 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Adaptive Contextual Biasing for Transducer Based Streaming Speech Recognition
Jun 01, 2023
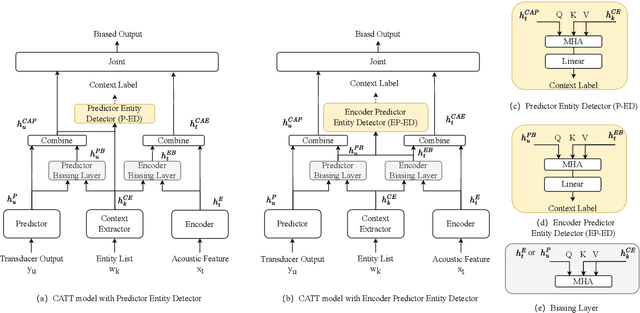

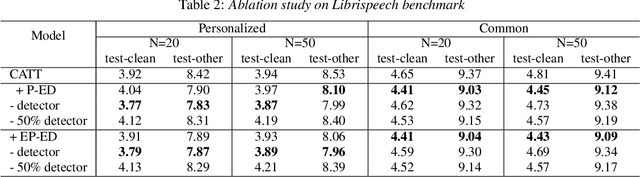
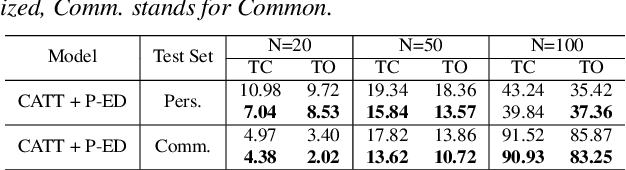
By incorporating additional contextual information, deep biasing methods have emerged as a promising solution for speech recognition of personalized words. However, for real-world voice assistants, always biasing on such personalized words with high prediction scores can significantly degrade the performance of recognizing common words. To address this issue, we propose an adaptive contextual biasing method based on Context-Aware Transformer Transducer (CATT) that utilizes the biased encoder and predictor embeddings to perform streaming prediction of contextual phrase occurrences. Such prediction is then used to dynamically switch the bias list on and off, enabling the model to adapt to both personalized and common scenarios. Experiments on Librispeech and internal voice assistant datasets show that our approach can achieve up to 6.7% and 20.7% relative reduction in WER and CER compared to the baseline respectively, mitigating up to 96.7% and 84.9% of the relative WER and CER increase for common cases. Furthermore, our approach has a minimal performance impact in personalized scenarios while maintaining a streaming inference pipeline with negligible RTF increase.
An Efficient Speech Separation Network Based on Recurrent Fusion Dilated Convolution and Channel Attention
Jun 09, 2023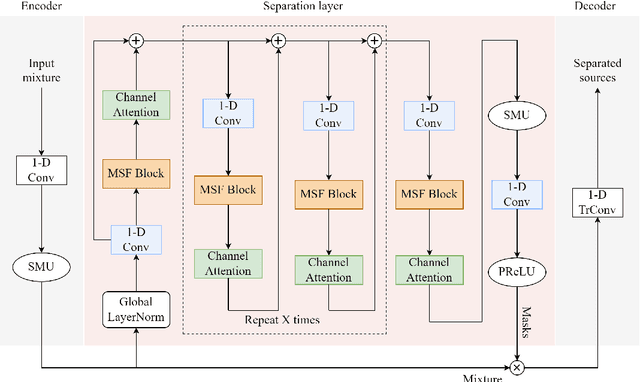
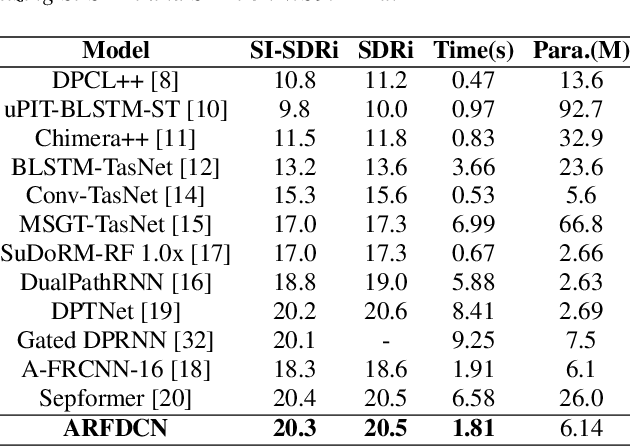
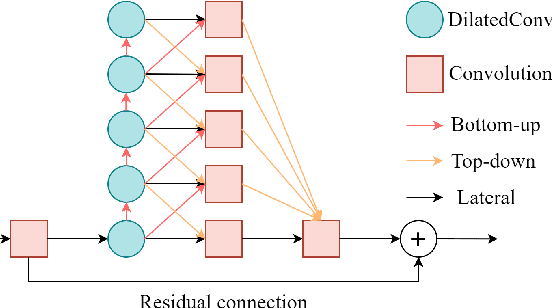
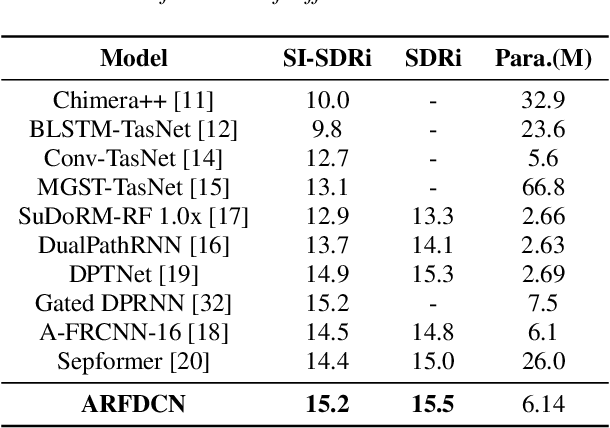
We present an efficient speech separation neural network, ARFDCN, which combines dilated convolutions, multi-scale fusion (MSF), and channel attention to overcome the limited receptive field of convolution-based networks and the high computational cost of transformer-based networks. The suggested network architecture is encoder-decoder based. By using dilated convolutions with gradually increasing dilation value to learn local and global features and fusing them at adjacent stages, the model can learn rich feature content. Meanwhile, by adding channel attention modules to the network, the model can extract channel weights, learn more important features, and thus improve its expressive power and robustness. Experimental results indicate that the model achieves a decent balance between performance and computational efficiency, making it a promising alternative to current mainstream models for practical applications.
Turkish Native Language Identification
Aug 04, 2023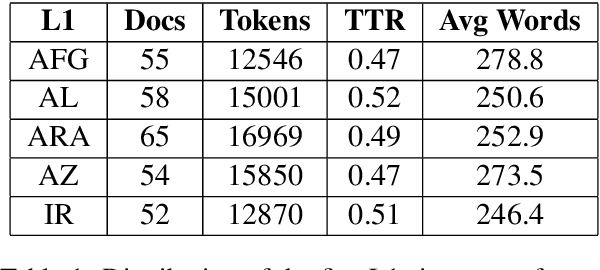
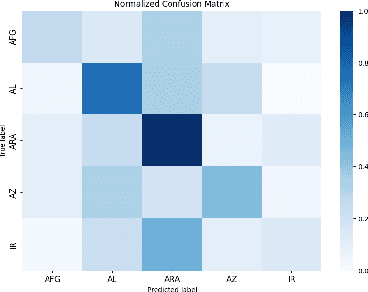
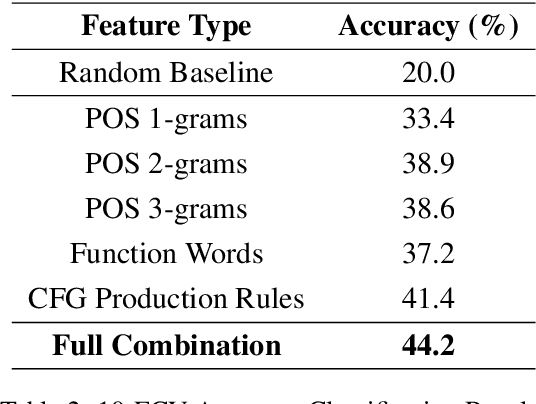
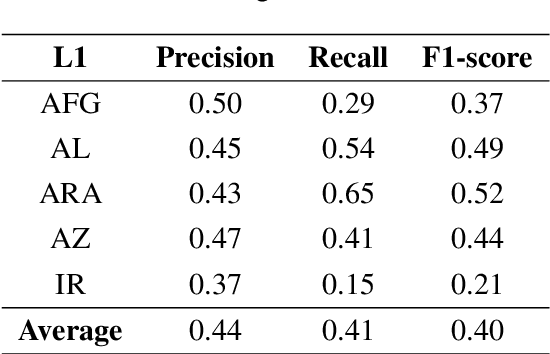
In this paper, we present the first application of Native Language Identification (NLI) for the Turkish language. NLI involves predicting the writer's first language by analysing their writing in different languages. While most NLI research has focused on English, our study extends its scope to Turkish. We used the recently constructed Turkish Learner Corpus and employed a combination of three syntactic features (CFG production rules, part-of-speech n-grams, and function words) with L2 texts to demonstrate their effectiveness in this task.
Rhythm Modeling for Voice Conversion
Jul 12, 2023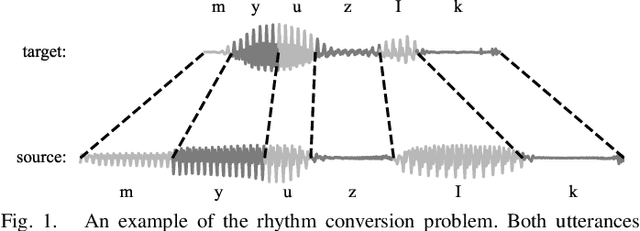

Voice conversion aims to transform source speech into a different target voice. However, typical voice conversion systems do not account for rhythm, which is an important factor in the perception of speaker identity. To bridge this gap, we introduce Urhythmic-an unsupervised method for rhythm conversion that does not require parallel data or text transcriptions. Using self-supervised representations, we first divide source audio into segments approximating sonorants, obstruents, and silences. Then we model rhythm by estimating speaking rate or the duration distribution of each segment type. Finally, we match the target speaking rate or rhythm by time-stretching the speech segments. Experiments show that Urhythmic outperforms existing unsupervised methods in terms of quality and prosody. Code and checkpoints: https://github.com/bshall/urhythmic. Audio demo page: https://ubisoft-laforge.github.io/speech/urhythmic.
NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning
Jun 21, 2023
This paper introduces NoRefER, a novel referenceless quality metric for automatic speech recognition (ASR) systems. Traditional reference-based metrics for evaluating ASR systems require costly ground-truth transcripts. NoRefER overcomes this limitation by fine-tuning a multilingual language model for pair-wise ranking ASR hypotheses using contrastive learning with Siamese network architecture. The self-supervised NoRefER exploits the known quality relationships between hypotheses from multiple compression levels of an ASR for learning to rank intra-sample hypotheses by quality, which is essential for model comparisons. The semi-supervised version also uses a referenced dataset to improve its inter-sample quality ranking, which is crucial for selecting potentially erroneous samples. The results indicate that NoRefER correlates highly with reference-based metrics and their intra-sample ranks, indicating a high potential for referenceless ASR evaluation or a/b testing.
Toward Generalizable Machine Learning Models in Speech, Language, and Hearing Sciences: Power Analysis and Sample Size Estimation
Aug 22, 2023
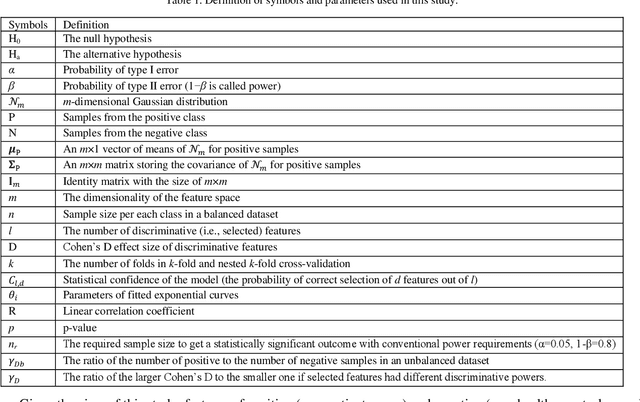
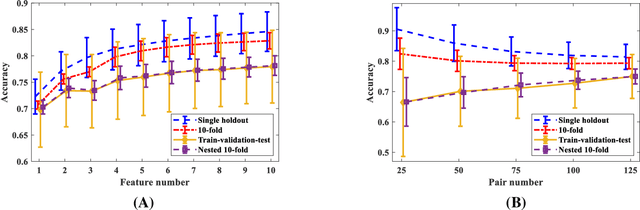

This study's first purpose is to provide quantitative evidence that would incentivize researchers to instead use the more robust method of nested cross-validation. The second purpose is to present methods and MATLAB codes for doing power analysis for ML-based analysis during the design of a study. Monte Carlo simulations were used to quantify the interactions between the employed cross-validation method, the discriminative power of features, the dimensionality of the feature space, and the dimensionality of the model. Four different cross-validations (single holdout, 10-fold, train-validation-test, and nested 10-fold) were compared based on the statistical power and statistical confidence of the ML models. Distributions of the null and alternative hypotheses were used to determine the minimum required sample size for obtaining a statistically significant outcome ({\alpha}=0.05, 1-\b{eta}=0.8). Statistical confidence of the model was defined as the probability of correct features being selected and hence being included in the final model. Our analysis showed that the model generated based on the single holdout method had very low statistical power and statistical confidence and that it significantly overestimated the accuracy. Conversely, the nested 10-fold cross-validation resulted in the highest statistical confidence and the highest statistical power, while providing an unbiased estimate of the accuracy. The required sample size with a single holdout could be 50% higher than what would be needed if nested cross-validation were used. Confidence in the model based on nested cross-validation was as much as four times higher than the confidence in the single holdout-based model. A computational model, MATLAB codes, and lookup tables are provided to assist researchers with estimating the sample size during the design of their future studies.
GNCformer Enhanced Self-attention for Automatic Speech Recognition
May 22, 2023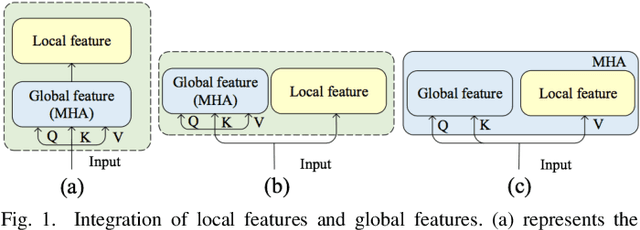
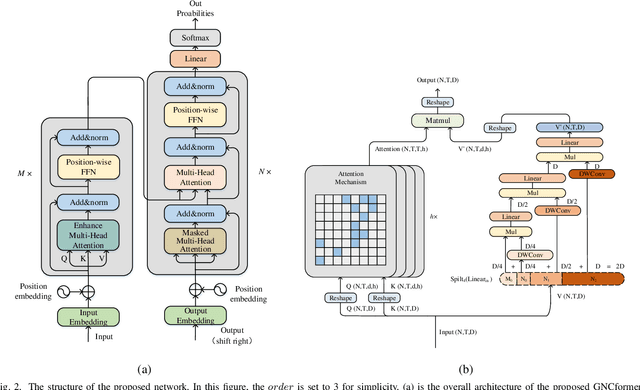
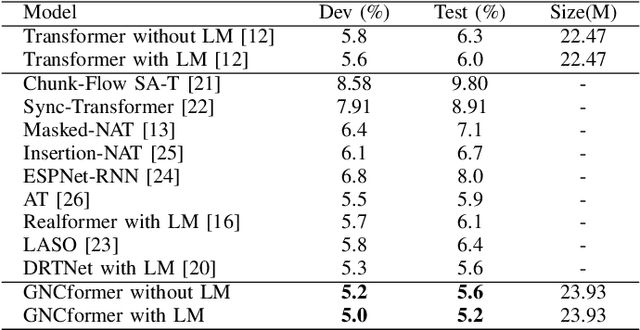

In this paper,an Enhanced Self-Attention (ESA) mechanism has been put forward for robust feature extraction.The proposed ESA is integrated with the recursive gated convolution and self-attention mechanism.In particular, the former is used to capture multi-order feature interaction and the latter is for global feature extraction.In addition, the location of interest that is suitable for inserting the ESA is also worth being explored.In this paper, the ESA is embedded into the encoder layer of the Transformer network for automatic speech recognition (ASR) tasks, and this newly proposed model is named GNCformer. The effectiveness of the GNCformer has been validated using two datasets, that are Aishell-1 and HKUST.Experimental results show that, compared with the Transformer network,0.8%CER,and 1.2%CER improvement for these two mentioned datasets, respectively, can be achieved.It is worth mentioning that only 1.4M additional parameters have been involved in our proposed GNCformer.
Fine-Tuning Llama 2 Large Language Models for Detecting Online Sexual Predatory Chats and Abusive Texts
Aug 28, 2023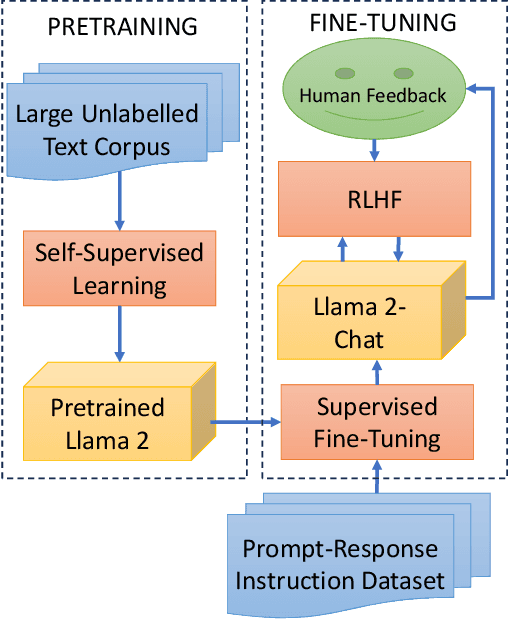
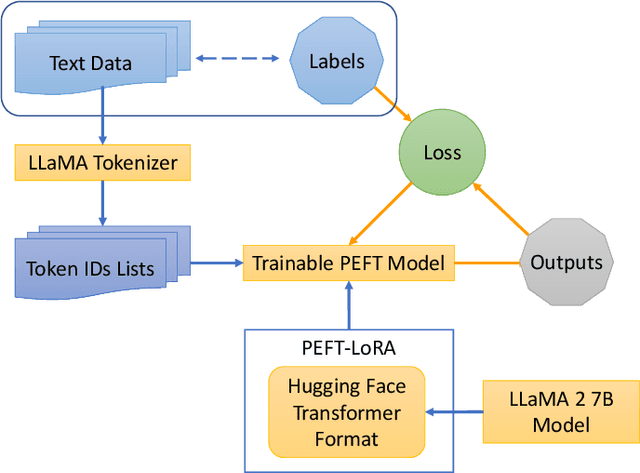

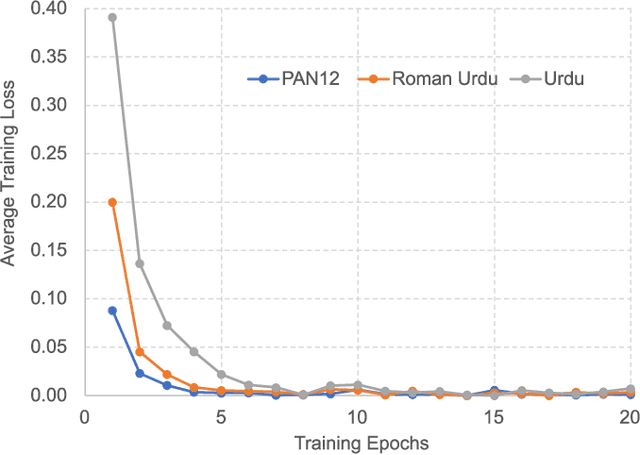
Detecting online sexual predatory behaviours and abusive language on social media platforms has become a critical area of research due to the growing concerns about online safety, especially for vulnerable populations such as children and adolescents. Researchers have been exploring various techniques and approaches to develop effective detection systems that can identify and mitigate these risks. Recent development of large language models (LLMs) has opened a new opportunity to address this problem more effectively. This paper proposes an approach to detection of online sexual predatory chats and abusive language using the open-source pretrained Llama 2 7B-parameter model, recently released by Meta GenAI. We fine-tune the LLM using datasets with different sizes, imbalance degrees, and languages (i.e., English, Roman Urdu and Urdu). Based on the power of LLMs, our approach is generic and automated without a manual search for a synergy between feature extraction and classifier design steps like conventional methods in this domain. Experimental results show a strong performance of the proposed approach, which performs proficiently and consistently across three distinct datasets with five sets of experiments. This study's outcomes indicate that the proposed method can be implemented in real-world applications (even with non-English languages) for flagging sexual predators, offensive or toxic content, hate speech, and discriminatory language in online discussions and comments to maintain respectful internet or digital communities. Furthermore, it can be employed for solving text classification problems with other potential applications such as sentiment analysis, spam and phishing detection, sorting legal documents, fake news detection, language identification, user intent recognition, text-based product categorization, medical record analysis, and resume screening.
Lenient Evaluation of Japanese Speech Recognition: Modeling Naturally Occurring Spelling Inconsistency
Jun 07, 2023
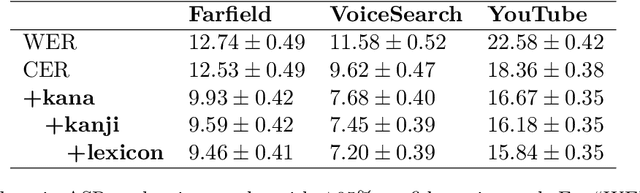
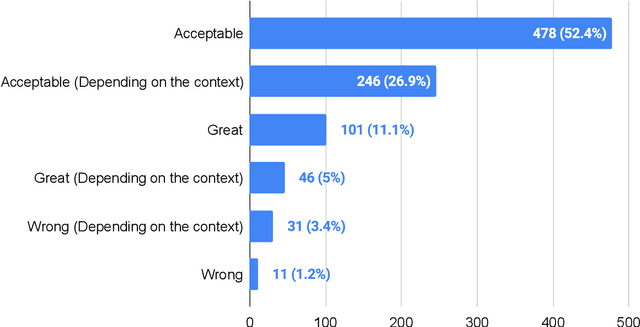
Word error rate (WER) and character error rate (CER) are standard metrics in Speech Recognition (ASR), but one problem has always been alternative spellings: If one's system transcribes adviser whereas the ground truth has advisor, this will count as an error even though the two spellings really represent the same word. Japanese is notorious for ``lacking orthography'': most words can be spelled in multiple ways, presenting a problem for accurate ASR evaluation. In this paper we propose a new lenient evaluation metric as a more defensible CER measure for Japanese ASR. We create a lattice of plausible respellings of the reference transcription, using a combination of lexical resources, a Japanese text-processing system, and a neural machine translation model for reconstructing kanji from hiragana or katakana. In a manual evaluation, raters rated 95.4% of the proposed spelling variants as plausible. ASR results show that our method, which does not penalize the system for choosing a valid alternate spelling of a word, affords a 2.4%-3.1% absolute reduction in CER depending on the task.
AQ-GT: a Temporally Aligned and Quantized GRU-Transformer for Co-Speech Gesture Synthesis
May 08, 2023
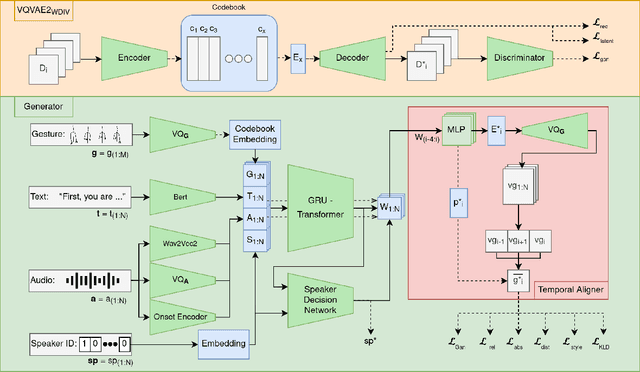
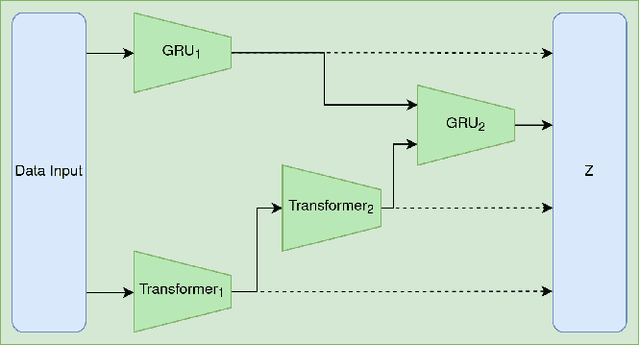
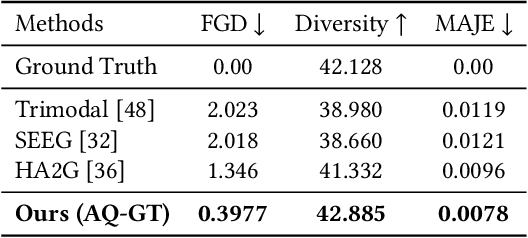
The generation of realistic and contextually relevant co-speech gestures is a challenging yet increasingly important task in the creation of multimodal artificial agents. Prior methods focused on learning a direct correspondence between co-speech gesture representations and produced motions, which created seemingly natural but often unconvincing gestures during human assessment. We present an approach to pre-train partial gesture sequences using a generative adversarial network with a quantization pipeline. The resulting codebook vectors serve as both input and output in our framework, forming the basis for the generation and reconstruction of gestures. By learning the mapping of a latent space representation as opposed to directly mapping it to a vector representation, this framework facilitates the generation of highly realistic and expressive gestures that closely replicate human movement and behavior, while simultaneously avoiding artifacts in the generation process. We evaluate our approach by comparing it with established methods for generating co-speech gestures as well as with existing datasets of human behavior. We also perform an ablation study to assess our findings. The results show that our approach outperforms the current state of the art by a clear margin and is partially indistinguishable from human gesturing. We make our data pipeline and the generation framework publicly available.