 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Can Self-Supervised Neural Networks Pre-Trained on Human Speech distinguish Animal Callers?
May 23, 2023
Self-supervised learning (SSL) models use only the intrinsic structure of a given signal, independent of its acoustic domain, to extract essential information from the input to an embedding space. This implies that the utility of such representations is not limited to modeling human speech alone. Building on this understanding, this paper explores the cross-transferability of SSL neural representations learned from human speech to analyze bio-acoustic signals. We conduct a caller discrimination analysis and a caller detection study on Marmoset vocalizations using eleven SSL models pre-trained with various pretext tasks. The results show that the embedding spaces carry meaningful caller information and can successfully distinguish the individual identities of Marmoset callers without fine-tuning. This demonstrates that representations pre-trained on human speech can be effectively applied to the bio-acoustics domain, providing valuable insights for future investigations in this field.
Spread Control Method on Unknown Networks Based on Hierarchical Reinforcement Learning
Aug 28, 2023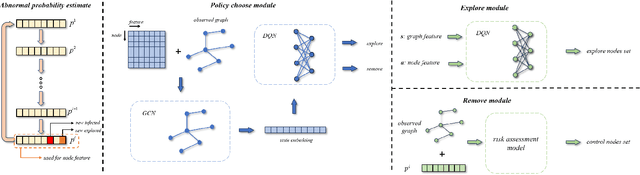
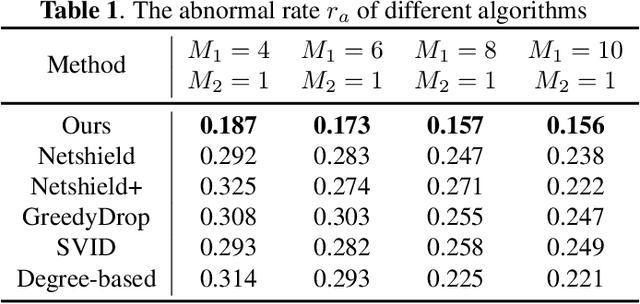
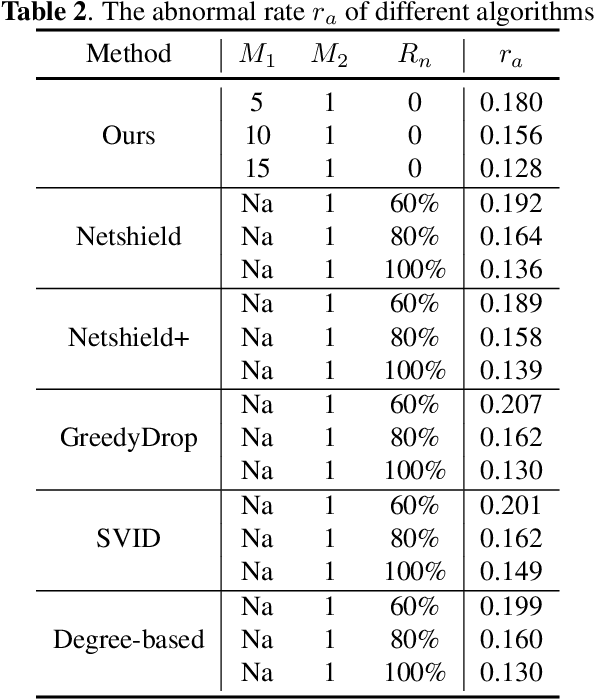
The spread of infectious diseases, rumors, and harmful speech in networks can result in substantial losses, underscoring the significance of studying how to suppress such hazardous events. However, previous studies often assume full knowledge of the network structure, which is often not the case in real-world scenarios. In this paper, we address the challenge of controlling the propagation of hazardous events by removing nodes when the network structure is unknown. To tackle this problem, we propose a hierarchical reinforcement learning method that drastically reduces the action space, making the problem feasible to solve. Simulation experiments demonstrate the superiority of our method over the baseline methods. Remarkably, even though the baseline methods possess extensive knowledge of the network structure, while our method has no prior information about it, our approach still achieves better results.
Turning Whisper into Real-Time Transcription System
Jul 27, 2023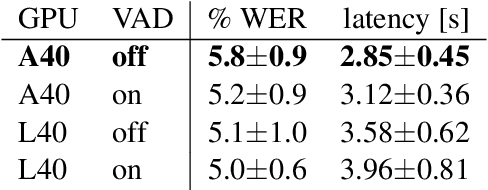
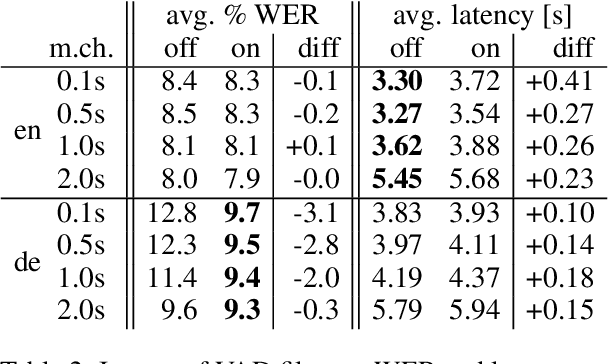
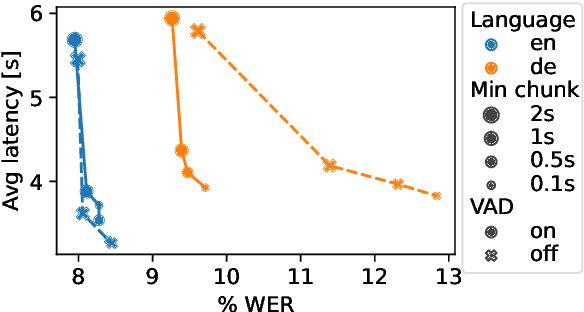
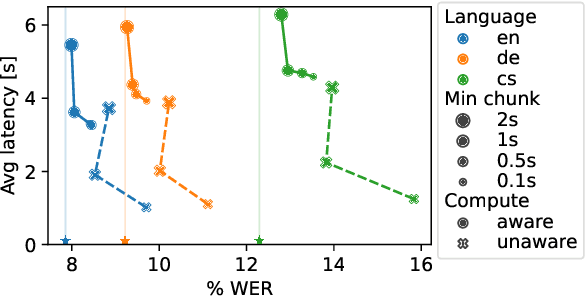
Whisper is one of the recent state-of-the-art multilingual speech recognition and translation models, however, it is not designed for real time transcription. In this paper, we build on top of Whisper and create Whisper-Streaming, an implementation of real-time speech transcription and translation of Whisper-like models. Whisper-Streaming uses local agreement policy with self-adaptive latency to enable streaming transcription. We show that Whisper-Streaming achieves high quality and 3.3 seconds latency on unsegmented long-form speech transcription test set, and we demonstrate its robustness and practical usability as a component in live transcription service at a multilingual conference.
Emotions Beyond Words: Non-Speech Audio Emotion Recognition With Edge Computing
May 01, 2023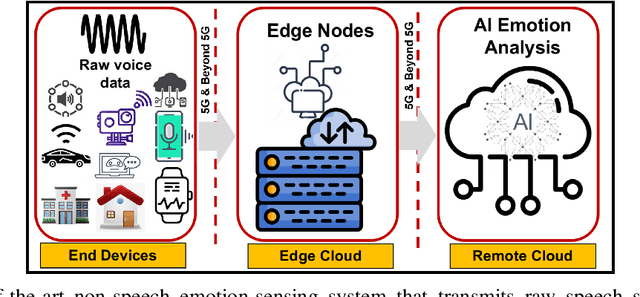

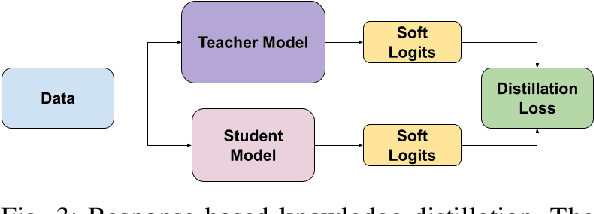
Non-speech emotion recognition has a wide range of applications including healthcare, crime control and rescue, and entertainment, to name a few. Providing these applications using edge computing has great potential, however, recent studies are focused on speech-emotion recognition using complex architectures. In this paper, a non-speech-based emotion recognition system is proposed, which can rely on edge computing to analyse emotions conveyed through non-speech expressions like screaming and crying. In particular, we explore knowledge distillation to design a computationally efficient system that can be deployed on edge devices with limited resources without degrading the performance significantly. We comprehensively evaluate our proposed framework using two publicly available datasets and highlight its effectiveness by comparing the results with the well-known MobileNet model. Our results demonstrate the feasibility and effectiveness of using edge computing for non-speech emotion detection, which can potentially improve applications that rely on emotion detection in communication networks. To the best of our knowledge, this is the first work on an edge-computing-based framework for detecting emotions in non-speech audio, offering promising directions for future research.
Let's Give a Voice to Conversational Agents in Virtual Reality
Aug 04, 2023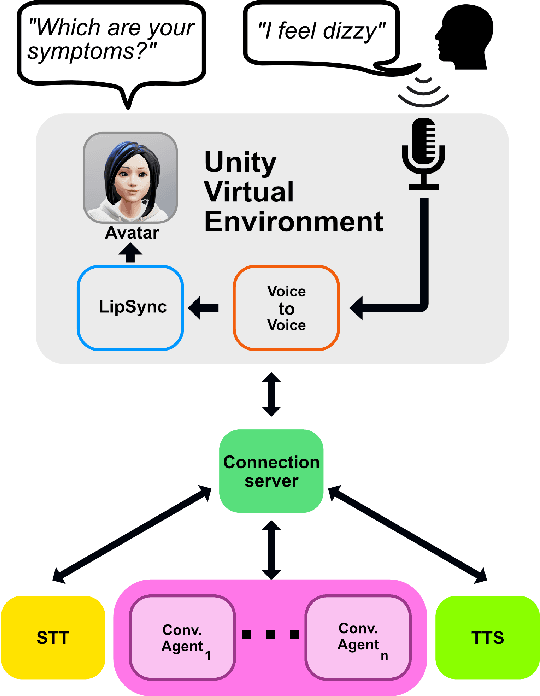

The dialogue experience with conversational agents can be greatly enhanced with multimodal and immersive interactions in virtual reality. In this work, we present an open-source architecture with the goal of simplifying the development of conversational agents operating in virtual environments. The architecture offers the possibility of plugging in conversational agents of different domains and adding custom or cloud-based Speech-To-Text and Text-To-Speech models to make the interaction voice-based. Using this architecture, we present two conversational prototypes operating in the digital health domain developed in Unity for both non-immersive displays and VR headsets.
Developing Social Robots with Empathetic Non-Verbal Cues Using Large Language Models
Aug 31, 2023We propose augmenting the empathetic capacities of social robots by integrating non-verbal cues. Our primary contribution is the design and labeling of four types of empathetic non-verbal cues, abbreviated as SAFE: Speech, Action (gesture), Facial expression, and Emotion, in a social robot. These cues are generated using a Large Language Model (LLM). We developed an LLM-based conversational system for the robot and assessed its alignment with social cues as defined by human counselors. Preliminary results show distinct patterns in the robot's responses, such as a preference for calm and positive social emotions like 'joy' and 'lively', and frequent nodding gestures. Despite these tendencies, our approach has led to the development of a social robot capable of context-aware and more authentic interactions. Our work lays the groundwork for future studies on human-robot interactions, emphasizing the essential role of both verbal and non-verbal cues in creating social and empathetic robots.
Rehearsal-Free Online Continual Learning for Automatic Speech Recognition
Jun 19, 2023
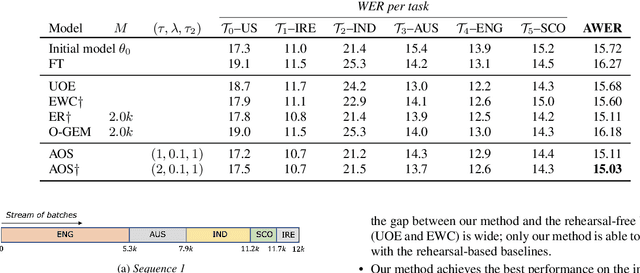
Fine-tuning an Automatic Speech Recognition (ASR) model to new domains results in degradation on original domains, referred to as Catastrophic Forgetting (CF). Continual Learning (CL) attempts to train ASR models without suffering from CF. While in ASR, offline CL is usually considered, online CL is a more realistic but also more challenging scenario where the model, unlike in offline CL, does not know when a task boundary occurs. Rehearsal-based methods, which store previously seen utterances in a memory, are often considered for online CL, in ASR and other research domains. However, recent research has shown that weight averaging is an effective method for offline CL in ASR. Based on this result, we propose, in this paper, a rehearsal-free method applicable for online CL. Our method outperforms all baselines, including rehearsal-based methods, in two experiments. Our method is a next step towards general CL for ASR, which should enable CL in all scenarios with few if any constraints.
CIF-PT: Bridging Speech and Text Representations for Spoken Language Understanding via Continuous Integrate-and-Fire Pre-Training
May 27, 2023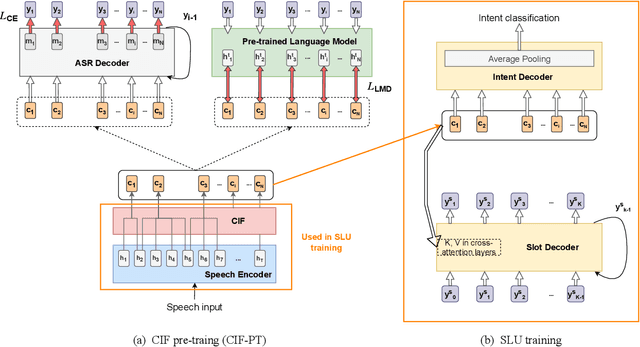
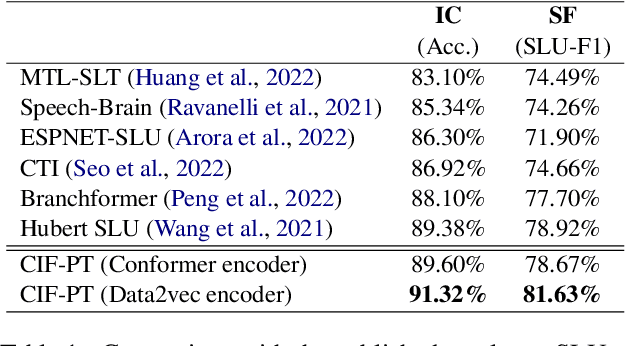
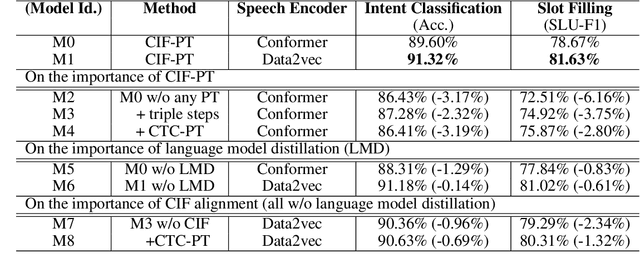
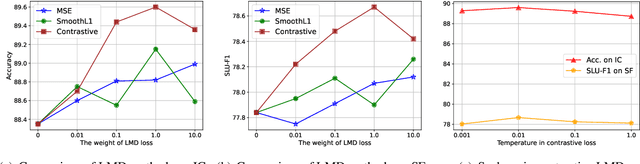
Speech or text representation generated by pre-trained models contains modal-specific information that could be combined for benefiting spoken language understanding (SLU) tasks. In this work, we propose a novel pre-training paradigm termed Continuous Integrate-and-Fire Pre-Training (CIF-PT). It relies on a simple but effective frame-to-token alignment: continuous integrate-and-fire (CIF) to bridge the representations between speech and text. It jointly performs speech-to-text training and language model distillation through CIF as the pre-training (PT). Evaluated on SLU benchmark SLURP dataset, CIF-PT outperforms the state-of-the-art model by 1.94% of accuracy and 2.71% of SLU-F1 on the tasks of intent classification and slot filling, respectively. We also observe the cross-modal representation extracted by CIF-PT obtains better performance than other neural interfaces for the tasks of SLU, including the dominant speech representation learned from self-supervised pre-training.
Improving Fairness and Robustness in End-to-End Speech Recognition through unsupervised clustering
Jun 06, 2023
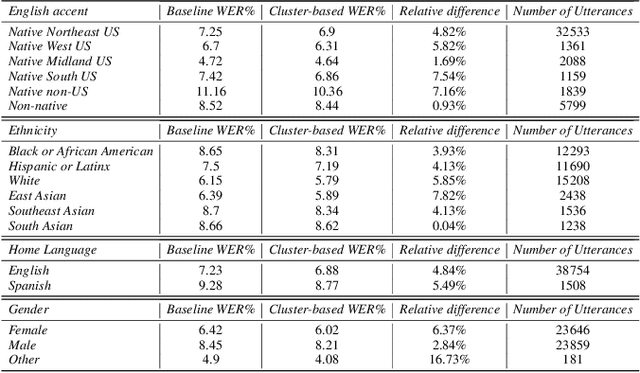
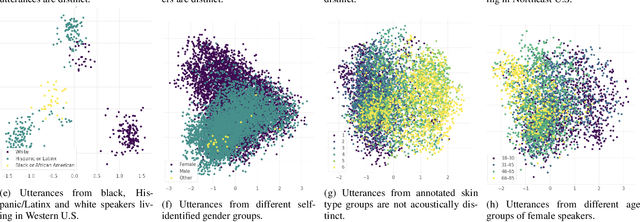
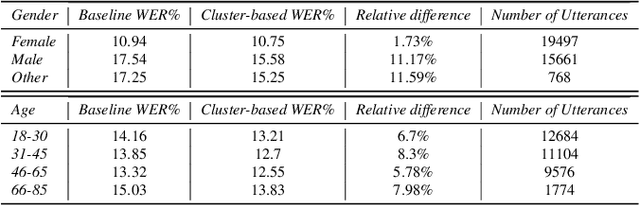
The challenge of fairness arises when Automatic Speech Recognition (ASR) systems do not perform equally well for all sub-groups of the population. In the past few years there have been many improvements in overall speech recognition quality, but without any particular focus on advancing Equality and Equity for all user groups for whom systems do not perform well. ASR fairness is therefore also a robustness issue. Meanwhile, data privacy also takes priority in production systems. In this paper, we present a privacy preserving approach to improve fairness and robustness of end-to-end ASR without using metadata, zip codes, or even speaker or utterance embeddings directly in training. We extract utterance level embeddings using a speaker ID model trained on a public dataset, which we then use in an unsupervised fashion to create acoustic clusters. We use cluster IDs instead of speaker utterance embeddings as extra features during model training, which shows improvements for all demographic groups and in particular for different accents.
Speech Intelligibility Classifiers from 550k Disordered Speech Samples
Mar 15, 2023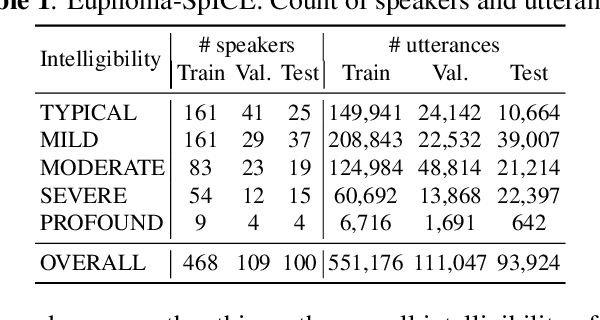
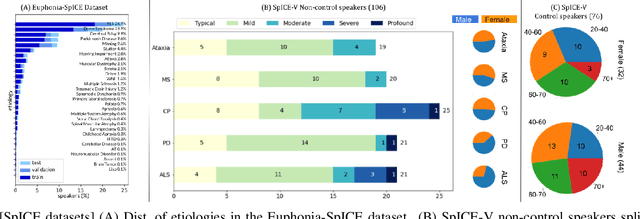
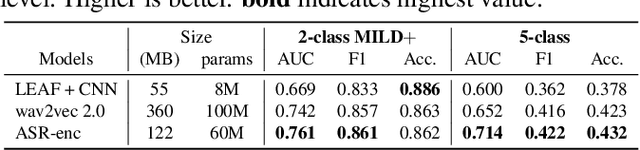
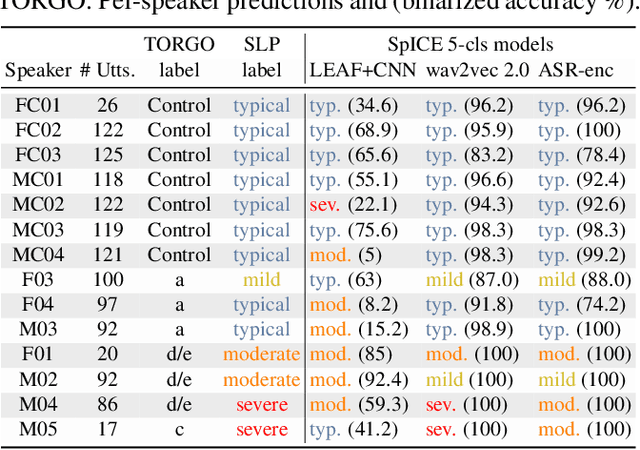
We developed dysarthric speech intelligibility classifiers on 551,176 disordered speech samples contributed by a diverse set of 468 speakers, with a range of self-reported speaking disorders and rated for their overall intelligibility on a five-point scale. We trained three models following different deep learning approaches and evaluated them on ~94K utterances from 100 speakers. We further found the models to generalize well (without further training) on the TORGO database (100% accuracy), UASpeech (0.93 correlation), ALS-TDI PMP (0.81 AUC) datasets as well as on a dataset of realistic unprompted speech we gathered (106 dysarthric and 76 control speakers,~2300 samples).