 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ICASSP 2023 Speech Signal Improvement Challenge
Apr 02, 2023
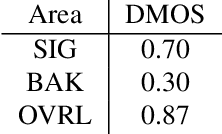
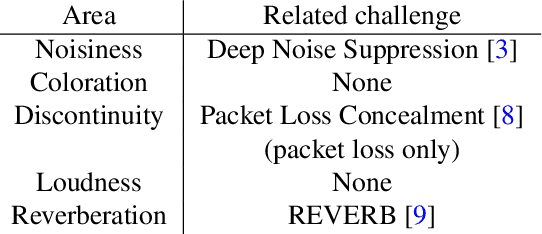

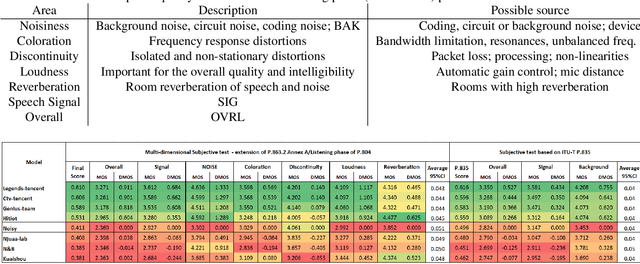
The ICASSP 2023 Speech Signal Improvement Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. The speech signal quality can be measured with SIG in ITU-T P.835 and is still a top issue in audio communication and conferencing systems. For example, in the ICASSP 2022 Deep Noise Suppression challenge, the improvement in the background and overall quality is impressive, but the improvement in the speech signal is statistically zero. To improve the speech signal the following speech impairment areas must be addressed: coloration, discontinuity, loudness, and reverberation. A dataset and test set were provided for the challenge, and the winners were determined using an extended crowdsourced implementation of ITU-T P.80's listening phase . The results show significant improvement was made across all measured dimensions of speech quality.
Interpretable Style Transfer for Text-to-Speech with ControlVAE and Diffusion Bridge
Jun 07, 2023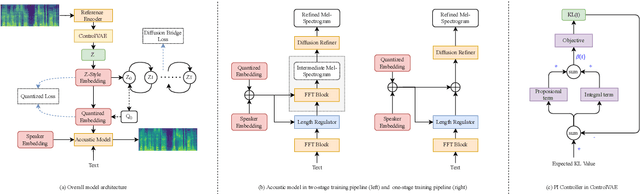
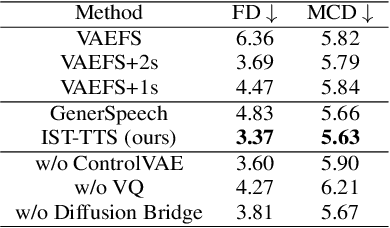
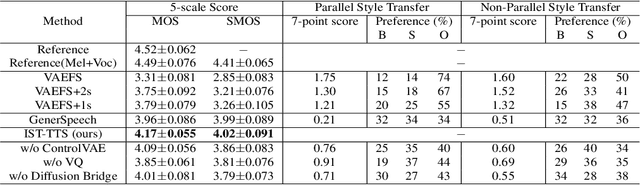
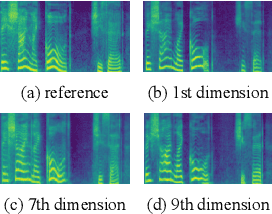
With the demand for autonomous control and personalized speech generation, the style control and transfer in Text-to-Speech (TTS) is becoming more and more important. In this paper, we propose a new TTS system that can perform style transfer with interpretability and high fidelity. Firstly, we design a TTS system that combines variational autoencoder (VAE) and diffusion refiner to get refined mel-spectrograms. Specifically, a two-stage and a one-stage system are designed respectively, to improve the audio quality and the performance of style transfer. Secondly, a diffusion bridge of quantized VAE is designed to efficiently learn complex discrete style representations and improve the performance of style transfer. To have a better ability of style transfer, we introduce ControlVAE to improve the reconstruction quality and have good interpretability simultaneously. Experiments on LibriTTS dataset demonstrate that our method is more effective than baseline models.
A Comparative Study of Pre-trained Speech and Audio Embeddings for Speech Emotion Recognition
Apr 22, 2023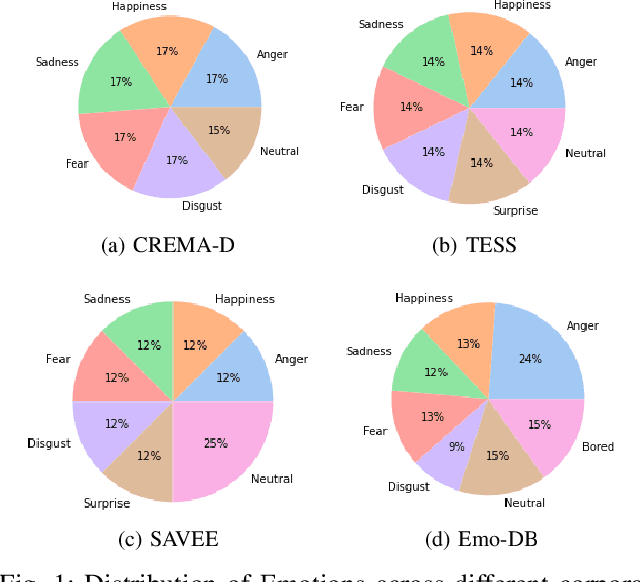
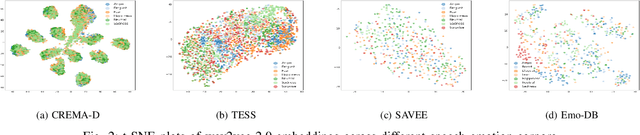

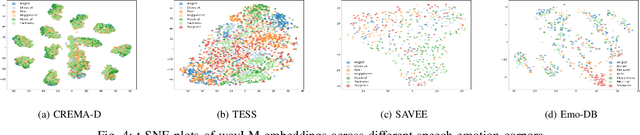
Pre-trained models (PTMs) have shown great promise in the speech and audio domain. Embeddings leveraged from these models serve as inputs for learning algorithms with applications in various downstream tasks. One such crucial task is Speech Emotion Recognition (SER) which has a wide range of applications, including dynamic analysis of customer calls, mental health assessment, and personalized language learning. PTM embeddings have helped advance SER, however, a comprehensive comparison of these PTM embeddings that consider multiple facets such as embedding model architecture, data used for pre-training, and the pre-training procedure being followed is missing. A thorough comparison of PTM embeddings will aid in the faster and more efficient development of models and enable their deployment in real-world scenarios. In this work, we exploit this research gap and perform a comparative analysis of embeddings extracted from eight speech and audio PTMs (wav2vec 2.0, data2vec, wavLM, UniSpeech-SAT, wav2clip, YAMNet, x-vector, ECAPA). We perform an extensive empirical analysis with four speech emotion datasets (CREMA-D, TESS, SAVEE, Emo-DB) by training three algorithms (XGBoost, Random Forest, FCN) on the derived embeddings. The results of our study indicate that the best performance is achieved by algorithms trained on embeddings derived from PTMs trained for speaker recognition followed by wav2clip and UniSpeech-SAT. This can relay that the top performance by embeddings from speaker recognition PTMs is most likely due to the model taking up information about numerous speech features such as tone, accent, pitch, and so on during its speaker recognition training. Insights from this work will assist future studies in their selection of embeddings for applications related to SER.
a unified front-end framework for english text-to-speech synthesis
May 18, 2023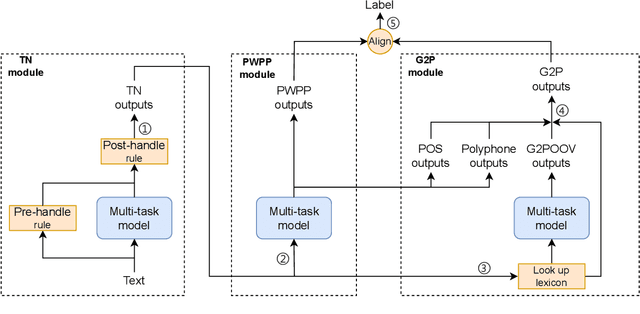

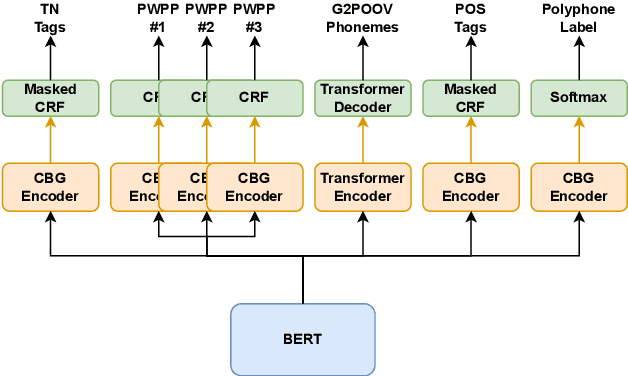
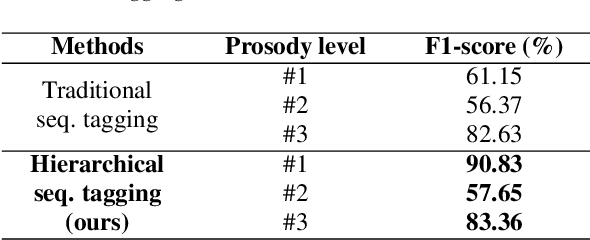
The front-end is a critical component of English text-to-speech (TTS) systems, responsible for extracting linguistic features that are essential for a text-to-speech model to synthesize speech, such as prosodies and phonemes. The English TTS front-end typically consists of a text normalization (TN) module, a prosody word prosody phrase (PWPP) module, and a grapheme-to-phoneme (G2P) module. However, current research on the English TTS front-end focuses solely on individual modules, neglecting the interdependence between them and resulting in sub-optimal performance for each module. Therefore, this paper proposes a unified front-end framework that captures the dependencies among the English TTS front-end modules. Extensive experiments have demonstrated that the proposed method achieves state-of-the-art (SOTA) performance in all modules.
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Aug 10, 2023
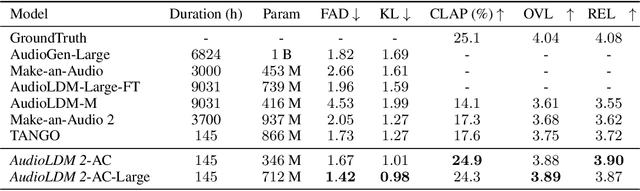

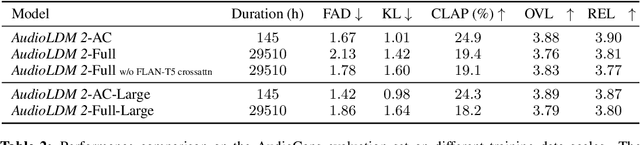
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate new state-of-the-art or competitive performance to previous approaches. Our demo and code are available at https://audioldm.github.io/audioldm2.
CALLS: Japanese Empathetic Dialogue Speech Corpus of Complaint Handling and Attentive Listening in Customer Center
May 23, 2023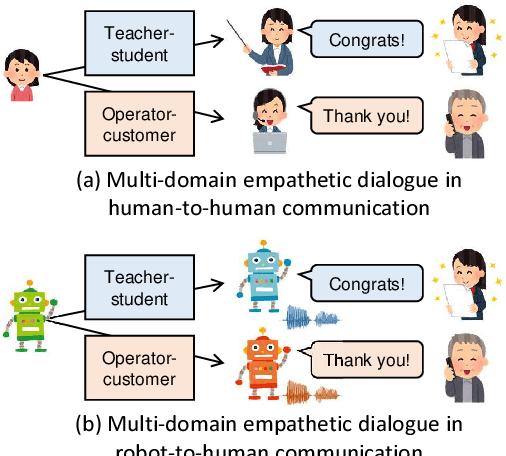
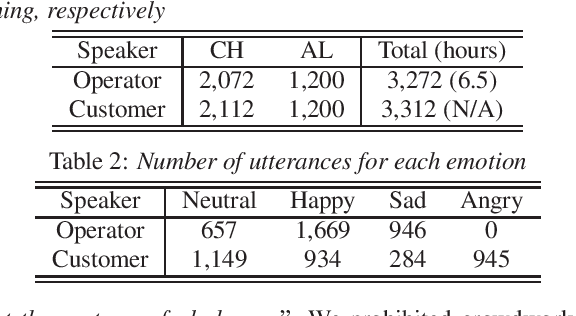
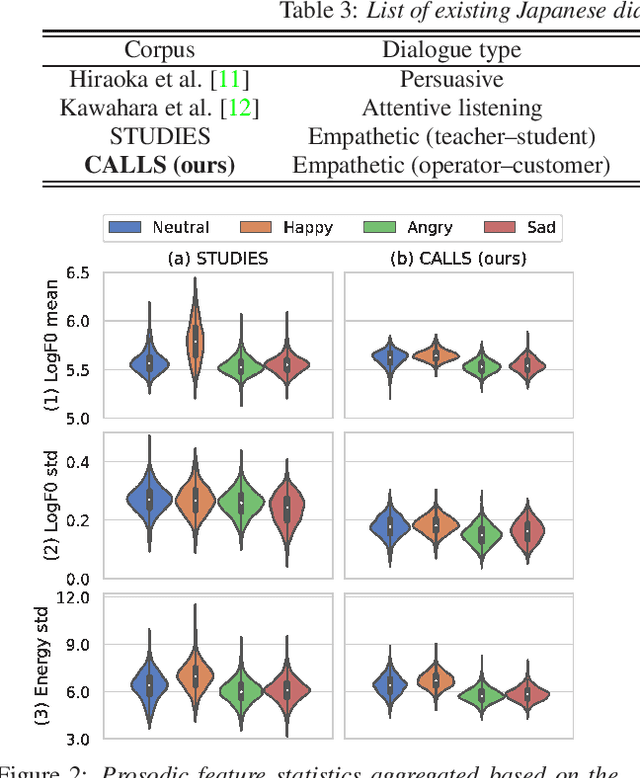
We present CALLS, a Japanese speech corpus that considers phone calls in a customer center as a new domain of empathetic spoken dialogue. The existing STUDIES corpus covers only empathetic dialogue between a teacher and student in a school. To extend the application range of empathetic dialogue speech synthesis (EDSS), we designed our corpus to include the same female speaker as the STUDIES teacher, acting as an operator in simulated phone calls. We describe a corpus construction methodology and analyze the recorded speech. We also conduct EDSS experiments using the CALLS and STUDIES corpora to investigate the effect of domain differences. The results show that mixing the two corpora during training causes biased improvements in the quality of synthetic speech due to the different degrees of expressiveness. Our project page of the corpus is http://sython.org/Corpus/STUDIES-2.
Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and Swahili
Jun 01, 2023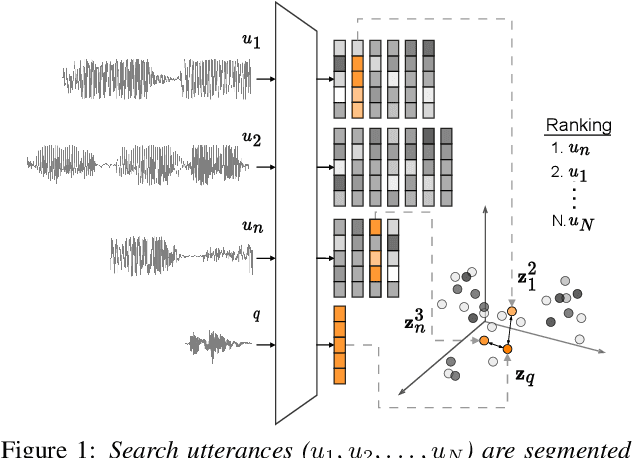
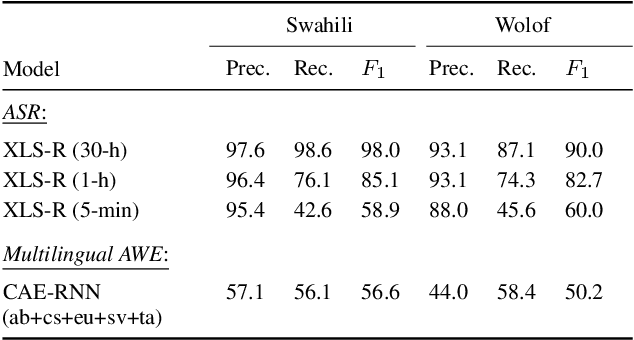
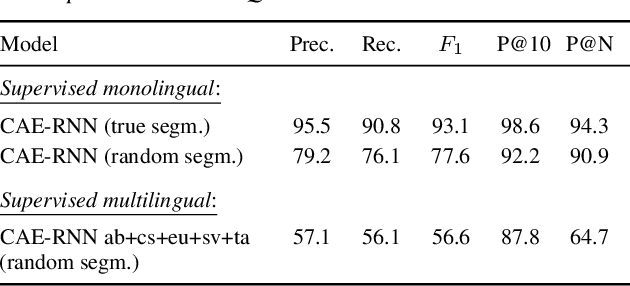
We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) models that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In contrast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar performance to an ASR system trained on 30 hours of labelled data.
RAMP: Retrieval-Augmented MOS Prediction via Confidence-based Dynamic Weighting
Aug 31, 2023
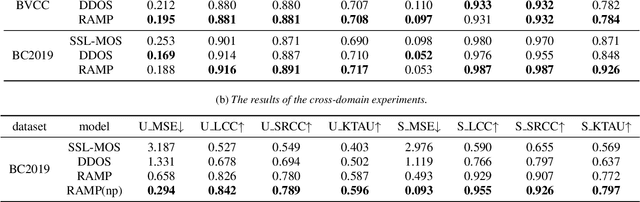
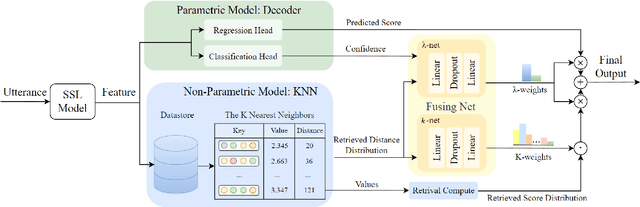

Automatic Mean Opinion Score (MOS) prediction is crucial to evaluate the perceptual quality of the synthetic speech. While recent approaches using pre-trained self-supervised learning (SSL) models have shown promising results, they only partly address the data scarcity issue for the feature extractor. This leaves the data scarcity issue for the decoder unresolved and leading to suboptimal performance. To address this challenge, we propose a retrieval-augmented MOS prediction method, dubbed {\bf RAMP}, to enhance the decoder's ability against the data scarcity issue. A fusing network is also proposed to dynamically adjust the retrieval scope for each instance and the fusion weights based on the predictive confidence. Experimental results show that our proposed method outperforms the existing methods in multiple scenarios.
* Accepted by Interspeech 2023, oral
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023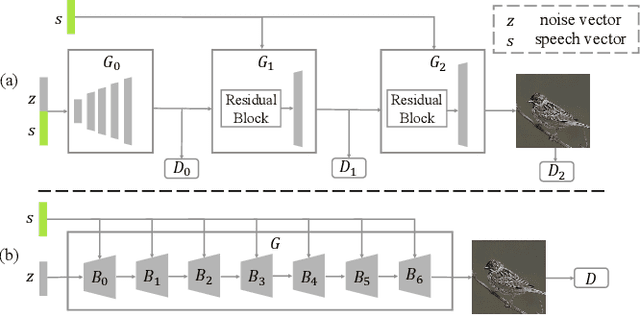
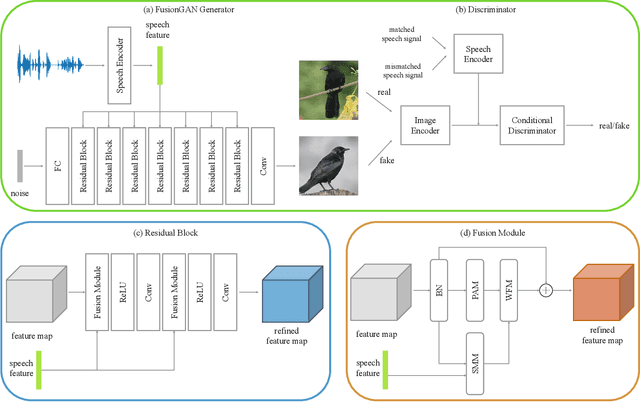
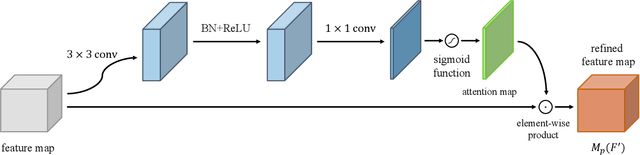
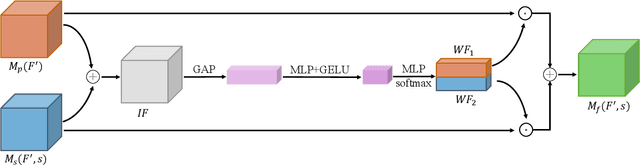
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.
Confidence-based Ensembles of End-to-End Speech Recognition Models
Jun 27, 2023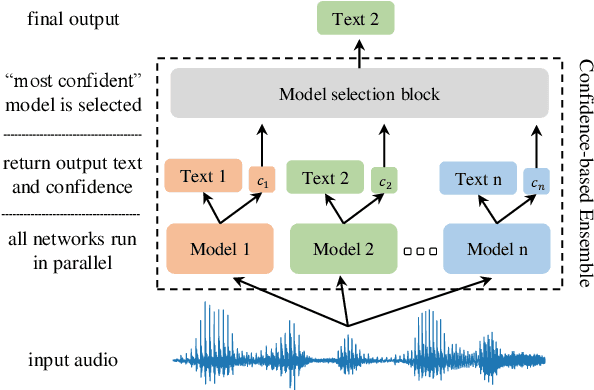

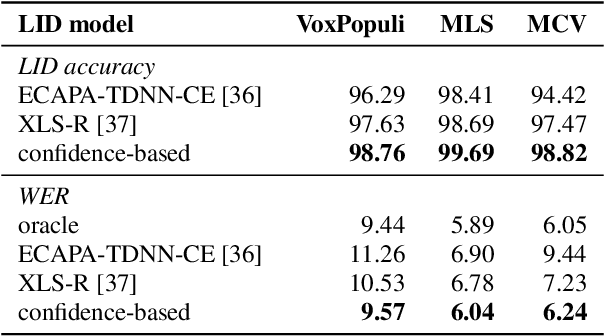
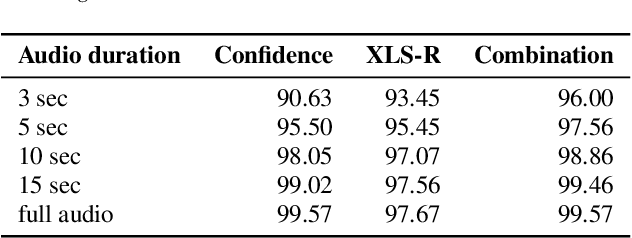
The number of end-to-end speech recognition models grows every year. These models are often adapted to new domains or languages resulting in a proliferation of expert systems that achieve great results on target data, while generally showing inferior performance outside of their domain of expertise. We explore combination of such experts via confidence-based ensembles: ensembles of models where only the output of the most-confident model is used. We assume that models' target data is not available except for a small validation set. We demonstrate effectiveness of our approach with two applications. First, we show that a confidence-based ensemble of 5 monolingual models outperforms a system where model selection is performed via a dedicated language identification block. Second, we demonstrate that it is possible to combine base and adapted models to achieve strong results on both original and target data. We validate all our results on multiple datasets and model architectures.