 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
Sep 14, 2023

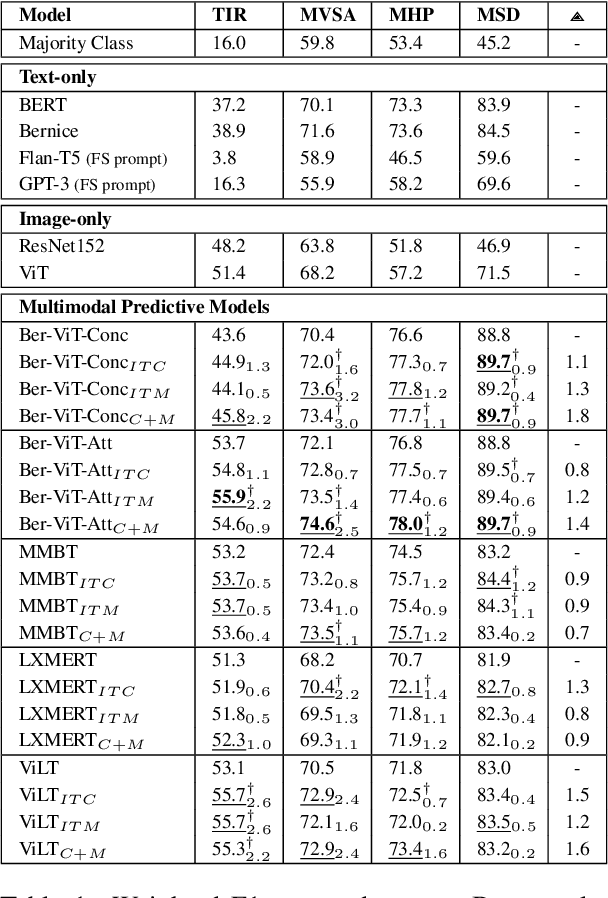
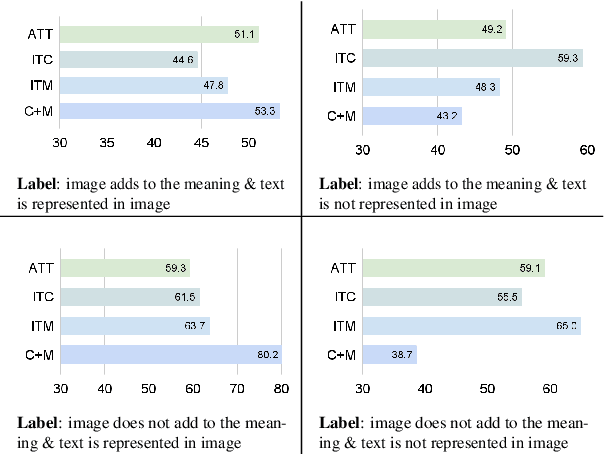

Effectively leveraging multimodal information from social media posts is essential to various downstream tasks such as sentiment analysis, sarcasm detection and hate speech classification. However, combining text and image information is challenging because of the idiosyncratic cross-modal semantics with hidden or complementary information present in matching image-text pairs. In this work, we aim to directly model this by proposing the use of two auxiliary losses jointly with the main task when fine-tuning any pre-trained multimodal model. Image-Text Contrastive (ITC) brings image-text representations of a post closer together and separates them from different posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates the understanding of semantic correspondence between images and text by penalizing unrelated pairs. We combine these objectives with five multimodal models, demonstrating consistent improvements across four popular social media datasets. Furthermore, through detailed analysis, we shed light on the specific scenarios and cases where each auxiliary task proves to be most effective.
Two-stage Autoencoder Neural Network for 3D Speech Enhancement
Jun 08, 2023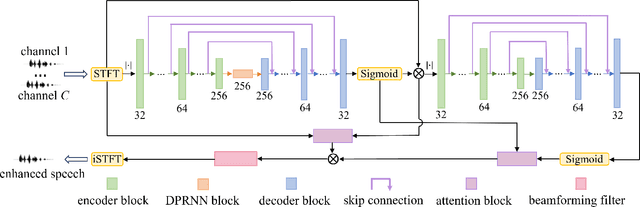
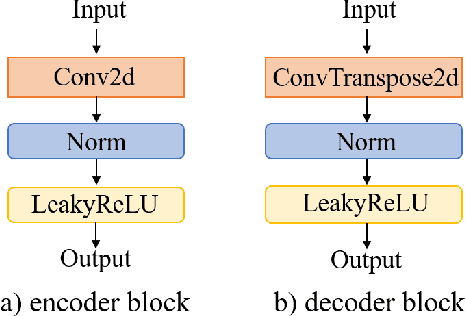
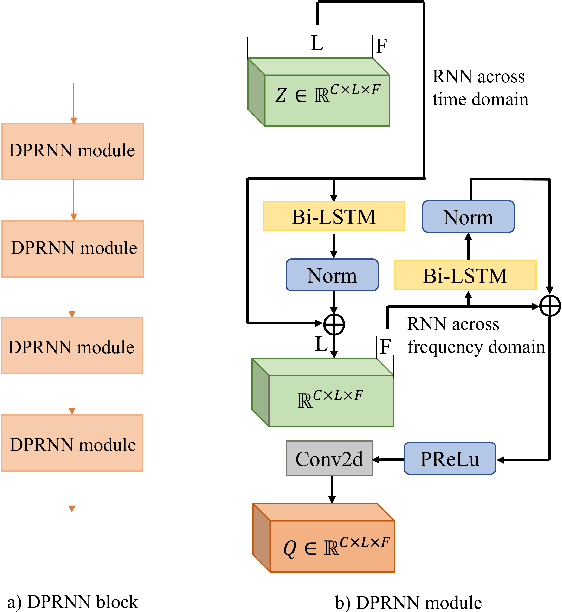
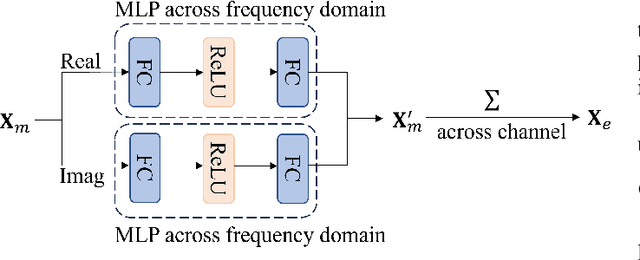
3D speech enhancement has attracted much attention in recent years with the development of augmented reality technology. Traditional denoising convolutional autoencoders have limitations in extracting dynamic voice information. In this paper, we propose a two-stage autoencoder neural network for 3D speech enhancement. We incorporate a dual-path recurrent neural network block into the convolutional autoencoder to iteratively apply time-domain and frequency-domain modeling in an alternate fashion. And an attention mechanism for fusing the high-dimension features is proposed. We also introduce a loss function to simultaneously optimize the network in the time-frequency and time domains. Experimental results show that our system outperforms the state-of-the-art systems on the dataset of ICASSP L3DAS23 challenge.
Text Generation with Speech Synthesis for ASR Data Augmentation
May 22, 2023
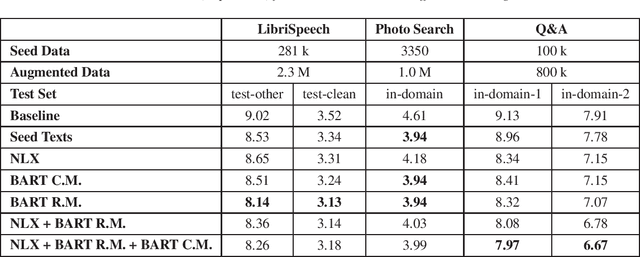
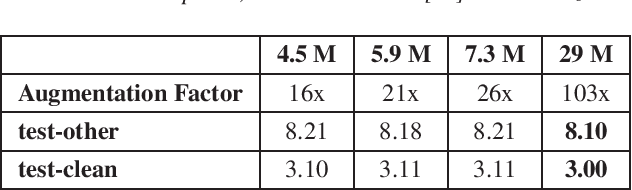
Aiming at reducing the reliance on expensive human annotations, data synthesis for Automatic Speech Recognition (ASR) has remained an active area of research. While prior work mainly focuses on synthetic speech generation for ASR data augmentation, its combination with text generation methods is considerably less explored. In this work, we explore text augmentation for ASR using large-scale pre-trained neural networks, and systematically compare those to traditional text augmentation methods. The generated synthetic texts are then converted to synthetic speech using a text-to-speech (TTS) system and added to the ASR training data. In experiments conducted on three datasets, we find that neural models achieve 9%-15% relative WER improvement and outperform traditional methods. We conclude that text augmentation, particularly through modern neural approaches, is a viable tool for improving the accuracy of ASR systems.
Creating Personalized Synthetic Voices from Post-Glossectomy Speech with Guided Diffusion Models
May 27, 2023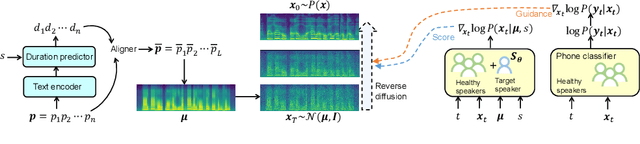
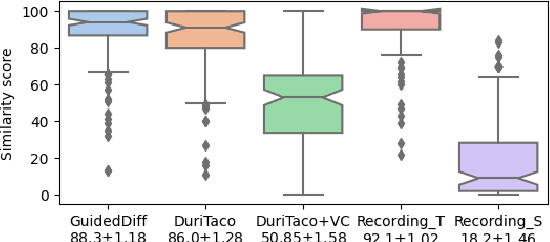
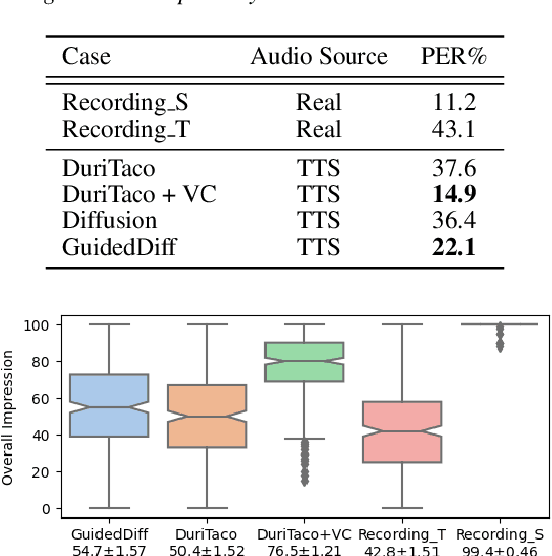
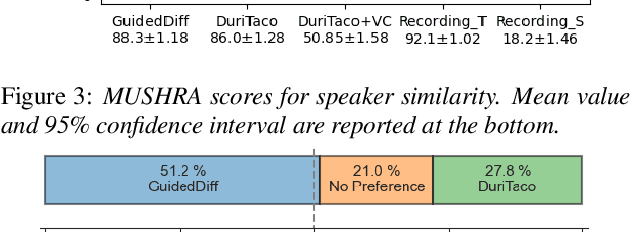
This paper is about developing personalized speech synthesis systems with recordings of mildly impaired speech. In particular, we consider consonant and vowel alterations resulted from partial glossectomy, the surgical removal of part of the tongue. The aim is to restore articulation in the synthesized speech and maximally preserve the target speaker's individuality. We propose to tackle the problem with guided diffusion models. Specifically, a diffusion-based speech synthesis model is trained on original recordings, to capture and preserve the target speaker's original articulation style. When using the model for inference, a separately trained phone classifier will guide the synthesis process towards proper articulation. Objective and subjective evaluation results show that the proposed method substantially improves articulation in the synthesized speech over original recordings, and preserves more of the target speaker's individuality than a voice conversion baseline.
Improving Speech Translation Accuracy and Time Efficiency with Fine-tuned wav2vec 2.0-based Speech Segmentation
Apr 25, 2023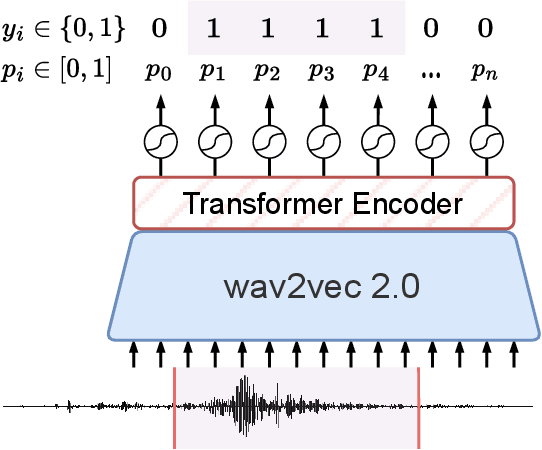
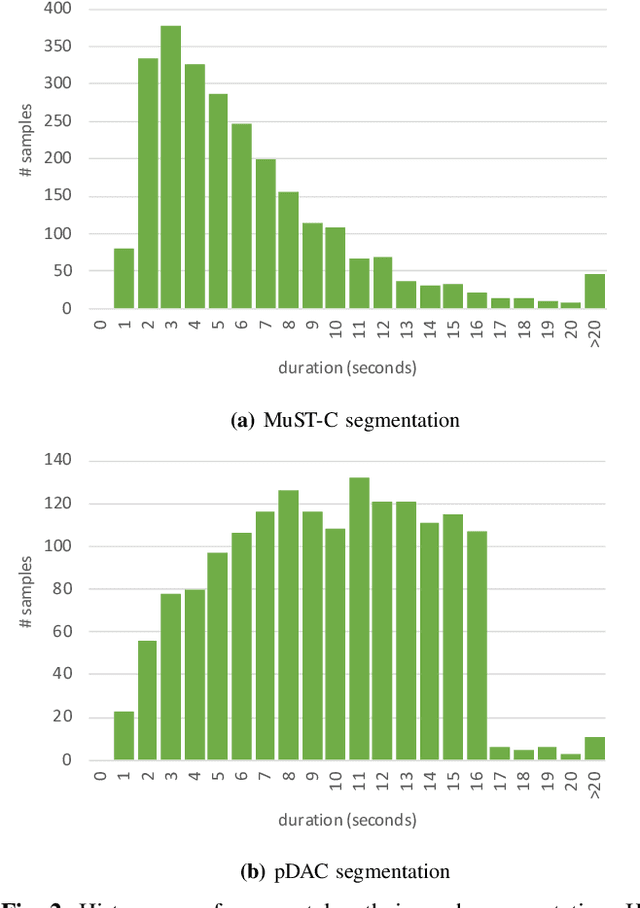
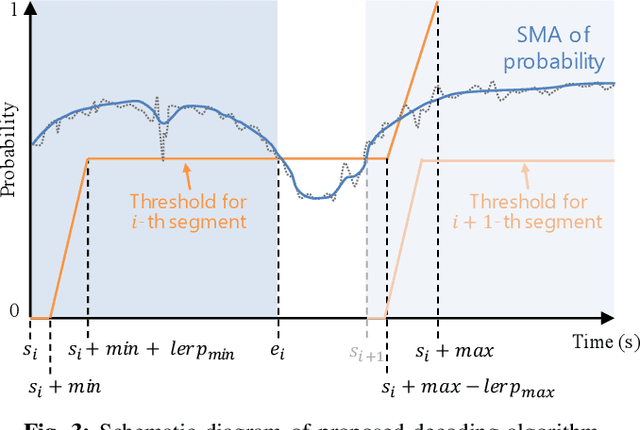
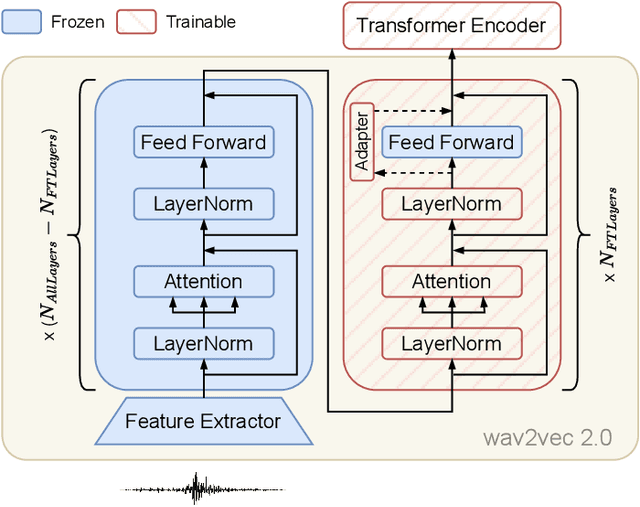
Speech translation (ST) automatically converts utterances in a source language into text in another language. Splitting continuous speech into shorter segments, known as speech segmentation, plays an important role in ST. Recent segmentation methods trained to mimic the segmentation of ST corpora have surpassed traditional approaches. Tsiamas et al. proposed a segmentation frame classifier (SFC) based on a pre-trained speech encoder called wav2vec 2.0. Their method, named SHAS, retains 95-98% of the BLEU score for ST corpus segmentation. However, the segments generated by SHAS are very different from ST corpus segmentation and tend to be longer with multiple combined utterances. This is due to SHAS's reliance on length heuristics, i.e., it splits speech into segments of easily translatable length without fully considering the potential for ST improvement by splitting them into even shorter segments. Longer segments often degrade translation quality and ST's time efficiency. In this study, we extended SHAS to improve ST translation accuracy and efficiency by splitting speech into shorter segments that correspond to sentences. We introduced a simple segmentation algorithm using the moving average of SFC predictions without relying on length heuristics and explored wav2vec 2.0 fine-tuning for improved speech segmentation prediction. Our experimental results reveal that our speech segmentation method significantly improved the quality and the time efficiency of speech translation compared to SHAS.
N-Shot Benchmarking of Whisper on Diverse Arabic Speech Recognition
Jun 05, 2023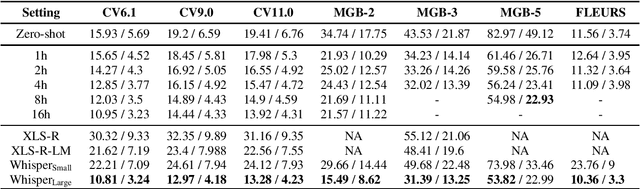
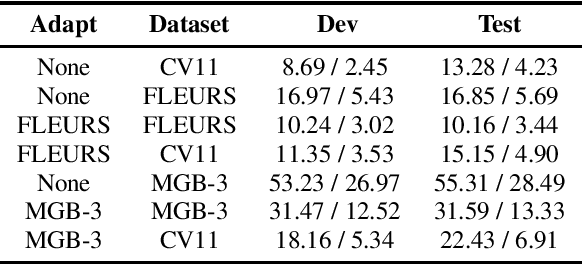
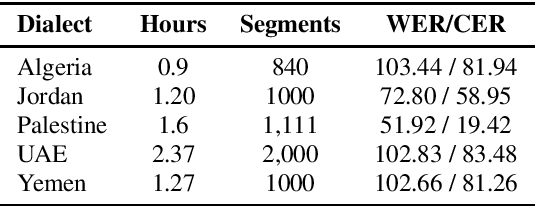
Whisper, the recently developed multilingual weakly supervised model, is reported to perform well on multiple speech recognition benchmarks in both monolingual and multilingual settings. However, it is not clear how Whisper would fare under diverse conditions even on languages it was evaluated on such as Arabic. In this work, we address this gap by comprehensively evaluating Whisper on several varieties of Arabic speech for the ASR task. Our evaluation covers most publicly available Arabic speech data and is performed under n-shot (zero-, few-, and full) finetuning. We also investigate the robustness of Whisper under completely novel conditions, such as in dialect-accented standard Arabic and in unseen dialects for which we develop evaluation data. Our experiments show that although Whisper zero-shot outperforms fully finetuned XLS-R models on all datasets, its performance deteriorates significantly in the zero-shot setting for five unseen dialects (i.e., Algeria, Jordan, Palestine, UAE, and Yemen).
FunASR: A Fundamental End-to-End Speech Recognition Toolkit
May 18, 2023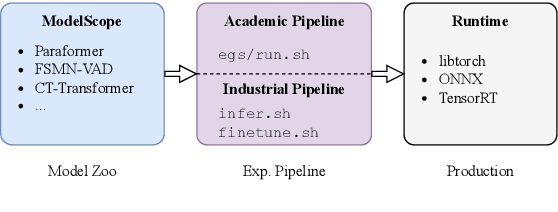

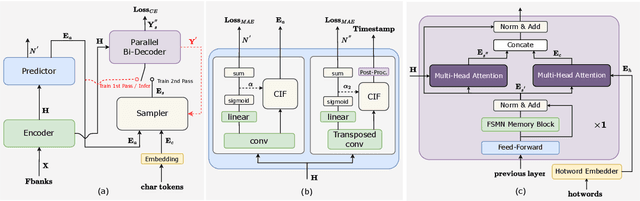
This paper introduces FunASR, an open-source speech recognition toolkit designed to bridge the gap between academic research and industrial applications. FunASR offers models trained on large-scale industrial corpora and the ability to deploy them in applications. The toolkit's flagship model, Paraformer, is a non-autoregressive end-to-end speech recognition model that has been trained on a manually annotated Mandarin speech recognition dataset that contains 60,000 hours of speech. To improve the performance of Paraformer, we have added timestamp prediction and hotword customization capabilities to the standard Paraformer backbone. In addition, to facilitate model deployment, we have open-sourced a voice activity detection model based on the Feedforward Sequential Memory Network (FSMN-VAD) and a text post-processing punctuation model based on the controllable time-delay Transformer (CT-Transformer), both of which were trained on industrial corpora. These functional modules provide a solid foundation for building high-precision long audio speech recognition services. Compared to other models trained on open datasets, Paraformer demonstrates superior performance.
Multiple Representation Transfer from Large Language Models to End-to-End ASR Systems
Sep 07, 2023Transferring the knowledge of large language models (LLMs) is a promising technique to incorporate linguistic knowledge into end-to-end automatic speech recognition (ASR) systems. However, existing works only transfer a single representation of LLM (e.g. the last layer of pretrained BERT), while the representation of a text is inherently non-unique and can be obtained variously from different layers, contexts and models. In this work, we explore a wide range of techniques to obtain and transfer multiple representations of LLMs into a transducer-based ASR system. While being conceptually simple, we show that transferring multiple representations of LLMs can be an effective alternative to transferring only a single representation.
Cross-Language Speech Emotion Recognition Using Multimodal Dual Attention Transformers
Jul 14, 2023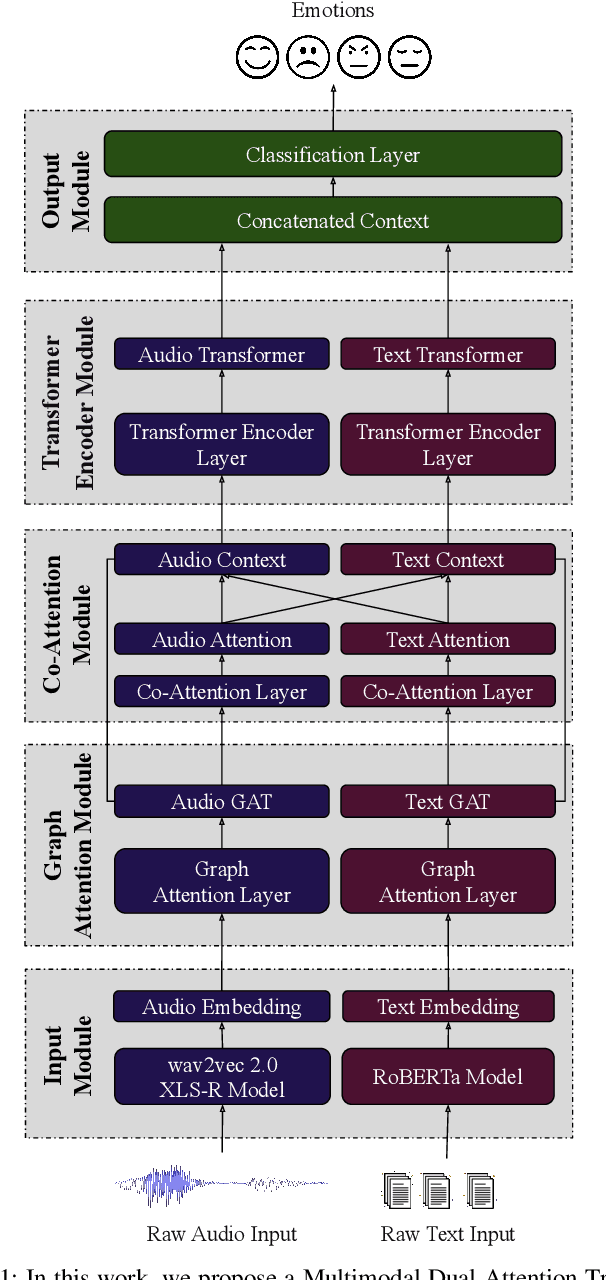
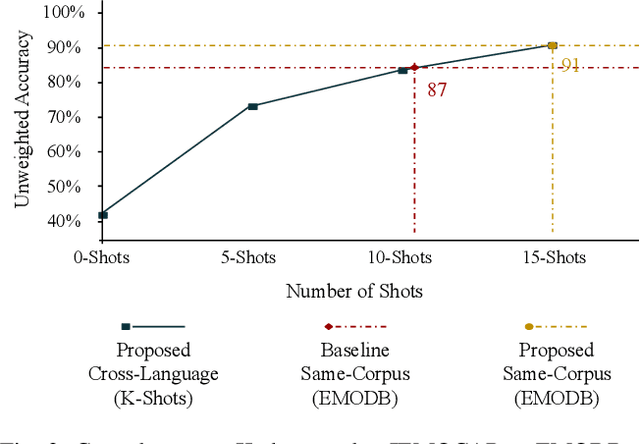
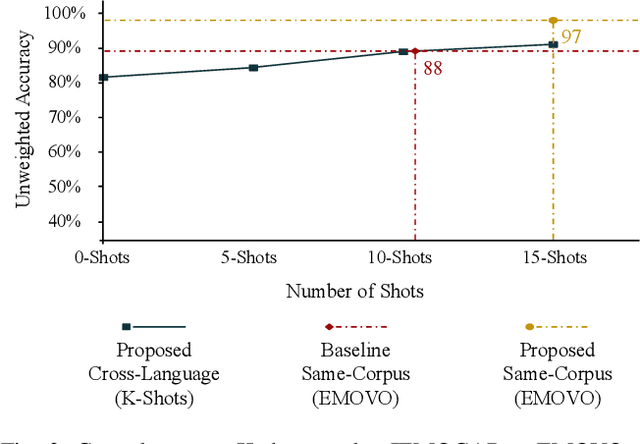
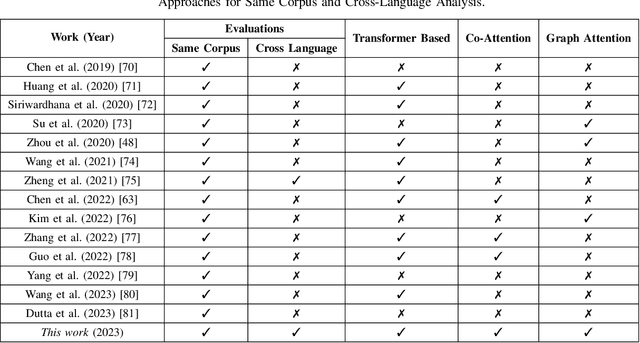
Despite the recent progress in speech emotion recognition (SER), state-of-the-art systems are unable to achieve improved performance in cross-language settings. In this paper, we propose a Multimodal Dual Attention Transformer (MDAT) model to improve cross-language SER. Our model utilises pre-trained models for multimodal feature extraction and is equipped with a dual attention mechanism including graph attention and co-attention to capture complex dependencies across different modalities and achieve improved cross-language SER results using minimal target language data. In addition, our model also exploits a transformer encoder layer for high-level feature representation to improve emotion classification accuracy. In this way, MDAT performs refinement of feature representation at various stages and provides emotional salient features to the classification layer. This novel approach also ensures the preservation of modality-specific emotional information while enhancing cross-modality and cross-language interactions. We assess our model's performance on four publicly available SER datasets and establish its superior effectiveness compared to recent approaches and baseline models.
DUB: Discrete Unit Back-translation for Speech Translation
May 19, 2023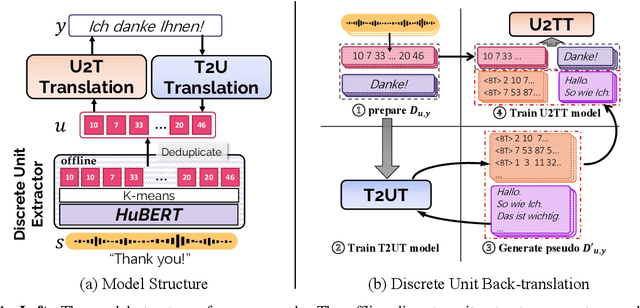

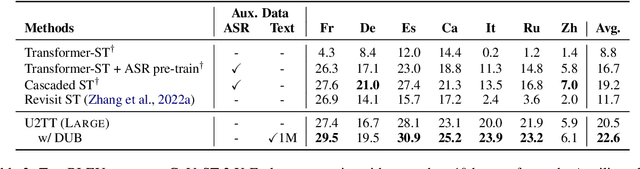
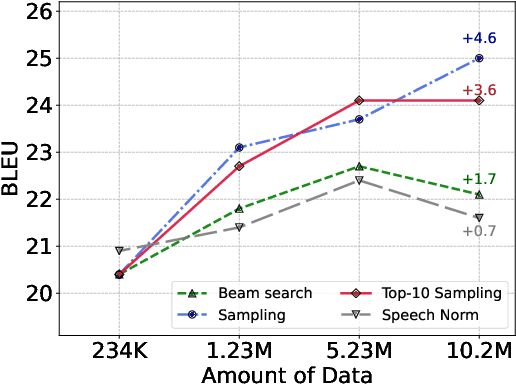
How can speech-to-text translation (ST) perform as well as machine translation (MT)? The key point is to bridge the modality gap between speech and text so that useful MT techniques can be applied to ST. Recently, the approach of representing speech with unsupervised discrete units yields a new way to ease the modality problem. This motivates us to propose Discrete Unit Back-translation (DUB) to answer two questions: (1) Is it better to represent speech with discrete units than with continuous features in direct ST? (2) How much benefit can useful MT techniques bring to ST? With DUB, the back-translation technique can successfully be applied on direct ST and obtains an average boost of 5.5 BLEU on MuST-C En-De/Fr/Es. In the low-resource language scenario, our method achieves comparable performance to existing methods that rely on large-scale external data. Code and models are available at https://github.com/0nutation/DUB.