 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
DST: Deformable Speech Transformer for Emotion Recognition
Feb 27, 2023
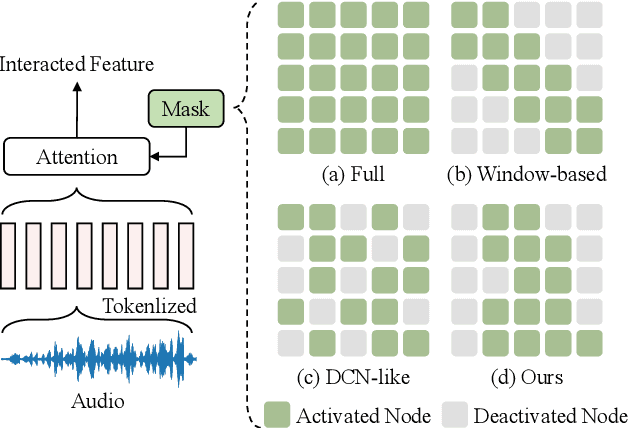
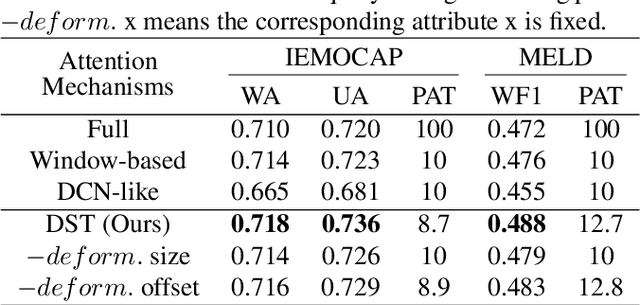
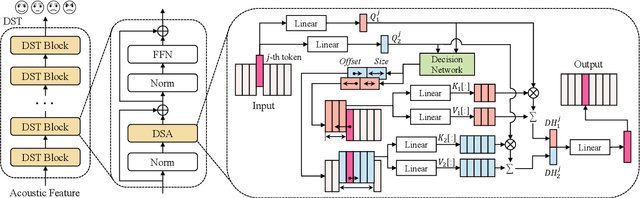
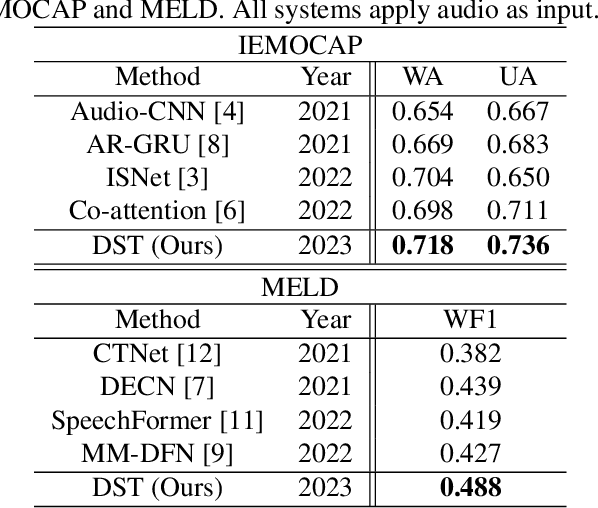
Enabled by multi-head self-attention, Transformer has exhibited remarkable results in speech emotion recognition (SER). Compared to the original full attention mechanism, window-based attention is more effective in learning fine-grained features while greatly reducing model redundancy. However, emotional cues are present in a multi-granularity manner such that the pre-defined fixed window can severely degrade the model flexibility. In addition, it is difficult to obtain the optimal window settings manually. In this paper, we propose a Deformable Speech Transformer, named DST, for SER task. DST determines the usage of window sizes conditioned on input speech via a light-weight decision network. Meanwhile, data-dependent offsets derived from acoustic features are utilized to adjust the positions of the attention windows, allowing DST to adaptively discover and attend to the valuable information embedded in the speech. Extensive experiments on IEMOCAP and MELD demonstrate the superiority of DST.
Developmental Bootstrapping of AIs
Aug 17, 2023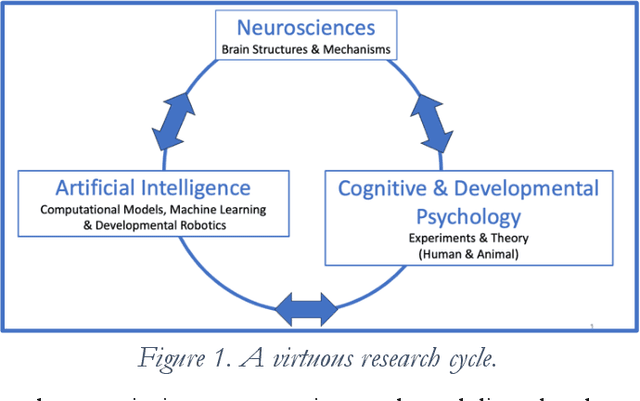

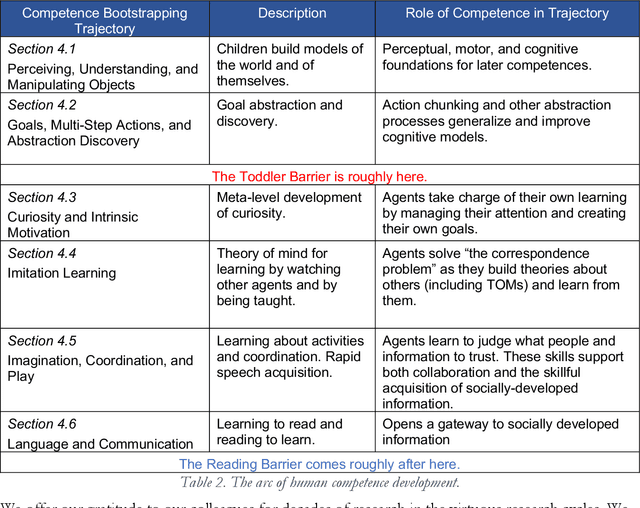
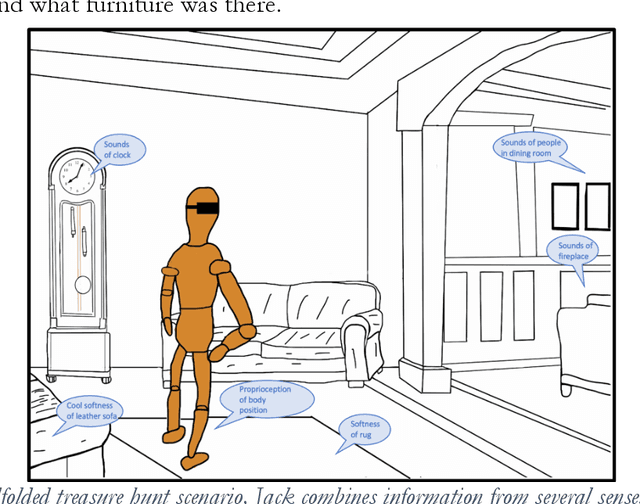
Although some current AIs surpass human abilities in closed artificial worlds such as board games, their abilities in the real world are limited. They make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. They do not make good collaborators. Mainstream approaches for creating AIs are the traditional manually-constructed symbolic AI approach and generative and deep learning AI approaches including large language models (LLMs). These systems are not well suited for creating robust and trustworthy AIs. Although it is outside of the mainstream, the developmental bootstrapping approach has more potential. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. They interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. They acquire the competences they need through bootstrapping. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped at the Toddler Barrier corresponding to human infant development at about two years of age, before their speech is fluent. They also do not bridge the Reading Barrier, to skillfully and skeptically draw on the socially developed information resources that power current LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This position paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to acquire further competences and create robust, resilient, and human-compatible AIs.
Speech Enhancement for Virtual Meetings on Cellular Networks
Feb 16, 2023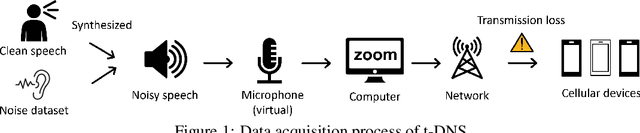
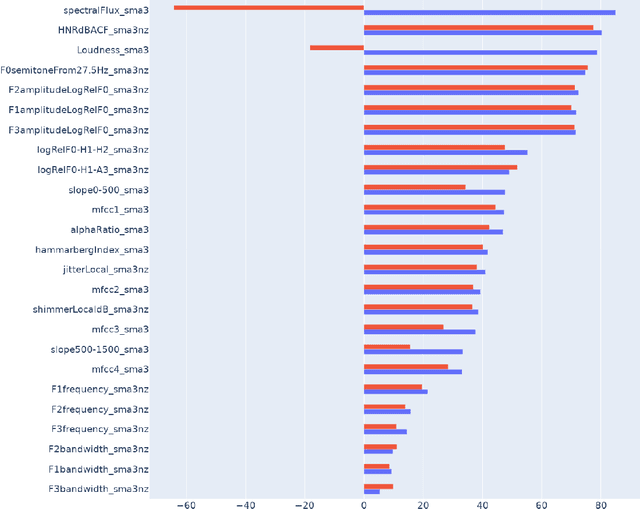
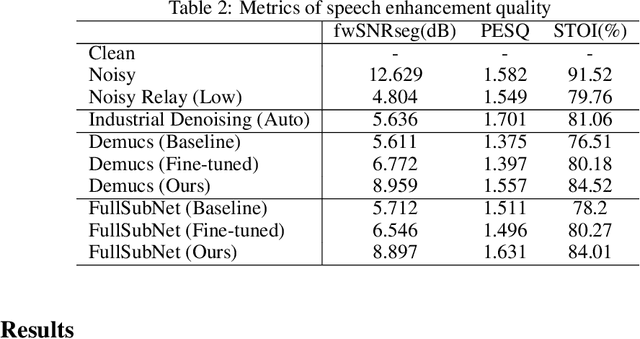
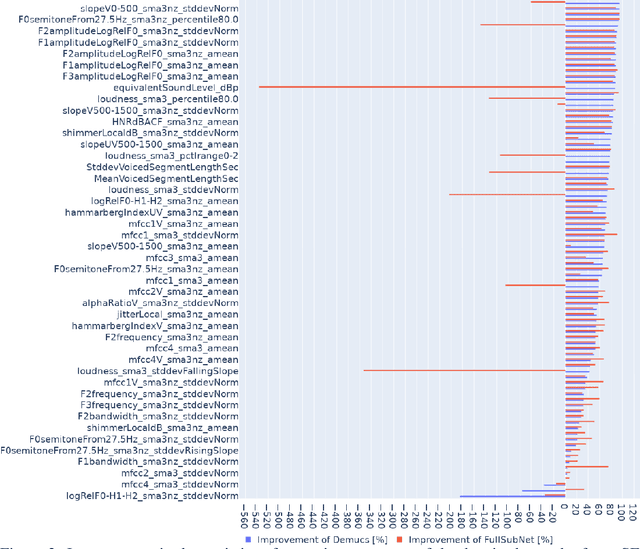
We study speech enhancement using deep learning (DL) for virtual meetings on cellular devices, where transmitted speech has background noise and transmission loss that affects speech quality. Since the Deep Noise Suppression (DNS) Challenge dataset does not contain practical disturbance, we collect a transmitted DNS (t-DNS) dataset using Zoom Meetings over T-Mobile network. We select two baseline models: Demucs and FullSubNet. The Demucs is an end-to-end model that takes time-domain inputs and outputs time-domain denoised speech, and the FullSubNet takes time-frequency-domain inputs and outputs the energy ratio of the target speech in the inputs. The goal of this project is to enhance the speech transmitted over the cellular networks using deep learning models.
Deep Learning-based F0 Synthesis for Speaker Anonymization
Jun 29, 2023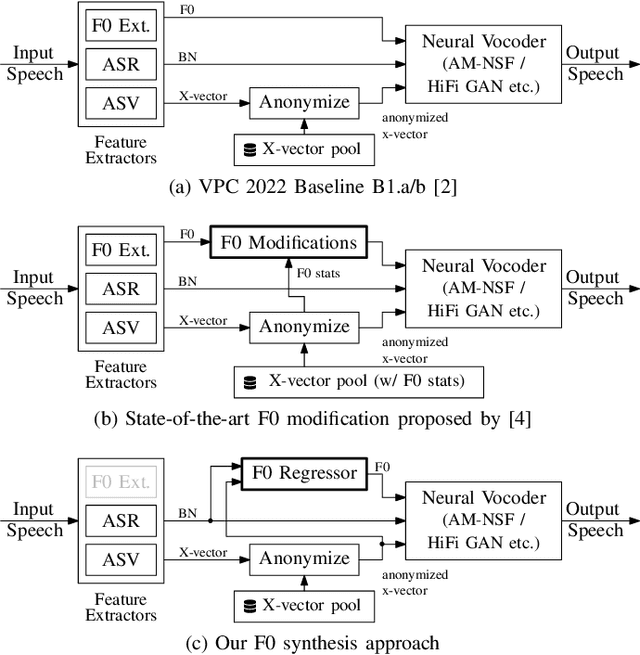
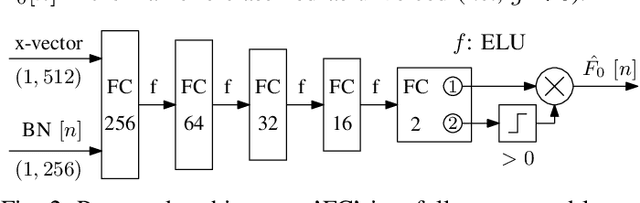
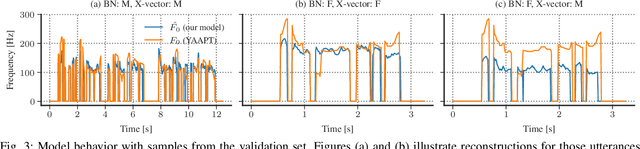
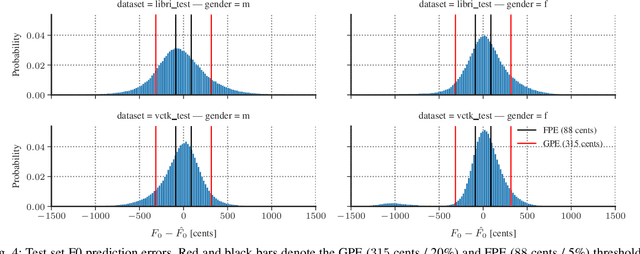
Voice conversion for speaker anonymization is an emerging concept for privacy protection. In a deep learning setting, this is achieved by extracting multiple features from speech, altering the speaker identity, and waveform synthesis. However, many existing systems do not modify fundamental frequency (F0) trajectories, which convey prosody information and can reveal speaker identity. Moreover, mismatch between F0 and other features can degrade speech quality and intelligibility. In this paper, we formally introduce a method that synthesizes F0 trajectories from other speech features and evaluate its reconstructional capabilities. Then we test our approach within a speaker anonymization framework, comparing it to a baseline and a state-of-the-art F0 modification that utilizes speaker information. The results show that our method improves both speaker anonymity, measured by the equal error rate, and utility, measured by the word error rate.
WESPER: Zero-shot and Realtime Whisper to Normal Voice Conversion for Whisper-based Speech Interactions
Mar 03, 2023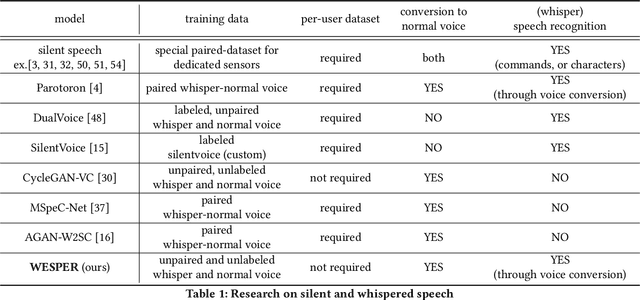
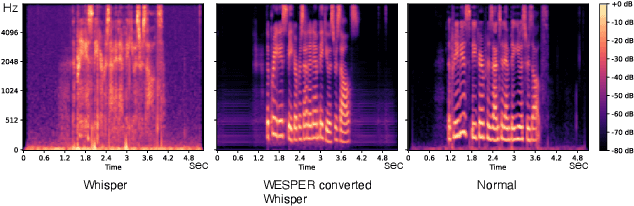

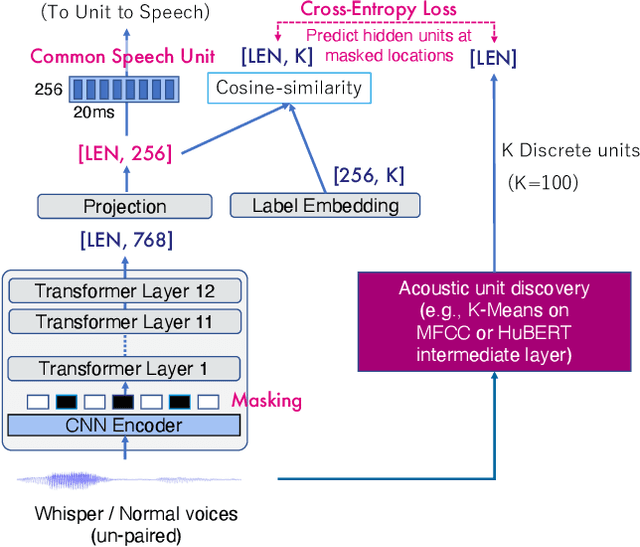
Recognizing whispered speech and converting it to normal speech creates many possibilities for speech interaction. Because the sound pressure of whispered speech is significantly lower than that of normal speech, it can be used as a semi-silent speech interaction in public places without being audible to others. Converting whispers to normal speech also improves the speech quality for people with speech or hearing impairments. However, conventional speech conversion techniques do not provide sufficient conversion quality or require speaker-dependent datasets consisting of pairs of whispered and normal speech utterances. To address these problems, we propose WESPER, a zero-shot, real-time whisper-to-normal speech conversion mechanism based on self-supervised learning. WESPER consists of a speech-to-unit (STU) encoder, which generates hidden speech units common to both whispered and normal speech, and a unit-to-speech (UTS) decoder, which reconstructs speech from the encoded speech units. Unlike the existing methods, this conversion is user-independent and does not require a paired dataset for whispered and normal speech. The UTS decoder can reconstruct speech in any target speaker's voice from speech units, and it requires only an unlabeled target speaker's speech data. We confirmed that the quality of the speech converted from a whisper was improved while preserving its natural prosody. Additionally, we confirmed the effectiveness of the proposed approach to perform speech reconstruction for people with speech or hearing disabilities. (project page: http://lab.rekimoto.org/projects/wesper )
* ACM CHI 2023 paper
GesGPT: Speech Gesture Synthesis With Text Parsing from GPT
Mar 23, 2023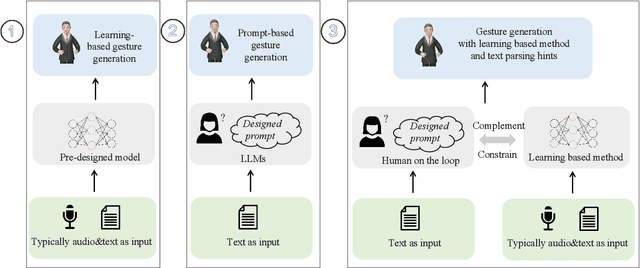
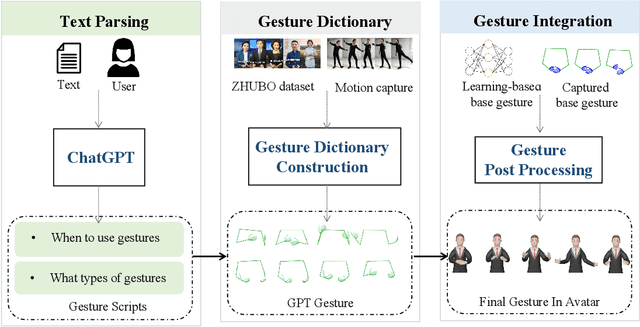
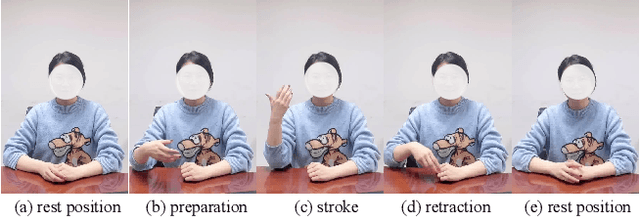
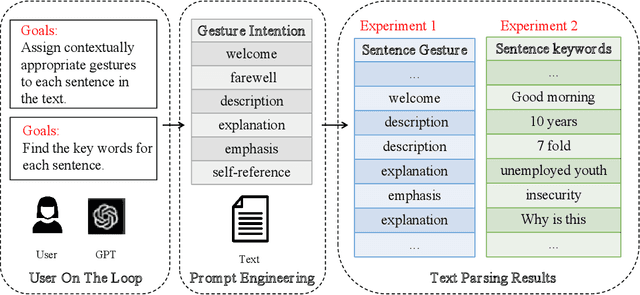
Gesture synthesis has gained significant attention as a critical research area, focusing on producing contextually appropriate and natural gestures corresponding to speech or textual input. Although deep learning-based approaches have achieved remarkable progress, they often overlook the rich semantic information present in the text, leading to less expressive and meaningful gestures. We propose GesGPT, a novel approach to gesture generation that leverages the semantic analysis capabilities of Large Language Models (LLMs), such as GPT. By capitalizing on the strengths of LLMs for text analysis, we design prompts to extract gesture-related information from textual input. Our method entails developing prompt principles that transform gesture generation into an intention classification problem based on GPT, and utilizing a curated gesture library and integration module to produce semantically rich co-speech gestures. Experimental results demonstrate that GesGPT effectively generates contextually appropriate and expressive gestures, offering a new perspective on semantic co-speech gesture generation.
Compensating Removed Frequency Components: Thwarting Voice Spectrum Reduction Attacks
Aug 18, 2023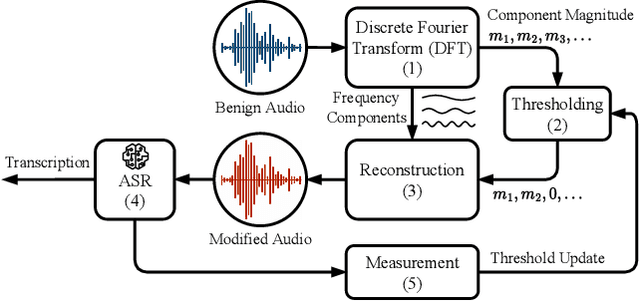
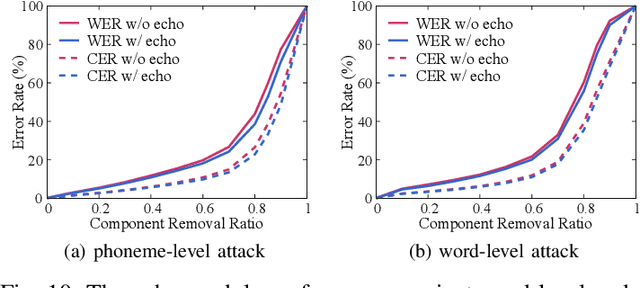
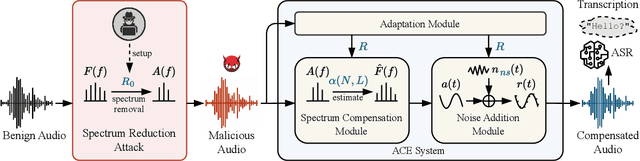
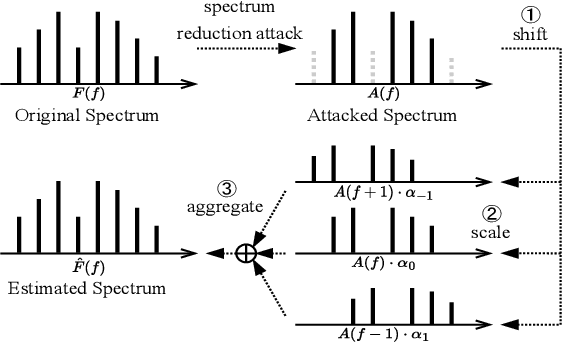
Automatic speech recognition (ASR) provides diverse audio-to-text services for humans to communicate with machines. However, recent research reveals ASR systems are vulnerable to various malicious audio attacks. In particular, by removing the non-essential frequency components, a new spectrum reduction attack can generate adversarial audios that can be perceived by humans but cannot be correctly interpreted by ASR systems. It raises a new challenge for content moderation solutions to detect harmful content in audio and video available on social media platforms. In this paper, we propose an acoustic compensation system named ACE to counter the spectrum reduction attacks over ASR systems. Our system design is based on two observations, namely, frequency component dependencies and perturbation sensitivity. First, since the Discrete Fourier Transform computation inevitably introduces spectral leakage and aliasing effects to the audio frequency spectrum, the frequency components with similar frequencies will have a high correlation. Thus, considering the intrinsic dependencies between neighboring frequency components, it is possible to recover more of the original audio by compensating for the removed components based on the remaining ones. Second, since the removed components in the spectrum reduction attacks can be regarded as an inverse of adversarial noise, the attack success rate will decrease when the adversarial audio is replayed in an over-the-air scenario. Hence, we can model the acoustic propagation process to add over-the-air perturbations into the attacked audio. We implement a prototype of ACE and the experiments show ACE can effectively reduce up to 87.9% of ASR inference errors caused by spectrum reduction attacks. Also, by analyzing residual errors, we summarize six general types of ASR inference errors and investigate the error causes and potential mitigation solutions.
Speaker Diarization of Scripted Audiovisual Content
Aug 04, 2023The media localization industry usually requires a verbatim script of the final film or TV production in order to create subtitles or dubbing scripts in a foreign language. In particular, the verbatim script (i.e. as-broadcast script) must be structured into a sequence of dialogue lines each including time codes, speaker name and transcript. Current speech recognition technology alleviates the transcription step. However, state-of-the-art speaker diarization models still fall short on TV shows for two main reasons: (i) their inability to track a large number of speakers, (ii) their low accuracy in detecting frequent speaker changes. To mitigate this problem, we present a novel approach to leverage production scripts used during the shooting process, to extract pseudo-labeled data for the speaker diarization task. We propose a novel semi-supervised approach and demonstrate improvements of 51.7% relative to two unsupervised baseline models on our metrics on a 66 show test set.
A Critical Review of Physics-Informed Machine Learning Applications in Subsurface Energy Systems
Aug 06, 2023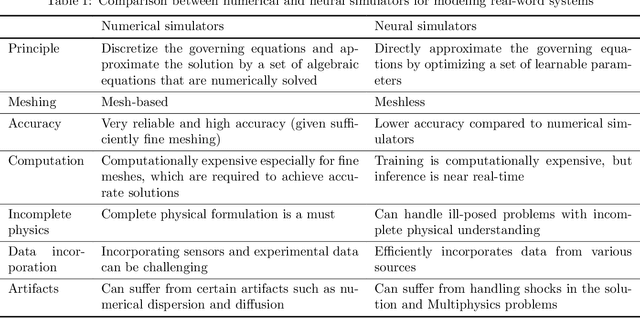
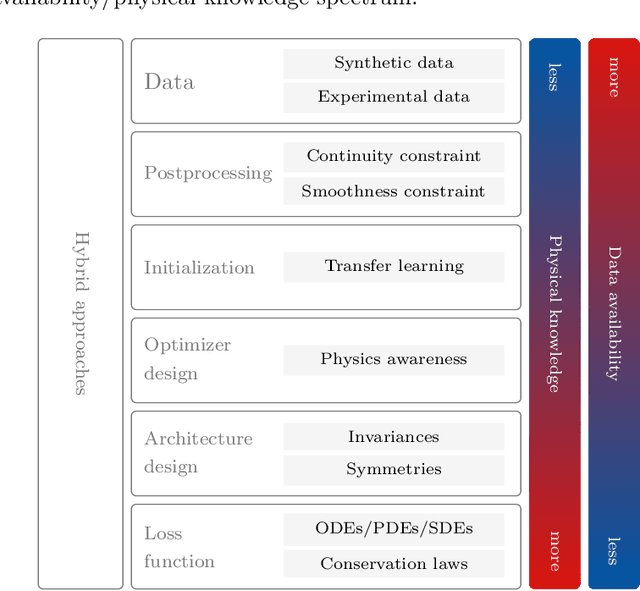
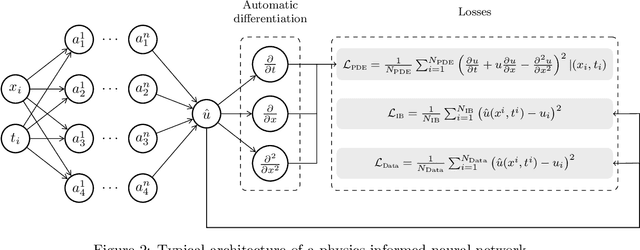
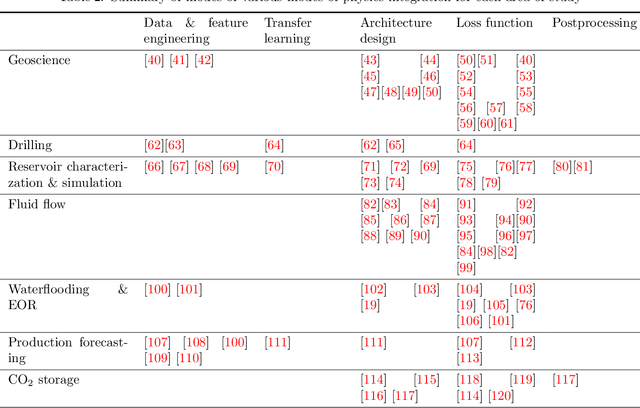
Machine learning has emerged as a powerful tool in various fields, including computer vision, natural language processing, and speech recognition. It can unravel hidden patterns within large data sets and reveal unparalleled insights, revolutionizing many industries and disciplines. However, machine and deep learning models lack interpretability and limited domain-specific knowledge, especially in applications such as physics and engineering. Alternatively, physics-informed machine learning (PIML) techniques integrate physics principles into data-driven models. By combining deep learning with domain knowledge, PIML improves the generalization of the model, abidance by the governing physical laws, and interpretability. This paper comprehensively reviews PIML applications related to subsurface energy systems, mainly in the oil and gas industry. The review highlights the successful utilization of PIML for tasks such as seismic applications, reservoir simulation, hydrocarbons production forecasting, and intelligent decision-making in the exploration and production stages. Additionally, it demonstrates PIML's capabilities to revolutionize the oil and gas industry and other emerging areas of interest, such as carbon and hydrogen storage; and geothermal systems by providing more accurate and reliable predictions for resource management and operational efficiency.
Model-Agnostic Meta-Learning for Multilingual Hate Speech Detection
Mar 04, 2023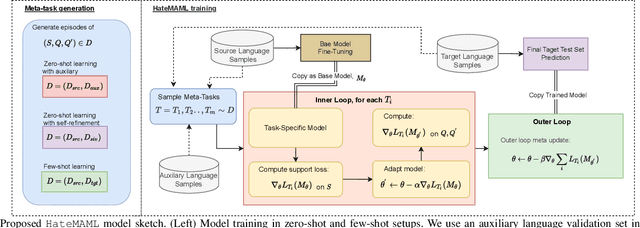


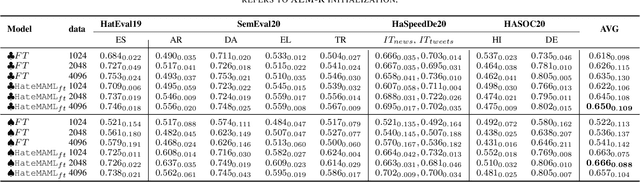
Hate speech in social media is a growing phenomenon, and detecting such toxic content has recently gained significant traction in the research community. Existing studies have explored fine-tuning language models (LMs) to perform hate speech detection, and these solutions have yielded significant performance. However, most of these studies are limited to detecting hate speech only in English, neglecting the bulk of hateful content that is generated in other languages, particularly in low-resource languages. Developing a classifier that captures hate speech and nuances in a low-resource language with limited data is extremely challenging. To fill the research gap, we propose HateMAML, a model-agnostic meta-learning-based framework that effectively performs hate speech detection in low-resource languages. HateMAML utilizes a self-supervision strategy to overcome the limitation of data scarcity and produces better LM initialization for fast adaptation to an unseen target language (i.e., cross-lingual transfer) or other hate speech datasets (i.e., domain generalization). Extensive experiments are conducted on five datasets across eight different low-resource languages. The results show that HateMAML outperforms the state-of-the-art baselines by more than 3% in the cross-domain multilingual transfer setting. We also conduct ablation studies to analyze the characteristics of HateMAML.