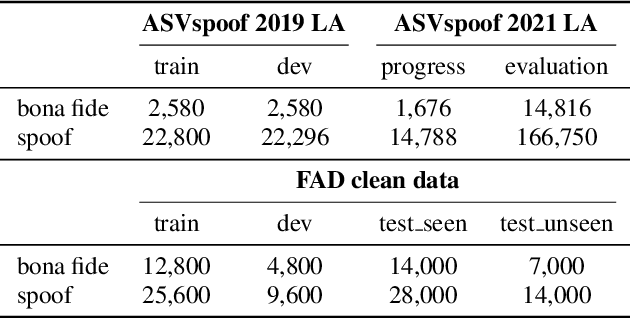
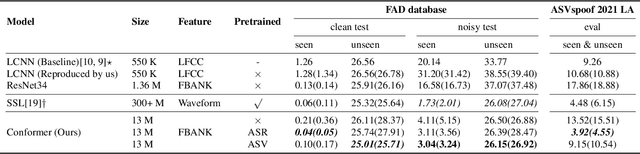
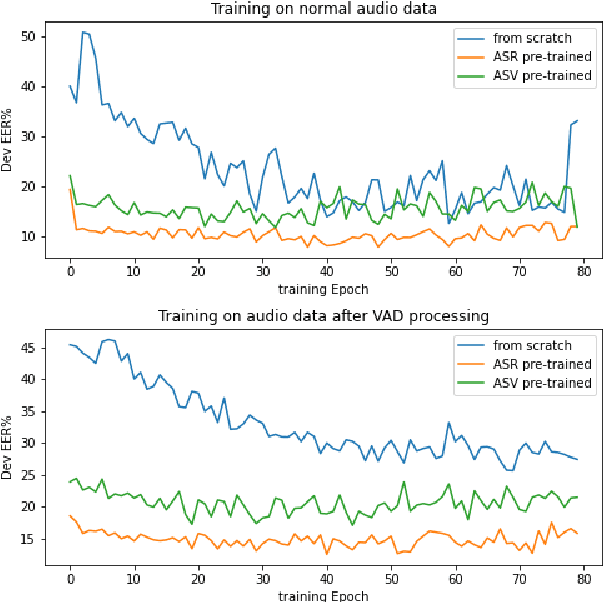
This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.
Exploration of Language Dependency for Japanese Self-Supervised Speech Representation Models
May 09, 2023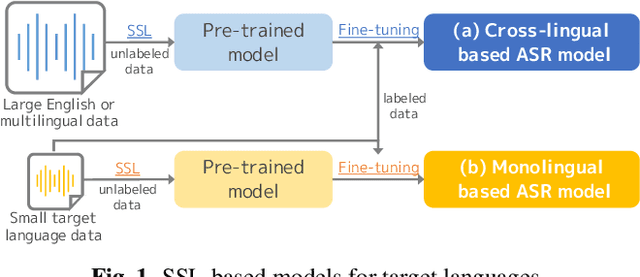
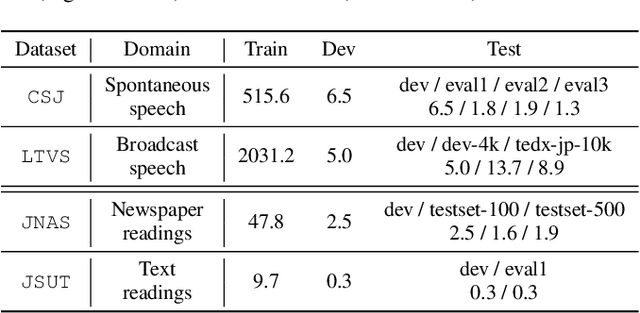
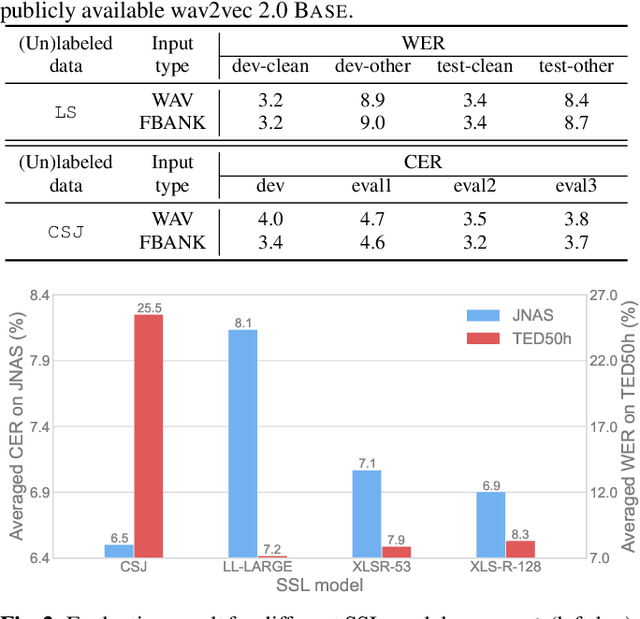
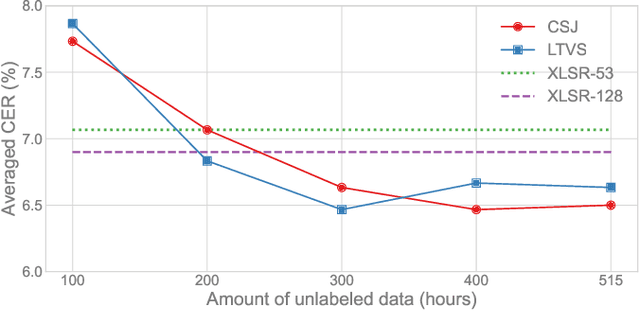
Self-supervised learning (SSL) has been dramatically successful not only in monolingual but also in cross-lingual settings. However, since the two settings have been studied individually in general, there has been little research focusing on how effective a cross-lingual model is in comparison with a monolingual model. In this paper, we investigate this fundamental question empirically with Japanese automatic speech recognition (ASR) tasks. First, we begin by comparing the ASR performance of cross-lingual and monolingual models for two different language tasks while keeping the acoustic domain as identical as possible. Then, we examine how much unlabeled data collected in Japanese is needed to achieve performance comparable to a cross-lingual model pre-trained with tens of thousands of hours of English and/or multilingual data. Finally, we extensively investigate the effectiveness of SSL in Japanese and demonstrate state-of-the-art performance on multiple ASR tasks. Since there is no comprehensive SSL study for Japanese, we hope this study will guide Japanese SSL research.
SpeechLMScore: Evaluating speech generation using speech language model
Dec 08, 2022
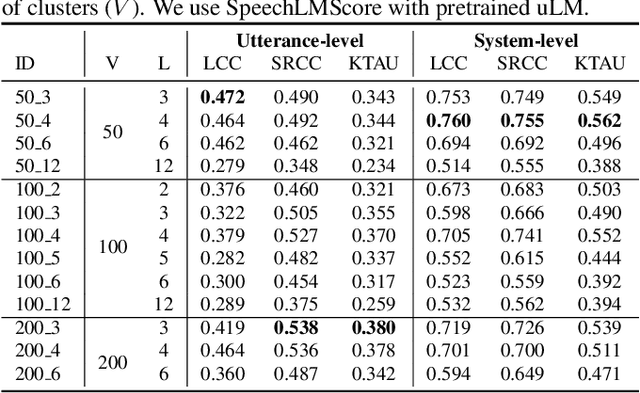
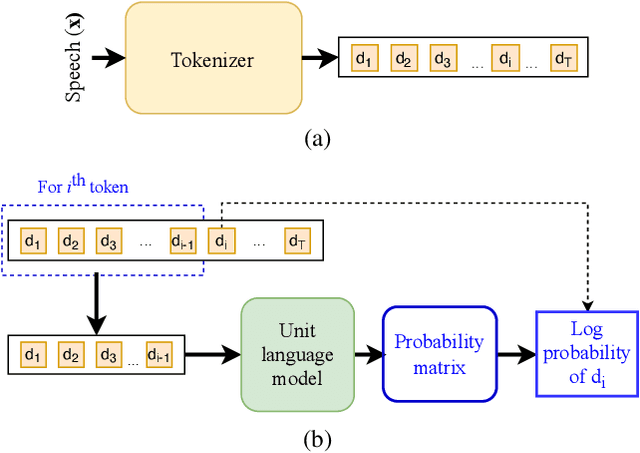
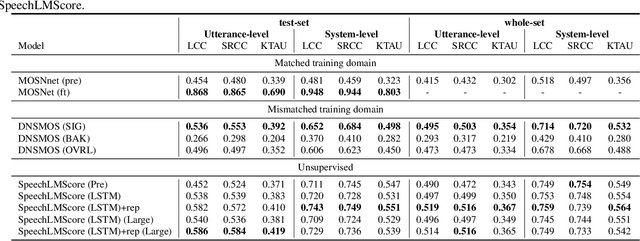
While human evaluation is the most reliable metric for evaluating speech generation systems, it is generally costly and time-consuming. Previous studies on automatic speech quality assessment address the problem by predicting human evaluation scores with machine learning models. However, they rely on supervised learning and thus suffer from high annotation costs and domain-shift problems. We propose SpeechLMScore, an unsupervised metric to evaluate generated speech using a speech-language model. SpeechLMScore computes the average log-probability of a speech signal by mapping it into discrete tokens and measures the average probability of generating the sequence of tokens. Therefore, it does not require human annotation and is a highly scalable framework. Evaluation results demonstrate that the proposed metric shows a promising correlation with human evaluation scores on different speech generation tasks including voice conversion, text-to-speech, and speech enhancement.
DSARSR: Deep Stacked Auto-encoders Enhanced Robust Speaker Recognition
Jul 06, 2023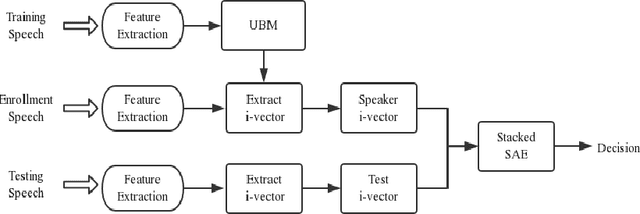

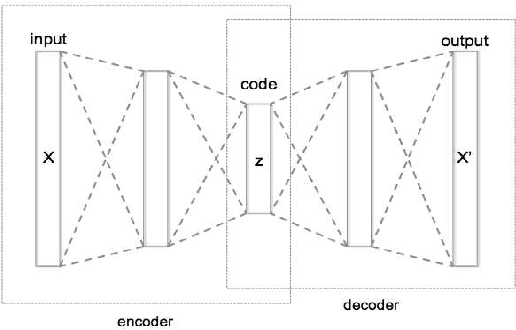
Speaker recognition is a biometric modality that utilizes the speaker's speech segments to recognize the identity, determining whether the test speaker belongs to one of the enrolled speakers. In order to improve the robustness of the i-vector framework on cross-channel conditions and explore the nova method for applying deep learning to speaker recognition, the Stacked Auto-encoders are used to get the abstract extraction of the i-vector instead of applying PLDA. After pre-processing and feature extraction, the speaker and channel-independent speeches are employed for UBM training. The UBM is then used to extract the i-vector of the enrollment and test speech. Unlike the traditional i-vector framework, which uses linear discriminant analysis (LDA) to reduce dimension and increase the discrimination between speaker subspaces, this research use stacked auto-encoders to reconstruct the i-vector with lower dimension and different classifiers can be chosen to achieve final classification. The experimental results show that the proposed method achieves better performance than the state-of-the-art method.
Speech Signal Improvement Using Causal Generative Diffusion Models
Mar 15, 2023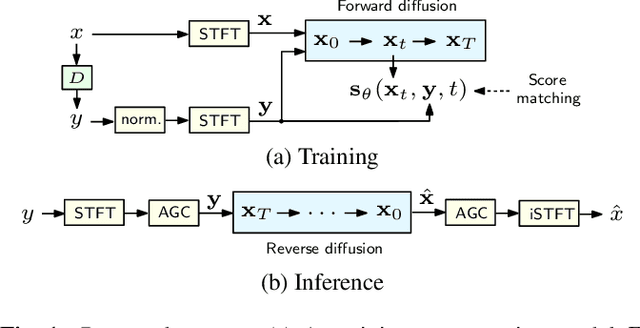

In this paper, we present a causal speech signal improvement system that is designed to handle different types of distortions. The method is based on a generative diffusion model which has been shown to work well in scenarios with missing data and non-linear corruptions. To guarantee causal processing, we modify the network architecture of our previous work and replace global normalization with causal adaptive gain control. We generate diverse training data containing a broad range of distortions. This work was performed in the context of an "ICASSP Signal Processing Grand Challenge" and submitted to the non-real-time track of the "Speech Signal Improvement Challenge 2023", where it was ranked fifth.
A Time-Frequency Generative Adversarial based method for Audio Packet Loss Concealment
Jul 28, 2023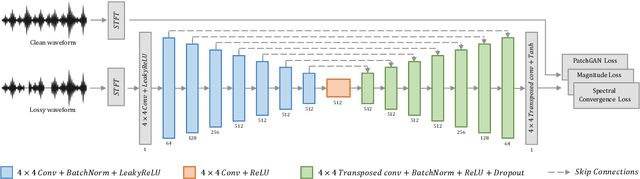
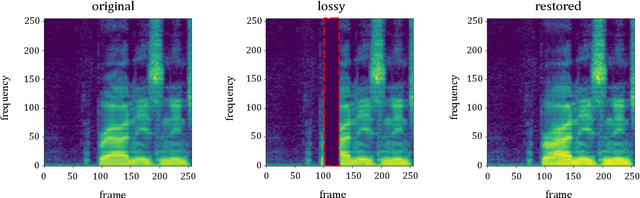
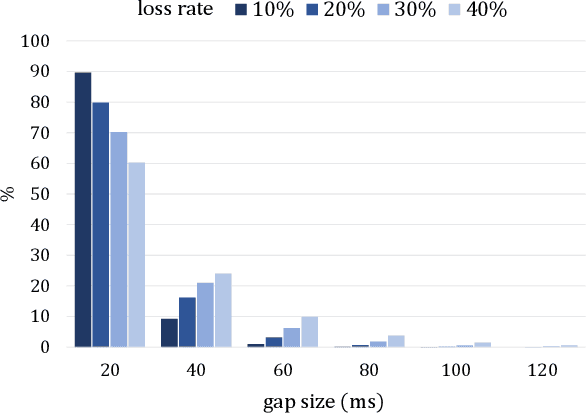
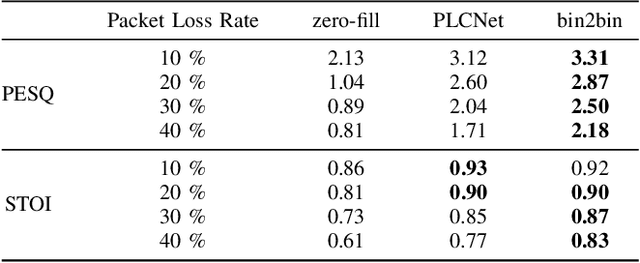
Packet loss is a major cause of voice quality degradation in VoIP transmissions with serious impact on intelligibility and user experience. This paper describes a system based on a generative adversarial approach, which aims to repair the lost fragments during the transmission of audio streams. Inspired by the powerful image-to-image translation capability of Generative Adversarial Networks (GANs), we propose bin2bin, an improved pix2pix framework to achieve the translation task from magnitude spectrograms of audio frames with lost packets, to noncorrupted speech spectrograms. In order to better maintain the structural information after spectrogram translation, this paper introduces the combination of two STFT-based loss functions, mixed with the traditional GAN objective. Furthermore, we employ a modified PatchGAN structure as discriminator and we lower the concealment time by a proper initialization of the phase reconstruction algorithm. Experimental results show that the proposed method has obvious advantages when compared with the current state-of-the-art methods, as it can better handle both high packet loss rates and large gaps.
Signal Reconstruction from Mel-spectrogram Based on Bi-level Consistency of Full-band Magnitude and Phase
Jul 23, 2023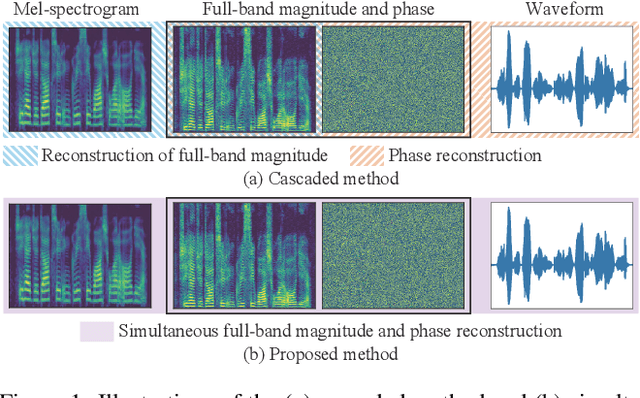
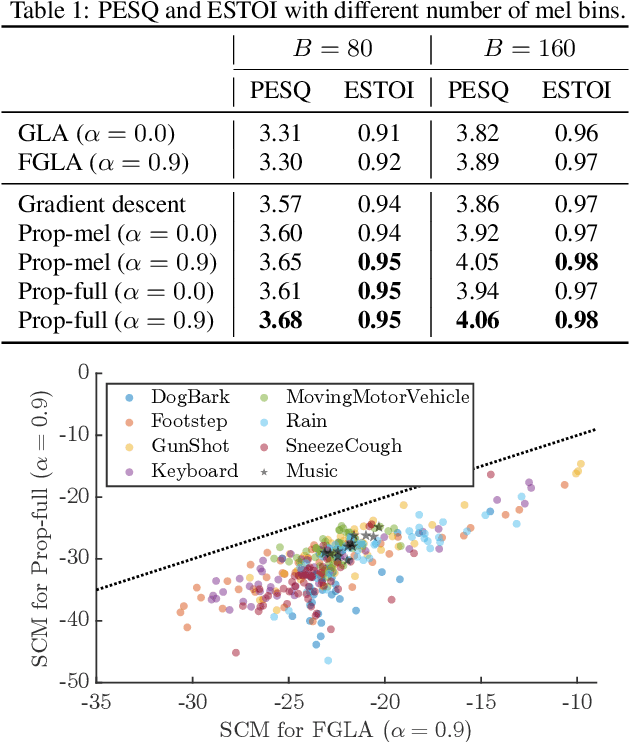
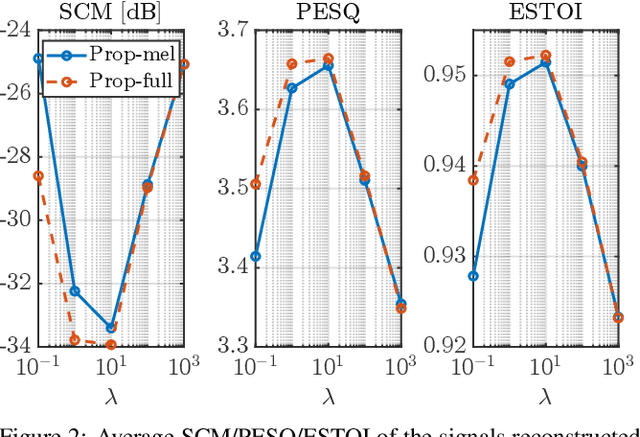
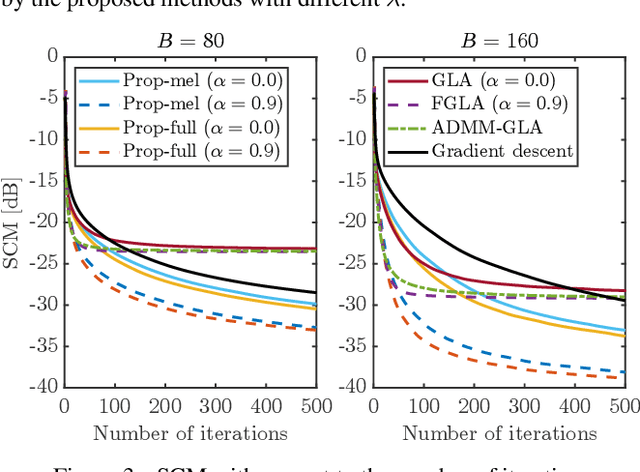
We propose an optimization-based method for reconstructing a time-domain signal from a low-dimensional spectral representation such as a mel-spectrogram. Phase reconstruction has been studied to reconstruct a time-domain signal from the full-band short-time Fourier transform (STFT) magnitude. The Griffin-Lim algorithm (GLA) has been widely used because it relies only on the redundancy of STFT and is applicable to various audio signals. In this paper, we jointly reconstruct the full-band magnitude and phase by considering the bi-level relationships among the time-domain signal, its STFT coefficients, and its mel-spectrogram. The proposed method is formulated as a rigorous optimization problem and estimates the full-band magnitude based on the criterion used in GLA. Our experiments demonstrate the effectiveness of the proposed method on speech, music, and environmental signals.