 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Creating Personalized Synthetic Voices from Post-Glossectomy Speech with Guided Diffusion Models
May 27, 2023
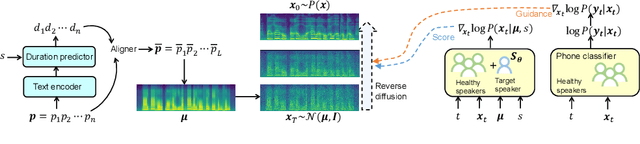
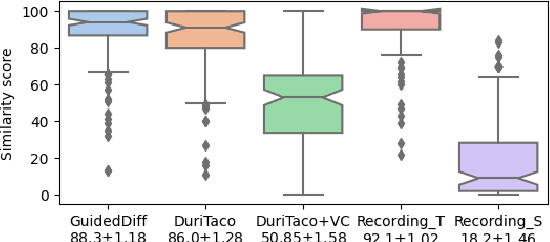
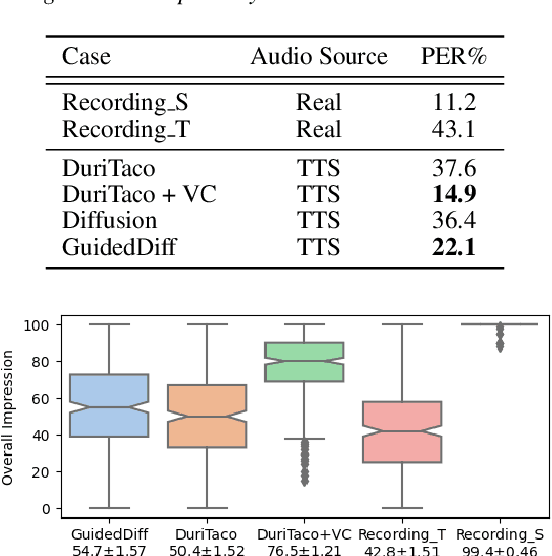
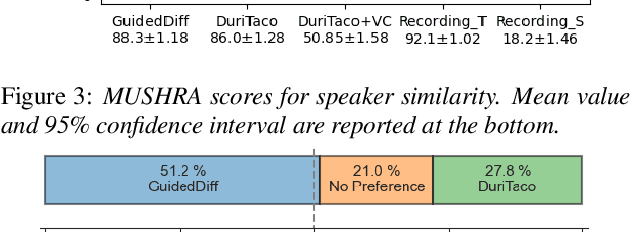
This paper is about developing personalized speech synthesis systems with recordings of mildly impaired speech. In particular, we consider consonant and vowel alterations resulted from partial glossectomy, the surgical removal of part of the tongue. The aim is to restore articulation in the synthesized speech and maximally preserve the target speaker's individuality. We propose to tackle the problem with guided diffusion models. Specifically, a diffusion-based speech synthesis model is trained on original recordings, to capture and preserve the target speaker's original articulation style. When using the model for inference, a separately trained phone classifier will guide the synthesis process towards proper articulation. Objective and subjective evaluation results show that the proposed method substantially improves articulation in the synthesized speech over original recordings, and preserves more of the target speaker's individuality than a voice conversion baseline.
Hearing Lips in Noise: Universal Viseme-Phoneme Mapping and Transfer for Robust Audio-Visual Speech Recognition
Jun 18, 2023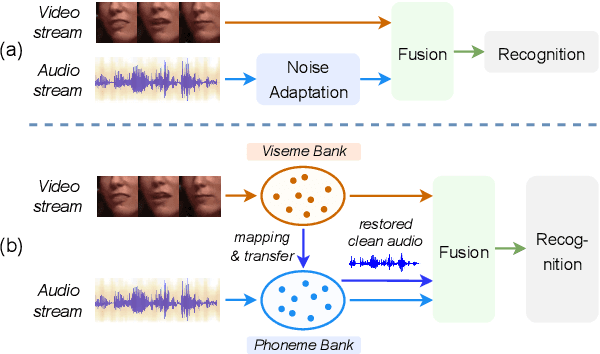
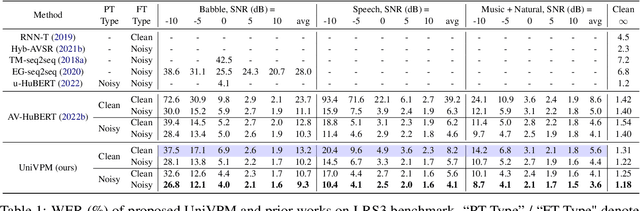
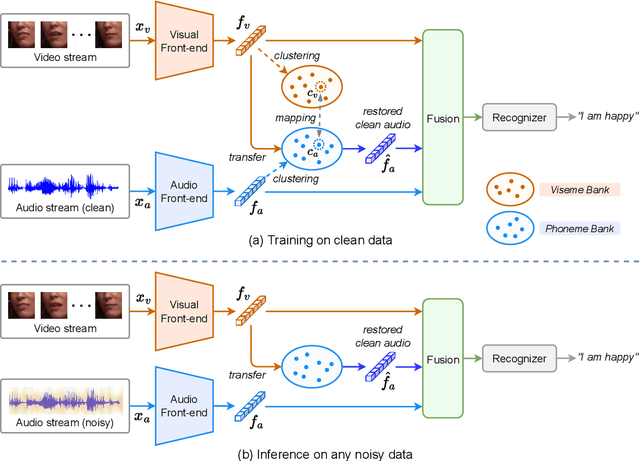
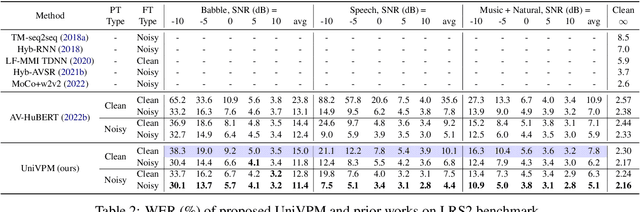
Audio-visual speech recognition (AVSR) provides a promising solution to ameliorate the noise-robustness of audio-only speech recognition with visual information. However, most existing efforts still focus on audio modality to improve robustness considering its dominance in AVSR task, with noise adaptation techniques such as front-end denoise processing. Though effective, these methods are usually faced with two practical challenges: 1) lack of sufficient labeled noisy audio-visual training data in some real-world scenarios and 2) less optimal model generality to unseen testing noises. In this work, we investigate the noise-invariant visual modality to strengthen robustness of AVSR, which can adapt to any testing noises while without dependence on noisy training data, a.k.a., unsupervised noise adaptation. Inspired by human perception mechanism, we propose a universal viseme-phoneme mapping (UniVPM) approach to implement modality transfer, which can restore clean audio from visual signals to enable speech recognition under any noisy conditions. Extensive experiments on public benchmarks LRS3 and LRS2 show that our approach achieves the state-of-the-art under various noisy as well as clean conditions. In addition, we also outperform previous state-of-the-arts on visual speech recognition task.
Zero-shot text-to-speech synthesis conditioned using self-supervised speech representation model
Apr 24, 2023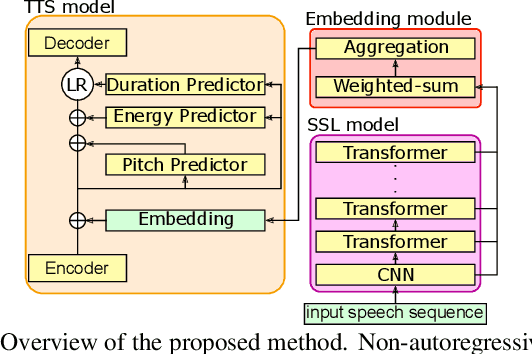
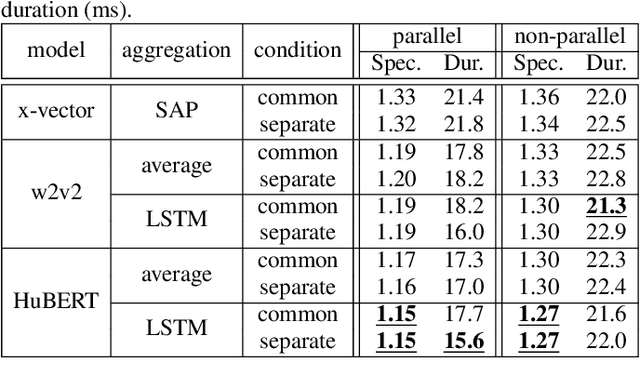
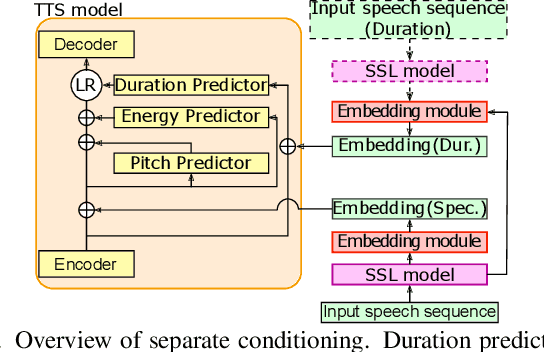

This paper proposes a zero-shot text-to-speech (TTS) conditioned by a self-supervised speech-representation model acquired through self-supervised learning (SSL). Conventional methods with embedding vectors from x-vector or global style tokens still have a gap in reproducing the speaker characteristics of unseen speakers. A novel point of the proposed method is the direct use of the SSL model to obtain embedding vectors from speech representations trained with a large amount of data. We also introduce the separate conditioning of acoustic features and a phoneme duration predictor to obtain the disentangled embeddings between rhythm-based speaker characteristics and acoustic-feature-based ones. The disentangled embeddings will enable us to achieve better reproduction performance for unseen speakers and rhythm transfer conditioned by different speeches. Objective and subjective evaluations showed that the proposed method can synthesize speech with improved similarity and achieve speech-rhythm transfer.
N-Shot Benchmarking of Whisper on Diverse Arabic Speech Recognition
Jun 05, 2023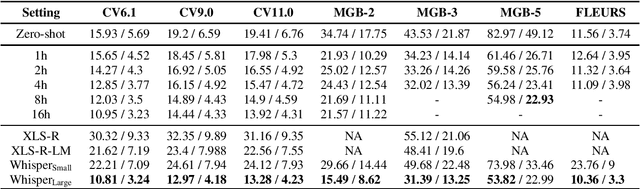
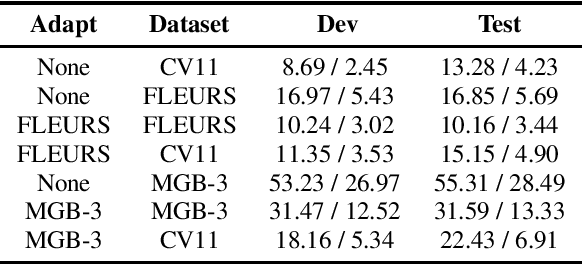
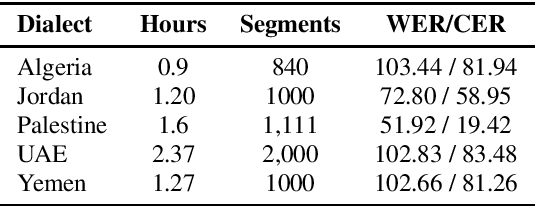
Whisper, the recently developed multilingual weakly supervised model, is reported to perform well on multiple speech recognition benchmarks in both monolingual and multilingual settings. However, it is not clear how Whisper would fare under diverse conditions even on languages it was evaluated on such as Arabic. In this work, we address this gap by comprehensively evaluating Whisper on several varieties of Arabic speech for the ASR task. Our evaluation covers most publicly available Arabic speech data and is performed under n-shot (zero-, few-, and full) finetuning. We also investigate the robustness of Whisper under completely novel conditions, such as in dialect-accented standard Arabic and in unseen dialects for which we develop evaluation data. Our experiments show that although Whisper zero-shot outperforms fully finetuned XLS-R models on all datasets, its performance deteriorates significantly in the zero-shot setting for five unseen dialects (i.e., Algeria, Jordan, Palestine, UAE, and Yemen).
DUB: Discrete Unit Back-translation for Speech Translation
May 19, 2023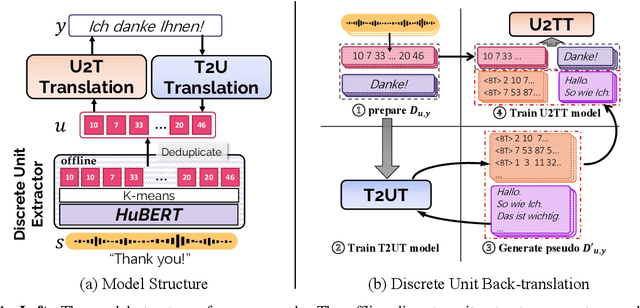

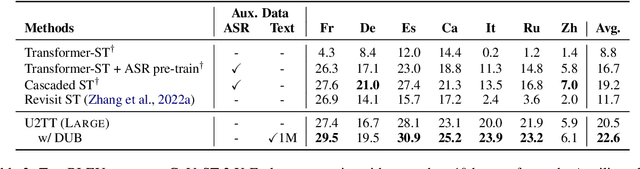
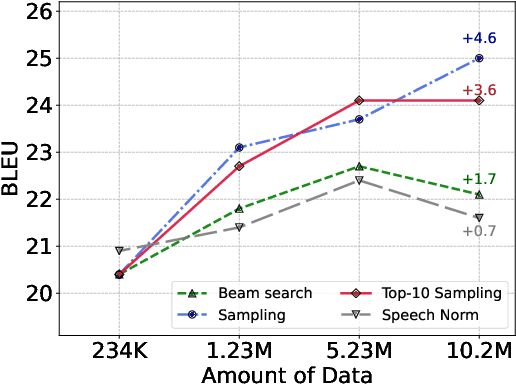
How can speech-to-text translation (ST) perform as well as machine translation (MT)? The key point is to bridge the modality gap between speech and text so that useful MT techniques can be applied to ST. Recently, the approach of representing speech with unsupervised discrete units yields a new way to ease the modality problem. This motivates us to propose Discrete Unit Back-translation (DUB) to answer two questions: (1) Is it better to represent speech with discrete units than with continuous features in direct ST? (2) How much benefit can useful MT techniques bring to ST? With DUB, the back-translation technique can successfully be applied on direct ST and obtains an average boost of 5.5 BLEU on MuST-C En-De/Fr/Es. In the low-resource language scenario, our method achieves comparable performance to existing methods that rely on large-scale external data. Code and models are available at https://github.com/0nutation/DUB.
Beyond Fairness: Age-Harmless Parkinson's Detection via Voice
Sep 23, 2023Parkinson's disease (PD), a neurodegenerative disorder, often manifests as speech and voice dysfunction. While utilizing voice data for PD detection has great potential in clinical applications, the widely used deep learning models currently have fairness issues regarding different ages of onset. These deep models perform well for the elderly group (age $>$ 55) but are less accurate for the young group (age $\leq$ 55). Through our investigation, the discrepancy between the elderly and the young arises due to 1) an imbalanced dataset and 2) the milder symptoms often seen in early-onset patients. However, traditional debiasing methods are impractical as they typically impair the prediction accuracy for the majority group while minimizing the discrepancy. To address this issue, we present a new debiasing method using GradCAM-based feature masking combined with ensemble models, ensuring that neither fairness nor accuracy is compromised. Specifically, the GradCAM-based feature masking selectively obscures age-related features in the input voice data while preserving essential information for PD detection. The ensemble models further improve the prediction accuracy for the minority (young group). Our approach effectively improves detection accuracy for early-onset patients without sacrificing performance for the elderly group. Additionally, we propose a two-step detection strategy for the young group, offering a practical risk assessment for potential early-onset PD patients.
Towards generalisable and calibrated synthetic speech detection with self-supervised representations
Sep 11, 2023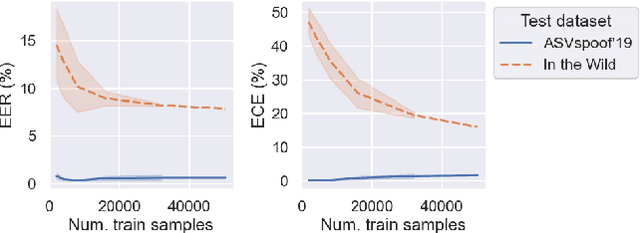
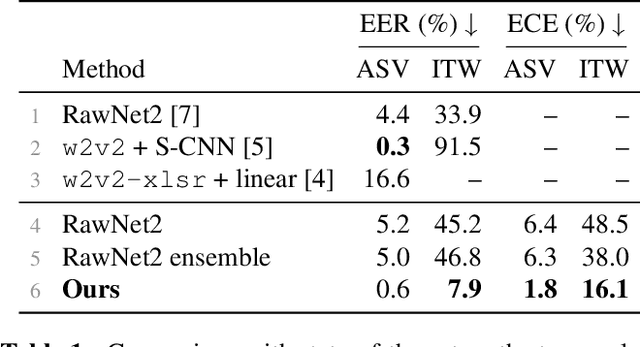
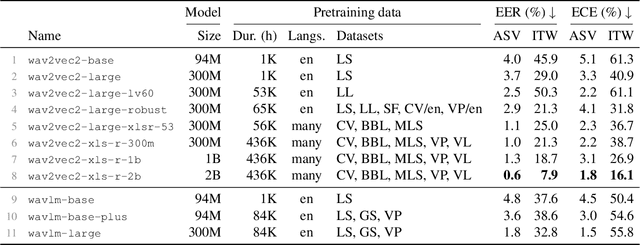
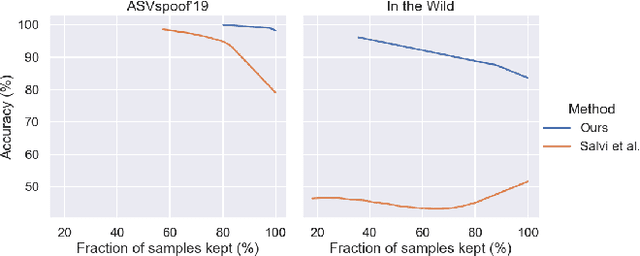
Generalisation -- the ability of a model to perform well on unseen data -- is crucial for building reliable deep fake detectors. However, recent studies have shown that the current audio deep fake models fall short of this desideratum. In this paper we show that pretrained self-supervised representations followed by a simple logistic regression classifier achieve strong generalisation capabilities, reducing the equal error rate from 30% to 8% on the newly introduced In-the-Wild dataset. Importantly, this approach also produces considerably better calibrated models when compared to previous approaches. This means that we can trust our model's predictions more and use these for downstream tasks, such as uncertainty estimation. In particular, we show that the entropy of the estimated probabilities provides a reliable way of rejecting uncertain samples and further improving the accuracy.
An Information-Theoretic Analysis of Self-supervised Discrete Representations of Speech
Jun 04, 2023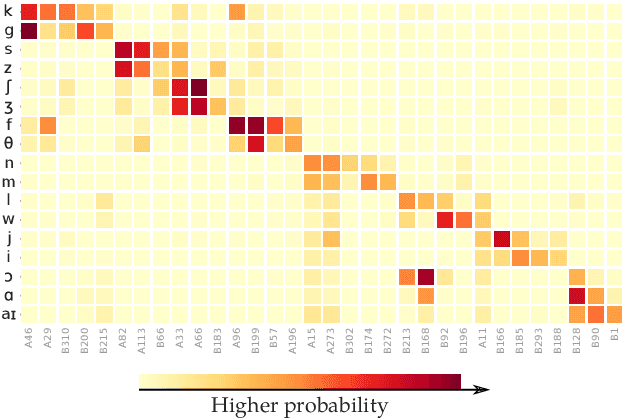
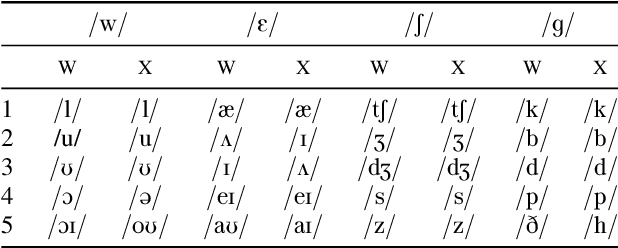
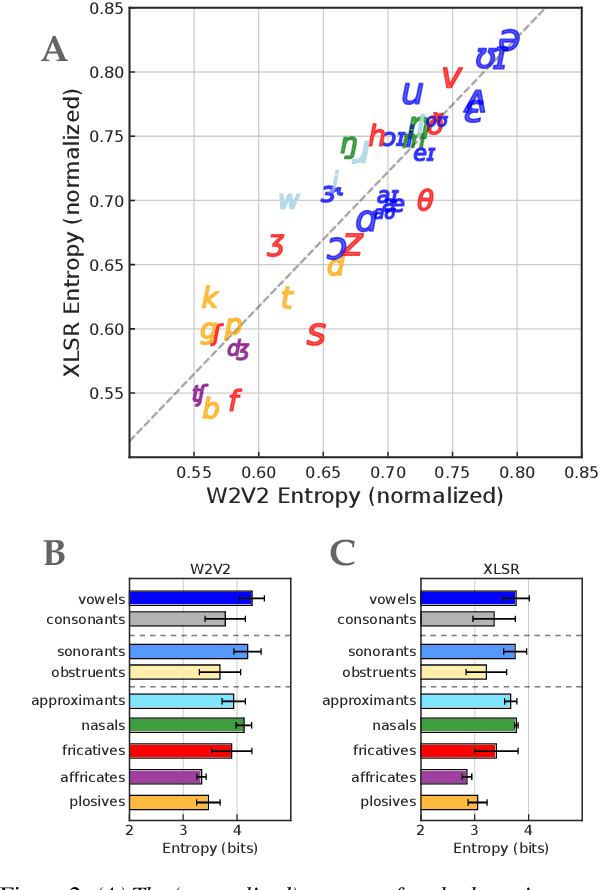
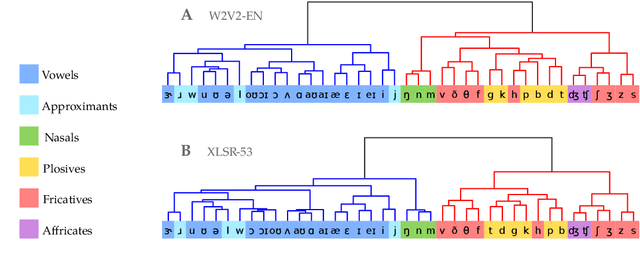
Self-supervised representation learning for speech often involves a quantization step that transforms the acoustic input into discrete units. However, it remains unclear how to characterize the relationship between these discrete units and abstract phonetic categories such as phonemes. In this paper, we develop an information-theoretic framework whereby we represent each phonetic category as a distribution over discrete units. We then apply our framework to two different self-supervised models (namely wav2vec 2.0 and XLSR) and use American English speech as a case study. Our study demonstrates that the entropy of phonetic distributions reflects the variability of the underlying speech sounds, with phonetically similar sounds exhibiting similar distributions. While our study confirms the lack of direct, one-to-one correspondence, we find an intriguing, indirect relationship between phonetic categories and discrete units.
Open-vocabulary Keyword-spotting with Adaptive Instance Normalization
Sep 13, 2023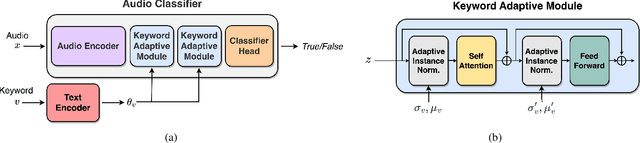

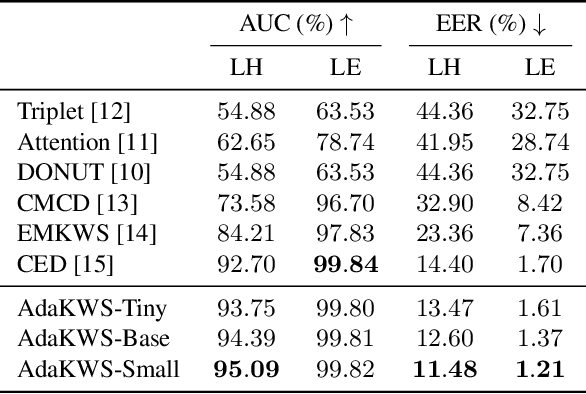
Open vocabulary keyword spotting is a crucial and challenging task in automatic speech recognition (ASR) that focuses on detecting user-defined keywords within a spoken utterance. Keyword spotting methods commonly map the audio utterance and keyword into a joint embedding space to obtain some affinity score. In this work, we propose AdaKWS, a novel method for keyword spotting in which a text encoder is trained to output keyword-conditioned normalization parameters. These parameters are used to process the auditory input. We provide an extensive evaluation using challenging and diverse multi-lingual benchmarks and show significant improvements over recent keyword spotting and ASR baselines. Furthermore, we study the effectiveness of our approach on low-resource languages that were unseen during the training. The results demonstrate a substantial performance improvement compared to baseline methods.
VoicePAT: An Efficient Open-source Evaluation Toolkit for Voice Privacy Research
Sep 14, 2023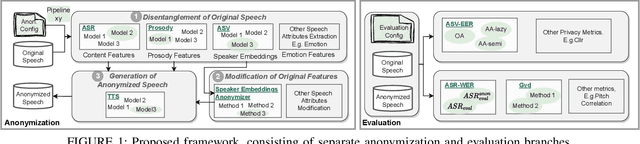
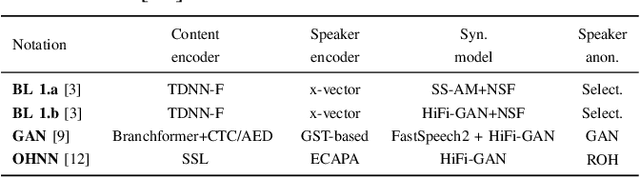

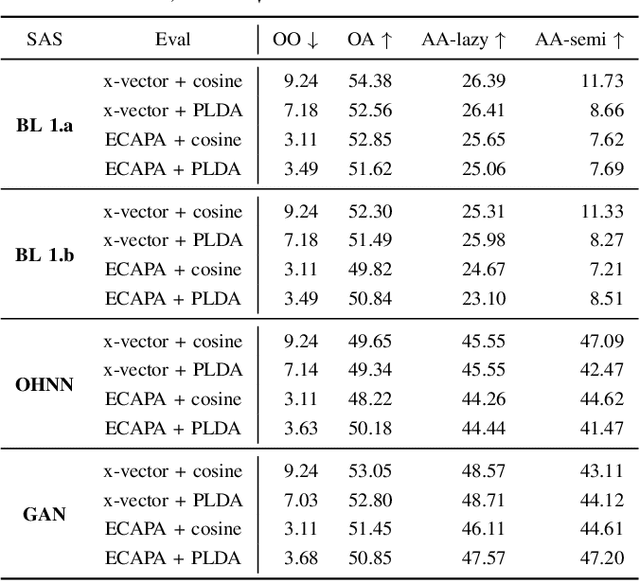
Speaker anonymization is the task of modifying a speech recording such that the original speaker cannot be identified anymore. Since the first Voice Privacy Challenge in 2020, along with the release of a framework, the popularity of this research topic is continually increasing. However, the comparison and combination of different anonymization approaches remains challenging due to the complexity of evaluation and the absence of user-friendly research frameworks. We therefore propose an efficient speaker anonymization and evaluation framework based on a modular and easily extendable structure, almost fully in Python. The framework facilitates the orchestration of several anonymization approaches in parallel and allows for interfacing between different techniques. Furthermore, we propose modifications to common evaluation methods which make the evaluation more powerful and reduces their computation time by 65 to 95\%, depending on the metric. Our code is fully open source.