 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Small and Fast BERT for Chinese Medical Punctuation Restoration
Aug 24, 2023

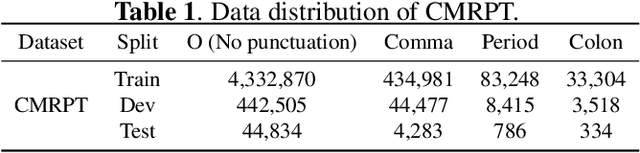
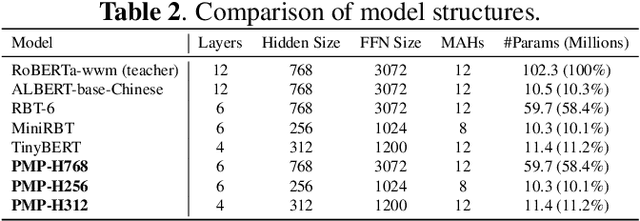
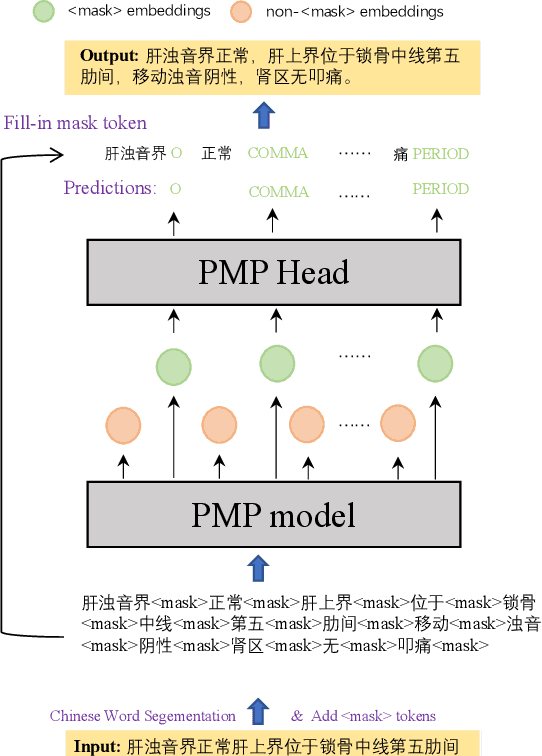
In clinical dictation, utterances after automatic speech recognition (ASR) without explicit punctuation marks may lead to the misunderstanding of dictated reports. To give a precise and understandable clinical report with ASR, automatic punctuation restoration is required. Considering a practical scenario, we propose a fast and light pre-trained model for Chinese medical punctuation restoration based on 'pretraining and fine-tuning' paradigm. In this work, we distill pre-trained models by incorporating supervised contrastive learning and a novel auxiliary pre-training task (Punctuation Mark Prediction) to make it well-suited for punctuation restoration. Our experiments on various distilled models reveal that our model can achieve 95% performance while 10% model size relative to state-of-the-art Chinese RoBERTa.
DGSD: Dynamical Graph Self-Distillation for EEG-Based Auditory Spatial Attention Detection
Sep 07, 2023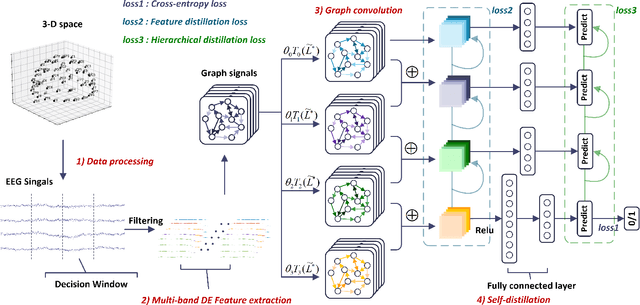
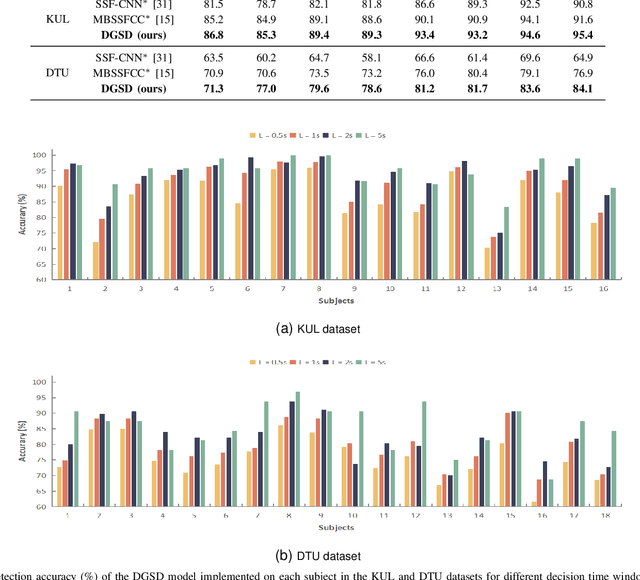
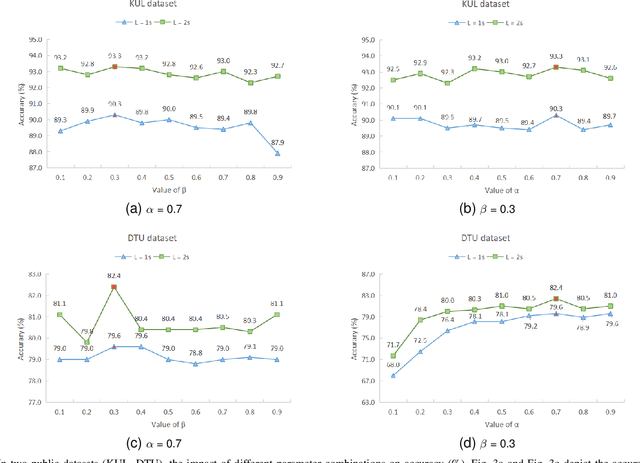

Auditory Attention Detection (AAD) aims to detect target speaker from brain signals in a multi-speaker environment. Although EEG-based AAD methods have shown promising results in recent years, current approaches primarily rely on traditional convolutional neural network designed for processing Euclidean data like images. This makes it challenging to handle EEG signals, which possess non-Euclidean characteristics. In order to address this problem, this paper proposes a dynamical graph self-distillation (DGSD) approach for AAD, which does not require speech stimuli as input. Specifically, to effectively represent the non-Euclidean properties of EEG signals, dynamical graph convolutional networks are applied to represent the graph structure of EEG signals, which can also extract crucial features related to auditory spatial attention in EEG signals. In addition, to further improve AAD detection performance, self-distillation, consisting of feature distillation and hierarchical distillation strategies at each layer, is integrated. These strategies leverage features and classification results from the deepest network layers to guide the learning of shallow layers. Our experiments are conducted on two publicly available datasets, KUL and DTU. Under a 1-second time window, we achieve results of 90.0\% and 79.6\% accuracy on KUL and DTU, respectively. We compare our DGSD method with competitive baselines, and the experimental results indicate that the detection performance of our proposed DGSD method is not only superior to the best reproducible baseline but also significantly reduces the number of trainable parameters by approximately 100 times.
Transforming the Embeddings: A Lightweight Technique for Speech Emotion Recognition Tasks
May 29, 2023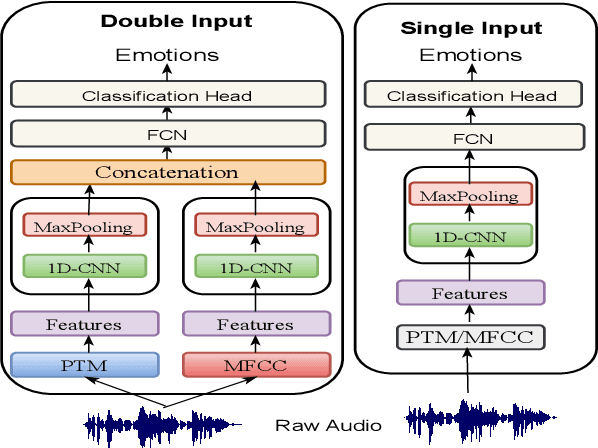

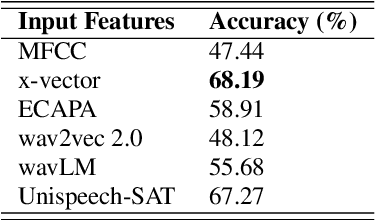
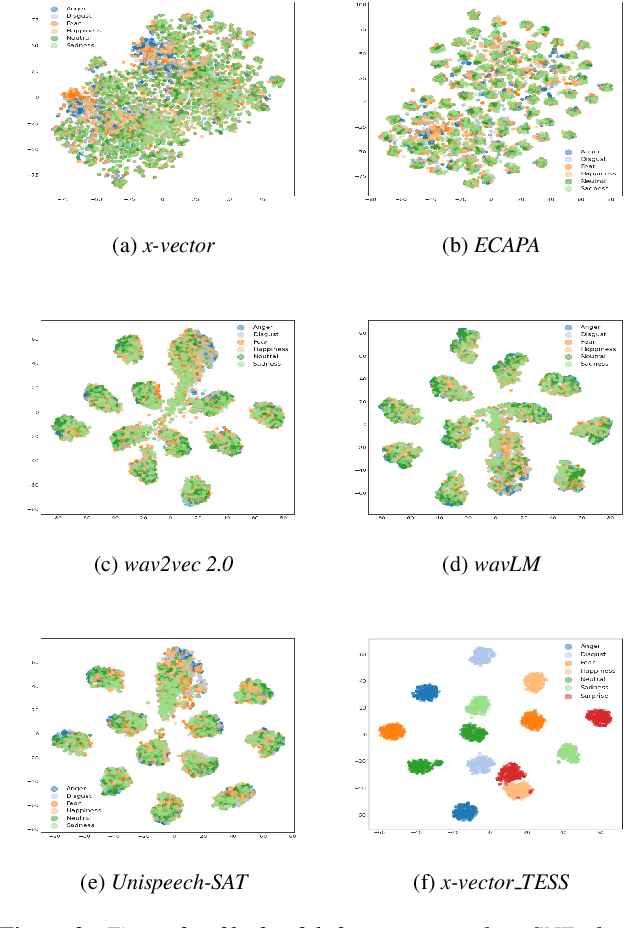
Speech emotion recognition (SER) is a field that has drawn a lot of attention due to its applications in diverse fields. A current trend in methods used for SER is to leverage embeddings from pre-trained models (PTMs) as input features to downstream models. However, the use of embeddings from speaker recognition PTMs hasn't garnered much focus in comparison to other PTM embeddings. To fill this gap and in order to understand the efficacy of speaker recognition PTM embeddings, we perform a comparative analysis of five PTM embeddings. Among all, x-vector embeddings performed the best possibly due to its training for speaker recognition leading to capturing various components of speech such as tone, pitch, etc. Our modeling approach which utilizes x-vector embeddings and mel-frequency cepstral coefficients (MFCC) as input features is the most lightweight approach while achieving comparable accuracy to previous state-of-the-art (SOTA) methods in the CREMA-D benchmark.
PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
Jun 01, 2023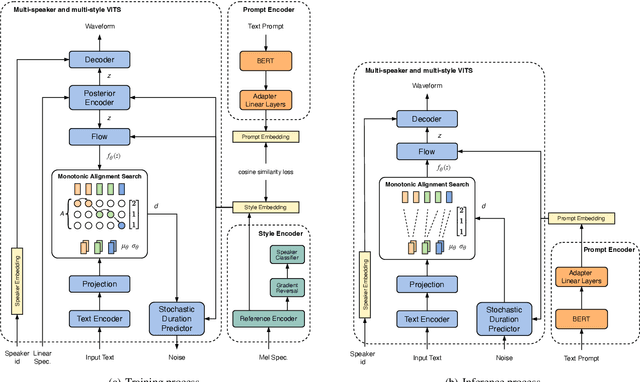
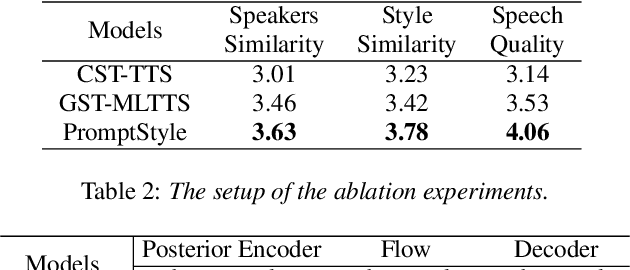
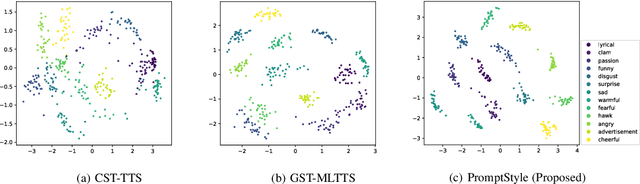
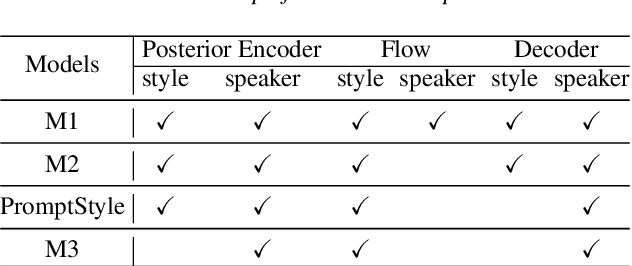
Style transfer TTS has shown impressive performance in recent years. However, style control is often restricted to systems built on expressive speech recordings with discrete style categories. In practical situations, users may be interested in transferring style by typing text descriptions of desired styles, without the reference speech in the target style. The text-guided content generation techniques have drawn wide attention recently. In this work, we explore the possibility of controllable style transfer with natural language descriptions. To this end, we propose PromptStyle, a text prompt-guided cross-speaker style transfer system. Specifically, PromptStyle consists of an improved VITS and a cross-modal style encoder. The cross-modal style encoder constructs a shared space of stylistic and semantic representation through a two-stage training process. Experiments show that PromptStyle can achieve proper style transfer with text prompts while maintaining relatively high stability and speaker similarity. Audio samples are available in our demo page.
Spoken Language Identification System for English-Mandarin Code-Switching Child-Directed Speech
Jun 01, 2023
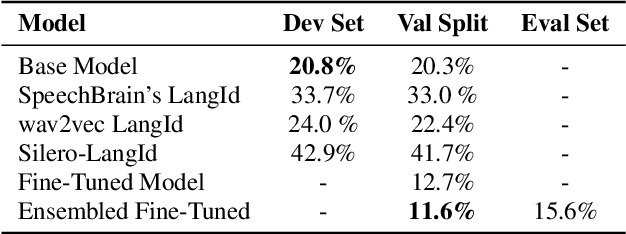
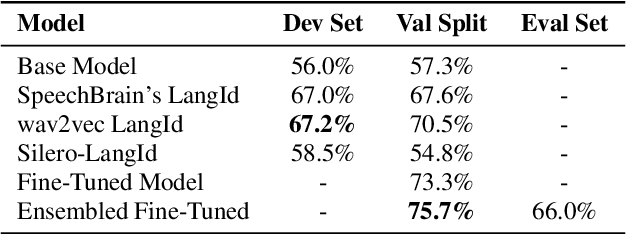

This work focuses on improving the Spoken Language Identification (LangId) system for a challenge that focuses on developing robust language identification systems that are reliable for non-standard, accented (Singaporean accent), spontaneous code-switched, and child-directed speech collected via Zoom. We propose a two-stage Encoder-Decoder-based E2E model. The encoder module consists of 1D depth-wise separable convolutions with Squeeze-and-Excitation (SE) layers with a global context. The decoder module uses an attentive temporal pooling mechanism to get fixed length time-independent feature representation. The total number of parameters in the model is around 22.1 M, which is relatively light compared to using some large-scale pre-trained speech models. We achieved an EER of 15.6% in the closed track and 11.1% in the open track (baseline system 22.1%). We also curated additional LangId data from YouTube videos (having Singaporean speakers), which will be released for public use.
Enhancing Gappy Speech Audio Signals with Generative Adversarial Networks
May 09, 2023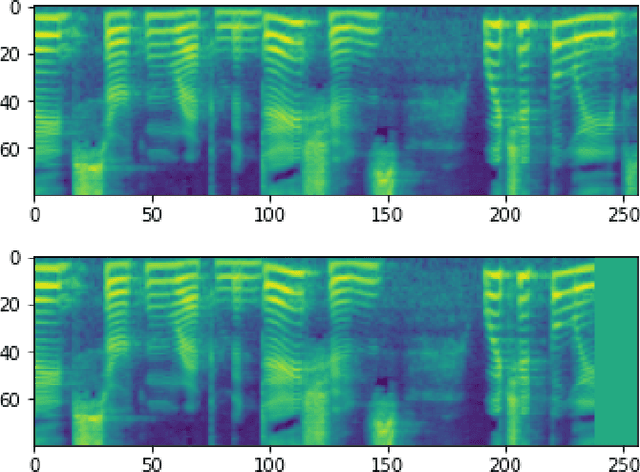
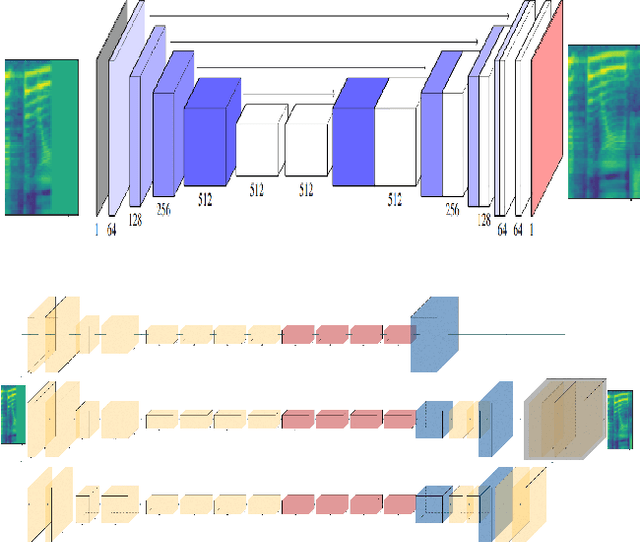
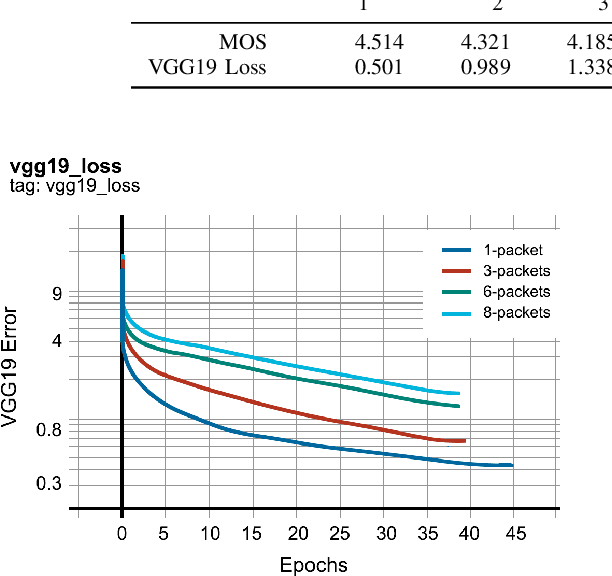

Gaps, dropouts and short clips of corrupted audio are a common problem and particularly annoying when they occur in speech. This paper uses machine learning to regenerate gaps of up to 320ms in an audio speech signal. Audio regeneration is translated into image regeneration by transforming audio into a Mel-spectrogram and using image in-painting to regenerate the gaps. The full Mel-spectrogram is then transferred back to audio using the Parallel-WaveGAN vocoder and integrated into the audio stream. Using a sample of 1300 spoken audio clips of between 1 and 10 seconds taken from the publicly-available LJSpeech dataset our results show regeneration of audio gaps in close to real time using GANs with a GPU equipped system. As expected, the smaller the gap in the audio, the better the quality of the filled gaps. On a gap of 240ms the average mean opinion score (MOS) for the best performing models was 3.737, on a scale of 1 (worst) to 5 (best) which is sufficient for a human to perceive as close to uninterrupted human speech.
Recycle-and-Distill: Universal Compression Strategy for Transformer-based Speech SSL Models with Attention Map Reusing and Masking Distillation
May 19, 2023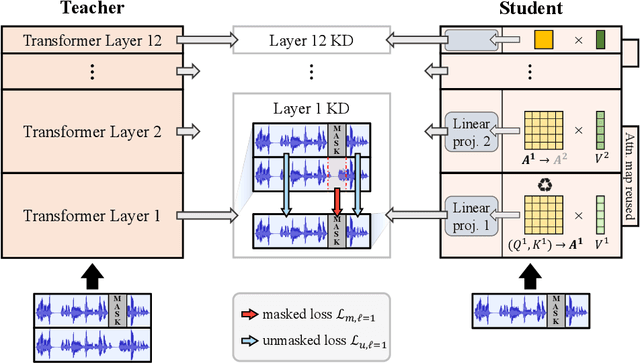
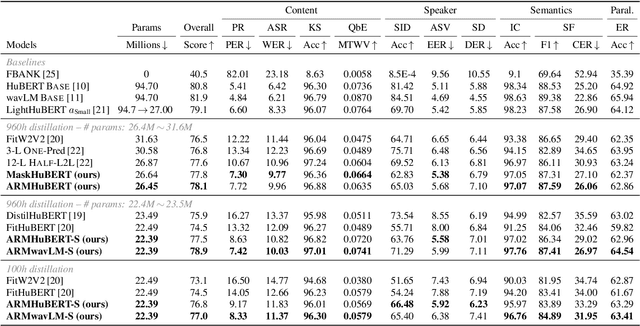
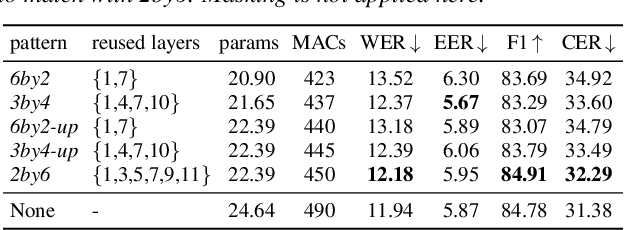
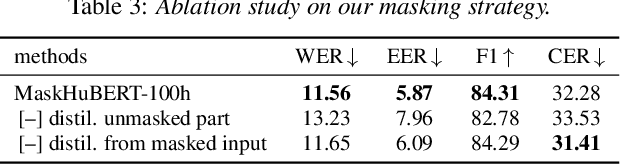
Transformer-based speech self-supervised learning (SSL) models, such as HuBERT, show surprising performance in various speech processing tasks. However, huge number of parameters in speech SSL models necessitate the compression to a more compact model for wider usage in academia or small companies. In this study, we suggest to reuse attention maps across the Transformer layers, so as to remove key and query parameters while retaining the number of layers. Furthermore, we propose a novel masking distillation strategy to improve the student model's speech representation quality. We extend the distillation loss to utilize both masked and unmasked speech frames to fully leverage the teacher model's high-quality representation. Our universal compression strategy yields the student model that achieves phoneme error rate (PER) of 7.72% and word error rate (WER) of 9.96% on the SUPERB benchmark.
ReZero: Region-customizable Sound Extraction
Aug 31, 2023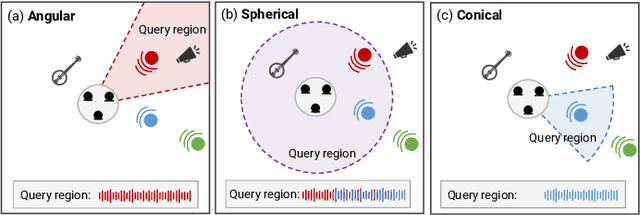
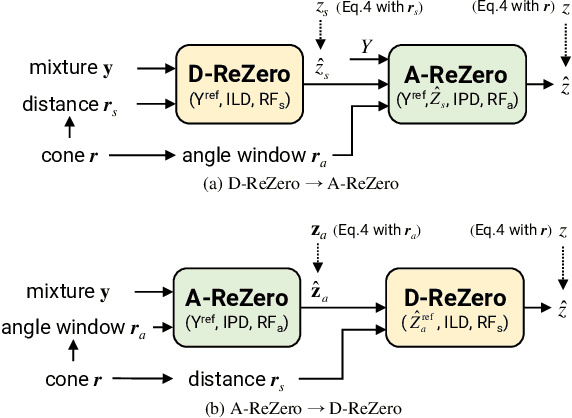
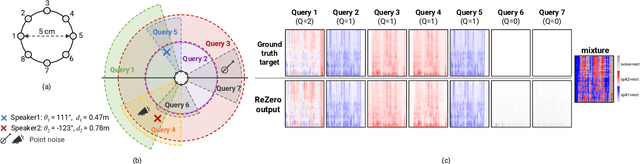

We introduce region-customizable sound extraction (ReZero), a general and flexible framework for the multi-channel region-wise sound extraction (R-SE) task. R-SE task aims at extracting all active target sounds (e.g., human speech) within a specific, user-defined spatial region, which is different from conventional and existing tasks where a blind separation or a fixed, predefined spatial region are typically assumed. The spatial region can be defined as an angular window, a sphere, a cone, or other geometric patterns. Being a solution to the R-SE task, the proposed ReZero framework includes (1) definitions of different types of spatial regions, (2) methods for region feature extraction and aggregation, and (3) a multi-channel extension of the band-split RNN (BSRNN) model specified for the R-SE task. We design experiments for different microphone array geometries, different types of spatial regions, and comprehensive ablation studies on different system configurations. Experimental results on both simulated and real-recorded data demonstrate the effectiveness of ReZero. Demos are available at https://innerselfm.github.io/rezero/.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023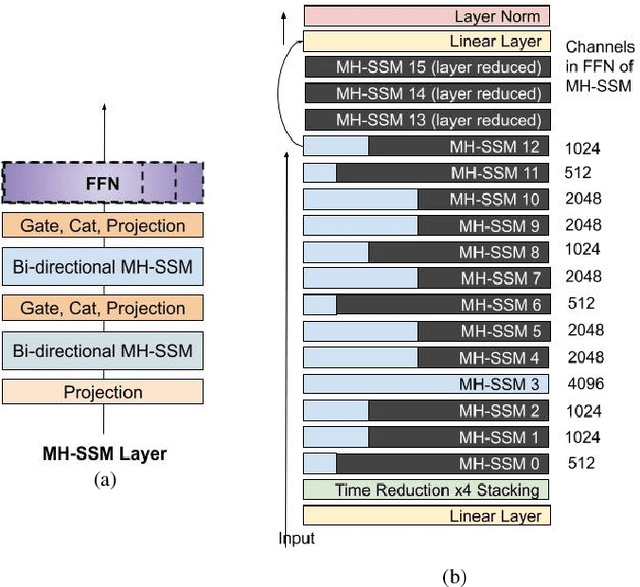
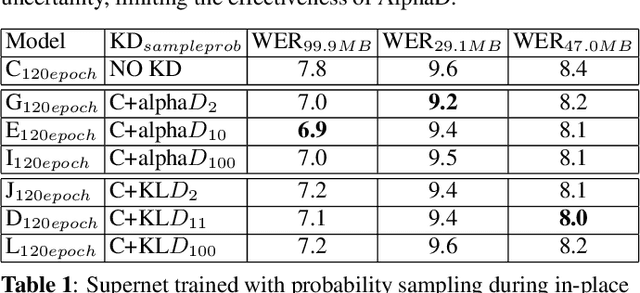
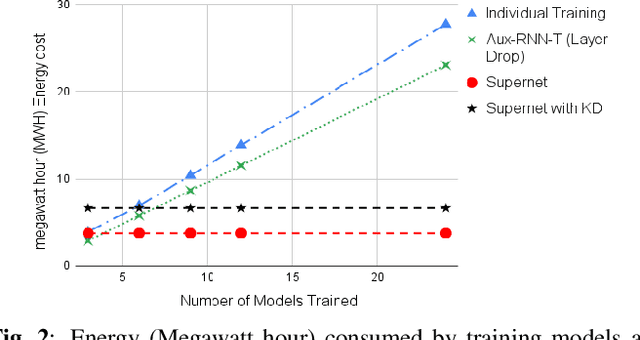
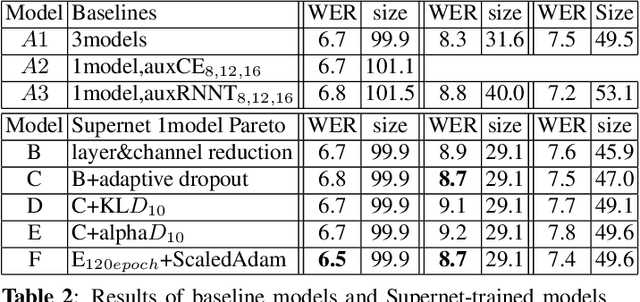
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation
May 19, 2023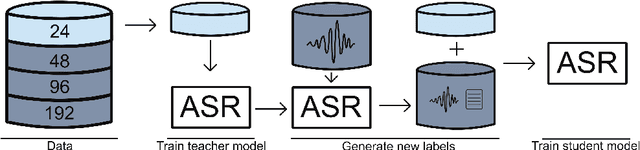
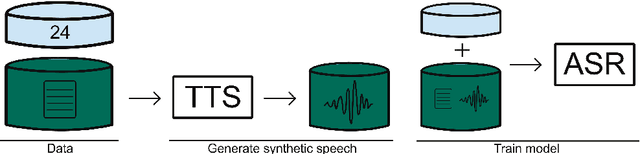
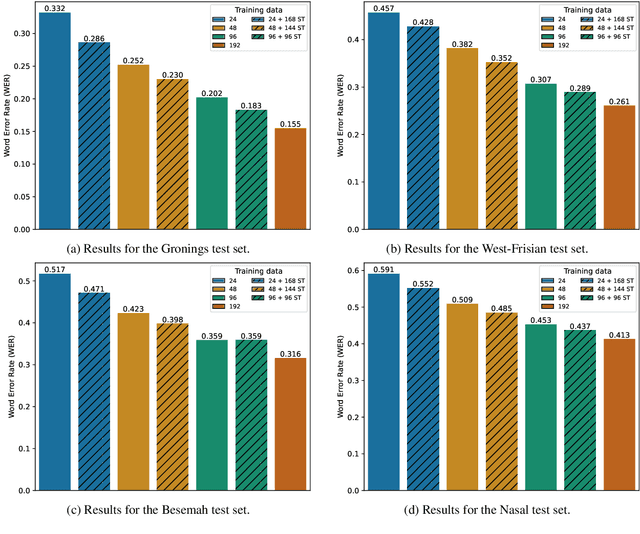
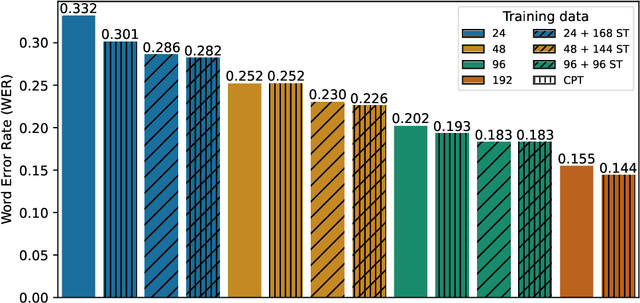
The performance of automatic speech recognition (ASR) systems has advanced substantially in recent years, particularly for languages for which a large amount of transcribed speech is available. Unfortunately, for low-resource languages, such as minority languages, regional languages or dialects, ASR performance generally remains much lower. In this study, we investigate whether data augmentation techniques could help improve low-resource ASR performance, focusing on four typologically diverse minority languages or language variants (West Germanic: Gronings, West-Frisian; Malayo-Polynesian: Besemah, Nasal). For all four languages, we examine the use of self-training, where an ASR system trained with the available human-transcribed data is used to generate transcriptions, which are then combined with the original data to train a new ASR system. For Gronings, for which there was a pre-existing text-to-speech (TTS) system available, we also examined the use of TTS to generate ASR training data from text-only sources. We find that using a self-training approach consistently yields improved performance (a relative WER reduction up to 20.5% compared to using an ASR system trained on 24 minutes of manually transcribed speech). The performance gain from TTS augmentation for Gronings was even stronger (up to 25.5% relative reduction in WER compared to a system based on 24 minutes of manually transcribed speech). In sum, our results show the benefit of using self-training or (if possible) TTS-generated data as an efficient solution to overcome the limitations of data availability for resource-scarce languages in order to improve ASR performance.