 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech-Text Dialog Pre-training for Spoken Dialog Understanding with Explicit Cross-Modal Alignment
May 19, 2023
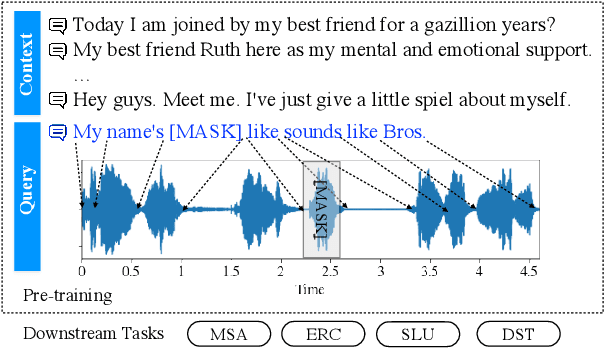

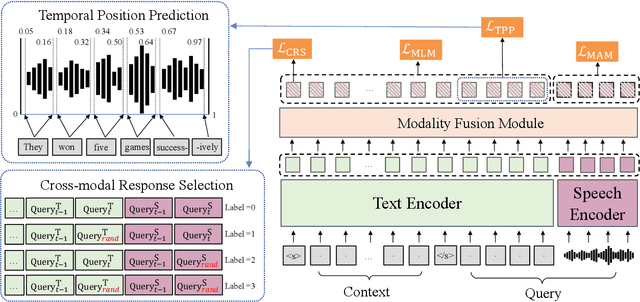
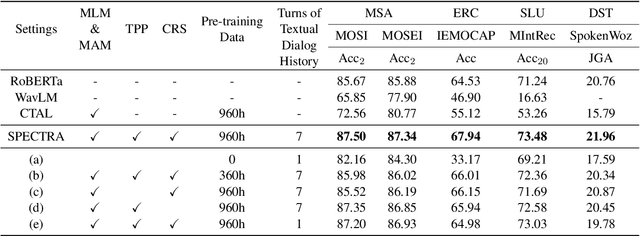
Recently, speech-text pre-training methods have shown remarkable success in many speech and natural language processing tasks. However, most previous pre-trained models are usually tailored for one or two specific tasks, but fail to conquer a wide range of speech-text tasks. In addition, existing speech-text pre-training methods fail to explore the contextual information within a dialogue to enrich utterance representations. In this paper, we propose Speech-text dialog Pre-training for spoken dialog understanding with ExpliCiT cRoss-Modal Alignment (SPECTRA), which is the first-ever speech-text dialog pre-training model. Concretely, to consider the temporality of speech modality, we design a novel temporal position prediction task to capture the speech-text alignment. This pre-training task aims to predict the start and end time of each textual word in the corresponding speech waveform. In addition, to learn the characteristics of spoken dialogs, we generalize a response selection task from textual dialog pre-training to speech-text dialog pre-training scenarios. Experimental results on four different downstream speech-text tasks demonstrate the superiority of SPECTRA in learning speech-text alignment and multi-turn dialog context.
EmoMix: Emotion Mixing via Diffusion Models for Emotional Speech Synthesis
Jun 01, 2023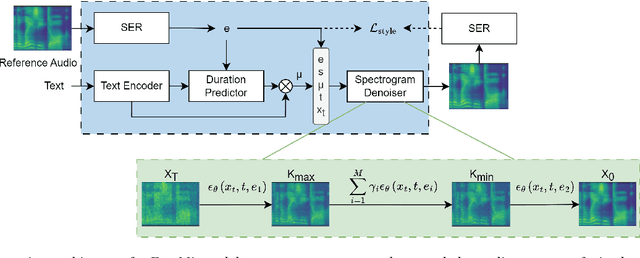
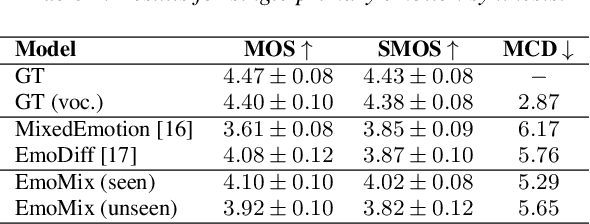
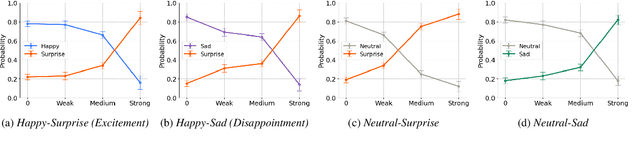

There has been significant progress in emotional Text-To-Speech (TTS) synthesis technology in recent years. However, existing methods primarily focus on the synthesis of a limited number of emotion types and have achieved unsatisfactory performance in intensity control. To address these limitations, we propose EmoMix, which can generate emotional speech with specified intensity or a mixture of emotions. Specifically, EmoMix is a controllable emotional TTS model based on a diffusion probabilistic model and a pre-trained speech emotion recognition (SER) model used to extract emotion embedding. Mixed emotion synthesis is achieved by combining the noises predicted by diffusion model conditioned on different emotions during only one sampling process at the run-time. We further apply the Neutral and specific primary emotion mixed in varying degrees to control intensity. Experimental results validate the effectiveness of EmoMix for synthesizing mixed emotion and intensity control.
AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment
May 24, 2023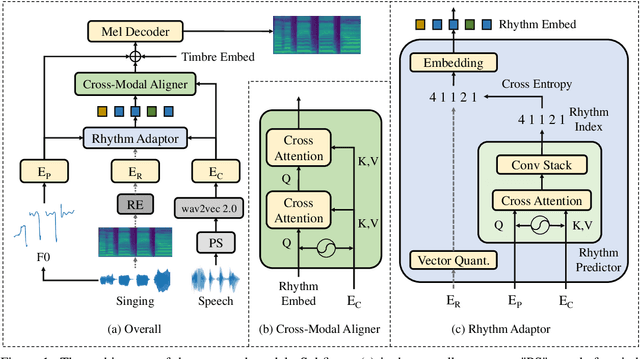
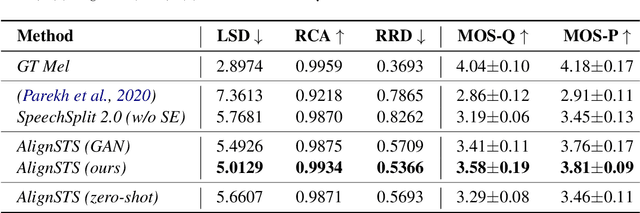
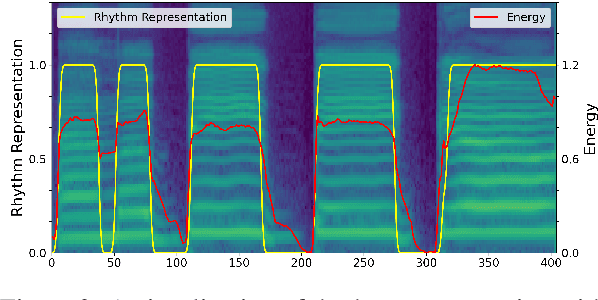
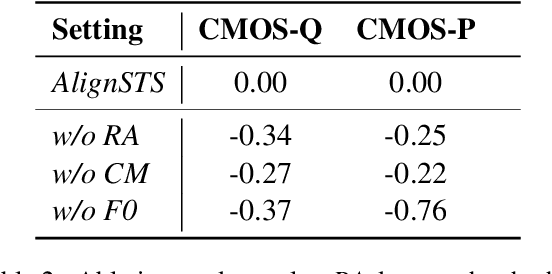
The speech-to-singing (STS) voice conversion task aims to generate singing samples corresponding to speech recordings while facing a major challenge: the alignment between the target (singing) pitch contour and the source (speech) content is difficult to learn in a text-free situation. This paper proposes AlignSTS, an STS model based on explicit cross-modal alignment, which views speech variance such as pitch and content as different modalities. Inspired by the mechanism of how humans will sing the lyrics to the melody, AlignSTS: 1) adopts a novel rhythm adaptor to predict the target rhythm representation to bridge the modality gap between content and pitch, where the rhythm representation is computed in a simple yet effective way and is quantized into a discrete space; and 2) uses the predicted rhythm representation to re-align the content based on cross-attention and conducts a cross-modal fusion for re-synthesize. Extensive experiments show that AlignSTS achieves superior performance in terms of both objective and subjective metrics. Audio samples are available at https://alignsts.github.io.
Eve Said Yes: AirBone Authentication for Head-Wearable Smart Voice Assistant
Sep 26, 2023Recent advances in machine learning and natural language processing have fostered the enormous prosperity of smart voice assistants and their services, e.g., Alexa, Google Home, Siri, etc. However, voice spoofing attacks are deemed to be one of the major challenges of voice control security, and never stop evolving such as deep-learning-based voice conversion and speech synthesis techniques. To solve this problem outside the acoustic domain, we focus on head-wearable devices, such as earbuds and virtual reality (VR) headsets, which are feasible to continuously monitor the bone-conducted voice in the vibration domain. Specifically, we identify that air and bone conduction (AC/BC) from the same vocalization are coupled (or concurrent) and user-level unique, which makes them suitable behavior and biometric factors for multi-factor authentication (MFA). The legitimate user can defeat acoustic domain and even cross-domain spoofing samples with the proposed two-stage AirBone authentication. The first stage answers \textit{whether air and bone conduction utterances are time domain consistent (TC)} and the second stage runs \textit{bone conduction speaker recognition (BC-SR)}. The security level is hence increased for two reasons: (1) current acoustic attacks on smart voice assistants cannot affect bone conduction, which is in the vibration domain; (2) even for advanced cross-domain attacks, the unique bone conduction features can detect adversary's impersonation and machine-induced vibration. Finally, AirBone authentication has good usability (the same level as voice authentication) compared with traditional MFA and those specially designed to enhance smart voice security. Our experimental results show that the proposed AirBone authentication is usable and secure, and can be easily equipped by commercial off-the-shelf head wearables with good user experience.
Cross-Language Speech Emotion Recognition Using Multimodal Dual Attention Transformers
Jul 14, 2023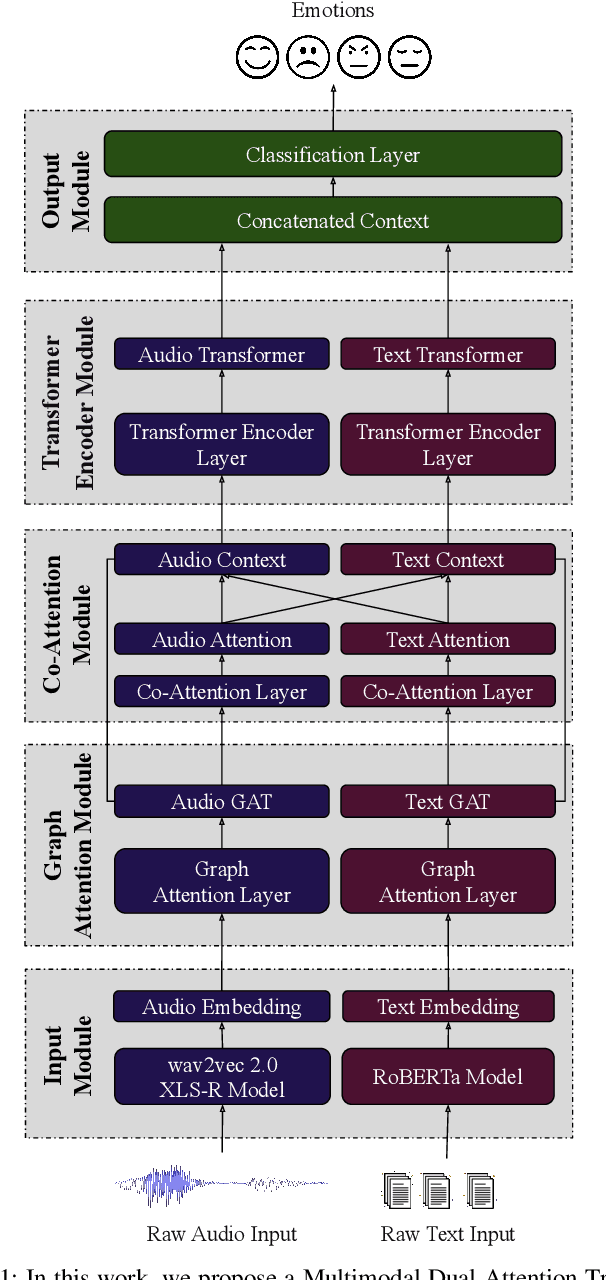
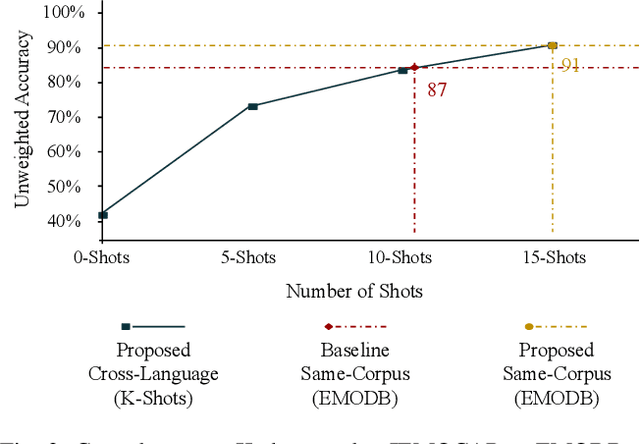
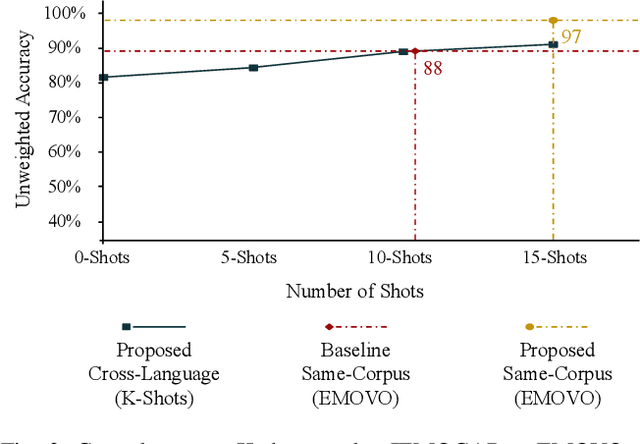
Despite the recent progress in speech emotion recognition (SER), state-of-the-art systems are unable to achieve improved performance in cross-language settings. In this paper, we propose a Multimodal Dual Attention Transformer (MDAT) model to improve cross-language SER. Our model utilises pre-trained models for multimodal feature extraction and is equipped with a dual attention mechanism including graph attention and co-attention to capture complex dependencies across different modalities and achieve improved cross-language SER results using minimal target language data. In addition, our model also exploits a transformer encoder layer for high-level feature representation to improve emotion classification accuracy. In this way, MDAT performs refinement of feature representation at various stages and provides emotional salient features to the classification layer. This novel approach also ensures the preservation of modality-specific emotional information while enhancing cross-modality and cross-language interactions. We assess our model's performance on four publicly available SER datasets and establish its superior effectiveness compared to recent approaches and baseline models.
Performance Comparison of Pre-trained Models for Speech-to-Text in Turkish: Whisper-Small and Wav2Vec2-XLS-R-300M
Jul 06, 2023In this study, the performances of the Whisper-Small and Wav2Vec2-XLS-R-300M models which are two pre-trained multilingual models for speech to text were examined for the Turkish language. Mozilla Common Voice version 11.0 which is prepared in Turkish language and is an open-source data set, was used in the study. The multilingual models, Whisper- Small and Wav2Vec2-XLS-R-300M were fine-tuned with this data set which contains a small amount of data. The speech to text performance of the two models was compared. WER values are calculated as 0.28 and 0.16 for the Wav2Vec2-XLS- R-300M and the Whisper-Small models respectively. In addition, the performances of the models were examined with the test data prepared with call center records that were not included in the training and validation dataset.
LibriSQA: Advancing Free-form and Open-ended Spoken Question Answering with a Novel Dataset and Framework
Aug 30, 2023While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
INTapt: Information-Theoretic Adversarial Prompt Tuning for Enhanced Non-Native Speech Recognition
May 25, 2023
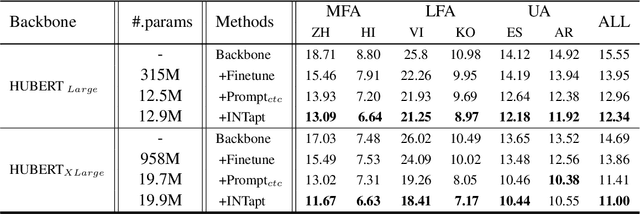
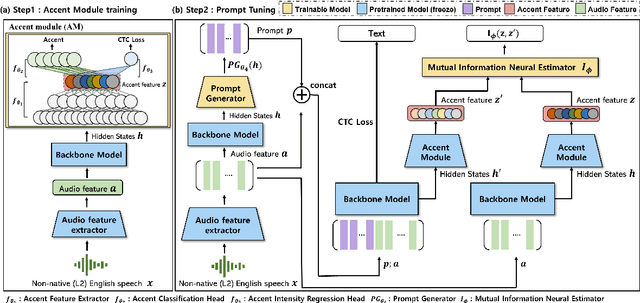
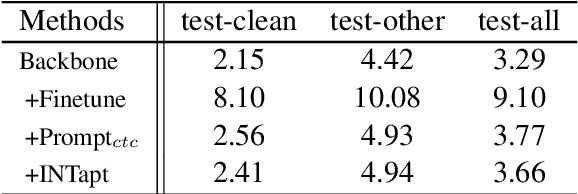
Automatic Speech Recognition (ASR) systems have attained unprecedented performance with large speech models pre-trained based on self-supervised speech representation learning. However, these pre-trained speech models suffer from representational bias as they tend to better represent those prominent accents (i.e., native (L1) English accent) in the pre-training speech corpus than less represented accents, resulting in a deteriorated performance for non-native (L2) English accents. Although there have been some approaches to mitigate this issue, all of these methods require updating the pre-trained model weights. In this paper, we propose Information Theoretic Adversarial Prompt Tuning (INTapt), which introduces prompts concatenated to the original input that can re-modulate the attention of the pre-trained model such that the corresponding input resembles a native (L1) English speech without updating the backbone weights. INTapt is trained simultaneously in the following two manners: (1) adversarial training to reduce accent feature dependence between the original input and the prompt-concatenated input and (2) training to minimize CTC loss for improving ASR performance to a prompt-concatenated input. Experimental results show that INTapt improves the performance of L2 English and increases feature similarity between L2 and L1 accents.
HM-Conformer: A Conformer-based audio deepfake detection system with hierarchical pooling and multi-level classification token aggregation methods
Sep 15, 2023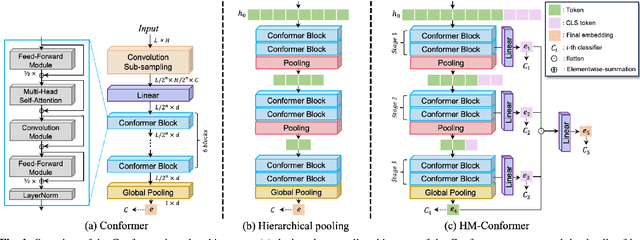

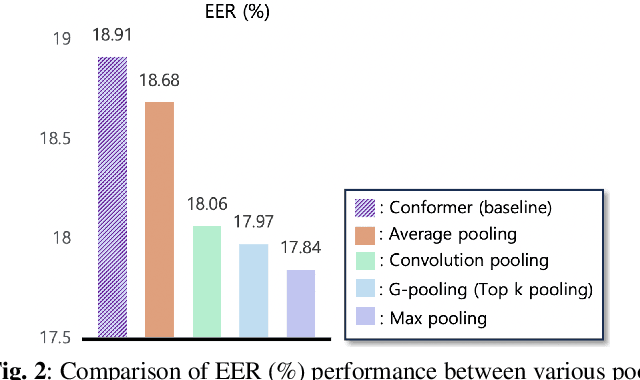

Audio deepfake detection (ADD) is the task of detecting spoofing attacks generated by text-to-speech or voice conversion systems. Spoofing evidence, which helps to distinguish between spoofed and bona-fide utterances, might exist either locally or globally in the input features. To capture these, the Conformer, which consists of Transformers and CNN, possesses a suitable structure. However, since the Conformer was designed for sequence-to-sequence tasks, its direct application to ADD tasks may be sub-optimal. To tackle this limitation, we propose HM-Conformer by adopting two components: (1) Hierarchical pooling method progressively reducing the sequence length to eliminate duplicated information (2) Multi-level classification token aggregation method utilizing classification tokens to gather information from different blocks. Owing to these components, HM-Conformer can efficiently detect spoofing evidence by processing various sequence lengths and aggregating them. In experimental results on the ASVspoof 2021 Deepfake dataset, HM-Conformer achieved a 15.71% EER, showing competitive performance compared to recent systems.
Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
May 19, 2023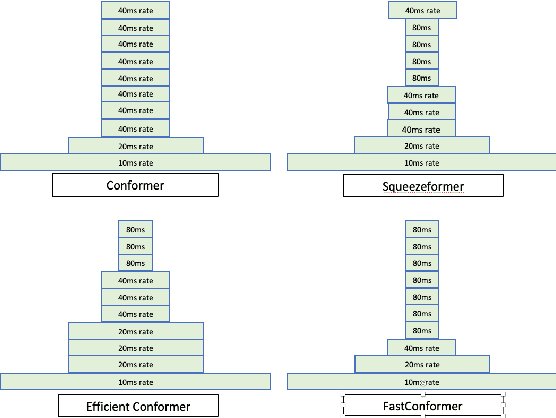

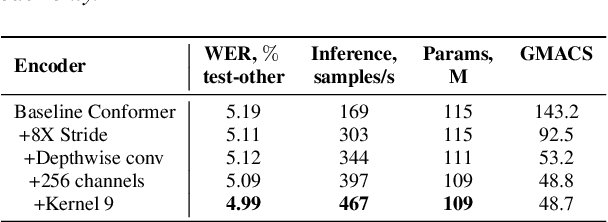

Conformer-based models have become the most dominant end-to-end architecture for speech processing tasks. In this work, we propose a carefully redesigned Conformer with a new down-sampling schema. The proposed model, named Fast Conformer, is 2.8x faster than original Conformer, while preserving state-of-the-art accuracy on Automatic Speech Recognition benchmarks. Also we replace the original Conformer global attention with limited context attention post-training to enable transcription of an hour-long audio. We further improve long-form speech transcription by adding a global token. Fast Conformer combined with a Transformer decoder also outperforms the original Conformer in accuracy and in speed for Speech Translation and Spoken Language Understanding.