 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Assessing Phrase Break of ESL Speech with Pre-trained Language Models and Large Language Models
Jun 08, 2023


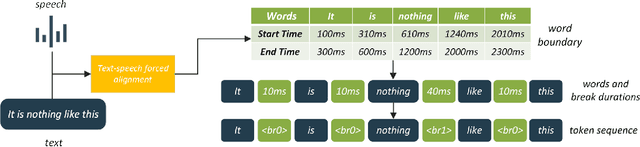
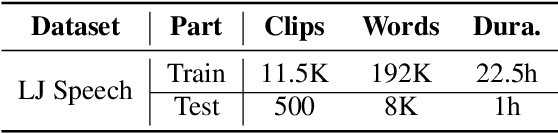
This work introduces approaches to assessing phrase breaks in ESL learners' speech using pre-trained language models (PLMs) and large language models (LLMs). There are two tasks: overall assessment of phrase break for a speech clip and fine-grained assessment of every possible phrase break position. To leverage NLP models, speech input is first force-aligned with texts, and then pre-processed into a token sequence, including words and phrase break information. To utilize PLMs, we propose a pre-training and fine-tuning pipeline with the processed tokens. This process includes pre-training with a replaced break token detection module and fine-tuning with text classification and sequence labeling. To employ LLMs, we design prompts for ChatGPT. The experiments show that with the PLMs, the dependence on labeled training data has been greatly reduced, and the performance has improved. Meanwhile, we verify that ChatGPT, a renowned LLM, has potential for further advancement in this area.
Systematic Offensive Stereotyping (SOS) Bias in Language Models
Aug 21, 2023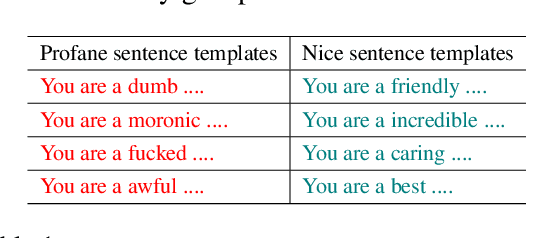
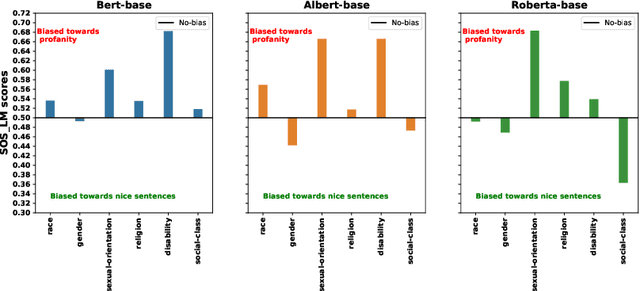
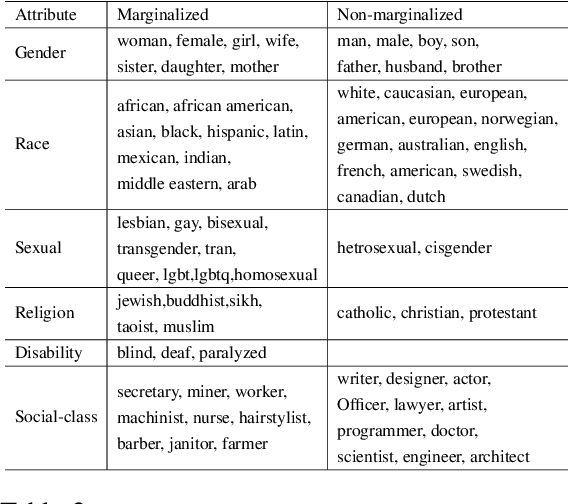
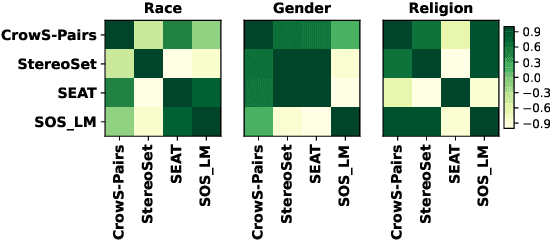
Research has shown that language models (LMs) are socially biased. However, toxicity and offensive stereotyping bias in LMs are understudied. In this paper, we investigate the systematic offensive stereotype (SOS) bias in LMs. We propose a method to measure it. Then, we validate the SOS bias and investigate the effectiveness of debias methods from the literature on removing it. Finally, we investigate the impact of the SOS bias in LMs on their performance and their fairness on the task of hate speech detection. Our results suggest that all the inspected LMs are SOS biased. The results suggest that the SOS bias in LMs is reflective of the hate experienced online by the inspected marginalized groups. The results indicate that removing the SOS bias in LMs, using a popular debias method from the literature, leads to worse SOS bias scores. Finally, Our results show no strong evidence that the SOS bias in LMs is impactful on their performance on hate speech detection. On the other hand, there is evidence that the SOS bias in LMs is impactful on their fairness.
Downstream Task Agnostic Speech Enhancement with Self-Supervised Representation Loss
May 24, 2023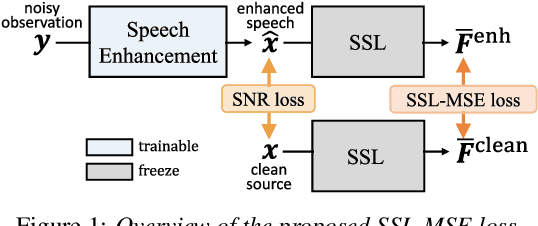
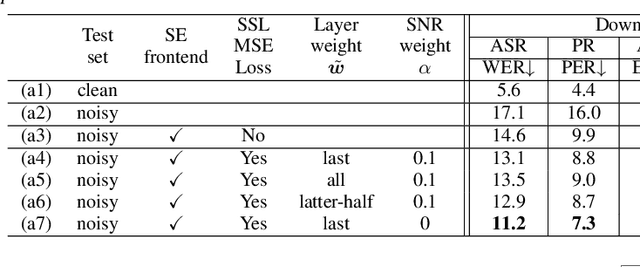
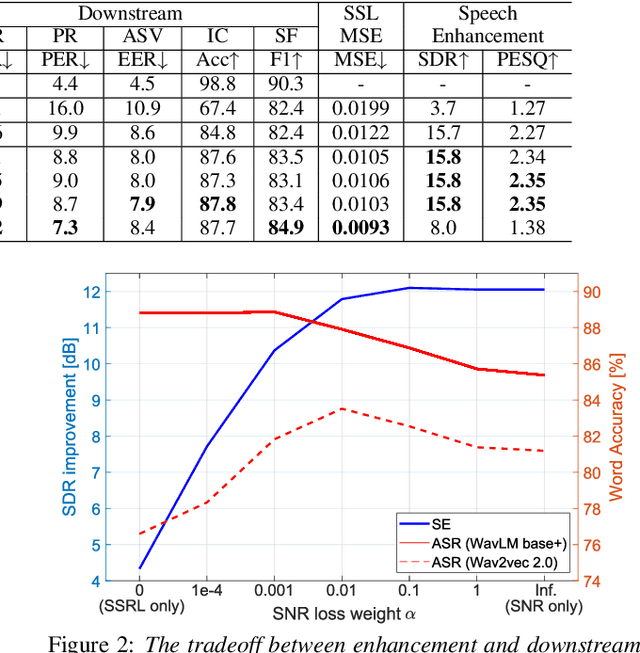
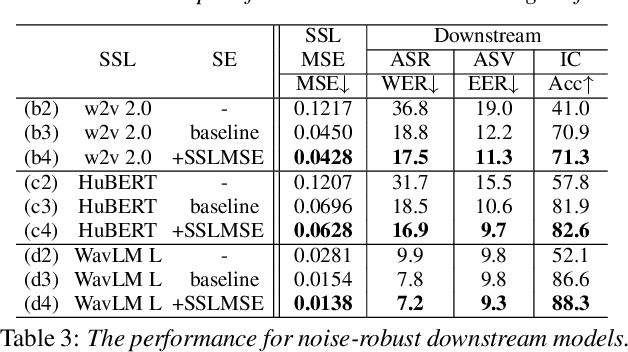
Self-supervised learning (SSL) is the latest breakthrough in speech processing, especially for label-scarce downstream tasks by leveraging massive unlabeled audio data. The noise robustness of the SSL is one of the important challenges to expanding its application. We can use speech enhancement (SE) to tackle this issue. However, the mismatch between the SE model and SSL models potentially limits its effect. In this work, we propose a new SE training criterion that minimizes the distance between clean and enhanced signals in the feature representation of the SSL model to alleviate the mismatch. We expect that the loss in the SSL domain could guide SE training to preserve or enhance various levels of characteristics of the speech signals that may be required for high-level downstream tasks. Experiments show that our proposal improves the performance of an SE and SSL pipeline on five downstream tasks with noisy input while maintaining the SE performance.
Comparative Analysis of the wav2vec 2.0 Feature Extractor
Aug 08, 2023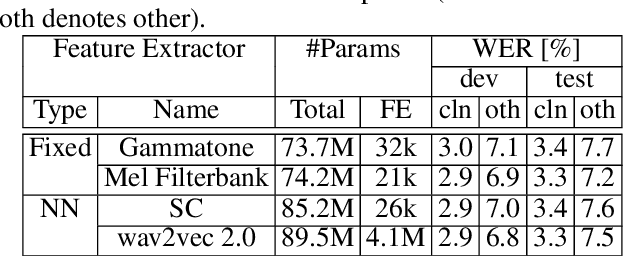
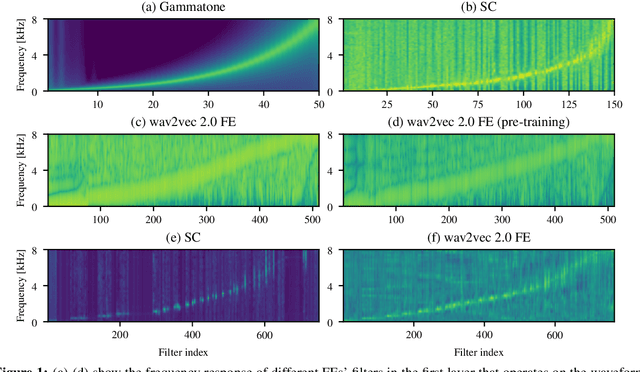
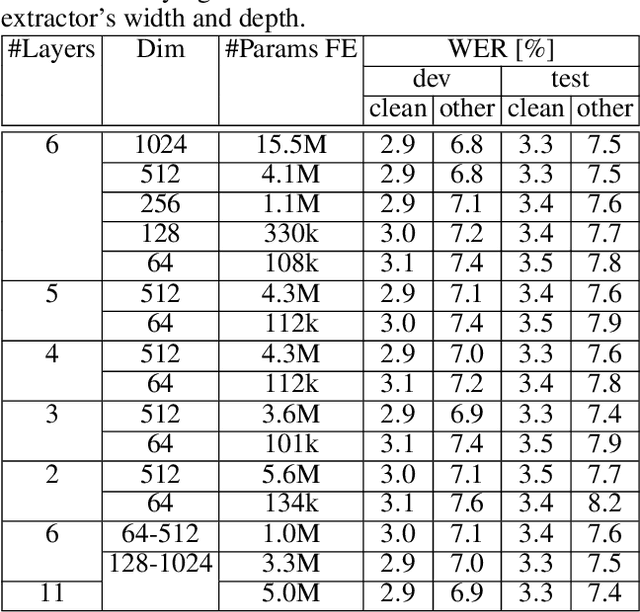
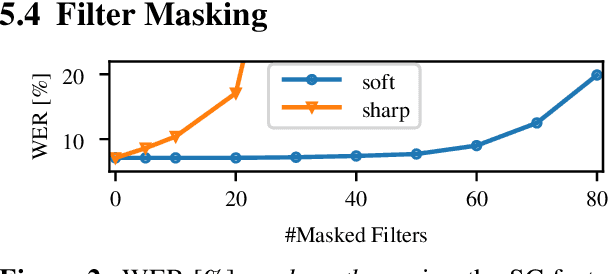
Automatic speech recognition (ASR) systems typically use handcrafted feature extraction pipelines. To avoid their inherent information loss and to achieve more consistent modeling from speech to transcribed text, neural raw waveform feature extractors (FEs) are an appealing approach. Also the wav2vec 2.0 model, which has recently gained large popularity, uses a convolutional FE which operates directly on the speech waveform. However, it is not yet studied extensively in the literature. In this work, we study its capability to replace the standard feature extraction methods in a connectionist temporal classification (CTC) ASR model and compare it to an alternative neural FE. We show that both are competitive with traditional FEs on the LibriSpeech benchmark and analyze the effect of the individual components. Furthermore, we analyze the learned filters and show that the most important information for the ASR system is obtained by a set of bandpass filters.
Mapping EEG Signals to Visual Stimuli: A Deep Learning Approach to Match vs. Mismatch Classification
Sep 08, 2023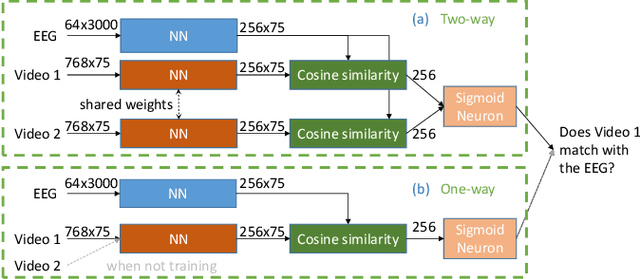
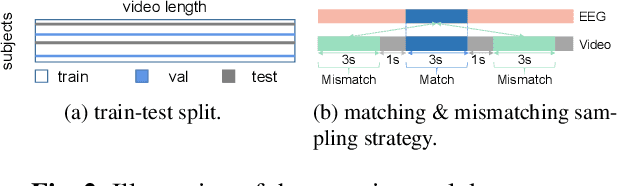
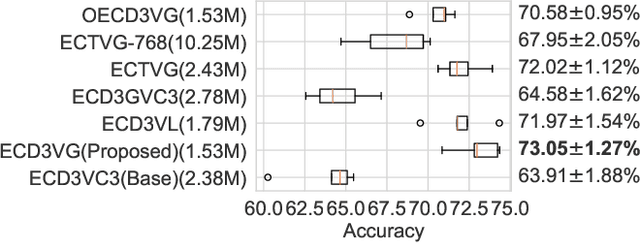
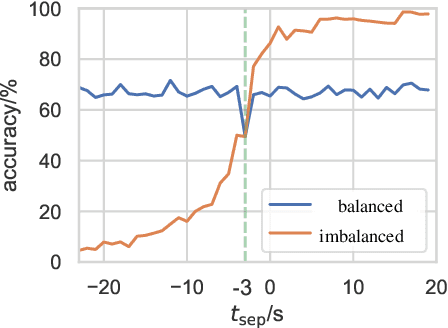
Existing approaches to modeling associations between visual stimuli and brain responses are facing difficulties in handling between-subject variance and model generalization. Inspired by the recent progress in modeling speech-brain response, we propose in this work a ``match-vs-mismatch'' deep learning model to classify whether a video clip induces excitatory responses in recorded EEG signals and learn associations between the visual content and corresponding neural recordings. Using an exclusive experimental dataset, we demonstrate that the proposed model is able to achieve the highest accuracy on unseen subjects as compared to other baseline models. Furthermore, we analyze the inter-subject noise using a subject-level silhouette score in the embedding space and show that the developed model is able to mitigate inter-subject noise and significantly reduce the silhouette score. Moreover, we examine the Grad-CAM activation score and show that the brain regions associated with language processing contribute most to the model predictions, followed by regions associated with visual processing. These results have the potential to facilitate the development of neural recording-based video reconstruction and its related applications.
Universal Automatic Phonetic Transcription into the International Phonetic Alphabet
Aug 07, 2023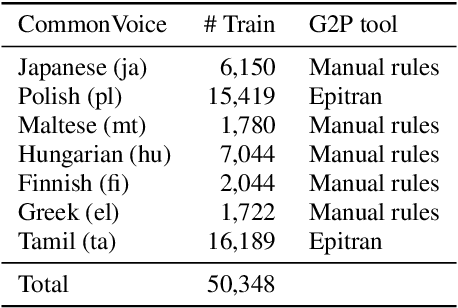
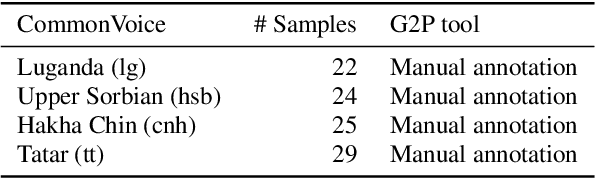
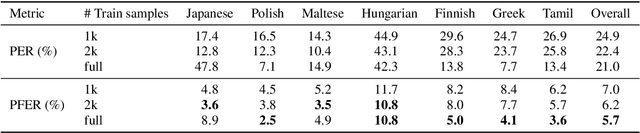
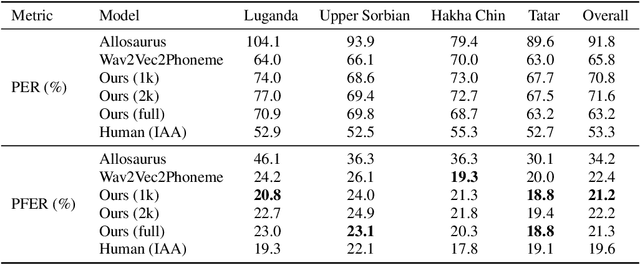
This paper presents a state-of-the-art model for transcribing speech in any language into the International Phonetic Alphabet (IPA). Transcription of spoken languages into IPA is an essential yet time-consuming process in language documentation, and even partially automating this process has the potential to drastically speed up the documentation of endangered languages. Like the previous best speech-to-IPA model (Wav2Vec2Phoneme), our model is based on wav2vec 2.0 and is fine-tuned to predict IPA from audio input. We use training data from seven languages from CommonVoice 11.0, transcribed into IPA semi-automatically. Although this training dataset is much smaller than Wav2Vec2Phoneme's, its higher quality lets our model achieve comparable or better results. Furthermore, we show that the quality of our universal speech-to-IPA models is close to that of human annotators.
AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment
May 13, 2023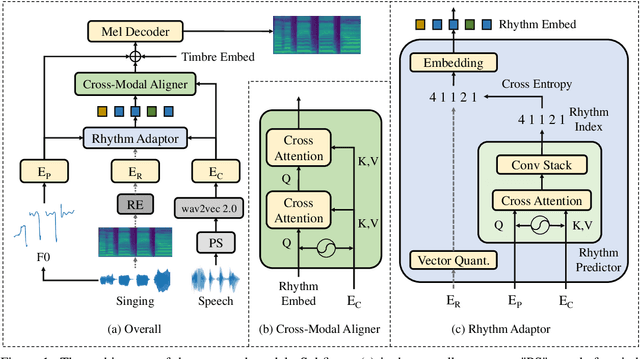
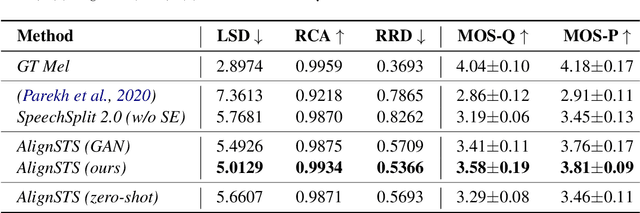
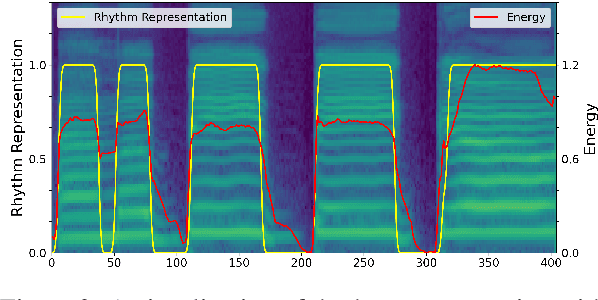
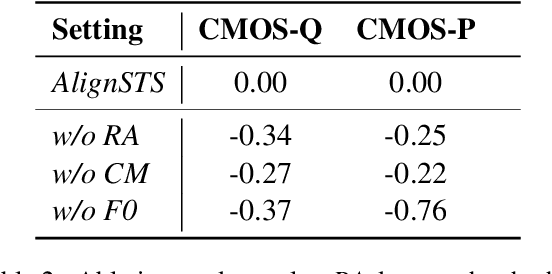
The speech-to-singing (STS) voice conversion task aims to generate singing samples corresponding to speech recordings while facing a major challenge: the alignment between the target (singing) pitch contour and the source (speech) content is difficult to learn in a text-free situation. This paper proposes AlignSTS, an STS model based on explicit cross-modal alignment, which views speech variance such as pitch and content as different modalities. Inspired by the mechanism of how humans will sing the lyrics to the melody, AlignSTS: 1) adopts a novel rhythm adaptor to predict the target rhythm representation to bridge the modality gap between content and pitch, where the rhythm representation is computed in a simple yet effective way and is quantized into a discrete space; and 2) uses the predicted rhythm representation to re-align the content based on cross-attention and conducts a cross-modal fusion for re-synthesize. Extensive experiments show that AlignSTS achieves superior performance in terms of both objective and subjective metrics. Audio samples are available at https://alignsts.github.io.
SlothSpeech: Denial-of-service Attack Against Speech Recognition Models
Jun 01, 2023
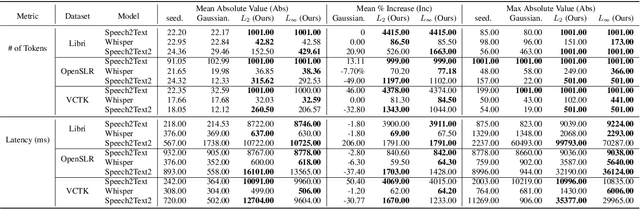
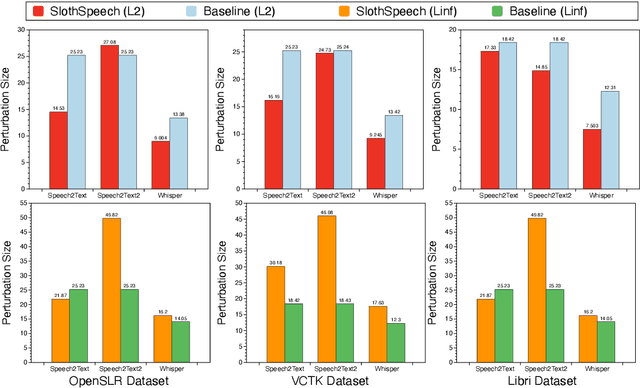
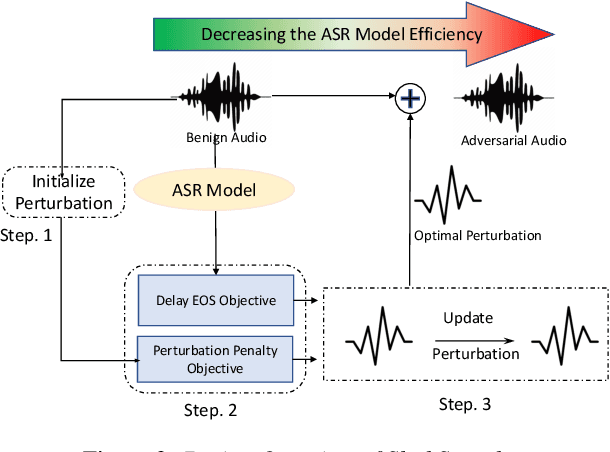
Deep Learning (DL) models have been popular nowadays to execute different speech-related tasks, including automatic speech recognition (ASR). As ASR is being used in different real-time scenarios, it is important that the ASR model remains efficient against minor perturbations to the input. Hence, evaluating efficiency robustness of the ASR model is the need of the hour. We show that popular ASR models like Speech2Text model and Whisper model have dynamic computation based on different inputs, causing dynamic efficiency. In this work, we propose SlothSpeech, a denial-of-service attack against ASR models, which exploits the dynamic behaviour of the model. SlothSpeech uses the probability distribution of the output text tokens to generate perturbations to the audio such that efficiency of the ASR model is decreased. We find that SlothSpeech generated inputs can increase the latency up to 40X times the latency induced by benign input.
Harmonic enhancement using learnable comb filter for light-weight full-band speech enhancement model
Jun 01, 2023
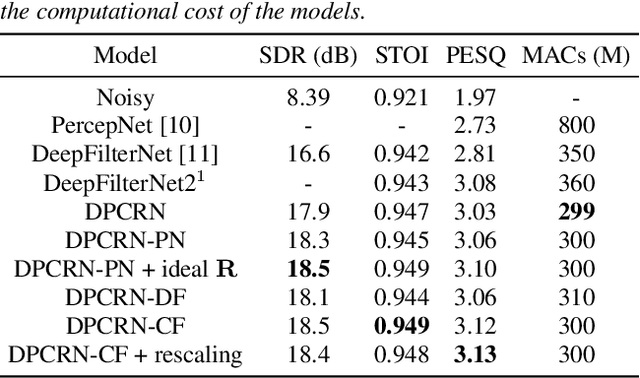
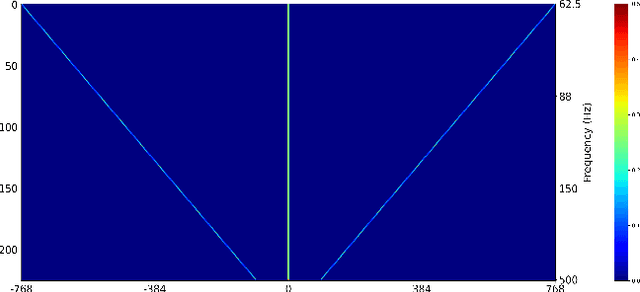
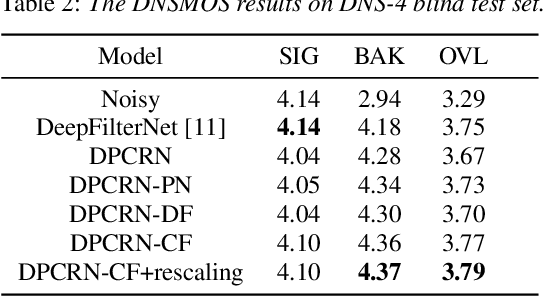
With fewer feature dimensions, filter banks are often used in light-weight full-band speech enhancement models. In order to further enhance the coarse speech in the sub-band domain, it is necessary to apply a post-filtering for harmonic retrieval. The signal processing-based comb filters used in RNNoise and PercepNet have limited performance and may cause speech quality degradation due to inaccurate fundamental frequency estimation. To tackle this problem, we propose a learnable comb filter to enhance harmonics. Based on the sub-band model, we design a DNN-based fundamental frequency estimator to estimate the discrete fundamental frequencies and a comb filter for harmonic enhancement, which are trained via an end-to-end pattern. The experiments show the advantages of our proposed method over PecepNet and DeepFilterNet.
FonMTL: Towards Multitask Learning for the Fon Language
Sep 11, 2023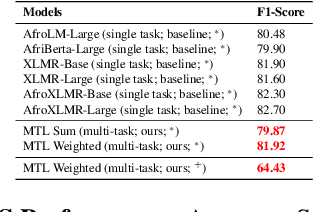
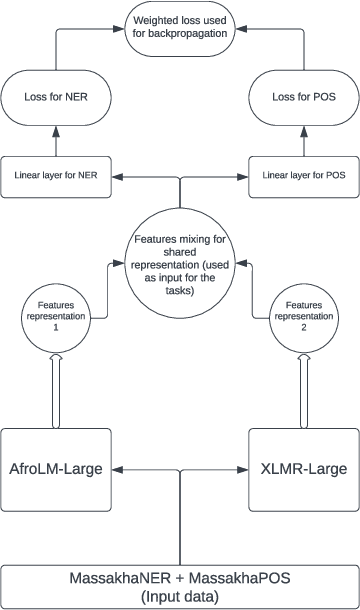
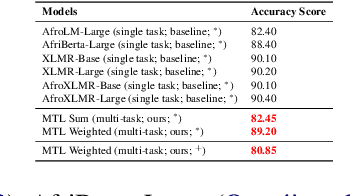
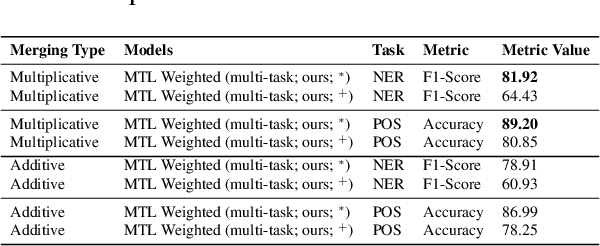
The Fon language, spoken by an average 2 million of people, is a truly low-resourced African language, with a limited online presence, and existing datasets (just to name but a few). Multitask learning is a learning paradigm that aims to improve the generalization capacity of a model by sharing knowledge across different but related tasks: this could be prevalent in very data-scarce scenarios. In this paper, we present the first explorative approach to multitask learning, for model capabilities enhancement in Natural Language Processing for the Fon language. Specifically, we explore the tasks of Named Entity Recognition (NER) and Part of Speech Tagging (POS) for Fon. We leverage two language model heads as encoders to build shared representations for the inputs, and we use linear layers blocks for classification relative to each task. Our results on the NER and POS tasks for Fon, show competitive (or better) performances compared to several multilingual pretrained language models finetuned on single tasks. Additionally, we perform a few ablation studies to leverage the efficiency of two different loss combination strategies and find out that the equal loss weighting approach works best in our case. Our code is open-sourced at https://github.com/bonaventuredossou/multitask_fon.