 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR
Mar 29, 2023
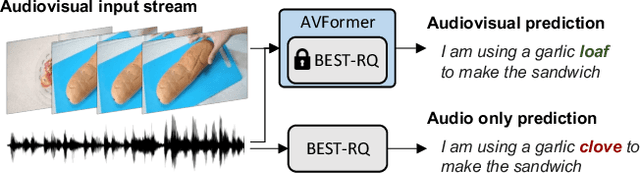
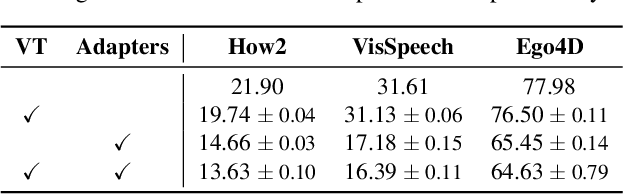
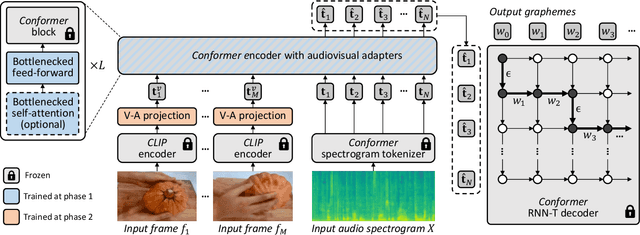

Audiovisual automatic speech recognition (AV-ASR) aims to improve the robustness of a speech recognition system by incorporating visual information. Training fully supervised multimodal models for this task from scratch, however is limited by the need for large labelled audiovisual datasets (in each downstream domain of interest). We present AVFormer, a simple method for augmenting audio-only models with visual information, at the same time performing lightweight domain adaptation. We do this by (i) injecting visual embeddings into a frozen ASR model using lightweight trainable adaptors. We show that these can be trained on a small amount of weakly labelled video data with minimum additional training time and parameters. (ii) We also introduce a simple curriculum scheme during training which we show is crucial to enable the model to jointly process audio and visual information effectively; and finally (iii) we show that our model achieves state of the art zero-shot results on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (LibriSpeech). Qualitative results show that our model effectively leverages visual information for robust speech recognition.
Comparison of Multilingual Self-Supervised and Weakly-Supervised Speech Pre-Training for Adaptation to Unseen Languages
May 21, 2023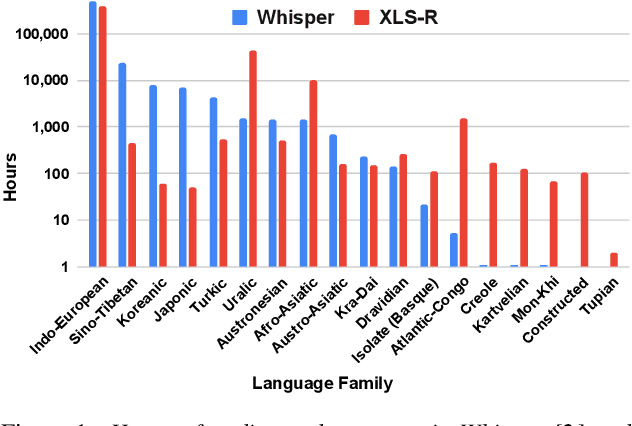
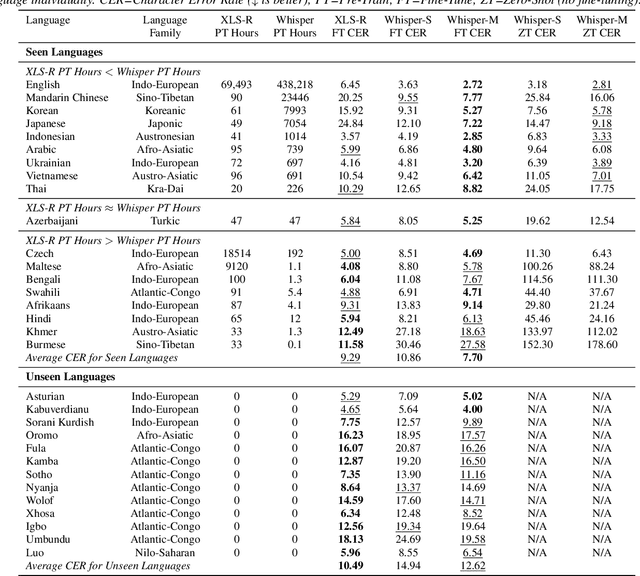
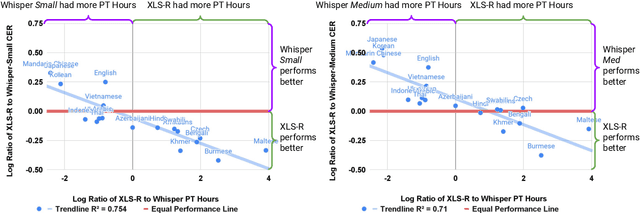
Recent models such as XLS-R and Whisper have made multilingual speech technologies more accessible by pre-training on audio from around 100 spoken languages each. However, there are thousands of spoken languages worldwide, and adapting to new languages is an important problem. In this work, we aim to understand which model adapts better to languages unseen during pre-training. We fine-tune both models on 13 unseen languages and 18 seen languages. Our results show that the number of hours seen per language and language family during pre-training is predictive of how the models compare, despite the significant differences in the pre-training methods.
Cross-lingual Prosody Transfer for Expressive Machine Dubbing
Jun 20, 2023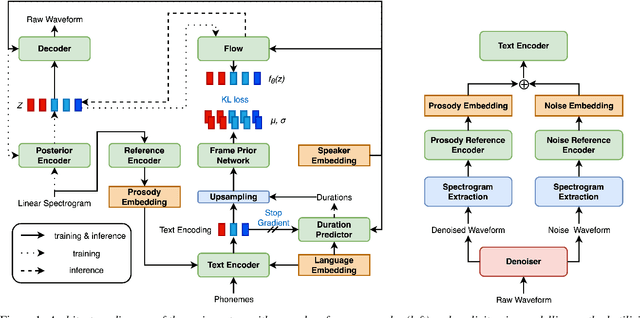
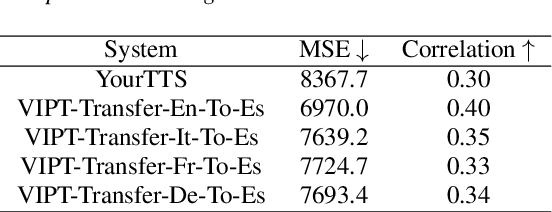
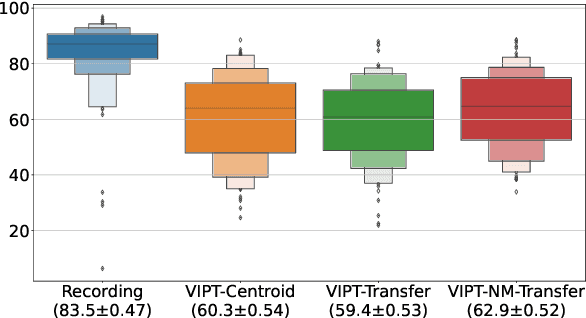
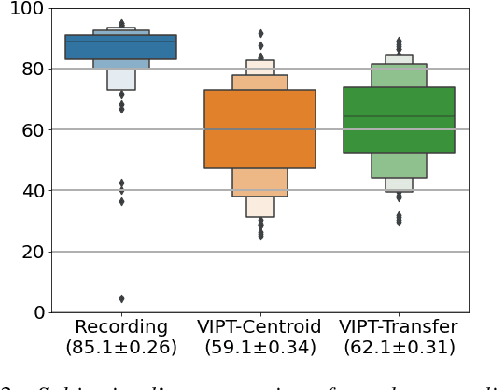
Prosody transfer is well-studied in the context of expressive speech synthesis. Cross-lingual prosody transfer, however, is challenging and has been under-explored to date. In this paper, we present a novel solution to learn prosody representations that are transferable across languages and speakers for machine dubbing of expressive multimedia contents. Multimedia contents often contain field recordings. To enable prosody transfer from noisy audios, we introduce a novel noise modelling module that disentangles noise conditioning from prosody conditioning, and thereby gains independent control of noise levels in the synthesised speech. We augment noisy training data with clean data to improve the ability of the model to map the denoised reference audio to clean speech. Our proposed system can generate speech with context-matching prosody and closes the gap between a strong baseline and human expressive dialogs by 11.2%.
FPGA Resource-aware Structured Pruning for Real-Time Neural Networks
Aug 09, 2023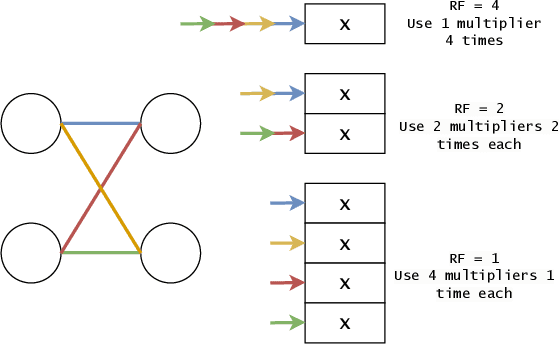
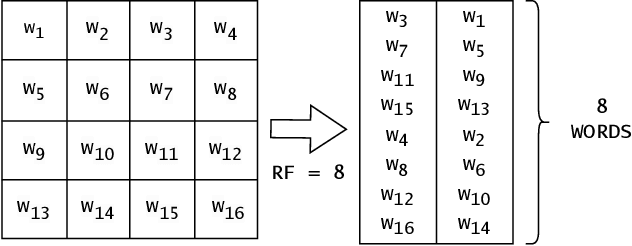
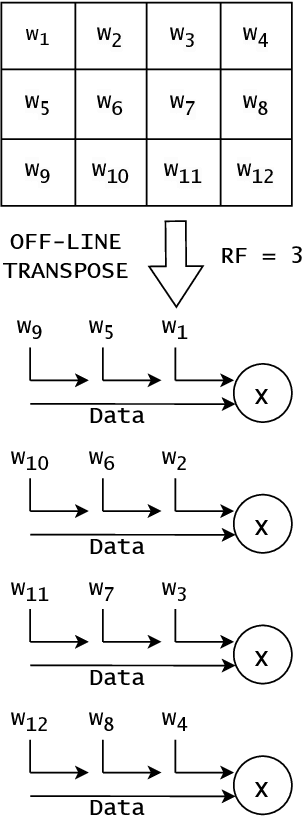
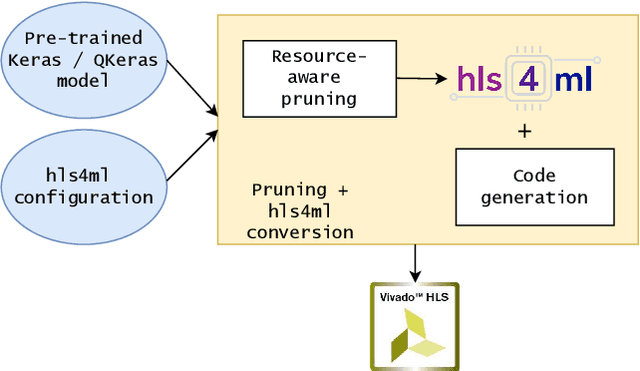
Neural networks achieve state-of-the-art performance in image classification, speech recognition, scientific analysis and many more application areas. With the ever-increasing need for faster computation and lower power consumption, driven by real-time systems and Internet-of-Things (IoT) devices, FPGAs have emerged as suitable devices for deep learning inference. Due to the high computational complexity and memory footprint of neural networks, various compression techniques, such as pruning, quantization and knowledge distillation, have been proposed in literature. Pruning sparsifies a neural network, reducing the number of multiplications and memory. However, pruning often fails to capture properties of the underlying hardware, causing unstructured sparsity and load-balance inefficiency, thus bottlenecking resource improvements. We propose a hardware-centric formulation of pruning, by formulating it as a knapsack problem with resource-aware tensor structures. The primary emphasis is on real-time inference, with latencies in the order of 1$\mu$s, accelerated with hls4ml, an open-source framework for deep learning inference on FPGAs. Evaluated on a range of tasks, including real-time particle classification at CERN's Large Hadron Collider and fast image classification, the proposed method achieves a reduction ranging between 55% and 92% in the utilization of digital signal processing blocks (DSP) and up to 81% in block memory (BRAM) utilization.
Do You Remember? Overcoming Catastrophic Forgetting for Fake Audio Detection
Aug 07, 2023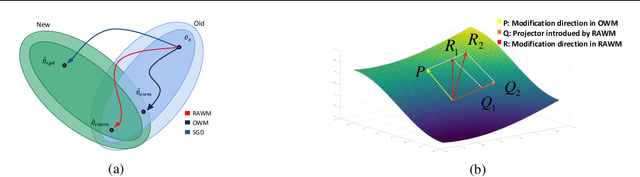

Current fake audio detection algorithms have achieved promising performances on most datasets. However, their performance may be significantly degraded when dealing with audio of a different dataset. The orthogonal weight modification to overcome catastrophic forgetting does not consider the similarity of genuine audio across different datasets. To overcome this limitation, we propose a continual learning algorithm for fake audio detection to overcome catastrophic forgetting, called Regularized Adaptive Weight Modification (RAWM). When fine-tuning a detection network, our approach adaptively computes the direction of weight modification according to the ratio of genuine utterances and fake utterances. The adaptive modification direction ensures the network can effectively detect fake audio on the new dataset while preserving its knowledge of old model, thus mitigating catastrophic forgetting. In addition, genuine audio collected from quite different acoustic conditions may skew their feature distribution, so we introduce a regularization constraint to force the network to remember the old distribution in this regard. Our method can easily be generalized to related fields, like speech emotion recognition. We also evaluate our approach across multiple datasets and obtain a significant performance improvement on cross-dataset experiments.
Expressive Machine Dubbing Through Phrase-level Cross-lingual Prosody Transfer
Jun 21, 2023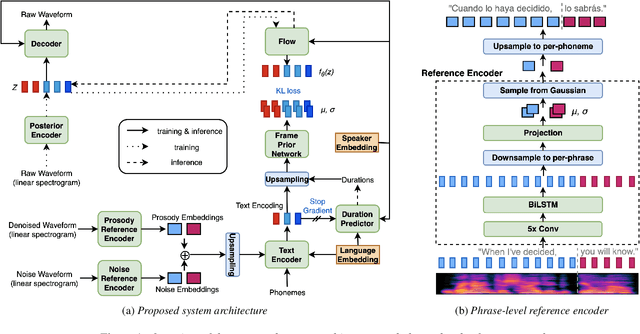
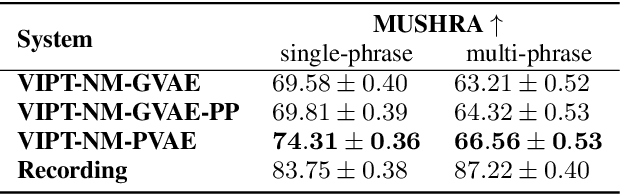
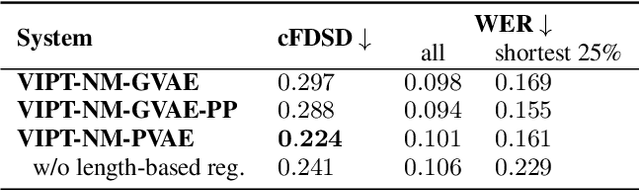
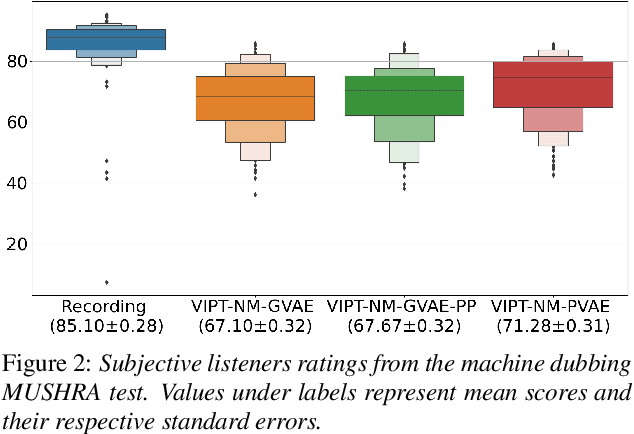
Speech generation for machine dubbing adds complexity to conventional Text-To-Speech solutions as the generated output is required to match the expressiveness, emotion and speaking rate of the source content. Capturing and transferring details and variations in prosody is a challenge. We introduce phrase-level cross-lingual prosody transfer for expressive multi-lingual machine dubbing. The proposed phrase-level prosody transfer delivers a significant 6.2% MUSHRA score increase over a baseline with utterance-level global prosody transfer, thereby closing the gap between the baseline and expressive human dubbing by 23.2%, while preserving intelligibility of the synthesised speech.
Enhancing multilingual speech recognition in air traffic control by sentence-level language identification
Apr 29, 2023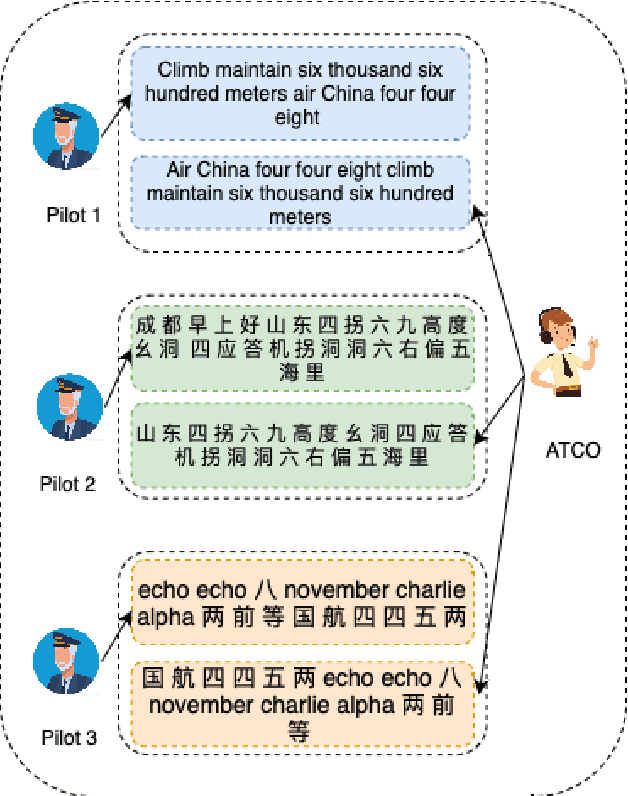
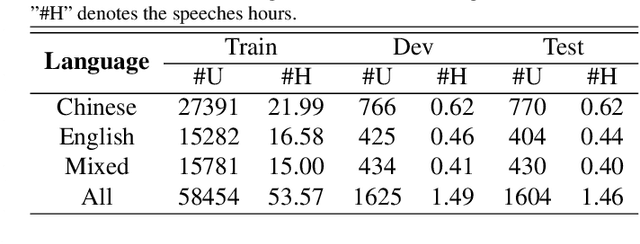
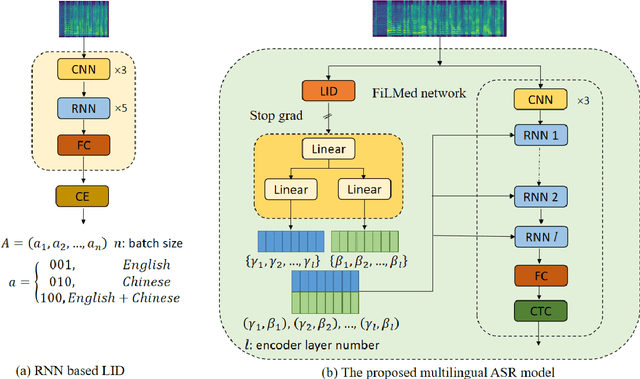
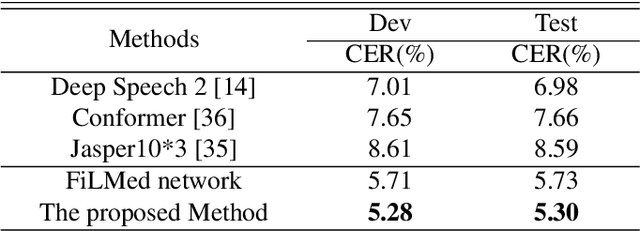
Automatic speech recognition (ASR) technique is becoming increasingly popular to improve the efficiency and safety of air traffic control (ATC) operations. However, the conversation between ATC controllers and pilots using multilingual speech brings a great challenge to building high-accuracy ASR systems. In this work, we present a two-stage multilingual ASR framework. The first stage is to train a language identifier (LID), that based on a recurrent neural network (RNN) to obtain sentence language identification in the form of one-hot encoding. The second stage aims to train an RNN-based end-to-end multilingual recognition model that utilizes sentence language features generated by LID to enhance input features. In this work, We introduce Featurewise Linear Modulation (FiLM) to improve the performance of multilingual ASR by utilizing sentence language identification. Furthermore, we introduce a new sentence language identification learning module called SLIL, which consists of a FiLM layer and a Squeeze-and-Excitation Networks layer. Extensive experiments on the ATCSpeech dataset show that our proposed method outperforms the baseline model. Compared to the vanilla FiLMed backbone model, the proposed multilingual ASR model obtains about 7.50% character error rate relative performance improvement.
Jointly Optimizing Translations and Speech Timing to Improve Isochrony in Automatic Dubbing
Feb 25, 2023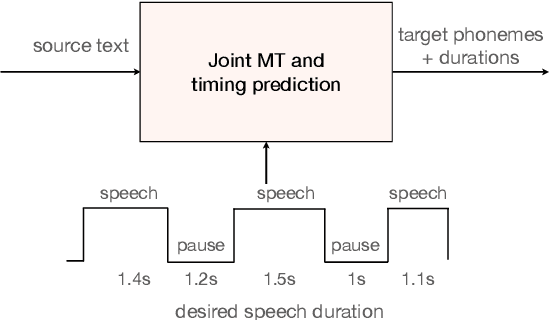
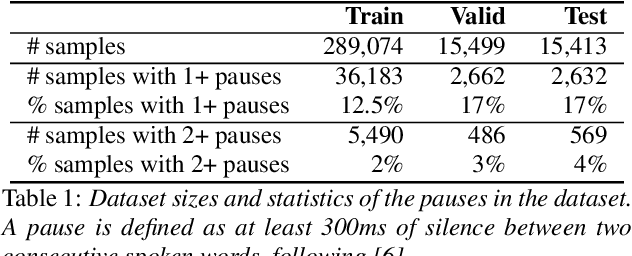
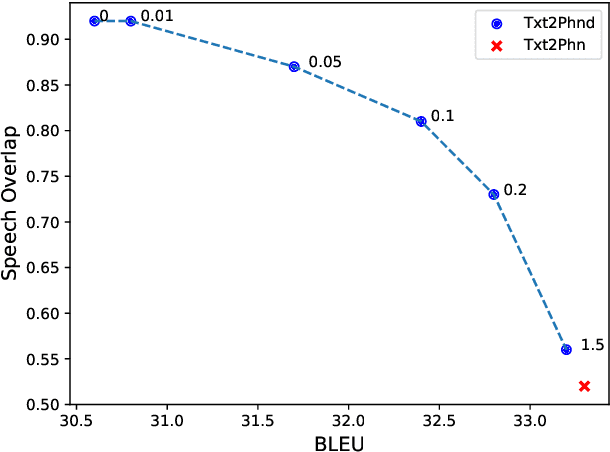
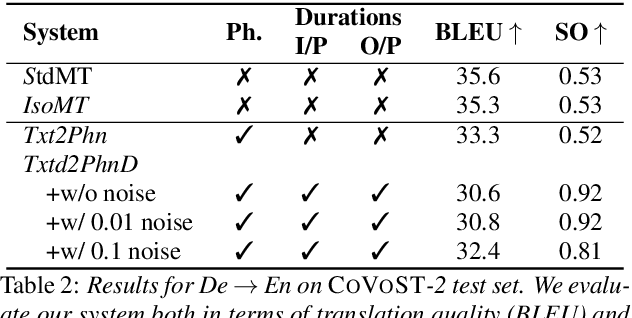
Automatic dubbing (AD) is the task of translating the original speech in a video into target language speech. The new target language speech should satisfy isochrony; that is, the new speech should be time aligned with the original video, including mouth movements, pauses, hand gestures, etc. In this paper, we propose training a model that directly optimizes both the translation as well as the speech duration of the generated translations. We show that this system generates speech that better matches the timing of the original speech, compared to prior work, while simplifying the system architecture.
Learning Robust Self-attention Features for Speech Emotion Recognition with Label-adaptive Mixup
May 07, 2023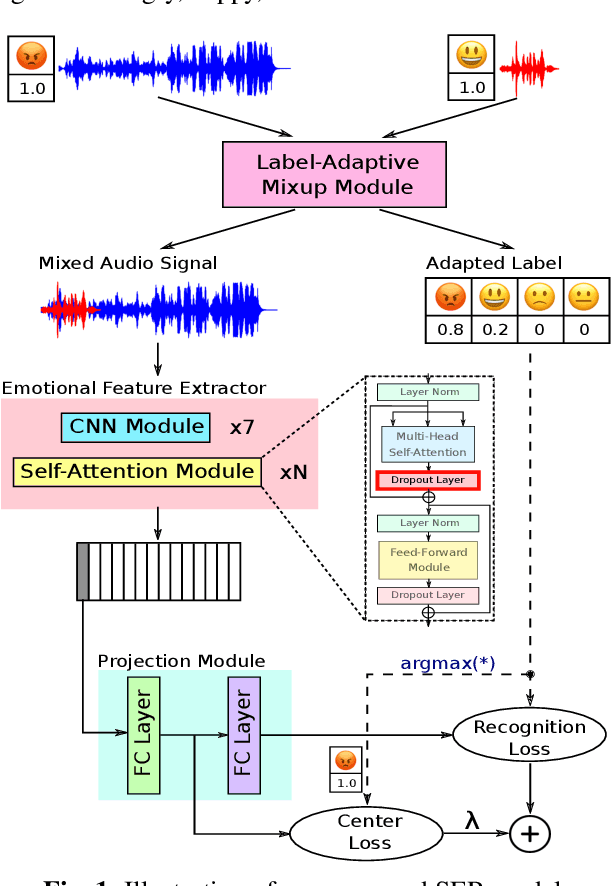
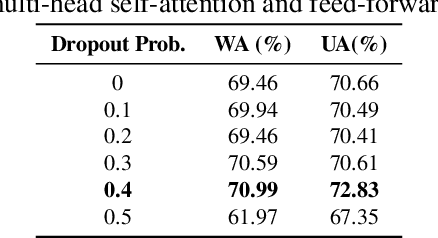
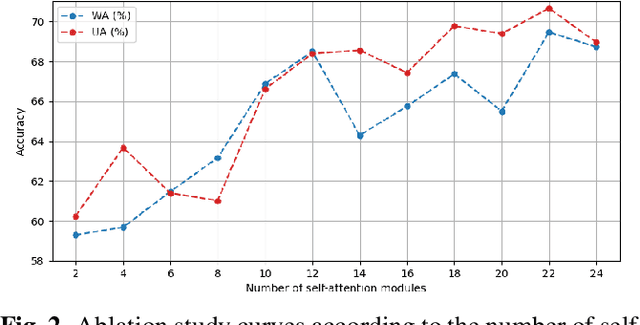

Speech Emotion Recognition (SER) is to recognize human emotions in a natural verbal interaction scenario with machines, which is considered as a challenging problem due to the ambiguous human emotions. Despite the recent progress in SER, state-of-the-art models struggle to achieve a satisfactory performance. We propose a self-attention based method with combined use of label-adaptive mixup and center loss. By adapting label probabilities in mixup and fitting center loss to the mixup training scheme, our proposed method achieves a superior performance to the state-of-the-art methods.
STHG: Spatial-Temporal Heterogeneous Graph Learning for Advanced Audio-Visual Diarization
Jun 18, 2023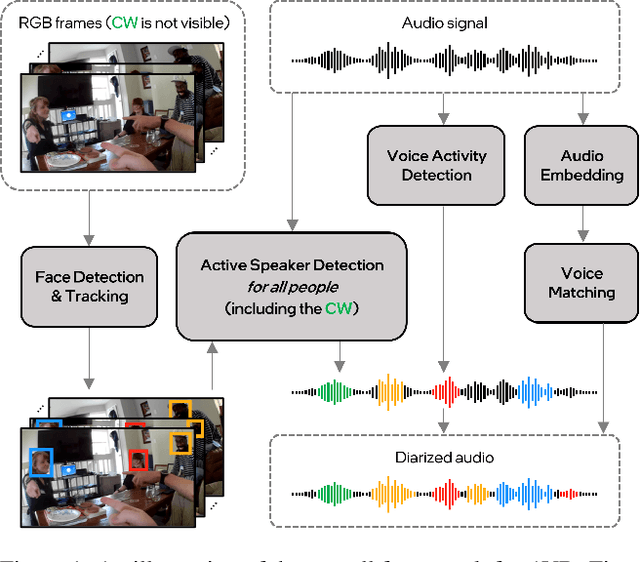
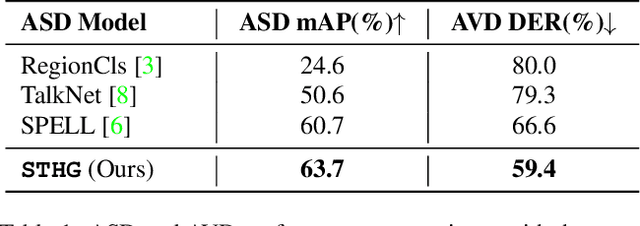
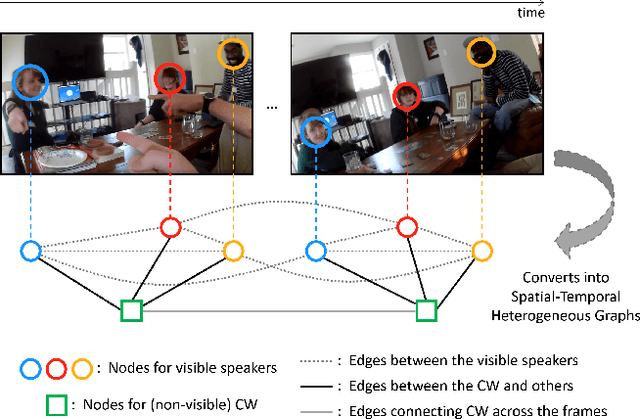
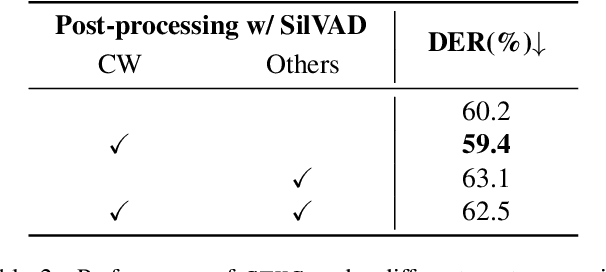
This report introduces our novel method named STHG for the Audio-Visual Diarization task of the Ego4D Challenge 2023. Our key innovation is that we model all the speakers in a video using a single, unified heterogeneous graph learning framework. Unlike previous approaches that require a separate component solely for the camera wearer, STHG can jointly detect the speech activities of all people including the camera wearer. Our final method obtains 61.1% DER on the test set of Ego4D, which significantly outperforms all the baselines as well as last year's winner. Our submission achieved 1st place in the Ego4D Challenge 2023. We additionally demonstrate that applying the off-the-shelf speech recognition system to the diarized speech segments by STHG produces a competitive performance on the Speech Transcription task of this challenge.