 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
GEmo-CLAP: Gender-Attribute-Enhanced Contrastive Language-Audio Pretraining for Speech Emotion Recognition
Jun 13, 2023
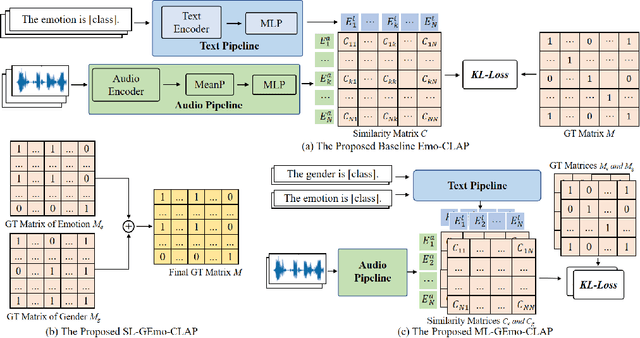
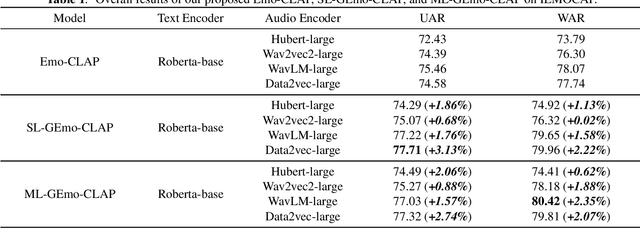
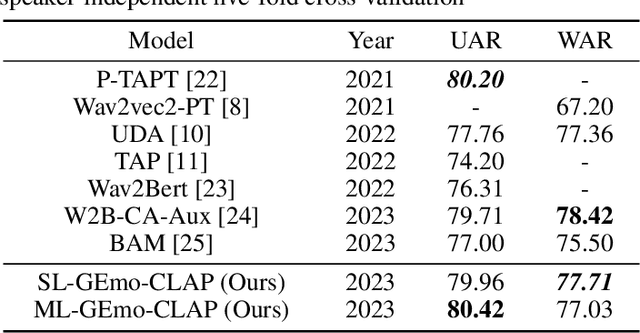
Contrastive Language-Audio Pretraining (CLAP) has recently exhibited impressive success in diverse fields. In this paper, we propose GEmo-CLAP, a kind of efficient gender-attribute-enhanced CLAP model for speech emotion recognition (SER). Specifically, we first build an effective emotion CLAP model termed Emo-CLAP for SER, utilizing various self-supervised learning based pre-trained models. Then, considering the importance of the gender attribute in speech emotion modeling, two GEmo-CLAP approaches are further proposed to integrate the emotion and gender information of speech signals, forming more reasonable objectives. Extensive experiments conducted on the IEMOCAP corpus demonstrate that our proposed two GEmo-CLAP approaches consistently outperform the baseline Emo-CLAP with different pre-trained models, while also achieving superior recognition performance compared with other state-of-the-art methods.
Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
Jun 06, 2023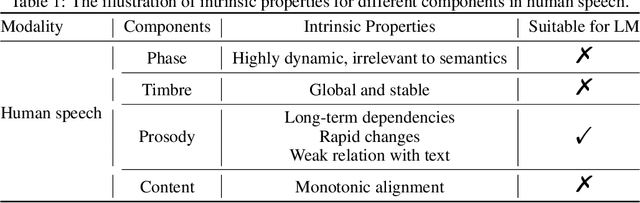
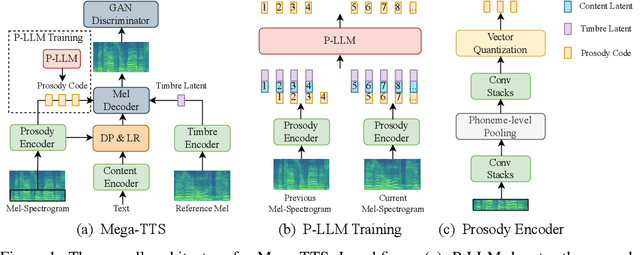
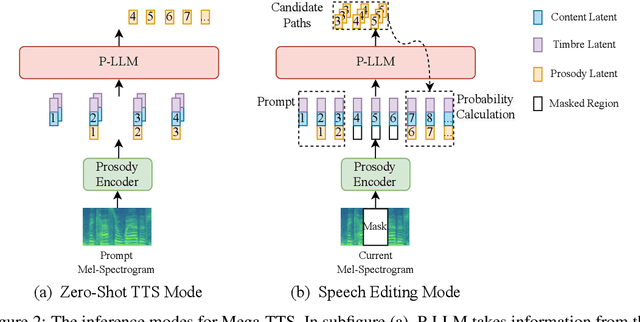
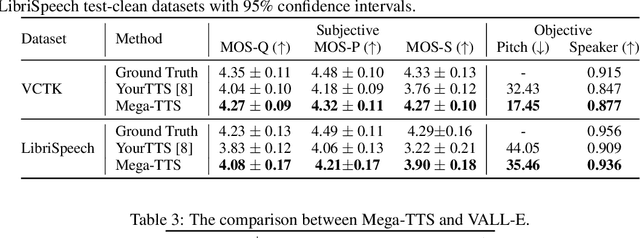
Scaling text-to-speech to a large and wild dataset has been proven to be highly effective in achieving timbre and speech style generalization, particularly in zero-shot TTS. However, previous works usually encode speech into latent using audio codec and use autoregressive language models or diffusion models to generate it, which ignores the intrinsic nature of speech and may lead to inferior or uncontrollable results. We argue that speech can be decomposed into several attributes (e.g., content, timbre, prosody, and phase) and each of them should be modeled using a module with appropriate inductive biases. From this perspective, we carefully design a novel and large zero-shot TTS system called Mega-TTS, which is trained with large-scale wild data and models different attributes in different ways: 1) Instead of using latent encoded by audio codec as the intermediate feature, we still choose spectrogram as it separates the phase and other attributes very well. Phase can be appropriately constructed by the GAN-based vocoder and does not need to be modeled by the language model. 2) We model the timbre using global vectors since timbre is a global attribute that changes slowly over time. 3) We further use a VQGAN-based acoustic model to generate the spectrogram and a latent code language model to fit the distribution of prosody, since prosody changes quickly over time in a sentence, and language models can capture both local and long-range dependencies. We scale Mega-TTS to multi-domain datasets with 20K hours of speech and evaluate its performance on unseen speakers. Experimental results demonstrate that Mega-TTS surpasses state-of-the-art TTS systems on zero-shot TTS, speech editing, and cross-lingual TTS tasks, with superior naturalness, robustness, and speaker similarity due to the proper inductive bias of each module. Audio samples are available at https://mega-tts.github.io/demo-page.
Diffusion-based Signal Refiner for Speech Separation
May 12, 2023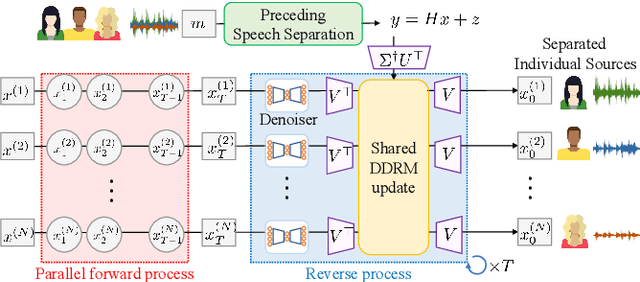
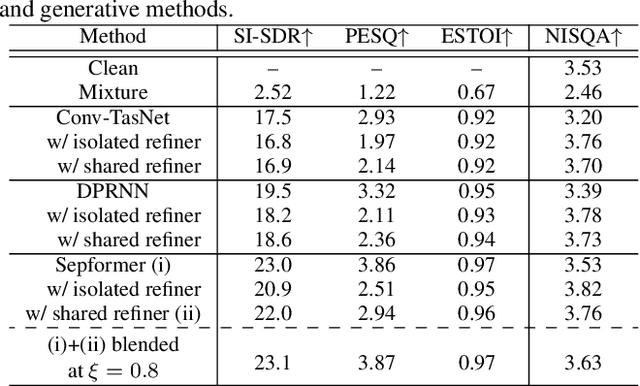
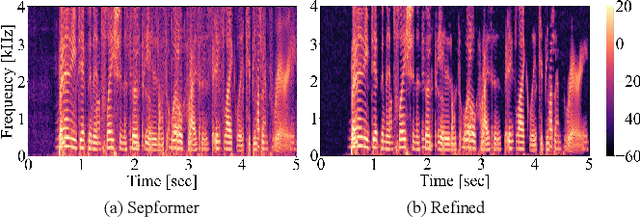
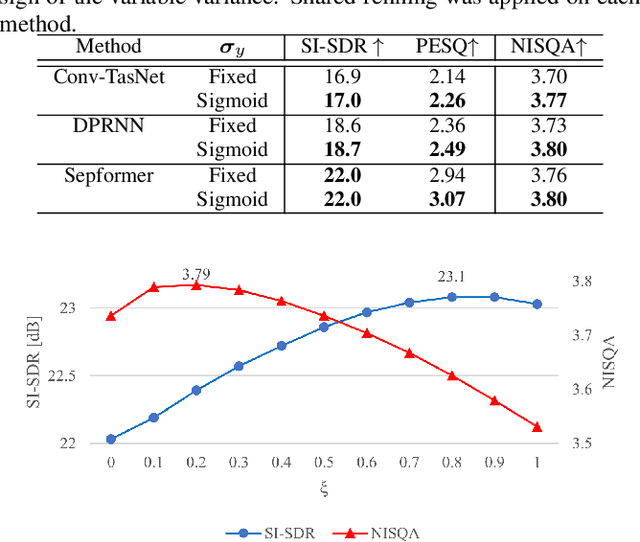
We have developed a diffusion-based speech refiner that improves the reference-free perceptual quality of the audio predicted by preceding single-channel speech separation models. Although modern deep neural network-based speech separation models have show high performance in reference-based metrics, they often produce perceptually unnatural artifacts. The recent advancements made to diffusion models motivated us to tackle this problem by restoring the degraded parts of initial separations with a generative approach. Utilizing the denoising diffusion restoration model (DDRM) as a basis, we propose a shared DDRM-based refiner that generates samples conditioned on the global information of preceding outputs from arbitrary speech separation models. We experimentally show that our refiner can provide a clearer harmonic structure of speech and improves the reference-free metric of perceptual quality for arbitrary preceding model architectures. Furthermore, we tune the variance of the measurement noise based on preceding outputs, which results in higher scores in both reference-free and reference-based metrics. The separation quality can also be further improved by blending the discriminative and generative outputs.
Inter-connection: Effective Connection between Pre-trained Encoder and Decoder for Speech Translation
May 26, 2023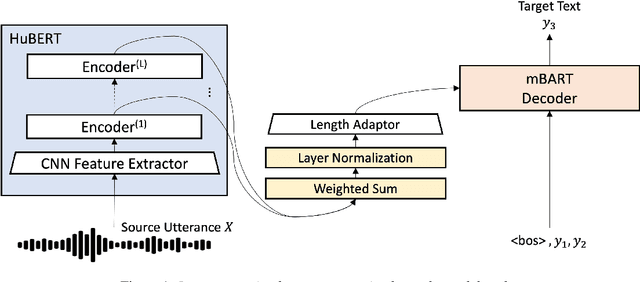
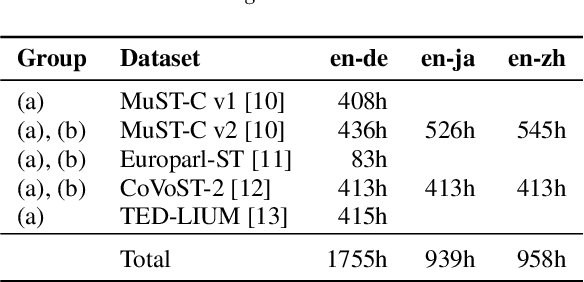
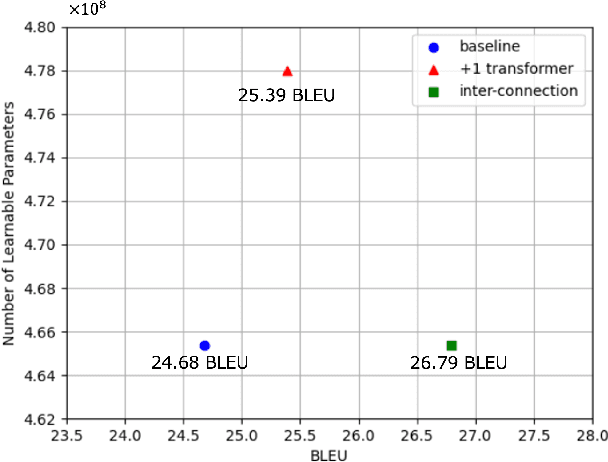

In end-to-end speech translation, speech and text pre-trained models improve translation quality. Recently proposed models simply connect the pre-trained models of speech and text as encoder and decoder. Therefore, only the information from the final layer of encoders is input to the decoder. Since it is clear that the speech pre-trained model outputs different information from each layer, the simple connection method cannot fully utilize the information that the speech pre-trained model has. In this study, we propose an inter-connection mechanism that aggregates the information from each layer of the speech pre-trained model by weighted sums and inputs into the decoder. This mechanism increased BLEU by approximately 2 points in en-de, en-ja, and en-zh by increasing parameters by 2K when the speech pre-trained model was frozen. Furthermore, we investigated the contribution of each layer for each language by visualizing layer weights and found that the contributions were different.
What do self-supervised speech models know about words?
Jun 30, 2023
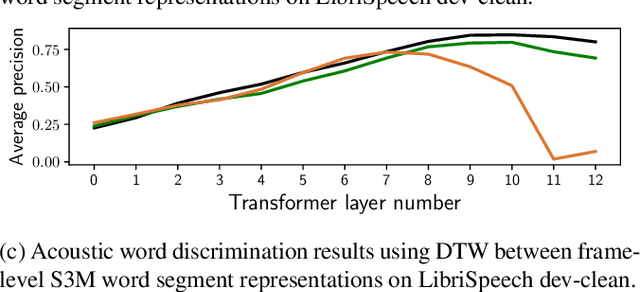

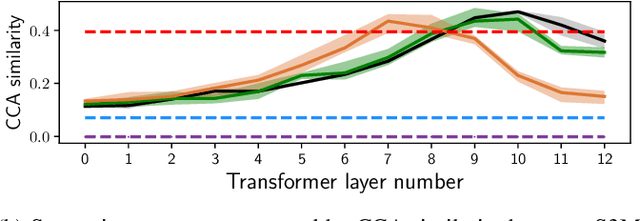
Many self-supervised speech models (S3Ms) have been introduced over the last few years, producing performance and data efficiency improvements for a variety of speech tasks. Evidence is emerging that different S3Ms encode linguistic information in different layers, and also that some S3Ms appear to learn phone-like sub-word units. However, the extent to which these models capture larger linguistic units, such as words, and where word-related information is encoded, remains unclear. In this study, we conduct several analyses of word segment representations extracted from different layers of three S3Ms: wav2vec2, HuBERT, and WavLM. We employ canonical correlation analysis (CCA), a lightweight analysis tool, to measure the similarity between these representations and word-level linguistic properties. We find that the maximal word-level linguistic content tends to be found in intermediate model layers, while some lower-level information like pronunciation is also retained in higher layers of HuBERT and WavLM. Syntactic and semantic word attributes have similar layer-wise behavior. We also find that, for all of the models tested, word identity information is concentrated near the center of each word segment. We then test the layer-wise performance of the same models, when used directly with no additional learned parameters, on several tasks: acoustic word discrimination, word segmentation, and semantic sentence similarity. We find similar layer-wise trends in performance, and furthermore, find that when using the best-performing layer of HuBERT or WavLM, it is possible to achieve performance on word segmentation and sentence similarity that rivals more complex existing approaches.
Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model
May 26, 2023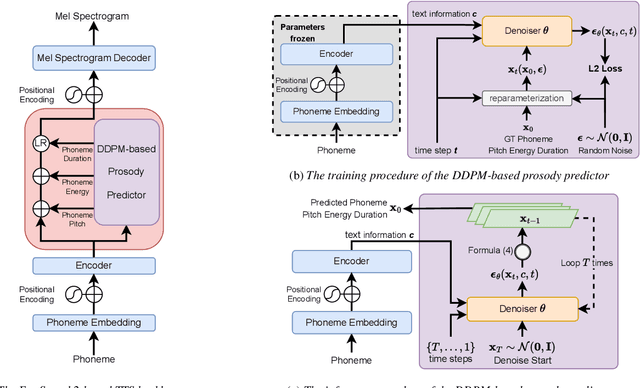
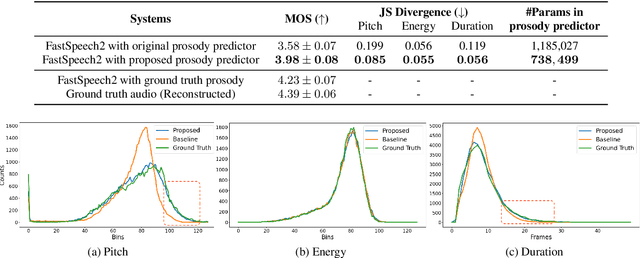
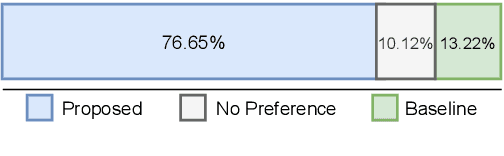
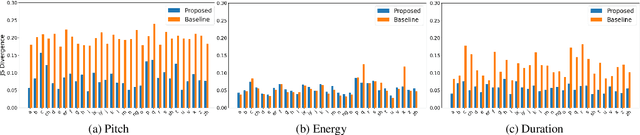
Expressive human speech generally abounds with rich and flexible speech prosody variations. The speech prosody predictors in existing expressive speech synthesis methods mostly produce deterministic predictions, which are learned by directly minimizing the norm of prosody prediction error. Its unimodal nature leads to a mismatch with ground truth distribution and harms the model's ability in making diverse predictions. Thus, we propose a novel prosody predictor based on the denoising diffusion probabilistic model to take advantage of its high-quality generative modeling and training stability. Experiment results confirm that the proposed prosody predictor outperforms the deterministic baseline on both the expressiveness and diversity of prediction results with even fewer network parameters.
SPEECH: Structured Prediction with Energy-Based Event-Centric Hyperspheres
May 23, 2023
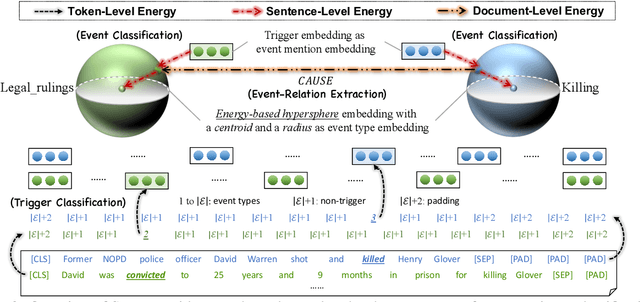
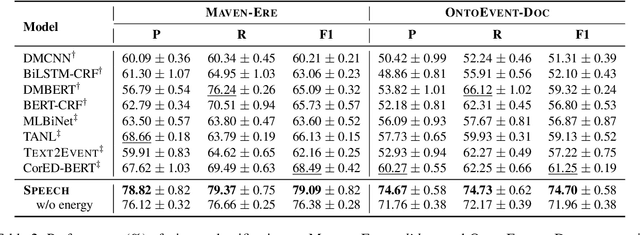
Event-centric structured prediction involves predicting structured outputs of events. In most NLP cases, event structures are complex with manifold dependency, and it is challenging to effectively represent these complicated structured events. To address these issues, we propose Structured Prediction with Energy-based Event-Centric Hyperspheres (SPEECH). SPEECH models complex dependency among event structured components with energy-based modeling, and represents event classes with simple but effective hyperspheres. Experiments on two unified-annotated event datasets indicate that SPEECH is predominant in event detection and event-relation extraction tasks.
DEPAC: a Corpus for Depression and Anxiety Detection from Speech
Jun 20, 2023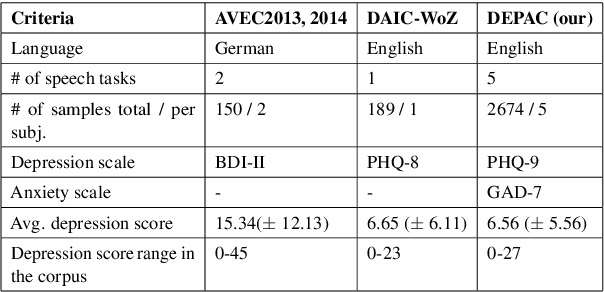

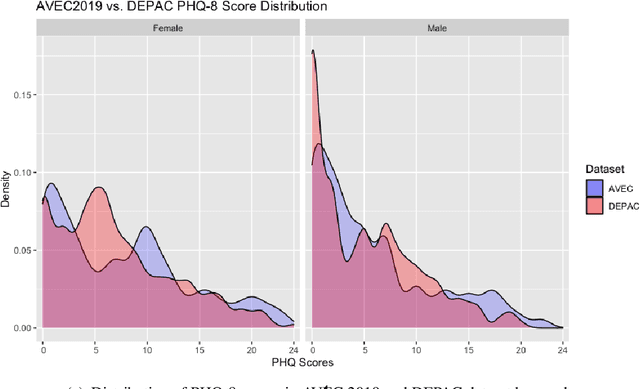
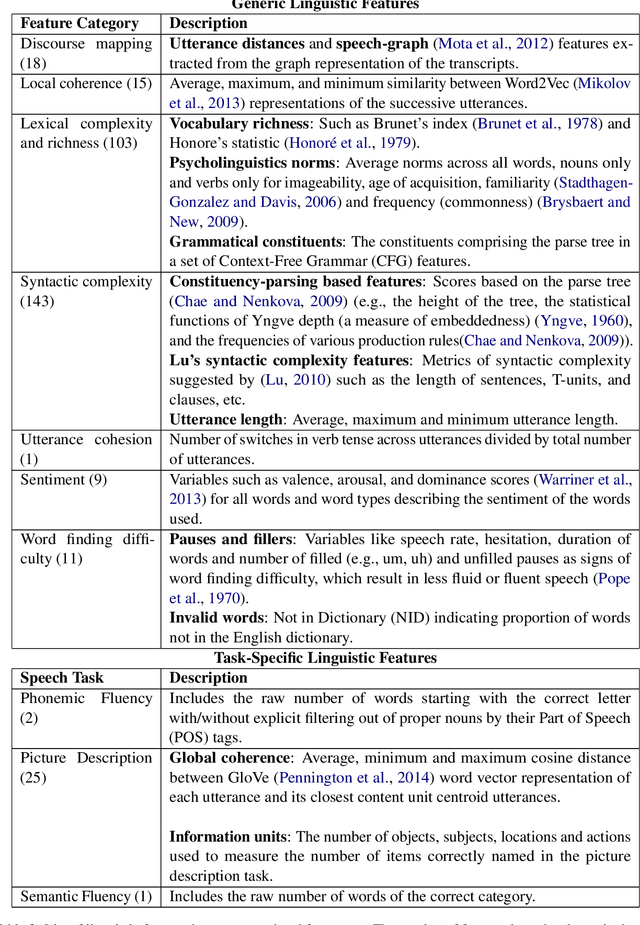
Mental distress like depression and anxiety contribute to the largest proportion of the global burden of diseases. Automated diagnosis systems of such disorders, empowered by recent innovations in Artificial Intelligence, can pave the way to reduce the sufferings of the affected individuals. Development of such systems requires information-rich and balanced corpora. In this work, we introduce a novel mental distress analysis audio dataset DEPAC, labeled based on established thresholds on depression and anxiety standard screening tools. This large dataset comprises multiple speech tasks per individual, as well as relevant demographic information. Alongside, we present a feature set consisting of hand-curated acoustic and linguistic features, which were found effective in identifying signs of mental illnesses in human speech. Finally, we justify the quality and effectiveness of our proposed audio corpus and feature set in predicting depression severity by comparing the performance of baseline machine learning models built on this dataset with baseline models trained on other well-known depression corpora.
Rule By Example: Harnessing Logical Rules for Explainable Hate Speech Detection
Jul 24, 2023Classic approaches to content moderation typically apply a rule-based heuristic approach to flag content. While rules are easily customizable and intuitive for humans to interpret, they are inherently fragile and lack the flexibility or robustness needed to moderate the vast amount of undesirable content found online today. Recent advances in deep learning have demonstrated the promise of using highly effective deep neural models to overcome these challenges. However, despite the improved performance, these data-driven models lack transparency and explainability, often leading to mistrust from everyday users and a lack of adoption by many platforms. In this paper, we present Rule By Example (RBE): a novel exemplar-based contrastive learning approach for learning from logical rules for the task of textual content moderation. RBE is capable of providing rule-grounded predictions, allowing for more explainable and customizable predictions compared to typical deep learning-based approaches. We demonstrate that our approach is capable of learning rich rule embedding representations using only a few data examples. Experimental results on 3 popular hate speech classification datasets show that RBE is able to outperform state-of-the-art deep learning classifiers as well as the use of rules in both supervised and unsupervised settings while providing explainable model predictions via rule-grounding.
Improving Speech Translation Accuracy and Time Efficiency with Fine-tuned wav2vec 2.0-based Speech Segmentation
Apr 25, 2023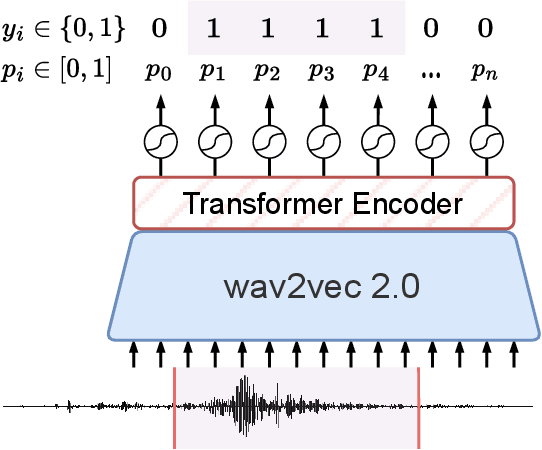
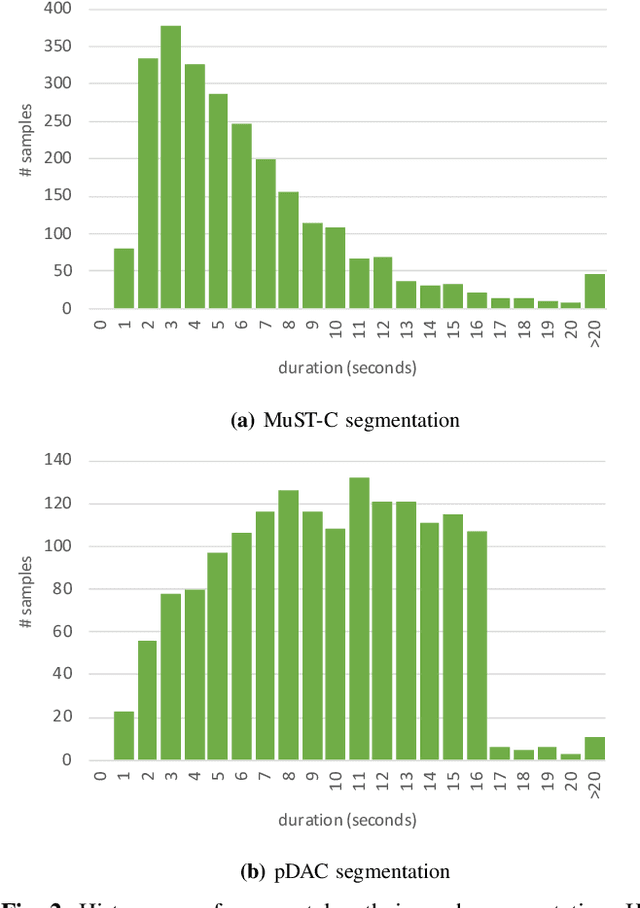
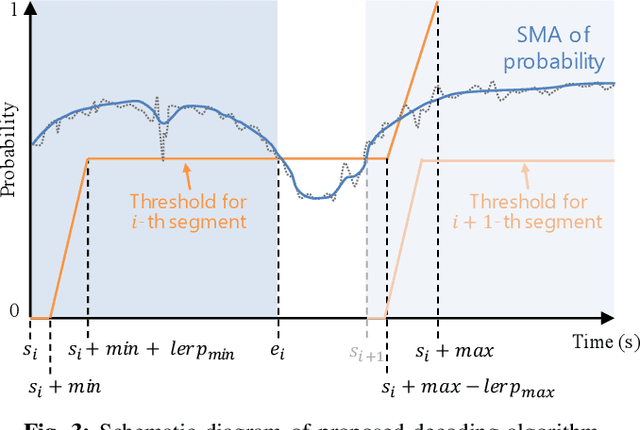
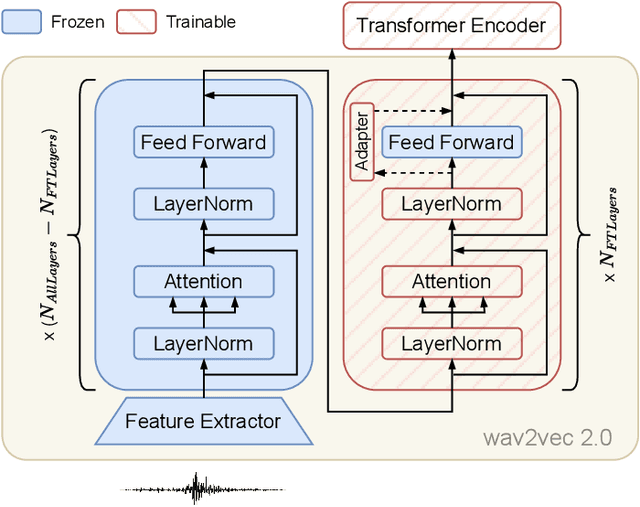
Speech translation (ST) automatically converts utterances in a source language into text in another language. Splitting continuous speech into shorter segments, known as speech segmentation, plays an important role in ST. Recent segmentation methods trained to mimic the segmentation of ST corpora have surpassed traditional approaches. Tsiamas et al. proposed a segmentation frame classifier (SFC) based on a pre-trained speech encoder called wav2vec 2.0. Their method, named SHAS, retains 95-98% of the BLEU score for ST corpus segmentation. However, the segments generated by SHAS are very different from ST corpus segmentation and tend to be longer with multiple combined utterances. This is due to SHAS's reliance on length heuristics, i.e., it splits speech into segments of easily translatable length without fully considering the potential for ST improvement by splitting them into even shorter segments. Longer segments often degrade translation quality and ST's time efficiency. In this study, we extended SHAS to improve ST translation accuracy and efficiency by splitting speech into shorter segments that correspond to sentences. We introduced a simple segmentation algorithm using the moving average of SFC predictions without relying on length heuristics and explored wav2vec 2.0 fine-tuning for improved speech segmentation prediction. Our experimental results reveal that our speech segmentation method significantly improved the quality and the time efficiency of speech translation compared to SHAS.