 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
QPGesture: Quantization-Based and Phase-Guided Motion Matching for Natural Speech-Driven Gesture Generation
May 18, 2023

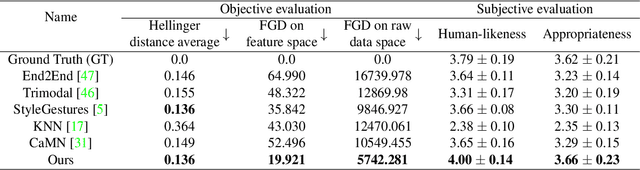
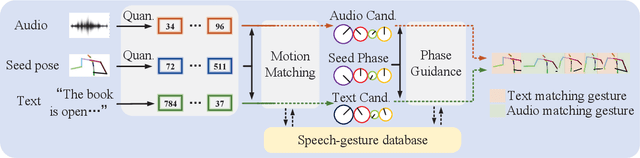
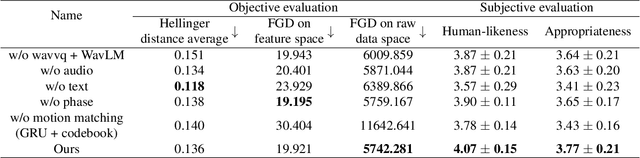
Speech-driven gesture generation is highly challenging due to the random jitters of human motion. In addition, there is an inherent asynchronous relationship between human speech and gestures. To tackle these challenges, we introduce a novel quantization-based and phase-guided motion-matching framework. Specifically, we first present a gesture VQ-VAE module to learn a codebook to summarize meaningful gesture units. With each code representing a unique gesture, random jittering problems are alleviated effectively. We then use Levenshtein distance to align diverse gestures with different speech. Levenshtein distance based on audio quantization as a similarity metric of corresponding speech of gestures helps match more appropriate gestures with speech, and solves the alignment problem of speech and gestures well. Moreover, we introduce phase to guide the optimal gesture matching based on the semantics of context or rhythm of audio. Phase guides when text-based or speech-based gestures should be performed to make the generated gestures more natural. Extensive experiments show that our method outperforms recent approaches on speech-driven gesture generation. Our code, database, pre-trained models, and demos are available at https://github.com/YoungSeng/QPGesture.
Automatic Annotation of Direct Speech in Written French Narratives
Jun 28, 2023
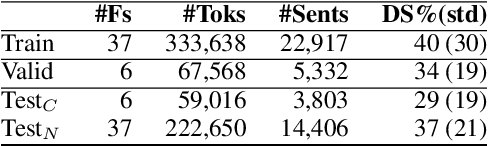

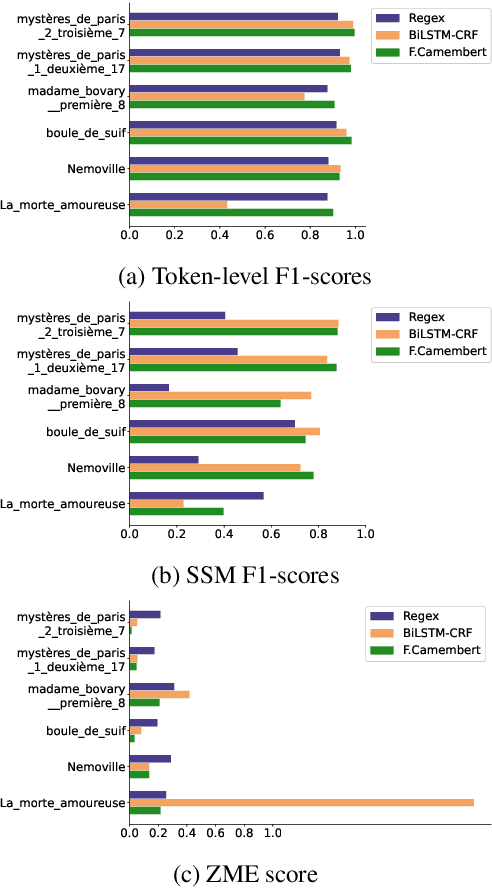
The automatic annotation of direct speech (AADS) in written text has been often used in computational narrative understanding. Methods based on either rules or deep neural networks have been explored, in particular for English or German languages. Yet, for French, our target language, not many works exist. Our goal is to create a unified framework to design and evaluate AADS models in French. For this, we consolidated the largest-to-date French narrative dataset annotated with DS per word; we adapted various baselines for sequence labelling or from AADS in other languages; and we designed and conducted an extensive evaluation focused on generalisation. Results show that the task still requires substantial efforts and emphasise characteristics of each baseline. Although this framework could be improved, it is a step further to encourage more research on the topic.
Scaling Laws for Discriminative Speech Recognition Rescoring Models
Jun 27, 2023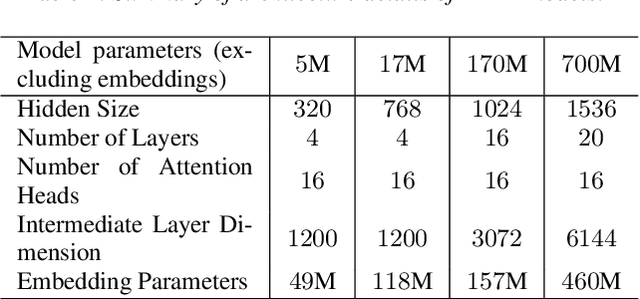
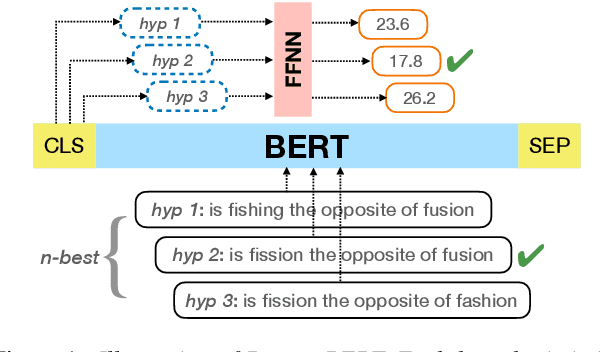
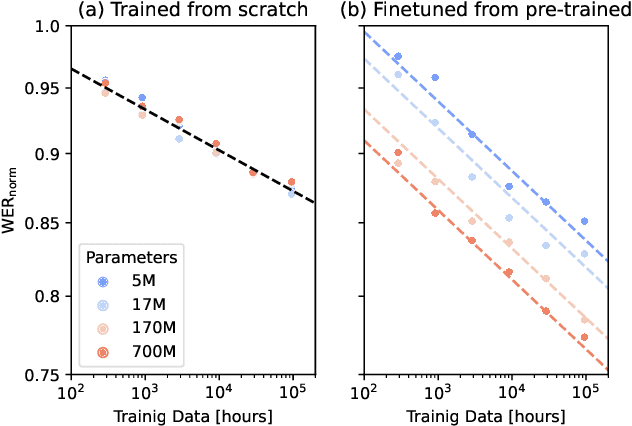
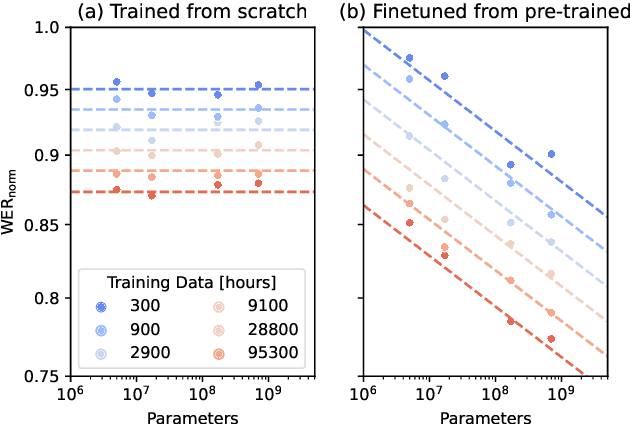
Recent studies have found that model performance has a smooth power-law relationship, or scaling laws, with training data and model size, for a wide range of problems. These scaling laws allow one to choose nearly optimal data and model sizes. We study whether this scaling property is also applicable to second-pass rescoring, which is an important component of speech recognition systems. We focus on RescoreBERT as the rescoring model, which uses a pre-trained Transformer-based architecture fined tuned with an ASR discriminative loss. Using such a rescoring model, we show that the word error rate (WER) follows a scaling law for over two orders of magnitude as training data and model size increase. In addition, it is found that a pre-trained model would require less data than a randomly initialized model of the same size, representing effective data transferred from pre-training step. This effective data transferred is found to also follow a scaling law with the data and model size.
Quantifying the perceptual value of lexical and non-lexical channels in speech
Jul 07, 2023
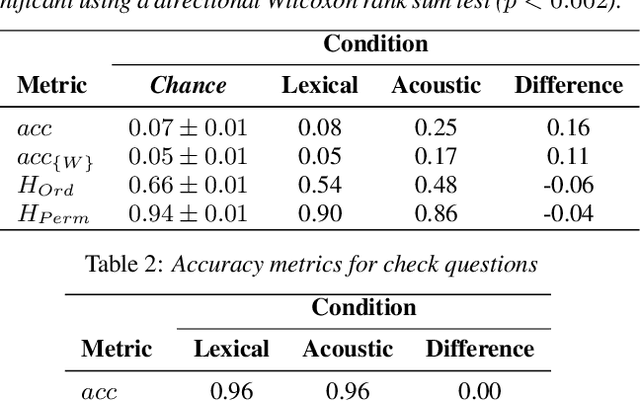
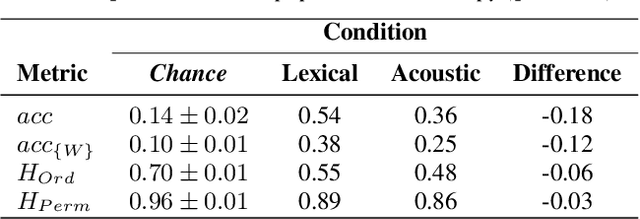
Speech is a fundamental means of communication that can be seen to provide two channels for transmitting information: the lexical channel of which words are said, and the non-lexical channel of how they are spoken. Both channels shape listener expectations of upcoming communication; however, directly quantifying their relative effect on expectations is challenging. Previous attempts require spoken variations of lexically-equivalent dialogue turns or conspicuous acoustic manipulations. This paper introduces a generalised paradigm to study the value of non-lexical information in dialogue across unconstrained lexical content. By quantifying the perceptual value of the non-lexical channel with both accuracy and entropy reduction, we show that non-lexical information produces a consistent effect on expectations of upcoming dialogue: even when it leads to poorer discriminative turn judgements than lexical content alone, it yields higher consensus among participants.
Probing self-supervised speech models for phonetic and phonemic information: a case study in aspiration
Jun 09, 2023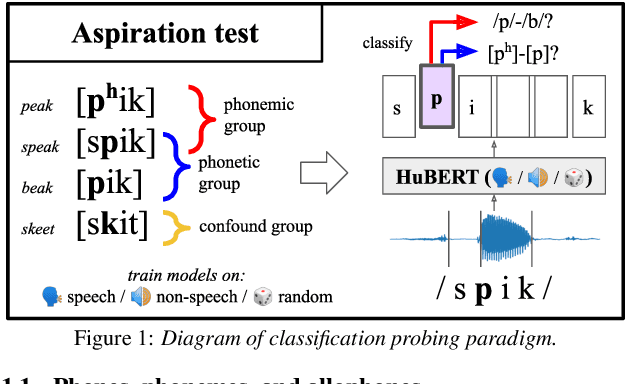
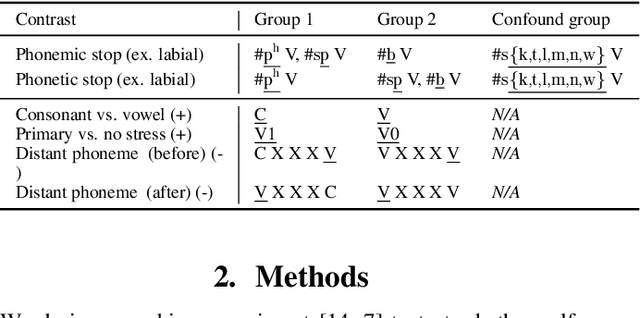
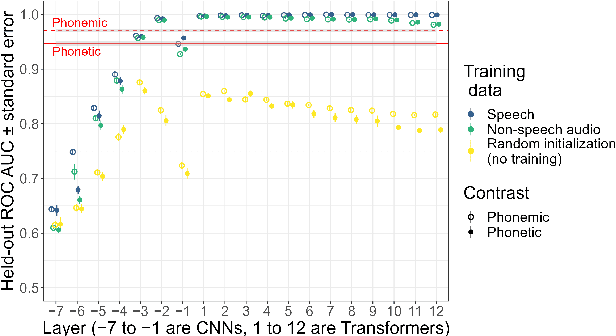
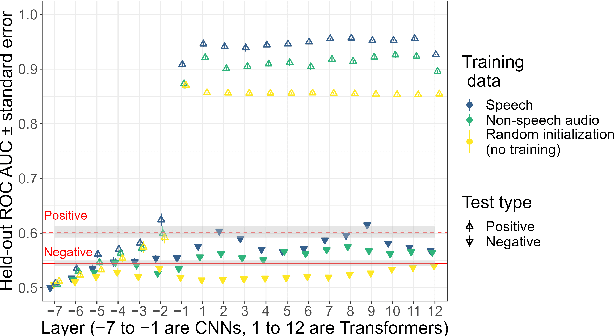
Textless self-supervised speech models have grown in capabilities in recent years, but the nature of the linguistic information they encode has not yet been thoroughly examined. We evaluate the extent to which these models' learned representations align with basic representational distinctions made by humans, focusing on a set of phonetic (low-level) and phonemic (more abstract) contrasts instantiated in word-initial stops. We find that robust representations of both phonetic and phonemic distinctions emerge in early layers of these models' architectures, and are preserved in the principal components of deeper layer representations. Our analyses suggest two sources for this success: some can only be explained by the optimization of the models on speech data, while some can be attributed to these models' high-dimensional architectures. Our findings show that speech-trained HuBERT derives a low-noise and low-dimensional subspace corresponding to abstract phonological distinctions.
In-the-wild Speech Emotion Conversion Using Disentangled Self-Supervised Representations and Neural Vocoder-based Resynthesis
Jun 02, 2023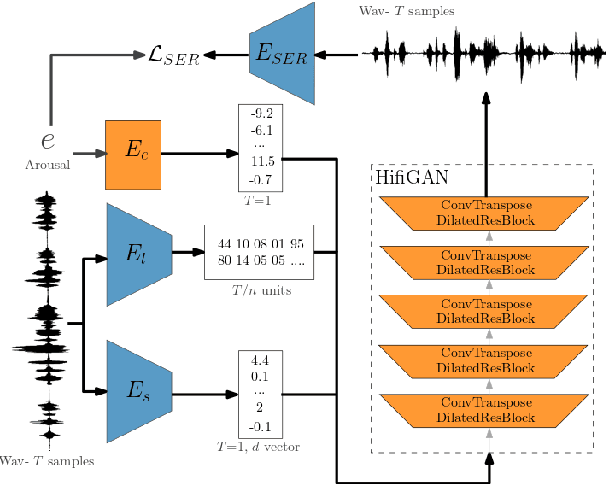
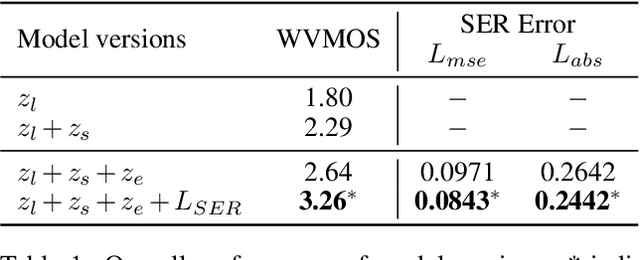
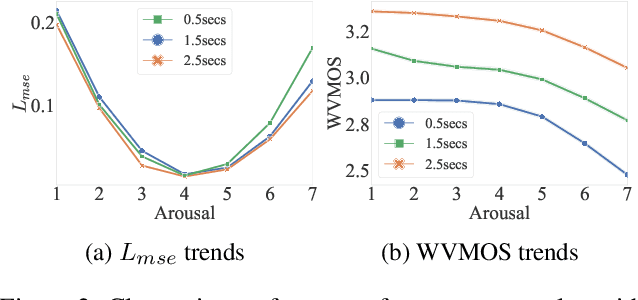
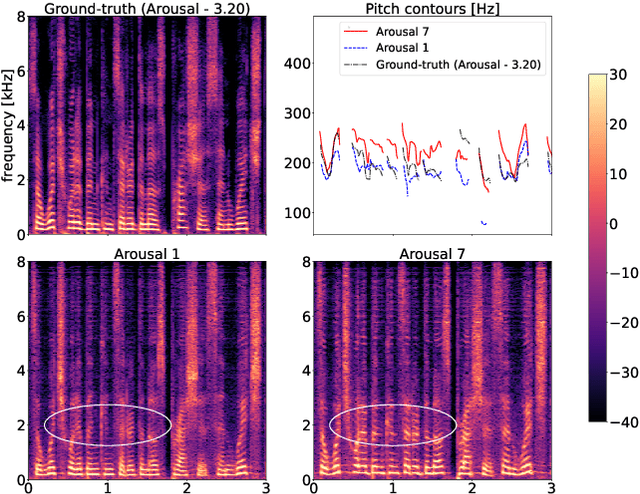
Speech emotion conversion aims to convert the expressed emotion of a spoken utterance to a target emotion while preserving the lexical information and the speaker's identity. In this work, we specifically focus on in-the-wild emotion conversion where parallel data does not exist, and the problem of disentangling lexical, speaker, and emotion information arises. In this paper, we introduce a methodology that uses self-supervised networks to disentangle the lexical, speaker, and emotional content of the utterance, and subsequently uses a HiFiGAN vocoder to resynthesise the disentangled representations to a speech signal of the targeted emotion. For better representation and to achieve emotion intensity control, we specifically focus on the aro\-usal dimension of continuous representations, as opposed to performing emotion conversion on categorical representations. We test our methodology on the large in-the-wild MSP-Podcast dataset. Results reveal that the proposed approach is aptly conditioned on the emotional content of input speech and is capable of synthesising natural-sounding speech for a target emotion. Results further reveal that the methodology better synthesises speech for mid-scale arousal (2 to 6) than for extreme arousal (1 and 7).
ExpCLIP: Bridging Text and Facial Expressions via Semantic Alignment
Aug 28, 2023
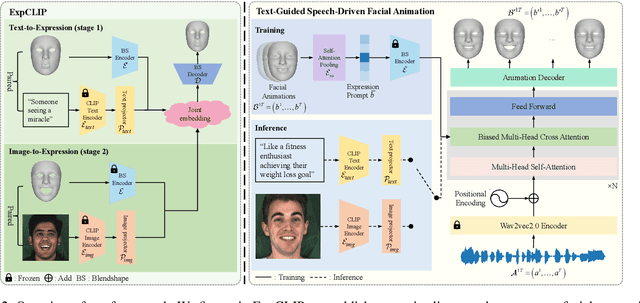
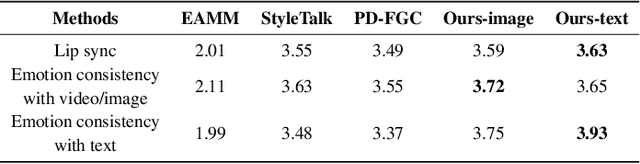
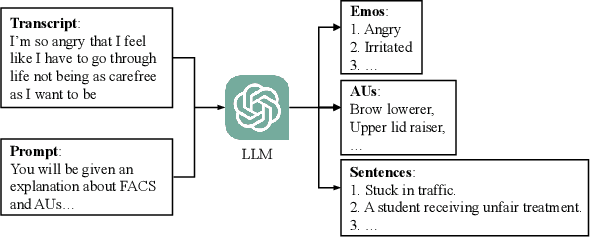
The objective of stylized speech-driven facial animation is to create animations that encapsulate specific emotional expressions. Existing methods often depend on pre-established emotional labels or facial expression templates, which may limit the necessary flexibility for accurately conveying user intent. In this research, we introduce a technique that enables the control of arbitrary styles by leveraging natural language as emotion prompts. This technique presents benefits in terms of both flexibility and user-friendliness. To realize this objective, we initially construct a Text-Expression Alignment Dataset (TEAD), wherein each facial expression is paired with several prompt-like descriptions.We propose an innovative automatic annotation method, supported by Large Language Models (LLMs), to expedite the dataset construction, thereby eliminating the substantial expense of manual annotation. Following this, we utilize TEAD to train a CLIP-based model, termed ExpCLIP, which encodes text and facial expressions into semantically aligned style embeddings. The embeddings are subsequently integrated into the facial animation generator to yield expressive and controllable facial animations. Given the limited diversity of facial emotions in existing speech-driven facial animation training data, we further introduce an effective Expression Prompt Augmentation (EPA) mechanism to enable the animation generator to support unprecedented richness in style control. Comprehensive experiments illustrate that our method accomplishes expressive facial animation generation and offers enhanced flexibility in effectively conveying the desired style.
Knowledge Distillation for Neural Transducer-based Target-Speaker ASR: Exploiting Parallel Mixture/Single-Talker Speech Data
May 25, 2023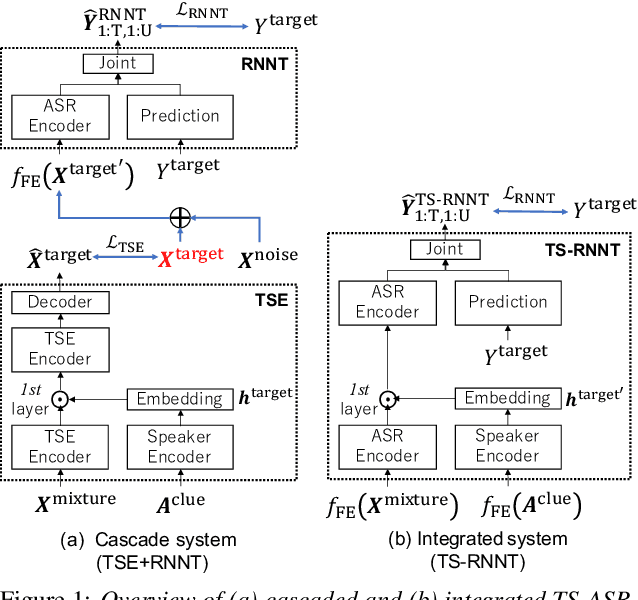

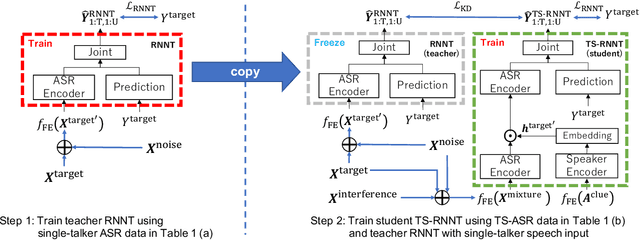
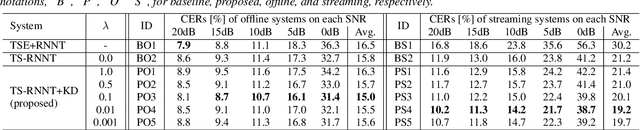
Neural transducer (RNNT)-based target-speaker speech recognition (TS-RNNT) directly transcribes a target speaker's voice from a multi-talker mixture. It is a promising approach for streaming applications because it does not incur the extra computation costs of a target speech extraction frontend, which is a critical barrier to quick response. TS-RNNT is trained end-to-end given the input speech (i.e., mixtures and enrollment speech) and reference transcriptions. The training mixtures are generally simulated by mixing single-talker signals, but conventional TS-RNNT training does not utilize single-speaker signals. This paper proposes using knowledge distillation (KD) to exploit the parallel mixture/single-talker speech data. Our proposed KD scheme uses an RNNT system pretrained with the target single-talker speech input to generate pseudo labels for the TS-RNNT training. Experimental results show that TS-RNNT systems trained with the proposed KD scheme outperform a baseline TS-RNNT.
A Study on the Reliability of Automatic Dysarthric Speech Assessments
Jun 07, 2023
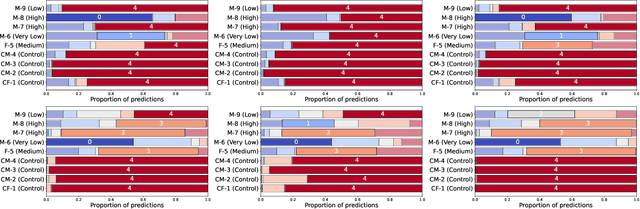
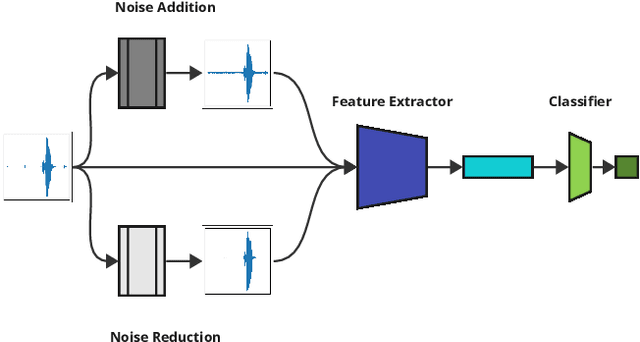
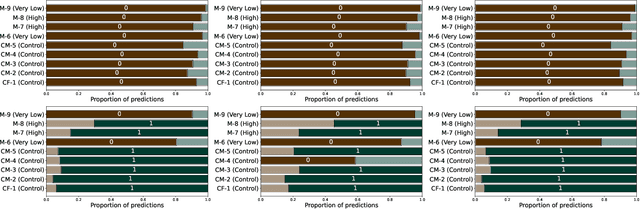
Automating dysarthria assessments offers the opportunity to develop effective, low-cost tools that address the current limitations of manual and subjective assessments. Nonetheless, it is unclear whether current approaches rely on dysarthria-related speech patterns or external factors. We aim toward obtaining a clearer understanding of dysarthria patterns. To this extent, we study the effects of noise in recordings, both through addition and reduction. We design and implement a new method for visualizing and comparing feature extractors and models, at a patient level, in a more interpretable way. We use the UA-Speech dataset with a speaker-based split of the dataset. Results reported in the literature appear to have been done irrespective of such split, leading to models that may be overconfident due to data-leakage. We hope that these results raise awareness in the research community regarding the requirements for establishing reliable automatic dysarthria assessment systems.
On the Efficacy and Noise-Robustness of Jointly Learned Speech Emotion and Automatic Speech Recognition
May 21, 2023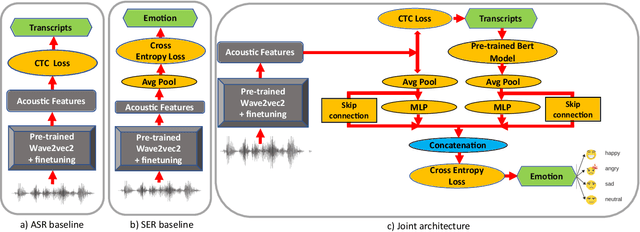
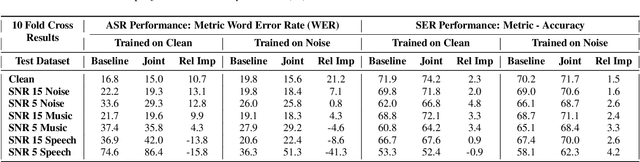
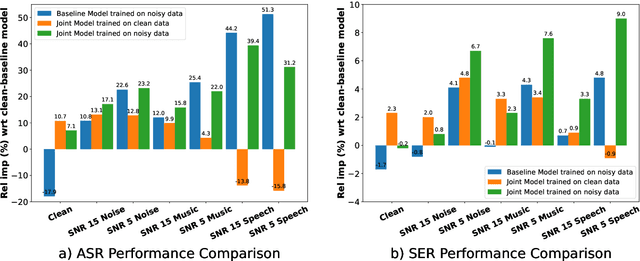
New-age conversational agent systems perform both speech emotion recognition (SER) and automatic speech recognition (ASR) using two separate and often independent approaches for real-world application in noisy environments. In this paper, we investigate a joint ASR-SER multitask learning approach in a low-resource setting and show that improvements are observed not only in SER, but also in ASR. We also investigate the robustness of such jointly trained models to the presence of background noise, babble, and music. Experimental results on the IEMOCAP dataset show that joint learning can improve ASR word error rate (WER) and SER classification accuracy by 10.7% and 2.3% respectively in clean scenarios. In noisy scenarios, results on data augmented with MUSAN show that the joint approach outperforms the independent ASR and SER approaches across many noisy conditions. Overall, the joint ASR-SER approach yielded more noise-resistant models than the independent ASR and SER approaches.