 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Decoding Continuous Character-based Language from Non-invasive Brain Recordings
Mar 19, 2024
Deciphering natural language from brain activity through non-invasive devices remains a formidable challenge. Previous non-invasive decoders either require multiple experiments with identical stimuli to pinpoint cortical regions and enhance signal-to-noise ratios in brain activity, or they are limited to discerning basic linguistic elements such as letters and words. We propose a novel approach to decoding continuous language from single-trial non-invasive fMRI recordings, in which a three-dimensional convolutional network augmented with information bottleneck is developed to automatically identify responsive voxels to stimuli, and a character-based decoder is designed for the semantic reconstruction of continuous language characterized by inherent character structures. The resulting decoder can produce intelligible textual sequences that faithfully capture the meaning of perceived speech both within and across subjects, while existing decoders exhibit significantly inferior performance in cross-subject contexts. The ability to decode continuous language from single trials across subjects demonstrates the promising applications of non-invasive language brain-computer interfaces in both healthcare and neuroscience.
EMO-SUPERB: An In-depth Look at Speech Emotion Recognition
Feb 22, 2024Speech emotion recognition (SER) is a pivotal technology for human-computer interaction systems. However, 80.77% of SER papers yield results that cannot be reproduced. We develop EMO-SUPERB, short for EMOtion Speech Universal PERformance Benchmark, which aims to enhance open-source initiatives for SER. EMO-SUPERB includes a user-friendly codebase to leverage 15 state-of-the-art speech self-supervised learning models (SSLMs) for exhaustive evaluation across six open-source SER datasets. EMO-SUPERB streamlines result sharing via an online leaderboard, fostering collaboration within a community-driven benchmark and thereby enhancing the development of SER. On average, 2.58% of annotations are annotated using natural language. SER relies on classification models and is unable to process natural languages, leading to the discarding of these valuable annotations. We prompt ChatGPT to mimic annotators, comprehend natural language annotations, and subsequently re-label the data. By utilizing labels generated by ChatGPT, we consistently achieve an average relative gain of 3.08% across all settings.
Speech Translation with Speech Foundation Models and Large Language Models: What is There and What is Missing?
Feb 19, 2024The field of natural language processing (NLP) has recently witnessed a transformative shift with the emergence of foundation models, particularly Large Language Models (LLMs) that have revolutionized text-based NLP. This paradigm has extended to other modalities, including speech, where researchers are actively exploring the combination of Speech Foundation Models (SFMs) and LLMs into single, unified models capable of addressing multimodal tasks. Among such tasks, this paper focuses on speech-to-text translation (ST). By examining the published papers on the topic, we propose a unified view of the architectural solutions and training strategies presented so far, highlighting similarities and differences among them. Based on this examination, we not only organize the lessons learned but also show how diverse settings and evaluation approaches hinder the identification of the best-performing solution for each architectural building block and training choice. Lastly, we outline recommendations for future works on the topic aimed at better understanding the strengths and weaknesses of the SFM+LLM solutions for ST.
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
Mar 18, 2024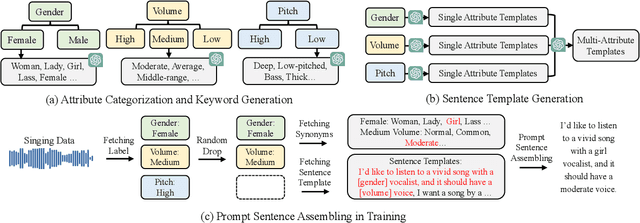
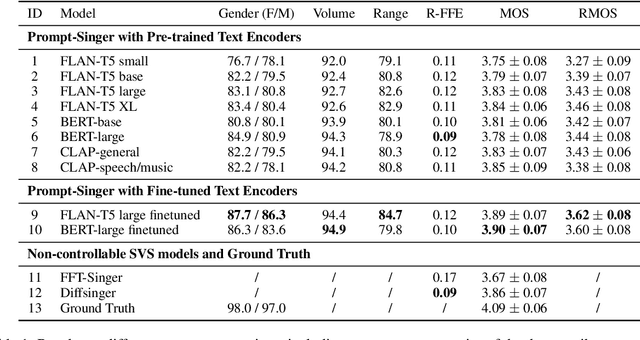
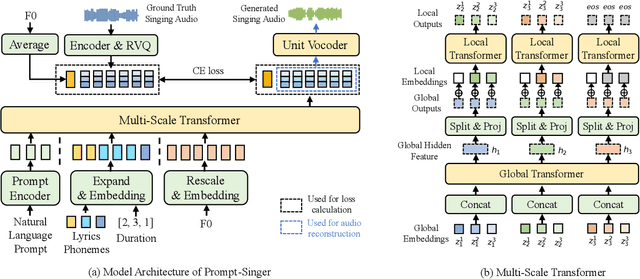
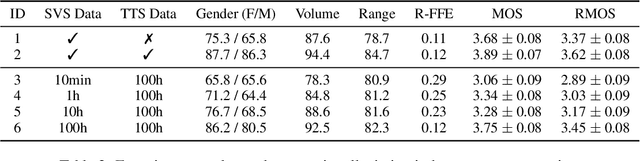
Recent singing-voice-synthesis (SVS) methods have achieved remarkable audio quality and naturalness, yet they lack the capability to control the style attributes of the synthesized singing explicitly. We propose Prompt-Singer, the first SVS method that enables attribute controlling on singer gender, vocal range and volume with natural language. We adopt a model architecture based on a decoder-only transformer with a multi-scale hierarchy, and design a range-melody decoupled pitch representation that enables text-conditioned vocal range control while keeping melodic accuracy. Furthermore, we explore various experiment settings, including different types of text representations, text encoder fine-tuning, and introducing speech data to alleviate data scarcity, aiming to facilitate further research. Experiments show that our model achieves favorable controlling ability and audio quality. Audio samples are available at http://prompt-singer.github.io .
Exploring Green AI for Audio Deepfake Detection
Mar 21, 2024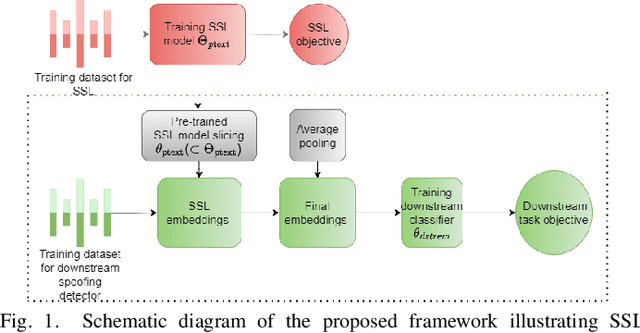
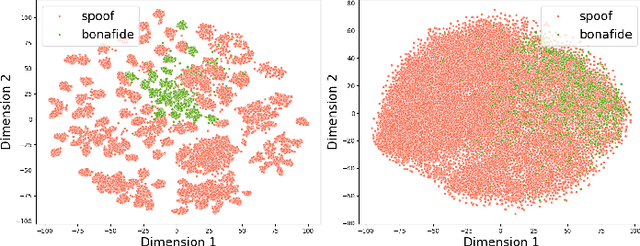
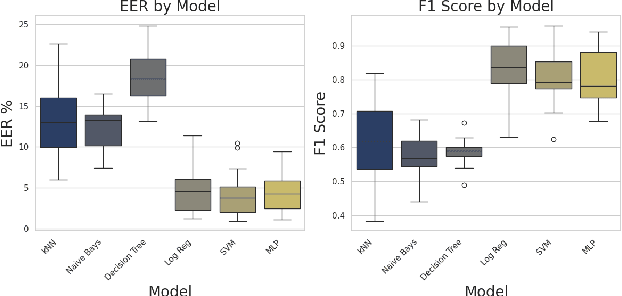
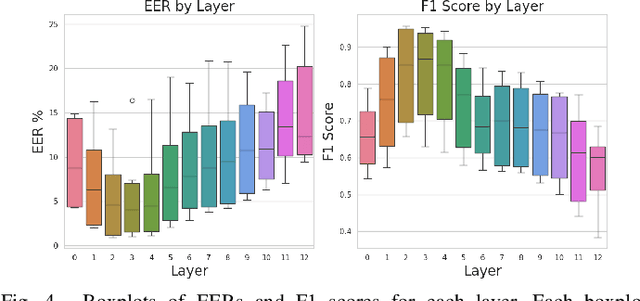
The state-of-the-art audio deepfake detectors leveraging deep neural networks exhibit impressive recognition performance. Nonetheless, this advantage is accompanied by a significant carbon footprint. This is mainly due to the use of high-performance computing with accelerators and high training time. Studies show that average deep NLP model produces around 626k lbs of CO\textsubscript{2} which is equivalent to five times of average US car emission at its lifetime. This is certainly a massive threat to the environment. To tackle this challenge, this study presents a novel framework for audio deepfake detection that can be seamlessly trained using standard CPU resources. Our proposed framework utilizes off-the-shelve self-supervised learning (SSL) based models which are pre-trained and available in public repositories. In contrast to existing methods that fine-tune SSL models and employ additional deep neural networks for downstream tasks, we exploit classical machine learning algorithms such as logistic regression and shallow neural networks using the SSL embeddings extracted using the pre-trained model. Our approach shows competitive results compared to the commonly used high-carbon footprint approaches. In experiments with the ASVspoof 2019 LA dataset, we achieve a 0.90\% equal error rate (EER) with less than 1k trainable model parameters. To encourage further research in this direction and support reproducible results, the Python code will be made publicly accessible following acceptance. Github: https://github.com/sahasubhajit/Speech-Spoofing-
Towards Environmental Preference Based Speech Enhancement For Individualised Multi-Modal Hearing Aids
Feb 26, 2024Since the advent of Deep Learning (DL), Speech Enhancement (SE) models have performed well under a variety of noise conditions. However, such systems may still introduce sonic artefacts, sound unnatural, and restrict the ability for a user to hear ambient sound which may be of importance. Hearing Aid (HA) users may wish to customise their SE systems to suit their personal preferences and day-to-day lifestyle. In this paper, we introduce a preference learning based SE (PLSE) model for future multi-modal HAs that can contextually exploit audio information to improve listening comfort, based upon the preferences of the user. The proposed system estimates the Signal-to-noise ratio (SNR) as a basic objective speech quality measure which quantifies the relative amount of background noise present in speech, and directly correlates to the intelligibility of the signal. Additionally, to provide contextual information we predict the acoustic scene in which the user is situated. These tasks are achieved via a multi-task DL model, which surpasses the performance of inferring the acoustic scene or SNR separately, by jointly leveraging a shared encoded feature space. These environmental inferences are exploited in a preference elicitation framework, which linearly learns a set of predictive functions to determine the target SNR of an AV (Audio-Visual) SE system. By greatly reducing noise in challenging listening conditions, and by novelly scaling the output of the SE model, we are able to provide HA users with contextually individualised SE. Preliminary results suggest an improvement over the non-individualised baseline model in some participants.
Probing Self-supervised Learning Models with Target Speech Extraction
Feb 17, 2024Large-scale pre-trained self-supervised learning (SSL) models have shown remarkable advancements in speech-related tasks. However, the utilization of these models in complex multi-talker scenarios, such as extracting a target speaker in a mixture, is yet to be fully evaluated. In this paper, we introduce target speech extraction (TSE) as a novel downstream task to evaluate the feature extraction capabilities of pre-trained SSL models. TSE uniquely requires both speaker identification and speech separation, distinguishing it from other tasks in the Speech processing Universal PERformance Benchmark (SUPERB) evaluation. Specifically, we propose a TSE downstream model composed of two lightweight task-oriented modules based on the same frozen SSL model. One module functions as a speaker encoder to obtain target speaker information from an enrollment speech, while the other estimates the target speaker's mask to extract its speech from the mixture. Experimental results on the Libri2mix datasets reveal the relevance of the TSE downstream task to probe SSL models, as its performance cannot be simply deduced from other related tasks such as speaker verification and separation.
Probing the Information Encoded in Neural-based Acoustic Models of Automatic Speech Recognition Systems
Feb 29, 2024Deep learning architectures have made significant progress in terms of performance in many research areas. The automatic speech recognition (ASR) field has thus benefited from these scientific and technological advances, particularly for acoustic modeling, now integrating deep neural network architectures. However, these performance gains have translated into increased complexity regarding the information learned and conveyed through these black-box architectures. Following many researches in neural networks interpretability, we propose in this article a protocol that aims to determine which and where information is located in an ASR acoustic model (AM). To do so, we propose to evaluate AM performance on a determined set of tasks using intermediate representations (here, at different layer levels). Regarding the performance variation and targeted tasks, we can emit hypothesis about which information is enhanced or perturbed at different architecture steps. Experiments are performed on both speaker verification, acoustic environment classification, gender classification, tempo-distortion detection systems and speech sentiment/emotion identification. Analysis showed that neural-based AMs hold heterogeneous information that seems surprisingly uncorrelated with phoneme recognition, such as emotion, sentiment or speaker identity. The low-level hidden layers globally appears useful for the structuring of information while the upper ones would tend to delete useless information for phoneme recognition.
Leveraging Linguistically Enhanced Embeddings for Open Information Extraction
Mar 20, 2024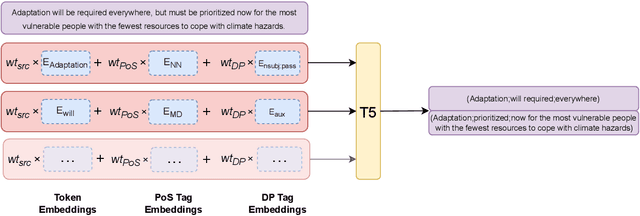

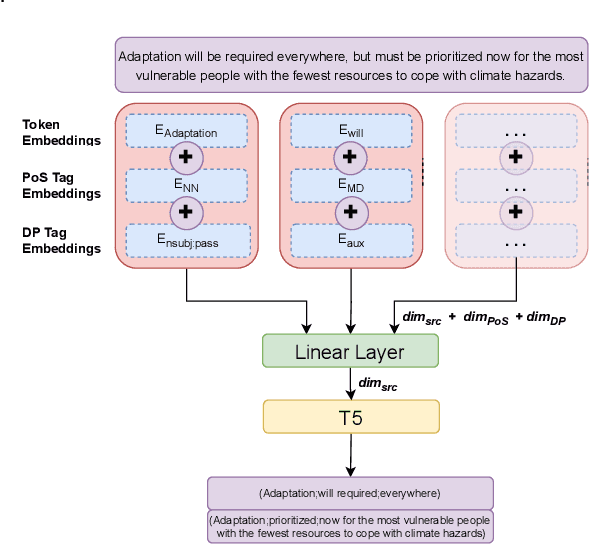
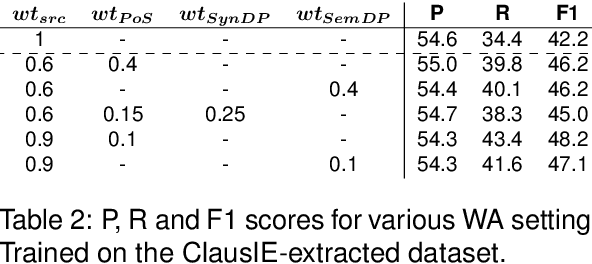
Open Information Extraction (OIE) is a structured prediction (SP) task in Natural Language Processing (NLP) that aims to extract structured $n$-ary tuples - usually subject-relation-object triples - from free text. The word embeddings in the input text can be enhanced with linguistic features, usually Part-of-Speech (PoS) and Syntactic Dependency Parse (SynDP) labels. However, past enhancement techniques cannot leverage the power of pretrained language models (PLMs), which themselves have been hardly used for OIE. To bridge this gap, we are the first to leverage linguistic features with a Seq2Seq PLM for OIE. We do so by introducing two methods - Weighted Addition and Linearized Concatenation. Our work can give any neural OIE architecture the key performance boost from both PLMs and linguistic features in one go. In our settings, this shows wide improvements of up to 24.9%, 27.3% and 14.9% on Precision, Recall and F1 scores respectively over the baseline. Beyond this, we address other important challenges in the field: to reduce compute overheads with the features, we are the first ones to exploit Semantic Dependency Parse (SemDP) tags; to address flaws in current datasets, we create a clean synthetic dataset; finally, we contribute the first known study of OIE behaviour in SP models.
A Study of Dropout-Induced Modality Bias on Robustness to Missing Video Frames for Audio-Visual Speech Recognition
Mar 07, 2024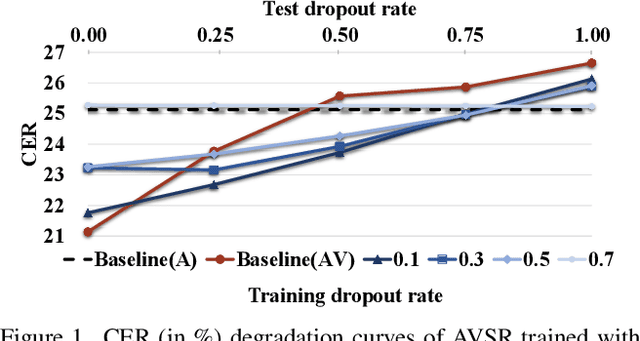

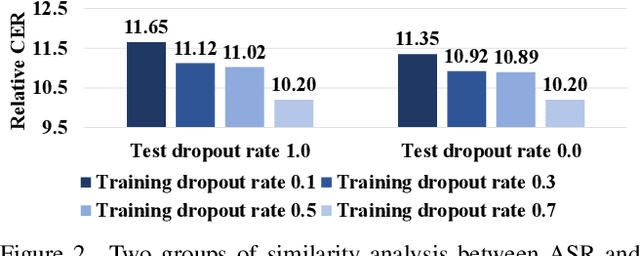
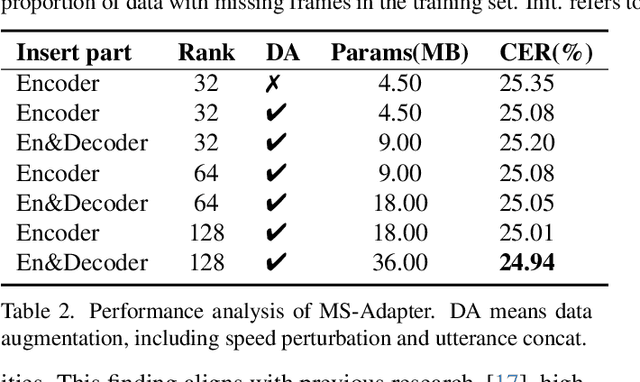
Advanced Audio-Visual Speech Recognition (AVSR) systems have been observed to be sensitive to missing video frames, performing even worse than single-modality models. While applying the dropout technique to the video modality enhances robustness to missing frames, it simultaneously results in a performance loss when dealing with complete data input. In this paper, we investigate this contrasting phenomenon from the perspective of modality bias and reveal that an excessive modality bias on the audio caused by dropout is the underlying reason. Moreover, we present the Modality Bias Hypothesis (MBH) to systematically describe the relationship between modality bias and robustness against missing modality in multimodal systems. Building on these findings, we propose a novel Multimodal Distribution Approximation with Knowledge Distillation (MDA-KD) framework to reduce over-reliance on the audio modality and to maintain performance and robustness simultaneously. Finally, to address an entirely missing modality, we adopt adapters to dynamically switch decision strategies. The effectiveness of our proposed approach is evaluated and validated through a series of comprehensive experiments using the MISP2021 and MISP2022 datasets. Our code is available at https://github.com/dalision/ModalBiasAVSR