 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Guided Speech Enhancement Network
Mar 13, 2023
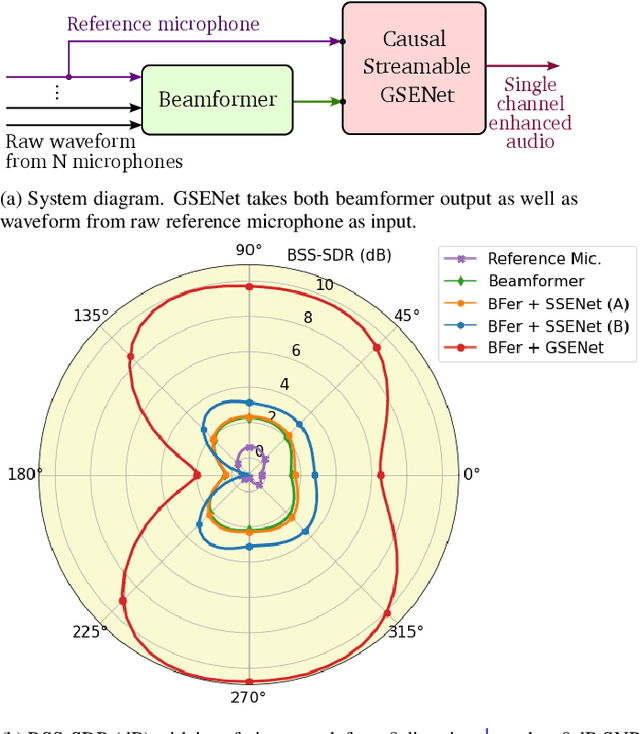

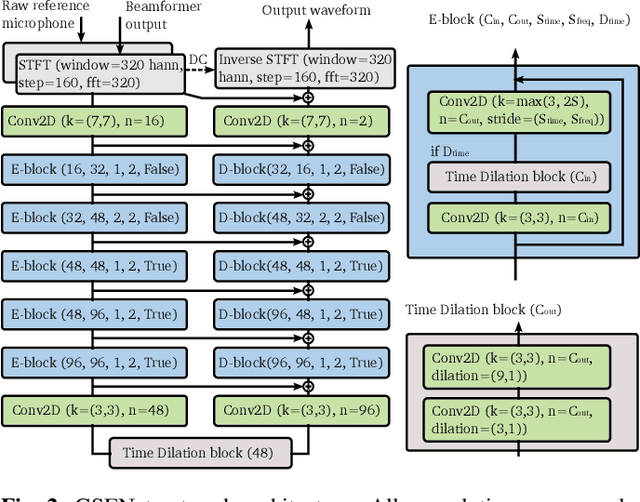
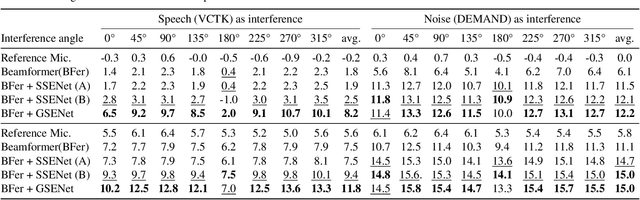
High quality speech capture has been widely studied for both voice communication and human computer interface reasons. To improve the capture performance, we can often find multi-microphone speech enhancement techniques deployed on various devices. Multi-microphone speech enhancement problem is often decomposed into two decoupled steps: a beamformer that provides spatial filtering and a single-channel speech enhancement model that cleans up the beamformer output. In this work, we propose a speech enhancement solution that takes both the raw microphone and beamformer outputs as the input for an ML model. We devise a simple yet effective training scheme that allows the model to learn from the cues of the beamformer by contrasting the two inputs and greatly boost its capability in spatial rejection, while conducting the general tasks of denoising and dereverberation. The proposed solution takes advantage of classical spatial filtering algorithms instead of competing with them. By design, the beamformer module then could be selected separately and does not require a large amount of data to be optimized for a given form factor, and the network model can be considered as a standalone module which is highly transferable independently from the microphone array. We name the ML module in our solution as GSENet, short for Guided Speech Enhancement Network. We demonstrate its effectiveness on real world data collected on multi-microphone devices in terms of the suppression of noise and interfering speech.
The Relationship Between Speech Features Changes When You Get Depressed: Feature Correlations for Improving Speed and Performance of Depression Detection
Jul 07, 2023
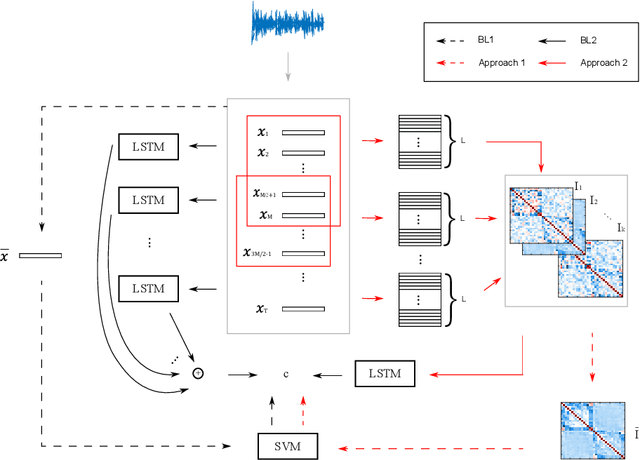
This work shows that depression changes the correlation between features extracted from speech. Furthermore, it shows that using such an insight can improve the training speed and performance of depression detectors based on SVMs and LSTMs. The experiments were performed over the Androids Corpus, a publicly available dataset involving 112 speakers, including 58 people diagnosed with depression by professional psychiatrists. The results show that the models used in the experiments improve in terms of training speed and performance when fed with feature correlation matrices rather than with feature vectors. The relative reduction of the error rate ranges between 23.1% and 26.6% depending on the model. The probable explanation is that feature correlation matrices appear to be more variable in the case of depressed speakers. Correspondingly, such a phenomenon can be thought of as a depression marker.
Relating EEG recordings to speech using envelope tracking and the speech-FFR
Mar 11, 2023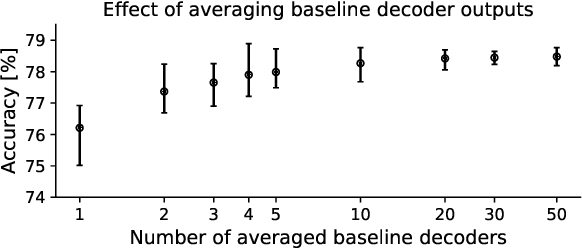
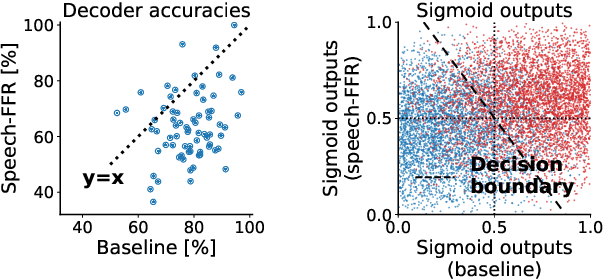
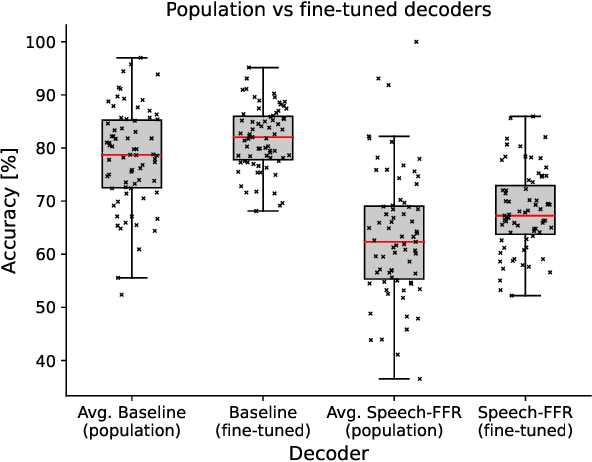
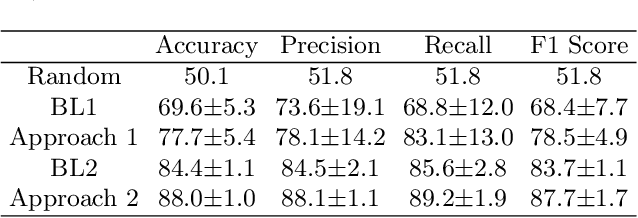
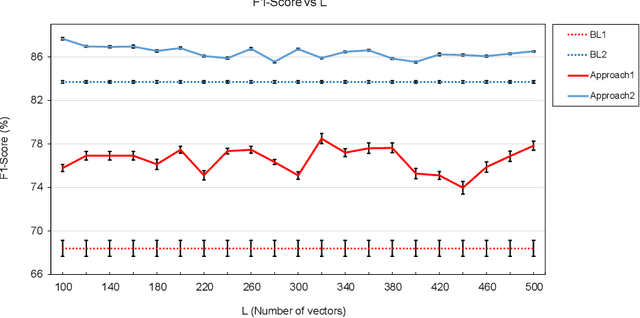
During speech perception, a listener's electroencephalogram (EEG) reflects acoustic-level processing as well as higher-level cognitive factors such as speech comprehension and attention. However, decoding speech from EEG recordings is challenging due to the low signal-to-noise ratios of EEG signals. We report on an approach developed for the ICASSP 2023 'Auditory EEG Decoding' Signal Processing Grand Challenge. A simple ensembling method is shown to considerably improve upon the baseline decoder performance. Even higher classification rates are achieved by jointly decoding the speech-evoked frequency-following response and responses to the temporal envelope of speech, as well as by fine-tuning the decoders to individual subjects. Our results could have applications in the diagnosis of hearing disorders or in cognitively steered hearing aids.
Efficient Acoustic Echo Suppression with Condition-Aware Training
Jul 28, 2023The topic of deep acoustic echo control (DAEC) has seen many approaches with various model topologies in recent years. Convolutional recurrent networks (CRNs), consisting of a convolutional encoder and decoder encompassing a recurrent bottleneck, are repeatedly employed due to their ability to preserve nearend speech even in double-talk (DT) condition. However, past architectures are either computationally complex or trade off smaller model sizes with a decrease in performance. We propose an improved CRN topology which, compared to other realizations of this class of architectures, not only saves parameters and computational complexity, but also shows improved performance in DT, outperforming both baseline architectures FCRN and CRUSE. Striving for a condition-aware training, we also demonstrate the importance of a high proportion of double-talk and the missing value of nearend-only speech in DAEC training data. Finally, we show how to control the trade-off between aggressive echo suppression and near-end speech preservation by fine-tuning with condition-aware component loss functions.
Task-Agnostic Structured Pruning of Speech Representation Models
Jun 02, 2023
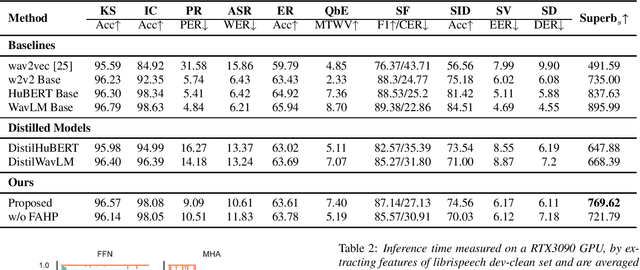
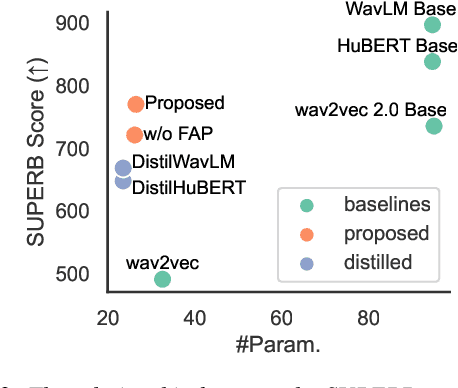
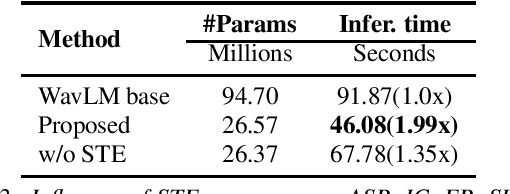
Self-supervised pre-trained models such as Wav2vec2, Hubert, and WavLM have been shown to significantly improve many speech tasks. However, their large memory and strong computational requirements hinder their industrial applicability. Structured pruning is a hardware-friendly model compression technique but usually results in a larger loss of accuracy. In this paper, we propose a fine-grained attention head pruning method to compensate for the performance degradation. In addition, we also introduce the straight through estimator into the L0 regularization to further accelerate the pruned model. Experiments on the SUPERB benchmark show that our model can achieve comparable performance to the dense model in multiple tasks and outperforms the Wav2vec 2.0 base model on average, with 72% fewer parameters and 2 times faster inference speed.
Advancing Hungarian Text Processing with HuSpaCy: Efficient and Accurate NLP Pipelines
Aug 24, 2023This paper presents a set of industrial-grade text processing models for Hungarian that achieve near state-of-the-art performance while balancing resource efficiency and accuracy. Models have been implemented in the spaCy framework, extending the HuSpaCy toolkit with several improvements to its architecture. Compared to existing NLP tools for Hungarian, all of our pipelines feature all basic text processing steps including tokenization, sentence-boundary detection, part-of-speech tagging, morphological feature tagging, lemmatization, dependency parsing and named entity recognition with high accuracy and throughput. We thoroughly evaluated the proposed enhancements, compared the pipelines with state-of-the-art tools and demonstrated the competitive performance of the new models in all text preprocessing steps. All experiments are reproducible and the pipelines are freely available under a permissive license.
CML-TTS A Multilingual Dataset for Speech Synthesis in Low-Resource Languages
Jun 16, 2023In this paper, we present CML-TTS, a recursive acronym for CML-Multi-Lingual-TTS, a new Text-to-Speech (TTS) dataset developed at the Center of Excellence in Artificial Intelligence (CEIA) of the Federal University of Goias (UFG). CML-TTS is based on Multilingual LibriSpeech (MLS) and adapted for training TTS models, consisting of audiobooks in seven languages: Dutch, French, German, Italian, Portuguese, Polish, and Spanish. Additionally, we provide the YourTTS model, a multi-lingual TTS model, trained using 3,176.13 hours from CML-TTS and also with 245.07 hours from LibriTTS, in English. Our purpose in creating this dataset is to open up new research possibilities in the TTS area for multi-lingual models. The dataset is publicly available under the CC-BY 4.0 license1.
Investigating Range-Equalizing Bias in Mean Opinion Score Ratings of Synthesized Speech
May 22, 2023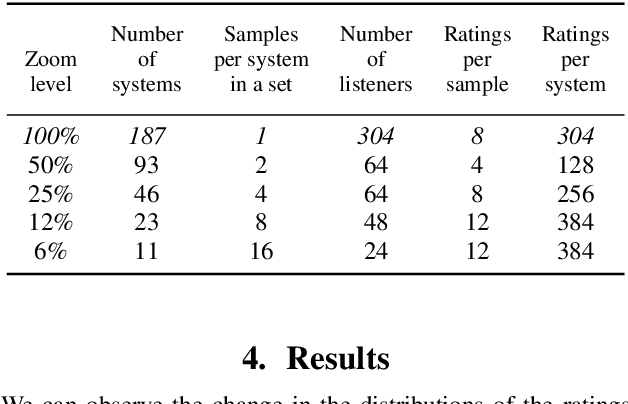
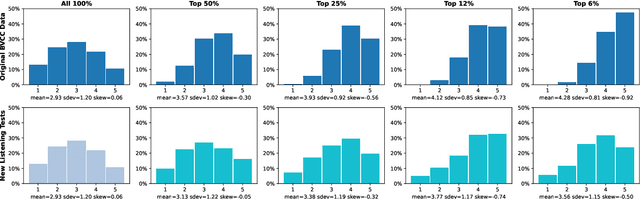
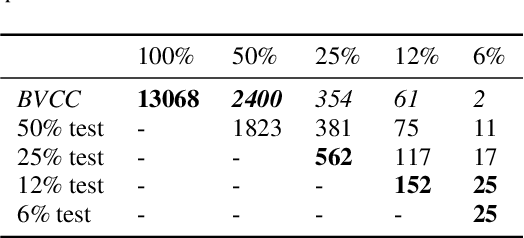

Mean Opinion Score (MOS) is a popular measure for evaluating synthesized speech. However, the scores obtained in MOS tests are heavily dependent upon many contextual factors. One such factor is the overall range of quality of the samples presented in the test -- listeners tend to try to use the entire range of scoring options available to them regardless of this, a phenomenon which is known as range-equalizing bias. In this paper, we systematically investigate the effects of range-equalizing bias on MOS tests for synthesized speech by conducting a series of listening tests in which we progressively "zoom in" on a smaller number of systems in the higher-quality range. This allows us to better understand and quantify the effects of range-equalizing bias in MOS tests.
Stochastic Pitch Prediction Improves the Diversity and Naturalness of Speech in Glow-TTS
May 28, 2023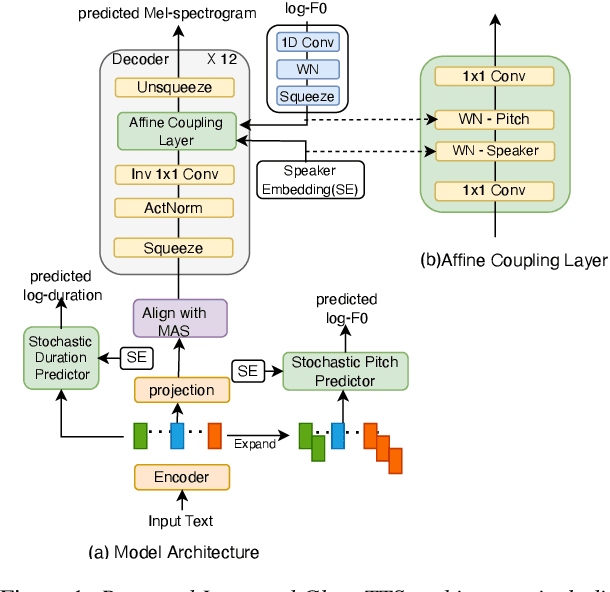
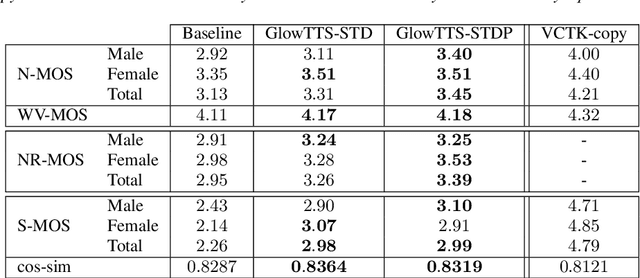
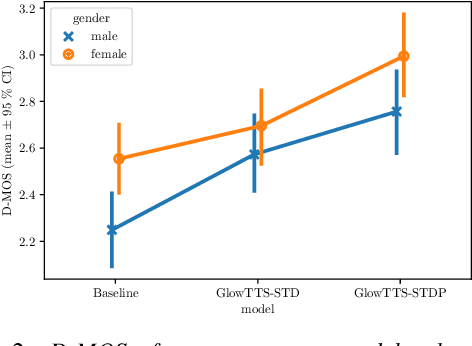
Flow-based generative models are widely used in text-to-speech (TTS) systems to learn the distribution of audio features (e.g., Mel-spectrograms) given the input tokens and to sample from this distribution to generate diverse utterances. However, in the zero-shot multi-speaker TTS scenario, the generated utterances lack diversity and naturalness. In this paper, we propose to improve the diversity of utterances by explicitly learning the distribution of fundamental frequency sequences (pitch contours) of each speaker during training using a stochastic flow-based pitch predictor, then conditioning the model on generated pitch contours during inference. The experimental results demonstrate that the proposed method yields a significant improvement in the naturalness and diversity of speech generated by a Glow-TTS model that uses explicit stochastic pitch prediction, over a Glow-TTS baseline and an improved Glow-TTS model that uses a stochastic duration predictor.
Characterizing Learning Curves During Language Model Pre-Training: Learning, Forgetting, and Stability
Aug 29, 2023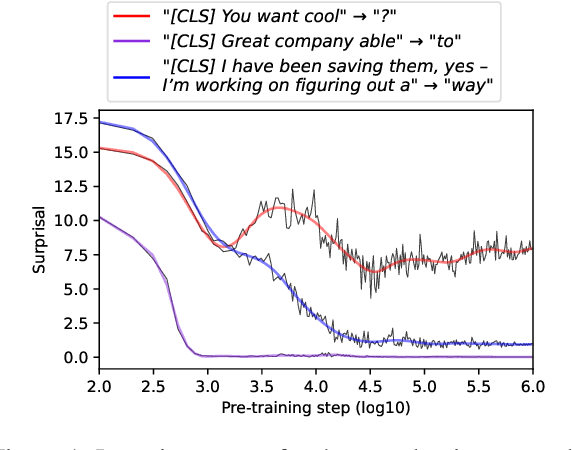

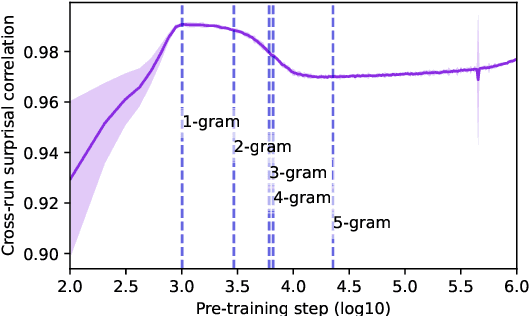
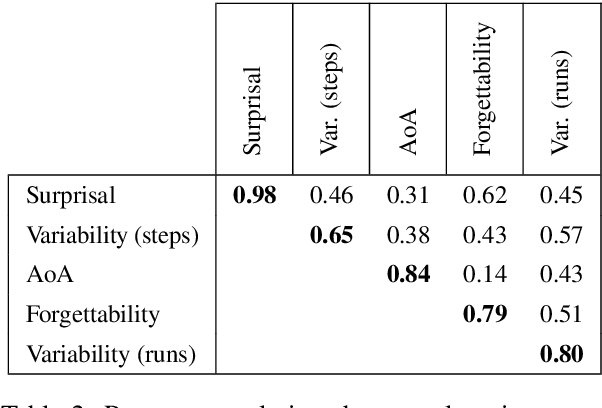
How do language models learn to make predictions during pre-training? To study this question, we extract learning curves from five autoregressive English language model pre-training runs, for 1M tokens in context. We observe that the language models generate short repetitive phrases before learning to generate longer and more coherent text. We quantify the final surprisal, within-run variability, age of acquisition, forgettability, and cross-run variability of learning curves for individual tokens in context. More frequent tokens reach lower final surprisals, exhibit less variability within and across pre-training runs, are learned earlier, and are less likely to be "forgotten" during pre-training. Higher n-gram probabilities further accentuate these effects. Independent of the target token, shorter and more frequent contexts correlate with marginally more stable and quickly acquired predictions. Effects of part-of-speech are also small, although nouns tend to be acquired later and less stably than verbs, adverbs, and adjectives. Our work contributes to a better understanding of language model pre-training dynamics and informs the deployment of stable language models in practice.