 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Sentence Embedding Models for Ancient Greek Using Multilingual Knowledge Distillation
Aug 24, 2023
Contextual language models have been trained on Classical languages, including Ancient Greek and Latin, for tasks such as lemmatization, morphological tagging, part of speech tagging, authorship attribution, and detection of scribal errors. However, high-quality sentence embedding models for these historical languages are significantly more difficult to achieve due to the lack of training data. In this work, we use a multilingual knowledge distillation approach to train BERT models to produce sentence embeddings for Ancient Greek text. The state-of-the-art sentence embedding approaches for high-resource languages use massive datasets, but our distillation approach allows our Ancient Greek models to inherit the properties of these models while using a relatively small amount of translated sentence data. We build a parallel sentence dataset using a sentence-embedding alignment method to align Ancient Greek documents with English translations, and use this dataset to train our models. We evaluate our models on translation search, semantic similarity, and semantic retrieval tasks and investigate translation bias. We make our training and evaluation datasets freely available at https://github.com/kevinkrahn/ancient-greek-datasets .
SURT 2.0: Advances in Transducer-based Multi-talker Speech Recognition
Jun 18, 2023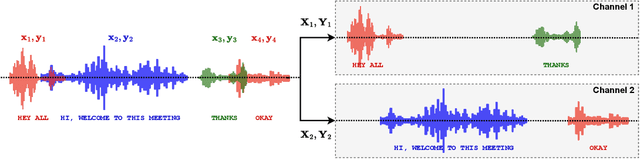
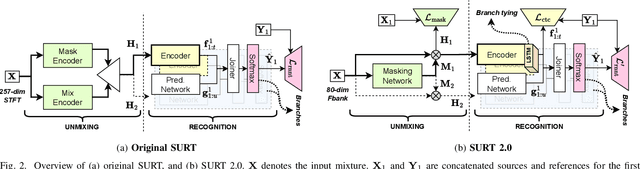
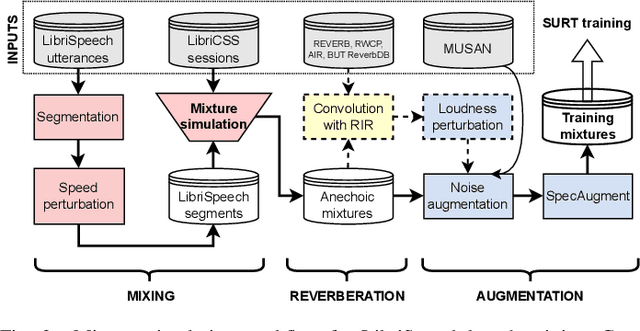
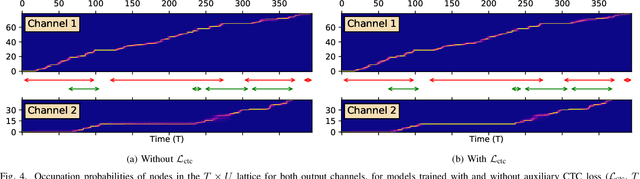
The Streaming Unmixing and Recognition Transducer (SURT) model was proposed recently as an end-to-end approach for continuous, streaming, multi-talker speech recognition (ASR). Despite impressive results on multi-turn meetings, SURT has notable limitations: (i) it suffers from leakage and omission related errors; (ii) it is computationally expensive, due to which it has not seen adoption in academia; and (iii) it has only been evaluated on synthetic mixtures. In this work, we propose several modifications to the original SURT which are carefully designed to fix the above limitations. In particular, we (i) change the unmixing module to a mask estimator that uses dual-path modeling, (ii) use a streaming zipformer encoder and a stateless decoder for the transducer, (iii) perform mixture simulation using force-aligned subsegments, (iv) pre-train the transducer on single-speaker data, (v) use auxiliary objectives in the form of masking loss and encoder CTC loss, and (vi) perform domain adaptation for far-field recognition. We show that our modifications allow SURT 2.0 to outperform its predecessor in terms of multi-talker ASR results, while being efficient enough to train with academic resources. We conduct our evaluations on 3 publicly available meeting benchmarks -- LibriCSS, AMI, and ICSI, where our best model achieves WERs of 16.9%, 44.6% and 32.2%, respectively, on far-field unsegmented recordings. We release training recipes and pre-trained models: https://sites.google.com/view/surt2.
HierVST: Hierarchical Adaptive Zero-shot Voice Style Transfer
Jul 30, 2023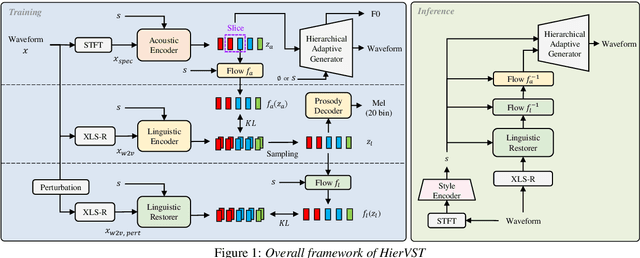
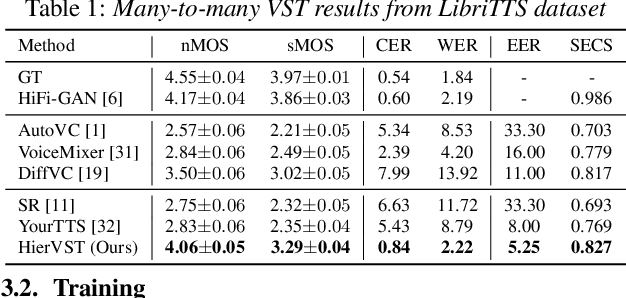
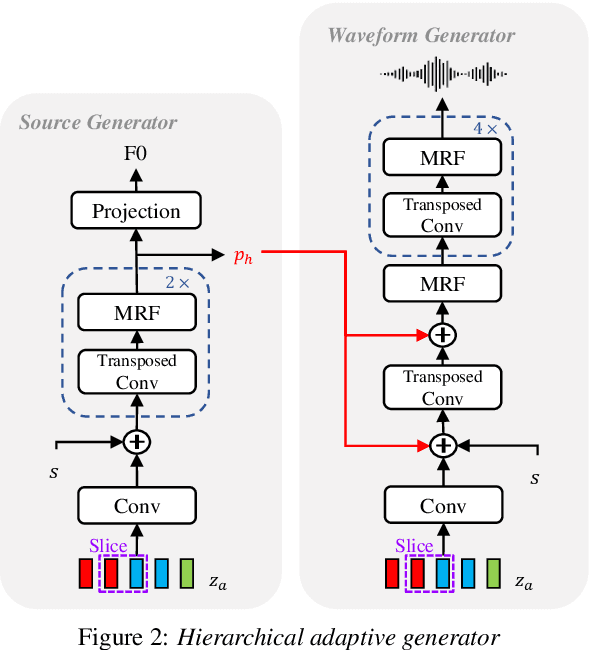
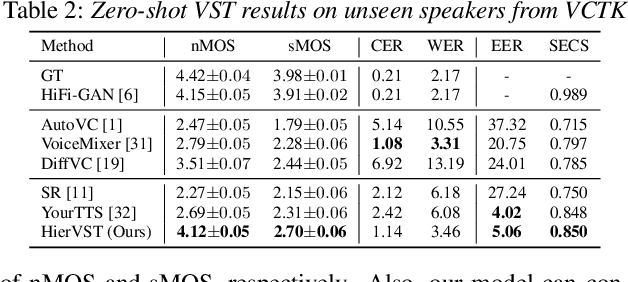
Despite rapid progress in the voice style transfer (VST) field, recent zero-shot VST systems still lack the ability to transfer the voice style of a novel speaker. In this paper, we present HierVST, a hierarchical adaptive end-to-end zero-shot VST model. Without any text transcripts, we only use the speech dataset to train the model by utilizing hierarchical variational inference and self-supervised representation. In addition, we adopt a hierarchical adaptive generator that generates the pitch representation and waveform audio sequentially. Moreover, we utilize unconditional generation to improve the speaker-relative acoustic capacity in the acoustic representation. With a hierarchical adaptive structure, the model can adapt to a novel voice style and convert speech progressively. The experimental results demonstrate that our method outperforms other VST models in zero-shot VST scenarios. Audio samples are available at \url{https://hiervst.github.io/}.
Multi-Head State Space Model for Speech Recognition
May 25, 2023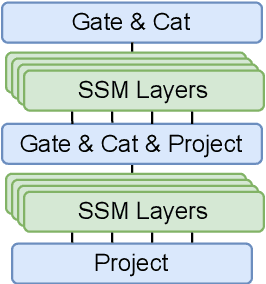
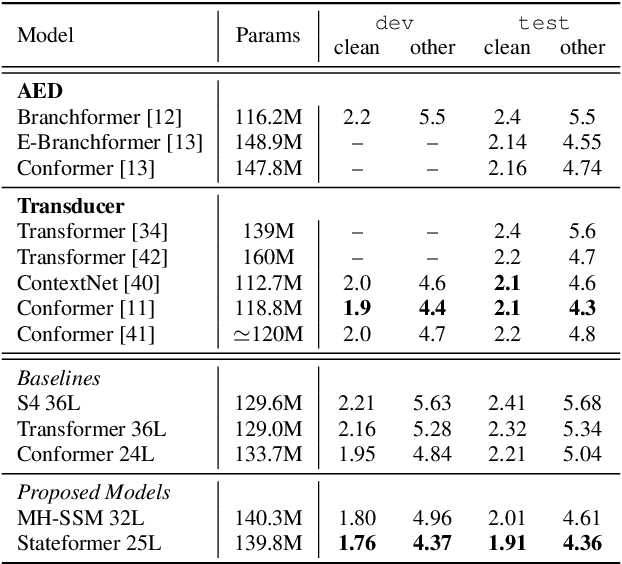
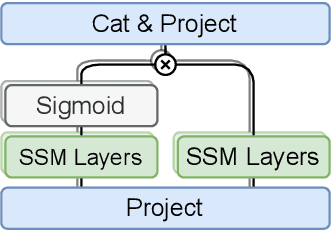
State space models (SSMs) have recently shown promising results on small-scale sequence and language modelling tasks, rivalling and outperforming many attention-based approaches. In this paper, we propose a multi-head state space (MH-SSM) architecture equipped with special gating mechanisms, where parallel heads are taught to learn local and global temporal dynamics on sequence data. As a drop-in replacement for multi-head attention in transformer encoders, this new model significantly outperforms the transformer transducer on the LibriSpeech speech recognition corpus. Furthermore, we augment the transformer block with MH-SSMs layers, referred to as the Stateformer, achieving state-of-the-art performance on the LibriSpeech task, with word error rates of 1.76\%/4.37\% on the development and 1.91\%/4.36\% on the test sets without using an external language model.
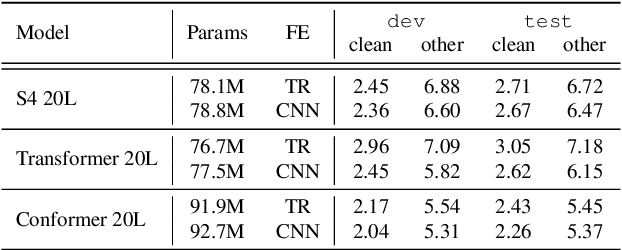
Multi-View Frequency-Attention Alternative to CNN Frontends for Automatic Speech Recognition
Jun 12, 2023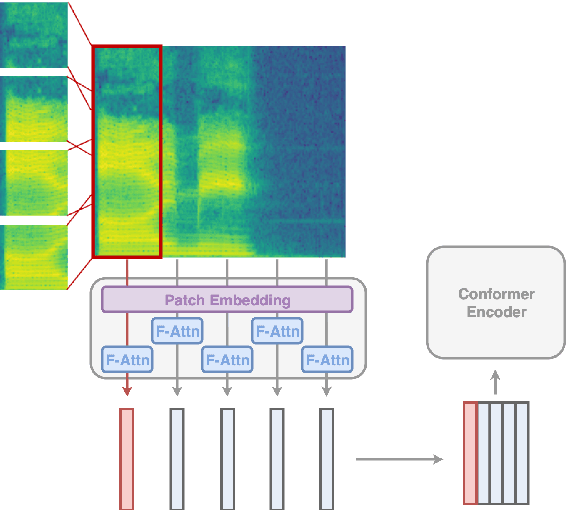
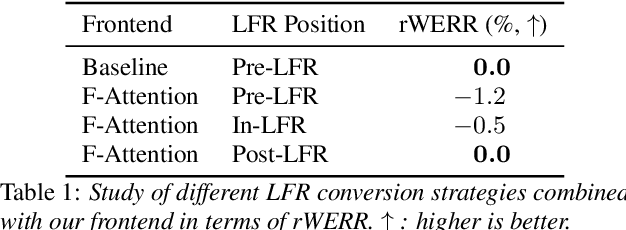
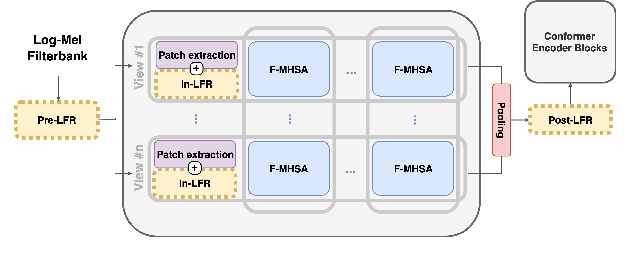
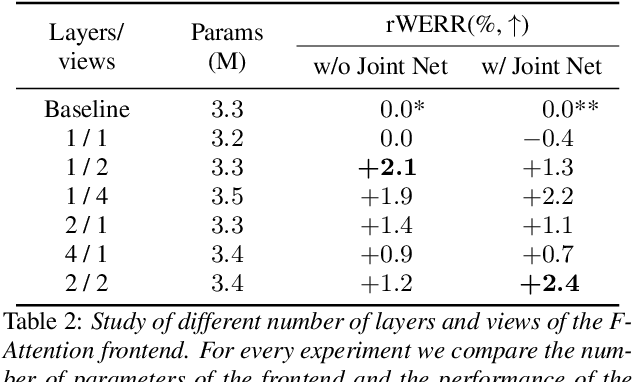
Convolutional frontends are a typical choice for Transformer-based automatic speech recognition to preprocess the spectrogram, reduce its sequence length, and combine local information in time and frequency similarly. However, the width and height of an audio spectrogram denote different information, e.g., due to reverberation as well as the articulatory system, the time axis has a clear left-to-right dependency. On the contrary, vowels and consonants demonstrate very different patterns and occupy almost disjoint frequency ranges. Therefore, we hypothesize, global attention over frequencies is beneficial over local convolution. We obtain 2.4 % relative word error rate reduction (rWERR) on a production scale Conformer transducer replacing its convolutional neural network frontend by the proposed F-Attention module on Alexa traffic. To demonstrate generalizability, we validate this on public LibriSpeech data with a long short term memory-based listen attend and spell architecture obtaining 4.6 % rWERR and demonstrate robustness to (simulated) noisy conditions.
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
Apr 18, 2023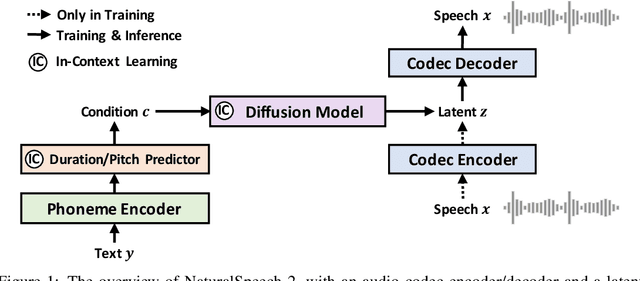


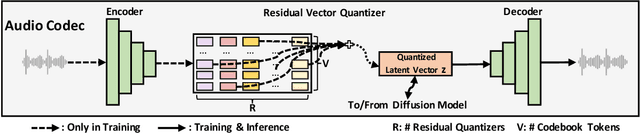
Scaling text-to-speech (TTS) to large-scale, multi-speaker, and in-the-wild datasets is important to capture the diversity in human speech such as speaker identities, prosodies, and styles (e.g., singing). Current large TTS systems usually quantize speech into discrete tokens and use language models to generate these tokens one by one, which suffer from unstable prosody, word skipping/repeating issue, and poor voice quality. In this paper, we develop NaturalSpeech 2, a TTS system that leverages a neural audio codec with residual vector quantizers to get the quantized latent vectors and uses a diffusion model to generate these latent vectors conditioned on text input. To enhance the zero-shot capability that is important to achieve diverse speech synthesis, we design a speech prompting mechanism to facilitate in-context learning in the diffusion model and the duration/pitch predictor. We scale NaturalSpeech 2 to large-scale datasets with 44K hours of speech and singing data and evaluate its voice quality on unseen speakers. NaturalSpeech 2 outperforms previous TTS systems by a large margin in terms of prosody/timbre similarity, robustness, and voice quality in a zero-shot setting, and performs novel zero-shot singing synthesis with only a speech prompt. Audio samples are available at https://speechresearch.github.io/naturalspeech2.
Enhancing Speech Articulation Analysis using a Geometric Transformation of the X-ray Microbeam Dataset
May 18, 2023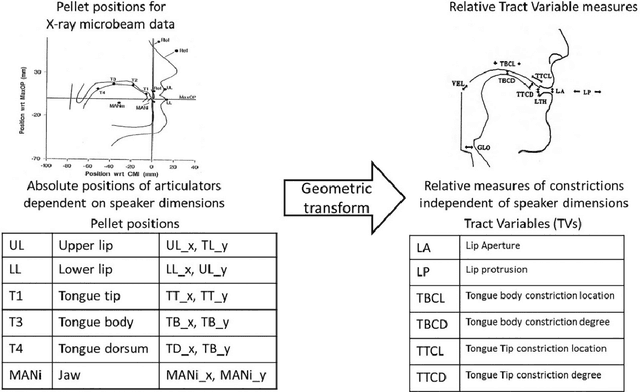
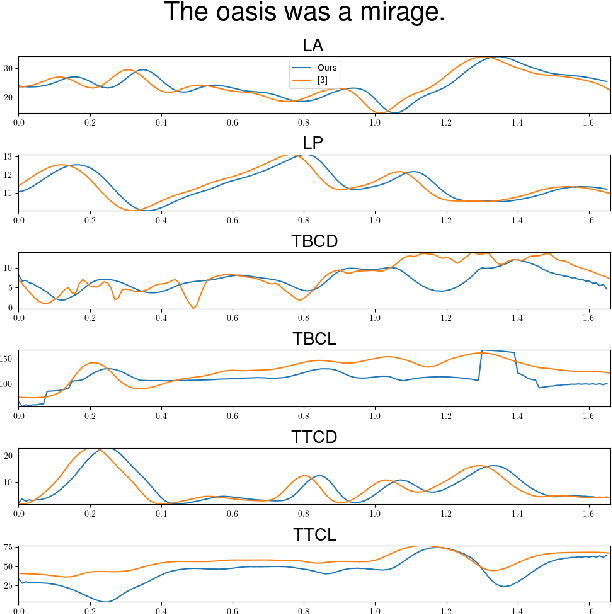
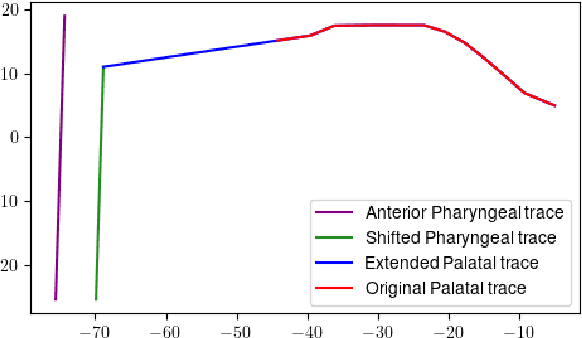
Accurate analysis of speech articulation is crucial for speech analysis. However, X-Y coordinates of articulators strongly depend on the anatomy of the speakers and the variability of pellet placements, and existing methods for mapping anatomical landmarks in the X-ray Microbeam Dataset (XRMB) fail to capture the entire anatomy of the vocal tract. In this paper, we propose a new geometric transformation that improves the accuracy of these measurements. Our transformation maps anatomical landmarks' X-Y coordinates along the midsagittal plane onto six relative measures: Lip Aperture (LA), Lip Protusion (LP), Tongue Body Constriction Location (TTCL), Degree (TBCD), Tongue Tip Constriction Location (TTCL) and Degree (TTCD). Our novel contribution is the extension of the palate trace towards the inferred anterior pharyngeal line, which improves measurements of tongue body constriction.
Attention-based Speech Enhancement Using Human Quality Perception Modelling
Mar 23, 2023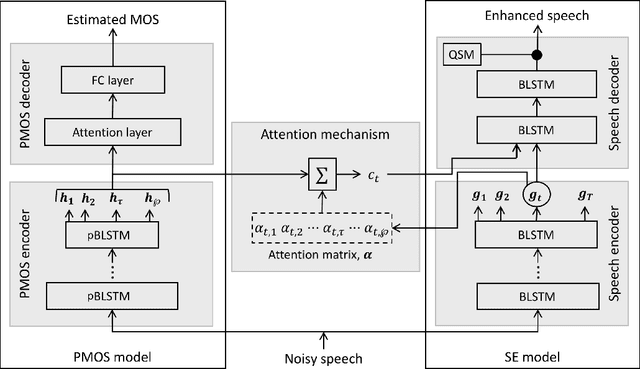
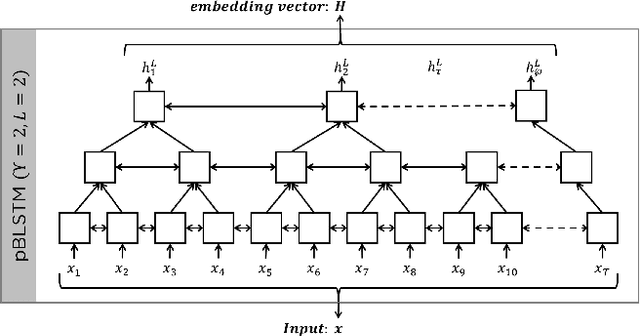
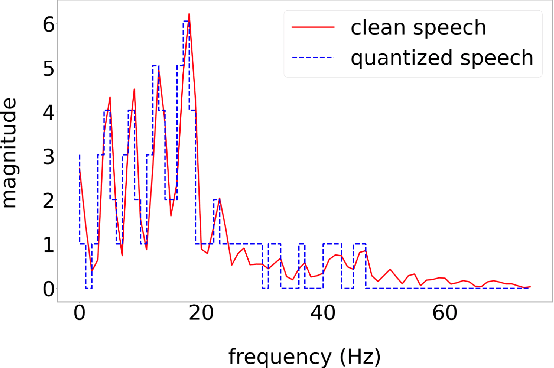
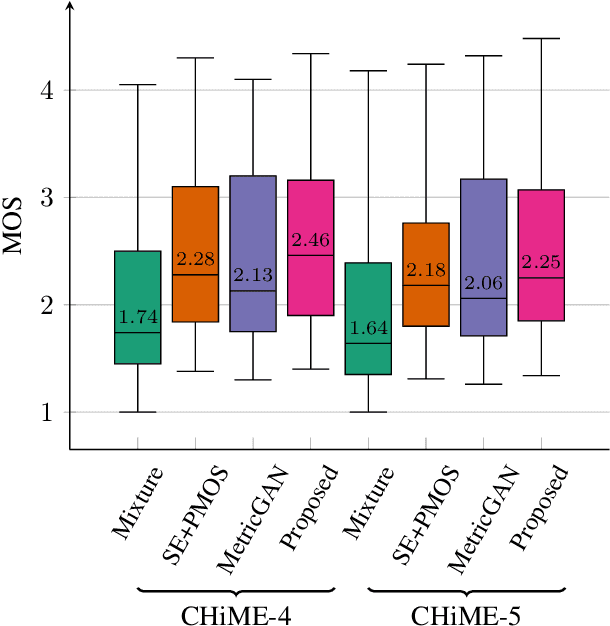
Perceptually-inspired objective functions such as the perceptual evaluation of speech quality (PESQ), signal-to-distortion ratio (SDR), and short-time objective intelligibility (STOI), have recently been used to optimize performance of deep-learning-based speech enhancement algorithms. These objective functions, however, do not always strongly correlate with a listener's assessment of perceptual quality, so optimizing with these measures often results in poorer performance in real-world scenarios. In this work, we propose an attention-based enhancement approach that uses learned speech embedding vectors from a mean-opinion score (MOS) prediction model and a speech enhancement module to jointly enhance noisy speech. The MOS prediction model estimates the perceptual MOS of speech quality, as assessed by human listeners, directly from the audio signal. The enhancement module also employs a quantized language model that enforces spectral constraints for better speech realism and performance. We train the model using real-world noisy speech data that has been captured in everyday environments and test it using unseen corpora. The results show that our proposed approach significantly outperforms other approaches that are optimized with objective measures, where the predicted quality scores strongly correlate with human judgments.
Multi-pass Training and Cross-information Fusion for Low-resource End-to-end Accented Speech Recognition
Jun 20, 2023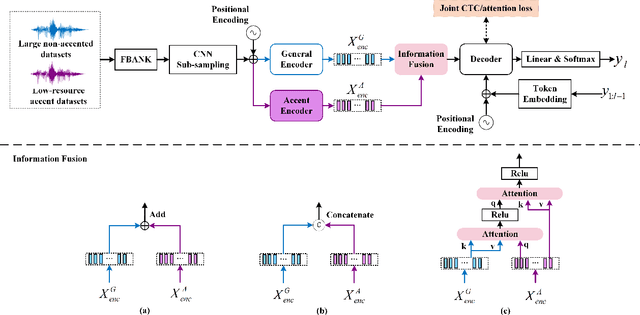
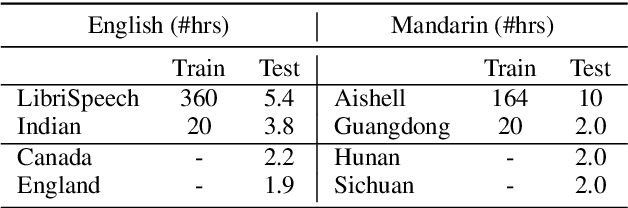

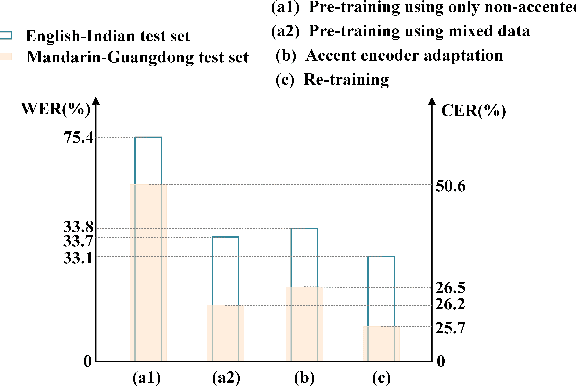
Low-resource accented speech recognition is one of the important challenges faced by current ASR technology in practical applications. In this study, we propose a Conformer-based architecture, called Aformer, to leverage both the acoustic information from large non-accented and limited accented training data. Specifically, a general encoder and an accent encoder are designed in the Aformer to extract complementary acoustic information. Moreover, we propose to train the Aformer in a multi-pass manner, and investigate three cross-information fusion methods to effectively combine the information from both general and accent encoders. All experiments are conducted on both the accented English and Mandarin ASR tasks. Results show that our proposed methods outperform the strong Conformer baseline by relative 10.2% to 24.5% word/character error rate reduction on six in-domain and out-of-domain accented test sets.
Characterization of cough sounds using statistical analysis
Aug 06, 2023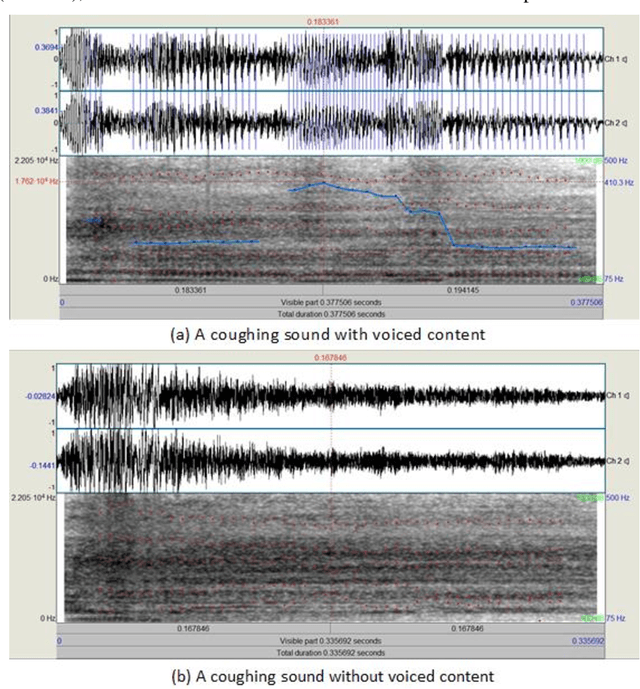
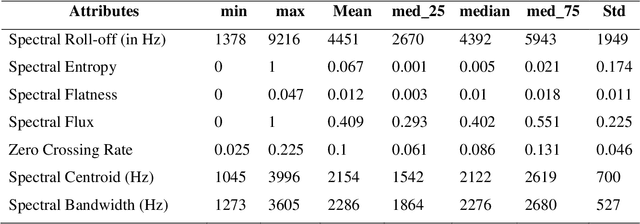
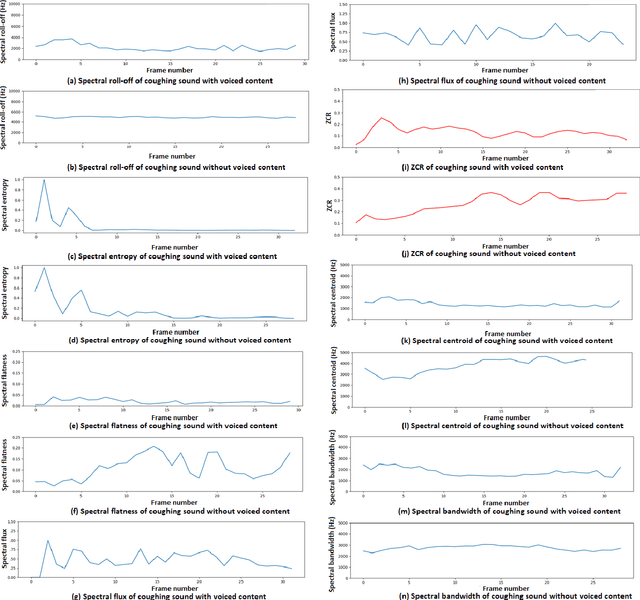
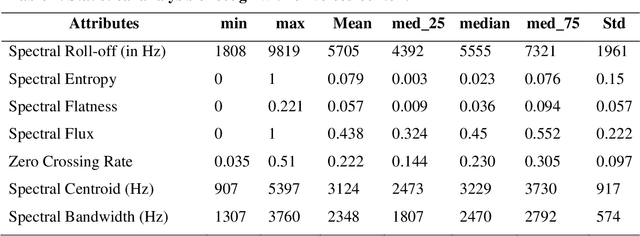
Cough is a primary symptom of most respiratory diseases, and changes in cough characteristics provide valuable information for diagnosing respiratory diseases. The characterization of cough sounds still lacks concrete evidence, which makes it difficult to accurately distinguish between different types of coughs and other sounds. The objective of this research work is to characterize cough sounds with voiced content and cough sounds without voiced content. Further, the cough sound characteristics are compared with the characteristics of speech. The proposed method to achieve this goal utilized spectral roll-off, spectral entropy, spectral flatness, spectral flux, zero crossing rate, spectral centroid, and spectral bandwidth attributes which describe the cough sounds related to the respiratory system, glottal information, and voice model. These attributes are then subjected to statistical analysis using the measures of minimum, maximum, mean, median, and standard deviation. The experimental results show that the mean and frequency distribution of spectral roll-off, spectral centroid, and spectral bandwidth are found to be higher for cough sounds than for speech signals. Spectral flatness levels in cough sounds will rise to 0.22, whereas spectral flux varies between 0.3 and 0.6. The Zero Crossing Rate (ZCR) of most frames of cough sounds is between 0.05 and 0.4. These attributes contribute significant information while characterizing cough sounds.