 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Modified Parametric Multichannel Wiener Filter \\for Low-latency Enhancement of Speech Mixtures with Unknown Number of Speakers
Jun 29, 2023
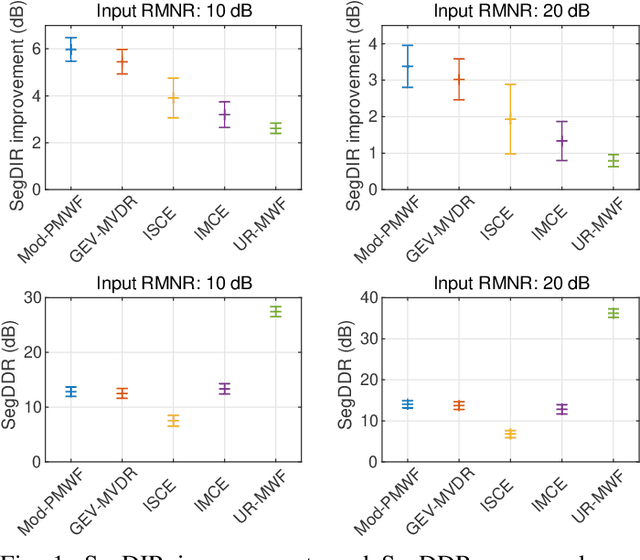
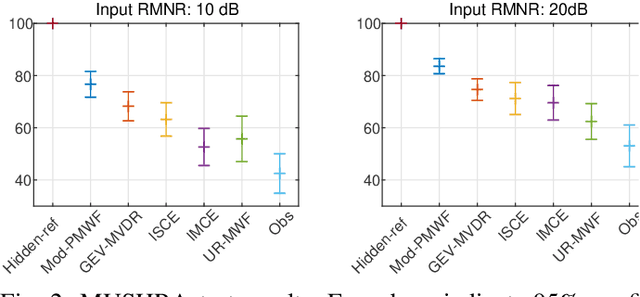
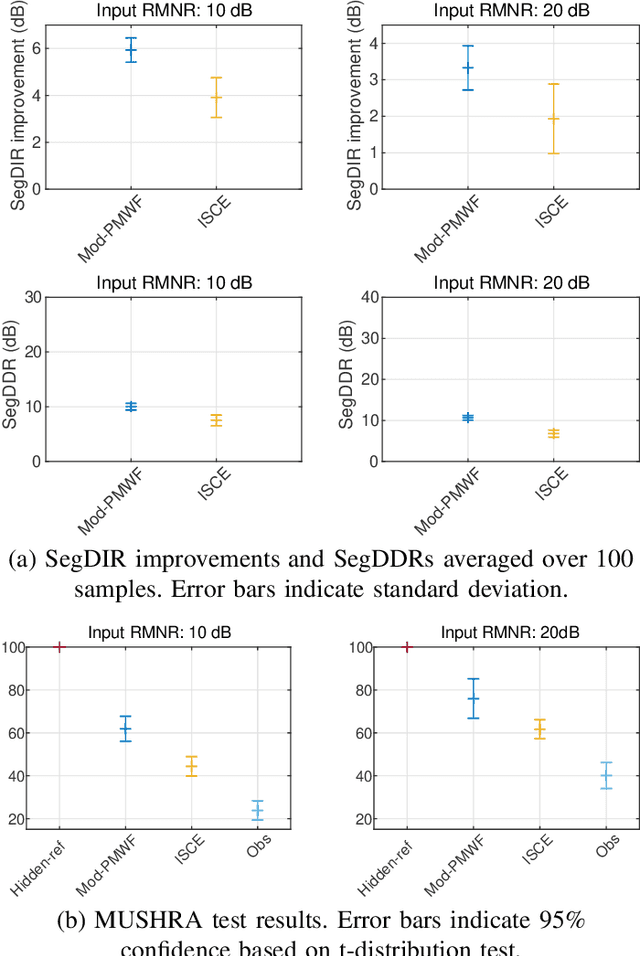
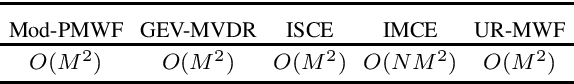
This paper introduces a novel low-latency online beamforming (BF) algorithm, named Modified Parametric Multichannel Wiener Filter (Mod-PMWF), for enhancing speech mixtures with unknown and varying number of speakers. Although conventional BFs such as linearly constrained minimum variance BF (LCMV BF) can enhance a speech mixture, they typically require such attributes of the speech mixture as the number of speakers and the acoustic transfer functions (ATFs) from the speakers to the microphones. When the mixture attributes are unavailable, estimating them by low-latency processing is challenging, hindering the application of the BFs to the problem. In this paper, we overcome this problem by modifying a conventional Parametric Multichannel Wiener Filter (PMWF). The proposed Mod-PMWF can adaptively form a directivity pattern that enhances all the speakers in the mixture without explicitly estimating these attributes. Our experiments will show the proposed BF's effectiveness in interference reduction ratios and subjective listening tests.
CiwaGAN: Articulatory information exchange
Sep 14, 2023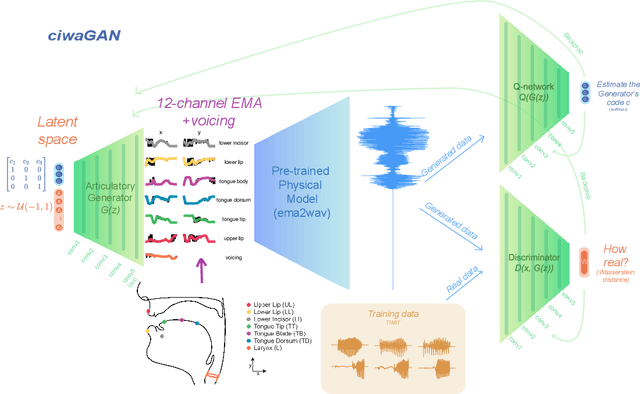

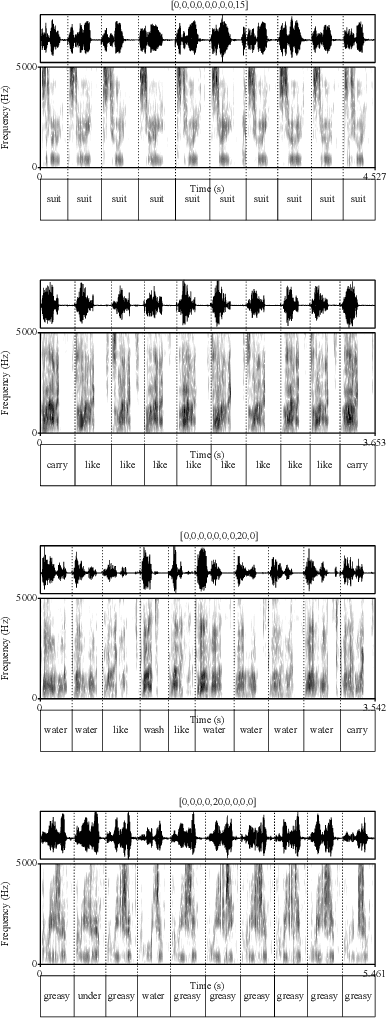

Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
How to Estimate Model Transferability of Pre-Trained Speech Models?
Jun 01, 2023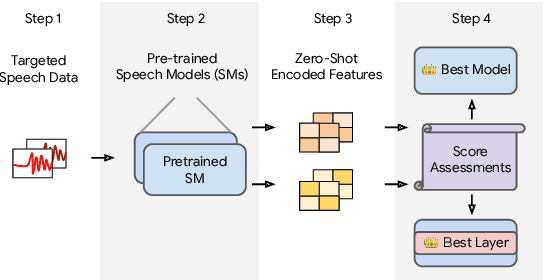
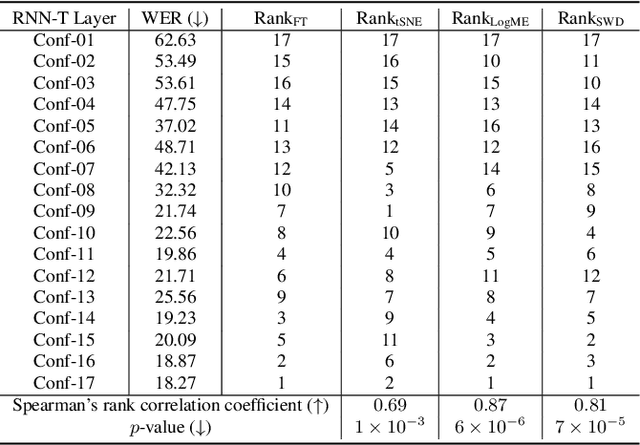
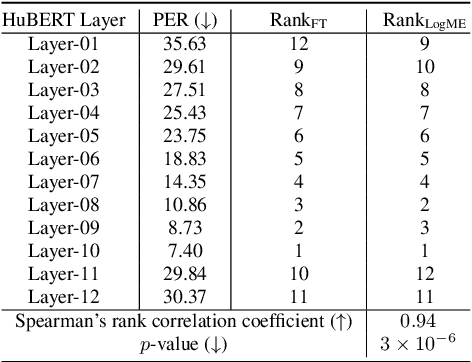
In this work, we introduce a ``score-based assessment'' framework for estimating the transferability of pre-trained speech models (PSMs) for fine-tuning target tasks. We leverage upon two representation theories, Bayesian likelihood estimation and optimal transport, to generate rank scores for the PSM candidates using the extracted representations. Our framework efficiently computes transferability scores without actual fine-tuning of candidate models or layers by making a temporal independent hypothesis. We evaluate some popular supervised speech models (e.g., Conformer RNN-Transducer) and self-supervised speech models (e.g., HuBERT) in cross-layer and cross-model settings using public data. Experimental results show a high Spearman's rank correlation and low $p$-value between our estimation framework and fine-tuning ground truth. Our proposed transferability framework requires less computational time and resources, making it a resource-saving and time-efficient approach for tuning speech foundation models.
Incorporating Ultrasound Tongue Images for Audio-Visual Speech Enhancement through Knowledge Distillation
May 24, 2023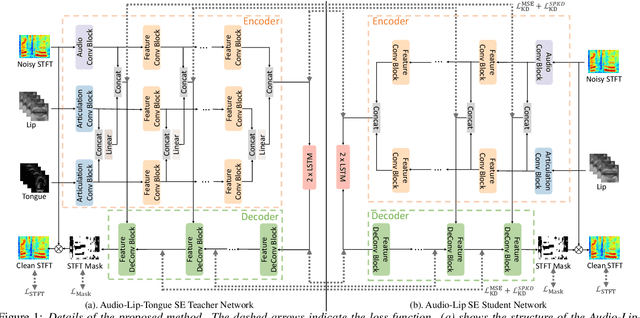
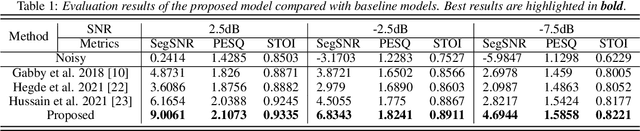
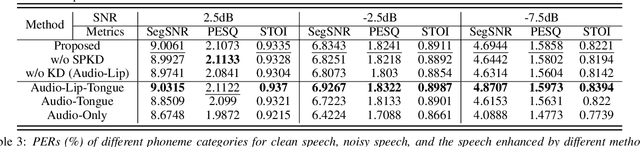
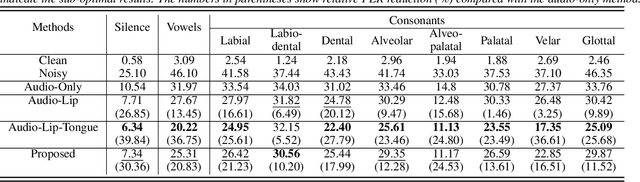
Audio-visual speech enhancement (AV-SE) aims to enhance degraded speech along with extra visual information such as lip videos, and has been shown to be more effective than audio-only speech enhancement. This paper proposes further incorporating ultrasound tongue images to improve lip-based AV-SE systems' performance. Knowledge distillation is employed at the training stage to address the challenge of acquiring ultrasound tongue images during inference, enabling an audio-lip speech enhancement student model to learn from a pre-trained audio-lip-tongue speech enhancement teacher model. Experimental results demonstrate significant improvements in the quality and intelligibility of the speech enhanced by the proposed method compared to the traditional audio-lip speech enhancement baselines. Further analysis using phone error rates (PER) of automatic speech recognition (ASR) shows that palatal and velar consonants benefit most from the introduction of ultrasound tongue images.
Bypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Jun 01, 2023
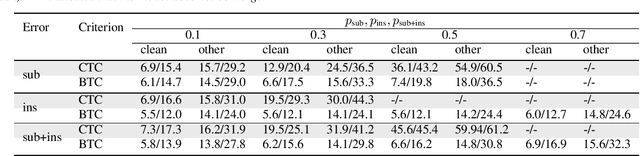
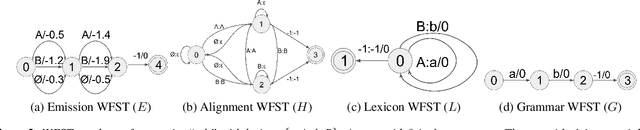
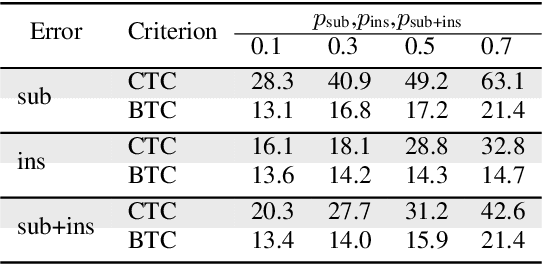
This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.
CTC-based Non-autoregressive Speech Translation
May 27, 2023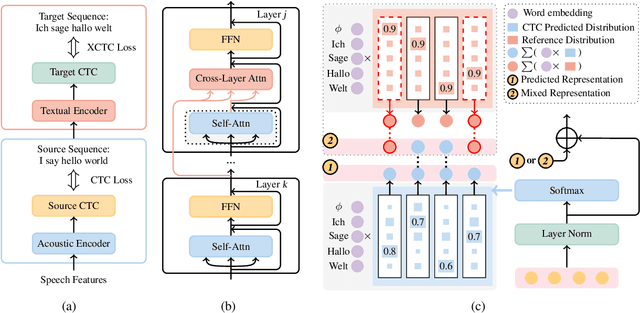
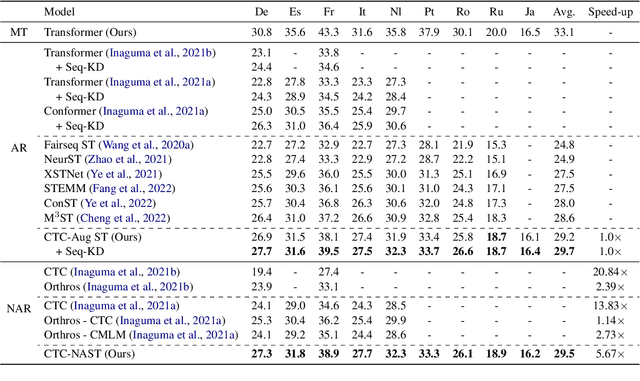
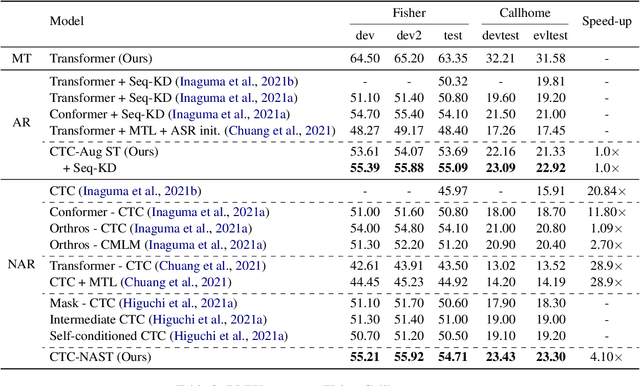
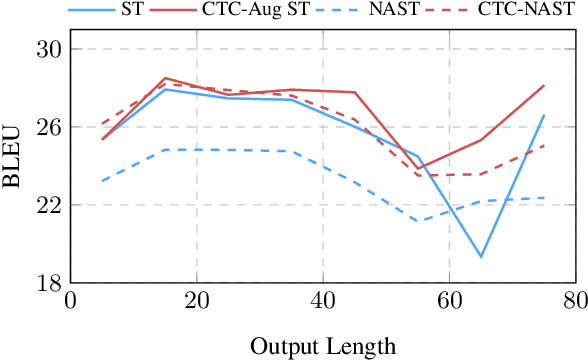
Combining end-to-end speech translation (ST) and non-autoregressive (NAR) generation is promising in language and speech processing for their advantages of less error propagation and low latency. In this paper, we investigate the potential of connectionist temporal classification (CTC) for non-autoregressive speech translation (NAST). In particular, we develop a model consisting of two encoders that are guided by CTC to predict the source and target texts, respectively. Introducing CTC into NAST on both language sides has obvious challenges: 1) the conditional independent generation somewhat breaks the interdependency among tokens, and 2) the monotonic alignment assumption in standard CTC does not hold in translation tasks. In response, we develop a prediction-aware encoding approach and a cross-layer attention approach to address these issues. We also use curriculum learning to improve convergence of training. Experiments on the MuST-C ST benchmarks show that our NAST model achieves an average BLEU score of 29.5 with a speed-up of 5.67$\times$, which is comparable to the autoregressive counterpart and even outperforms the previous best result of 0.9 BLEU points.
Improving Metrics for Speech Translation
May 22, 2023

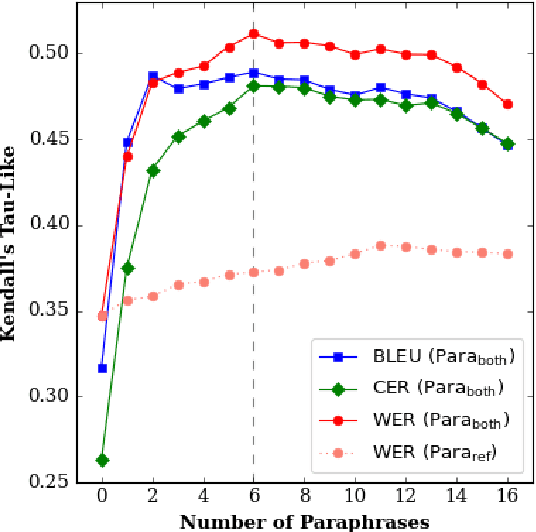
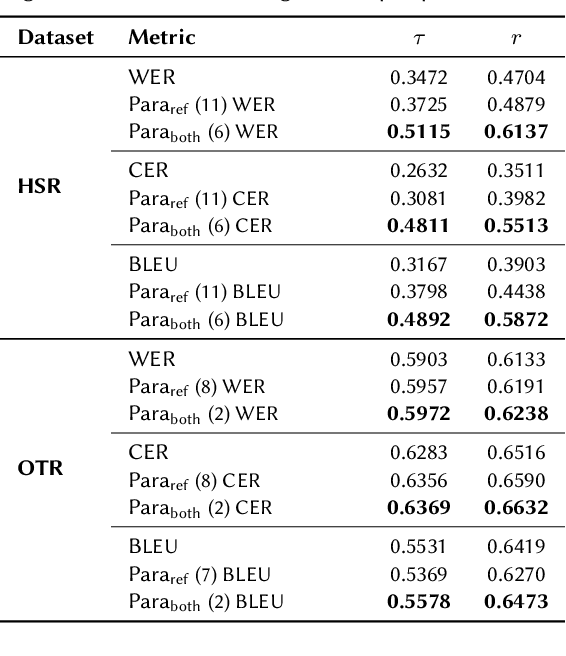
We introduce Parallel Paraphrasing ($\text{Para}_\text{both}$), an augmentation method for translation metrics making use of automatic paraphrasing of both the reference and hypothesis. This method counteracts the typically misleading results of speech translation metrics such as WER, CER, and BLEU if only a single reference is available. We introduce two new datasets explicitly created to measure the quality of metrics intended to be applied to Swiss German speech-to-text systems. Based on these datasets, we show that we are able to significantly improve the correlation with human quality perception if our method is applied to commonly used metrics.
Affect Recognition in Conversations Using Large Language Models
Sep 22, 2023

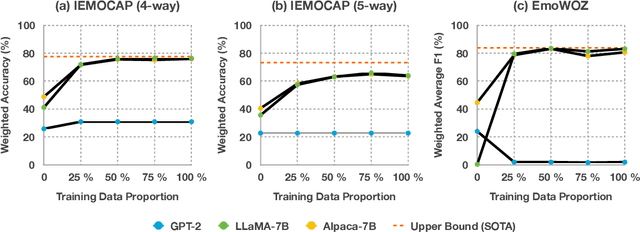
Affect recognition, encompassing emotions, moods, and feelings, plays a pivotal role in human communication. In the realm of conversational artificial intelligence (AI), the ability to discern and respond to human affective cues is a critical factor for creating engaging and empathetic interactions. This study delves into the capacity of large language models (LLMs) to recognise human affect in conversations, with a focus on both open-domain chit-chat dialogues and task-oriented dialogues. Leveraging three diverse datasets, namely IEMOCAP, EmoWOZ, and DAIC-WOZ, covering a spectrum of dialogues from casual conversations to clinical interviews, we evaluated and compared LLMs' performance in affect recognition. Our investigation explores the zero-shot and few-shot capabilities of LLMs through in-context learning (ICL) as well as their model capacities through task-specific fine-tuning. Additionally, this study takes into account the potential impact of automatic speech recognition (ASR) errors on LLM predictions. With this work, we aim to shed light on the extent to which LLMs can replicate human-like affect recognition capabilities in conversations.
Self-supervised learning with diffusion-based multichannel speech enhancement for speaker verification under noisy conditions
Jul 05, 2023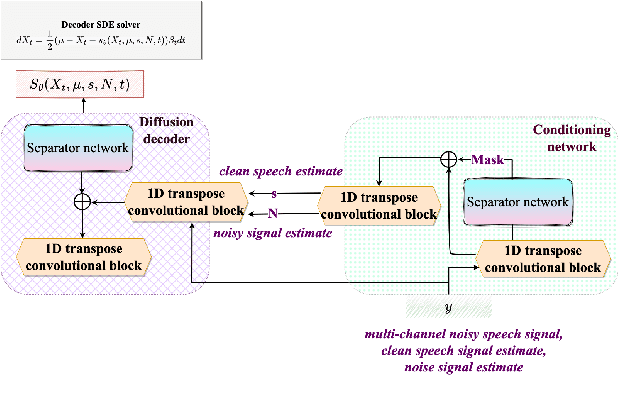
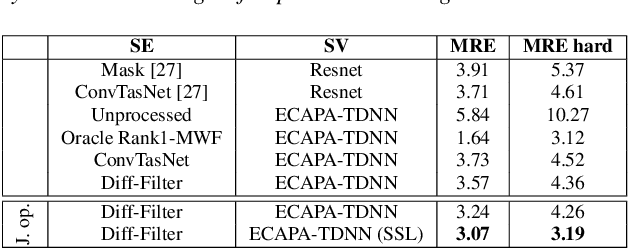
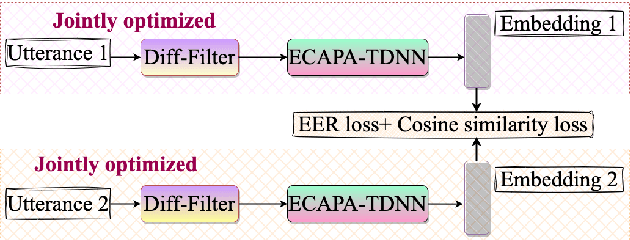
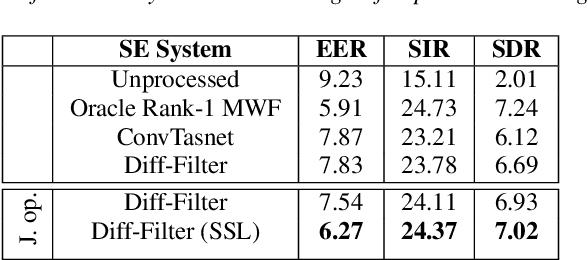
The paper introduces Diff-Filter, a multichannel speech enhancement approach based on the diffusion probabilistic model, for improving speaker verification performance under noisy and reverberant conditions. It also presents a new two-step training procedure that takes the benefit of self-supervised learning. In the first stage, the Diff-Filter is trained by conducting timedomain speech filtering using a scoring-based diffusion model. In the second stage, the Diff-Filter is jointly optimized with a pre-trained ECAPA-TDNN speaker verification model under a self-supervised learning framework. We present a novel loss based on equal error rate. This loss is used to conduct selfsupervised learning on a dataset that is not labelled in terms of speakers. The proposed approach is evaluated on MultiSV, a multichannel speaker verification dataset, and shows significant improvements in performance under noisy multichannel conditions.
An Effective Transformer-based Contextual Model and Temporal Gate Pooling for Speaker Identification
Aug 22, 2023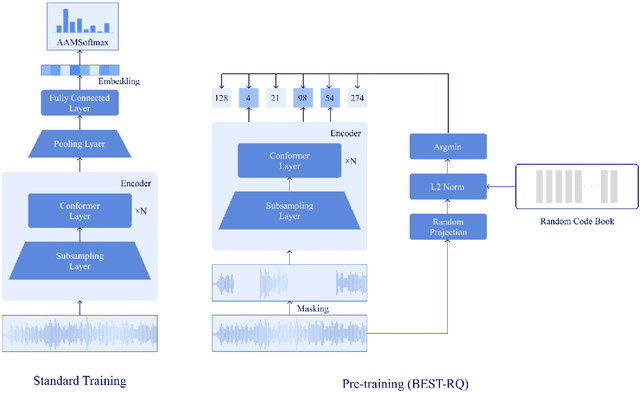
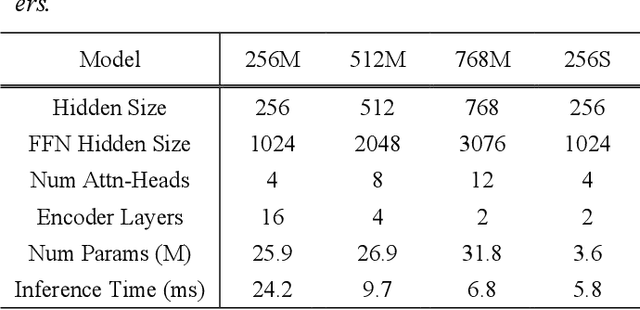
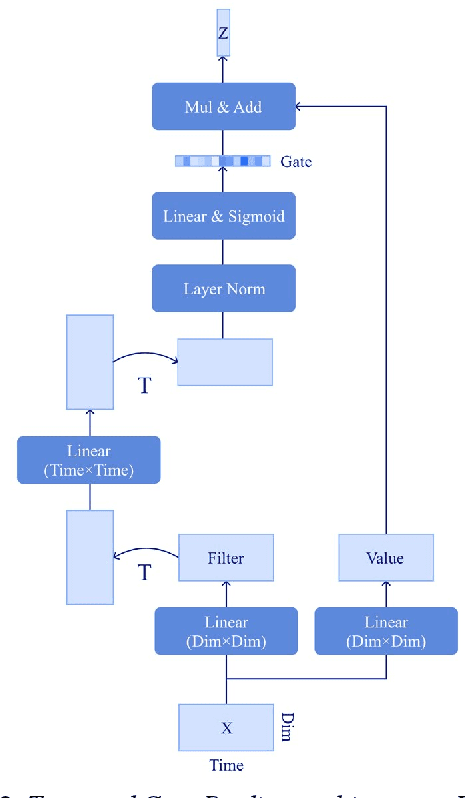
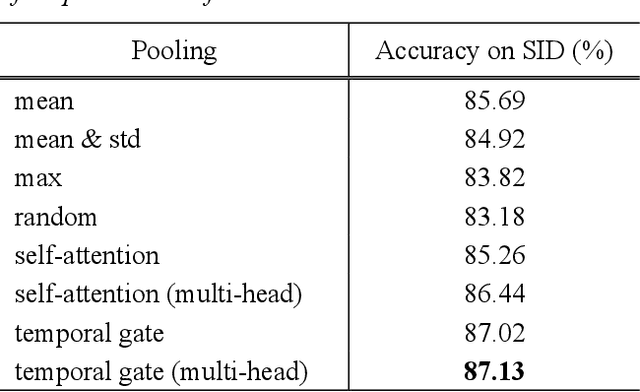
Wav2vec2 has achieved success in applying Transformer architecture and self-supervised learning to speech recognition. Recently, these have come to be used not only for speech recognition but also for the entire speech processing. This paper introduces an effective end-to-end speaker identification model applied Transformer-based contextual model. We explored the relationship between the parameters and the performance in order to discern the structure of an effective model. Furthermore, we propose a pooling method, Temporal Gate Pooling, with powerful learning ability for speaker identification. We applied Conformer as encoder and BEST-RQ for pre-training and conducted an evaluation utilizing the speaker identification of VoxCeleb1. The proposed method has achieved an accuracy of 85.9% with 28.5M parameters, demonstrating comparable precision to wav2vec2 with 317.7M parameters. Code is available at https://github.com/HarunoriKawano/speaker-identification-with-tgp.