 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Towards an AI to Win Ghana's National Science and Maths Quiz
Aug 08, 2023

Can an AI win Ghana's National Science and Maths Quiz (NSMQ)? That is the question we seek to answer in the NSMQ AI project, an open-source project that is building AI to compete live in the NSMQ and win. The NSMQ is an annual live science and mathematics competition for senior secondary school students in Ghana in which 3 teams of 2 students compete by answering questions across biology, chemistry, physics, and math in 5 rounds over 5 progressive stages until a winning team is crowned for that year. The NSMQ is an exciting live quiz competition with interesting technical challenges across speech-to-text, text-to-speech, question-answering, and human-computer interaction. In this ongoing work that began in January 2023, we give an overview of the project, describe each of the teams, progress made thus far, and the next steps toward our planned launch and debut of the AI in October for NSMQ 2023. An AI that conquers this grand challenge can have real-world impact on education such as enabling millions of students across Africa to have one-on-one learning support from this AI.
Exploiting Time-Frequency Conformers for Music Audio Enhancement
Aug 24, 2023
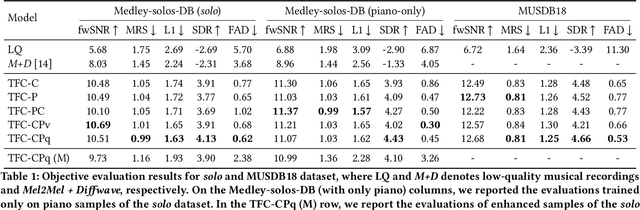
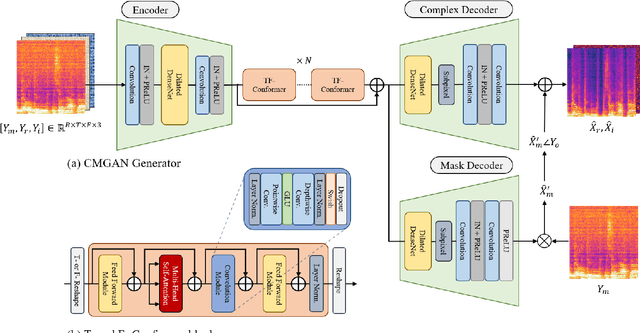
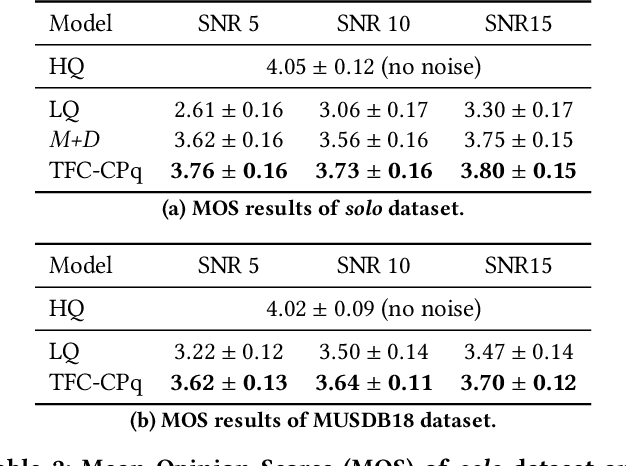
With the proliferation of video platforms on the internet, recording musical performances by mobile devices has become commonplace. However, these recordings often suffer from degradation such as noise and reverberation, which negatively impact the listening experience. Consequently, the necessity for music audio enhancement (referred to as music enhancement from this point onward), involving the transformation of degraded audio recordings into pristine high-quality music, has surged to augment the auditory experience. To address this issue, we propose a music enhancement system based on the Conformer architecture that has demonstrated outstanding performance in speech enhancement tasks. Our approach explores the attention mechanisms of the Conformer and examines their performance to discover the best approach for the music enhancement task. Our experimental results show that our proposed model achieves state-of-the-art performance on single-stem music enhancement. Furthermore, our system can perform general music enhancement with multi-track mixtures, which has not been examined in previous work.
Context-aware Coherent Speaking Style Prediction with Hierarchical Transformers for Audiobook Speech Synthesis
Apr 13, 2023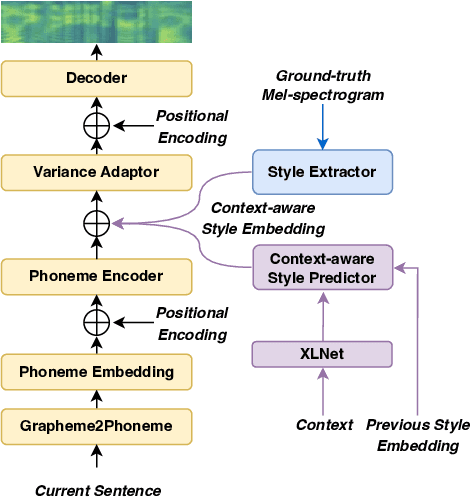
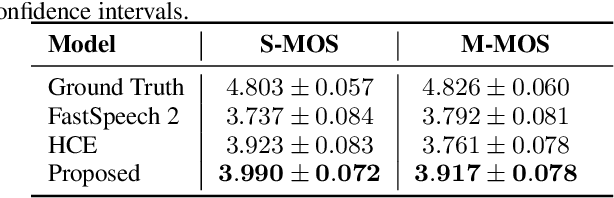
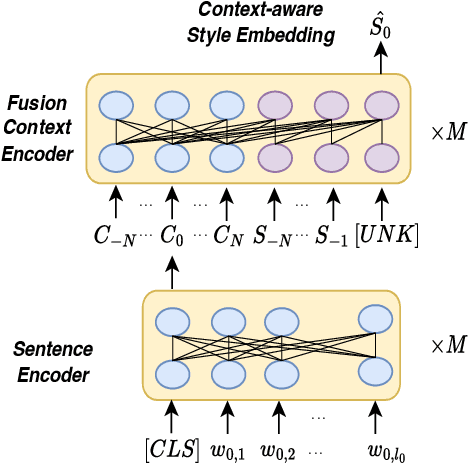
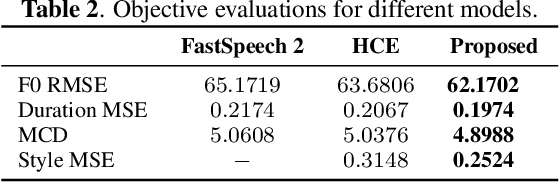
Recent advances in text-to-speech have significantly improved the expressiveness of synthesized speech. However, it is still challenging to generate speech with contextually appropriate and coherent speaking style for multi-sentence text in audiobooks. In this paper, we propose a context-aware coherent speaking style prediction method for audiobook speech synthesis. To predict the style embedding of the current utterance, a hierarchical transformer-based context-aware style predictor with a mixture attention mask is designed, considering both text-side context information and speech-side style information of previous speeches. Based on this, we can generate long-form speech with coherent style and prosody sentence by sentence. Objective and subjective evaluations on a Mandarin audiobook dataset demonstrate that our proposed model can generate speech with more expressive and coherent speaking style than baselines, for both single-sentence and multi-sentence test.
A Deep Dive into the Disparity of Word Error Rates Across Thousands of NPTEL MOOC Videos
Jul 20, 2023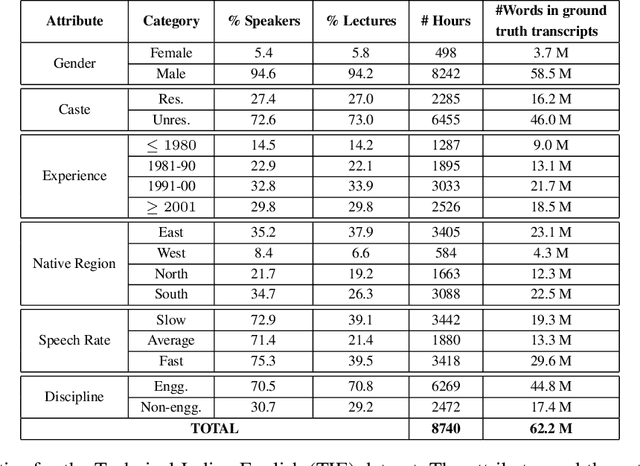
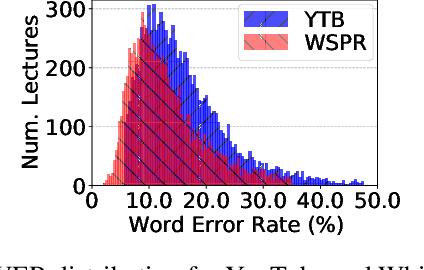
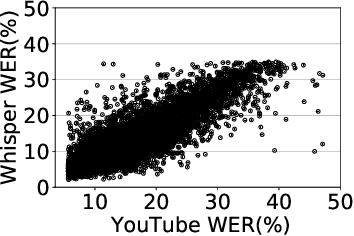
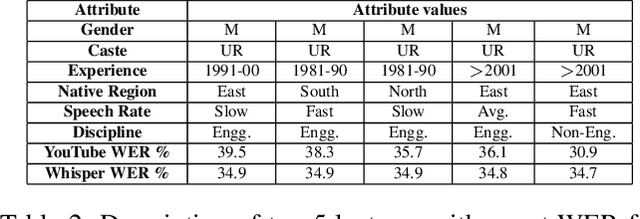
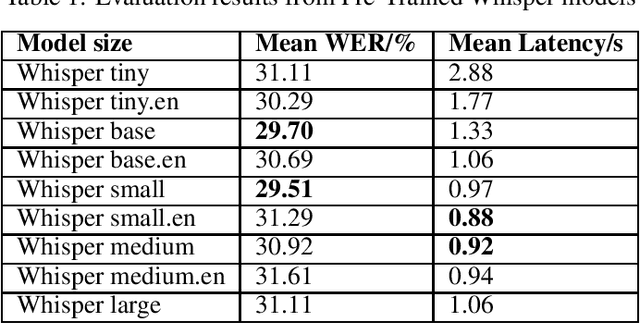
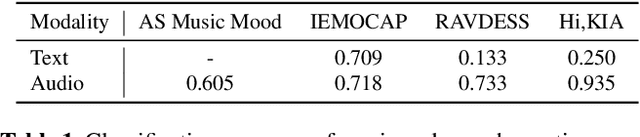
Automatic speech recognition (ASR) systems are designed to transcribe spoken language into written text and find utility in a variety of applications including voice assistants and transcription services. However, it has been observed that state-of-the-art ASR systems which deliver impressive benchmark results, struggle with speakers of certain regions or demographics due to variation in their speech properties. In this work, we describe the curation of a massive speech dataset of 8740 hours consisting of $\sim9.8$K technical lectures in the English language along with their transcripts delivered by instructors representing various parts of Indian demography. The dataset is sourced from the very popular NPTEL MOOC platform. We use the curated dataset to measure the existing disparity in YouTube Automatic Captions and OpenAI Whisper model performance across the diverse demographic traits of speakers in India. While there exists disparity due to gender, native region, age and speech rate of speakers, disparity based on caste is non-existent. We also observe statistically significant disparity across the disciplines of the lectures. These results indicate the need of more inclusive and robust ASR systems and more representational datasets for disparity evaluation in them.
Parts of Speech-Grounded Subspaces in Vision-Language Models
May 23, 2023

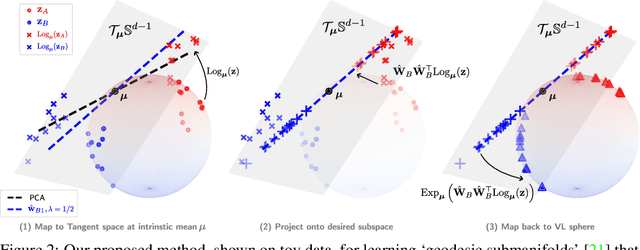
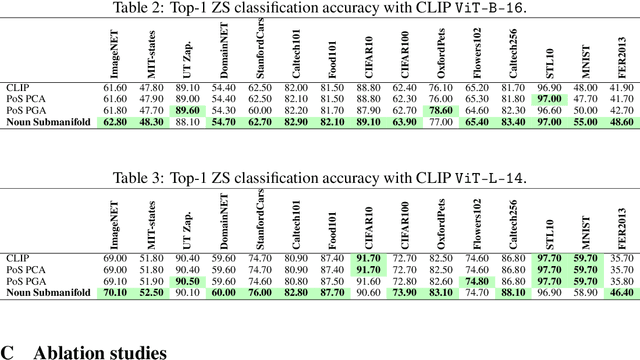
Latent image representations arising from vision-language models have proved immensely useful for a variety of downstream tasks. However, their utility is limited by their entanglement with respect to different visual attributes. For instance, recent work has shown that CLIP image representations are often biased toward specific visual properties (such as objects or actions) in an unpredictable manner. In this paper, we propose to separate representations of the different visual modalities in CLIP's joint vision-language space by leveraging the association between parts of speech and specific visual modes of variation (e.g. nouns relate to objects, adjectives describe appearance). This is achieved by formulating an appropriate component analysis model that learns subspaces capturing variability corresponding to a specific part of speech, while jointly minimising variability to the rest. Such a subspace yields disentangled representations of the different visual properties of an image or text in closed form while respecting the underlying geometry of the manifold on which the representations lie. What's more, we show the proposed model additionally facilitates learning subspaces corresponding to specific visual appearances (e.g. artists' painting styles), which enables the selective removal of entire visual themes from CLIP-based text-to-image synthesis. We validate the model both qualitatively, by visualising the subspace projections with a text-to-image model and by preventing the imitation of artists' styles, and quantitatively, through class invariance metrics and improvements to baseline zero-shot classification. Our code is available at: https://github.com/james-oldfield/PoS-subspaces.
Transfer Learning of Transformer-based Speech Recognition Models from Czech to Slovak
Jun 07, 2023
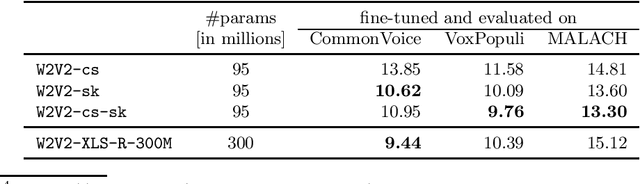
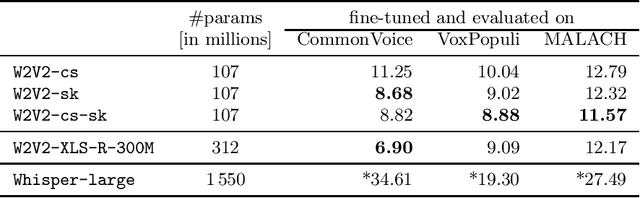
In this paper, we are comparing several methods of training the Slovak speech recognition models based on the Transformers architecture. Specifically, we are exploring the approach of transfer learning from the existing Czech pre-trained Wav2Vec 2.0 model into Slovak. We are demonstrating the benefits of the proposed approach on three Slovak datasets. Our Slovak models scored the best results when initializing the weights from the Czech model at the beginning of the pre-training phase. Our results show that the knowledge stored in the Cezch pre-trained model can be successfully reused to solve tasks in Slovak while outperforming even much larger public multilingual models.
On the Robustness of Arabic Speech Dialect Identification
Jun 01, 2023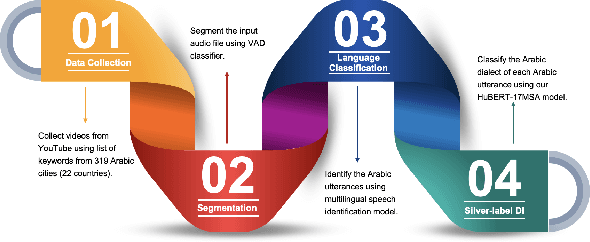
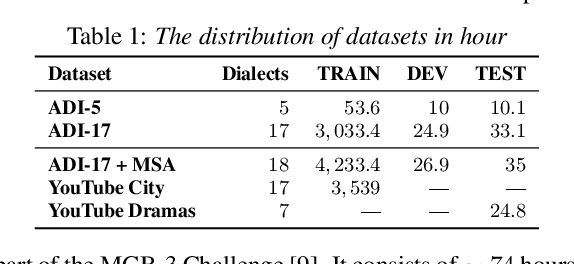


Arabic dialect identification (ADI) tools are an important part of the large-scale data collection pipelines necessary for training speech recognition models. As these pipelines require application of ADI tools to potentially out-of-domain data, we aim to investigate how vulnerable the tools may be to this domain shift. With self-supervised learning (SSL) models as a starting point, we evaluate transfer learning and direct classification from SSL features. We undertake our evaluation under rich conditions, with a goal to develop ADI systems from pretrained models and ultimately evaluate performance on newly collected data. In order to understand what factors contribute to model decisions, we carry out a careful human study of a subset of our data. Our analysis confirms that domain shift is a major challenge for ADI models. We also find that while self-training does alleviate this challenges, it may be insufficient for realistic conditions.
Predicting EEG Responses to Attended Speech via Deep Neural Networks for Speech
Feb 27, 2023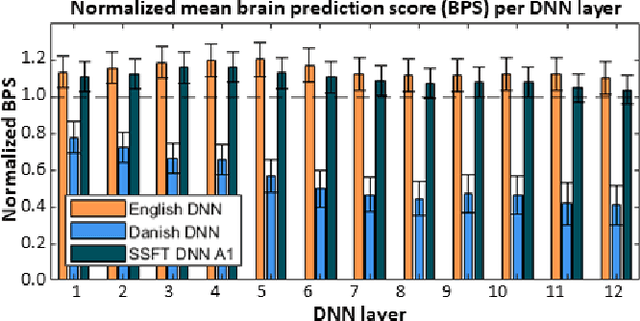
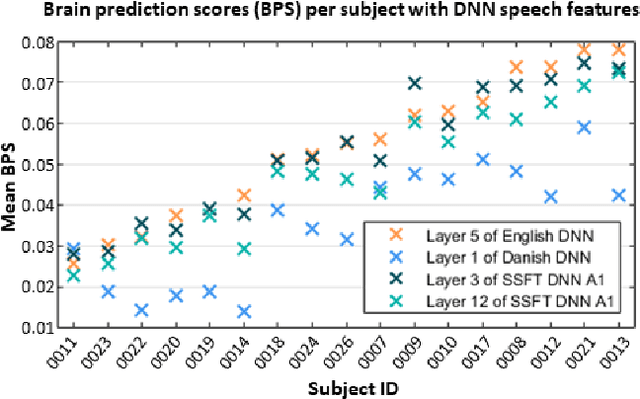
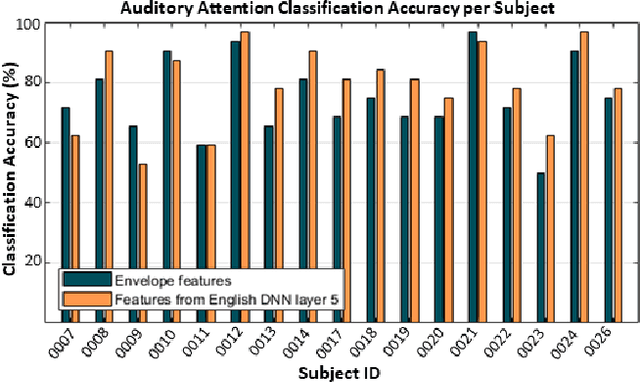
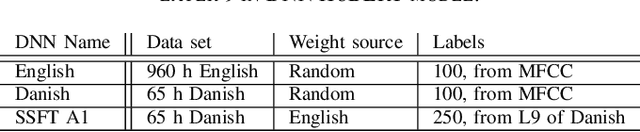
Attending to the speech stream of interest in multi-talker environments can be a challenging task, particularly for listeners with hearing impairment. Research suggests that neural responses assessed with electroencephalography (EEG) are modulated by listener`s auditory attention, revealing selective neural tracking (NT) of the attended speech. NT methods mostly rely on hand-engineered acoustic and linguistic speech features to predict the neural response. Only recently, deep neural network (DNN) models without specific linguistic information have been used to extract speech features for NT, demonstrating that speech features in hierarchical DNN layers can predict neural responses throughout the auditory pathway. In this study, we go one step further to investigate the suitability of similar DNN models for speech to predict neural responses to competing speech observed in EEG. We recorded EEG data using a 64-channel acquisition system from 17 listeners with normal hearing instructed to attend to one of two competing talkers. Our data revealed that EEG responses are significantly better predicted by DNN-extracted speech features than by hand-engineered acoustic features. Furthermore, analysis of hierarchical DNN layers showed that early layers yielded the highest predictions. Moreover, we found a significant increase in auditory attention classification accuracies with the use of DNN-extracted speech features over the use of hand-engineered acoustic features. These findings open a new avenue for development of new NT measures to evaluate and further advance hearing technology.
Textless Speech-to-Music Retrieval Using Emotion Similarity
Mar 19, 2023
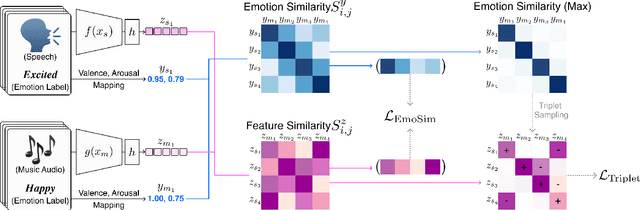

We introduce a framework that recommends music based on the emotions of speech. In content creation and daily life, speech contains information about human emotions, which can be enhanced by music. Our framework focuses on a cross-domain retrieval system to bridge the gap between speech and music via emotion labels. We explore different speech representations and report their impact on different speech types, including acting voice and wake-up words. We also propose an emotion similarity regularization term in cross-domain retrieval tasks. By incorporating the regularization term into training, similar speech-and-music pairs in the emotion space are closer in the joint embedding space. Our comprehensive experimental results show that the proposed model is effective in textless speech-to-music retrieval.
ICASSP 2023 Speech Signal Improvement Challenge
Mar 12, 2023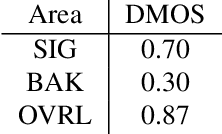
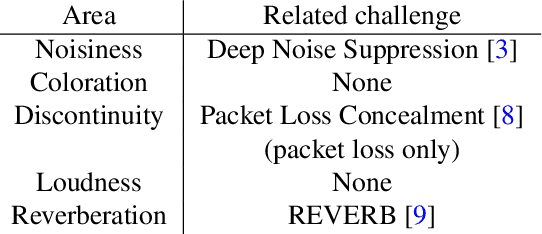

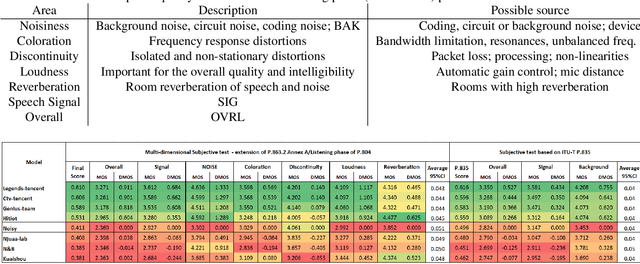
The ICASSP 2023 Speech Signal Improvement Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. The speech signal quality can be measured with SIG in ITU-T P.835 and is still a top issue in audio communication and conferencing systems. For example, in the ICASSP 2022 Deep Noise Suppression challenge, the improvement in the background (BAK) and overall (OVRL) quality is impressive, but the improvement in the speech signal (SIG) is statistically zero. To improve SIG the following speech impairment areas must be addressed: coloration, discontinuity, loudness, and reverberation. A dataset and test set were provided for the challenge, and the winners were determined using an extended crowdsourced implementation of ITU-T P.804. The results show significant improvement was made across all measured dimensions of speech quality.