 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
The Hidden Dance of Phonemes and Visage: Unveiling the Enigmatic Link between Phonemes and Facial Features
Jul 26, 2023
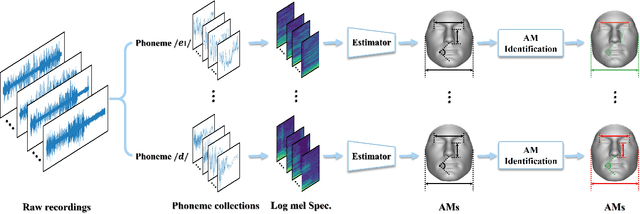
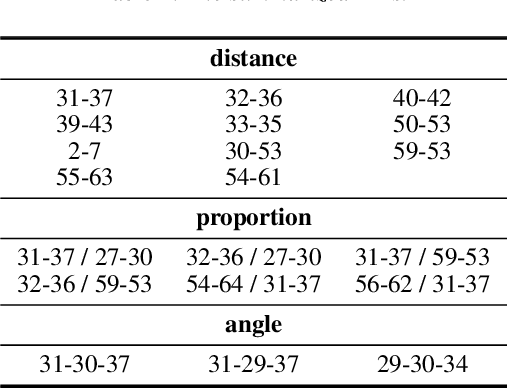
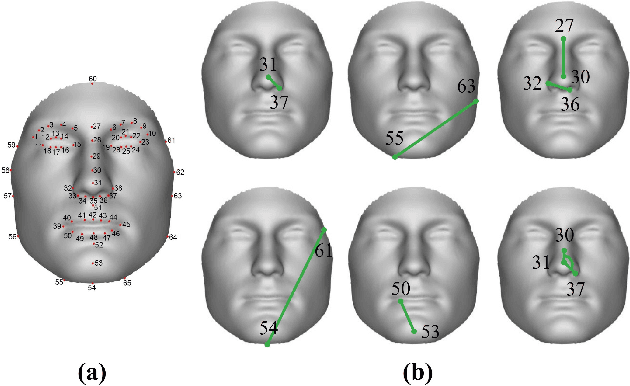
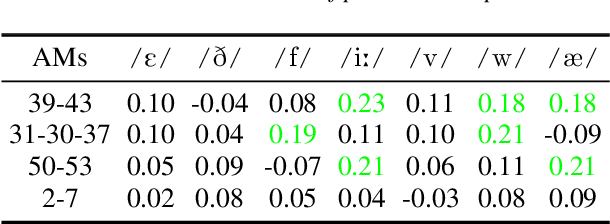
This work unveils the enigmatic link between phonemes and facial features. Traditional studies on voice-face correlations typically involve using a long period of voice input, including generating face images from voices and reconstructing 3D face meshes from voices. However, in situations like voice-based crimes, the available voice evidence may be short and limited. Additionally, from a physiological perspective, each segment of speech -- phoneme -- corresponds to different types of airflow and movements in the face. Therefore, it is advantageous to discover the hidden link between phonemes and face attributes. In this paper, we propose an analysis pipeline to help us explore the voice-face relationship in a fine-grained manner, i.e., phonemes v.s. facial anthropometric measurements (AM). We build an estimator for each phoneme-AM pair and evaluate the correlation through hypothesis testing. Our results indicate that AMs are more predictable from vowels compared to consonants, particularly with plosives. Additionally, we observe that if a specific AM exhibits more movement during phoneme pronunciation, it is more predictable. Our findings support those in physiology regarding correlation and lay the groundwork for future research on speech-face multimodal learning.
A Survey on Audio Diffusion Models: Text To Speech Synthesis and Enhancement in Generative AI
Apr 02, 2023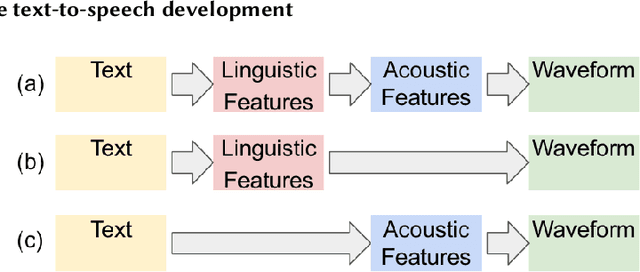
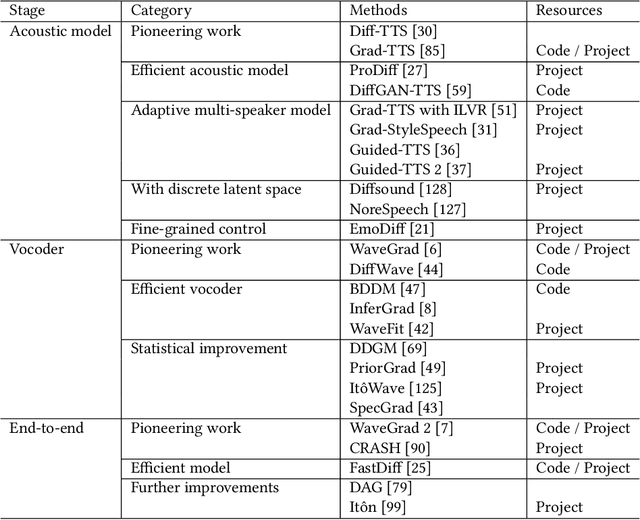
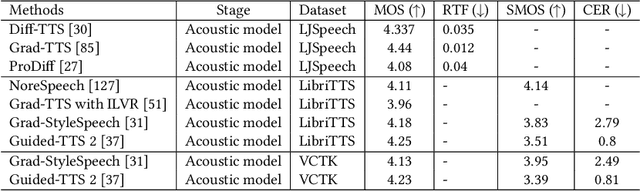

Generative AI has demonstrated impressive performance in various fields, among which speech synthesis is an interesting direction. With the diffusion model as the most popular generative model, numerous works have attempted two active tasks: text to speech and speech enhancement. This work conducts a survey on audio diffusion model, which is complementary to existing surveys that either lack the recent progress of diffusion-based speech synthesis or highlight an overall picture of applying diffusion model in multiple fields. Specifically, this work first briefly introduces the background of audio and diffusion model. As for the text-to-speech task, we divide the methods into three categories based on the stage where diffusion model is adopted: acoustic model, vocoder and end-to-end framework. Moreover, we categorize various speech enhancement tasks by either certain signals are removed or added into the input speech. Comparisons of experimental results and discussions are also covered in this survey.
AQ-GT: a Temporally Aligned and Quantized GRU-Transformer for Co-Speech Gesture Synthesis
May 02, 2023
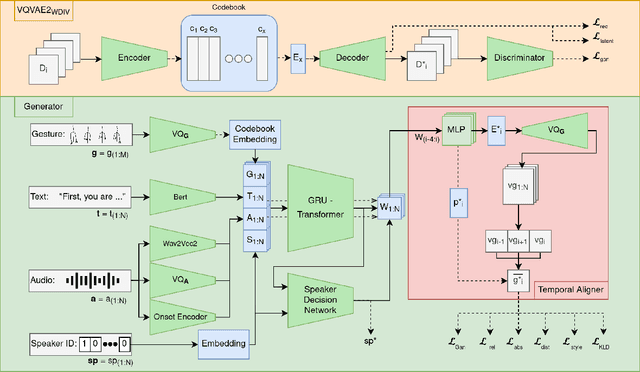
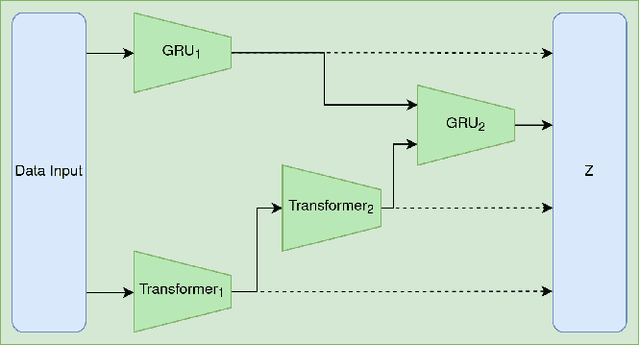
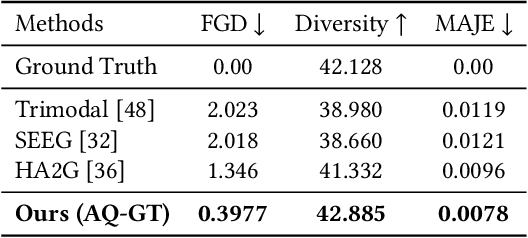
The generation of realistic and contextually relevant co-speech gestures is a challenging yet increasingly important task in the creation of multimodal artificial agents. Prior methods focused on learning a direct correspondence between co-speech gesture representations and produced motions, which created seemingly natural but often unconvincing gestures during human assessment. We present an approach to pre-train partial gesture sequences using a generative adversarial network with a quantization pipeline. The resulting codebook vectors serve as both input and output in our framework, forming the basis for the generation and reconstruction of gestures. By learning the mapping of a latent space representation as opposed to directly mapping it to a vector representation, this framework facilitates the generation of highly realistic and expressive gestures that closely replicate human movement and behavior, while simultaneously avoiding artifacts in the generation process. We evaluate our approach by comparing it with established methods for generating co-speech gestures as well as with existing datasets of human behavior. We also perform an ablation study to assess our findings. The results show that our approach outperforms the current state of the art by a clear margin and is partially indistinguishable from human gesturing. We make our data pipeline and the generation framework publicly available.
Some voices are too common: Building fair speech recognition systems using the Common Voice dataset
Jun 01, 2023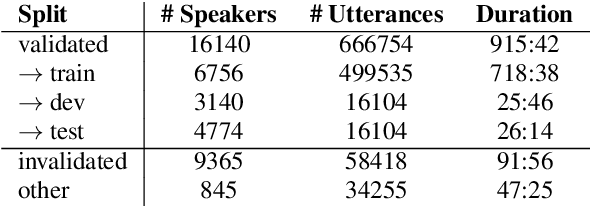
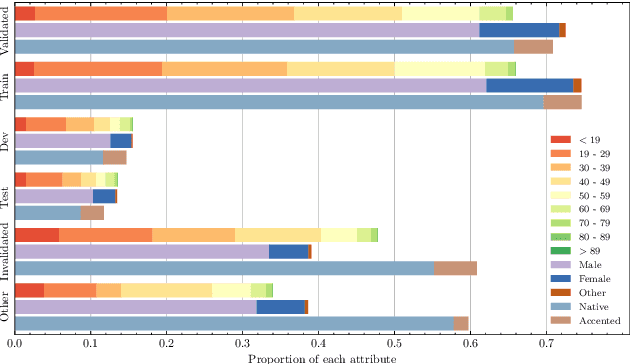
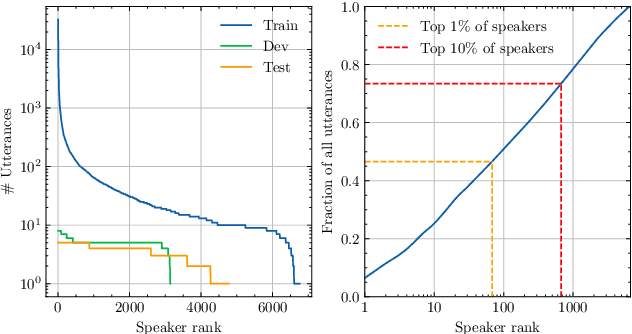
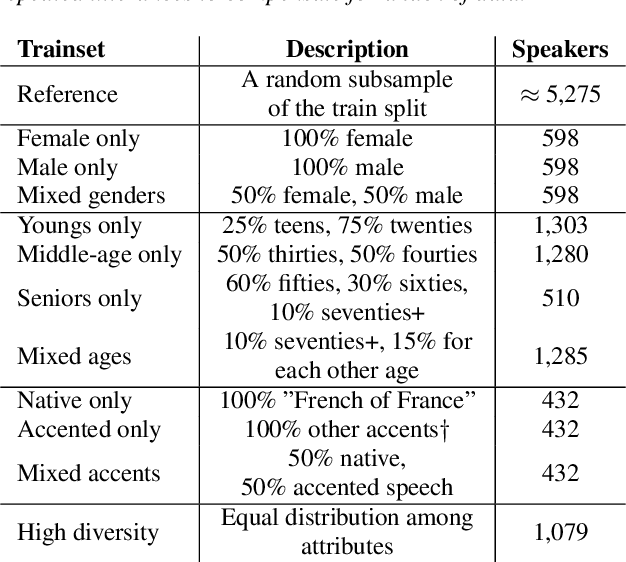
Automatic speech recognition (ASR) systems become increasingly efficient thanks to new advances in neural network training like self-supervised learning. However, they are known to be unfair toward certain groups, for instance, people speaking with an accent. In this work, we use the French Common Voice dataset to quantify the biases of a pre-trained wav2vec~2.0 model toward several demographic groups. By fine-tuning the pre-trained model on a variety of fixed-size, carefully crafted training sets, we demonstrate the importance of speaker diversity. We also run an in-depth analysis of the Common Voice corpus and identify important shortcomings that should be taken into account by users of this dataset.
Investigating the dynamics of hand and lips in French Cued Speech using attention mechanisms and CTC-based decoding
Jun 14, 2023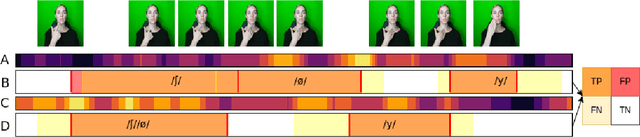
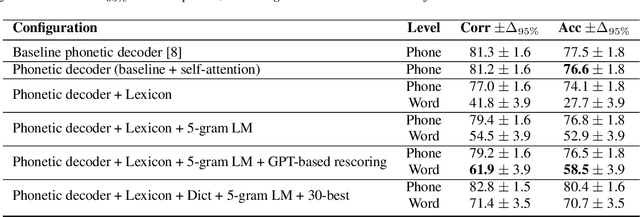
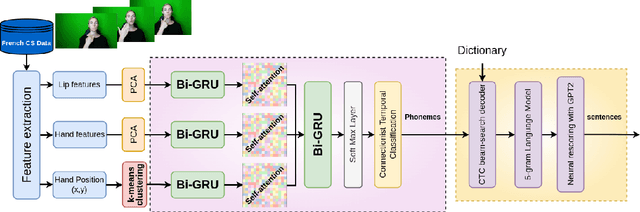
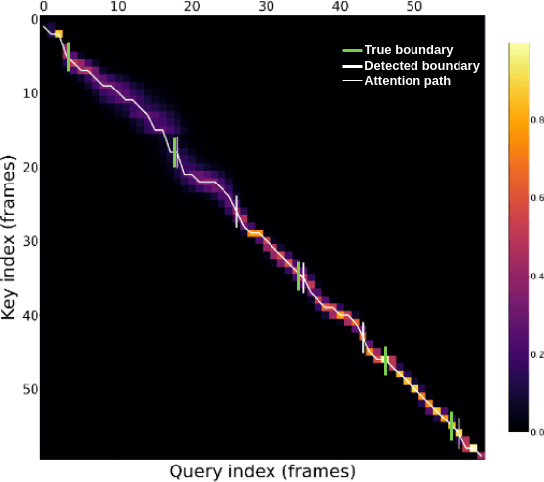
Hard of hearing or profoundly deaf people make use of cued speech (CS) as a communication tool to understand spoken language. By delivering cues that are relevant to the phonetic information, CS offers a way to enhance lipreading. In literature, there have been several studies on the dynamics between the hand and the lips in the context of human production. This article proposes a way to investigate how a neural network learns this relation for a single speaker while performing a recognition task using attention mechanisms. Further, an analysis of the learnt dynamics is utilized to establish the relationship between the two modalities and extract automatic segments. For the purpose of this study, a new dataset has been recorded for French CS. Along with the release of this dataset, a benchmark will be reported for word-level recognition, a novelty in the automatic recognition of French CS.
UniFLG: Unified Facial Landmark Generator from Text or Speech
Feb 28, 2023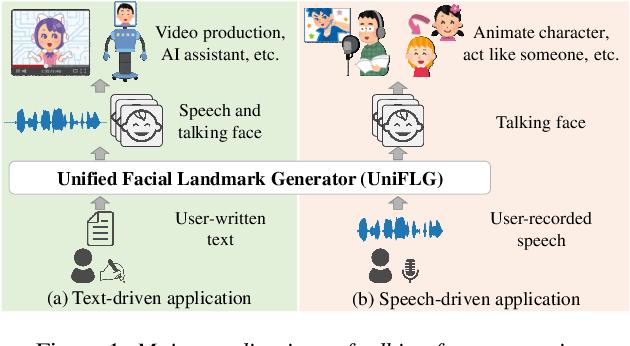
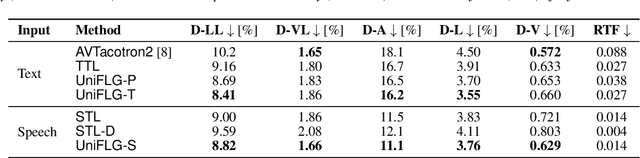
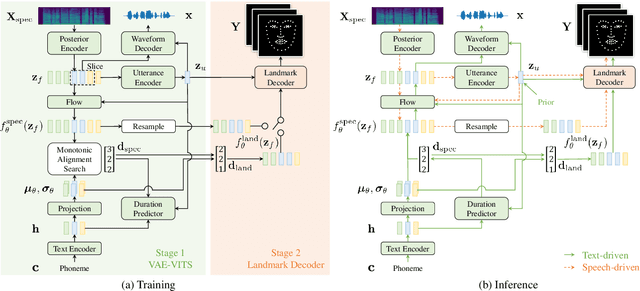
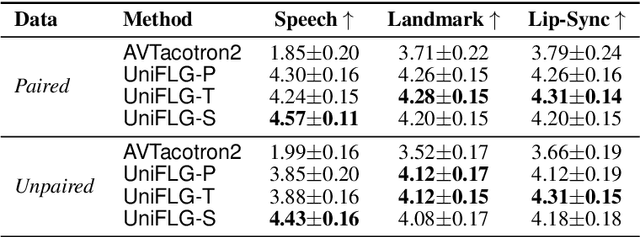
Talking face generation has been extensively investigated owing to its wide applicability. The two primary frameworks used for talking face generation comprise a text-driven framework, which generates synchronized speech and talking faces from text, and a speech-driven framework, which generates talking faces from speech. To integrate these frameworks, this paper proposes a unified facial landmark generator (UniFLG). The proposed system exploits end-to-end text-to-speech not only for synthesizing speech but also for extracting a series of latent representations that are common to text and speech, and feeds it to a landmark decoder to generate facial landmarks. We demonstrate that our system achieves higher naturalness in both speech synthesis and facial landmark generation compared to the state-of-the-art text-driven method. We further demonstrate that our system can generate facial landmarks from speech of speakers without facial video data or even speech data.
Bilingual Streaming ASR with Grapheme units and Auxiliary Monolingual Loss
Aug 11, 2023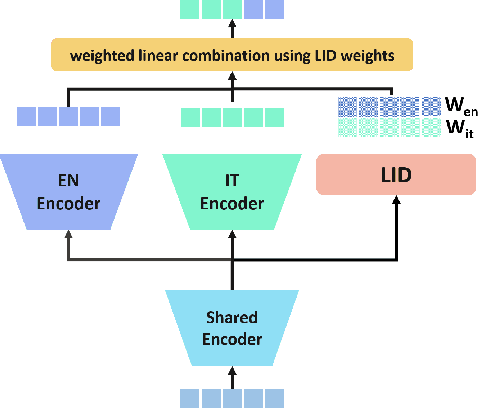
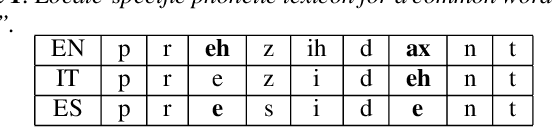
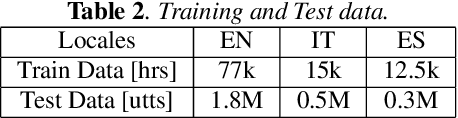
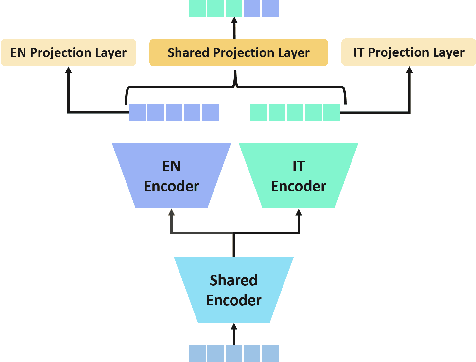
We introduce a bilingual solution to support English as secondary locale for most primary locales in hybrid automatic speech recognition (ASR) settings. Our key developments constitute: (a) pronunciation lexicon with grapheme units instead of phone units, (b) a fully bilingual alignment model and subsequently bilingual streaming transformer model, (c) a parallel encoder structure with language identification (LID) loss, (d) parallel encoder with an auxiliary loss for monolingual projections. We conclude that in comparison to LID loss, our proposed auxiliary loss is superior in specializing the parallel encoders to respective monolingual locales, and that contributes to stronger bilingual learning. We evaluate our work on large-scale training and test tasks for bilingual Spanish (ES) and bilingual Italian (IT) applications. Our bilingual models demonstrate strong English code-mixing capability. In particular, the bilingual IT model improves the word error rate (WER) for a code-mix IT task from 46.5% to 13.8%, while also achieving a close parity (9.6%) with the monolingual IT model (9.5%) over IT tests.
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 17, 2023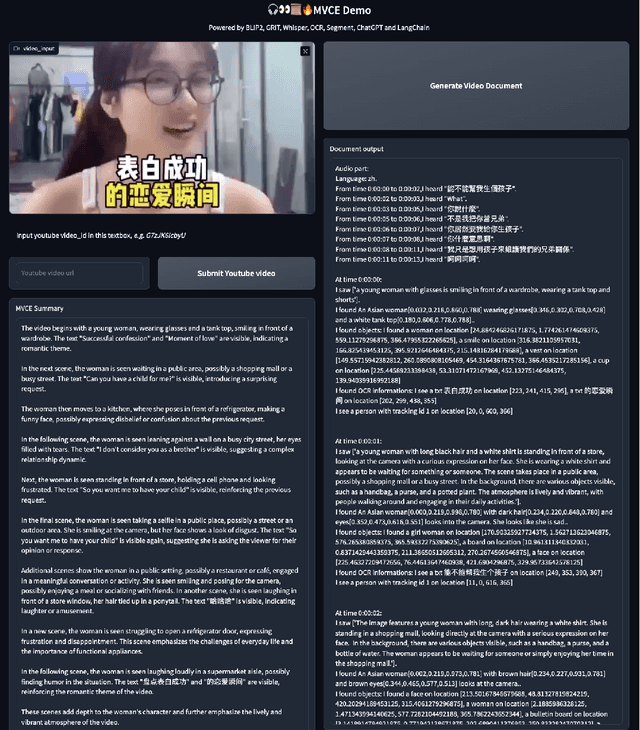
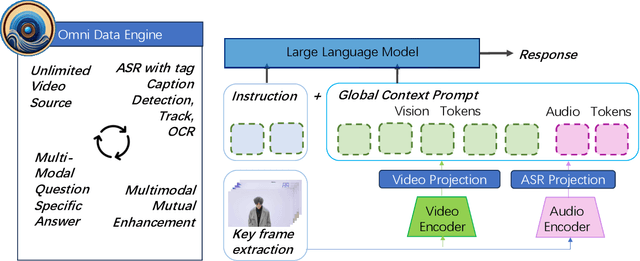

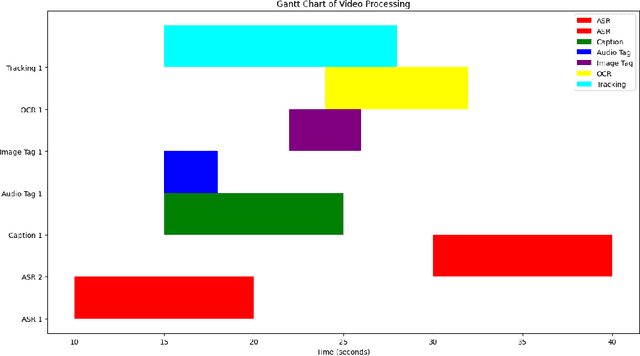
This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.
Controlling Federated Learning for Covertness
Aug 17, 2023
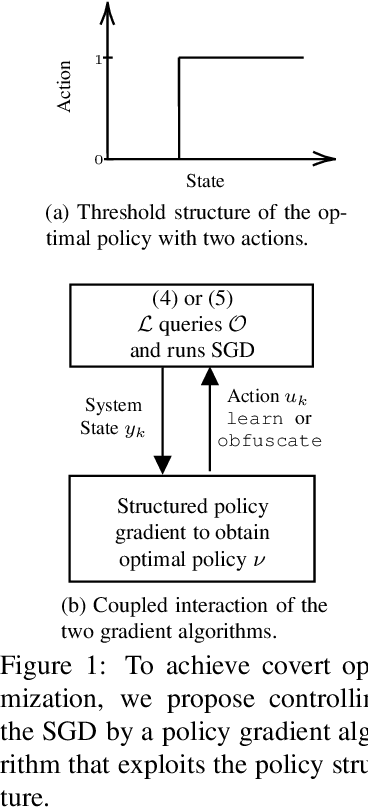
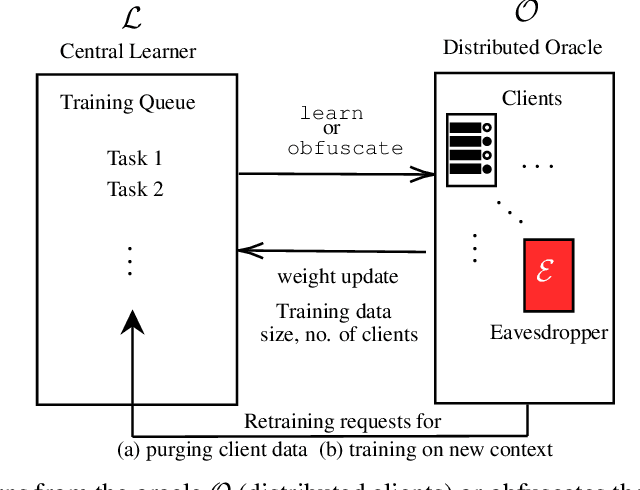
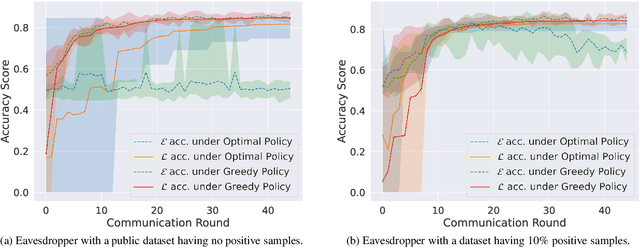
A learner aims to minimize a function $f$ by repeatedly querying a distributed oracle that provides noisy gradient evaluations. At the same time, the learner seeks to hide $\arg\min f$ from a malicious eavesdropper that observes the learner's queries. This paper considers the problem of \textit{covert} or \textit{learner-private} optimization, where the learner has to dynamically choose between learning and obfuscation by exploiting the stochasticity. The problem of controlling the stochastic gradient algorithm for covert optimization is modeled as a Markov decision process, and we show that the dynamic programming operator has a supermodular structure implying that the optimal policy has a monotone threshold structure. A computationally efficient policy gradient algorithm is proposed to search for the optimal querying policy without knowledge of the transition probabilities. As a practical application, our methods are demonstrated on a hate speech classification task in a federated setting where an eavesdropper can use the optimal weights to generate toxic content, which is more easily misclassified. Numerical results show that when the learner uses the optimal policy, an eavesdropper can only achieve a validation accuracy of $52\%$ with no information and $69\%$ when it has a public dataset with 10\% positive samples compared to $83\%$ when the learner employs a greedy policy.
A Trustable LSTM-Autoencoder Network for Cyberbullying Detection on Social Media Using Synthetic Data
Aug 15, 2023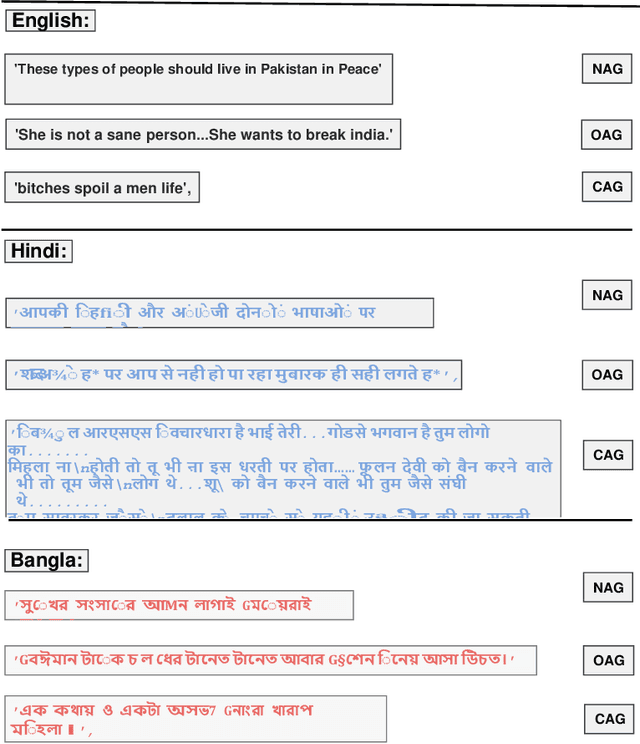

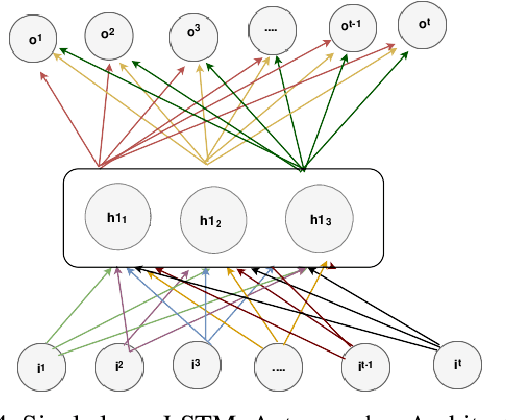
Social media cyberbullying has a detrimental effect on human life. As online social networking grows daily, the amount of hate speech also increases. Such terrible content can cause depression and actions related to suicide. This paper proposes a trustable LSTM-Autoencoder Network for cyberbullying detection on social media using synthetic data. We have demonstrated a cutting-edge method to address data availability difficulties by producing machine-translated data. However, several languages such as Hindi and Bangla still lack adequate investigations due to a lack of datasets. We carried out experimental identification of aggressive comments on Hindi, Bangla, and English datasets using the proposed model and traditional models, including Long Short-Term Memory (LSTM), Bidirectional Long Short-Term Memory (BiLSTM), LSTM-Autoencoder, Word2vec, Bidirectional Encoder Representations from Transformers (BERT), and Generative Pre-trained Transformer 2 (GPT-2) models. We employed evaluation metrics such as f1-score, accuracy, precision, and recall to assess the models performance. Our proposed model outperformed all the models on all datasets, achieving the highest accuracy of 95%. Our model achieves state-of-the-art results among all the previous works on the dataset we used in this paper.