 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
IANS: Intelligibility-aware Null-steering Beamforming for Dual-Microphone Arrays
Jul 09, 2023
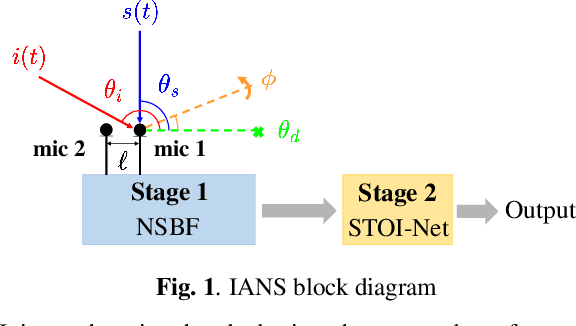
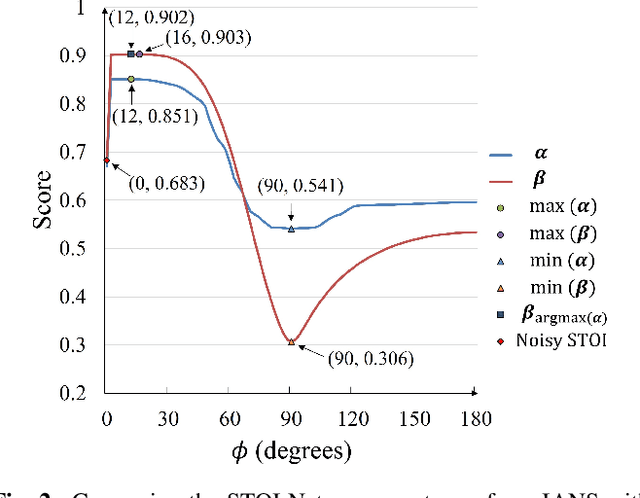
Beamforming techniques are popular in speech-related applications due to their effective spatial filtering capabilities. Nonetheless, conventional beamforming techniques generally depend heavily on either the target's direction-of-arrival (DOA), relative transfer function (RTF) or covariance matrix. This paper presents a new approach, the intelligibility-aware null-steering (IANS) beamforming framework, which uses the STOI-Net intelligibility prediction model to improve speech intelligibility without prior knowledge of the speech signal parameters mentioned earlier. The IANS framework combines a null-steering beamformer (NSBF) to generate a set of beamformed outputs, and STOI-Net, to determine the optimal result. Experimental results indicate that IANS can produce intelligibility-enhanced signals using a small dual-microphone array. The results are comparable to those obtained by null-steering beamformers with given knowledge of DOAs.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023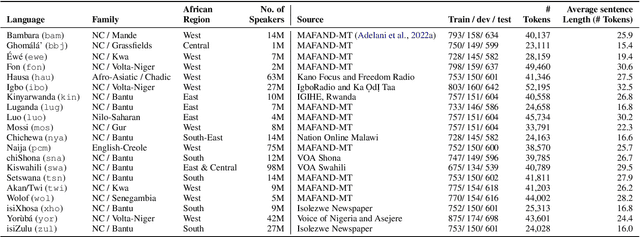
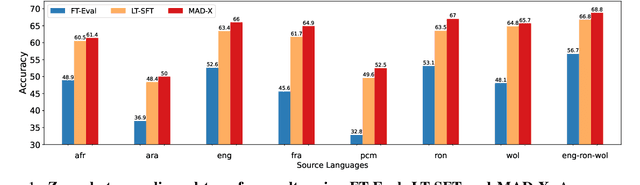
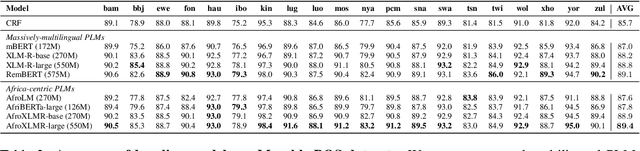
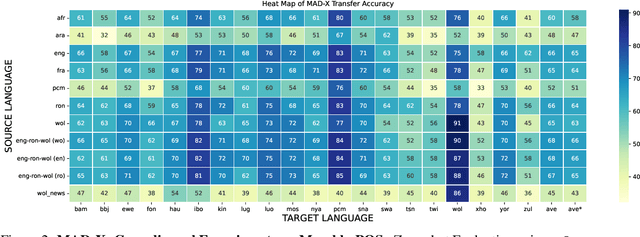
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
Adaptation and Optimization of Automatic Speech Recognition (ASR) for the Maritime Domain in the Field of VHF Communication
Jun 01, 2023This paper introduces a multilingual automatic speech recognizer (ASR) for maritime radio communi-cation that automatically converts received VHF radio signals into text. The challenges of maritime radio communication are described at first, and the deep learning architecture of marFM consisting of audio processing techniques and machine learning algorithms is presented. Subsequently, maritime radio data of interest is analyzed and then used to evaluate the transcription performance of our ASR model for various maritime radio data.
Developmental Bootstrapping: From Simple Competences to Intelligent Human-Compatible AIs
Aug 23, 2023

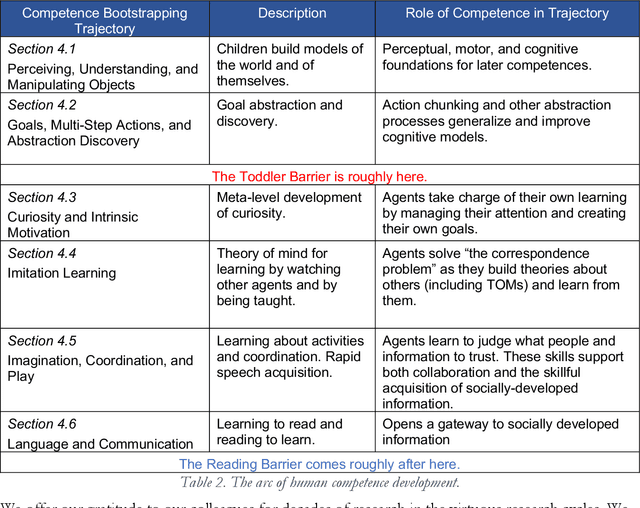
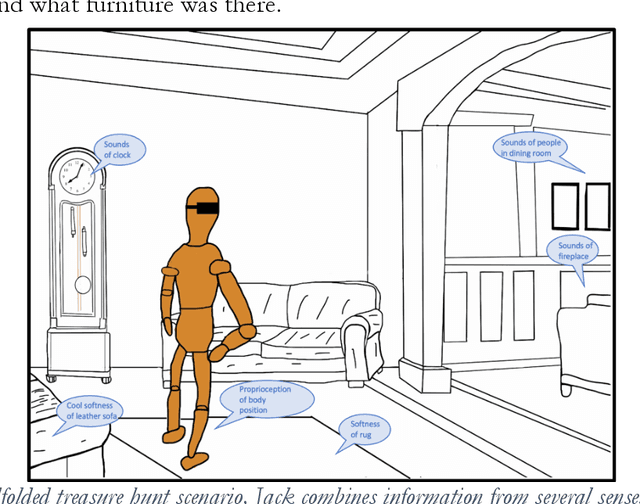
Although some AIs surpass human abilities in closed artificial worlds such as board games, in the real world they make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. Mainstream approaches for creating AIs include the traditional manually-constructed symbolic AI approach and the generative and deep learning AI approaches including large language models (LLMs). Although it is outside of the mainstream, the developmental bootstrapping approach may have more potential. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. They interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. They acquire the competences they need through competence bootstrapping. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped before reaching the Toddler Barrier. This corresponds to human infant development at about two years of age, before infant speech becomes fluent. They also do not bridge the Reading Barrier, where they could skillfully and skeptically draw on the socially developed online information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This position paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to create robust, trustworthy, and human-compatible AIs.
Optimizing Performance of Feedforward and Convolutional Neural Networks through Dynamic Activation Functions
Aug 10, 2023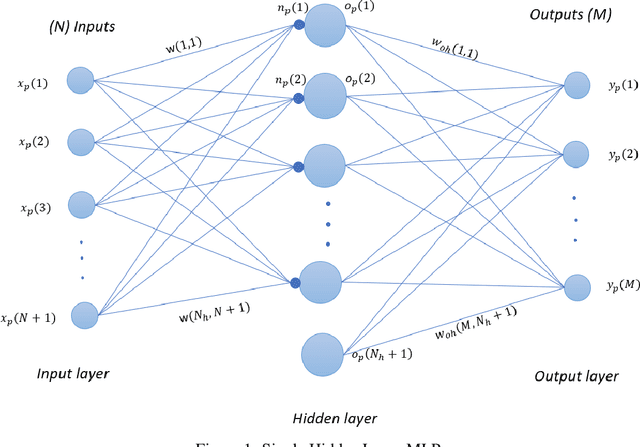
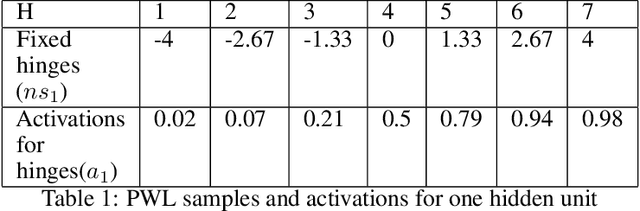
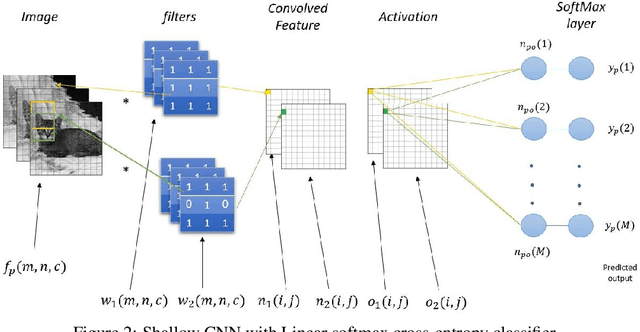
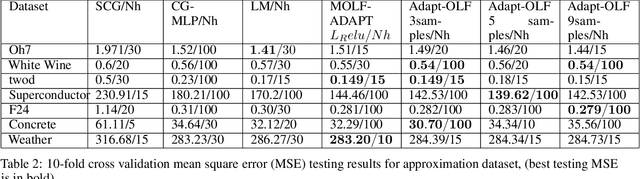
Deep learning training training algorithms are a huge success in recent years in many fields including speech, text,image video etc. Deeper and deeper layers are proposed with huge success with resnet structures having around 152 layers. Shallow convolution neural networks(CNN's) are still an active research, where some phenomena are still unexplained. Activation functions used in the network are of utmost importance, as they provide non linearity to the networks. Relu's are the most commonly used activation function.We show a complex piece-wise linear(PWL) activation in the hidden layer. We show that these PWL activations work much better than relu activations in our networks for convolution neural networks and multilayer perceptrons. Result comparison in PyTorch for shallow and deep CNNs are given to further strengthen our case.
Cross-speaker Emotion Transfer by Manipulating Speech Style Latents
Mar 15, 2023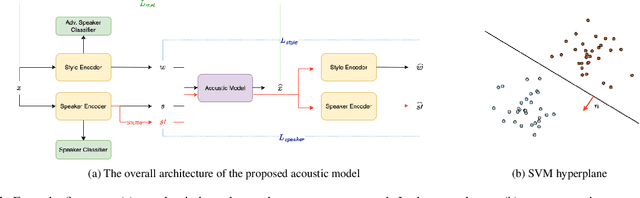
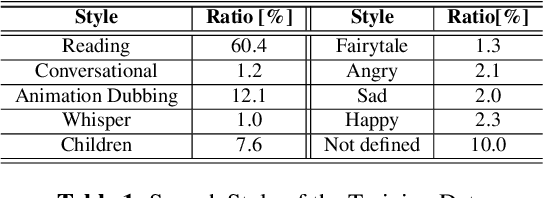
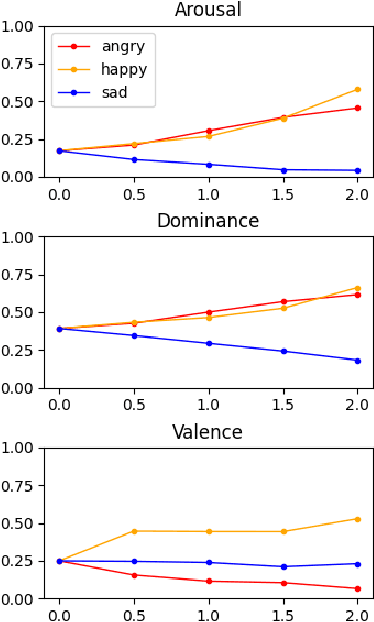
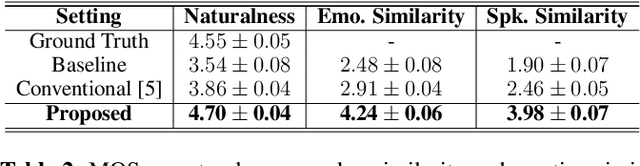
In recent years, emotional text-to-speech has shown considerable progress. However, it requires a large amount of labeled data, which is not easily accessible. Even if it is possible to acquire an emotional speech dataset, there is still a limitation in controlling emotion intensity. In this work, we propose a novel method for cross-speaker emotion transfer and manipulation using vector arithmetic in latent style space. By leveraging only a few labeled samples, we generate emotional speech from reading-style speech without losing the speaker identity. Furthermore, emotion strength is readily controllable using a scalar value, providing an intuitive way for users to manipulate speech. Experimental results show the proposed method affords superior performance in terms of expressiveness, naturalness, and controllability, preserving speaker identity.
Modality Confidence Aware Training for Robust End-to-End Spoken Language Understanding
Jul 22, 2023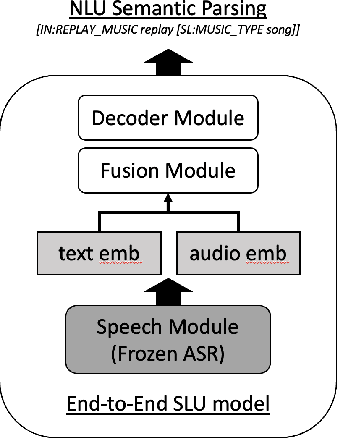
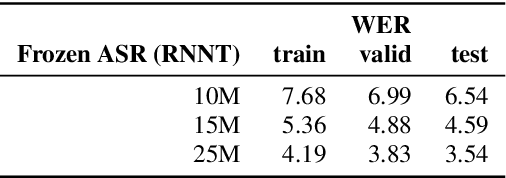
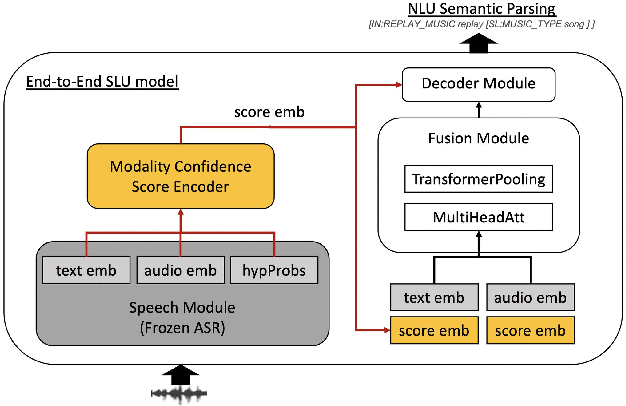

End-to-end (E2E) spoken language understanding (SLU) systems that generate a semantic parse from speech have become more promising recently. This approach uses a single model that utilizes audio and text representations from pre-trained speech recognition models (ASR), and outperforms traditional pipeline SLU systems in on-device streaming scenarios. However, E2E SLU systems still show weakness when text representation quality is low due to ASR transcription errors. To overcome this issue, we propose a novel E2E SLU system that enhances robustness to ASR errors by fusing audio and text representations based on the estimated modality confidence of ASR hypotheses. We introduce two novel techniques: 1) an effective method to encode the quality of ASR hypotheses and 2) an effective approach to integrate them into E2E SLU models. We show accuracy improvements on STOP dataset and share the analysis to demonstrate the effectiveness of our approach.
Improving Continuous Sign Language Recognition with Cross-Lingual Signs
Aug 21, 2023



This work dedicates to continuous sign language recognition (CSLR), which is a weakly supervised task dealing with the recognition of continuous signs from videos, without any prior knowledge about the temporal boundaries between consecutive signs. Data scarcity heavily impedes the progress of CSLR. Existing approaches typically train CSLR models on a monolingual corpus, which is orders of magnitude smaller than that of speech recognition. In this work, we explore the feasibility of utilizing multilingual sign language corpora to facilitate monolingual CSLR. Our work is built upon the observation of cross-lingual signs, which originate from different sign languages but have similar visual signals (e.g., hand shape and motion). The underlying idea of our approach is to identify the cross-lingual signs in one sign language and properly leverage them as auxiliary training data to improve the recognition capability of another. To achieve the goal, we first build two sign language dictionaries containing isolated signs that appear in two datasets. Then we identify the sign-to-sign mappings between two sign languages via a well-optimized isolated sign language recognition model. At last, we train a CSLR model on the combination of the target data with original labels and the auxiliary data with mapped labels. Experimentally, our approach achieves state-of-the-art performance on two widely-used CSLR datasets: Phoenix-2014 and Phoenix-2014T.
EmoTalk: Speech-driven emotional disentanglement for 3D face animation
Mar 20, 2023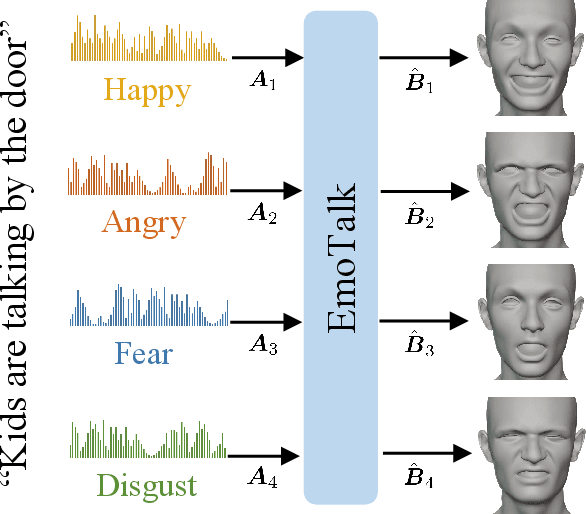

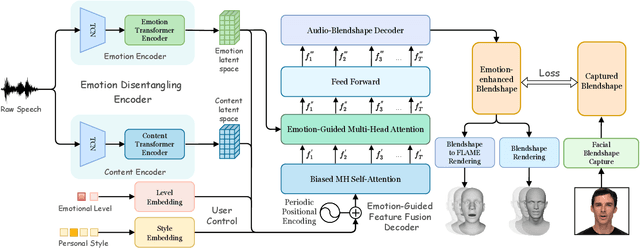
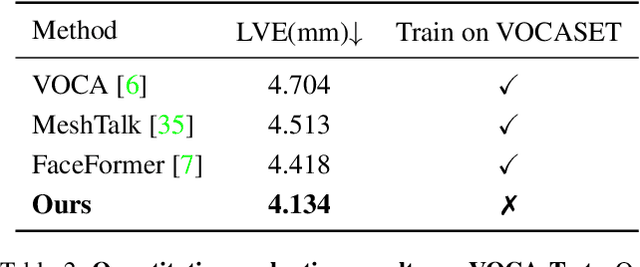
Speech-driven 3D face animation aims to generate realistic facial expressions that match the speech content and emotion. However, existing methods often neglect emotional facial expressions or fail to disentangle them from speech content. To address this issue, this paper proposes an end-to-end neural network to disentangle different emotions in speech so as to generate rich 3D facial expressions. Specifically, we introduce the emotion disentangling encoder (EDE) to disentangle the emotion and content in the speech by cross-reconstructed speech signals with different emotion labels. Then an emotion-guided feature fusion decoder is employed to generate a 3D talking face with enhanced emotion. The decoder is driven by the disentangled identity, emotional, and content embeddings so as to generate controllable personal and emotional styles. Finally, considering the scarcity of the 3D emotional talking face data, we resort to the supervision of facial blendshapes, which enables the reconstruction of plausible 3D faces from 2D emotional data, and contribute a large-scale 3D emotional talking face dataset (3D-ETF) to train the network. Our experiments and user studies demonstrate that our approach outperforms state-of-the-art methods and exhibits more diverse facial movements. We recommend watching the supplementary video: https://ziqiaopeng.github.io/emotalk
BASEN: Time-Domain Brain-Assisted Speech Enhancement Network with Convolutional Cross Attention in Multi-talker Conditions
May 17, 2023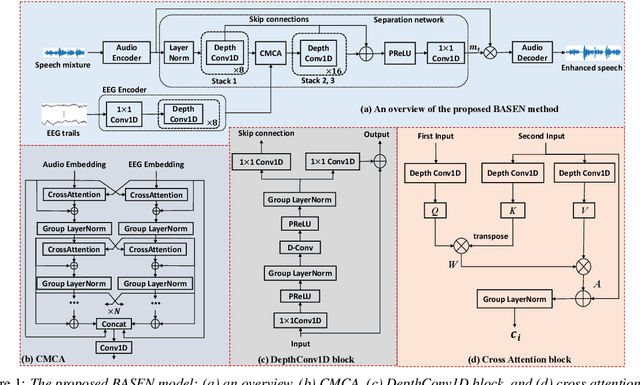
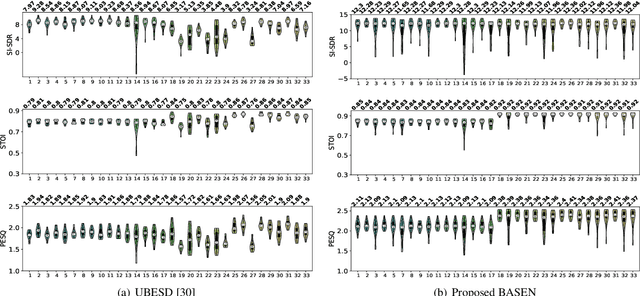
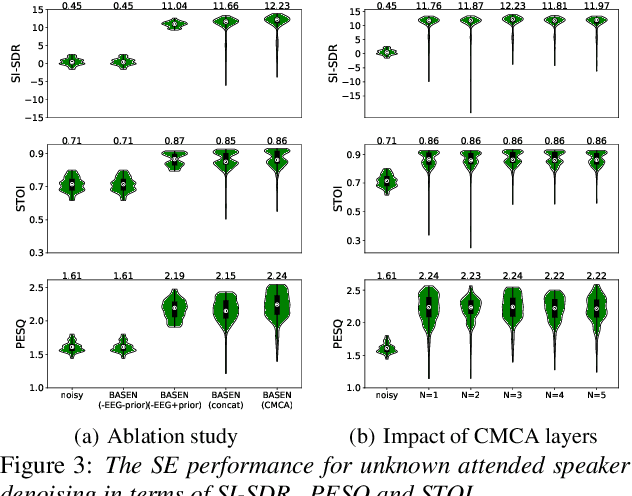
Time-domain single-channel speech enhancement (SE) still remains challenging to extract the target speaker without any prior information on multi-talker conditions. It has been shown via auditory attention decoding that the brain activity of the listener contains the auditory information of the attended speaker. In this paper, we thus propose a novel time-domain brain-assisted SE network (BASEN) incorporating electroencephalography (EEG) signals recorded from the listener for extracting the target speaker from monaural speech mixtures. The proposed BASEN is based on the fully-convolutional time-domain audio separation network. In order to fully leverage the complementary information contained in the EEG signals, we further propose a convolutional multi-layer cross attention module to fuse the dual-branch features. Experimental results on a public dataset show that the proposed model outperforms the state-of-the-art method in several evaluation metrics. The reproducible code is available at https://github.com/jzhangU/Basen.git.