 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 08, 2023
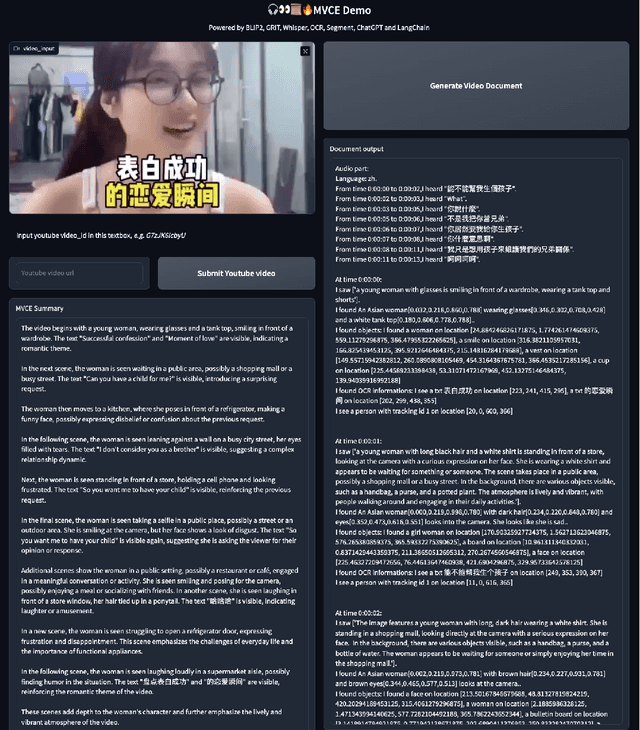
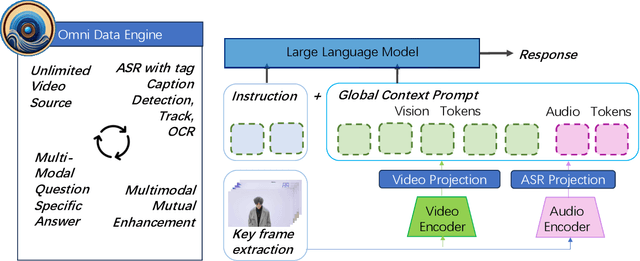

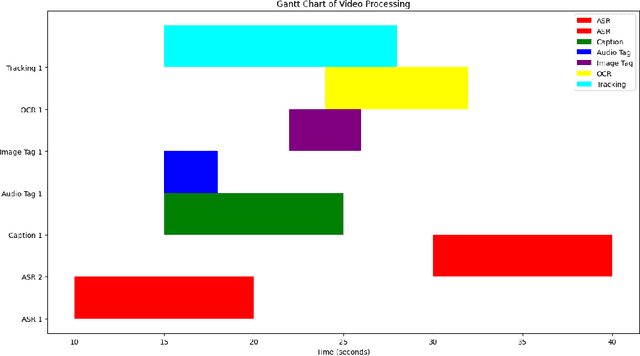
This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.
Multi-channel Speech Separation Using Spatially Selective Deep Non-linear Filters
Apr 24, 2023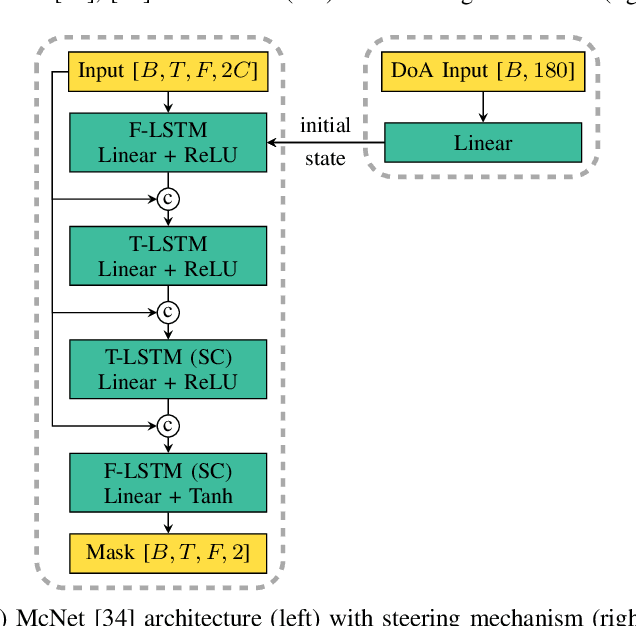
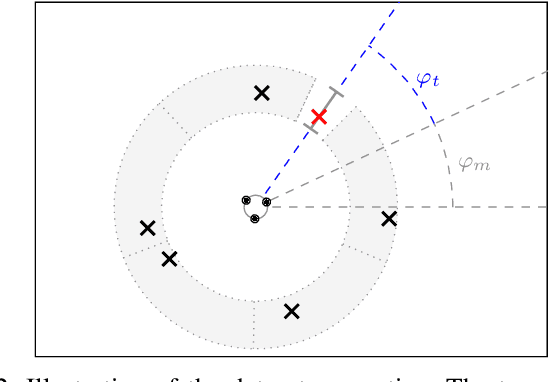
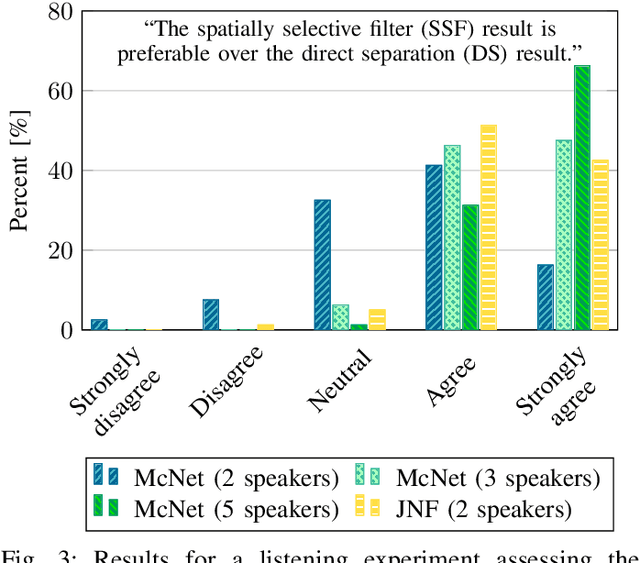
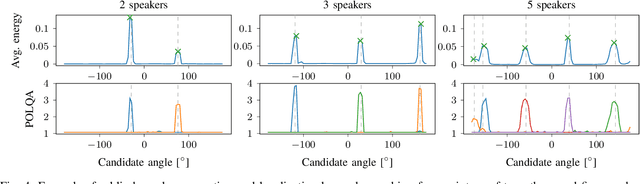
In a multi-channel separation task with multiple speakers, we aim to recover all individual speech signals from the mixture. In contrast to single-channel approaches, which rely on the different spectro-temporal characteristics of the speech signals, multi-channel approaches should additionally utilize the different spatial locations of the sources for a more powerful separation especially when the number of sources increases. To enhance the spatial processing in a multi-channel source separation scenario, in this work, we propose a deep neural network (DNN) based spatially selective filter (SSF) that can be spatially steered to extract the speaker of interest by initializing a recurrent neural network layer with the target direction. We compare the proposed SSF with a common end-to-end direct separation (DS) approach trained using utterance-wise permutation invariant training (PIT), which only implicitly learns to perform spatial filtering. We show that the SSF has a clear advantage over a DS approach with the same underlying network architecture when there are more than two speakers in the mixture, which can be attributed to a better use of the spatial information. Furthermore, we find that the SSF generalizes much better to additional noise sources that were not seen during training.
Boosting Punctuation Restoration with Data Generation and Reinforcement Learning
Jul 24, 2023Punctuation restoration is an important task in automatic speech recognition (ASR) which aim to restore the syntactic structure of generated ASR texts to improve readability. While punctuated texts are abundant from written documents, the discrepancy between written punctuated texts and ASR texts limits the usability of written texts in training punctuation restoration systems for ASR texts. This paper proposes a reinforcement learning method to exploit in-topic written texts and recent advances in large pre-trained generative language models to bridge this gap. The experiments show that our method achieves state-of-the-art performance on the ASR test set on two benchmark datasets for punctuation restoration.
Exploration on HuBERT with Multiple Resolutions
Jun 22, 2023

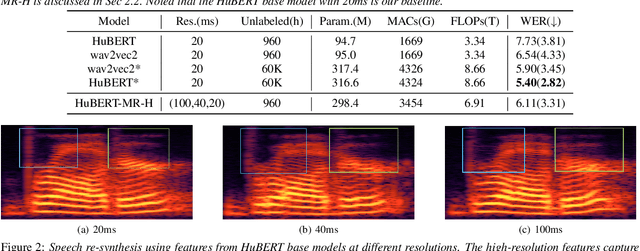
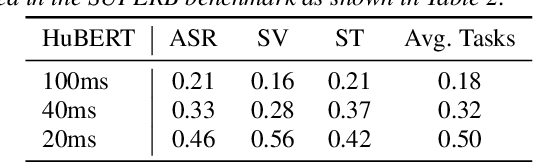
Hidden-unit BERT (HuBERT) is a widely-used self-supervised learning (SSL) model in speech processing. However, we argue that its fixed 20ms resolution for hidden representations would not be optimal for various speech-processing tasks since their attributes (e.g., speaker characteristics and semantics) are based on different time scales. To address this limitation, we propose utilizing HuBERT representations at multiple resolutions for downstream tasks. We explore two approaches, namely the parallel and hierarchical approaches, for integrating HuBERT features with different resolutions. Through experiments, we demonstrate that HuBERT with multiple resolutions outperforms the original model. This highlights the potential of utilizing multiple resolutions in SSL models like HuBERT to capture diverse information from speech signals.
ForkNet: Simultaneous Time and Time-Frequency Domain Modeling for Speech Enhancement
May 15, 2023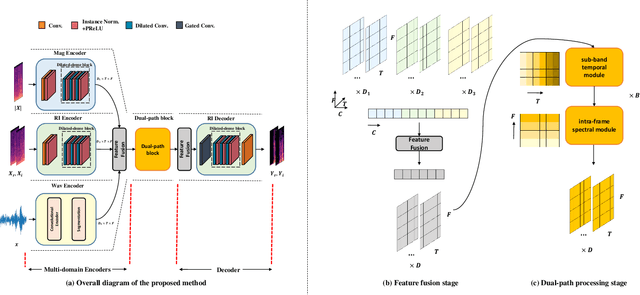

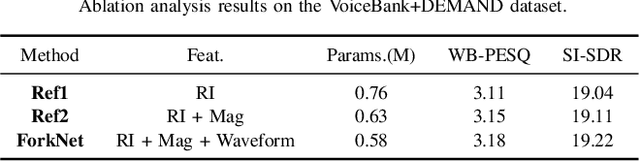
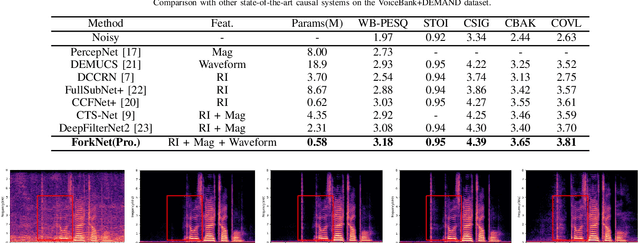
Previous research in speech enhancement has mostly focused on modeling time or time-frequency domain information alone, with little consideration given to the potential benefits of simultaneously modeling both domains. Since these domains contain complementary information, combining them may improve the performance of the model. In this letter, we propose a new approach to simultaneously model time and time-frequency domain information in a single model. We begin with the DPT-FSNet (causal version) model as a baseline and modify the encoder structure by replacing the original encoder with three separate encoders, each dedicated to modeling time-domain, real-imaginary, and magnitude information, respectively. Additionally, we introduce a feature fusion module both before and after the dual-path processing blocks to better leverage information from the different domains. The outcomes of our experiments reveal that the proposed approach achieves superior performance compared to existing state-of-the-art causal models, while preserving a relatively compact model size and low computational complexity.
Two-stage Neural Network for ICASSP 2023 Speech Signal Improvement Challenge
Mar 14, 2023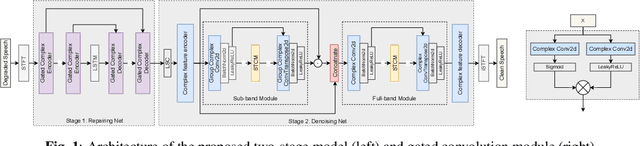
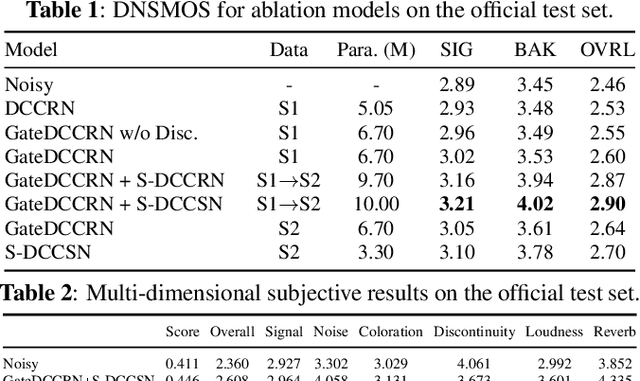
In ICASSP 2023 speech signal improvement challenge, we developed a dual-stage neural model which improves speech signal quality induced by different distortions in a stage-wise divide-and-conquer fashion. Specifically, in the first stage, the speech improvement network focuses on recovering the missing components of the spectrum, while in the second stage, our model aims to further suppress noise, reverberation, and artifacts introduced by the first-stage model. Achieving 0.446 in the final score and 0.517 in the P.835 score, our system ranks 4th in the non-real-time track.
Leveraging Large Text Corpora for End-to-End Speech Summarization
Mar 02, 2023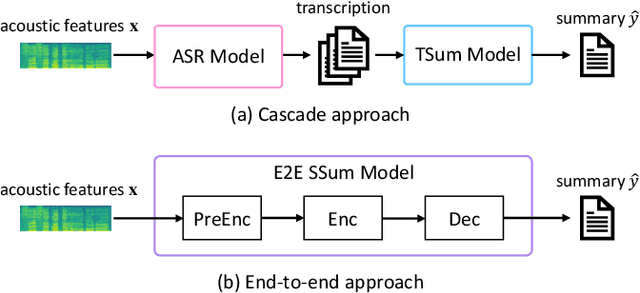

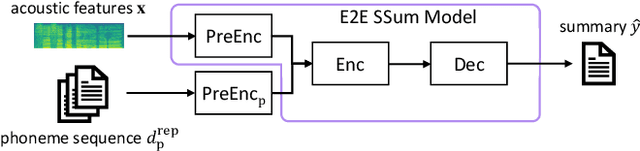

End-to-end speech summarization (E2E SSum) is a technique to directly generate summary sentences from speech. Compared with the cascade approach, which combines automatic speech recognition (ASR) and text summarization models, the E2E approach is more promising because it mitigates ASR errors, incorporates nonverbal information, and simplifies the overall system. However, since collecting a large amount of paired data (i.e., speech and summary) is difficult, the training data is usually insufficient to train a robust E2E SSum system. In this paper, we present two novel methods that leverage a large amount of external text summarization data for E2E SSum training. The first technique is to utilize a text-to-speech (TTS) system to generate synthesized speech, which is used for E2E SSum training with the text summary. The second is a TTS-free method that directly inputs phoneme sequence instead of synthesized speech to the E2E SSum model. Experiments show that our proposed TTS- and phoneme-based methods improve several metrics on the How2 dataset. In particular, our best system outperforms a previous state-of-the-art one by a large margin (i.e., METEOR score improvements of more than 6 points). To the best of our knowledge, this is the first work to use external language resources for E2E SSum. Moreover, we report a detailed analysis of the How2 dataset to confirm the validity of our proposed E2E SSum system.
Front-End Adapter: Adapting Front-End Input of Speech based Self-Supervised Learning for Speech Recognition
Feb 18, 2023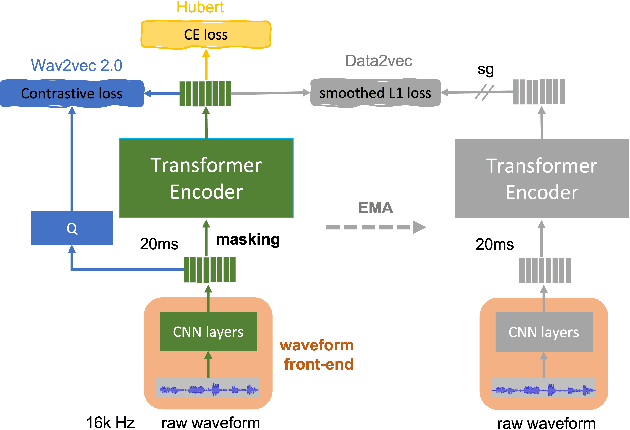
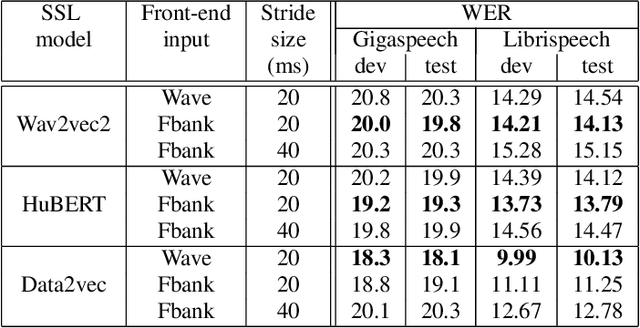
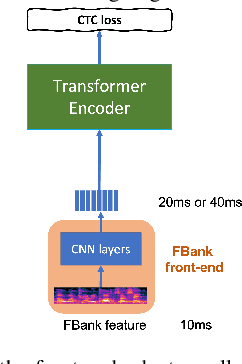
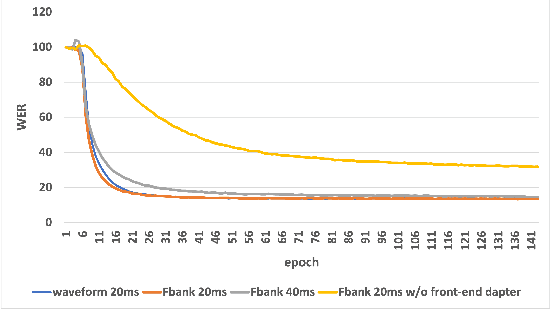
Recent years have witnessed a boom in self-supervised learning (SSL) in various areas including speech processing. Speech based SSL models present promising performance in a range of speech related tasks. However, the training of SSL models is computationally expensive and a common practice is to fine-tune a released SSL model on the specific task. It is essential to use consistent front-end input during pre-training and fine-tuning. This consistency may introduce potential issues when the optimal front-end is not the same as that used in pre-training. In this paper, we propose a simple but effective front-end adapter to address this front-end discrepancy. By minimizing the distance between the outputs of different front-ends, the filterbank feature (Fbank) can be compatible with SSL models which are pre-trained with waveform. The experiment results demonstrate the effectiveness of our proposed front-end adapter on several popular SSL models for the speech recognition task.
SpeechPrompt v2: Prompt Tuning for Speech Classification Tasks
Mar 01, 2023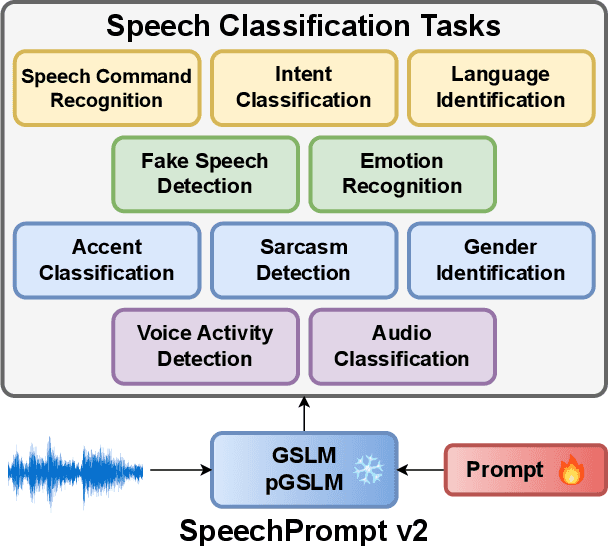
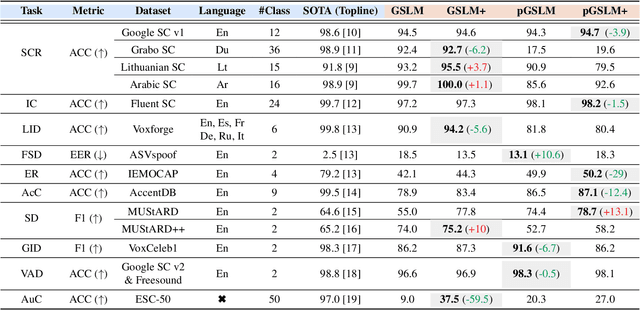
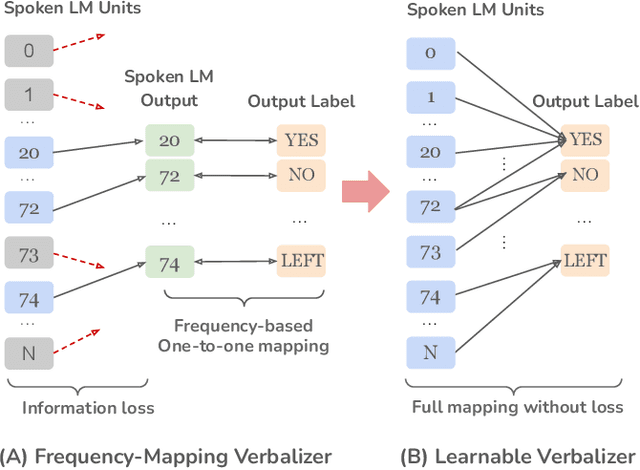
Prompt tuning is a technology that tunes a small set of parameters to steer a pre-trained language model (LM) to directly generate the output for downstream tasks. Recently, prompt tuning has demonstrated its storage and computation efficiency in both natural language processing (NLP) and speech processing fields. These advantages have also revealed prompt tuning as a candidate approach to serving pre-trained LM for multiple tasks in a unified manner. For speech processing, SpeechPrompt shows its high parameter efficiency and competitive performance on a few speech classification tasks. However, whether SpeechPrompt is capable of serving a large number of tasks is unanswered. In this work, we propose SpeechPrompt v2, a prompt tuning framework capable of performing a wide variety of speech classification tasks, covering multiple languages and prosody-related tasks. The experiment result shows that SpeechPrompt v2 achieves performance on par with prior works with less than 0.15M trainable parameters in a unified framework.
MoLE : Mixture of Language Experts for Multi-Lingual Automatic Speech Recognition
Feb 27, 2023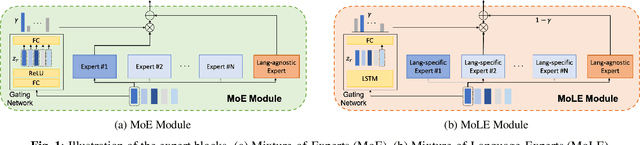
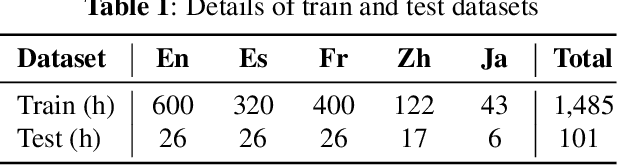
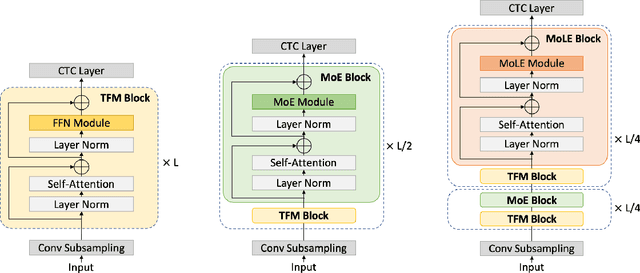
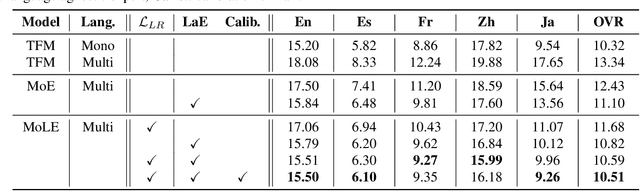
Multi-lingual speech recognition aims to distinguish linguistic expressions in different languages and integrate acoustic processing simultaneously. In contrast, current multi-lingual speech recognition research follows a language-aware paradigm, mainly targeted to improve recognition performance rather than discriminate language characteristics. In this paper, we present a multi-lingual speech recognition network named Mixture-of-Language-Expert(MoLE), which digests speech in a variety of languages. Specifically, MoLE analyzes linguistic expression from input speech in arbitrary languages, activating a language-specific expert with a lightweight language tokenizer. The tokenizer not only activates experts, but also estimates the reliability of the activation. Based on the reliability, the activated expert and the language-agnostic expert are aggregated to represent language-conditioned embedding for efficient speech recognition. Our proposed model is evaluated in 5 languages scenario, and the experimental results show that our structure is advantageous on multi-lingual recognition, especially for speech in low-resource language.