 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving TTS for Shanghainese: Addressing Tone Sandhi via Word Segmentation
Jul 30, 2023

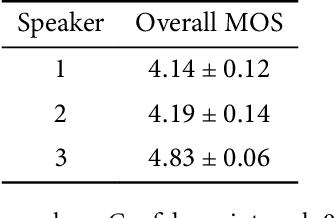
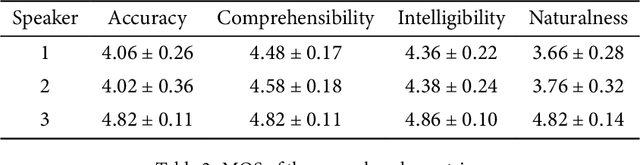
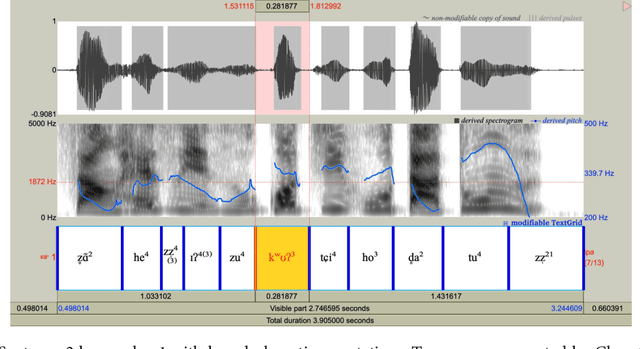
Tone is a crucial component of the prosody of Shanghainese, a Wu Chinese variety spoken primarily in urban Shanghai. Tone sandhi, which applies to all multi-syllabic words in Shanghainese, then, is key to natural-sounding speech. Unfortunately, recent work on Shanghainese TTS (text-to-speech) such as Apple's VoiceOver has shown poor performance with tone sandhi, especially LD (left-dominant sandhi). Here I show that word segmentation during text preprocessing can improve the quality of tone sandhi production in TTS models. Syllables within the same word are annotated with a special symbol, which serves as a proxy for prosodic information of the domain of LD. Contrary to the common practice of using prosodic annotation mainly for static pauses, this paper demonstrates that prosodic annotation can also be applied to dynamic tonal phenomena. I anticipate this project to be a starting point for bringing formal linguistic accounts of Shanghainese into computational projects. Too long have we been using the Mandarin models to approximate Shanghainese, but it is a different language with its own linguistic features, and its digitisation and revitalisation should be treated as such.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023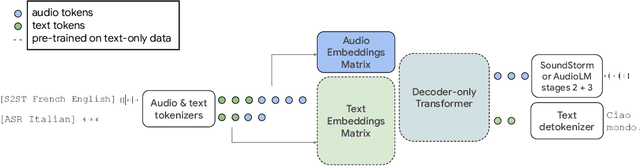



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
TSSR: A Truncated and Signed Square Root Activation Function for Neural Networks
Aug 09, 2023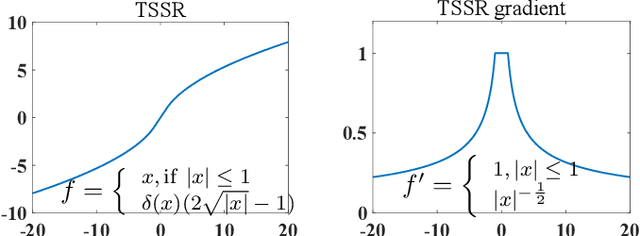
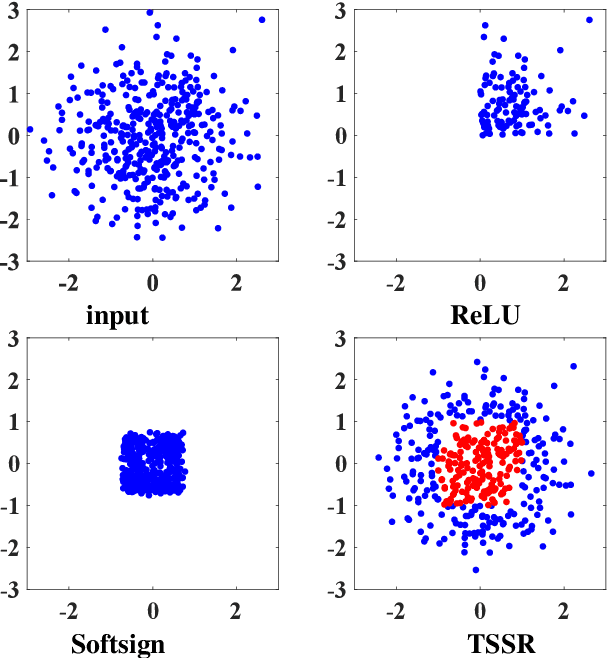
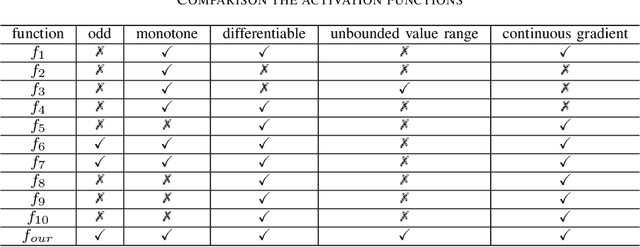
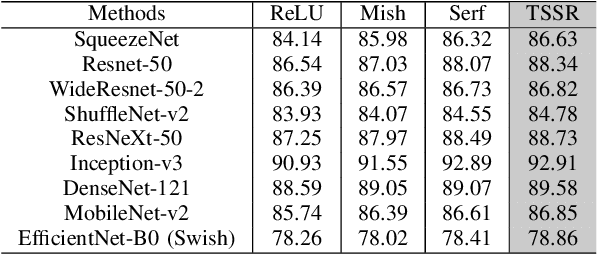
Activation functions are essential components of neural networks. In this paper, we introduce a new activation function called the Truncated and Signed Square Root (TSSR) function. This function is distinctive because it is odd, nonlinear, monotone and differentiable. Its gradient is continuous and always positive. Thanks to these properties, it has the potential to improve the numerical stability of neural networks. Several experiments confirm that the proposed TSSR has better performance than other stat-of-the-art activation functions. The proposed function has significant implications for the development of neural network models and can be applied to a wide range of applications in fields such as computer vision, natural language processing, and speech recognition.
Classifying Rhoticity of /r/ in Speech Sound Disorder using Age-and-Sex Normalized Formants
May 25, 2023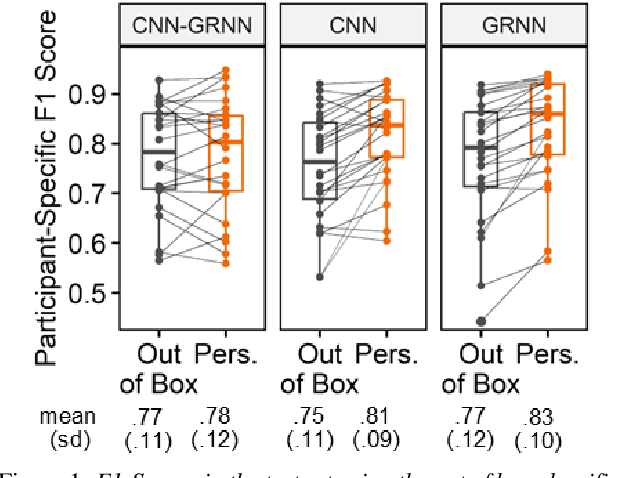

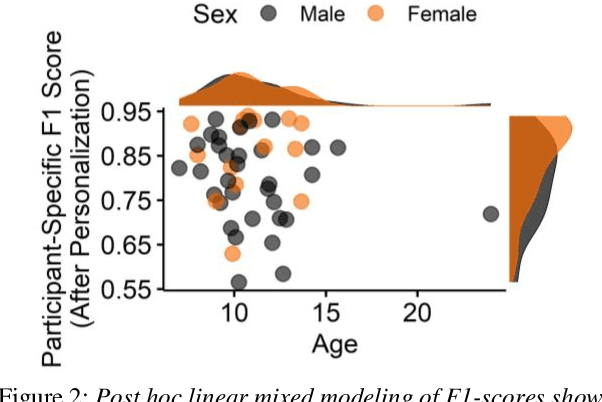
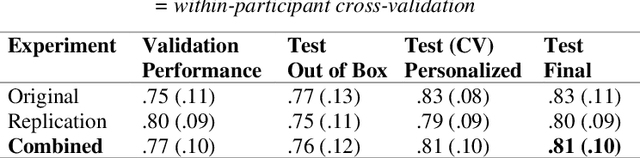
Mispronunciation detection tools could increase treatment access for speech sound disorders impacting, e.g., /r/. We show age-and-sex normalized formant estimation outperforms cepstral representation for detection of fully rhotic vs. derhotic /r/ in the PERCEPT-R Corpus. Gated recurrent neural networks trained on this feature set achieve a mean test participant-specific F1-score =.81 ({\sigma}x=.10, med = .83, n = 48), with post hoc modeling showing no significant effect of child age or sex.
Investigating the Sensitivity of Automatic Speech Recognition Systems to Phonetic Variation in L2 Englishes
May 12, 2023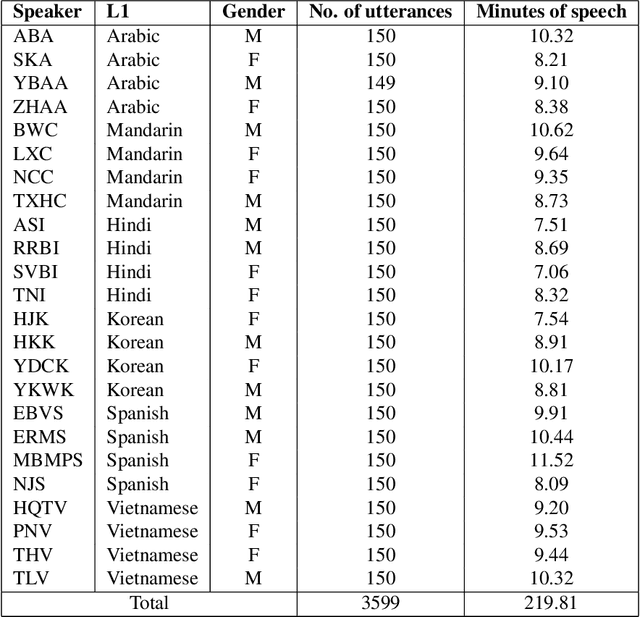
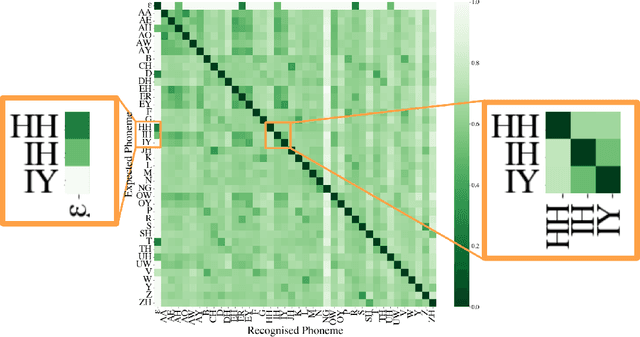
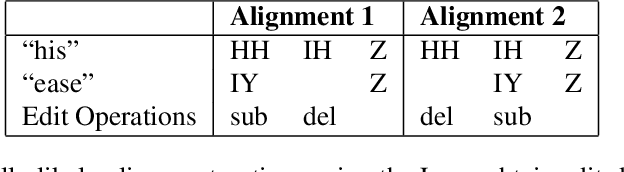
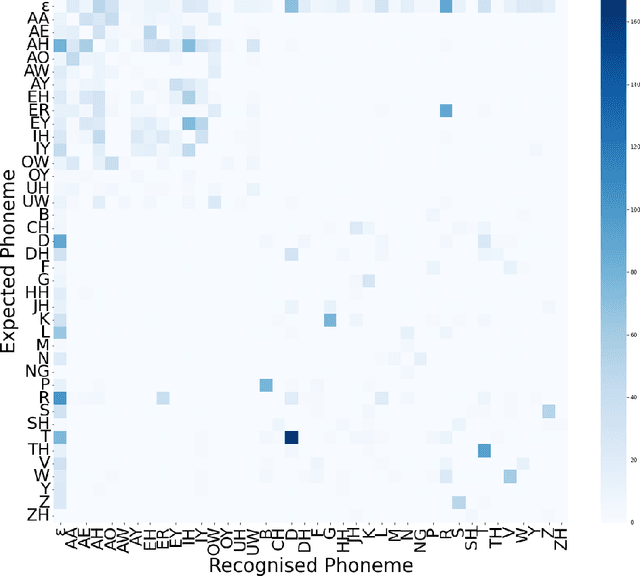
Automatic Speech Recognition (ASR) systems exhibit the best performance on speech that is similar to that on which it was trained. As such, underrepresented varieties including regional dialects, minority-speakers, and low-resource languages, see much higher word error rates (WERs) than those varieties seen as 'prestigious', 'mainstream', or 'standard'. This can act as a barrier to incorporating ASR technology into the annotation process for large-scale linguistic research since the manual correction of the erroneous automated transcripts can be just as time and resource consuming as manual transcriptions. A deeper understanding of the behaviour of an ASR system is thus beneficial from a speech technology standpoint, in terms of improving ASR accuracy, and from an annotation standpoint, where knowing the likely errors made by an ASR system can aid in this manual correction. This work demonstrates a method of probing an ASR system to discover how it handles phonetic variation across a number of L2 Englishes. Specifically, how particular phonetic realisations which were rare or absent in the system's training data can lead to phoneme level misrecognitions and contribute to higher WERs. It is demonstrated that the behaviour of the ASR is systematic and consistent across speakers with similar spoken varieties (in this case the same L1) and phoneme substitution errors are typically in agreement with human annotators. By identifying problematic productions specific weaknesses can be addressed by sourcing such realisations for training and fine-tuning thus making the system more robust to pronunciation variation.
LAHM : Large Annotated Dataset for Multi-Domain and Multilingual Hate Speech Identification
Apr 03, 2023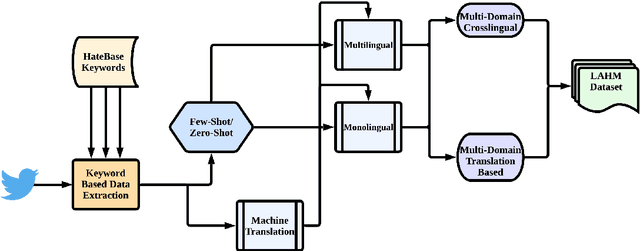
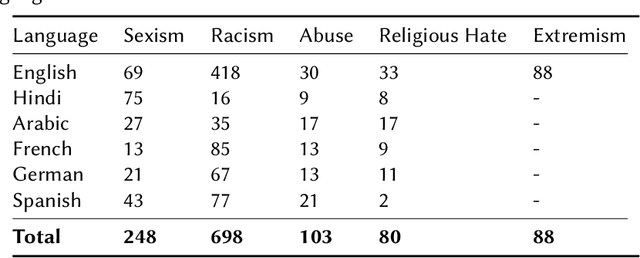
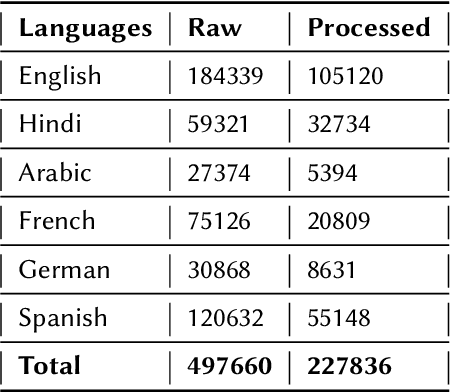
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual hate speech analysis dataset for English, Hindi, Arabic, French, German and Spanish languages for multiple domains across hate speech - Abuse, Racism, Sexism, Religious Hate and Extremism. To the best of our knowledge, this paper is the first to address the problem of identifying various types of hate speech in these five wide domains in these six languages. In this work, we describe how we created the dataset, created annotations at high level and low level for different domains and how we use it to test the current state-of-the-art multilingual and multitask learning approaches. We evaluate our dataset in various monolingual, cross-lingual and machine translation classification settings and compare it against open source English datasets that we aggregated and merged for this task. Then we discuss how this approach can be used to create large scale hate-speech datasets and how to leverage our annotations in order to improve hate speech detection and classification in general.
Basic syntax from speech: Spontaneous concatenation in unsupervised deep neural networks
May 02, 2023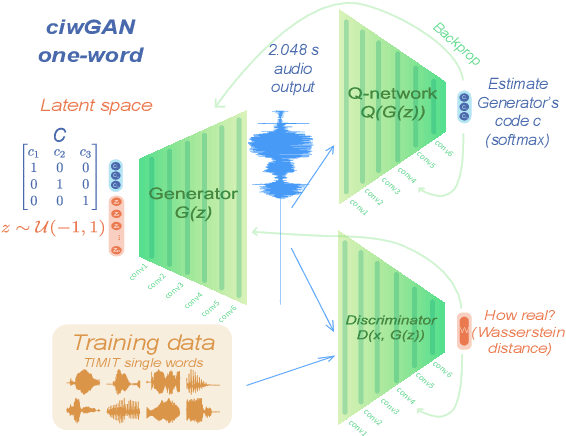

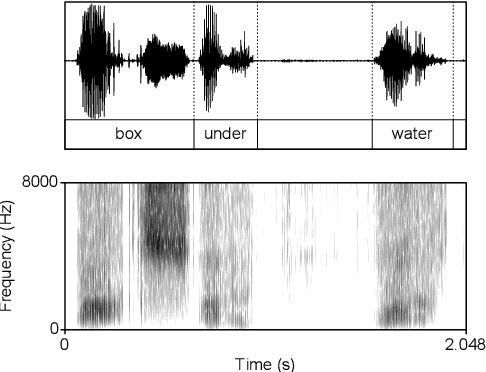
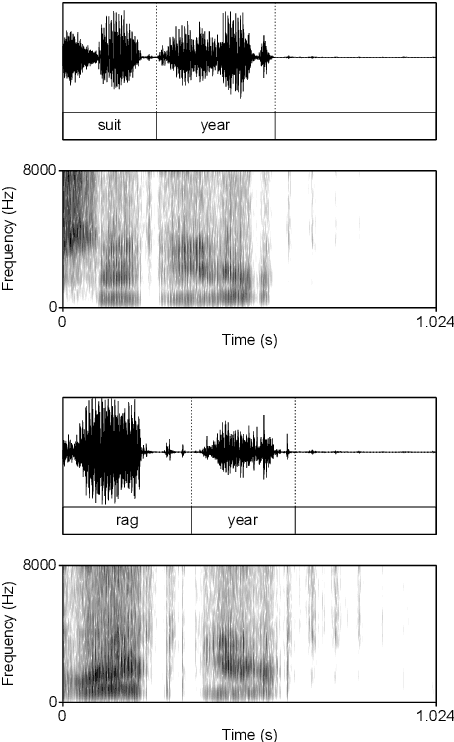
Computational models of syntax are predominantly text-based. Here we propose that basic syntax can be modeled directly from raw speech in a fully unsupervised way. We focus on one of the most ubiquitous and basic properties of syntax -- concatenation. We introduce spontaneous concatenation: a phenomenon where convolutional neural networks (CNNs) trained on acoustic recordings of individual words start generating outputs with two or even three words concatenated without ever accessing data with multiple words in the input. Additionally, networks trained on two words learn to embed words into novel unobserved word combinations. To our knowledge, this is a previously unreported property of CNNs trained on raw speech in the Generative Adversarial Network setting and has implications both for our understanding of how these architectures learn as well as for modeling syntax and its evolution from raw acoustic inputs.
MC-DRE: Multi-Aspect Cross Integration for Drug Event/Entity Extraction
Aug 15, 2023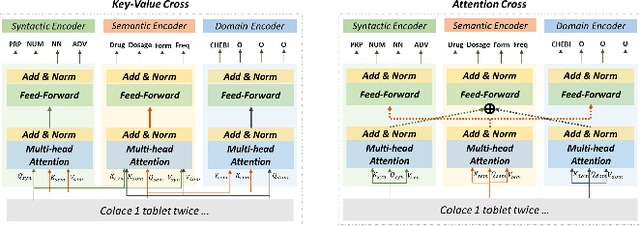
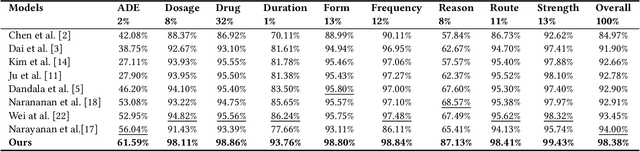

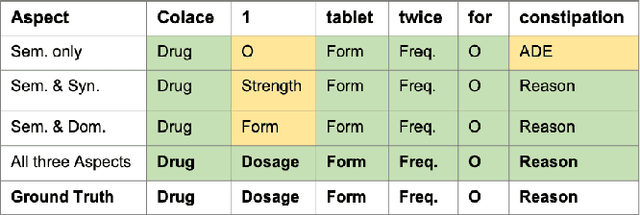
Extracting meaningful drug-related information chunks, such as adverse drug events (ADE), is crucial for preventing morbidity and saving many lives. Most ADEs are reported via an unstructured conversation with the medical context, so applying a general entity recognition approach is not sufficient enough. In this paper, we propose a new multi-aspect cross-integration framework for drug entity/event detection by capturing and aligning different context/language/knowledge properties from drug-related documents. We first construct multi-aspect encoders to describe semantic, syntactic, and medical document contextual information by conducting those slot tagging tasks, main drug entity/event detection, part-of-speech tagging, and general medical named entity recognition. Then, each encoder conducts cross-integration with other contextual information in three ways: the key-value cross, attention cross, and feedforward cross, so the multi-encoders are integrated in depth. Our model outperforms all SOTA on two widely used tasks, flat entity detection and discontinuous event extraction.
End-to-End Open Vocabulary Keyword Search With Multilingual Neural Representations
Aug 15, 2023Conventional keyword search systems operate on automatic speech recognition (ASR) outputs, which causes them to have a complex indexing and search pipeline. This has led to interest in ASR-free approaches to simplify the search procedure. We recently proposed a neural ASR-free keyword search model which achieves competitive performance while maintaining an efficient and simplified pipeline, where queries and documents are encoded with a pair of recurrent neural network encoders and the encodings are combined with a dot-product. In this article, we extend this work with multilingual pretraining and detailed analysis of the model. Our experiments show that the proposed multilingual training significantly improves the model performance and that despite not matching a strong ASR-based conventional keyword search system for short queries and queries comprising in-vocabulary words, the proposed model outperforms the ASR-based system for long queries and queries that do not appear in the training data.
* Accepted by IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2023
AI in the Gray: Exploring Moderation Policies in Dialogic Large Language Models vs. Human Answers in Controversial Topics
Aug 28, 2023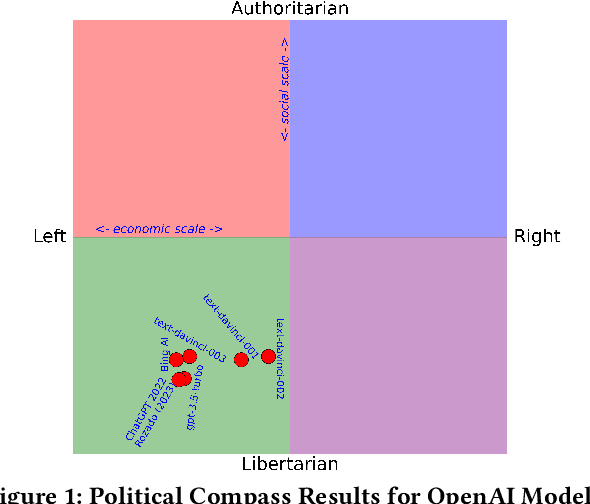

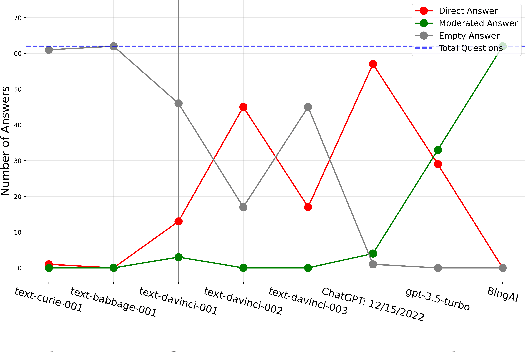

The introduction of ChatGPT and the subsequent improvement of Large Language Models (LLMs) have prompted more and more individuals to turn to the use of ChatBots, both for information and assistance with decision-making. However, the information the user is after is often not formulated by these ChatBots objectively enough to be provided with a definite, globally accepted answer. Controversial topics, such as "religion", "gender identity", "freedom of speech", and "equality", among others, can be a source of conflict as partisan or biased answers can reinforce preconceived notions or promote disinformation. By exposing ChatGPT to such debatable questions, we aim to understand its level of awareness and if existing models are subject to socio-political and/or economic biases. We also aim to explore how AI-generated answers compare to human ones. For exploring this, we use a dataset of a social media platform created for the purpose of debating human-generated claims on polemic subjects among users, dubbed Kialo. Our results show that while previous versions of ChatGPT have had important issues with controversial topics, more recent versions of ChatGPT (gpt-3.5-turbo) are no longer manifesting significant explicit biases in several knowledge areas. In particular, it is well-moderated regarding economic aspects. However, it still maintains degrees of implicit libertarian leaning toward right-winged ideals which suggest the need for increased moderation from the socio-political point of view. In terms of domain knowledge on controversial topics, with the exception of the "Philosophical" category, ChatGPT is performing well in keeping up with the collective human level of knowledge. Finally, we see that sources of Bing AI have slightly more tendency to the center when compared to human answers. All the analyses we make are generalizable to other types of biases and domains.