 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MOSPC: MOS Prediction Based on Pairwise Comparison
Jun 18, 2023
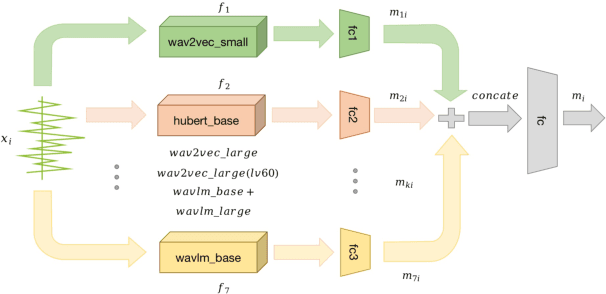

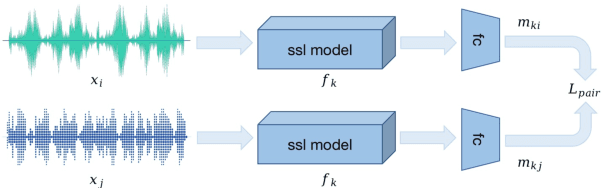
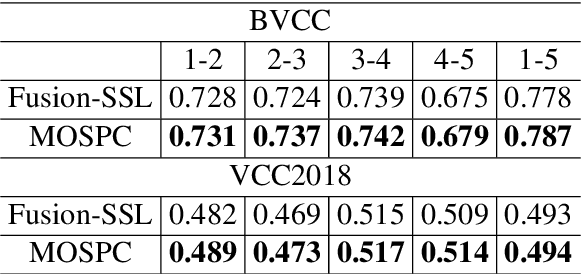
As a subjective metric to evaluate the quality of synthesized speech, Mean opinion score~(MOS) usually requires multiple annotators to score the same speech. Such an annotation approach requires a lot of manpower and is also time-consuming. MOS prediction model for automatic evaluation can significantly reduce labor cost. In previous works, it is difficult to accurately rank the quality of speech when the MOS scores are close. However, in practical applications, it is more important to correctly rank the quality of synthesis systems or sentences than simply predicting MOS scores. Meanwhile, as each annotator scores multiple audios during annotation, the score is probably a relative value based on the first or the first few speech scores given by the annotator. Motivated by the above two points, we propose a general framework for MOS prediction based on pair comparison (MOSPC), and we utilize C-Mixup algorithm to enhance the generalization performance of MOSPC. The experiments on BVCC and VCC2018 show that our framework outperforms the baselines on most of the correlation coefficient metrics, especially on the metric KTAU related to quality ranking. And our framework also surpasses the strong baseline in ranking accuracy on each fine-grained segment. These results indicate that our framework contributes to improving the ranking accuracy of speech quality.
Leveraging Large Text Corpora for End-to-End Speech Summarization
Mar 02, 2023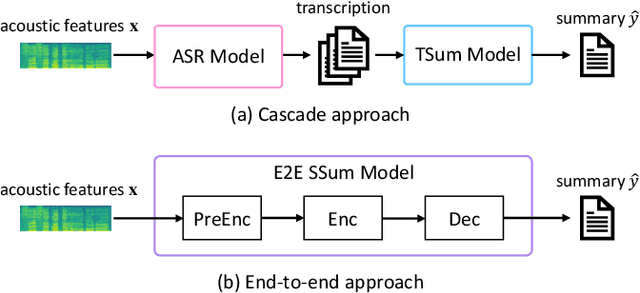

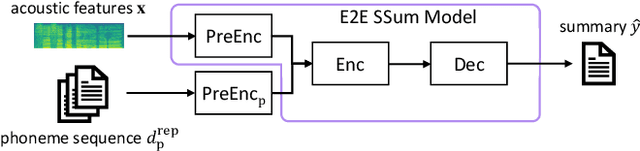

End-to-end speech summarization (E2E SSum) is a technique to directly generate summary sentences from speech. Compared with the cascade approach, which combines automatic speech recognition (ASR) and text summarization models, the E2E approach is more promising because it mitigates ASR errors, incorporates nonverbal information, and simplifies the overall system. However, since collecting a large amount of paired data (i.e., speech and summary) is difficult, the training data is usually insufficient to train a robust E2E SSum system. In this paper, we present two novel methods that leverage a large amount of external text summarization data for E2E SSum training. The first technique is to utilize a text-to-speech (TTS) system to generate synthesized speech, which is used for E2E SSum training with the text summary. The second is a TTS-free method that directly inputs phoneme sequence instead of synthesized speech to the E2E SSum model. Experiments show that our proposed TTS- and phoneme-based methods improve several metrics on the How2 dataset. In particular, our best system outperforms a previous state-of-the-art one by a large margin (i.e., METEOR score improvements of more than 6 points). To the best of our knowledge, this is the first work to use external language resources for E2E SSum. Moreover, we report a detailed analysis of the How2 dataset to confirm the validity of our proposed E2E SSum system.
SpeechPrompt v2: Prompt Tuning for Speech Classification Tasks
Mar 01, 2023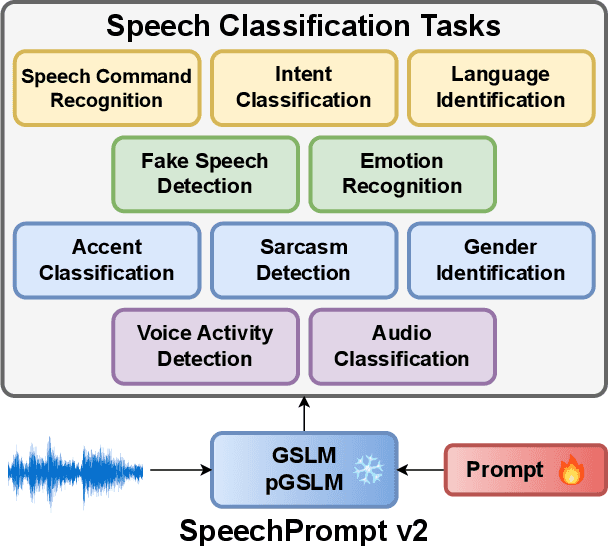
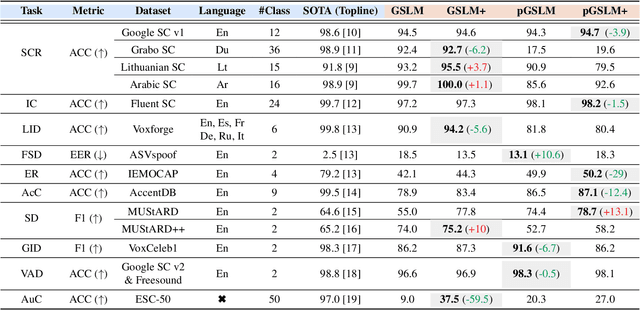
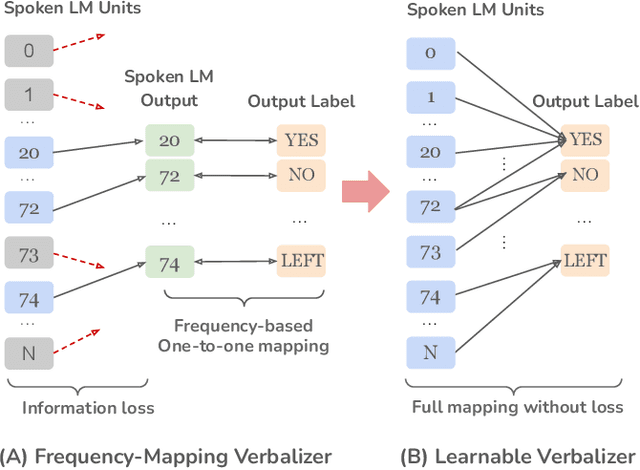
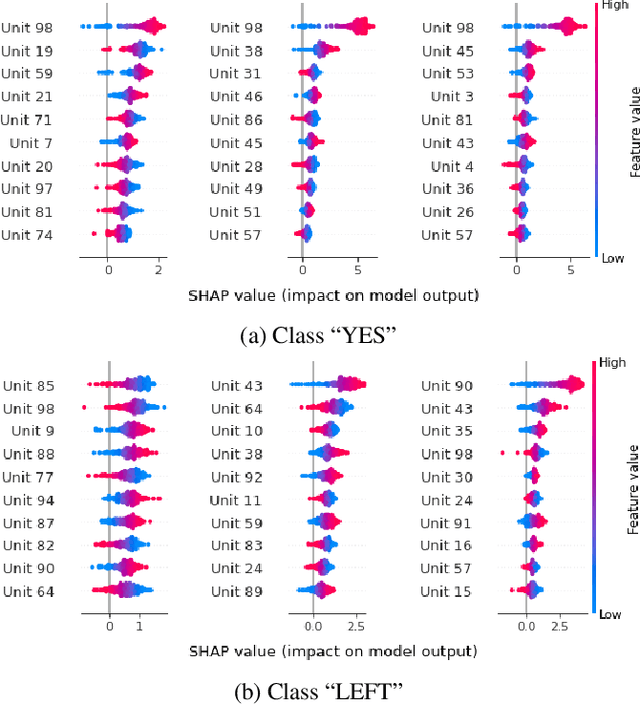
Prompt tuning is a technology that tunes a small set of parameters to steer a pre-trained language model (LM) to directly generate the output for downstream tasks. Recently, prompt tuning has demonstrated its storage and computation efficiency in both natural language processing (NLP) and speech processing fields. These advantages have also revealed prompt tuning as a candidate approach to serving pre-trained LM for multiple tasks in a unified manner. For speech processing, SpeechPrompt shows its high parameter efficiency and competitive performance on a few speech classification tasks. However, whether SpeechPrompt is capable of serving a large number of tasks is unanswered. In this work, we propose SpeechPrompt v2, a prompt tuning framework capable of performing a wide variety of speech classification tasks, covering multiple languages and prosody-related tasks. The experiment result shows that SpeechPrompt v2 achieves performance on par with prior works with less than 0.15M trainable parameters in a unified framework.
Front-End Adapter: Adapting Front-End Input of Speech based Self-Supervised Learning for Speech Recognition
Feb 18, 2023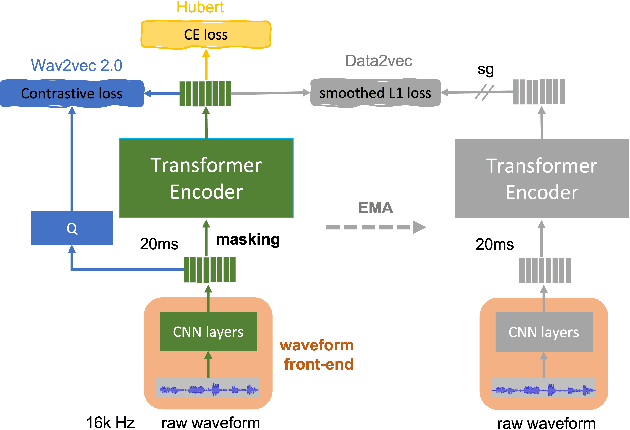
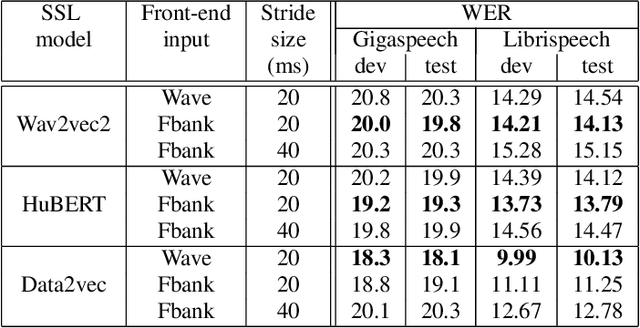
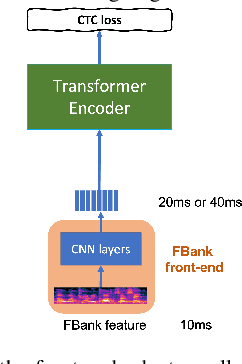
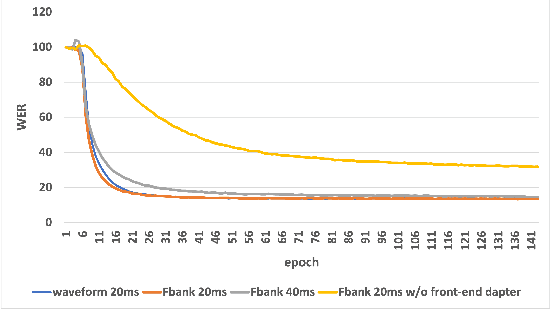
Recent years have witnessed a boom in self-supervised learning (SSL) in various areas including speech processing. Speech based SSL models present promising performance in a range of speech related tasks. However, the training of SSL models is computationally expensive and a common practice is to fine-tune a released SSL model on the specific task. It is essential to use consistent front-end input during pre-training and fine-tuning. This consistency may introduce potential issues when the optimal front-end is not the same as that used in pre-training. In this paper, we propose a simple but effective front-end adapter to address this front-end discrepancy. By minimizing the distance between the outputs of different front-ends, the filterbank feature (Fbank) can be compatible with SSL models which are pre-trained with waveform. The experiment results demonstrate the effectiveness of our proposed front-end adapter on several popular SSL models for the speech recognition task.
MoLE : Mixture of Language Experts for Multi-Lingual Automatic Speech Recognition
Feb 27, 2023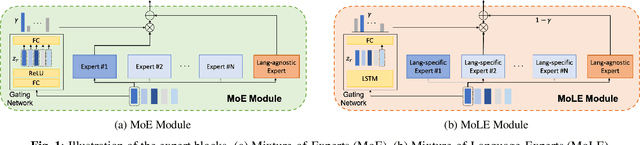
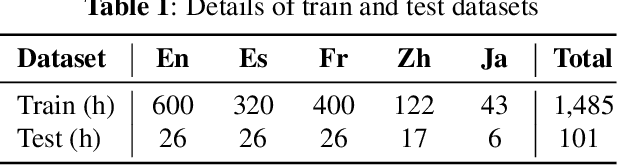
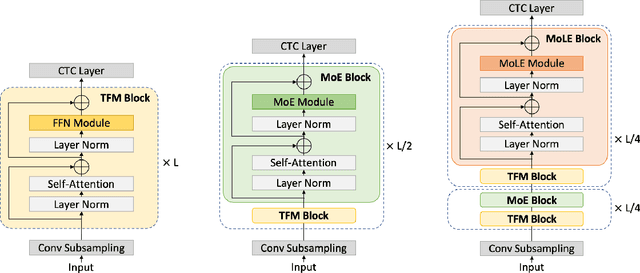
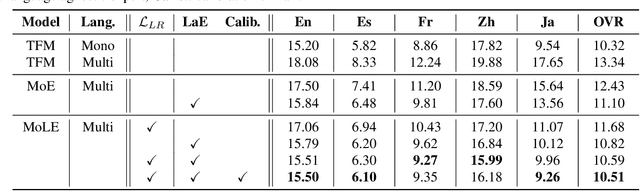
Multi-lingual speech recognition aims to distinguish linguistic expressions in different languages and integrate acoustic processing simultaneously. In contrast, current multi-lingual speech recognition research follows a language-aware paradigm, mainly targeted to improve recognition performance rather than discriminate language characteristics. In this paper, we present a multi-lingual speech recognition network named Mixture-of-Language-Expert(MoLE), which digests speech in a variety of languages. Specifically, MoLE analyzes linguistic expression from input speech in arbitrary languages, activating a language-specific expert with a lightweight language tokenizer. The tokenizer not only activates experts, but also estimates the reliability of the activation. Based on the reliability, the activated expert and the language-agnostic expert are aggregated to represent language-conditioned embedding for efficient speech recognition. Our proposed model is evaluated in 5 languages scenario, and the experimental results show that our structure is advantageous on multi-lingual recognition, especially for speech in low-resource language.
Identity Construction in a Misogynist Incels Forum
Jun 30, 2023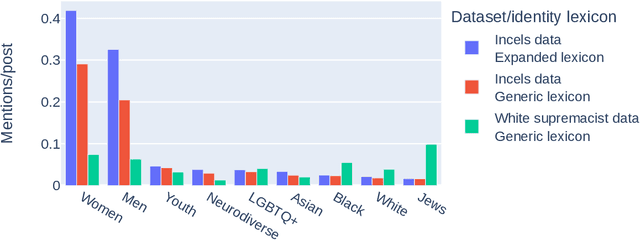
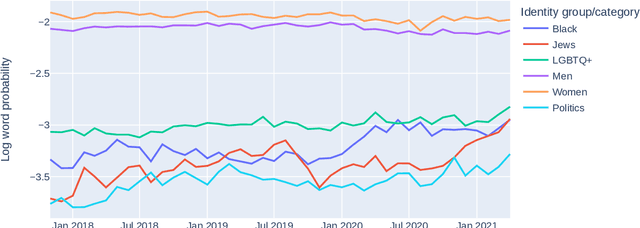
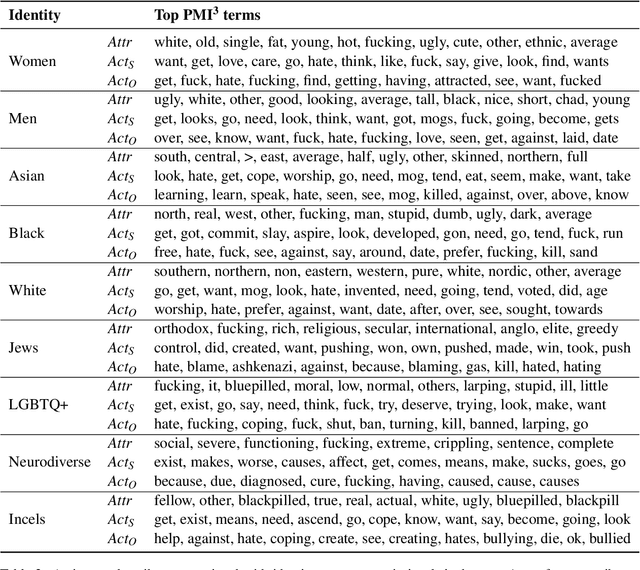
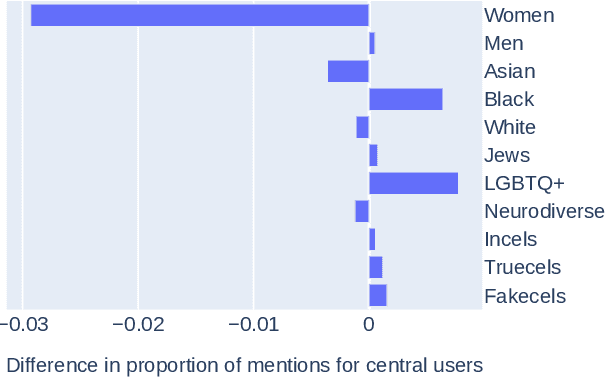
Online communities of involuntary celibates (incels) are a prominent source of misogynist hate speech. In this paper, we use quantitative text and network analysis approaches to examine how identity groups are discussed on <incels.is>, the largest black-pilled incels forum. We find that this community produces a wide range of novel identity terms and, while terms for women are most common, mentions of other minoritized identities are increasing. An analysis of the associations made with identity groups suggests an essentialist ideology where physical appearance, as well as gender and racial hierarchies, determine human value. We discuss implications for research into automated misogynist hate speech detection.
Online Binaural Speech Separation of Moving Speakers With a Wavesplit Network
Mar 13, 2023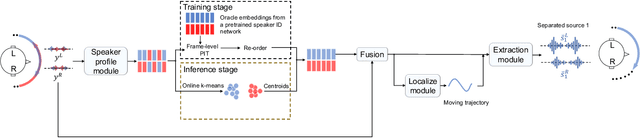
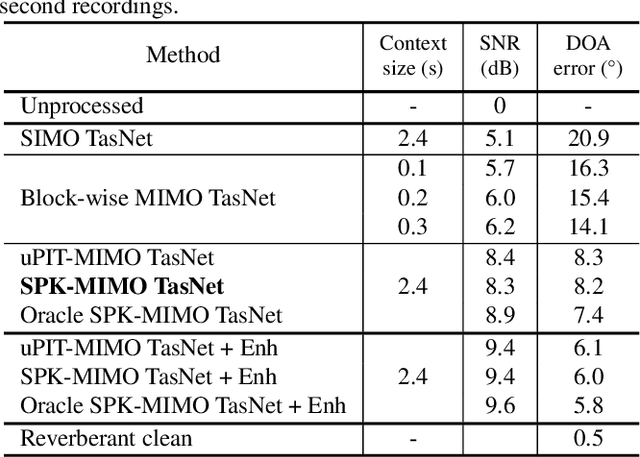
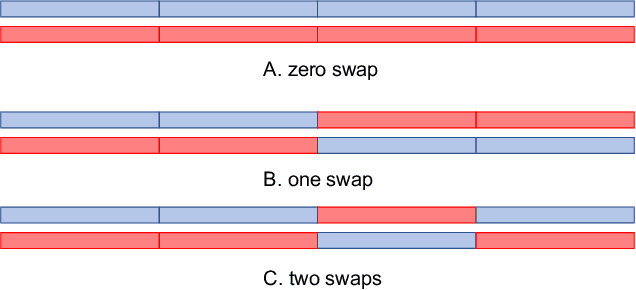
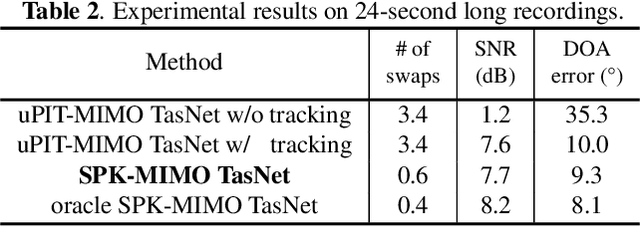
Binaural speech separation in real-world scenarios often involves moving speakers. Most current speech separation methods use utterance-level permutation invariant training (u-PIT) for training. In inference time, however, the order of outputs can be inconsistent over time particularly in long-form speech separation. This situation which is referred to as the speaker swap problem is even more problematic when speakers constantly move in space and therefore poses a challenge for consistent placement of speakers in output channels. Here, we describe a real-time binaural speech separation model based on a Wavesplit network to mitigate the speaker swap problem for moving speaker separation. Our model computes a speaker embedding for each speaker at each time frame from the mixed audio, aggregates embeddings using online clustering, and uses cluster centroids as speaker profiles to track each speaker throughout the long duration. Experimental results on reverberant, long-form moving multitalker speech separation show that the proposed method is less prone to speaker swap and achieves comparable performance with u-PIT based models with ground truth tracking in both separation accuracy and preserving the interaural cues.
Towards spoken dialect identification of Irish
Jul 14, 2023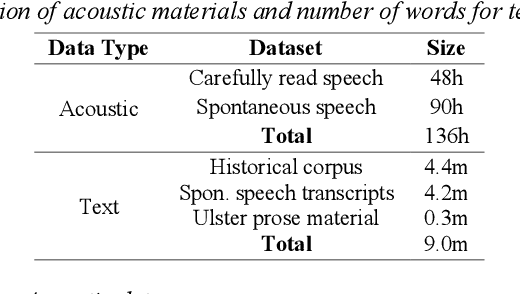
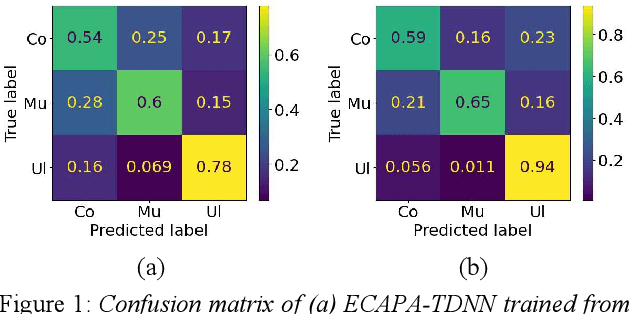
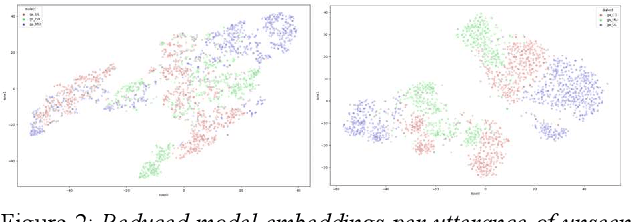
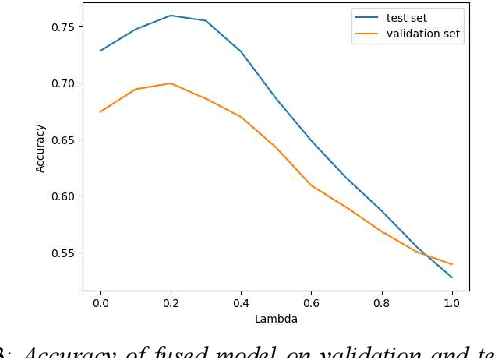
The Irish language is rich in its diversity of dialects and accents. This compounds the difficulty of creating a speech recognition system for the low-resource language, as such a system must contend with a high degree of variability with limited corpora. A recent study investigating dialect bias in Irish ASR found that balanced training corpora gave rise to unequal dialect performance, with performance for the Ulster dialect being consistently worse than for the Connacht or Munster dialects. Motivated by this, the present experiments investigate spoken dialect identification of Irish, with a view to incorporating such a system into the speech recognition pipeline. Two acoustic classification models are tested, XLS-R and ECAPA-TDNN, in conjunction with a text-based classifier using a pretrained Irish-language BERT model. The ECAPA-TDNN, particularly a model pretrained for language identification on the VoxLingua107 dataset, performed best overall, with an accuracy of 73%. This was further improved to 76% by fusing the model's outputs with the text-based model. The Ulster dialect was most accurately identified, with an accuracy of 94%, however the model struggled to disambiguate between the Connacht and Munster dialects, suggesting a more nuanced approach may be necessary to robustly distinguish between the dialects of Irish.
Developmental Bootstrapping of AIs
Aug 11, 2023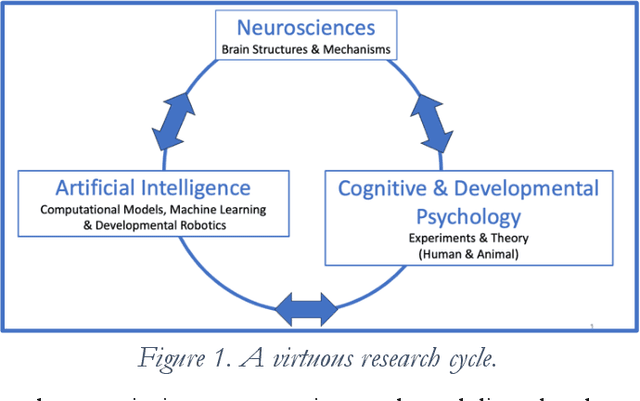

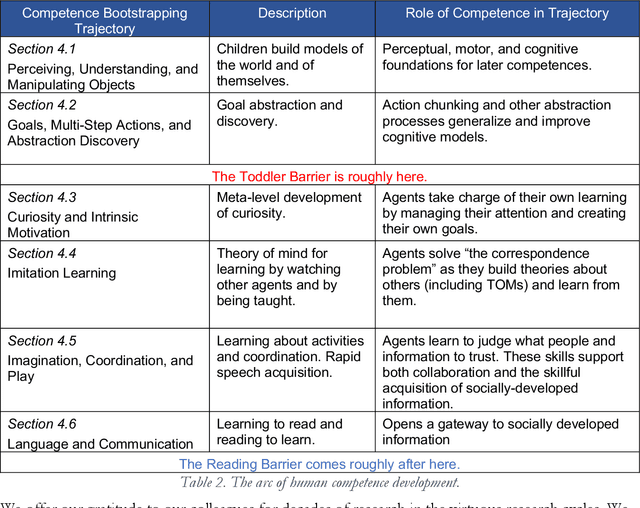
Although some current AIs surpass human abilities especially in closed artificial worlds such as board games, their abilities in the real world are limited. They make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. They do not make good collaborators. Mainstream approaches for creating AIs are built using the traditional manually-constructed symbolic AI approach and generative and deep learning AI approaches including large language models (LLMs). These systems are not well suited for creating robust and trustworthy AIs. Although it is outside of the mainstream, the developmental bootstrapping approach has more promise. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. They interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. They acquire the competences that they need through an incremental bootstrapping process. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped at the Toddler Barrier corresponding to human infant development at about two years of age, before their speech is fluent. They also do not bridge the Reading Barrier, to skillfully and skeptically tap into the vast socially developed recorded information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This position paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to acquire further competences and create robust and resilient AIs.
UniBriVL: Robust Universal Representation and Generation of Audio Driven Diffusion Models
Jul 29, 2023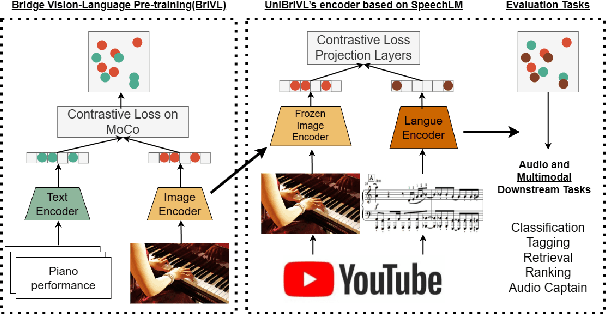
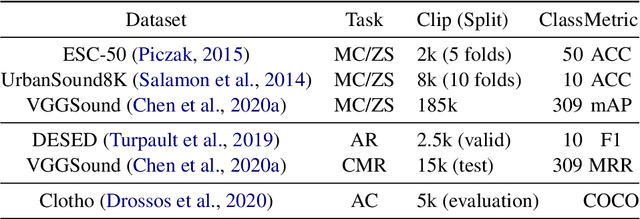

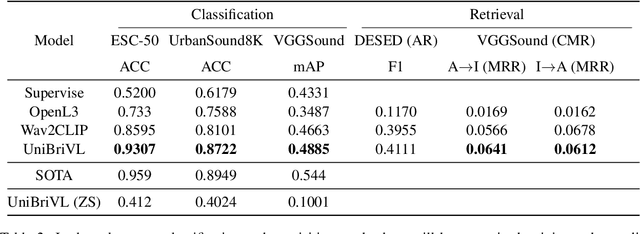
Multimodal large models have been recognized for their advantages in various performance and downstream tasks. The development of these models is crucial towards achieving general artificial intelligence in the future. In this paper, we propose a novel universal language representation learning method called UniBriVL, which is based on Bridging-Vision-and-Language (BriVL). Universal BriVL embeds audio, image, and text into a shared space, enabling the realization of various multimodal applications. Our approach addresses major challenges in robust language (both text and audio) representation learning and effectively captures the correlation between audio and image. Additionally, we demonstrate the qualitative evaluation of the generated images from UniBriVL, which serves to highlight the potential of our approach in creating images from audio. Overall, our experimental results demonstrate the efficacy of UniBriVL in downstream tasks and its ability to choose appropriate images from audio. The proposed approach has the potential for various applications such as speech recognition, music signal processing, and captioning systems.