 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Investigating the Utility of Surprisal from Large Language Models for Speech Synthesis Prosody
Jun 16, 2023
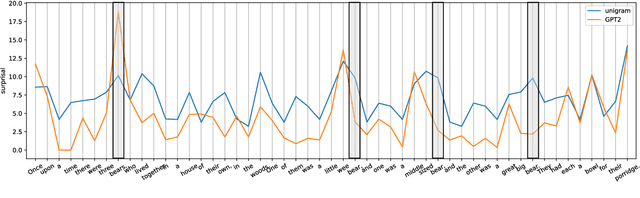
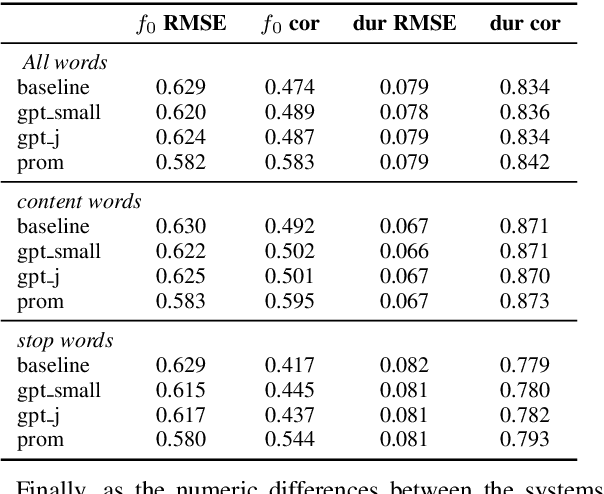
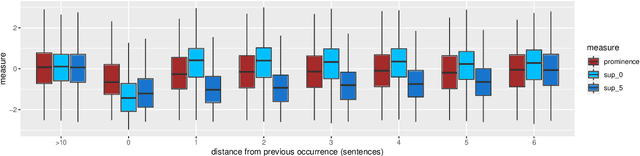
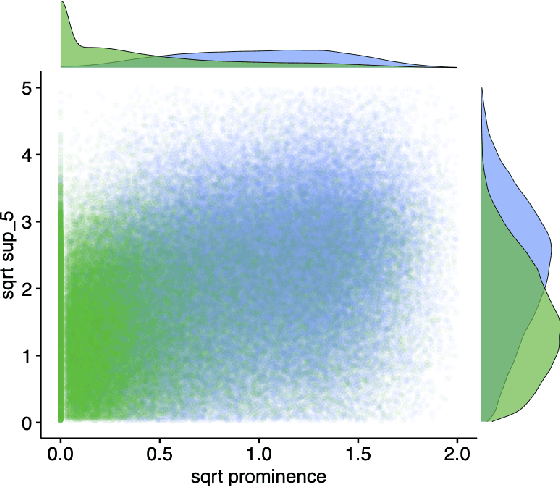
This paper investigates the use of word surprisal, a measure of the predictability of a word in a given context, as a feature to aid speech synthesis prosody. We explore how word surprisal extracted from large language models (LLMs) correlates with word prominence, a signal-based measure of the salience of a word in a given discourse. We also examine how context length and LLM size affect the results, and how a speech synthesizer conditioned with surprisal values compares with a baseline system. To evaluate these factors, we conducted experiments using a large corpus of English text and LLMs of varying sizes. Our results show that word surprisal and word prominence are moderately correlated, suggesting that they capture related but distinct aspects of language use. We find that length of context and size of the LLM impact the correlations, but not in the direction anticipated, with longer contexts and larger LLMs generally underpredicting prominent words in a nearly linear manner. We demonstrate that, in line with these findings, a speech synthesizer conditioned with surprisal values provides a minimal improvement over the baseline with the results suggesting a limited effect of using surprisal values for eliciting appropriate prominence patterns.
Speech Self-Supervised Representation Benchmarking: Are We Doing it Right?
Jun 01, 2023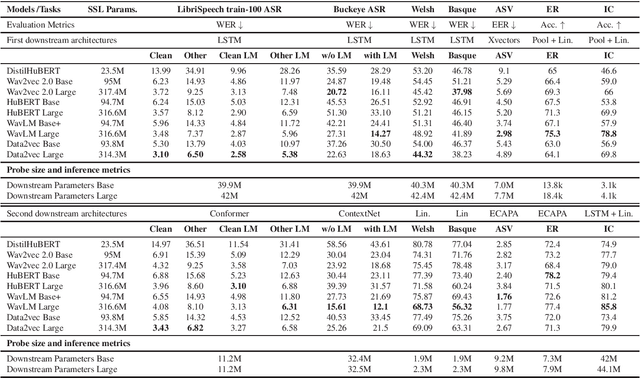
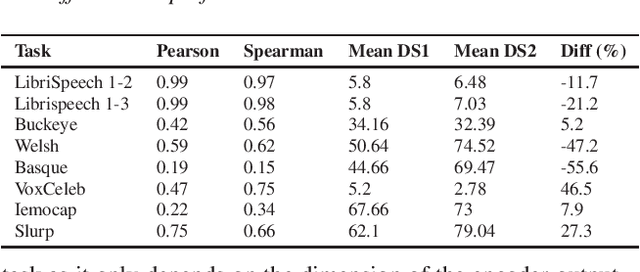
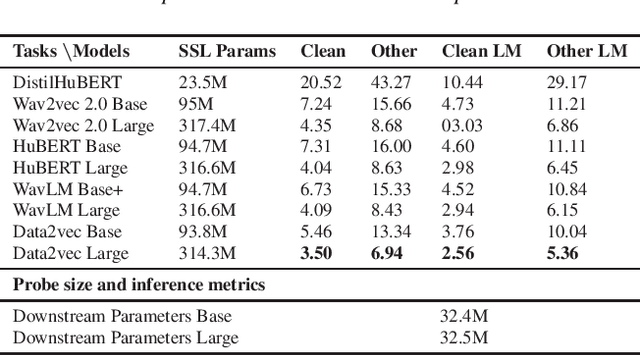
Self-supervised learning (SSL) has recently allowed leveraging large datasets of unlabeled speech signals to reach impressive performance on speech tasks using only small amounts of annotated data. The high number of proposed approaches fostered the need and rise of extended benchmarks that evaluate their performance on a set of downstream tasks exploring various aspects of the speech signal. However, and while the number of considered tasks has been growing, most rely upon a single decoding architecture that maps the frozen SSL representations to the downstream labels. This work investigates the robustness of such benchmarking results to changes in the decoder architecture. Interestingly, it appears that varying the architecture of the downstream decoder leads to significant variations in the leaderboards of most tasks. Concerningly, our study reveals that benchmarking using limited decoders may cause a counterproductive increase in the sizes of the developed SSL models.
* 6 pages
RedPenNet for Grammatical Error Correction: Outputs to Tokens, Attentions to Spans
Sep 19, 2023The text editing tasks, including sentence fusion, sentence splitting and rephrasing, text simplification, and Grammatical Error Correction (GEC), share a common trait of dealing with highly similar input and output sequences. This area of research lies at the intersection of two well-established fields: (i) fully autoregressive sequence-to-sequence approaches commonly used in tasks like Neural Machine Translation (NMT) and (ii) sequence tagging techniques commonly used to address tasks such as Part-of-speech tagging, Named-entity recognition (NER), and similar. In the pursuit of a balanced architecture, researchers have come up with numerous imaginative and unconventional solutions, which we're discussing in the Related Works section. Our approach to addressing text editing tasks is called RedPenNet and is aimed at reducing architectural and parametric redundancies presented in specific Sequence-To-Edits models, preserving their semi-autoregressive advantages. Our models achieve $F_{0.5}$ scores of 77.60 on the BEA-2019 (test), which can be considered as state-of-the-art the only exception for system combination and 67.71 on the UAGEC+Fluency (test) benchmarks. This research is being conducted in the context of the UNLP 2023 workshop, where it was presented as a paper as a paper for the Shared Task in Grammatical Error Correction (GEC) for Ukrainian. This study aims to apply the RedPenNet approach to address the GEC problem in the Ukrainian language.
Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
May 19, 2023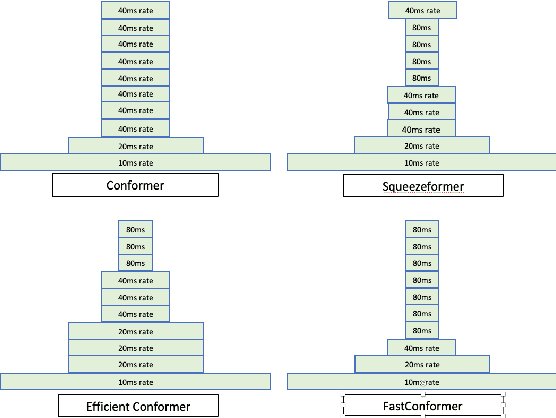

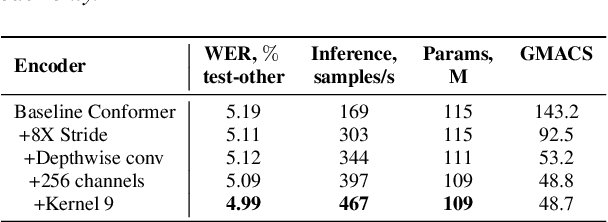

Conformer-based models have become the most dominant end-to-end architecture for speech processing tasks. In this work, we propose a carefully redesigned Conformer with a new down-sampling schema. The proposed model, named Fast Conformer, is 2.8x faster than original Conformer, while preserving state-of-the-art accuracy on Automatic Speech Recognition benchmarks. Also we replace the original Conformer global attention with limited context attention post-training to enable transcription of an hour-long audio. We further improve long-form speech transcription by adding a global token. Fast Conformer combined with a Transformer decoder also outperforms the original Conformer in accuracy and in speed for Speech Translation and Spoken Language Understanding.
Recovering implicit pitch contours from formants in whispered speech
Jul 06, 2023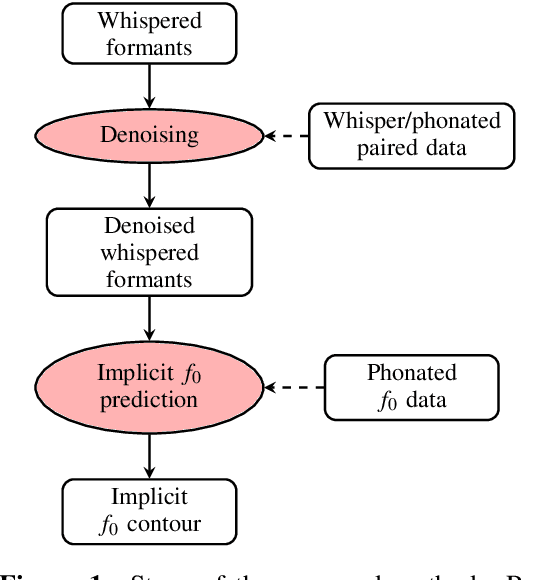
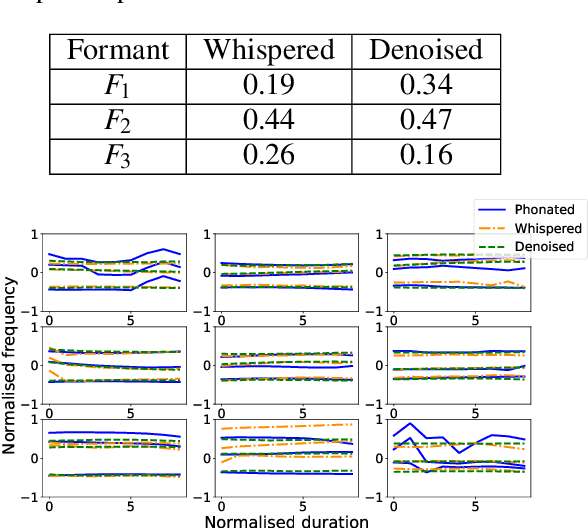
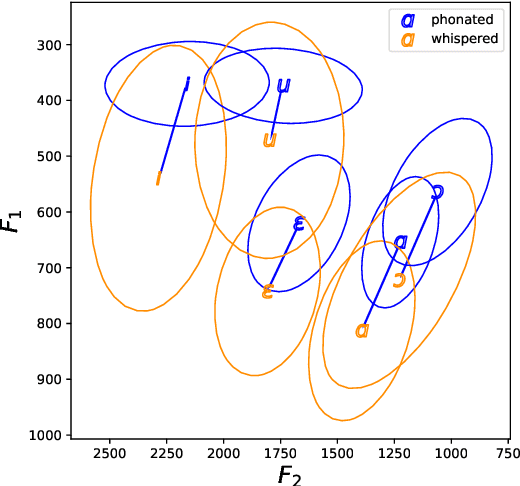
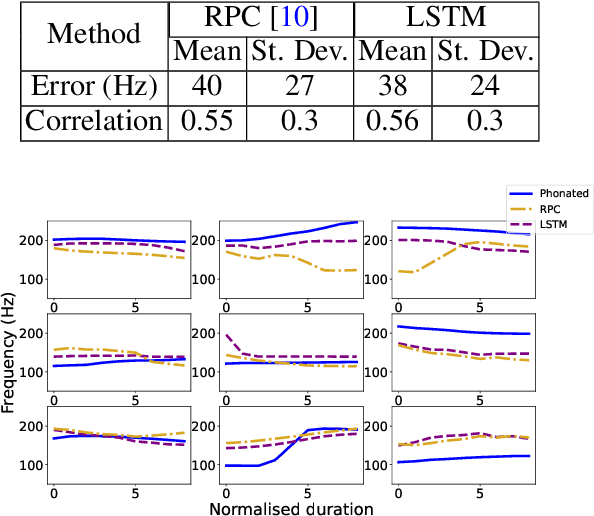
Whispered speech is characterised by a noise-like excitation that results in the lack of fundamental frequency. Considering that prosodic phenomena such as intonation are perceived through f0 variation, the perception of whispered prosody is relatively difficult. At the same time, studies have shown that speakers do attempt to produce intonation when whispering and that prosodic variability is being transmitted, suggesting that intonation "survives" in whispered formant structure. In this paper, we aim to estimate the way in which formant contours correlate with an "implicit" pitch contour in whisper, using a machine learning model. We propose a two-step method: using a parallel corpus, we first transform the whispered formants into their phonated equivalents using a denoising autoencoder. We then analyse the formant contours to predict phonated pitch contour variation. We observe that our method is effective in establishing a relationship between whispered and phonated formants and in uncovering implicit pitch contours in whisper.
Incorporating Class-based Language Model for Named Entity Recognition in Factorized Neural Transducer
Sep 14, 2023In spite of the excellent strides made by end-to-end (E2E) models in speech recognition in recent years, named entity recognition is still challenging but critical for semantic understanding. In order to enhance the ability to recognize named entities in E2E models, previous studies mainly focus on various rule-based or attention-based contextual biasing algorithms. However, their performance might be sensitive to the biasing weight or degraded by excessive attention to the named entity list, along with a risk of false triggering. Inspired by the success of the class-based language model (LM) in named entity recognition in conventional hybrid systems and the effective decoupling of acoustic and linguistic information in the factorized neural Transducer (FNT), we propose a novel E2E model to incorporate class-based LMs into FNT, which is referred as C-FNT. In C-FNT, the language model score of named entities can be associated with the name class instead of its surface form. The experimental results show that our proposed C-FNT presents significant error reduction in named entities without hurting performance in general word recognition.
OpenSR: Open-Modality Speech Recognition via Maintaining Multi-Modality Alignment
Jun 10, 2023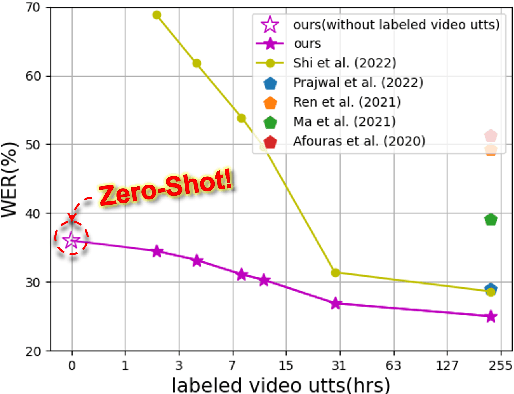
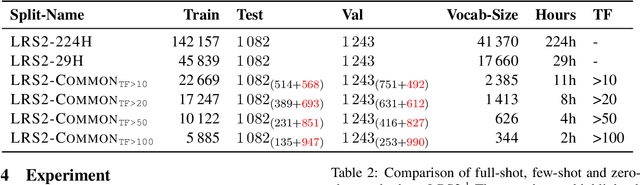
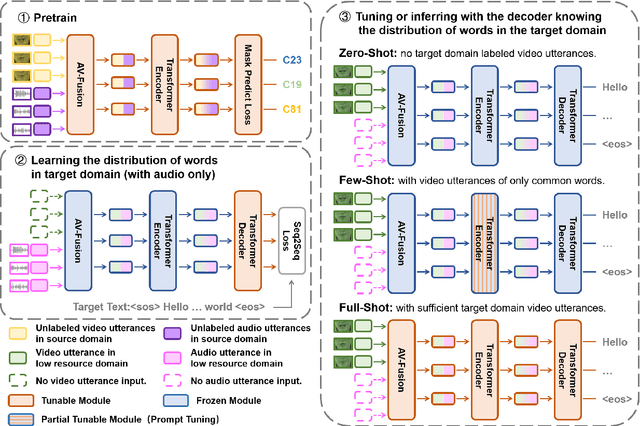
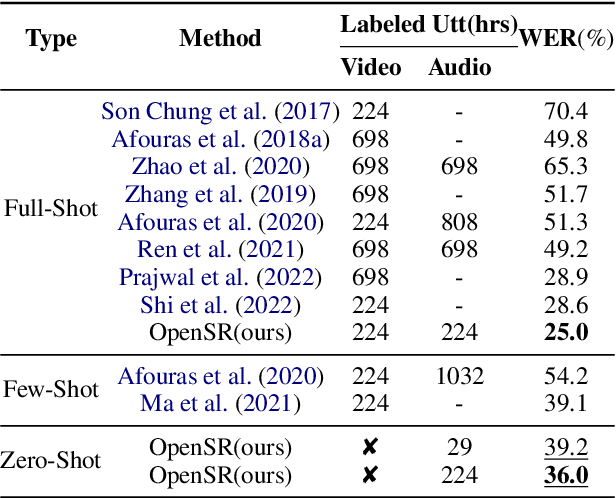
Speech Recognition builds a bridge between the multimedia streaming (audio-only, visual-only or audio-visual) and the corresponding text transcription. However, when training the specific model of new domain, it often gets stuck in the lack of new-domain utterances, especially the labeled visual utterances. To break through this restriction, we attempt to achieve zero-shot modality transfer by maintaining the multi-modality alignment in phoneme space learned with unlabeled multimedia utterances in the high resource domain during the pre-training \cite{shi2022learning}, and propose a training system Open-modality Speech Recognition (\textbf{OpenSR}) that enables the models trained on a single modality (e.g., audio-only) applicable to more modalities (e.g., visual-only and audio-visual). Furthermore, we employ a cluster-based prompt tuning strategy to handle the domain shift for the scenarios with only common words in the new domain utterances. We demonstrate that OpenSR enables modality transfer from one to any in three different settings (zero-, few- and full-shot), and achieves highly competitive zero-shot performance compared to the existing few-shot and full-shot lip-reading methods. To the best of our knowledge, OpenSR achieves the state-of-the-art performance of word error rate in LRS2 on audio-visual speech recognition and lip-reading with 2.7\% and 25.0\%, respectively. The code and demo are available at https://github.com/Exgc/OpenSR.
Better speech synthesis through scaling
May 12, 2023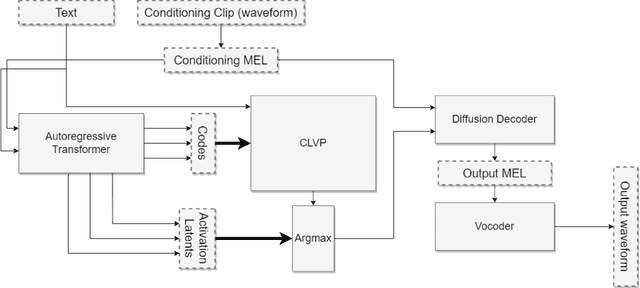

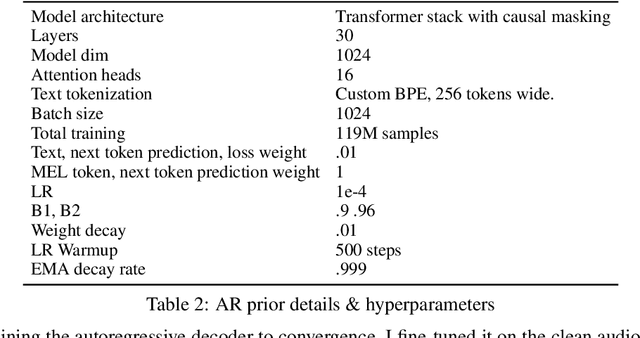
In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise -- an expressive, multi-voice text-to-speech system. All model code and trained weights have been open-sourced at https://github.com/neonbjb/tortoise-tts.
Improving Robustness of Neural Inverse Text Normalization via Data-Augmentation, Semi-Supervised Learning, and Post-Aligning Method
Sep 12, 2023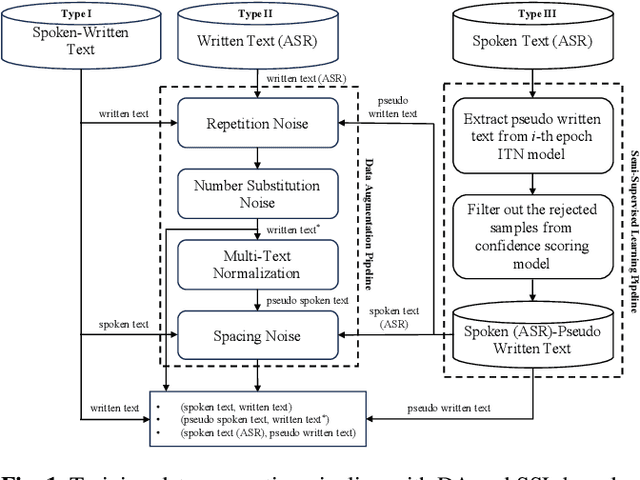
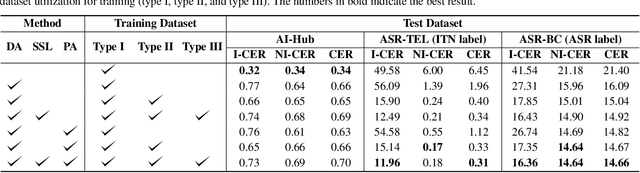
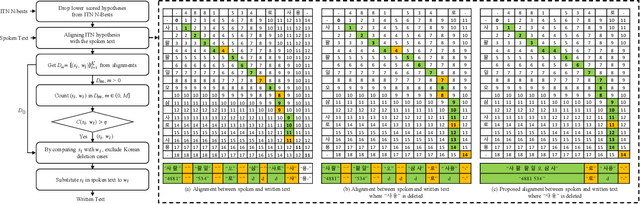
Inverse text normalization (ITN) is crucial for converting spoken-form into written-form, especially in the context of automatic speech recognition (ASR). While most downstream tasks of ASR rely on written-form, ASR systems often output spoken-form, highlighting the necessity for robust ITN in product-level ASR-based applications. Although neural ITN methods have shown promise, they still encounter performance challenges, particularly when dealing with ASR-generated spoken text. These challenges arise from the out-of-domain problem between training data and ASR-generated text. To address this, we propose a direct training approach that utilizes ASR-generated written or spoken text, with pairs augmented through ASR linguistic context emulation and a semi-supervised learning method enhanced by a large language model, respectively. Additionally, we introduce a post-aligning method to manage unpredictable errors, thereby enhancing the reliability of ITN. Our experiments show that our proposed methods remarkably improved ITN performance in various ASR scenarios.
Considerations for Ethical Speech Recognition Datasets
May 03, 2023Speech AI Technologies are largely trained on publicly available datasets or by the massive web-crawling of speech. In both cases, data acquisition focuses on minimizing collection effort, without necessarily taking the data subjects' protection or user needs into consideration. This results to models that are not robust when used on users who deviate from the dominant demographics in the training set, discriminating individuals having different dialects, accents, speaking styles, and disfluencies. In this talk, we use automatic speech recognition as a case study and examine the properties that ethical speech datasets should possess towards responsible AI applications. We showcase diversity issues, inclusion practices, and necessary considerations that can improve trained models, while facilitating model explainability and protecting users and data subjects. We argue for the legal & privacy protection of data subjects, targeted data sampling corresponding to user demographics & needs, appropriate meta data that ensure explainability & accountability in cases of model failure, and the sociotechnical \& situated model design. We hope this talk can inspire researchers \& practitioners to design and use more human-centric datasets in speech technologies and other domains, in ways that empower and respect users, while improving machine learning models' robustness and utility.