 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Online Binaural Speech Separation of Moving Speakers With a Wavesplit Network
Mar 13, 2023
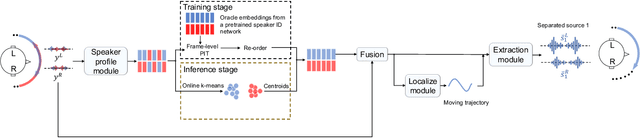
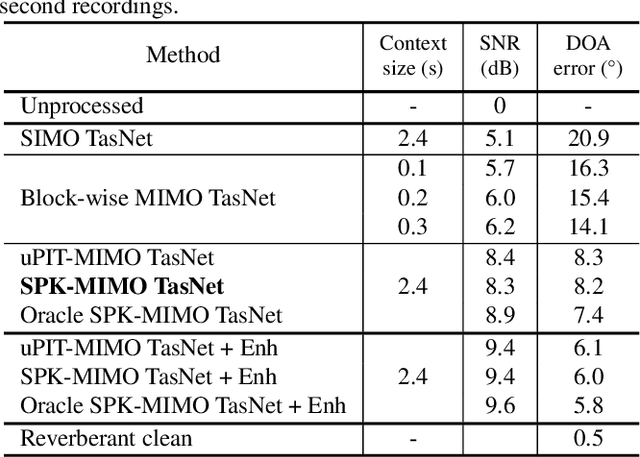
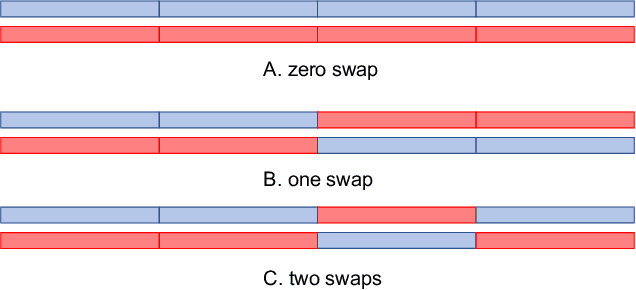
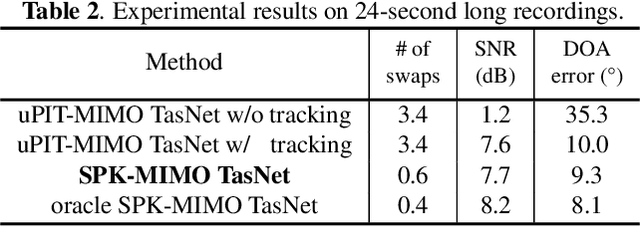
Binaural speech separation in real-world scenarios often involves moving speakers. Most current speech separation methods use utterance-level permutation invariant training (u-PIT) for training. In inference time, however, the order of outputs can be inconsistent over time particularly in long-form speech separation. This situation which is referred to as the speaker swap problem is even more problematic when speakers constantly move in space and therefore poses a challenge for consistent placement of speakers in output channels. Here, we describe a real-time binaural speech separation model based on a Wavesplit network to mitigate the speaker swap problem for moving speaker separation. Our model computes a speaker embedding for each speaker at each time frame from the mixed audio, aggregates embeddings using online clustering, and uses cluster centroids as speaker profiles to track each speaker throughout the long duration. Experimental results on reverberant, long-form moving multitalker speech separation show that the proposed method is less prone to speaker swap and achieves comparable performance with u-PIT based models with ground truth tracking in both separation accuracy and preserving the interaural cues.
ITALIC: An Italian Intent Classification Dataset
Jun 14, 2023
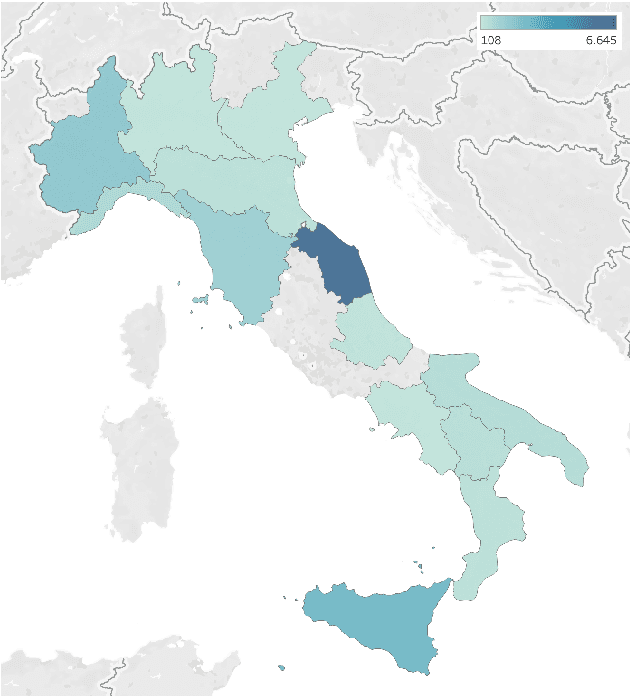
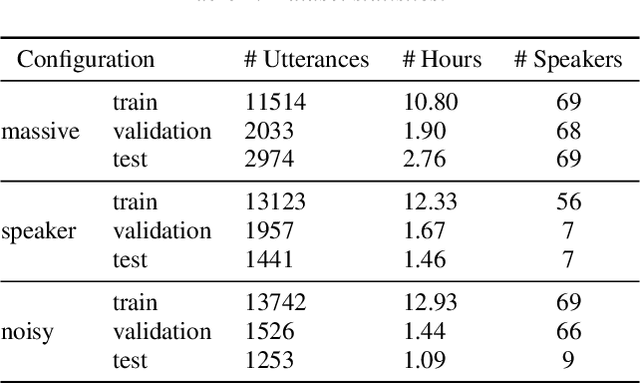
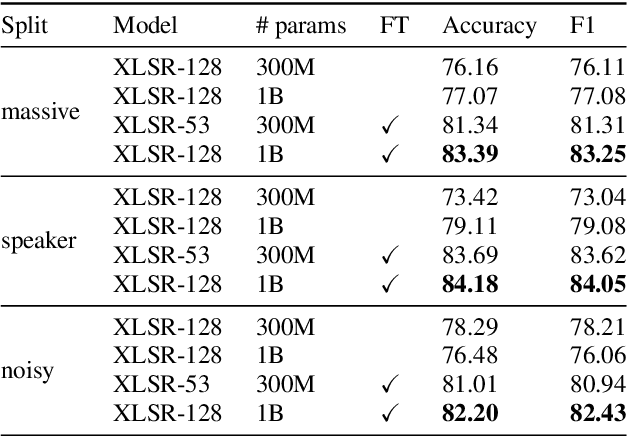
Recent large-scale Spoken Language Understanding datasets focus predominantly on English and do not account for language-specific phenomena such as particular phonemes or words in different lects. We introduce ITALIC, the first large-scale speech dataset designed for intent classification in Italian. The dataset comprises 16,521 crowdsourced audio samples recorded by 70 speakers from various Italian regions and annotated with intent labels and additional metadata. We explore the versatility of ITALIC by evaluating current state-of-the-art speech and text models. Results on intent classification suggest that increasing scale and running language adaptation yield better speech models, monolingual text models outscore multilingual ones, and that speech recognition on ITALIC is more challenging than on existing Italian benchmarks. We release both the dataset and the annotation scheme to streamline the development of new Italian SLU models and language-specific datasets.
Pyramid Multi-branch Fusion DCNN with Multi-Head Self-Attention for Mandarin Speech Recognition
Mar 23, 2023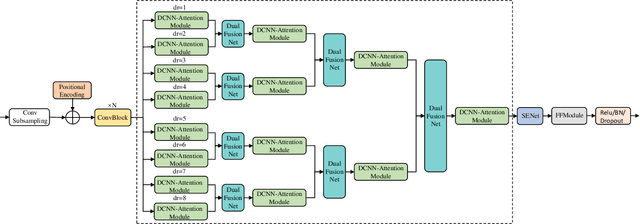

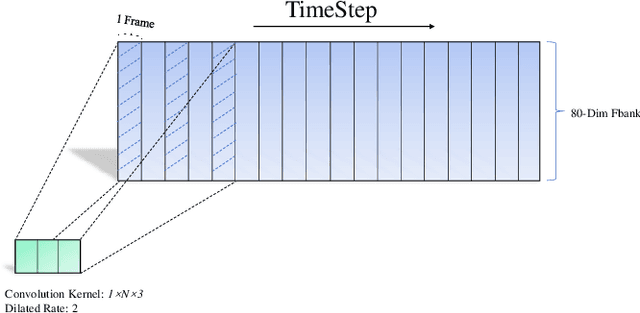

As one of the major branches of automatic speech recognition, attention-based models greatly improves the feature representation ability of the model. In particular, the multi-head mechanism is employed in the attention, hoping to learn speech features of more aspects in different attention subspaces. For speech recognition of complex languages, on the one hand, a small head size will lead to an obvious shortage of learnable aspects. On the other hand, we need to reduce the dimension of each subspace to keep the size of the overall feature space unchanged when we increase the number of heads, which will significantly weaken the ability to represent the feature of each subspace. Therefore, this paper explores how to use a small attention subspace to represent complete speech features while ensuring many heads. In this work we propose a novel neural network architecture, namely, pyramid multi-branch fusion DCNN with multi-head self-attention. The proposed architecture is inspired by Dilated Convolution Neural Networks (DCNN), it uses multiple branches with DCNN to extract the feature of the input speech under different receptive fields. To reduce the number of parameters, every two branches are merged until all the branches are merged into one. Thus, its shape is like a pyramid rotated 90 degrees. We demonstrate that on Aishell-1, a widely used Mandarin speech dataset, our model achieves a character error rate (CER) of 6.45% on the test sets.
A Federated Approach for Hate Speech Detection
Feb 18, 2023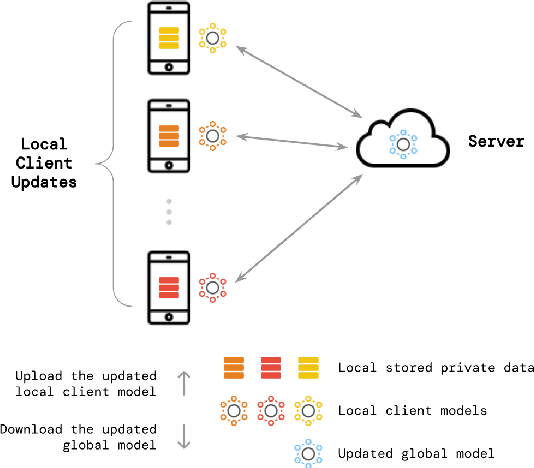
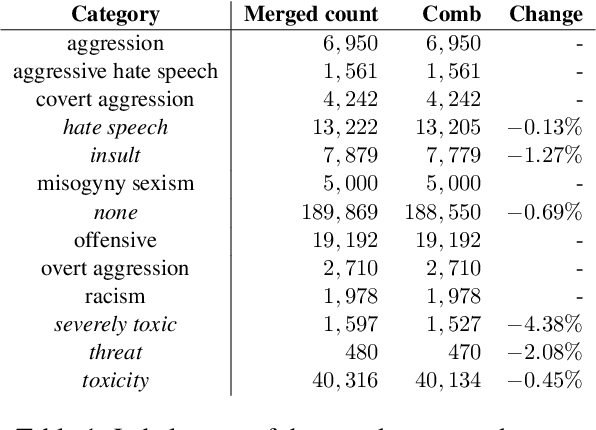
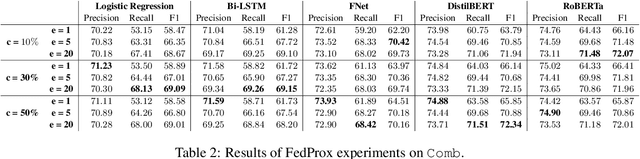
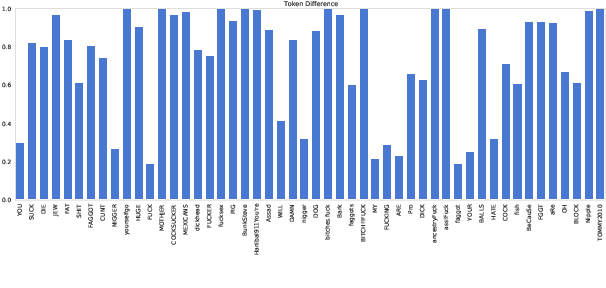
Hate speech detection has been the subject of high research attention, due to the scale of content created on social media. In spite of the attention and the sensitive nature of the task, privacy preservation in hate speech detection has remained under-studied. The majority of research has focused on centralised machine learning infrastructures which risk leaking data. In this paper, we show that using federated machine learning can help address privacy the concerns that are inherent to hate speech detection while obtaining up to 6.81% improvement in terms of F1-score.
AlignAtt: Using Attention-based Audio-Translation Alignments as a Guide for Simultaneous Speech Translation
May 19, 2023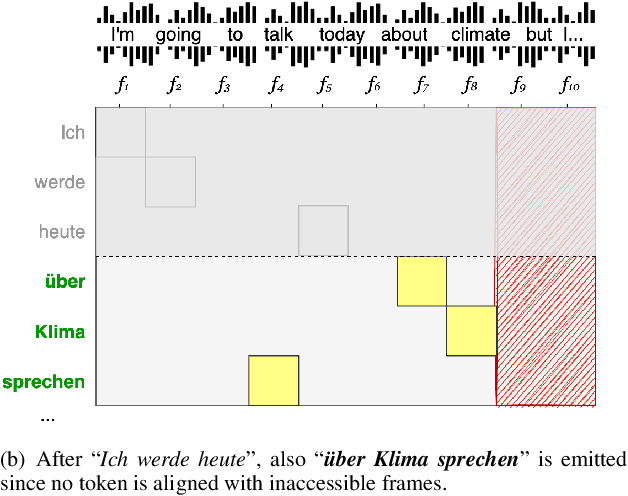

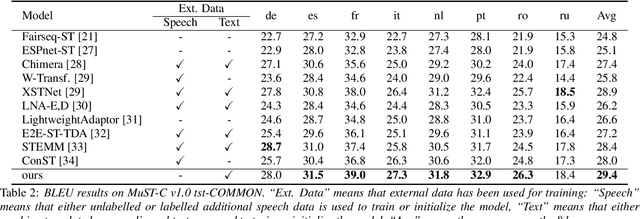
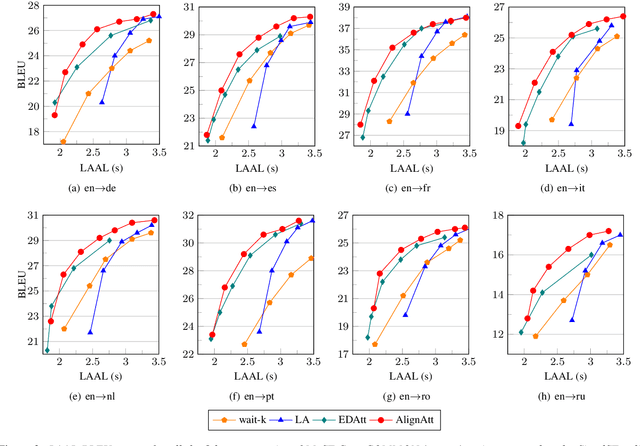
Attention is the core mechanism of today's most used architectures for natural language processing and has been analyzed from many perspectives, including its effectiveness for machine translation-related tasks. Among these studies, attention resulted to be a useful source of information to get insights about word alignment also when the input text is substituted with audio segments, as in the case of the speech translation (ST) task. In this paper, we propose AlignAtt, a novel policy for simultaneous ST (SimulST) that exploits the attention information to generate source-target alignments that guide the model during inference. Through experiments on the 8 language pairs of MuST-C v1.0, we show that AlignAtt outperforms previous state-of-the-art SimulST policies applied to offline-trained models with gains in terms of BLEU of 2 points and latency reductions ranging from 0.5s to 0.8s across the 8 languages.
Ensemble knowledge distillation of self-supervised speech models
Feb 24, 2023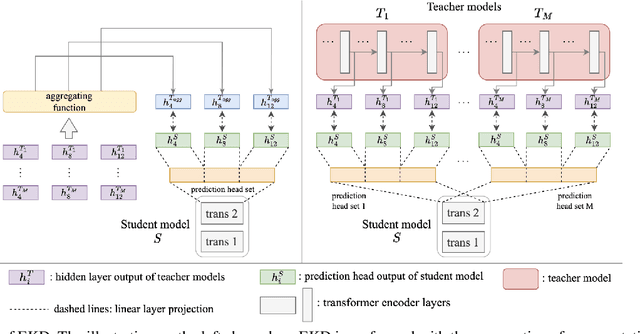
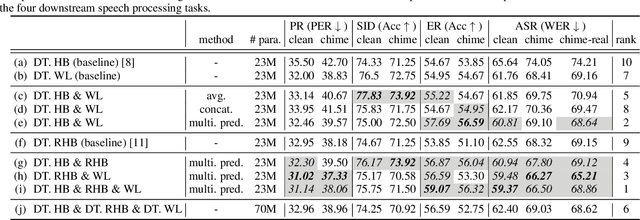
Distilled self-supervised models have shown competitive performance and efficiency in recent years. However, there is a lack of experience in jointly distilling multiple self-supervised speech models. In our work, we performed Ensemble Knowledge Distillation (EKD) on various self-supervised speech models such as HuBERT, RobustHuBERT, and WavLM. We tried two different aggregation techniques, layerwise-average and layerwise-concatenation, to the representations of different teacher models and found that the former was more effective. On top of that, we proposed a multiple prediction head method for student models to predict different layer outputs of multiple teacher models simultaneously. The experimental results show that our method improves the performance of the distilled models on four downstream speech processing tasks, Phoneme Recognition, Speaker Identification, Emotion Recognition, and Automatic Speech Recognition in the hidden-set track of the SUPERB benchmark.
Cross-lingual Knowledge Transfer and Iterative Pseudo-labeling for Low-Resource Speech Recognition with Transducers
May 23, 2023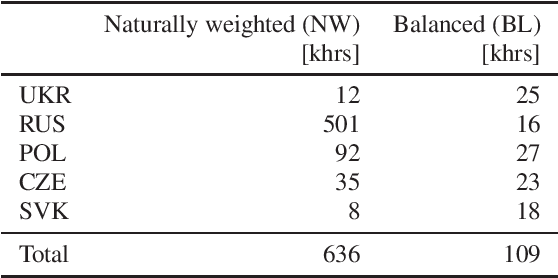


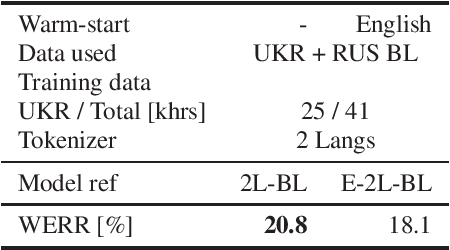
Voice technology has become ubiquitous recently. However, the accuracy, and hence experience, in different languages varies significantly, which makes the technology not equally inclusive. The availability of data for different languages is one of the key factors affecting accuracy, especially in training of all-neural end-to-end automatic speech recognition systems. Cross-lingual knowledge transfer and iterative pseudo-labeling are two techniques that have been shown to be successful for improving the accuracy of ASR systems, in particular for low-resource languages, like Ukrainian. Our goal is to train an all-neural Transducer-based ASR system to replace a DNN-HMM hybrid system with no manually annotated training data. We show that the Transducer system trained using transcripts produced by the hybrid system achieves 18% reduction in terms of word error rate. However, using a combination of cross-lingual knowledge transfer from related languages and iterative pseudo-labeling, we are able to achieve 35% reduction of the error rate.
A Vector Quantized Approach for Text to Speech Synthesis on Real-World Spontaneous Speech
Feb 08, 2023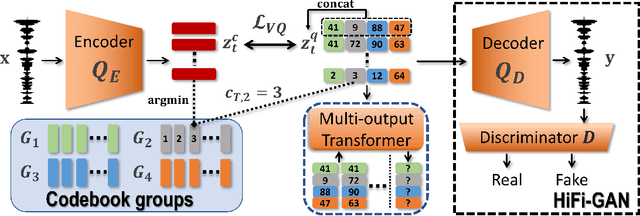
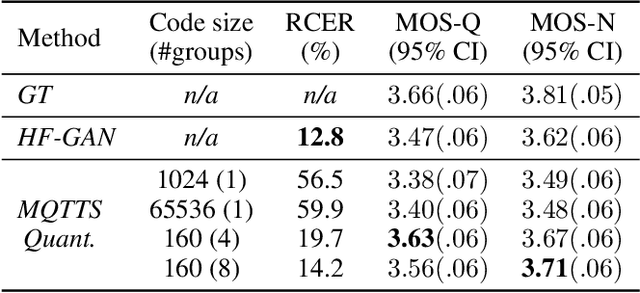
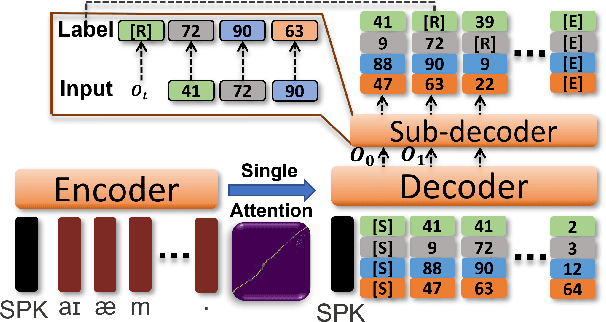
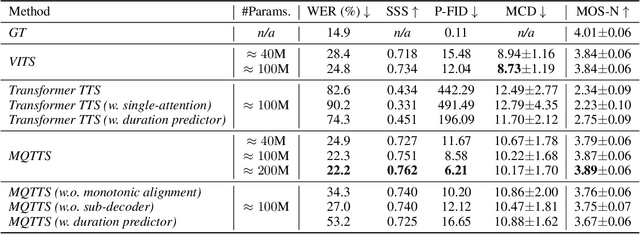
Recent Text-to-Speech (TTS) systems trained on reading or acted corpora have achieved near human-level naturalness. The diversity of human speech, however, often goes beyond the coverage of these corpora. We believe the ability to handle such diversity is crucial for AI systems to achieve human-level communication. Our work explores the use of more abundant real-world data for building speech synthesizers. We train TTS systems using real-world speech from YouTube and podcasts. We observe the mismatch between training and inference alignments in mel-spectrogram based autoregressive models, leading to unintelligible synthesis, and demonstrate that learned discrete codes within multiple code groups effectively resolves this issue. We introduce our MQTTS system whose architecture is designed for multiple code generation and monotonic alignment, along with the use of a clean silence prompt to improve synthesis quality. We conduct ablation analyses to identify the efficacy of our methods. We show that MQTTS outperforms existing TTS systems in several objective and subjective measures.
Deep Neural Networks and Brain Alignment: Brain Encoding and Decoding (Survey)
Jul 17, 2023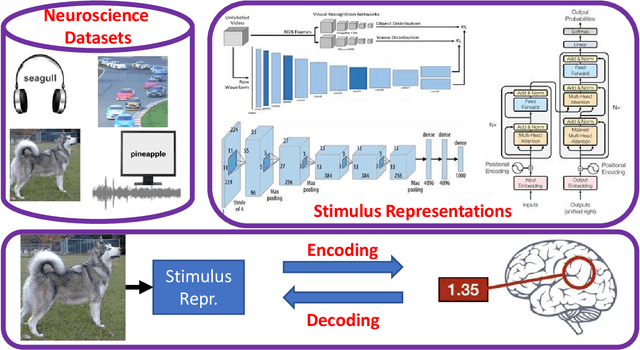
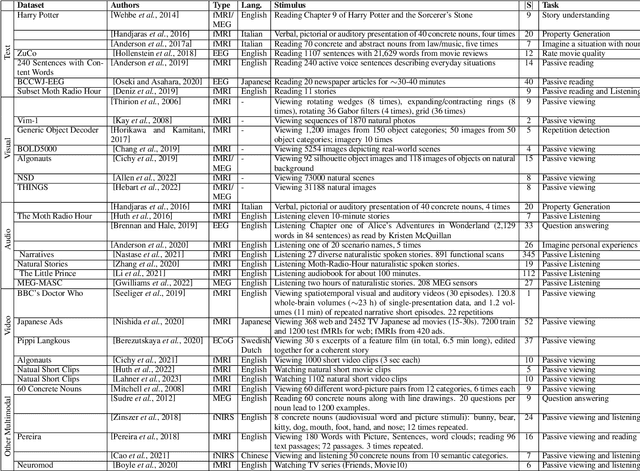
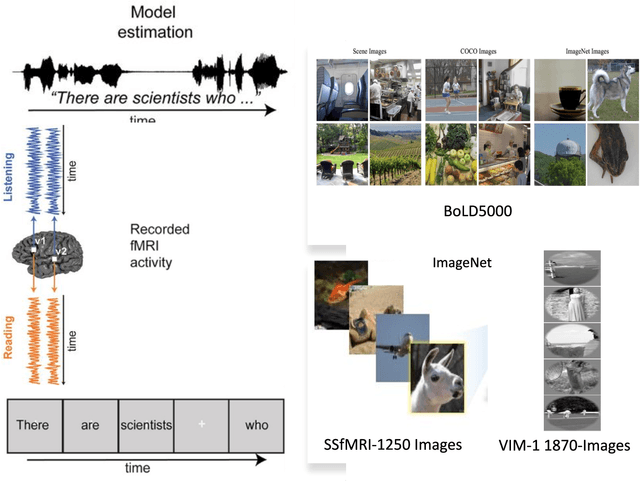
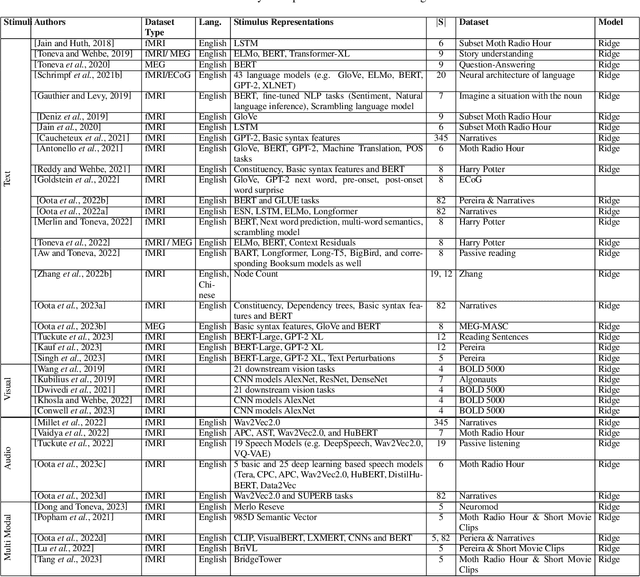
How does the brain represent different modes of information? Can we design a system that automatically understands what the user is thinking? Such questions can be answered by studying brain recordings like functional magnetic resonance imaging (fMRI). As a first step, the neuroscience community has contributed several large cognitive neuroscience datasets related to passive reading/listening/viewing of concept words, narratives, pictures and movies. Encoding and decoding models using these datasets have also been proposed in the past two decades. These models serve as additional tools for basic research in cognitive science and neuroscience. Encoding models aim at generating fMRI brain representations given a stimulus automatically. They have several practical applications in evaluating and diagnosing neurological conditions and thus also help design therapies for brain damage. Decoding models solve the inverse problem of reconstructing the stimuli given the fMRI. They are useful for designing brain-machine or brain-computer interfaces. Inspired by the effectiveness of deep learning models for natural language processing, computer vision, and speech, recently several neural encoding and decoding models have been proposed. In this survey, we will first discuss popular representations of language, vision and speech stimuli, and present a summary of neuroscience datasets. Further, we will review popular deep learning based encoding and decoding architectures and note their benefits and limitations. Finally, we will conclude with a brief summary and discussion about future trends. Given the large amount of recently published work in the `computational cognitive neuroscience' community, we believe that this survey nicely organizes the plethora of work and presents it as a coherent story.
DIVERSIFY: A General Framework for Time Series Out-of-distribution Detection and Generalization
Aug 04, 2023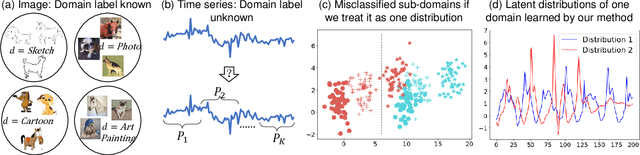
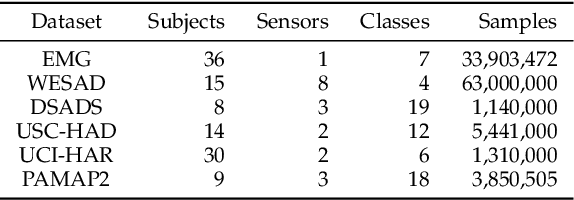

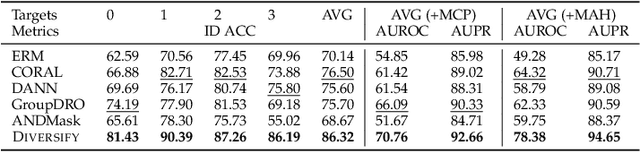
Time series remains one of the most challenging modalities in machine learning research. The out-of-distribution (OOD) detection and generalization on time series tend to suffer due to its non-stationary property, i.e., the distribution changes over time. The dynamic distributions inside time series pose great challenges to existing algorithms to identify invariant distributions since they mainly focus on the scenario where the domain information is given as prior knowledge. In this paper, we attempt to exploit subdomains within a whole dataset to counteract issues induced by non-stationary for generalized representation learning. We propose DIVERSIFY, a general framework, for OOD detection and generalization on dynamic distributions of time series. DIVERSIFY takes an iterative process: it first obtains the "worst-case" latent distribution scenario via adversarial training, then reduces the gap between these latent distributions. We implement DIVERSIFY via combining existing OOD detection methods according to either extracted features or outputs of models for detection while we also directly utilize outputs for classification. In addition, theoretical insights illustrate that DIVERSIFY is theoretically supported. Extensive experiments are conducted on seven datasets with different OOD settings across gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition. Qualitative and quantitative results demonstrate that DIVERSIFY learns more generalized features and significantly outperforms other baselines.