 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
EffCRN: An Efficient Convolutional Recurrent Network for High-Performance Speech Enhancement
Jun 05, 2023
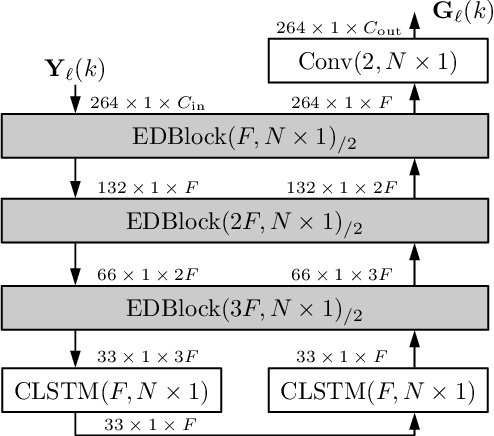
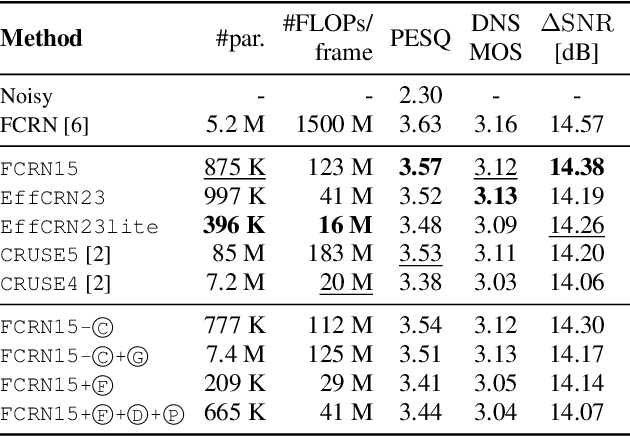
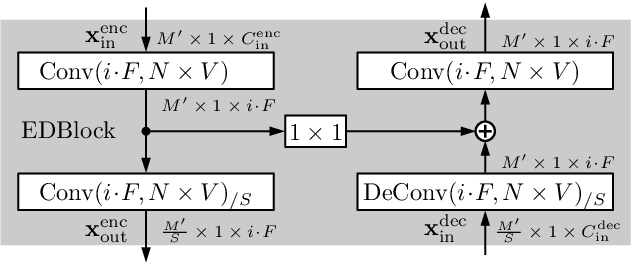
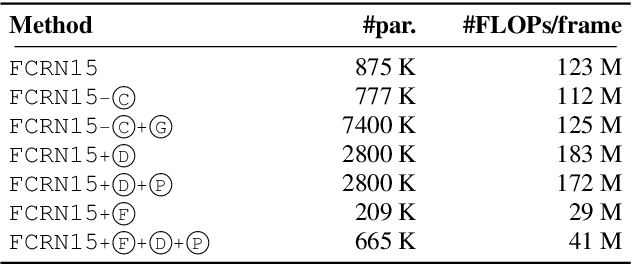
Fully convolutional recurrent neural networks (FCRNs) have shown state-of-the-art performance in single-channel speech enhancement. However, the number of parameters and the FLOPs/second of the original FCRN are restrictively high. A further important class of efficient networks is the CRUSE topology, serving as reference in our work. By applying a number of topological changes at once, we propose both an efficient FCRN (FCRN15), and a new family of efficient convolutional recurrent neural networks (EffCRN23, EffCRN23lite). We show that our FCRN15 (875K parameters) and EffCRN23lite (396K) outperform the already efficient CRUSE5 (85M) and CRUSE4 (7.2M) networks, respectively, w.r.t. PESQ, DNSMOS and DeltaSNR, while requiring about 94% less parameters and about 20% less #FLOPs/frame. Thereby, according to these metrics, the FCRN/EffCRN class of networks provides new best-in-class network topologies for speech enhancement.
Adversarial Training of Denoising Diffusion Model Using Dual Discriminators for High-Fidelity Multi-Speaker TTS
Aug 03, 2023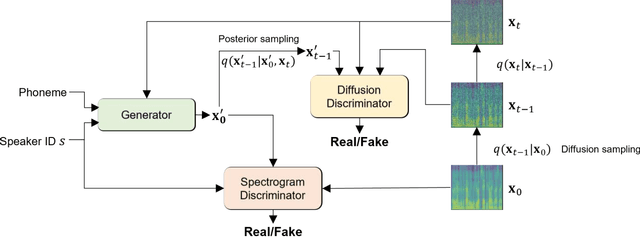
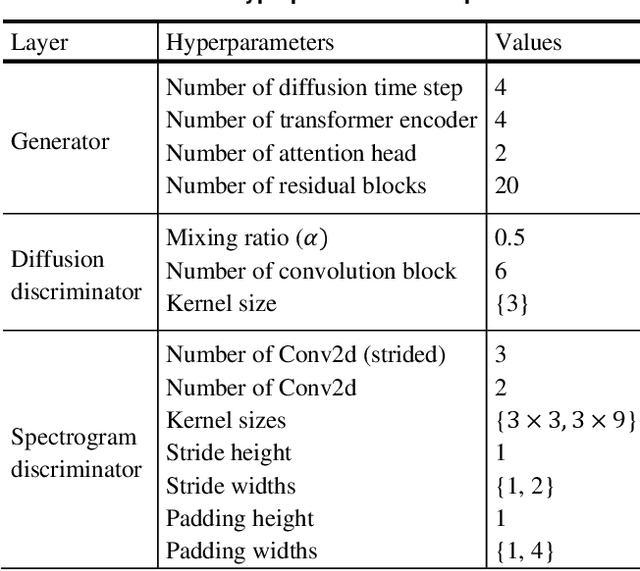
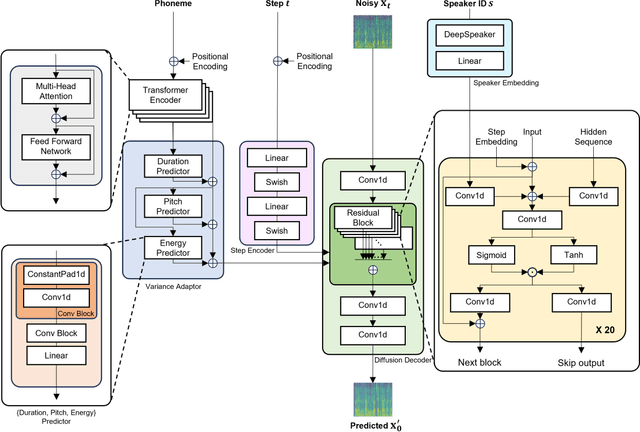
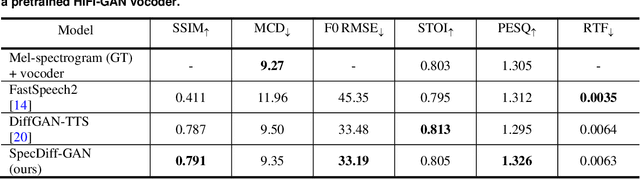
The diffusion model is capable of generating high-quality data through a probabilistic approach. However, it suffers from the drawback of slow generation speed due to the requirement of a large number of time steps. To address this limitation, recent models such as denoising diffusion implicit models (DDIM) focus on generating samples without directly modeling the probability distribution, while models like denoising diffusion generative adversarial networks (GAN) combine diffusion processes with GANs. In the field of speech synthesis, a recent diffusion speech synthesis model called DiffGAN-TTS, utilizing the structure of GANs, has been introduced and demonstrates superior performance in both speech quality and generation speed. In this paper, to further enhance the performance of DiffGAN-TTS, we propose a speech synthesis model with two discriminators: a diffusion discriminator for learning the distribution of the reverse process and a spectrogram discriminator for learning the distribution of the generated data. Objective metrics such as structural similarity index measure (SSIM), mel-cepstral distortion (MCD), F0 root mean squared error (F0 RMSE), short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), as well as subjective metrics like mean opinion score (MOS), are used to evaluate the performance of the proposed model. The evaluation results show that the proposed model outperforms recent state-of-the-art models such as FastSpeech2 and DiffGAN-TTS in various metrics. Our implementation and audio samples are located on GitHub.
On-Device Constrained Self-Supervised Speech Representation Learning for Keyword Spotting via Knowledge Distillation
Jul 06, 2023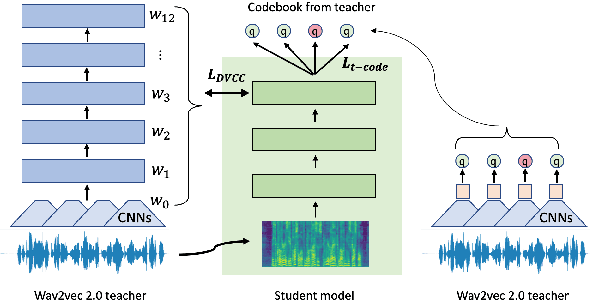
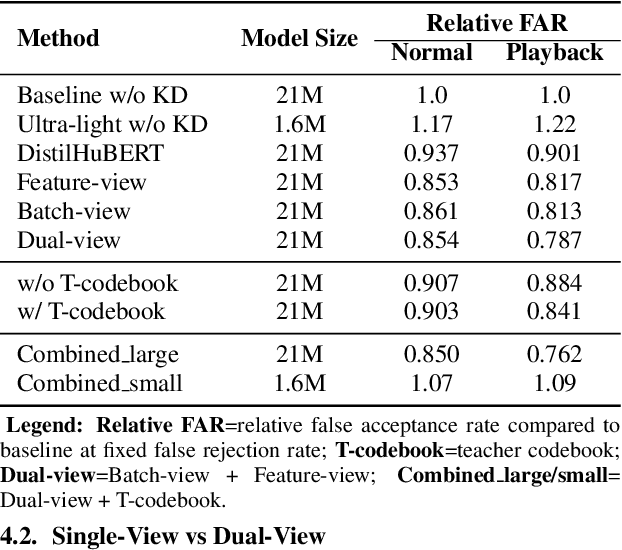
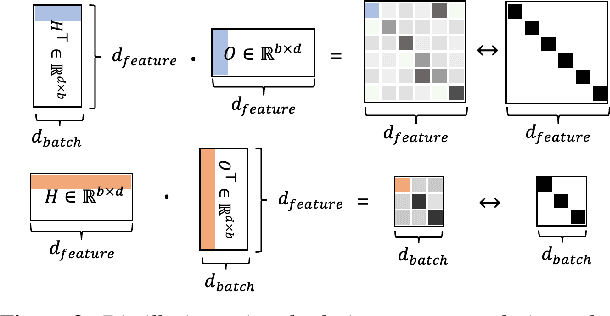
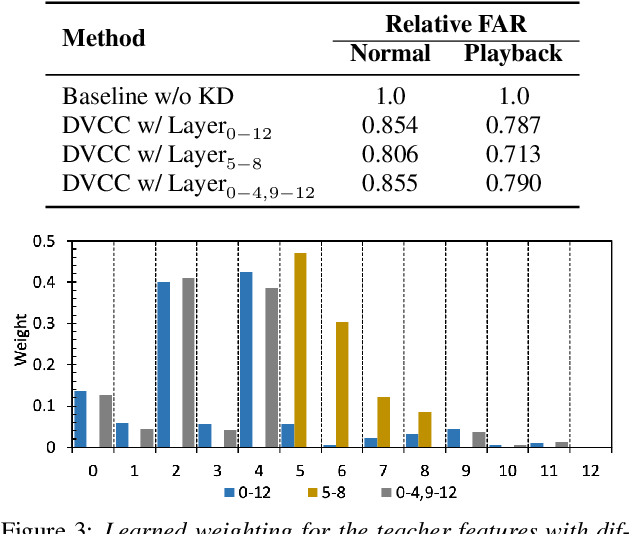
Large self-supervised models are effective feature extractors, but their application is challenging under on-device budget constraints and biased dataset collection, especially in keyword spotting. To address this, we proposed a knowledge distillation-based self-supervised speech representation learning (S3RL) architecture for on-device keyword spotting. Our approach used a teacher-student framework to transfer knowledge from a larger, more complex model to a smaller, light-weight model using dual-view cross-correlation distillation and the teacher's codebook as learning objectives. We evaluated our model's performance on an Alexa keyword spotting detection task using a 16.6k-hour in-house dataset. Our technique showed exceptional performance in normal and noisy conditions, demonstrating the efficacy of knowledge distillation methods in constructing self-supervised models for keyword spotting tasks while working within on-device resource constraints.
2-bit Conformer quantization for automatic speech recognition
May 26, 2023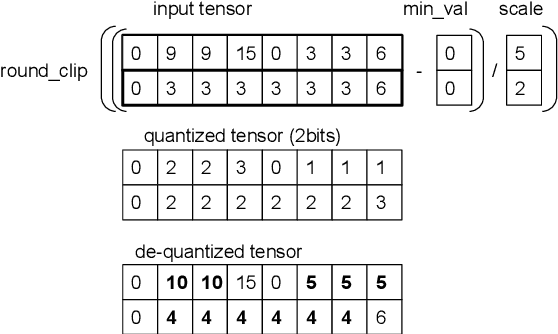
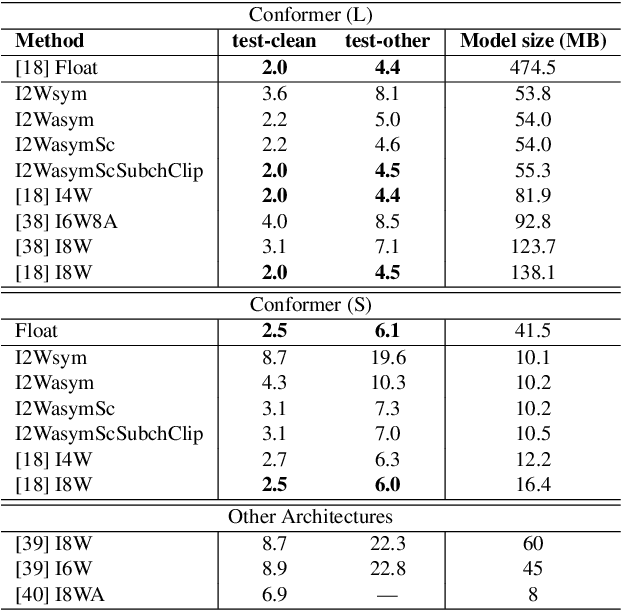
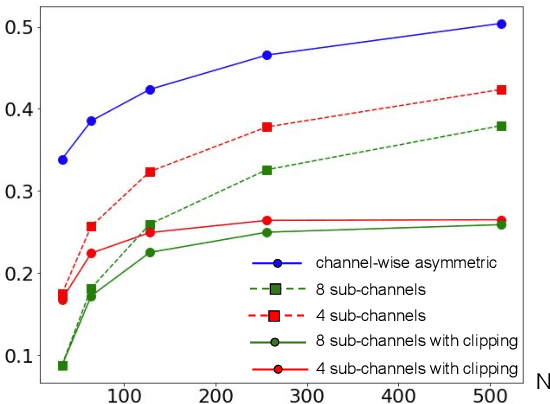

Large speech models are rapidly gaining traction in research community. As a result, model compression has become an important topic, so that these models can fit in memory and be served with reduced cost. Practical approaches for compressing automatic speech recognition (ASR) model use int8 or int4 weight quantization. In this study, we propose to develop 2-bit ASR models. We explore the impact of symmetric and asymmetric quantization combined with sub-channel quantization and clipping on both LibriSpeech dataset and large-scale training data. We obtain a lossless 2-bit Conformer model with 32% model size reduction when compared to state of the art 4-bit Conformer model for LibriSpeech. With the large-scale training data, we obtain a 2-bit Conformer model with over 40% model size reduction against the 4-bit version at the cost of 17% relative word error rate degradation
Classifying Dementia in the Presence of Depression: A Cross-Corpus Study
Aug 16, 2023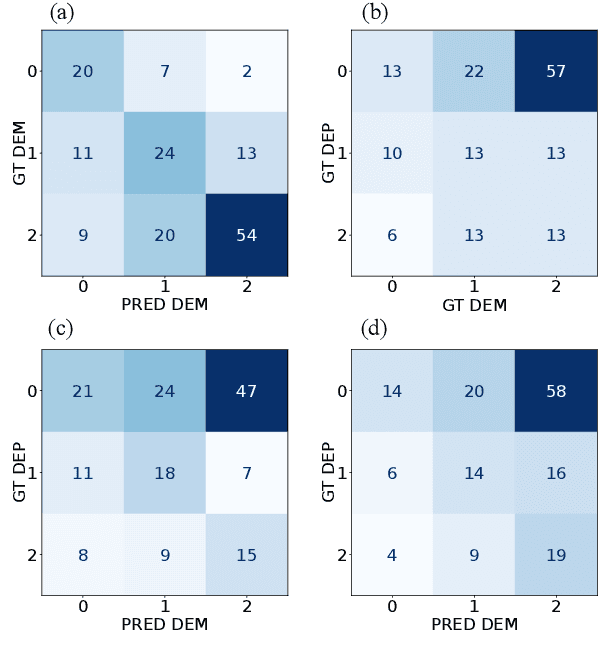
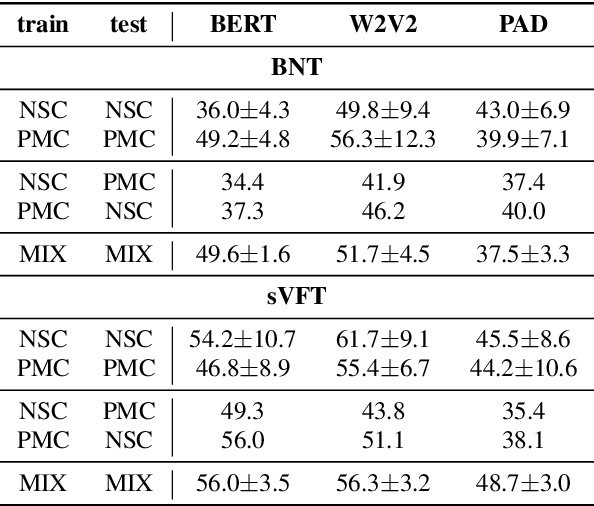
Automated dementia screening enables early detection and intervention, reducing costs to healthcare systems and increasing quality of life for those affected. Depression has shared symptoms with dementia, adding complexity to diagnoses. The research focus so far has been on binary classification of dementia (DEM) and healthy controls (HC) using speech from picture description tests from a single dataset. In this work, we apply established baseline systems to discriminate cognitive impairment in speech from the semantic Verbal Fluency Test and the Boston Naming Test using text, audio and emotion embeddings in a 3-class classification problem (HC vs. MCI vs. DEM). We perform cross-corpus and mixed-corpus experiments on two independently recorded German datasets to investigate generalization to larger populations and different recording conditions. In a detailed error analysis, we look at depression as a secondary diagnosis to understand what our classifiers actually learn.
Audio Diffusion Model for Speech Synthesis: A Survey on Text To Speech and Speech Enhancement in Generative AI
Mar 23, 2023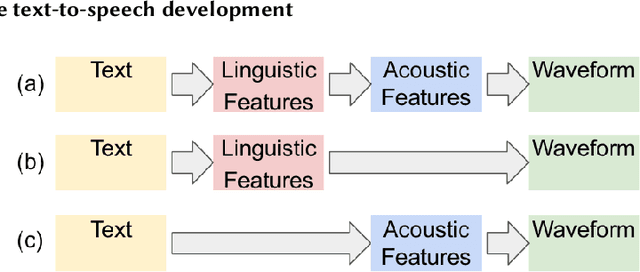
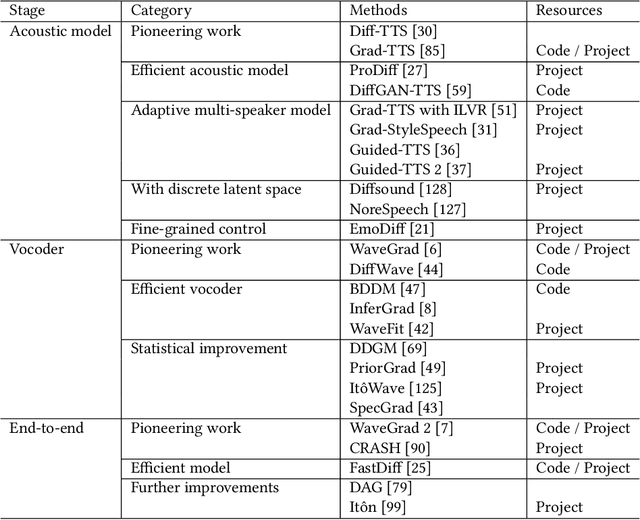
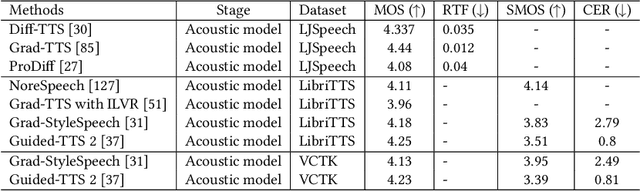

Generative AI has demonstrated impressive performance in various fields, among which speech synthesis is an interesting direction. With the diffusion model as the most popular generative model, numerous works have attempted two active tasks: text to speech and speech enhancement. This work conducts a survey on audio diffusion model, which is complementary to existing surveys that either lack the recent progress of diffusion-based speech synthesis or highlight an overall picture of applying diffusion model in multiple fields. Specifically, this work first briefly introduces the background of audio and diffusion model. As for the text-to-speech task, we divide the methods into three categories based on the stage where diffusion model is adopted: acoustic model, vocoder and end-to-end framework. Moreover, we categorize various speech enhancement tasks by either certain signals are removed or added into the input speech. Comparisons of experimental results and discussions are also covered in this survey.
RAMP: Retrieval-Augmented MOS Prediction via Confidence-based Dynamic Weighting
Aug 31, 2023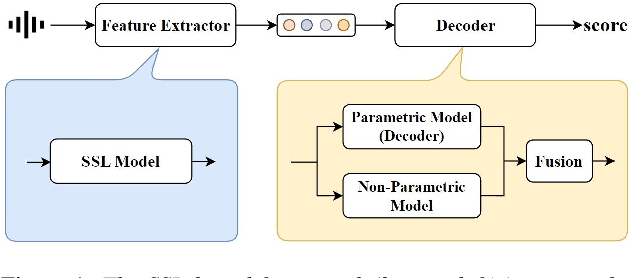
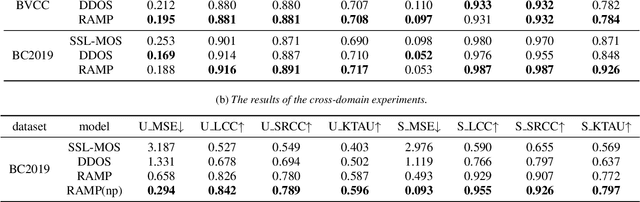
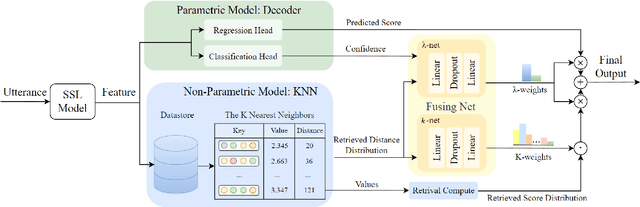

Automatic Mean Opinion Score (MOS) prediction is crucial to evaluate the perceptual quality of the synthetic speech. While recent approaches using pre-trained self-supervised learning (SSL) models have shown promising results, they only partly address the data scarcity issue for the feature extractor. This leaves the data scarcity issue for the decoder unresolved and leading to suboptimal performance. To address this challenge, we propose a retrieval-augmented MOS prediction method, dubbed {\bf RAMP}, to enhance the decoder's ability against the data scarcity issue. A fusing network is also proposed to dynamically adjust the retrieval scope for each instance and the fusion weights based on the predictive confidence. Experimental results show that our proposed method outperforms the existing methods in multiple scenarios.
* Accepted by Interspeech 2023, oral
A vector quantized masked autoencoder for audiovisual speech emotion recognition
May 05, 2023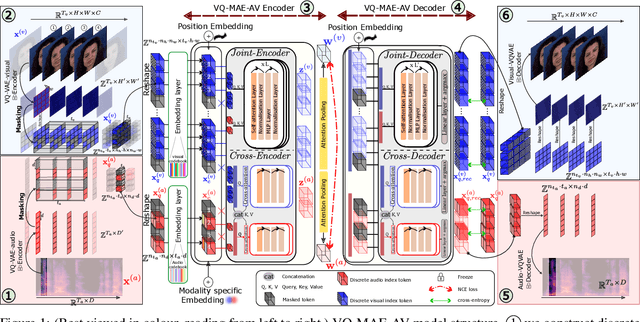
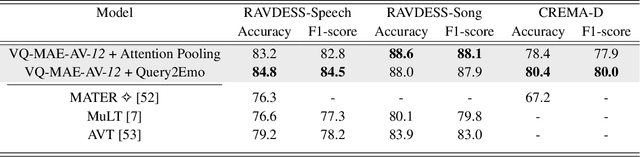
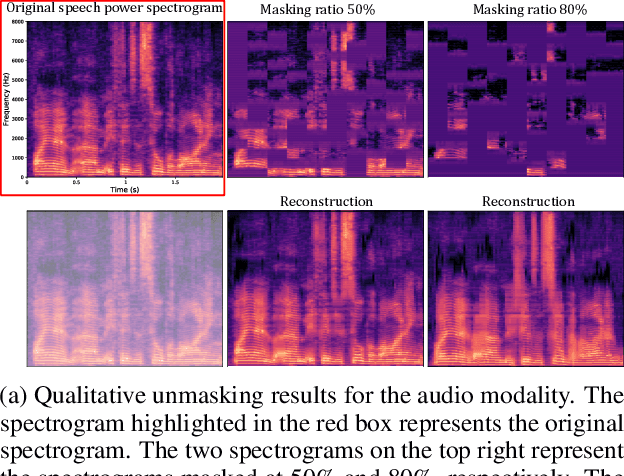
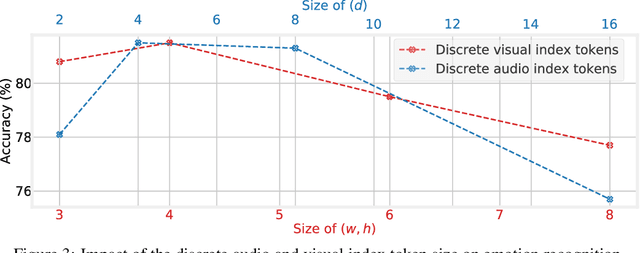
While fully-supervised models have been shown to be effective for audiovisual speech emotion recognition (SER), the limited availability of labeled data remains a major challenge in the field. To address this issue, self-supervised learning approaches, such as masked autoencoders (MAEs), have gained popularity as potential solutions. In this paper, we propose the VQ-MAE-AV model, a vector quantized MAE specifically designed for audiovisual speech self-supervised representation learning. Unlike existing multimodal MAEs that rely on the processing of the raw audiovisual speech data, the proposed method employs a self-supervised paradigm based on discrete audio and visual speech representations learned by two pre-trained vector quantized variational autoencoders. Experimental results show that the proposed approach, which is pre-trained on the VoxCeleb2 database and fine-tuned on standard emotional audiovisual speech datasets, outperforms the state-of-the-art audiovisual SER methods.
Diffusion-Based Mel-Spectrogram Enhancement for Personalized Speech Synthesis with Found Data
May 18, 2023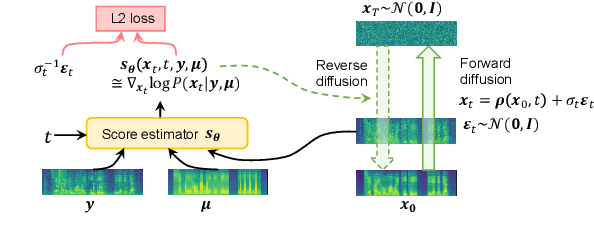
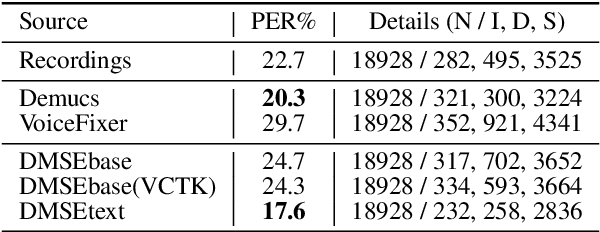
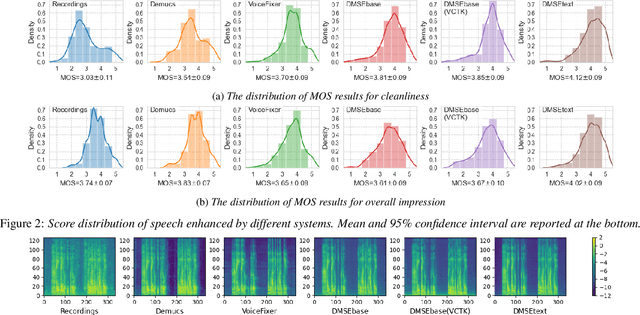
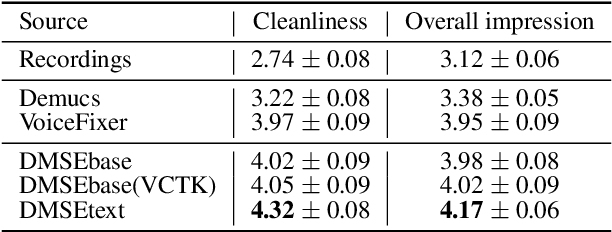
Creating synthetic voices with found data is challenging, as real-world recordings often contain various types of audio degradation. One way to address this problem is to pre-enhance the speech with an enhancement model and then use the enhanced data for text-to-speech (TTS) model training. Ideally, the enhancement model should be able to tackle multiple types of audio degradation simultaneously. This paper investigates the use of conditional diffusion models for generalized speech enhancement. The enhancement is performed on the log Mel-spectrogram domain to align with the TTS training objective. Text information is introduced as an additional condition to improve the model robustness. Experiments on real-world recordings demonstrate that the synthetic voice built on data enhanced by the proposed model produces higher-quality synthetic speech, compared to those trained on data enhanced by strong baselines. Audio samples are available at \url{https://dmse4tts.github.io/}.
Speech Separation based on Contrastive Learning and Deep Modularization
May 18, 2023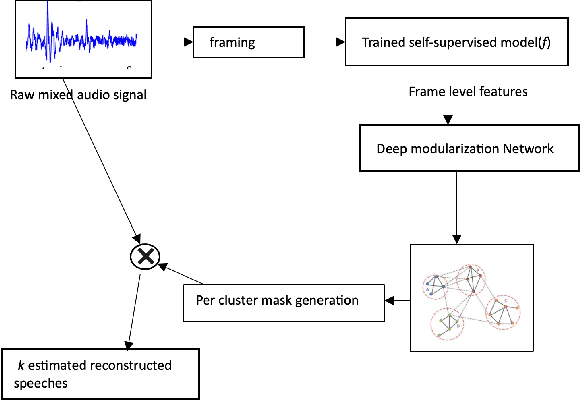
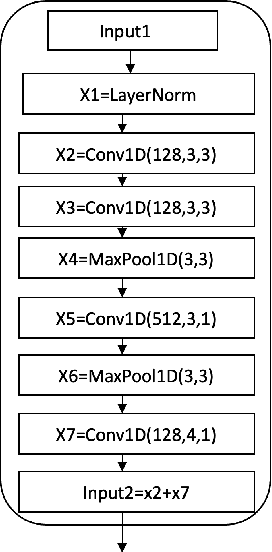
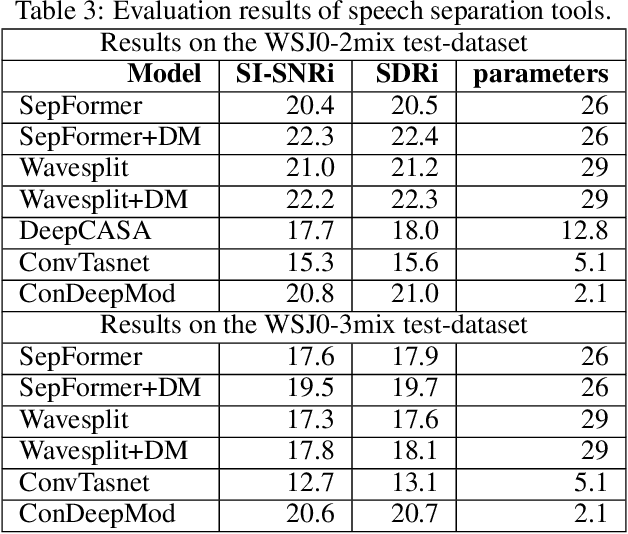
The current monaural state of the art tools for speech separation relies on supervised learning. This means that they must deal with permutation problem, they are impacted by the mismatch on the number of speakers used in training and inference. Moreover, their performance heavily relies on the presence of high-quality labelled data. These problems can be effectively addressed by employing a fully unsupervised technique for speech separation. In this paper, we use contrastive learning to establish the representations of frames then use the learned representations in the downstream deep modularization task. Concretely, we demonstrate experimentally that in speech separation, different frames of a speaker can be viewed as augmentations of a given hidden standard frame of that speaker. The frames of a speaker contain enough prosodic information overlap which is key in speech separation. Based on this, we implement a self-supervised learning to learn to minimize the distance between frames belonging to a given speaker. The learned representations are used in a downstream deep modularization task to cluster frames based on speaker identity. Evaluation of the developed technique on WSJ0-2mix and WSJ0-3mix shows that the technique attains SI-SNRi and SDRi of 20.8 and 21.0 respectively in WSJ0-2mix. In WSJ0-3mix, it attains SI-SNRi and SDRi of 20.7 and 20.7 respectively in WSJ0-2mix. Its greatest strength being that as the number of speakers increase, its performance does not degrade significantly.