 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unifying Speech Enhancement and Separation with Gradient Modulation for End-to-End Noise-Robust Speech Separation
Feb 22, 2023

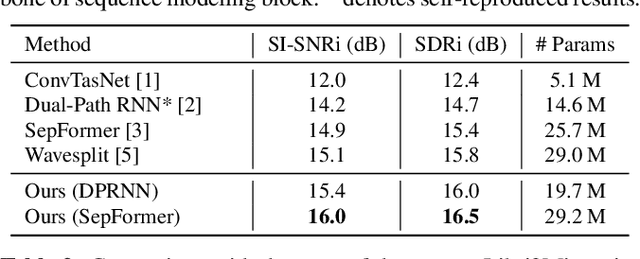
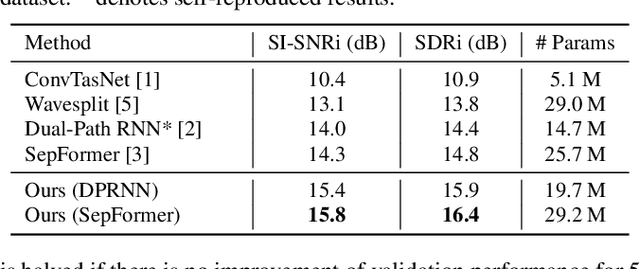
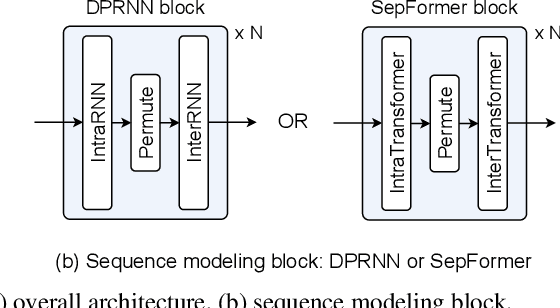
Recent studies in neural network-based monaural speech separation (SS) have achieved a remarkable success thanks to increasing ability of long sequence modeling. However, they would degrade significantly when put under realistic noisy conditions, as the background noise could be mistaken for speaker's speech and thus interfere with the separated sources. To alleviate this problem, we propose a novel network to unify speech enhancement and separation with gradient modulation to improve noise-robustness. Specifically, we first build a unified network by combining speech enhancement (SE) and separation modules, with multi-task learning for optimization, where SE is supervised by parallel clean mixture to reduce noise for downstream speech separation. Furthermore, in order to avoid suppressing valid speaker information when reducing noise, we propose a gradient modulation (GM) strategy to harmonize the SE and SS tasks from optimization view. Experimental results show that our approach achieves the state-of-the-art on large-scale Libri2Mix- and Libri3Mix-noisy datasets, with SI-SNRi results of 16.0 dB and 15.8 dB respectively. Our code is available at GitHub.
Reprogramming Audio-driven Talking Face Synthesis into Text-driven
Jun 28, 2023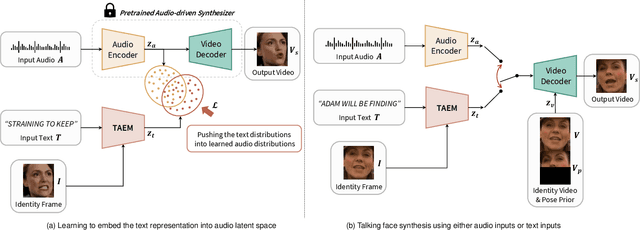
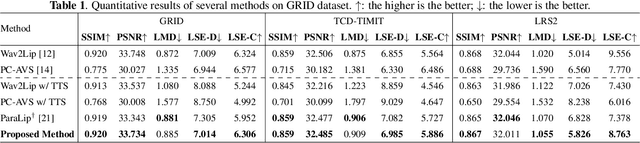
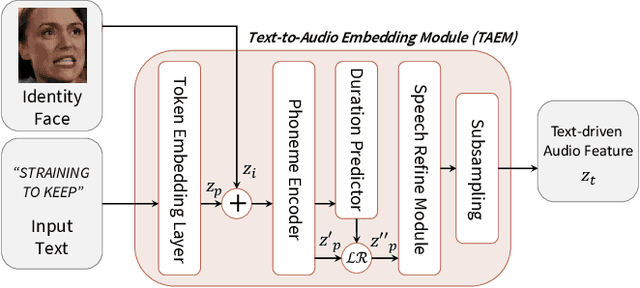
In this paper, we propose a method to reprogram pre-trained audio-driven talking face synthesis models to be able to operate with text inputs. As the audio-driven talking face synthesis model takes speech audio as inputs, in order to generate a talking avatar with the desired speech content, speech recording needs to be performed in advance. However, this is burdensome to record audio for every video to be generated. In order to alleviate this problem, we propose a novel method that embeds input text into the learned audio latent space of the pre-trained audio-driven model. To this end, we design a Text-to-Audio Embedding Module (TAEM) which is guided to learn to map a given text input to the audio latent features. Moreover, to model the speaker characteristics lying in the audio features, we propose to inject visual speaker embedding into the TAEM, which is obtained from a single face image. After training, we can synthesize talking face videos with either text or speech audio.
A Multi-dimensional Deep Structured State Space Approach to Speech Enhancement Using Small-footprint Models
Jun 01, 2023
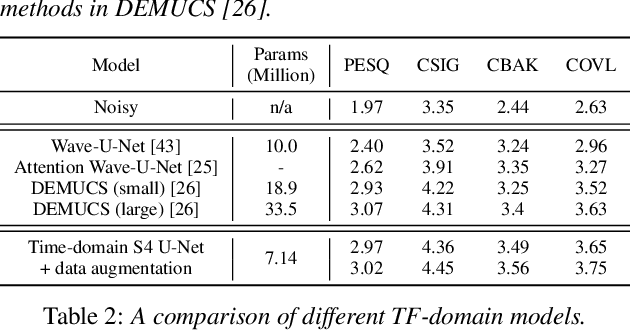
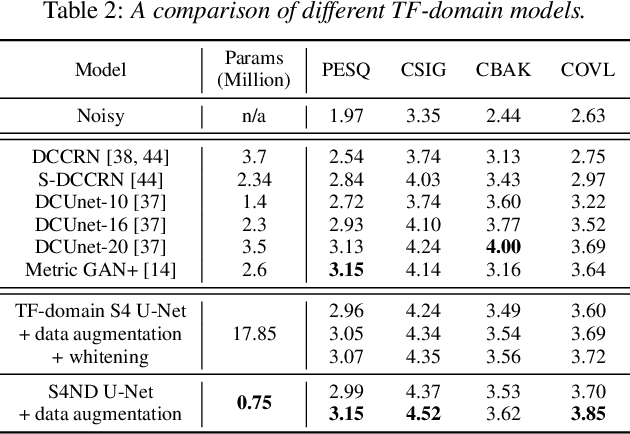
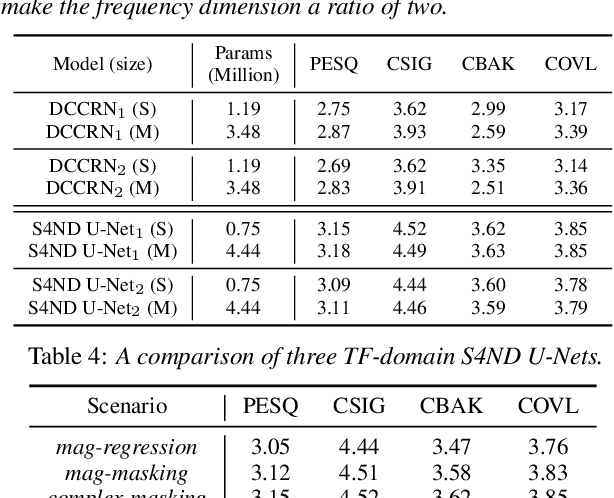
We propose a multi-dimensional structured state space (S4) approach to speech enhancement. To better capture the spectral dependencies across the frequency axis, we focus on modifying the multi-dimensional S4 layer with whitening transformation to build new small-footprint models that also achieve good performance. We explore several S4-based deep architectures in time (T) and time-frequency (TF) domains. The 2-D S4 layer can be considered a particular convolutional layer with an infinite receptive field although it utilizes fewer parameters than a conventional convolutional layer. Evaluated on the VoiceBank-DEMAND data set, when compared with the conventional U-net model based on convolutional layers, the proposed TF-domain S4-based model is 78.6% smaller in size, yet it still achieves competitive results with a PESQ score of 3.15 with data augmentation. By increasing the model size, we can even reach a PESQ score of 3.18.
Cross-Attribute Matrix Factorization Model with Shared User Embedding
Aug 14, 2023
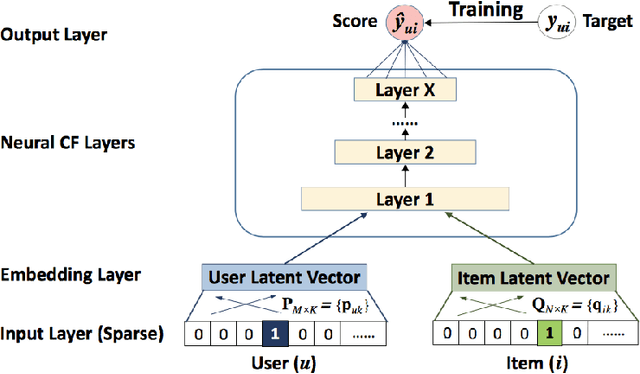
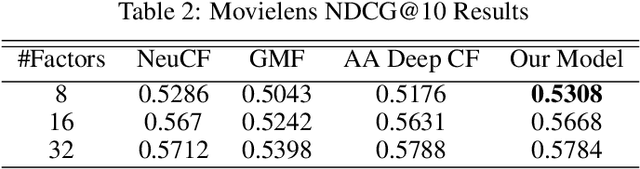
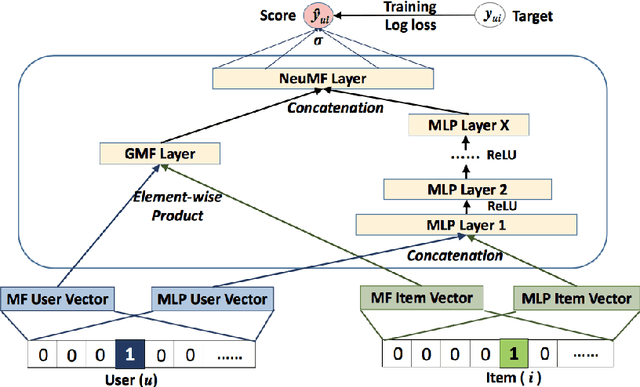
Over the past few years, deep learning has firmly established its prowess across various domains, including computer vision, speech recognition, and natural language processing. Motivated by its outstanding success, researchers have been directing their efforts towards applying deep learning techniques to recommender systems. Neural collaborative filtering (NCF) and Neural Matrix Factorization (NeuMF) refreshes the traditional inner product in matrix factorization with a neural architecture capable of learning complex and data-driven functions. While these models effectively capture user-item interactions, they overlook the specific attributes of both users and items. This can lead to robustness issues, especially for items and users that belong to the "long tail". Such challenges are commonly recognized in recommender systems as a part of the cold-start problem. A direct and intuitive approach to address this issue is by leveraging the features and attributes of the items and users themselves. In this paper, we introduce a refined NeuMF model that considers not only the interaction between users and items, but also acrossing associated attributes. Moreover, our proposed architecture features a shared user embedding, seamlessly integrating with user embeddings to imporve the robustness and effectively address the cold-start problem. Rigorous experiments on both the Movielens and Pinterest datasets demonstrate the superiority of our Cross-Attribute Matrix Factorization model, particularly in scenarios characterized by higher dataset sparsity.
Acoustic absement in detail: Quantifying acoustic differences across time-series representations of speech data
Apr 14, 2023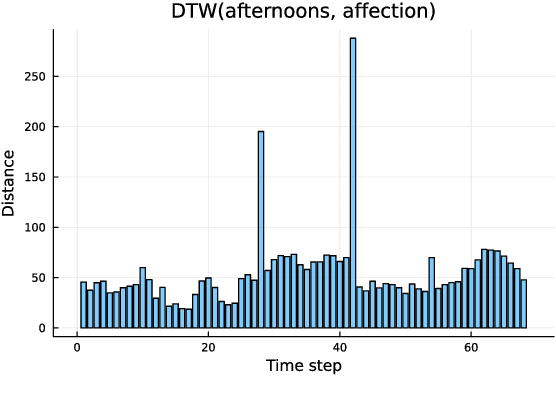
The speech signal is a consummate example of time-series data. The acoustics of the signal change over time, sometimes dramatically. Yet, the most common type of comparison we perform in phonetics is between instantaneous acoustic measurements, such as formant values. In the present paper, I discuss the concept of absement as a quantification of differences between two time-series. I then provide an experimental example of absement applied to phonetic analysis for human and/or computer speech recognition. The experiment is a template-based speech recognition task, using dynamic time warping to compare the acoustics between recordings of isolated words. A recognition accuracy of 57.9% was achieved. The results of the experiment are discussed in terms of using absement as a tool, as well as the implications of using acoustics-only models of spoken word recognition with the word as the smallest discrete linguistic unit.
ClArTTS: An Open-Source Classical Arabic Text-to-Speech Corpus
Feb 28, 2023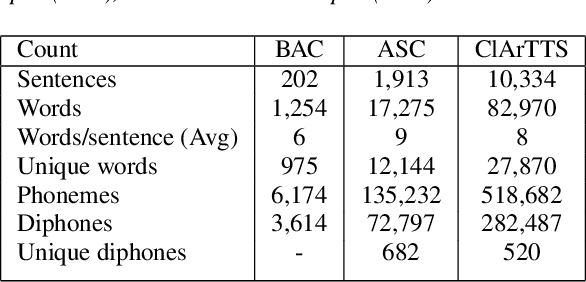
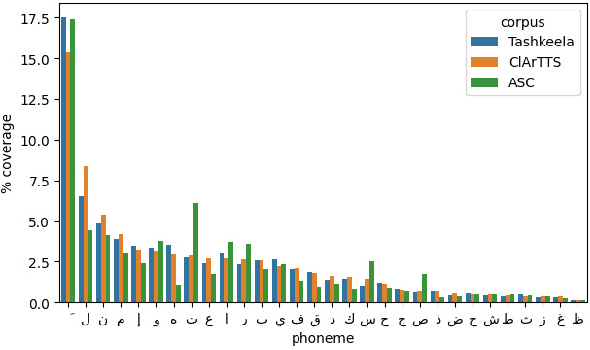
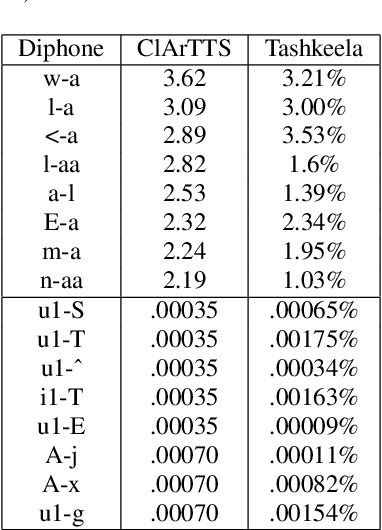
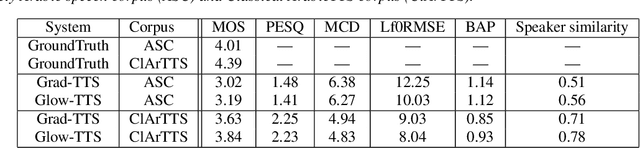
At present, Text-to-speech (TTS) systems that are trained with high-quality transcribed speech data using end-to-end neural models can generate speech that is intelligible, natural, and closely resembles human speech. These models are trained with relatively large single-speaker professionally recorded audio, typically extracted from audiobooks. Meanwhile, due to the scarcity of freely available speech corpora of this kind, a larger gap exists in Arabic TTS research and development. Most of the existing freely available Arabic speech corpora are not suitable for TTS training as they contain multi-speaker casual speech with variations in recording conditions and quality, whereas the corpus curated for speech synthesis are generally small in size and not suitable for training state-of-the-art end-to-end models. In a move towards filling this gap in resources, we present a speech corpus for Classical Arabic Text-to-Speech (ClArTTS) to support the development of end-to-end TTS systems for Arabic. The speech is extracted from a LibriVox audiobook, which is then processed, segmented, and manually transcribed and annotated. The final ClArTTS corpus contains about 12 hours of speech from a single male speaker sampled at 40100 kHz. In this paper, we describe the process of corpus creation and provide details of corpus statistics and a comparison with existing resources. Furthermore, we develop two TTS systems based on Grad-TTS and Glow-TTS and illustrate the performance of the resulting systems via subjective and objective evaluations. The corpus will be made publicly available at www.clartts.com for research purposes, along with the baseline TTS systems demo.
SynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Apr 03, 2023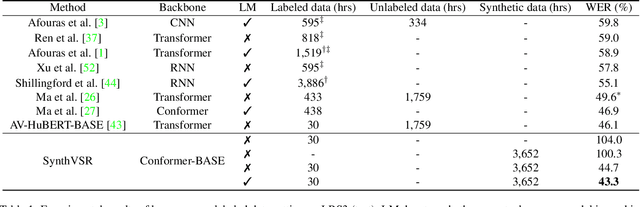
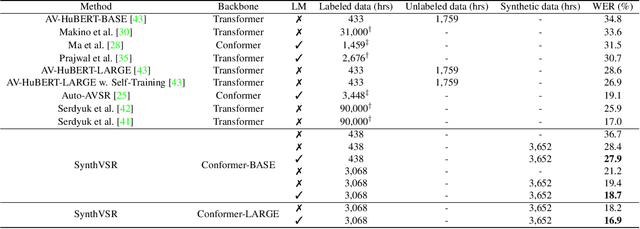

Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.
Improving Frame-level Classifier for Word Timings with Non-peaky CTC in End-to-End Automatic Speech Recognition
Jun 09, 2023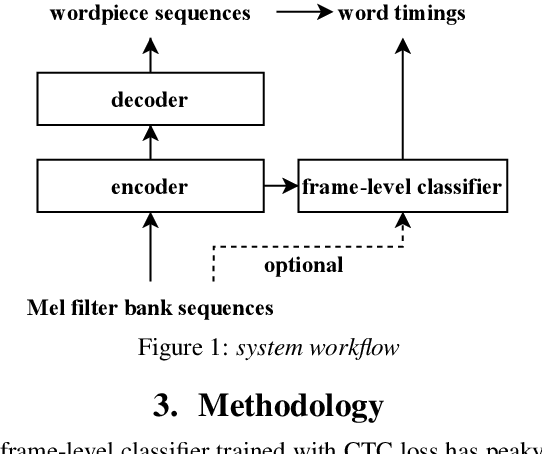
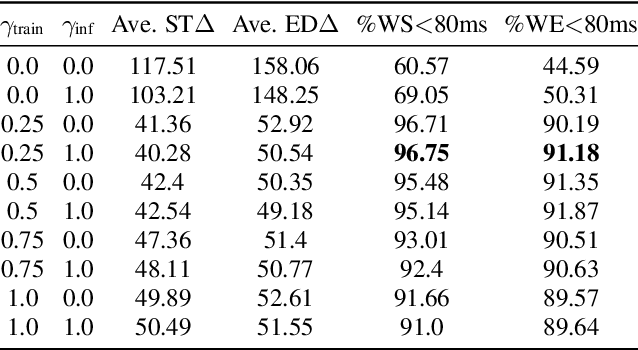
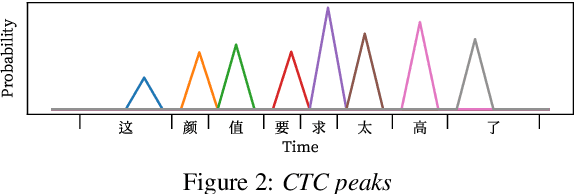
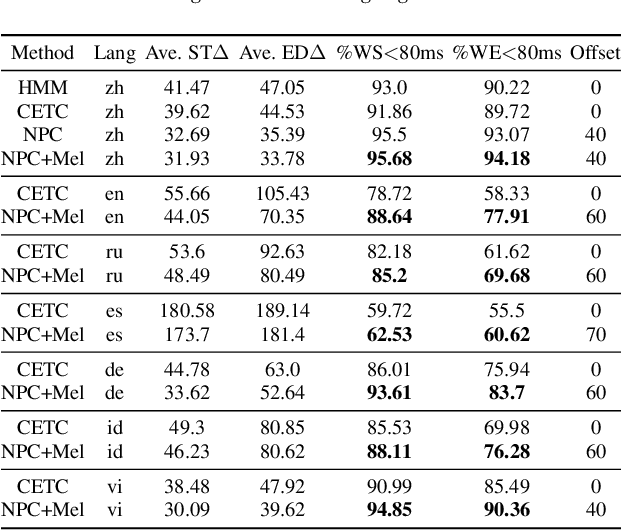
End-to-end (E2E) systems have shown comparable performance to hybrid systems for automatic speech recognition (ASR). Word timings, as a by-product of ASR, are essential in many applications, especially for subtitling and computer-aided pronunciation training. In this paper, we improve the frame-level classifier for word timings in E2E system by introducing label priors in connectionist temporal classification (CTC) loss, which is adopted from prior works, and combining low-level Mel-scale filter banks with high-level ASR encoder output as input feature. On the internal Chinese corpus, the proposed method achieves 95.68%/94.18% compared to the hybrid system 93.0%/90.22% on the word timing accuracy metrics. It also surpass a previous E2E approach with an absolute increase of 4.80%/8.02% on the metrics on 7 languages. In addition, we further improve word timing accuracy by delaying CTC peaks with frame-wise knowledge distillation, though only experimenting on LibriSpeech.
LAST: Scalable Lattice-Based Speech Modelling in JAX
Apr 25, 2023
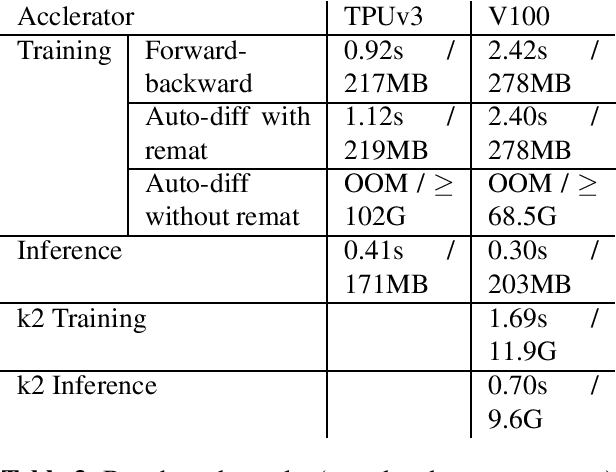
We introduce LAST, a LAttice-based Speech Transducer library in JAX. With an emphasis on flexibility, ease-of-use, and scalability, LAST implements differentiable weighted finite state automaton (WFSA) algorithms needed for training \& inference that scale to a large WFSA such as a recognition lattice over the entire utterance. Despite these WFSA algorithms being well-known in the literature, new challenges arise from performance characteristics of modern architectures, and from nuances in automatic differentiation. We describe a suite of generally applicable techniques employed in LAST to address these challenges, and demonstrate their effectiveness with benchmarks on TPUv3 and V100 GPU.
Point to the Hidden: Exposing Speech Audio Splicing via Signal Pointer Nets
Aug 02, 2023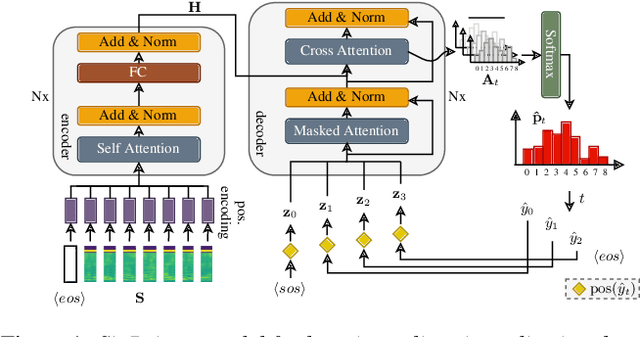
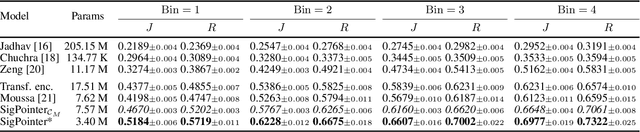
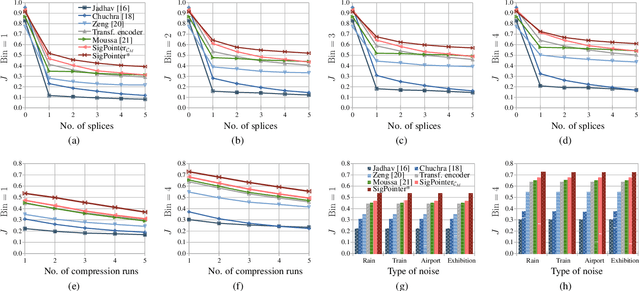
Verifying the integrity of voice recording evidence for criminal investigations is an integral part of an audio forensic analyst's work. Here, one focus is on detecting deletion or insertion operations, so called audio splicing. While this is a rather easy approach to alter spoken statements, careful editing can yield quite convincing results. For difficult cases or big amounts of data, automated tools can support in detecting potential editing locations. To this end, several analytical and deep learning methods have been proposed by now. Still, few address unconstrained splicing scenarios as expected in practice. With SigPointer, we propose a pointer network framework for continuous input that uncovers splice locations naturally and more efficiently than existing works. Extensive experiments on forensically challenging data like strongly compressed and noisy signals quantify the benefit of the pointer mechanism with performance increases between about 6 to 10 percentage points.