 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023
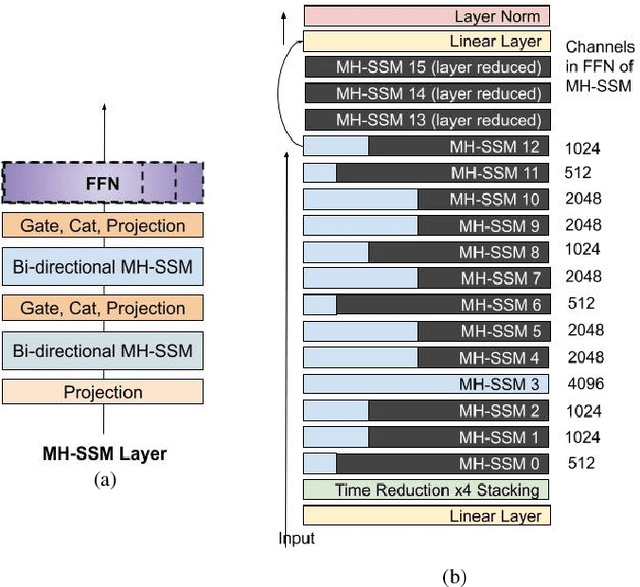
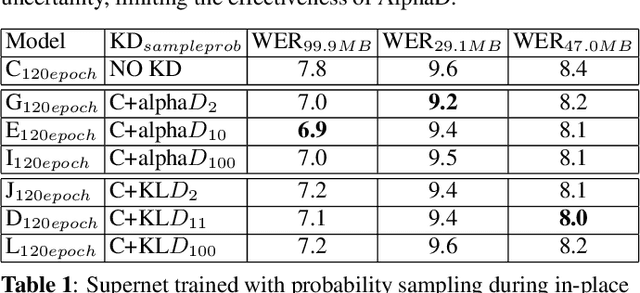
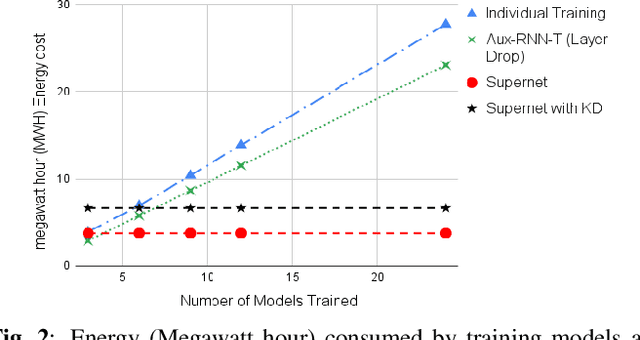
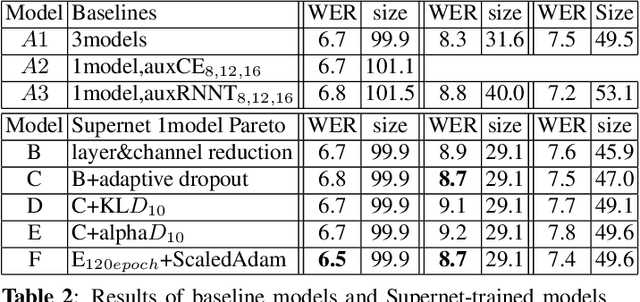
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
The DKU-MSXF Diarization System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023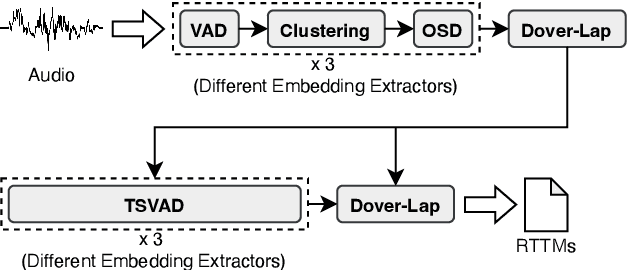
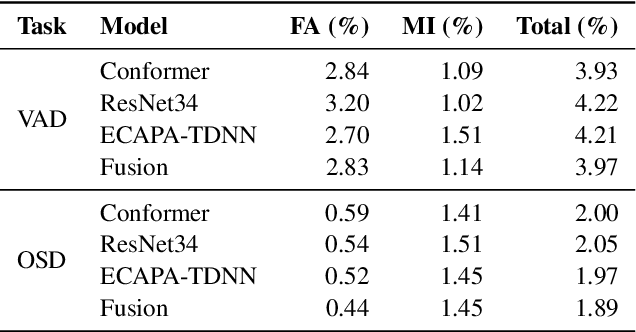

This paper describes the DKU-MSXF submission to track 4 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our system pipeline contains voice activity detection, clustering-based diarization, overlapped speech detection, and target-speaker voice activity detection, where each procedure has a fused output from 3 sub-models. Finally, we fuse different clustering-based and TSVAD-based diarization systems using DOVER-Lap and achieve the 4.30% diarization error rate (DER), which ranks first place on track 4 of the challenge leaderboard.
Contrastive Speech Mixup for Low-resource Keyword Spotting
May 02, 2023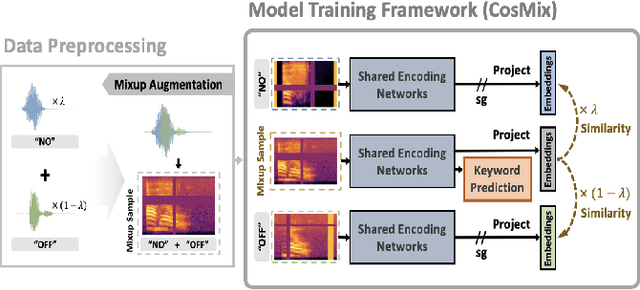
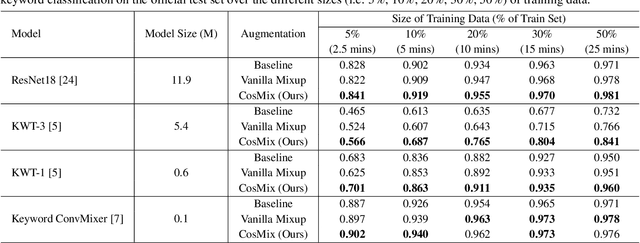

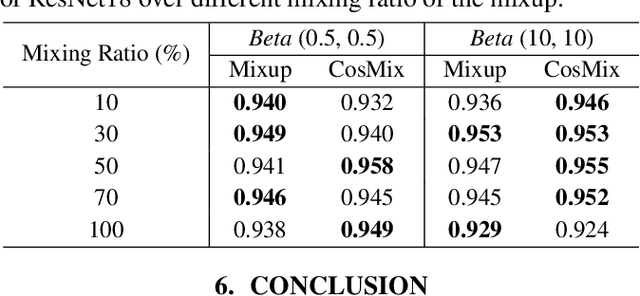
Most of the existing neural-based models for keyword spotting (KWS) in smart devices require thousands of training samples to learn a decent audio representation. However, with the rising demand for smart devices to become more personalized, KWS models need to adapt quickly to smaller user samples. To tackle this challenge, we propose a contrastive speech mixup (CosMix) learning algorithm for low-resource KWS. CosMix introduces an auxiliary contrastive loss to the existing mixup augmentation technique to maximize the relative similarity between the original pre-mixed samples and the augmented samples. The goal is to inject enhancing constraints to guide the model towards simpler but richer content-based speech representations from two augmented views (i.e. noisy mixed and clean pre-mixed utterances). We conduct our experiments on the Google Speech Command dataset, where we trim the size of the training set to as small as 2.5 mins per keyword to simulate a low-resource condition. Our experimental results show a consistent improvement in the performance of multiple models, which exhibits the effectiveness of our method.
On Monotonic Aggregation for Open-domain QA
Aug 08, 2023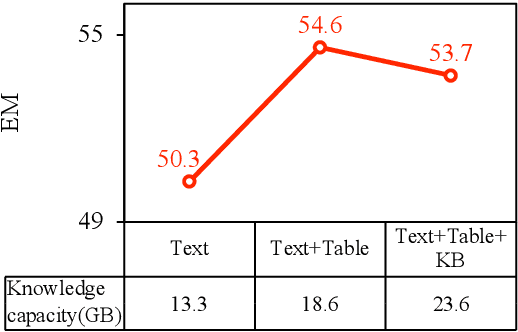
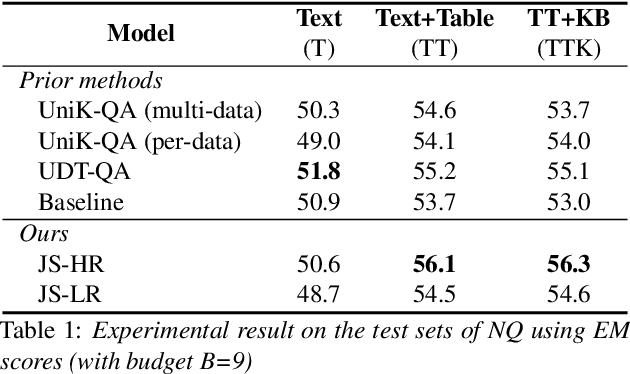
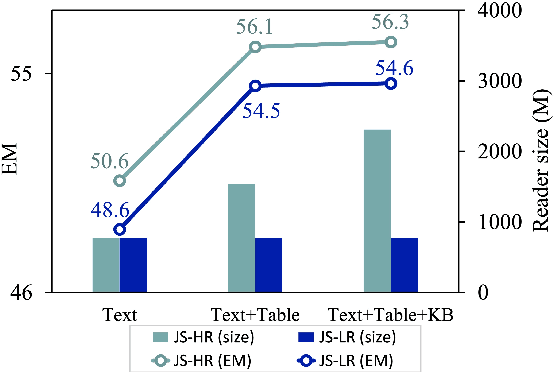
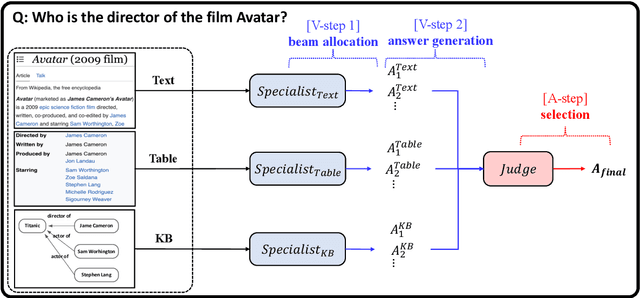
Question answering (QA) is a critical task for speech-based retrieval from knowledge sources, by sifting only the answers without requiring to read supporting documents. Specifically, open-domain QA aims to answer user questions on unrestricted knowledge sources. Ideally, adding a source should not decrease the accuracy, but we find this property (denoted as "monotonicity") does not hold for current state-of-the-art methods. We identify the cause, and based on that we propose Judge-Specialist framework. Our framework consists of (1) specialist retrievers/readers to cover individual sources, and (2) judge, a dedicated language model to select the final answer. Our experiments show that our framework not only ensures monotonicity, but also outperforms state-of-the-art multi-source QA methods on Natural Questions. Additionally, we show that our models robustly preserve the monotonicity against noise from speech recognition. We publicly release our code and setting.
Mitigating Negative Transfer with Task Awareness for Sexism, Hate Speech, and Toxic Language Detection
Jul 07, 2023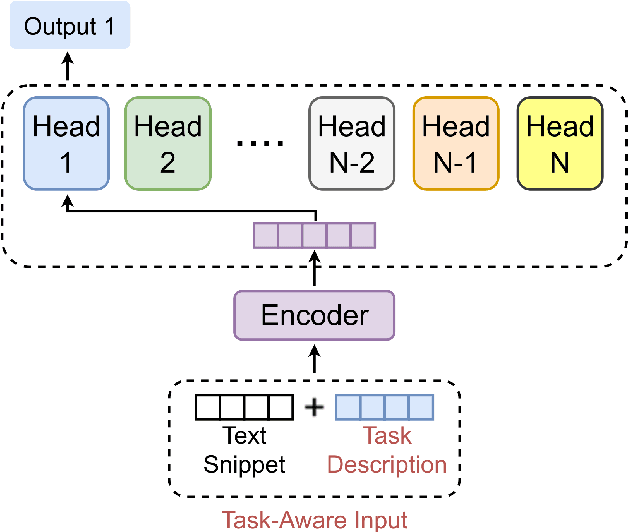
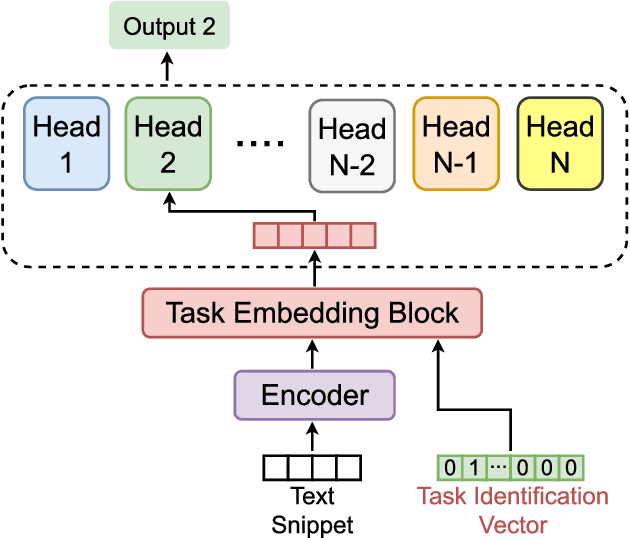
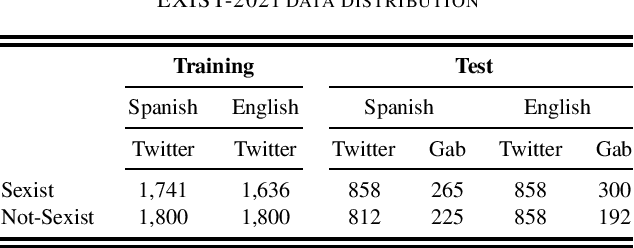
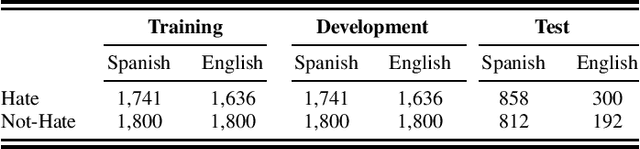
This paper proposes a novelty approach to mitigate the negative transfer problem. In the field of machine learning, the common strategy is to apply the Single-Task Learning approach in order to train a supervised model to solve a specific task. Training a robust model requires a lot of data and a significant amount of computational resources, making this solution unfeasible in cases where data are unavailable or expensive to gather. Therefore another solution, based on the sharing of information between tasks, has been developed: Multi-Task Learning (MTL). Despite the recent developments regarding MTL, the problem of negative transfer has still to be solved. Negative transfer is a phenomenon that occurs when noisy information is shared between tasks, resulting in a drop in performance. This paper proposes a new approach to mitigate the negative transfer problem based on the task awareness concept. The proposed approach results in diminishing the negative transfer together with an improvement of performance over classic MTL solution. Moreover, the proposed approach has been implemented in two unified architectures to detect Sexism, Hate Speech, and Toxic Language in text comments. The proposed architectures set a new state-of-the-art both in EXIST-2021 and HatEval-2019 benchmarks.
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 09, 2023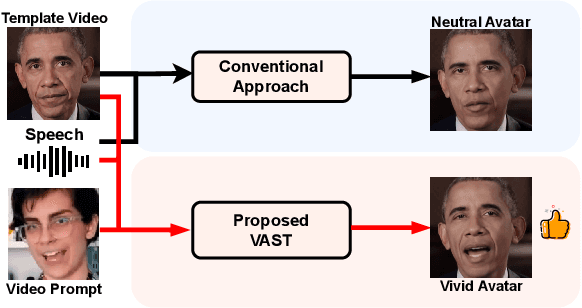

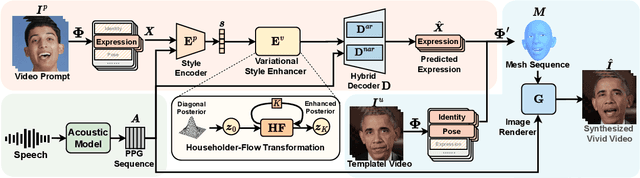
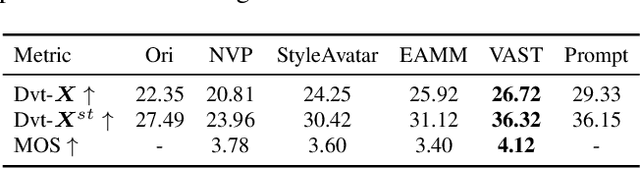
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
Exploring Energy-based Language Models with Different Architectures and Training Methods for Speech Recognition
May 26, 2023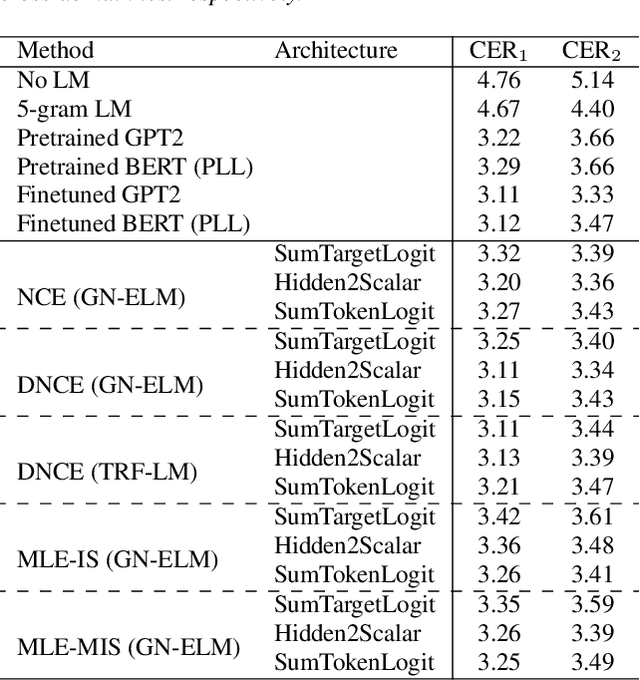
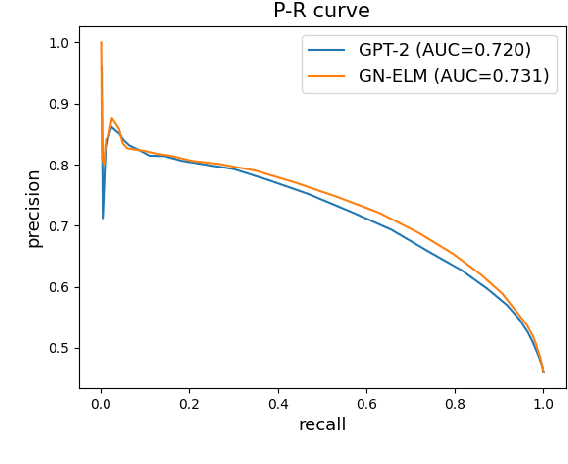
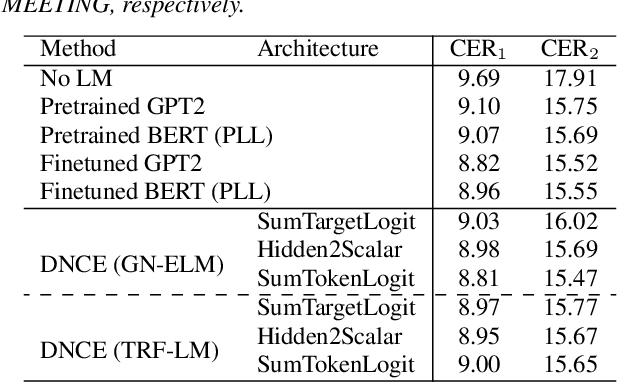

Energy-based language models (ELMs) parameterize an unnormalized distribution for natural sentences and are radically different from popular autoregressive language models (ALMs). As an important application, ELMs have been successfully used as a means for calculating sentence scores in speech recognition, but they all use less-modern CNN or LSTM networks. The recent progress in Transformer networks and large pretrained models such as BERT and GPT2 opens new possibility to further advancing ELMs. In this paper, we explore different architectures of energy functions and different training methods to investigate the capabilities of ELMs in rescoring for speech recognition, all using large pretrained models as backbones.
An Experimental Review of Speaker Diarization methods with application to Two-Speaker Conversational Telephone Speech recordings
May 29, 2023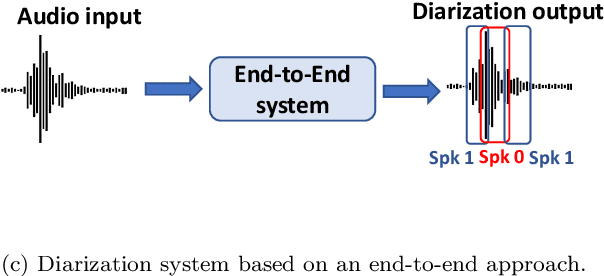
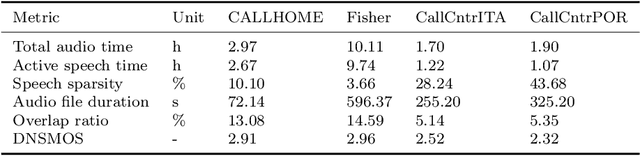
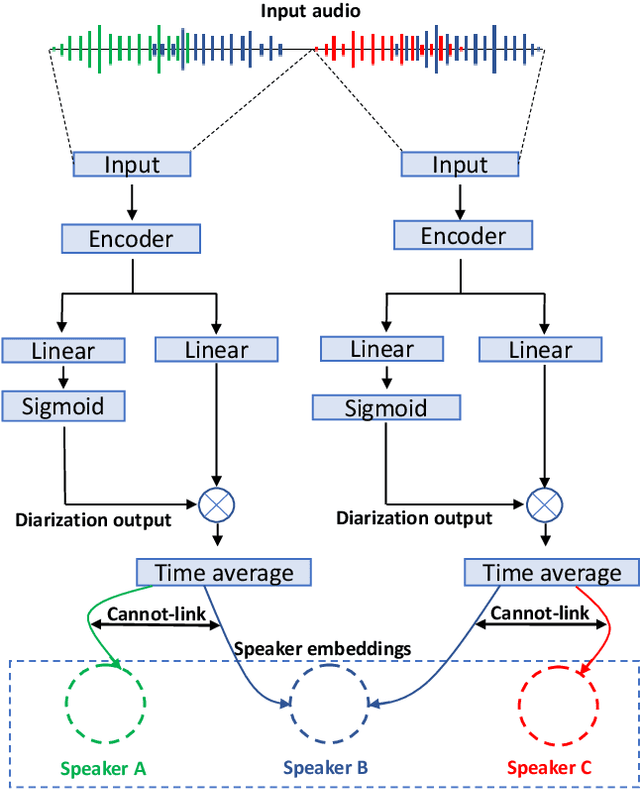
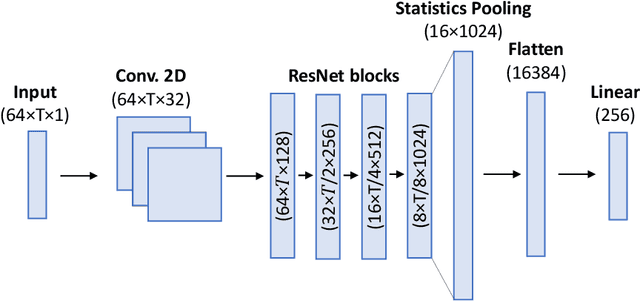
We performed an experimental review of current diarization systems for the conversational telephone speech (CTS) domain. In detail, we considered a total of eight different algorithms belonging to clustering-based, end-to-end neural diarization (EEND), and speech separation guided diarization (SSGD) paradigms. We studied the inference-time computational requirements and diarization accuracy on four CTS datasets with different characteristics and languages. We found that, among all methods considered, EEND-vector clustering (EEND-VC) offers the best trade-off in terms of computing requirements and performance. More in general, EEND models have been found to be lighter and faster in inference compared to clustering-based methods. However, they also require a large amount of diarization-oriented annotated data. In particular EEND-VC performance in our experiments degraded when the dataset size was reduced, whereas self-attentive EEND (SA-EEND) was less affected. We also found that SA-EEND gives less consistent results among all the datasets compared to EEND-VC, with its performance degrading on long conversations with high speech sparsity. Clustering-based diarization systems, and in particular VBx, instead have more consistent performance compared to SA-EEND but are outperformed by EEND-VC. The gap with respect to this latter is reduced when overlap-aware clustering methods are considered. SSGD is the most computationally demanding method, but it could be convenient if speech recognition has to be performed. Its performance is close to SA-EEND but degrades significantly when the training and inference data characteristics are less matched.
Code-Switched Urdu ASR for Noisy Telephonic Environment using Data Centric Approach with Hybrid HMM and CNN-TDNN
Jul 24, 2023Call Centers have huge amount of audio data which can be used for achieving valuable business insights and transcription of phone calls is manually tedious task. An effective Automated Speech Recognition system can accurately transcribe these calls for easy search through call history for specific context and content allowing automatic call monitoring, improving QoS through keyword search and sentiment analysis. ASR for Call Center requires more robustness as telephonic environment are generally noisy. Moreover, there are many low-resourced languages that are on verge of extinction which can be preserved with help of Automatic Speech Recognition Technology. Urdu is the $10^{th}$ most widely spoken language in the world, with 231,295,440 worldwide still remains a resource constrained language in ASR. Regional call-center conversations operate in local language, with a mix of English numbers and technical terms generally causing a "code-switching" problem. Hence, this paper describes an implementation framework of a resource efficient Automatic Speech Recognition/ Speech to Text System in a noisy call-center environment using Chain Hybrid HMM and CNN-TDNN for Code-Switched Urdu Language. Using Hybrid HMM-DNN approach allowed us to utilize the advantages of Neural Network with less labelled data. Adding CNN with TDNN has shown to work better in noisy environment due to CNN's additional frequency dimension which captures extra information from noisy speech, thus improving accuracy. We collected data from various open sources and labelled some of the unlabelled data after analysing its general context and content from Urdu language as well as from commonly used words from other languages, primarily English and were able to achieve WER of 5.2% with noisy as well as clean environment in isolated words or numbers as well as in continuous spontaneous speech.
Contextual Biasing of Named-Entities with Large Language Models
Sep 01, 2023
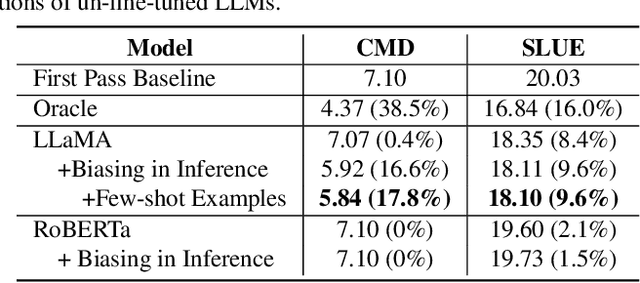
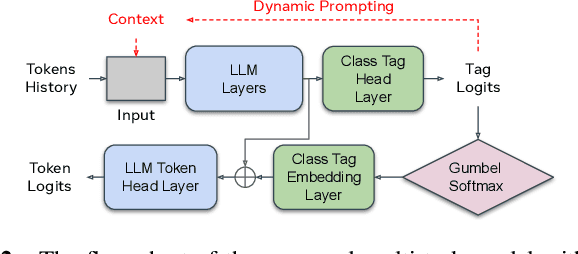
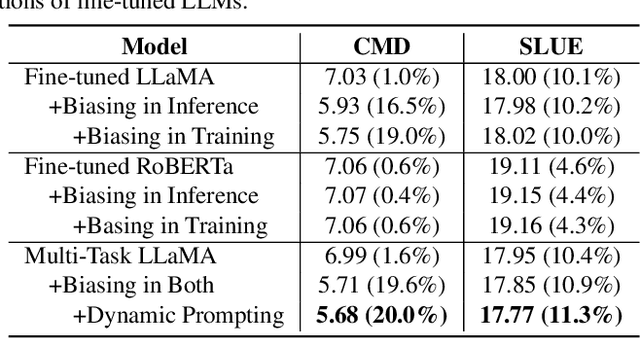
This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.