 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos
Jun 27, 2023
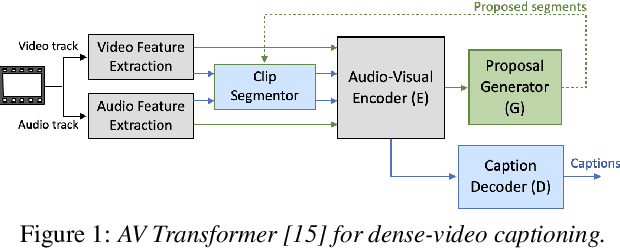

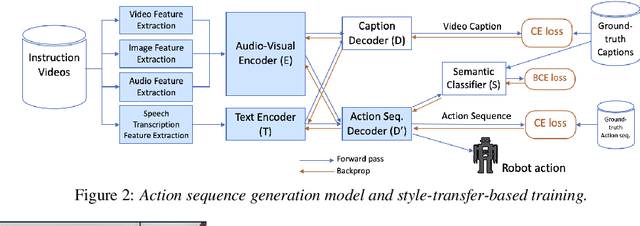
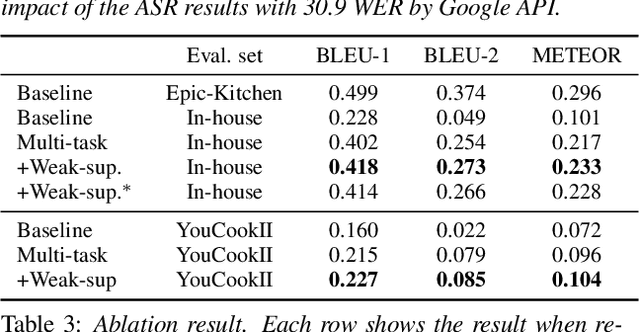
To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 26, 2023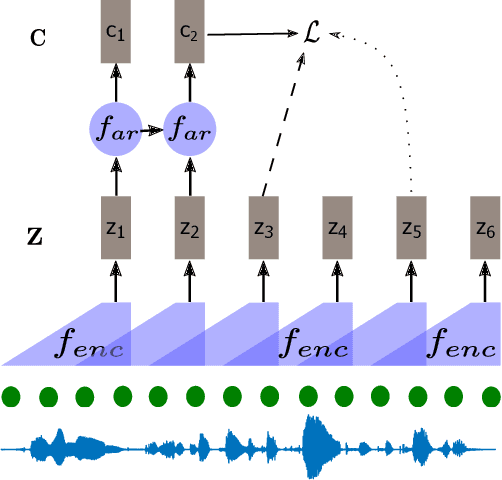
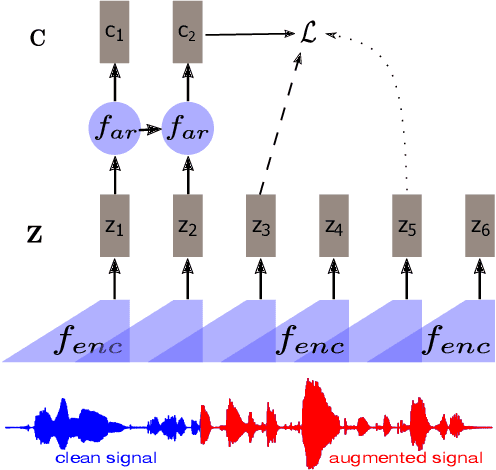
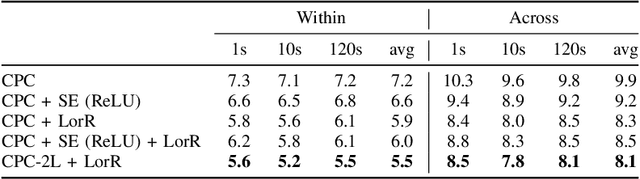
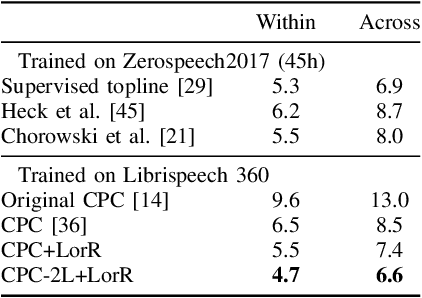
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-Right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models on the ABX task.
VoxSnap: X-Large Speaker Verification Dataset on Camera
Aug 14, 2023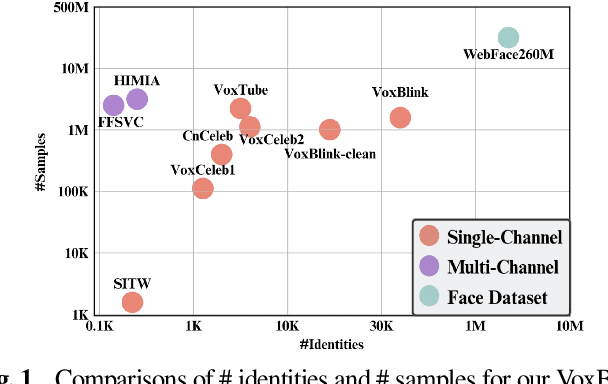
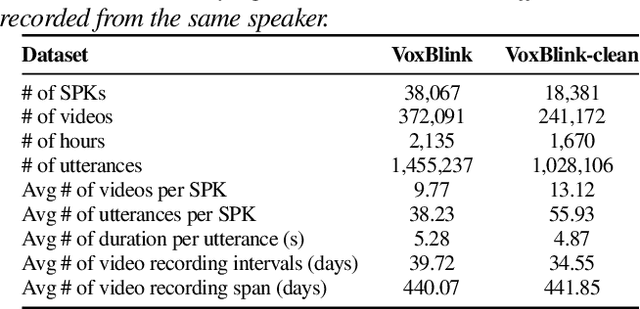
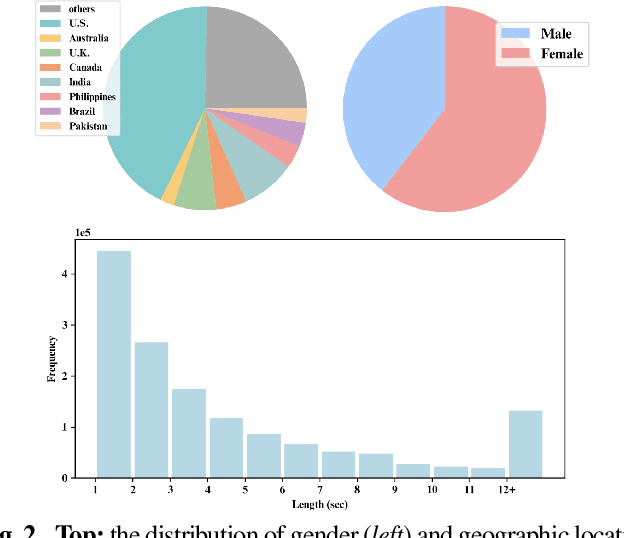
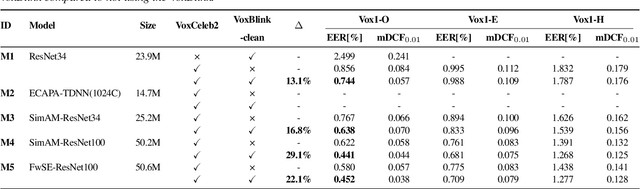
In this paper, we contribute a novel and extensive dataset for speaker verification, which contains noisy 38k identities/1.45M utterances (VoxSnap) and relatively cleaned 18k identities/1.02M (VoxSnap-Clean) utterances for training. Firstly, we collect a 60K+ users' list as well as their avatar and download their SHORT videos on the YouTube. Then, an automatically pipeline is devised to extract target user's speech segments and videos, which is efficient and scalable. To the best of our knowledge, the VoxSnap dataset is the largest speaker recognition dataset. Secondly, we develop a series of experiments based on VoxSnap-clean together with VoxCeleb2. Our findings highlight a notable improvement in performance, ranging from 15% to 30%, across different backbone architectures, upon integrating our dataset for training. The dataset will be released SOON~.
Towards cross-language prosody transfer for dialog
Jul 09, 2023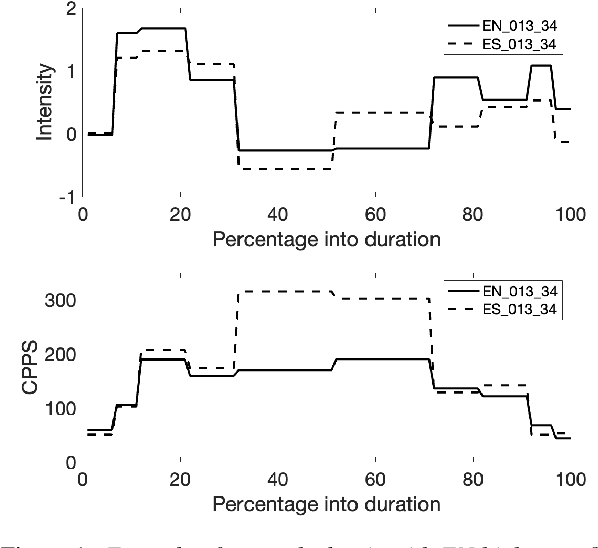



Speech-to-speech translation systems today do not adequately support use for dialog purposes. In particular, nuances of speaker intent and stance can be lost due to improper prosody transfer. We present an exploration of what needs to be done to overcome this. First, we developed a data collection protocol in which bilingual speakers re-enact utterances from an earlier conversation in their other language, and used this to collect an English-Spanish corpus, so far comprising 1871 matched utterance pairs. Second, we developed a simple prosodic dissimilarity metric based on Euclidean distance over a broad set of prosodic features. We then used these to investigate cross-language prosodic differences, measure the likely utility of three simple baseline models, and identify phenomena which will require more powerful modeling. Our findings should inform future research on cross-language prosody and the design of speech-to-speech translation systems capable of effective prosody transfer.
Adaptive Contextual Biasing for Transducer Based Streaming Speech Recognition
Jun 01, 2023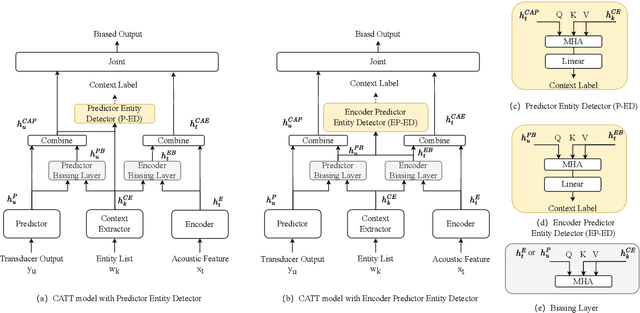

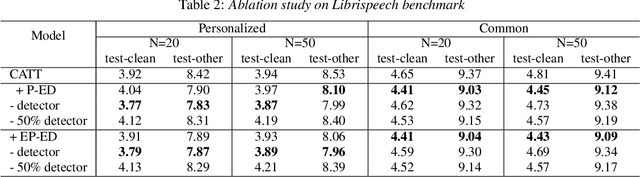
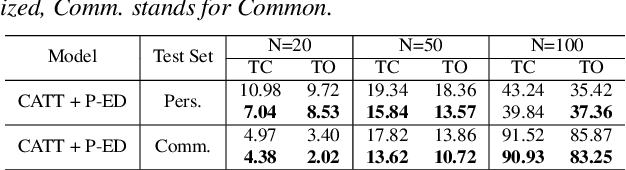
By incorporating additional contextual information, deep biasing methods have emerged as a promising solution for speech recognition of personalized words. However, for real-world voice assistants, always biasing on such personalized words with high prediction scores can significantly degrade the performance of recognizing common words. To address this issue, we propose an adaptive contextual biasing method based on Context-Aware Transformer Transducer (CATT) that utilizes the biased encoder and predictor embeddings to perform streaming prediction of contextual phrase occurrences. Such prediction is then used to dynamically switch the bias list on and off, enabling the model to adapt to both personalized and common scenarios. Experiments on Librispeech and internal voice assistant datasets show that our approach can achieve up to 6.7% and 20.7% relative reduction in WER and CER compared to the baseline respectively, mitigating up to 96.7% and 84.9% of the relative WER and CER increase for common cases. Furthermore, our approach has a minimal performance impact in personalized scenarios while maintaining a streaming inference pipeline with negligible RTF increase.
An End-to-End Multi-Module Audio Deepfake Generation System for ADD Challenge 2023
Jul 03, 2023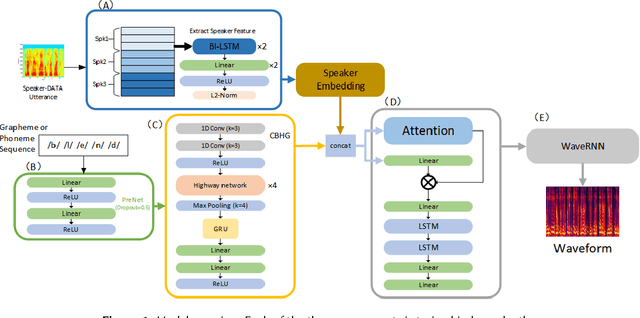
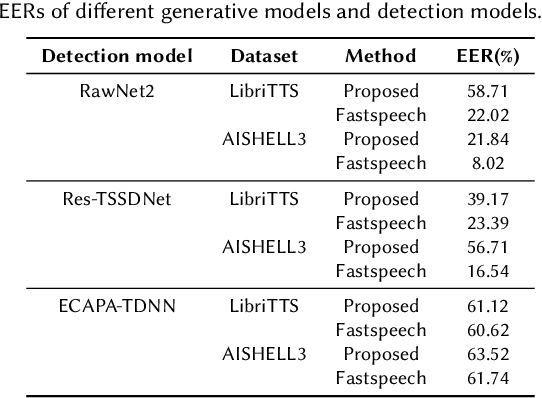
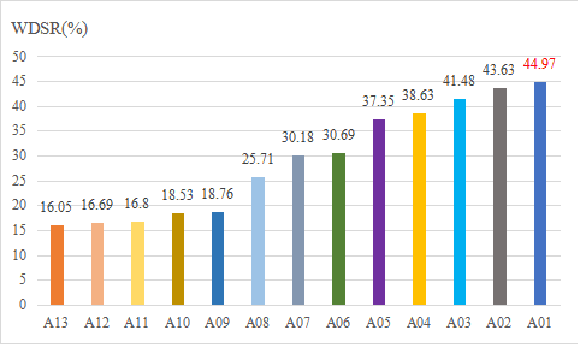
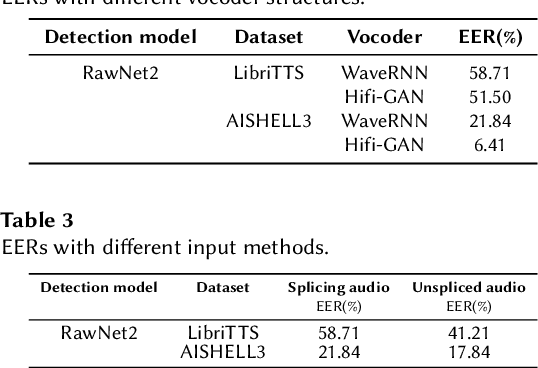
The task of synthetic speech generation is to generate language content from a given text, then simulating fake human voice.The key factors that determine the effect of synthetic speech generation mainly include speed of generation, accuracy of word segmentation, naturalness of synthesized speech, etc. This paper builds an end-to-end multi-module synthetic speech generation model, including speaker encoder, synthesizer based on Tacotron2, and vocoder based on WaveRNN. In addition, we perform a lot of comparative experiments on different datasets and various model structures. Finally, we won the first place in the ADD 2023 challenge Track 1.1 with the weighted deception success rate (WDSR) of 44.97%.
An Efficient Speech Separation Network Based on Recurrent Fusion Dilated Convolution and Channel Attention
Jun 09, 2023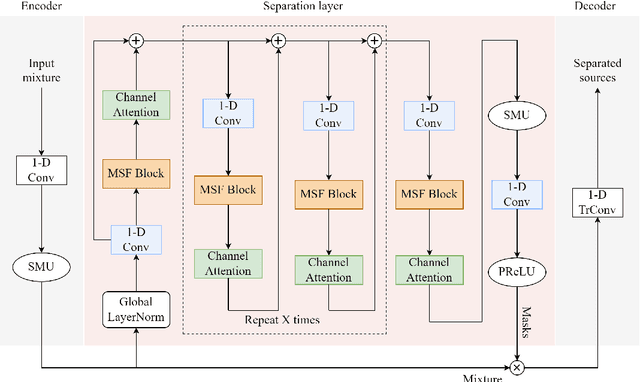
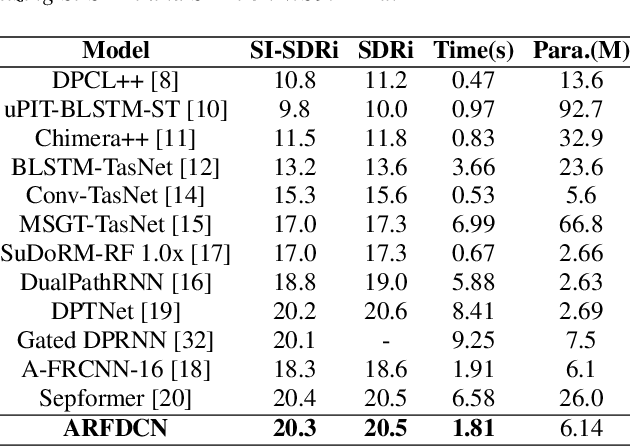
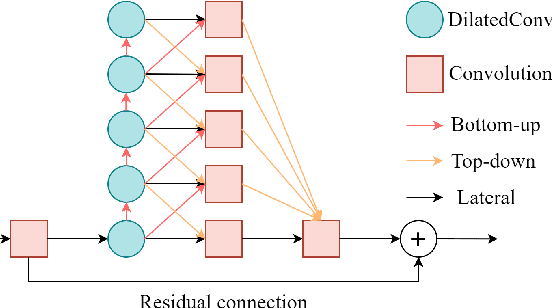
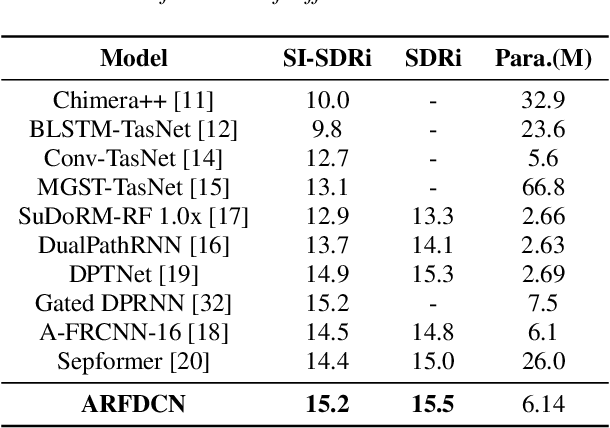
We present an efficient speech separation neural network, ARFDCN, which combines dilated convolutions, multi-scale fusion (MSF), and channel attention to overcome the limited receptive field of convolution-based networks and the high computational cost of transformer-based networks. The suggested network architecture is encoder-decoder based. By using dilated convolutions with gradually increasing dilation value to learn local and global features and fusing them at adjacent stages, the model can learn rich feature content. Meanwhile, by adding channel attention modules to the network, the model can extract channel weights, learn more important features, and thus improve its expressive power and robustness. Experimental results indicate that the model achieves a decent balance between performance and computational efficiency, making it a promising alternative to current mainstream models for practical applications.
GNCformer Enhanced Self-attention for Automatic Speech Recognition
May 22, 2023
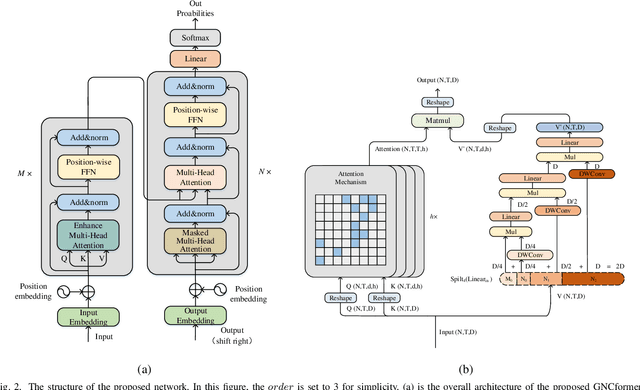
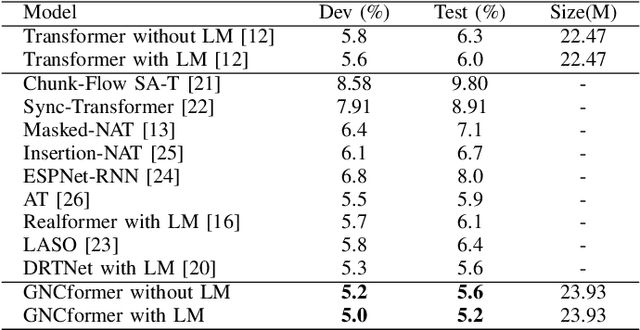

In this paper,an Enhanced Self-Attention (ESA) mechanism has been put forward for robust feature extraction.The proposed ESA is integrated with the recursive gated convolution and self-attention mechanism.In particular, the former is used to capture multi-order feature interaction and the latter is for global feature extraction.In addition, the location of interest that is suitable for inserting the ESA is also worth being explored.In this paper, the ESA is embedded into the encoder layer of the Transformer network for automatic speech recognition (ASR) tasks, and this newly proposed model is named GNCformer. The effectiveness of the GNCformer has been validated using two datasets, that are Aishell-1 and HKUST.Experimental results show that, compared with the Transformer network,0.8%CER,and 1.2%CER improvement for these two mentioned datasets, respectively, can be achieved.It is worth mentioning that only 1.4M additional parameters have been involved in our proposed GNCformer.
Turkish Native Language Identification
Aug 04, 2023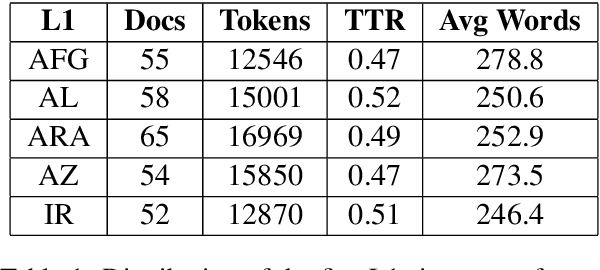
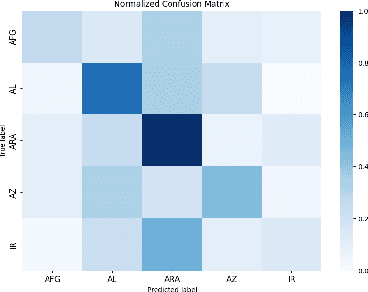
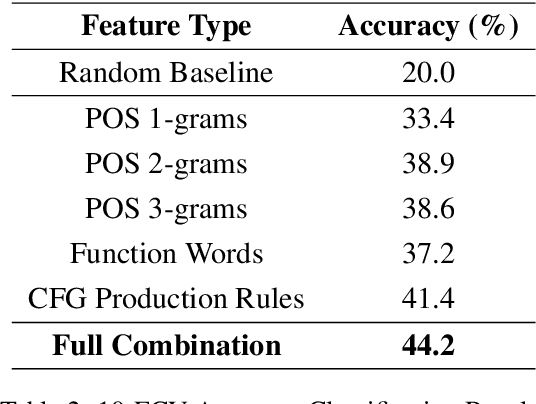
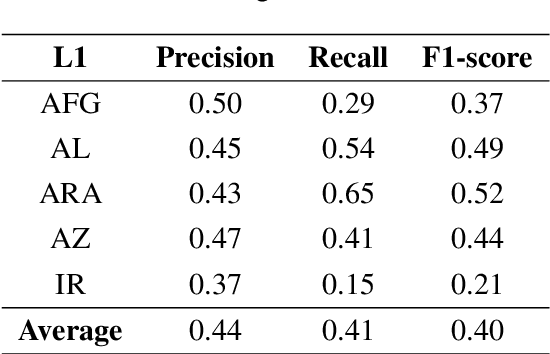
In this paper, we present the first application of Native Language Identification (NLI) for the Turkish language. NLI involves predicting the writer's first language by analysing their writing in different languages. While most NLI research has focused on English, our study extends its scope to Turkish. We used the recently constructed Turkish Learner Corpus and employed a combination of three syntactic features (CFG production rules, part-of-speech n-grams, and function words) with L2 texts to demonstrate their effectiveness in this task.
NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning
Jun 21, 2023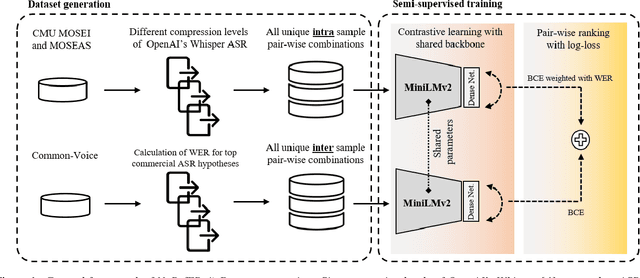
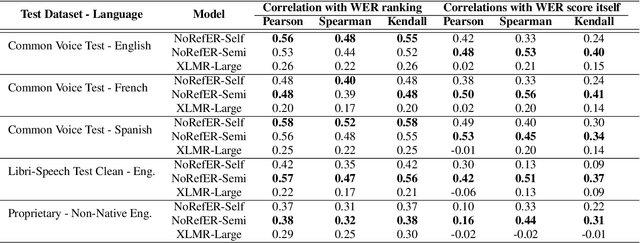
This paper introduces NoRefER, a novel referenceless quality metric for automatic speech recognition (ASR) systems. Traditional reference-based metrics for evaluating ASR systems require costly ground-truth transcripts. NoRefER overcomes this limitation by fine-tuning a multilingual language model for pair-wise ranking ASR hypotheses using contrastive learning with Siamese network architecture. The self-supervised NoRefER exploits the known quality relationships between hypotheses from multiple compression levels of an ASR for learning to rank intra-sample hypotheses by quality, which is essential for model comparisons. The semi-supervised version also uses a referenced dataset to improve its inter-sample quality ranking, which is crucial for selecting potentially erroneous samples. The results indicate that NoRefER correlates highly with reference-based metrics and their intra-sample ranks, indicating a high potential for referenceless ASR evaluation or a/b testing.