 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 09, 2023

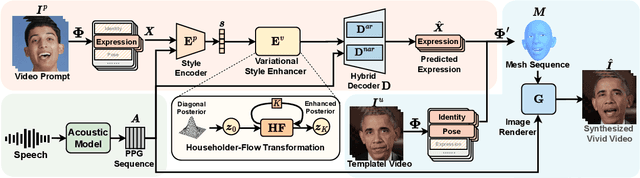
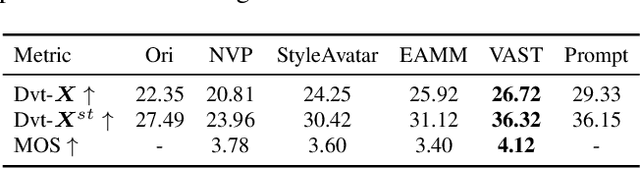
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
Boosting Local Spectro-Temporal Features for Speech Analysis
May 17, 2023We introduce the problem of phone classification in the context of speech recognition, and explore several sets of local spectro-temporal features that can be used for phone classification. In particular, we present some preliminary results for phone classification using two sets of features that are commonly used for object detection: Haar features and SVM-classified Histograms of Gradients (HoG)
Guided Speech Enhancement Network
Mar 13, 2023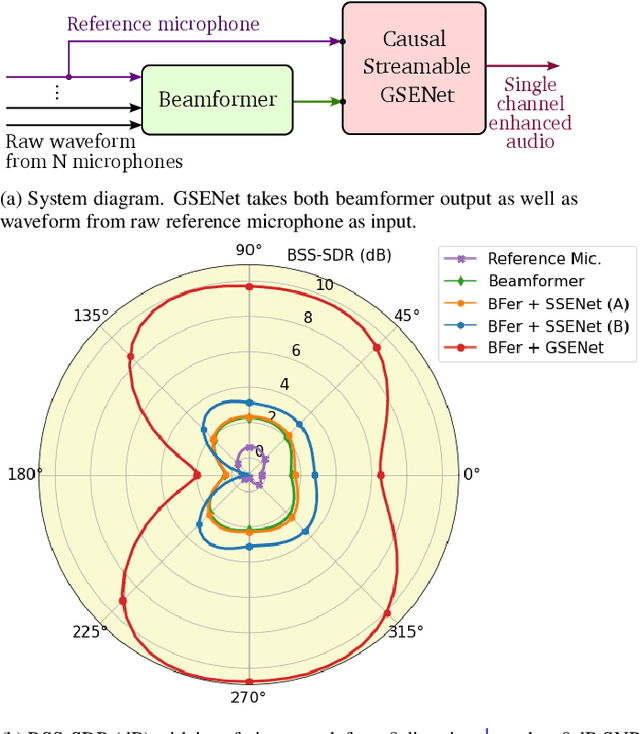

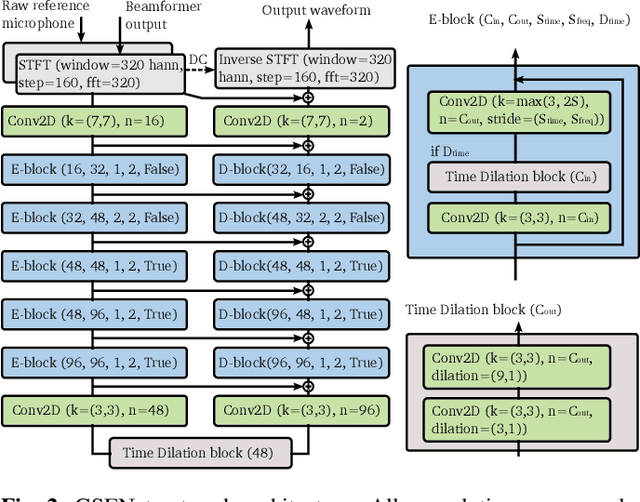
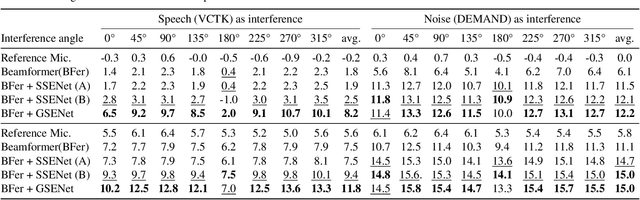
High quality speech capture has been widely studied for both voice communication and human computer interface reasons. To improve the capture performance, we can often find multi-microphone speech enhancement techniques deployed on various devices. Multi-microphone speech enhancement problem is often decomposed into two decoupled steps: a beamformer that provides spatial filtering and a single-channel speech enhancement model that cleans up the beamformer output. In this work, we propose a speech enhancement solution that takes both the raw microphone and beamformer outputs as the input for an ML model. We devise a simple yet effective training scheme that allows the model to learn from the cues of the beamformer by contrasting the two inputs and greatly boost its capability in spatial rejection, while conducting the general tasks of denoising and dereverberation. The proposed solution takes advantage of classical spatial filtering algorithms instead of competing with them. By design, the beamformer module then could be selected separately and does not require a large amount of data to be optimized for a given form factor, and the network model can be considered as a standalone module which is highly transferable independently from the microphone array. We name the ML module in our solution as GSENet, short for Guided Speech Enhancement Network. We demonstrate its effectiveness on real world data collected on multi-microphone devices in terms of the suppression of noise and interfering speech.
Relating EEG recordings to speech using envelope tracking and the speech-FFR
Mar 11, 2023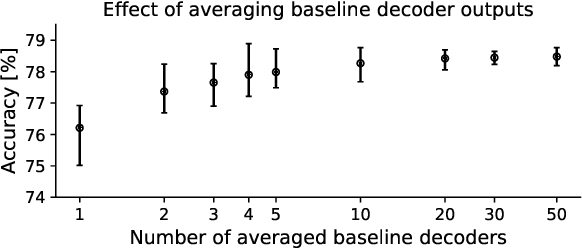
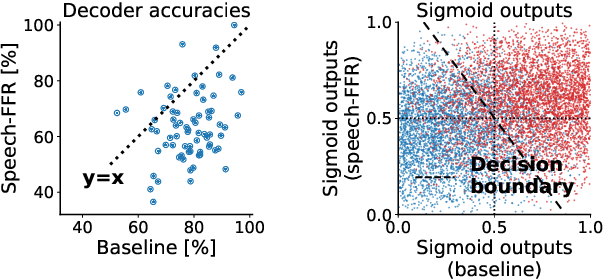
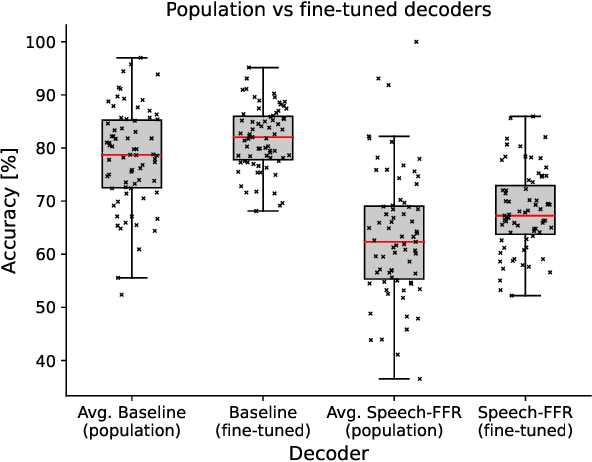
During speech perception, a listener's electroencephalogram (EEG) reflects acoustic-level processing as well as higher-level cognitive factors such as speech comprehension and attention. However, decoding speech from EEG recordings is challenging due to the low signal-to-noise ratios of EEG signals. We report on an approach developed for the ICASSP 2023 'Auditory EEG Decoding' Signal Processing Grand Challenge. A simple ensembling method is shown to considerably improve upon the baseline decoder performance. Even higher classification rates are achieved by jointly decoding the speech-evoked frequency-following response and responses to the temporal envelope of speech, as well as by fine-tuning the decoders to individual subjects. Our results could have applications in the diagnosis of hearing disorders or in cognitively steered hearing aids.
Contextual Biasing of Named-Entities with Large Language Models
Sep 01, 2023
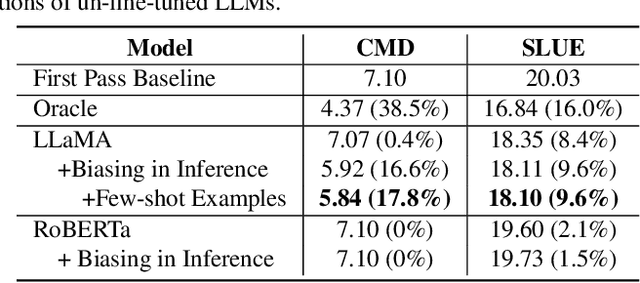
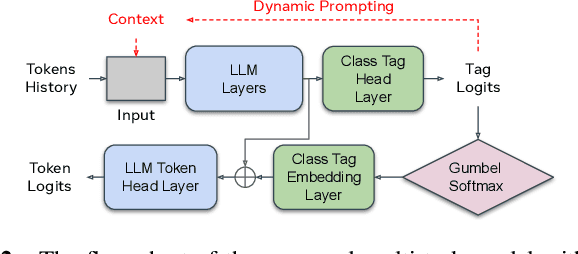
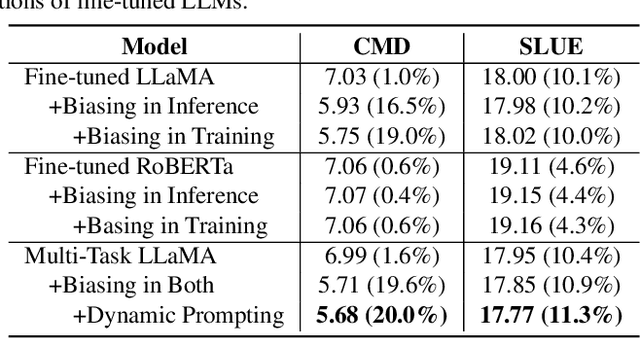
This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Amortizing Pragmatic Program Synthesis with Rankings
Sep 01, 2023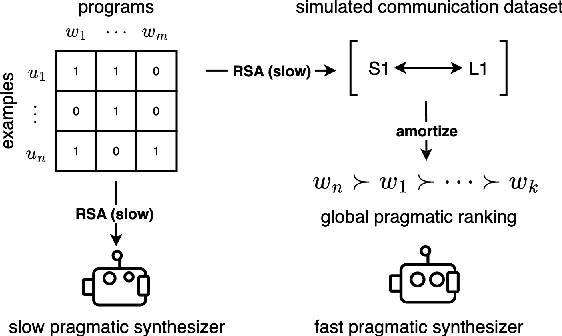
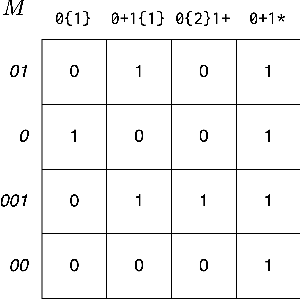
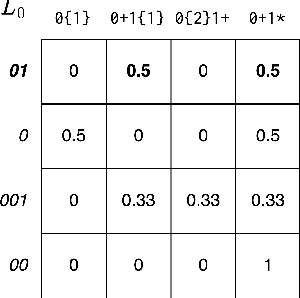
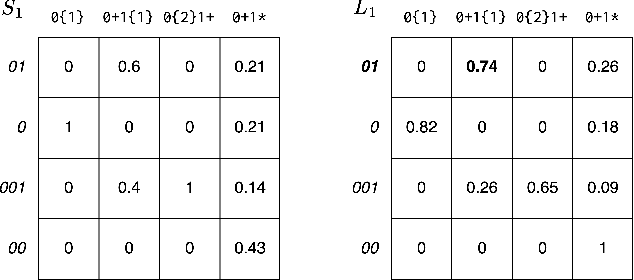
In program synthesis, an intelligent system takes in a set of user-generated examples and returns a program that is logically consistent with these examples. The usage of Rational Speech Acts (RSA) framework has been successful in building \emph{pragmatic} program synthesizers that return programs which -- in addition to being logically consistent -- account for the fact that a user chooses their examples informatively. However, the computational burden of running the RSA algorithm has restricted the application of pragmatic program synthesis to domains with a small number of possible programs. This work presents a novel method of amortizing the RSA algorithm by leveraging a \emph{global pragmatic ranking} -- a single, total ordering of all the hypotheses. We prove that for a pragmatic synthesizer that uses a single demonstration, our global ranking method exactly replicates RSA's ranked responses. We further empirically show that global rankings effectively approximate the full pragmatic synthesizer in an online, multi-demonstration setting. Experiments on two program synthesis domains using our pragmatic ranking method resulted in orders of magnitudes of speed ups compared to the RSA synthesizer, while outperforming the standard, non-pragmatic synthesizer.
The Relationship Between Speech Features Changes When You Get Depressed: Feature Correlations for Improving Speed and Performance of Depression Detection
Jul 07, 2023
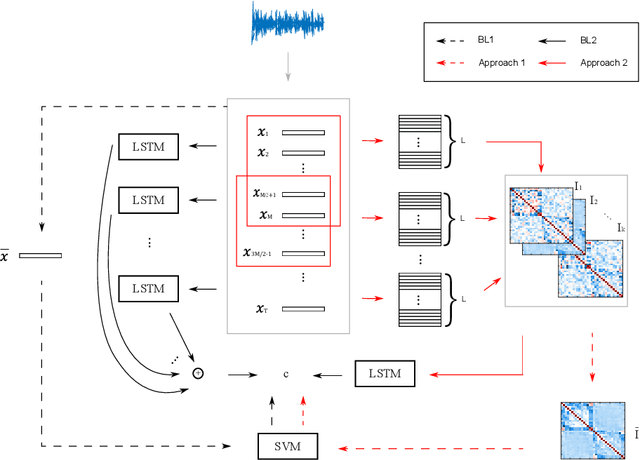
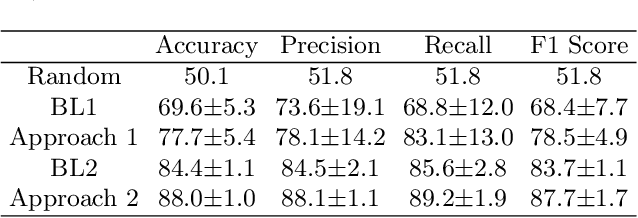
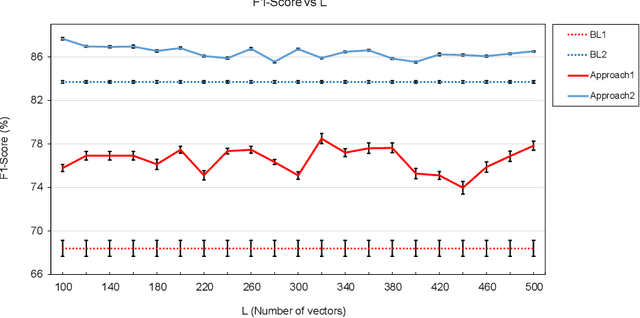
This work shows that depression changes the correlation between features extracted from speech. Furthermore, it shows that using such an insight can improve the training speed and performance of depression detectors based on SVMs and LSTMs. The experiments were performed over the Androids Corpus, a publicly available dataset involving 112 speakers, including 58 people diagnosed with depression by professional psychiatrists. The results show that the models used in the experiments improve in terms of training speed and performance when fed with feature correlation matrices rather than with feature vectors. The relative reduction of the error rate ranges between 23.1% and 26.6% depending on the model. The probable explanation is that feature correlation matrices appear to be more variable in the case of depressed speakers. Correspondingly, such a phenomenon can be thought of as a depression marker.
Task-Agnostic Structured Pruning of Speech Representation Models
Jun 02, 2023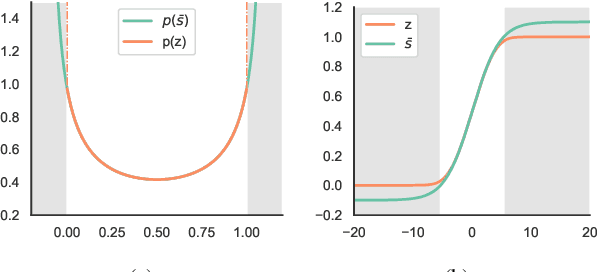
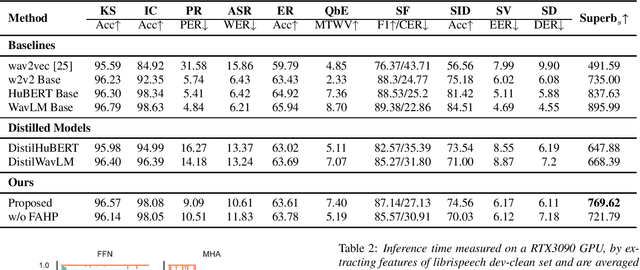
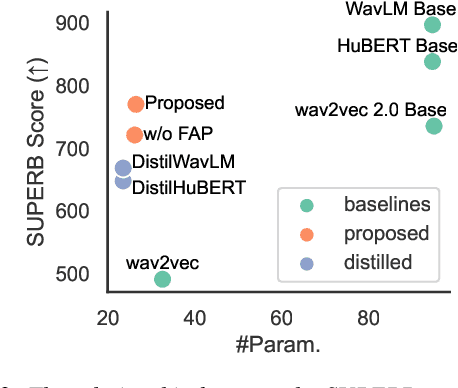
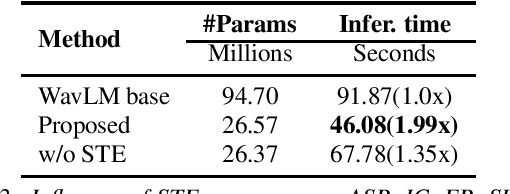
Self-supervised pre-trained models such as Wav2vec2, Hubert, and WavLM have been shown to significantly improve many speech tasks. However, their large memory and strong computational requirements hinder their industrial applicability. Structured pruning is a hardware-friendly model compression technique but usually results in a larger loss of accuracy. In this paper, we propose a fine-grained attention head pruning method to compensate for the performance degradation. In addition, we also introduce the straight through estimator into the L0 regularization to further accelerate the pruned model. Experiments on the SUPERB benchmark show that our model can achieve comparable performance to the dense model in multiple tasks and outperforms the Wav2vec 2.0 base model on average, with 72% fewer parameters and 2 times faster inference speed.
Evil Operation: Breaking Speaker Recognition with PaddingBack
Aug 08, 2023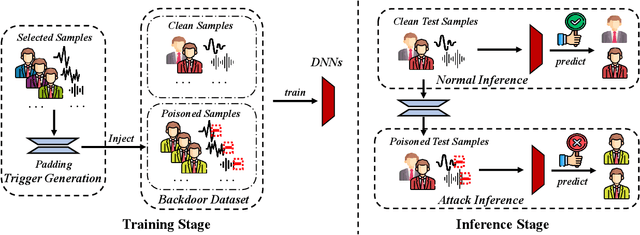
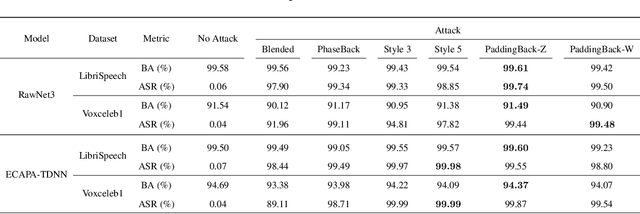
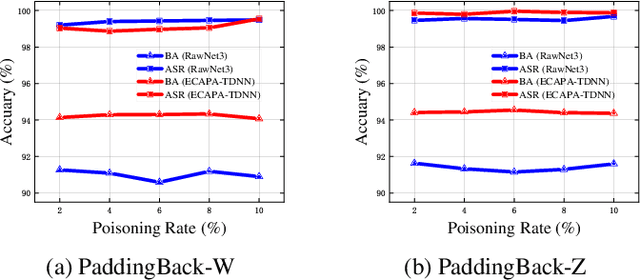
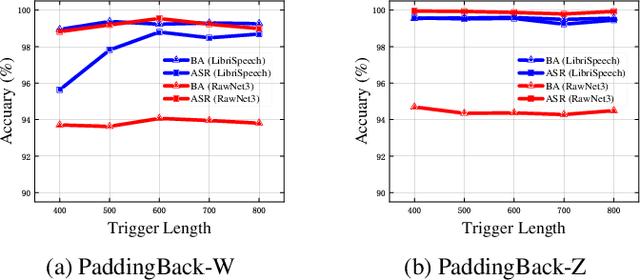
Machine Learning as a Service (MLaaS) has gained popularity due to advancements in machine learning. However, untrusted third-party platforms have raised concerns about AI security, particularly in backdoor attacks. Recent research has shown that speech backdoors can utilize transformations as triggers, similar to image backdoors. However, human ears easily detect these transformations, leading to suspicion. In this paper, we introduce PaddingBack, an inaudible backdoor attack that utilizes malicious operations to make poisoned samples indistinguishable from clean ones. Instead of using external perturbations as triggers, we exploit the widely used speech signal operation, padding, to break speaker recognition systems. Our experimental results demonstrate the effectiveness of the proposed approach, achieving a significantly high attack success rate while maintaining a high rate of benign accuracy. Furthermore, PaddingBack demonstrates the ability to resist defense methods while maintaining its stealthiness against human perception. The results of the stealthiness experiment have been made available at https://nbufabio25.github.io/paddingback/.
Efficient Acoustic Echo Suppression with Condition-Aware Training
Jul 28, 2023The topic of deep acoustic echo control (DAEC) has seen many approaches with various model topologies in recent years. Convolutional recurrent networks (CRNs), consisting of a convolutional encoder and decoder encompassing a recurrent bottleneck, are repeatedly employed due to their ability to preserve nearend speech even in double-talk (DT) condition. However, past architectures are either computationally complex or trade off smaller model sizes with a decrease in performance. We propose an improved CRN topology which, compared to other realizations of this class of architectures, not only saves parameters and computational complexity, but also shows improved performance in DT, outperforming both baseline architectures FCRN and CRUSE. Striving for a condition-aware training, we also demonstrate the importance of a high proportion of double-talk and the missing value of nearend-only speech in DAEC training data. Finally, we show how to control the trade-off between aggressive echo suppression and near-end speech preservation by fine-tuning with condition-aware component loss functions.