 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
XPhoneBERT: A Pre-trained Multilingual Model for Phoneme Representations for Text-to-Speech
May 31, 2023
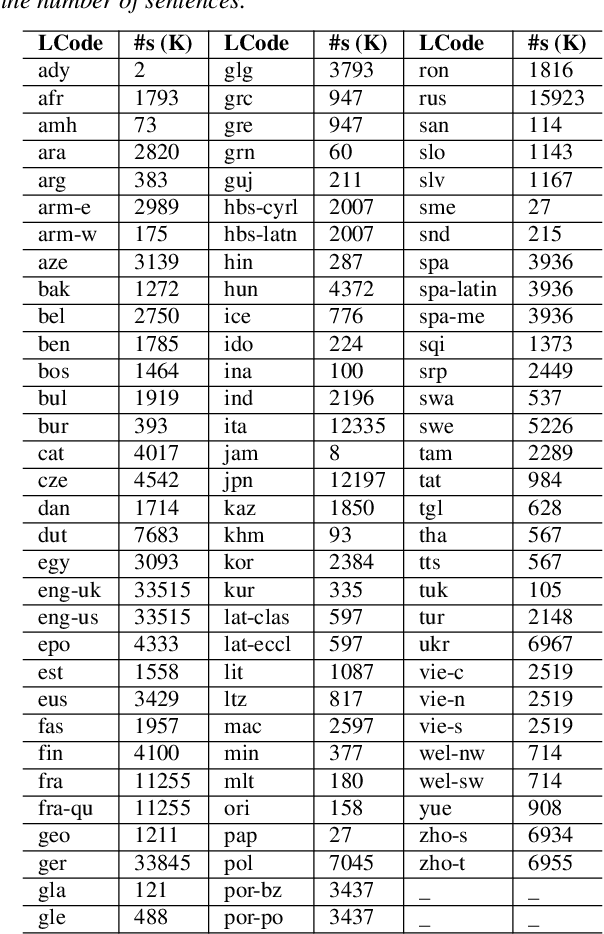

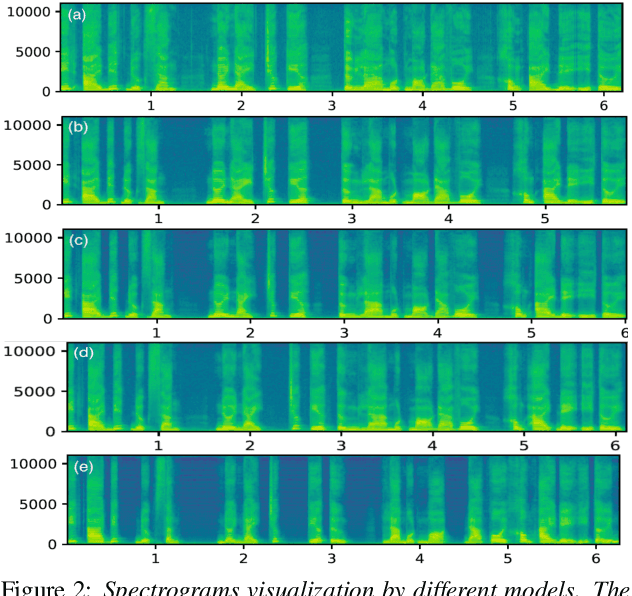
We present XPhoneBERT, the first multilingual model pre-trained to learn phoneme representations for the downstream text-to-speech (TTS) task. Our XPhoneBERT has the same model architecture as BERT-base, trained using the RoBERTa pre-training approach on 330M phoneme-level sentences from nearly 100 languages and locales. Experimental results show that employing XPhoneBERT as an input phoneme encoder significantly boosts the performance of a strong neural TTS model in terms of naturalness and prosody and also helps produce fairly high-quality speech with limited training data. We publicly release our pre-trained XPhoneBERT with the hope that it would facilitate future research and downstream TTS applications for multiple languages. Our XPhoneBERT model is available at https://github.com/VinAIResearch/XPhoneBERT
Evaluation of Speech Representations for MOS prediction
Jun 16, 2023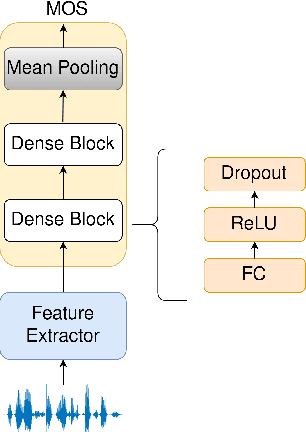
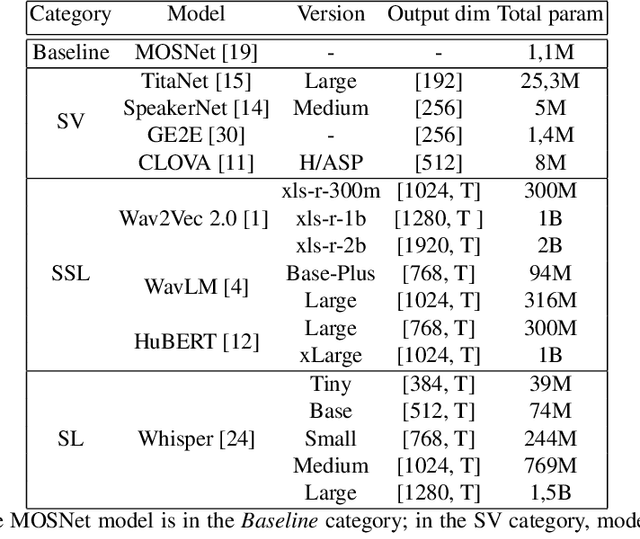
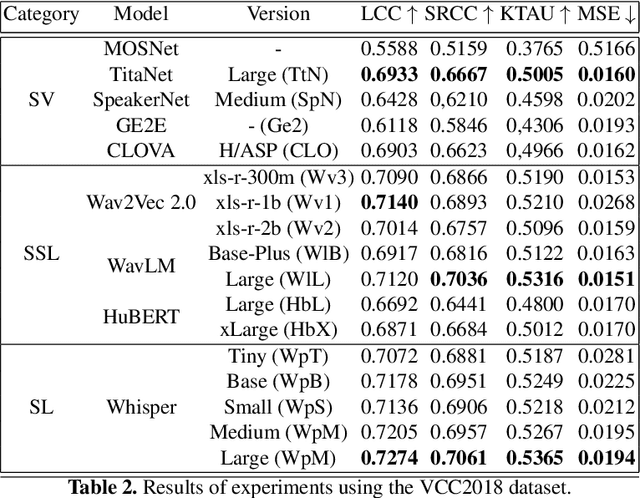
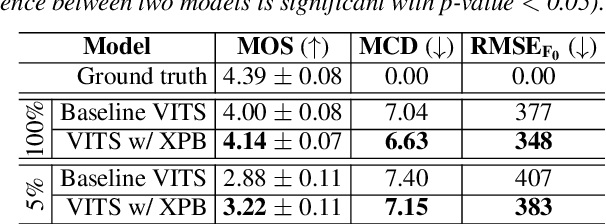
In this paper, we evaluate feature extraction models for predicting speech quality. We also propose a model architecture to compare embeddings of supervised learning and self-supervised learning models with embeddings of speaker verification models to predict the metric MOS. Our experiments were performed on the VCC2018 dataset and a Brazilian-Portuguese dataset called BRSpeechMOS, which was created for this work. The results show that the Whisper model is appropriate in all scenarios: with both the VCC2018 and BRSpeech- MOS datasets. Among the supervised and self-supervised learning models using BRSpeechMOS, Whisper-Small achieved the best linear correlation of 0.6980, and the speaker verification model, SpeakerNet, had linear correlation of 0.6963. Using VCC2018, the best supervised and self-supervised learning model, Whisper-Large, achieved linear correlation of 0.7274, and the best model speaker verification, TitaNet, achieved a linear correlation of 0.6933. Although the results of the speaker verification models are slightly lower, the SpeakerNet model has only 5M parameters, making it suitable for real-time applications, and the TitaNet model produces an embedding of size 192, the smallest among all the evaluated models. The experiment results are reproducible with publicly available source-code1 .
Speech Intelligibility Classifiers from 550k Disordered Speech Samples
Mar 15, 2023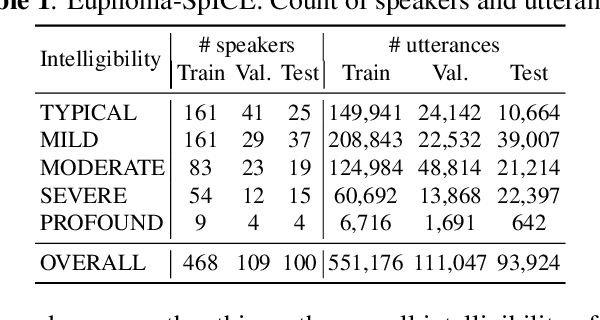
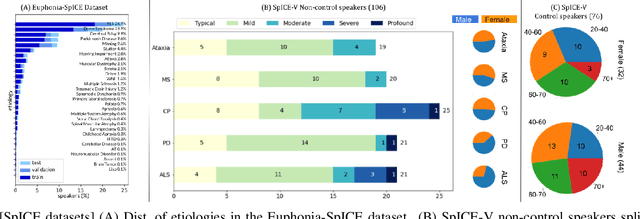
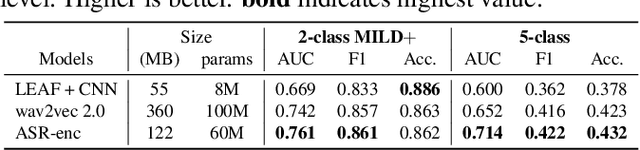
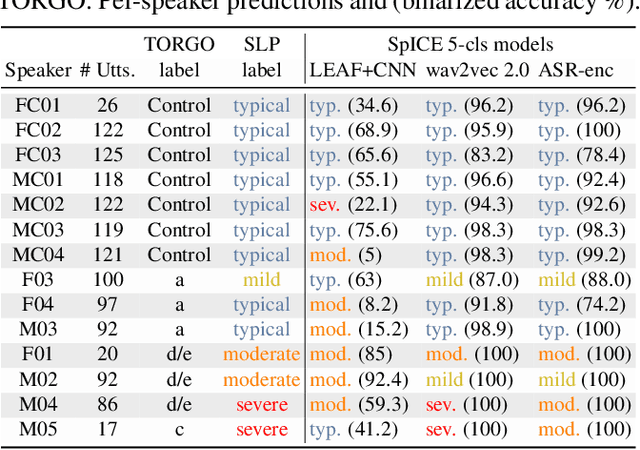
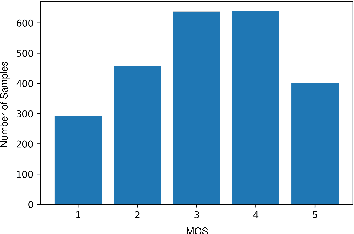
We developed dysarthric speech intelligibility classifiers on 551,176 disordered speech samples contributed by a diverse set of 468 speakers, with a range of self-reported speaking disorders and rated for their overall intelligibility on a five-point scale. We trained three models following different deep learning approaches and evaluated them on ~94K utterances from 100 speakers. We further found the models to generalize well (without further training) on the TORGO database (100% accuracy), UASpeech (0.93 correlation), ALS-TDI PMP (0.81 AUC) datasets as well as on a dataset of realistic unprompted speech we gathered (106 dysarthric and 76 control speakers,~2300 samples).
Prompting Large Language Models for Zero-Shot Domain Adaptation in Speech Recognition
Jun 28, 2023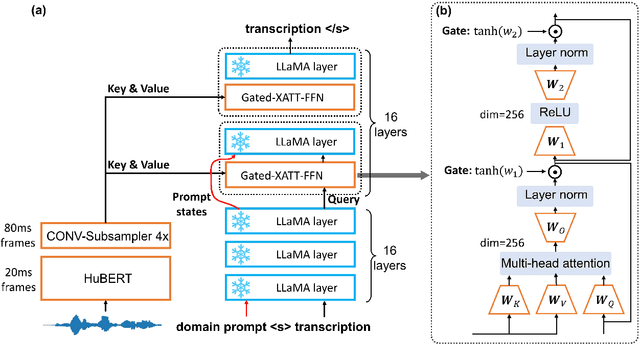
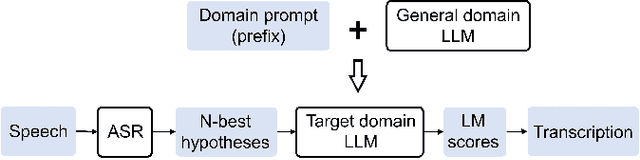
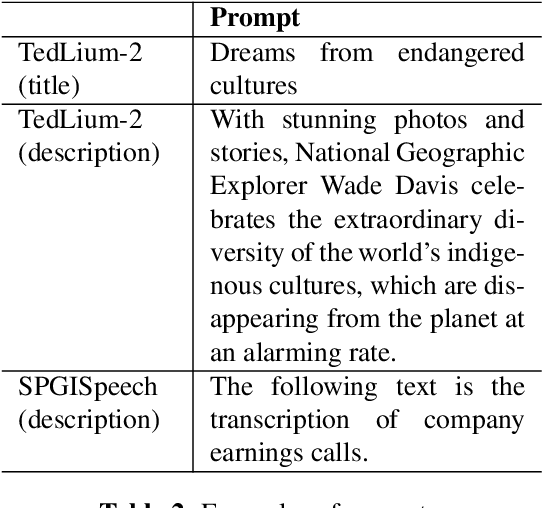
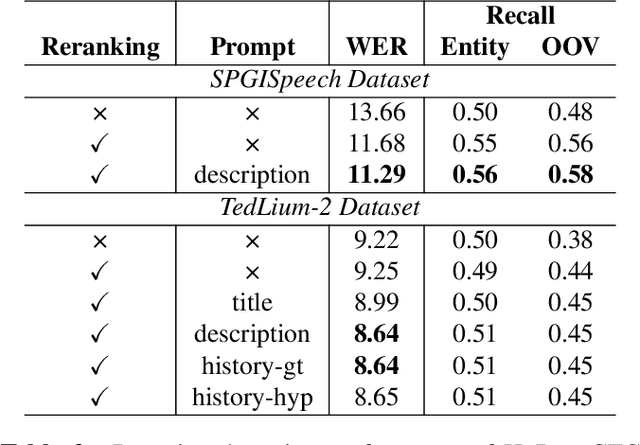
The integration of Language Models (LMs) has proven to be an effective way to address domain shifts in speech recognition. However, these approaches usually require a significant amount of target domain text data for the training of LMs. Different from these methods, in this work, with only a domain-specific text prompt, we propose two zero-shot ASR domain adaptation methods using LLaMA, a 7-billion-parameter large language model (LLM). LLM is used in two ways: 1) second-pass rescoring: reranking N-best hypotheses of a given ASR system with LLaMA; 2) deep LLM-fusion: incorporating LLM into the decoder of an encoder-decoder based ASR system. Experiments show that, with only one domain prompt, both methods can effectively reduce word error rates (WER) on out-of-domain TedLium-2 and SPGISpeech datasets. Especially, the deep LLM-fusion has the advantage of better recall of entity and out-of-vocabulary words.
Employing Hybrid Deep Neural Networks on Dari Speech
May 04, 2023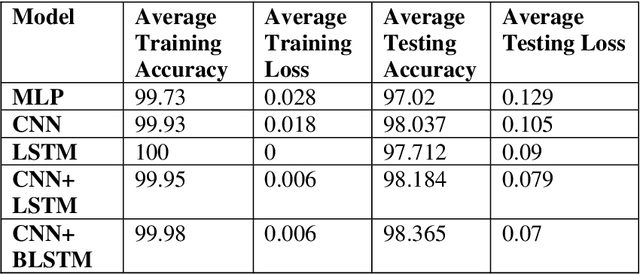
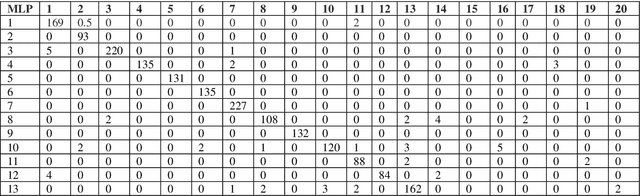

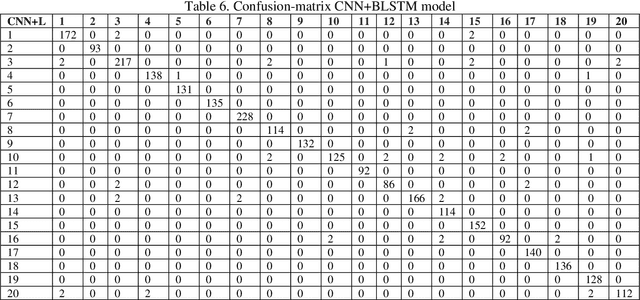
This paper is an extension of our previous conference paper. In recent years, there has been a growing interest among researchers in developing and improving speech recognition systems to facilitate and enhance human-computer interaction. Today, Automatic Speech Recognition (ASR) systems have become ubiquitous, used in everything from games to translation systems, robots, and more. However, much research is still needed on speech recognition systems for low-resource languages. This article focuses on the recognition of individual words in the Dari language using the Mel-frequency cepstral coefficients (MFCCs) feature extraction method and three different deep neural network models: Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Multilayer Perceptron (MLP), as well as two hybrid models combining CNN and RNN. We evaluate these models using an isolated Dari word corpus that we have created, consisting of 1000 utterances for 20 short Dari terms. Our study achieved an impressive average accuracy of 98.365%.
MERLIon CCS Challenge: A English-Mandarin code-switching child-directed speech corpus for language identification and diarization
May 30, 2023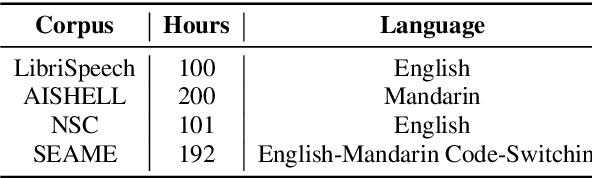
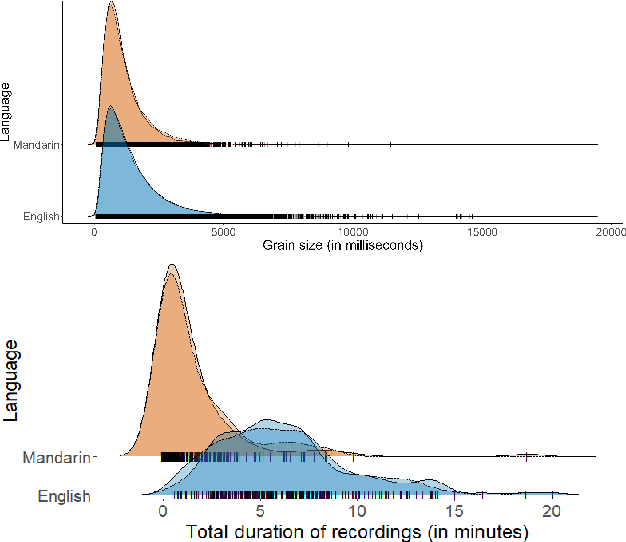
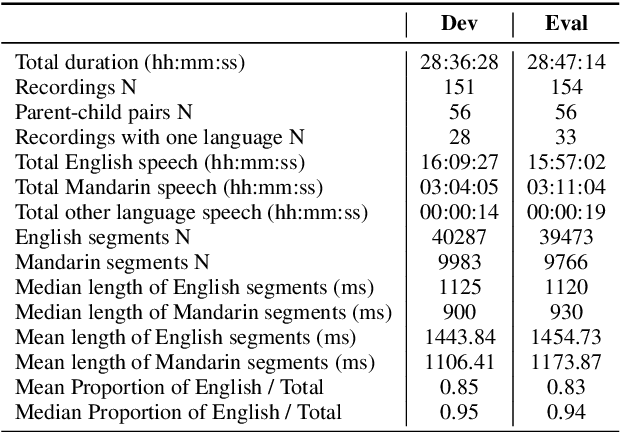
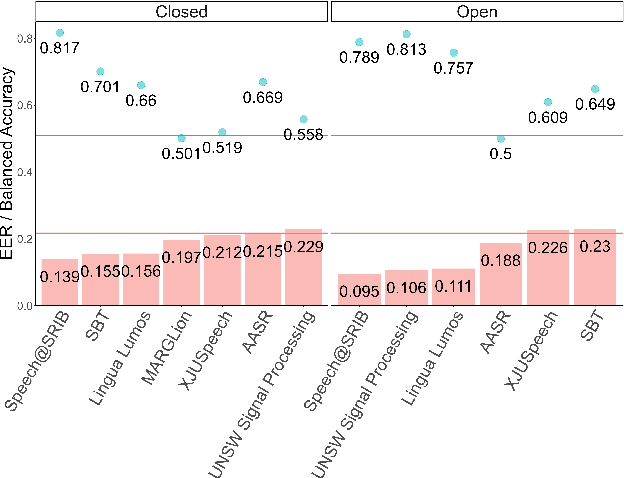
To enhance the reliability and robustness of language identification (LID) and language diarization (LD) systems for heterogeneous populations and scenarios, there is a need for speech processing models to be trained on datasets that feature diverse language registers and speech patterns. We present the MERLIon CCS challenge, featuring a first-of-its-kind Zoom video call dataset of parent-child shared book reading, of over 30 hours with over 300 recordings, annotated by multilingual transcribers using a high-fidelity linguistic transcription protocol. The audio corpus features spontaneous and in-the-wild English-Mandarin code-switching, child-directed speech in non-standard accents with diverse language-mixing patterns recorded in a variety of home environments. This report describes the corpus, as well as LID and LD results for our baseline and several systems submitted to the MERLIon CCS challenge using the corpus.
Robust Open-Set Spoken Language Identification and the CU MultiLang Dataset
Aug 29, 2023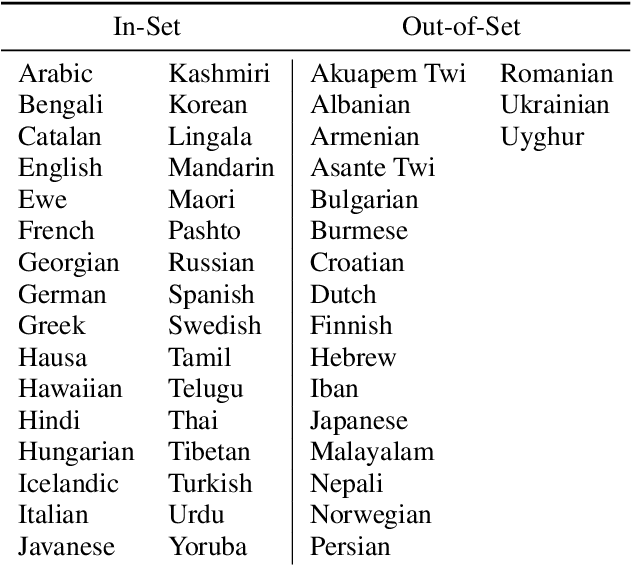
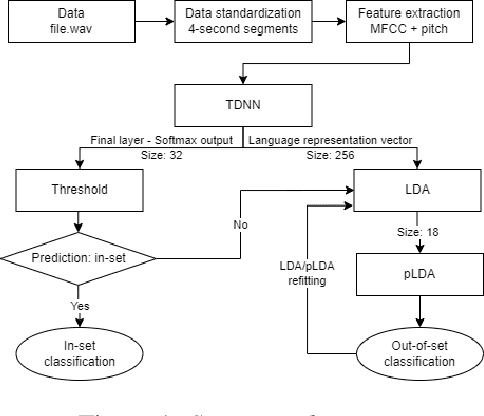
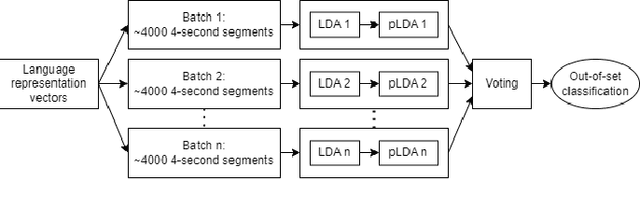
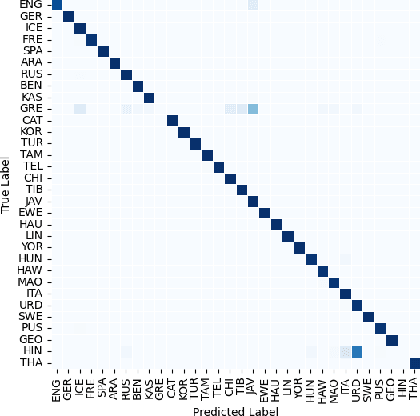
Most state-of-the-art spoken language identification models are closed-set; in other words, they can only output a language label from the set of classes they were trained on. Open-set spoken language identification systems, however, gain the ability to detect when an input exhibits none of the original languages. In this paper, we implement a novel approach to open-set spoken language identification that uses MFCC and pitch features, a TDNN model to extract meaningful feature embeddings, confidence thresholding on softmax outputs, and LDA and pLDA for learning to classify new unknown languages. We present a spoken language identification system that achieves 91.76% accuracy on trained languages and has the capability to adapt to unknown languages on the fly. To that end, we also built the CU MultiLang Dataset, a large and diverse multilingual speech corpus which was used to train and evaluate our system.
* 6pages, 1 table, 6 figures
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 11, 2023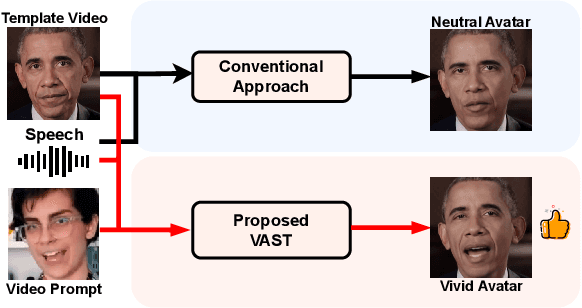

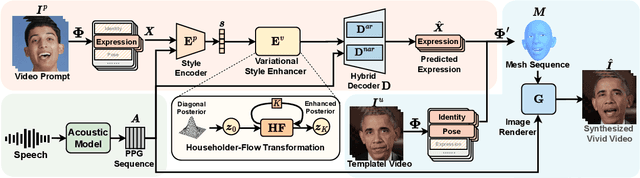
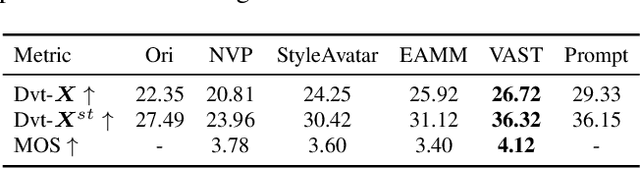
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
Toward Connecting Speech Acts and Search Actions in Conversational Search Tasks
May 08, 2023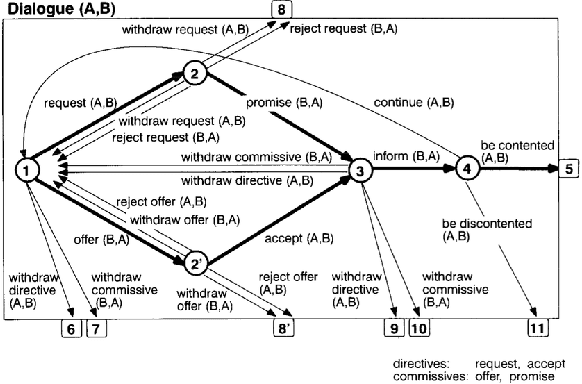
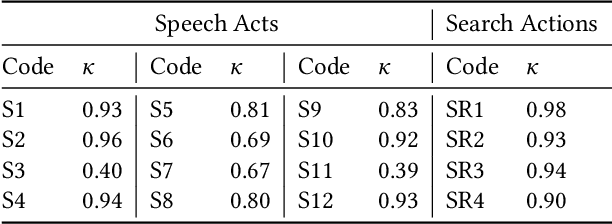
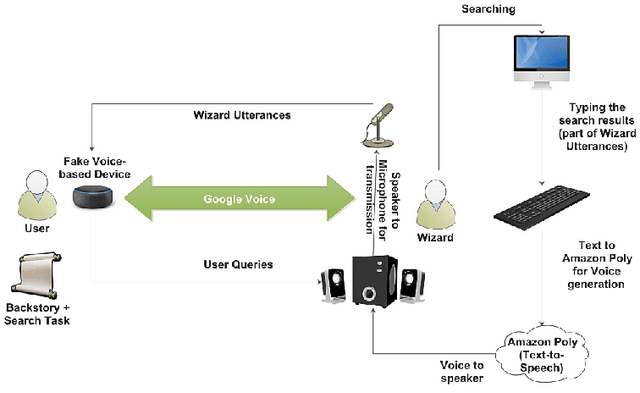
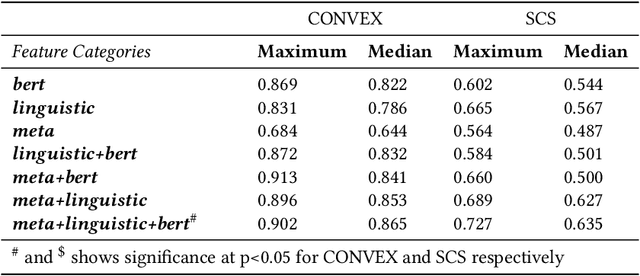
Conversational search systems can improve user experience in digital libraries by facilitating a natural and intuitive way to interact with library content. However, most conversational search systems are limited to performing simple tasks and controlling smart devices. Therefore, there is a need for systems that can accurately understand the user's information requirements and perform the appropriate search activity. Prior research on intelligent systems suggested that it is possible to comprehend the functional aspect of discourse (search intent) by identifying the speech acts in user dialogues. In this work, we automatically identify the speech acts associated with spoken utterances and use them to predict the system-level search actions. First, we conducted a Wizard-of-Oz study to collect data from 75 search sessions. We performed thematic analysis to curate a gold standard dataset -- containing 1,834 utterances and 509 system actions -- of human-system interactions in three information-seeking scenarios. Next, we developed attention-based deep neural networks to understand natural language and predict speech acts. Then, the speech acts were fed to the model to predict the corresponding system-level search actions. We also annotated a second dataset to validate our results. For the two datasets, the best-performing classification model achieved maximum accuracy of 90.2% and 72.7% for speech act classification and 58.8% and 61.1%, respectively, for search act classification.
Hybrid Transducer and Attention based Encoder-Decoder Modeling for Speech-to-Text Tasks
May 04, 2023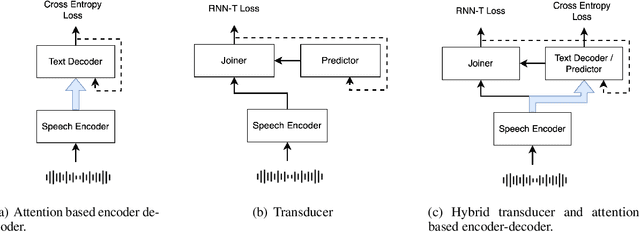
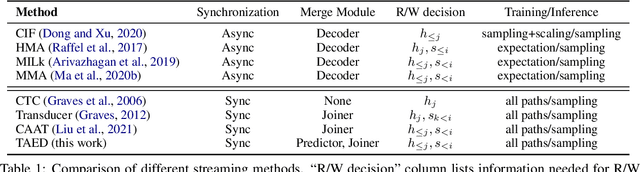


Transducer and Attention based Encoder-Decoder (AED) are two widely used frameworks for speech-to-text tasks. They are designed for different purposes and each has its own benefits and drawbacks for speech-to-text tasks. In order to leverage strengths of both modeling methods, we propose a solution by combining Transducer and Attention based Encoder-Decoder (TAED) for speech-to-text tasks. The new method leverages AED's strength in non-monotonic sequence to sequence learning while retaining Transducer's streaming property. In the proposed framework, Transducer and AED share the same speech encoder. The predictor in Transducer is replaced by the decoder in the AED model, and the outputs of the decoder are conditioned on the speech inputs instead of outputs from an unconditioned language model. The proposed solution ensures that the model is optimized by covering all possible read/write scenarios and creates a matched environment for streaming applications. We evaluate the proposed approach on the \textsc{MuST-C} dataset and the findings demonstrate that TAED performs significantly better than Transducer for offline automatic speech recognition (ASR) and speech-to-text translation (ST) tasks. In the streaming case, TAED outperforms Transducer in the ASR task and one ST direction while comparable results are achieved in another translation direction.