 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving TTS for Shanghainese: Addressing Tone Sandhi via Word Segmentation
Jul 30, 2023

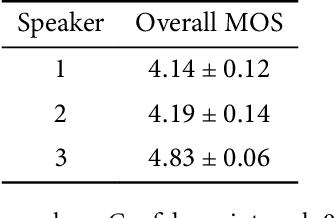
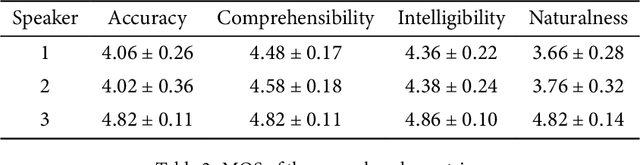
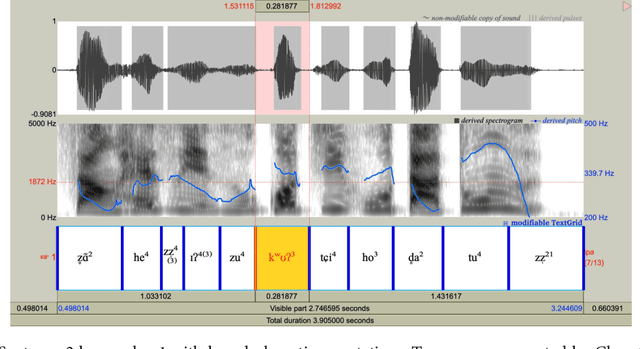
Tone is a crucial component of the prosody of Shanghainese, a Wu Chinese variety spoken primarily in urban Shanghai. Tone sandhi, which applies to all multi-syllabic words in Shanghainese, then, is key to natural-sounding speech. Unfortunately, recent work on Shanghainese TTS (text-to-speech) such as Apple's VoiceOver has shown poor performance with tone sandhi, especially LD (left-dominant sandhi). Here I show that word segmentation during text preprocessing can improve the quality of tone sandhi production in TTS models. Syllables within the same word are annotated with a special symbol, which serves as a proxy for prosodic information of the domain of LD. Contrary to the common practice of using prosodic annotation mainly for static pauses, this paper demonstrates that prosodic annotation can also be applied to dynamic tonal phenomena. I anticipate this project to be a starting point for bringing formal linguistic accounts of Shanghainese into computational projects. Too long have we been using the Mandarin models to approximate Shanghainese, but it is a different language with its own linguistic features, and its digitisation and revitalisation should be treated as such.
TSSR: A Truncated and Signed Square Root Activation Function for Neural Networks
Aug 09, 2023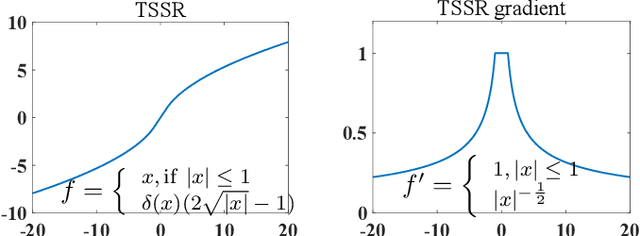
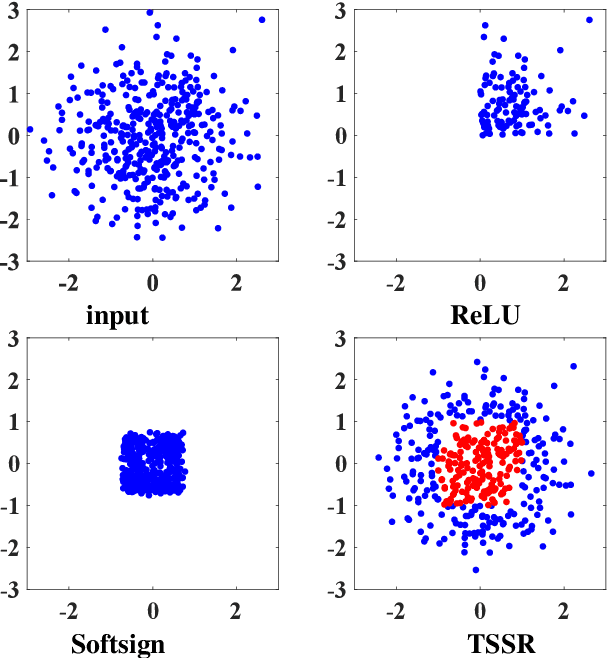
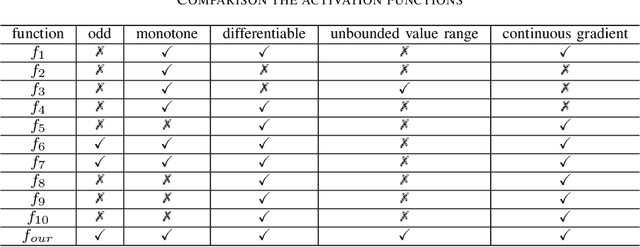
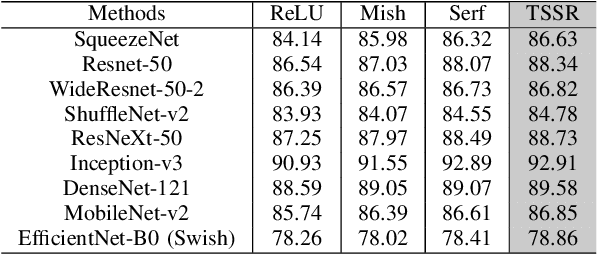
Activation functions are essential components of neural networks. In this paper, we introduce a new activation function called the Truncated and Signed Square Root (TSSR) function. This function is distinctive because it is odd, nonlinear, monotone and differentiable. Its gradient is continuous and always positive. Thanks to these properties, it has the potential to improve the numerical stability of neural networks. Several experiments confirm that the proposed TSSR has better performance than other stat-of-the-art activation functions. The proposed function has significant implications for the development of neural network models and can be applied to a wide range of applications in fields such as computer vision, natural language processing, and speech recognition.
MC-DRE: Multi-Aspect Cross Integration for Drug Event/Entity Extraction
Aug 15, 2023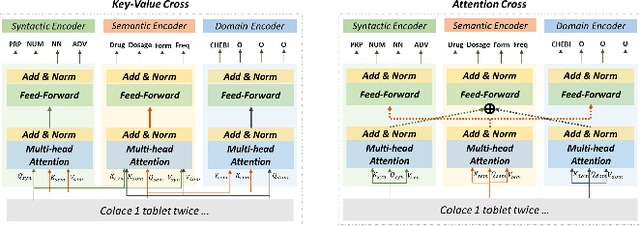
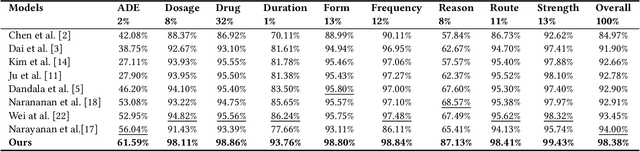

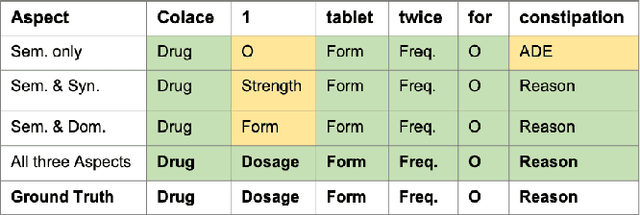
Extracting meaningful drug-related information chunks, such as adverse drug events (ADE), is crucial for preventing morbidity and saving many lives. Most ADEs are reported via an unstructured conversation with the medical context, so applying a general entity recognition approach is not sufficient enough. In this paper, we propose a new multi-aspect cross-integration framework for drug entity/event detection by capturing and aligning different context/language/knowledge properties from drug-related documents. We first construct multi-aspect encoders to describe semantic, syntactic, and medical document contextual information by conducting those slot tagging tasks, main drug entity/event detection, part-of-speech tagging, and general medical named entity recognition. Then, each encoder conducts cross-integration with other contextual information in three ways: the key-value cross, attention cross, and feedforward cross, so the multi-encoders are integrated in depth. Our model outperforms all SOTA on two widely used tasks, flat entity detection and discontinuous event extraction.
End-to-End Open Vocabulary Keyword Search With Multilingual Neural Representations
Aug 15, 2023Conventional keyword search systems operate on automatic speech recognition (ASR) outputs, which causes them to have a complex indexing and search pipeline. This has led to interest in ASR-free approaches to simplify the search procedure. We recently proposed a neural ASR-free keyword search model which achieves competitive performance while maintaining an efficient and simplified pipeline, where queries and documents are encoded with a pair of recurrent neural network encoders and the encodings are combined with a dot-product. In this article, we extend this work with multilingual pretraining and detailed analysis of the model. Our experiments show that the proposed multilingual training significantly improves the model performance and that despite not matching a strong ASR-based conventional keyword search system for short queries and queries comprising in-vocabulary words, the proposed model outperforms the ASR-based system for long queries and queries that do not appear in the training data.
* Accepted by IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2023
Improving Speech Enhancement via Event-based Query
Feb 24, 2023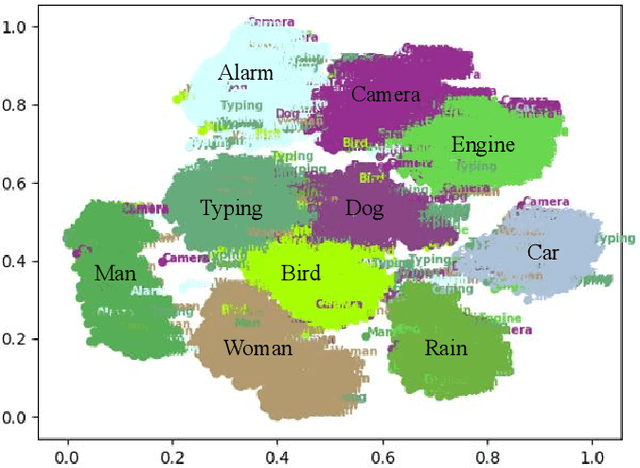
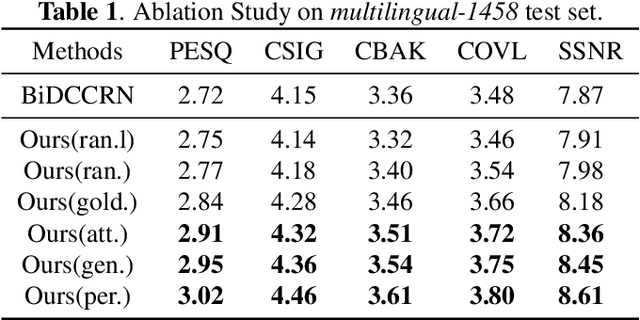
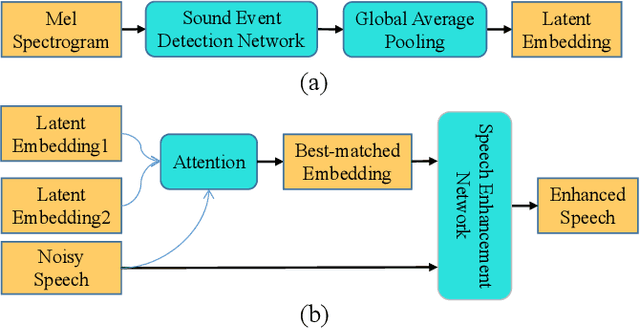
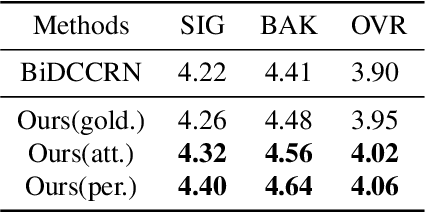
Existing deep learning based speech enhancement (SE) methods either use blind end-to-end training or explicitly incorporate speaker embedding or phonetic information into the SE network to enhance speech quality. In this paper, we perceive speech and noises as different types of sound events and propose an event-based query method for SE. Specifically, representative speech embeddings that can discriminate speech with noises are first pre-trained with the sound event detection (SED) task. The embeddings are then clustered into fixed golden speech queries to assist the SE network to enhance the speech from noisy audio. The golden speech queries can be obtained offline and generalizable to different SE datasets and networks. Therefore, little extra complexity is introduced and no enrollment is needed for each speaker. Experimental results show that the proposed method yields significant gains compared with baselines and the golden queries are well generalized to different datasets.
Vocoder-Free Non-Parallel Conversion of Whispered Speech With Masked Cycle-Consistent Generative Adversarial Networks
Jun 10, 2023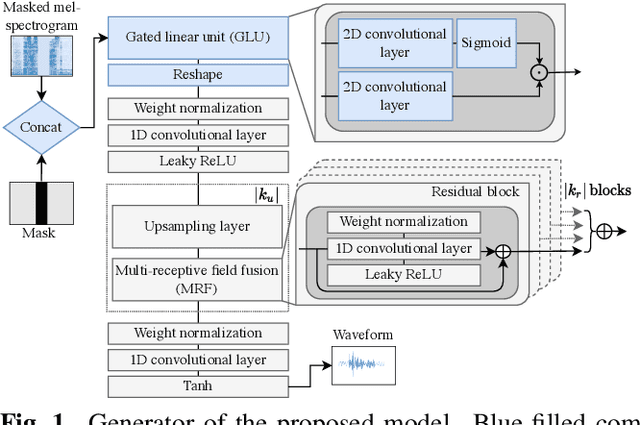
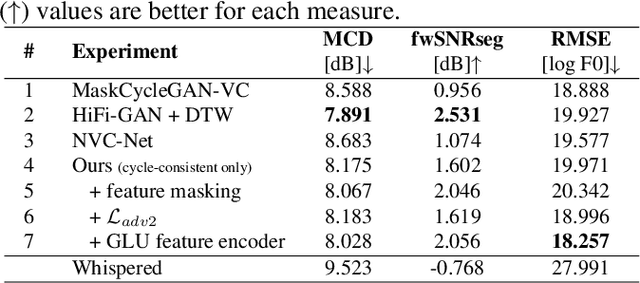
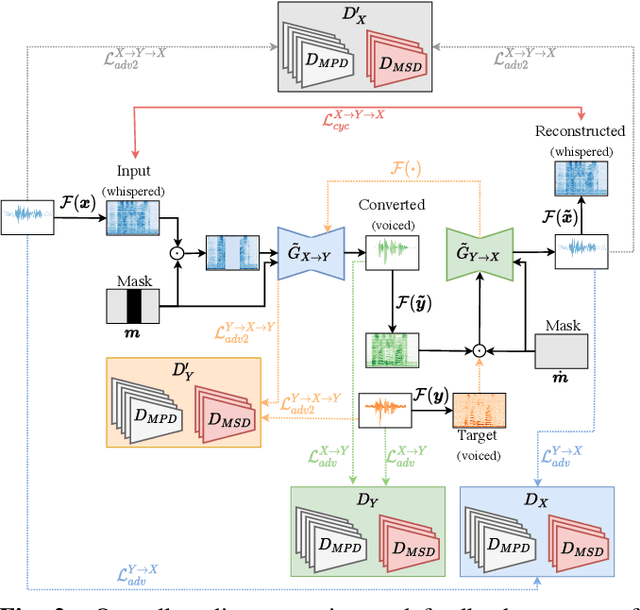
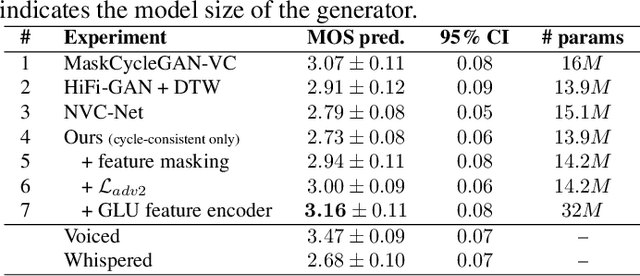
Cycle-consistent generative adversarial networks have been widely used in non-parallel voice conversion (VC). Their ability to learn mappings between source and target features without relying on parallel training data eliminates the need for temporal alignments. However, most methods decouple the conversion of acoustic features from synthesizing the audio signal by using separate models for conversion and waveform synthesis. This work unifies conversion and synthesis into a single model, thereby eliminating the need for a separate vocoder. By leveraging cycle-consistent training and a self-supervised auxiliary training task, our model is able to efficiently generate converted high-quality raw audio waveforms. Subjective listening tests show that our method outperforms the baseline in whispered speech conversion (up to 6.7% relative improvement), and mean opinion score predictions yield competitive results in conventional VC (between 0.5% and 2.4% relative improvement).
AI in the Gray: Exploring Moderation Policies in Dialogic Large Language Models vs. Human Answers in Controversial Topics
Aug 28, 2023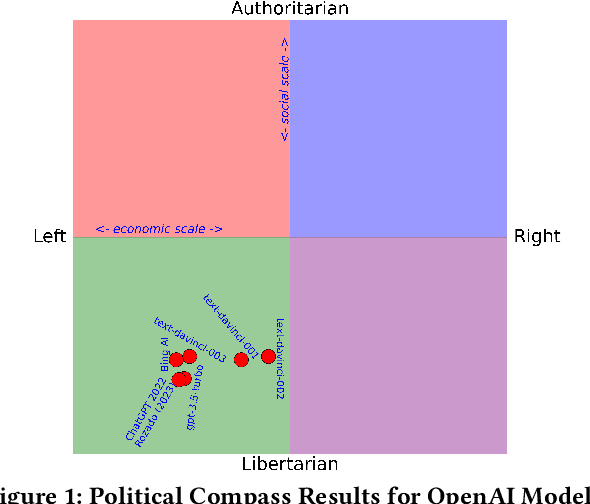

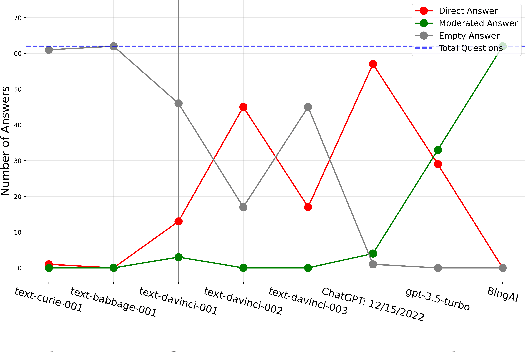

The introduction of ChatGPT and the subsequent improvement of Large Language Models (LLMs) have prompted more and more individuals to turn to the use of ChatBots, both for information and assistance with decision-making. However, the information the user is after is often not formulated by these ChatBots objectively enough to be provided with a definite, globally accepted answer. Controversial topics, such as "religion", "gender identity", "freedom of speech", and "equality", among others, can be a source of conflict as partisan or biased answers can reinforce preconceived notions or promote disinformation. By exposing ChatGPT to such debatable questions, we aim to understand its level of awareness and if existing models are subject to socio-political and/or economic biases. We also aim to explore how AI-generated answers compare to human ones. For exploring this, we use a dataset of a social media platform created for the purpose of debating human-generated claims on polemic subjects among users, dubbed Kialo. Our results show that while previous versions of ChatGPT have had important issues with controversial topics, more recent versions of ChatGPT (gpt-3.5-turbo) are no longer manifesting significant explicit biases in several knowledge areas. In particular, it is well-moderated regarding economic aspects. However, it still maintains degrees of implicit libertarian leaning toward right-winged ideals which suggest the need for increased moderation from the socio-political point of view. In terms of domain knowledge on controversial topics, with the exception of the "Philosophical" category, ChatGPT is performing well in keeping up with the collective human level of knowledge. Finally, we see that sources of Bing AI have slightly more tendency to the center when compared to human answers. All the analyses we make are generalizable to other types of biases and domains.
Improving Speech Emotion Recognition Performance using Differentiable Architecture Search
May 23, 2023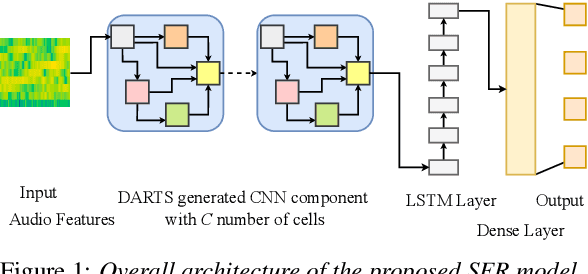
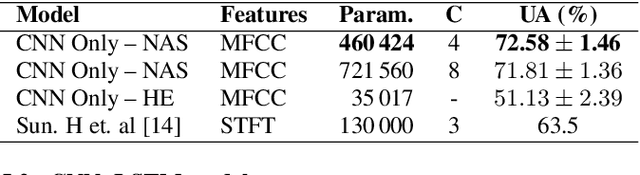
Speech Emotion Recognition (SER) is a critical enabler of emotion-aware communication in human-computer interactions. Deep Learning (DL) has improved the performance of SER models by improving model complexity. However, designing DL architectures requires prior experience and experimental evaluations. Encouragingly, Neural Architecture Search (NAS) allows automatic search for an optimum DL model. In particular, Differentiable Architecture Search (DARTS) is an efficient method of using NAS to search for optimised models. In this paper, we propose DARTS for a joint CNN and LSTM architecture for improving SER performance. Our choice of the CNN LSTM coupling is inspired by results showing that similar models offer improved performance. While SER researchers have considered CNNs and RNNs separately, the viability of using DARTs jointly for CNN and LSTM still needs exploration. Experimenting with the IEMOCAP dataset, we demonstrate that our approach outperforms best-reported results using DARTS for SER.
Beyond Neural-on-Neural Approaches to Speaker Gender Protection
Jun 30, 2023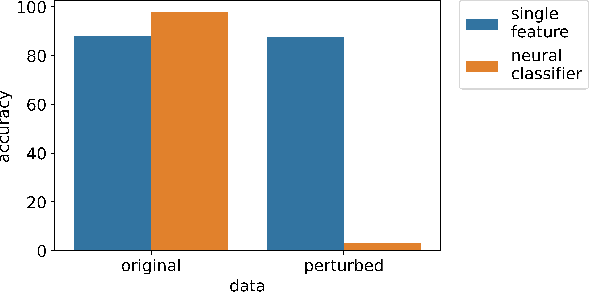

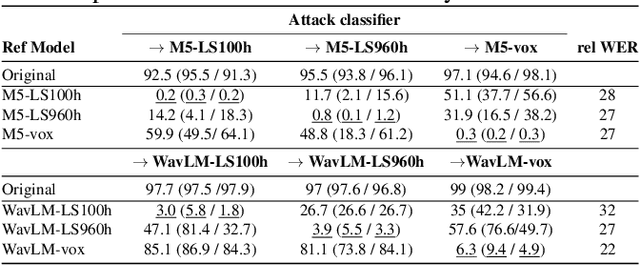
Recent research has proposed approaches that modify speech to defend against gender inference attacks. The goal of these protection algorithms is to control the availability of information about a speaker's gender, a privacy-sensitive attribute. Currently, the common practice for developing and testing gender protection algorithms is "neural-on-neural", i.e., perturbations are generated and tested with a neural network. In this paper, we propose to go beyond this practice to strengthen the study of gender protection. First, we demonstrate the importance of testing gender inference attacks that are based on speech features historically developed by speech scientists, alongside the conventionally used neural classifiers. Next, we argue that researchers should use speech features to gain insight into how protective modifications change the speech signal. Finally, we point out that gender-protection algorithms should be compared with novel "vocal adversaries", human-executed voice adaptations, in order to improve interpretability and enable before-the-mic protection.
O-1: Self-training with Oracle and 1-best Hypothesis
Aug 14, 2023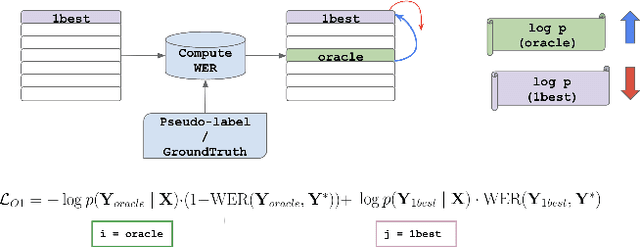
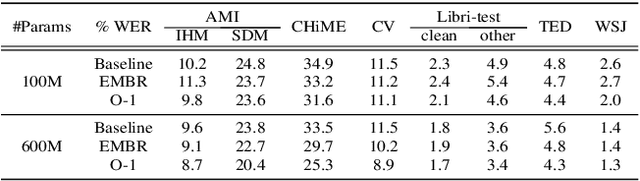
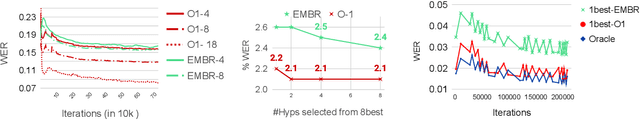
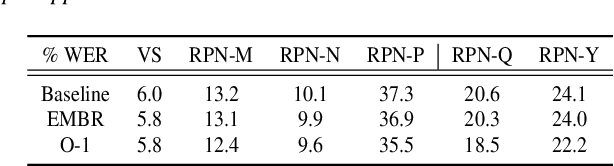
We introduce O-1, a new self-training objective to reduce training bias and unify training and evaluation metrics for speech recognition. O-1 is a faster variant of Expected Minimum Bayes Risk (EMBR), that boosts the oracle hypothesis and can accommodate both supervised and unsupervised data. We demonstrate the effectiveness of our approach in terms of recognition on publicly available SpeechStew datasets and a large-scale, in-house data set. On Speechstew, the O-1 objective closes the gap between the actual and oracle performance by 80\% relative compared to EMBR which bridges the gap by 43\% relative. O-1 achieves 13\% to 25\% relative improvement over EMBR on the various datasets that SpeechStew comprises of, and a 12\% relative gap reduction with respect to the oracle WER over EMBR training on the in-house dataset. Overall, O-1 results in a 9\% relative improvement in WER over EMBR, thereby speaking to the scalability of the proposed objective for large-scale datasets.