 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
PEFT-SER: On the Use of Parameter Efficient Transfer Learning Approaches For Speech Emotion Recognition Using Pre-trained Speech Models
Jun 08, 2023
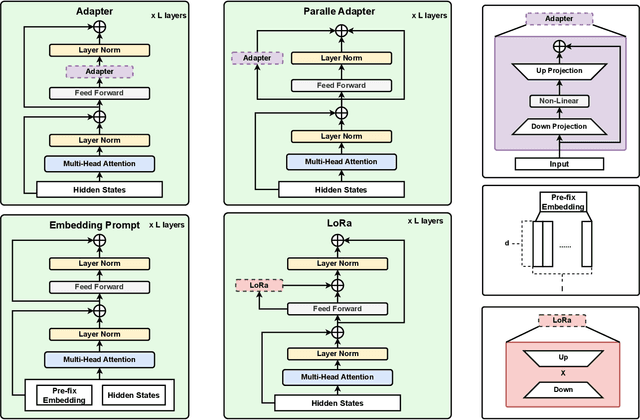
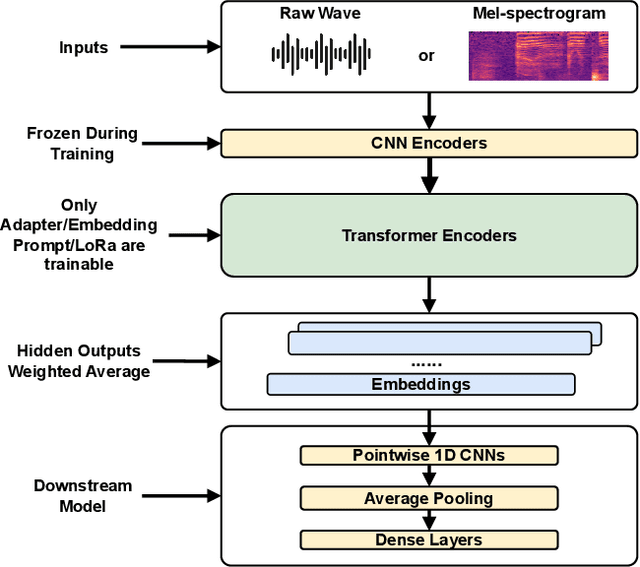

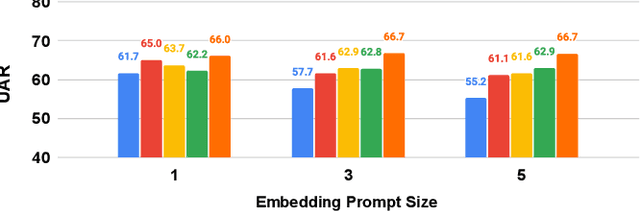
Many recent studies have focused on fine-tuning pre-trained models for speech emotion recognition (SER), resulting in promising performance compared to traditional methods that rely largely on low-level, knowledge-inspired acoustic features. These pre-trained speech models learn general-purpose speech representations using self-supervised or weakly-supervised learning objectives from large-scale datasets. Despite the significant advances made in SER through the use of pre-trained architecture, fine-tuning these large pre-trained models for different datasets requires saving copies of entire weight parameters, rendering them impractical to deploy in real-world settings. As an alternative, this work explores parameter-efficient fine-tuning (PEFT) approaches for adapting pre-trained speech models for emotion recognition. Specifically, we evaluate the efficacy of adapter tuning, embedding prompt tuning, and LoRa (Low-rank approximation) on four popular SER testbeds. Our results reveal that LoRa achieves the best fine-tuning performance in emotion recognition while enhancing fairness and requiring only a minimal extra amount of weight parameters. Furthermore, our findings offer novel insights into future research directions in SER, distinct from existing approaches focusing on directly fine-tuning the model architecture. Our code is publicly available under: https://github.com/usc-sail/peft-ser.
EMALG: An Enhanced Mandarin Lombard Grid Corpus with Meaningful Sentences
Sep 13, 2023This study investigates the Lombard effect, where individuals adapt their speech in noisy environments. We introduce an enhanced Mandarin Lombard grid (EMALG) corpus with meaningful sentences , enhancing the Mandarin Lombard grid (MALG) corpus. EMALG features 34 speakers and improves recording setups, addressing challenges faced by MALG with nonsense sentences. Our findings reveal that in Mandarin, female exhibit a more pronounced Lombard effect than male, particularly when uttering meaningful sentences. Additionally, we uncover that nonsense sentences negatively impact Lombard effect analysis. Moreover, our results reaffirm the consistency in the Lombard effect comparison between English and Mandarin found in previous research.
CiwaGAN: Articulatory information exchange
Sep 14, 2023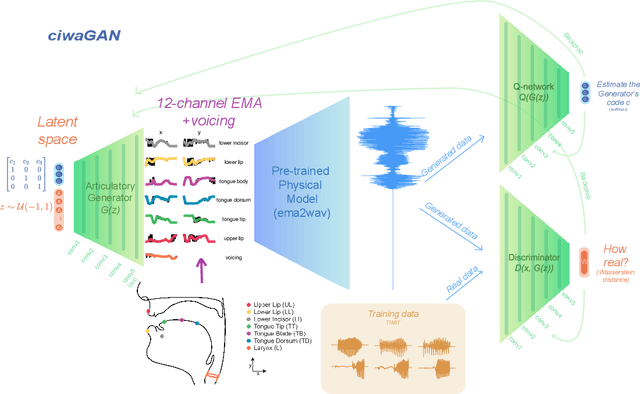

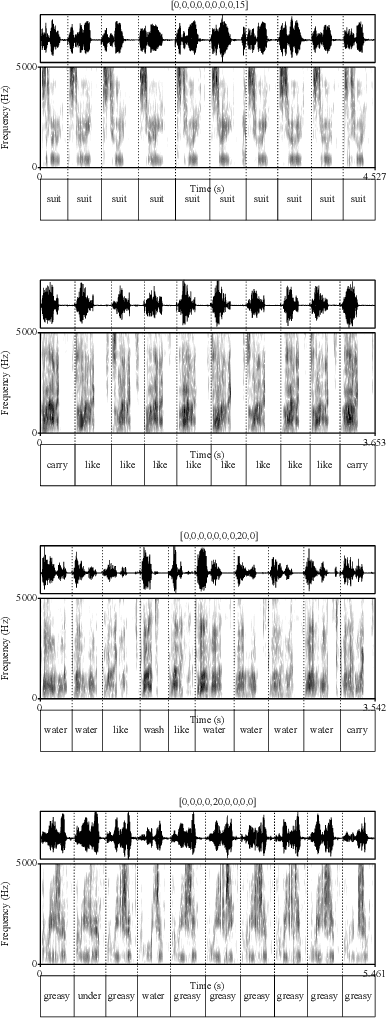

Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
Affect Recognition in Conversations Using Large Language Models
Sep 22, 2023

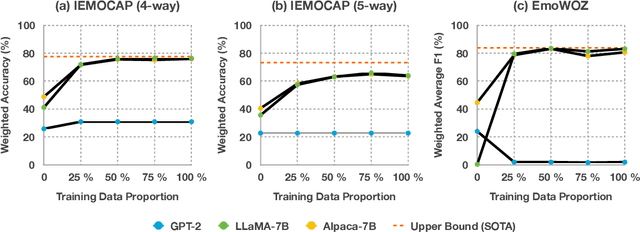
Affect recognition, encompassing emotions, moods, and feelings, plays a pivotal role in human communication. In the realm of conversational artificial intelligence (AI), the ability to discern and respond to human affective cues is a critical factor for creating engaging and empathetic interactions. This study delves into the capacity of large language models (LLMs) to recognise human affect in conversations, with a focus on both open-domain chit-chat dialogues and task-oriented dialogues. Leveraging three diverse datasets, namely IEMOCAP, EmoWOZ, and DAIC-WOZ, covering a spectrum of dialogues from casual conversations to clinical interviews, we evaluated and compared LLMs' performance in affect recognition. Our investigation explores the zero-shot and few-shot capabilities of LLMs through in-context learning (ICL) as well as their model capacities through task-specific fine-tuning. Additionally, this study takes into account the potential impact of automatic speech recognition (ASR) errors on LLM predictions. With this work, we aim to shed light on the extent to which LLMs can replicate human-like affect recognition capabilities in conversations.
Privacy in Speech Technology
May 09, 2023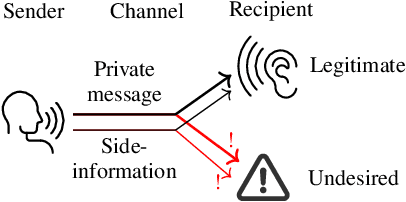
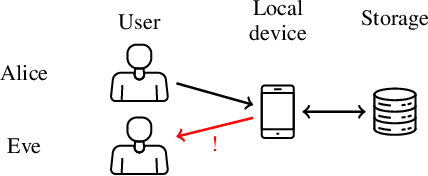
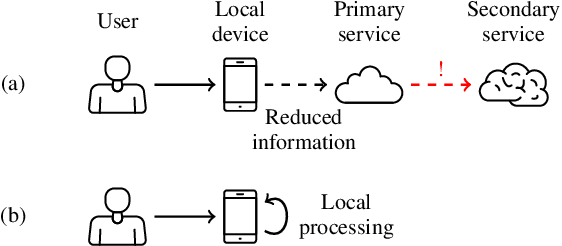
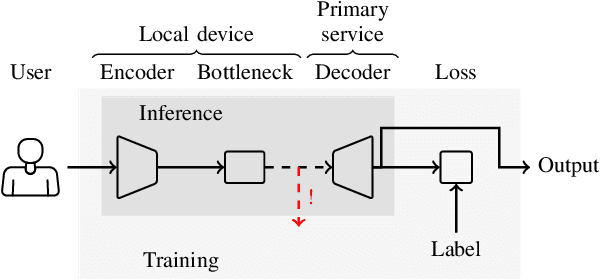
Speech technology for communication, accessing information and services has rapidly improved in quality. It is convenient and appealing because speech is the primary mode of communication for humans. Such technology however also presents proven threats to privacy. Speech is a tool for communication and it will thus inherently contain private information. Importantly, it however also contains a wealth of side information, such as information related to health, emotions, affiliations, and relationships, all of which are private. Exposing such private information can lead to serious threats such as price gouging, harassment, extortion, and stalking. This paper is a tutorial on privacy issues related to speech technology, modeling their threats, approaches for protecting users' privacy, measuring the performance of privacy-protecting methods, perception of privacy as well as societal and legal consequences. In addition to a tutorial overview, it also presents lines for further development where improvements are most urgently needed.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023
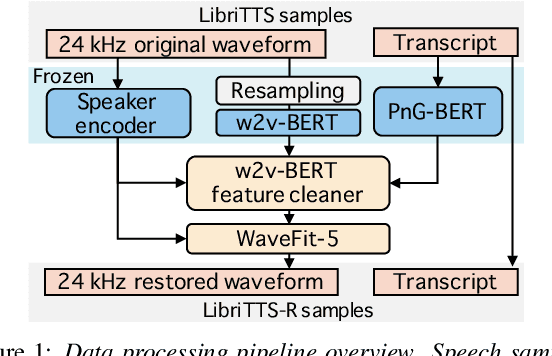
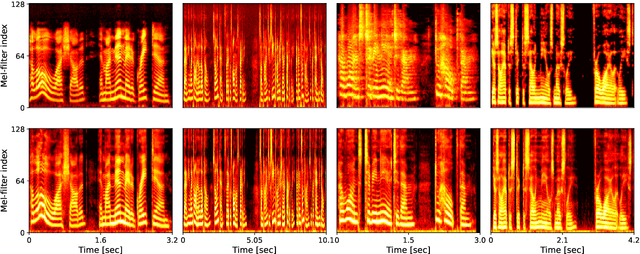

This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.
TRAVID: An End-to-End Video Translation Framework
Sep 20, 2023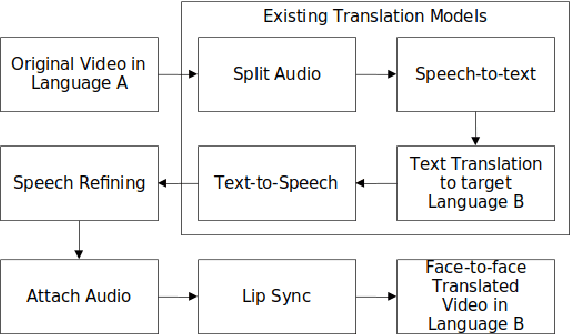

In today's globalized world, effective communication with people from diverse linguistic backgrounds has become increasingly crucial. While traditional methods of language translation, such as written text or voice-only translations, can accomplish the task, they often fail to capture the complete context and nuanced information conveyed through nonverbal cues like facial expressions and lip movements. In this paper, we present an end-to-end video translation system that not only translates spoken language but also synchronizes the translated speech with the lip movements of the speaker. Our system focuses on translating educational lectures in various Indian languages, and it is designed to be effective even in low-resource system settings. By incorporating lip movements that align with the target language and matching them with the speaker's voice using voice cloning techniques, our application offers an enhanced experience for students and users. This additional feature creates a more immersive and realistic learning environment, ultimately making the learning process more effective and engaging.
PEACE: Cross-Platform Hate Speech Detection- A Causality-guided Framework
Jun 15, 2023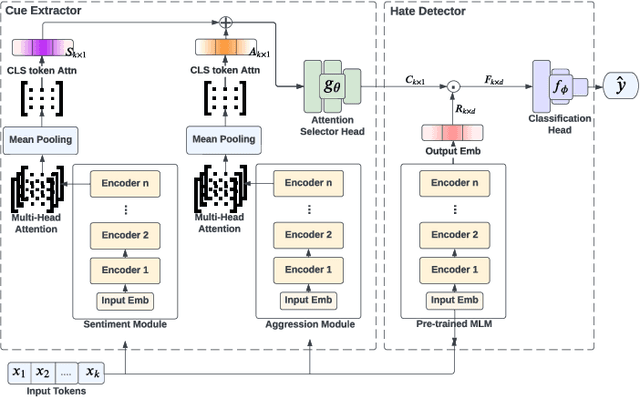
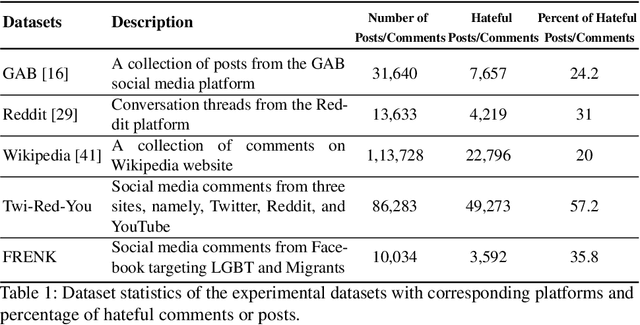
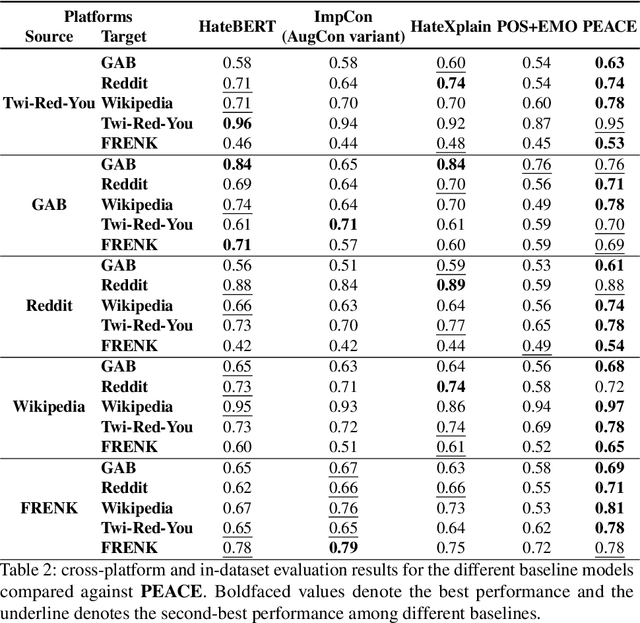
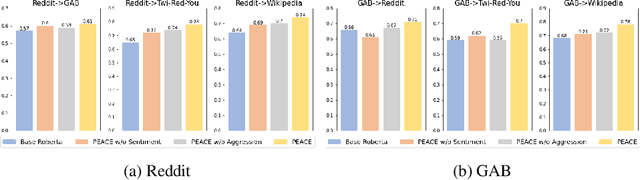
Hate speech detection refers to the task of detecting hateful content that aims at denigrating an individual or a group based on their religion, gender, sexual orientation, or other characteristics. Due to the different policies of the platforms, different groups of people express hate in different ways. Furthermore, due to the lack of labeled data in some platforms it becomes challenging to build hate speech detection models. To this end, we revisit if we can learn a generalizable hate speech detection model for the cross platform setting, where we train the model on the data from one (source) platform and generalize the model across multiple (target) platforms. Existing generalization models rely on linguistic cues or auxiliary information, making them biased towards certain tags or certain kinds of words (e.g., abusive words) on the source platform and thus not applicable to the target platforms. Inspired by social and psychological theories, we endeavor to explore if there exist inherent causal cues that can be leveraged to learn generalizable representations for detecting hate speech across these distribution shifts. To this end, we propose a causality-guided framework, PEACE, that identifies and leverages two intrinsic causal cues omnipresent in hateful content: the overall sentiment and the aggression in the text. We conduct extensive experiments across multiple platforms (representing the distribution shift) showing if causal cues can help cross-platform generalization.
STT4SG-350: A Speech Corpus for All Swiss German Dialect Regions
May 30, 2023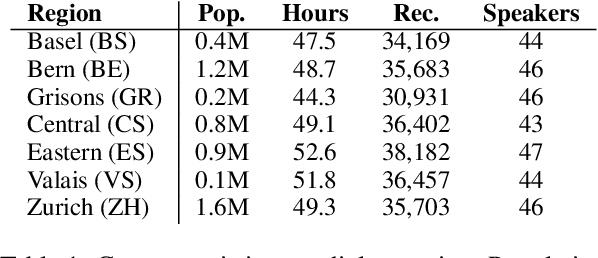
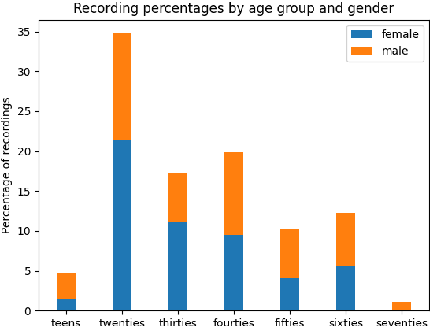
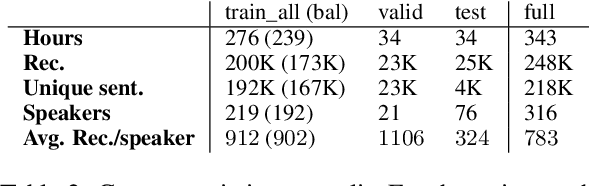
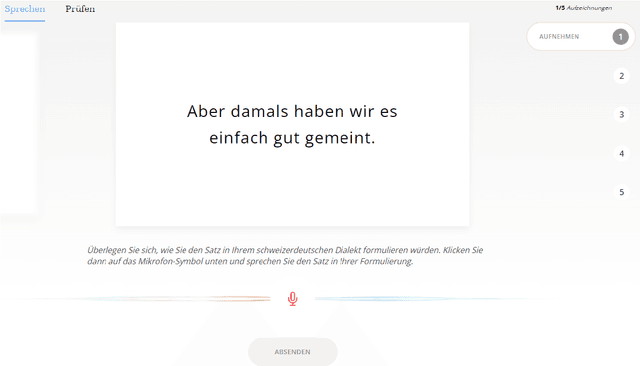
We present STT4SG-350 (Speech-to-Text for Swiss German), a corpus of Swiss German speech, annotated with Standard German text at the sentence level. The data is collected using a web app in which the speakers are shown Standard German sentences, which they translate to Swiss German and record. We make the corpus publicly available. It contains 343 hours of speech from all dialect regions and is the largest public speech corpus for Swiss German to date. Application areas include automatic speech recognition (ASR), text-to-speech, dialect identification, and speaker recognition. Dialect information, age group, and gender of the 316 speakers are provided. Genders are equally represented and the corpus includes speakers of all ages. Roughly the same amount of speech is provided per dialect region, which makes the corpus ideally suited for experiments with speech technology for different dialects. We provide training, validation, and test splits of the data. The test set consists of the same spoken sentences for each dialect region and allows a fair evaluation of the quality of speech technologies in different dialects. We train an ASR model on the training set and achieve an average BLEU score of 74.7 on the test set. The model beats the best published BLEU scores on 2 other Swiss German ASR test sets, demonstrating the quality of the corpus.
DistilXLSR: A Light Weight Cross-Lingual Speech Representation Model
Jun 02, 2023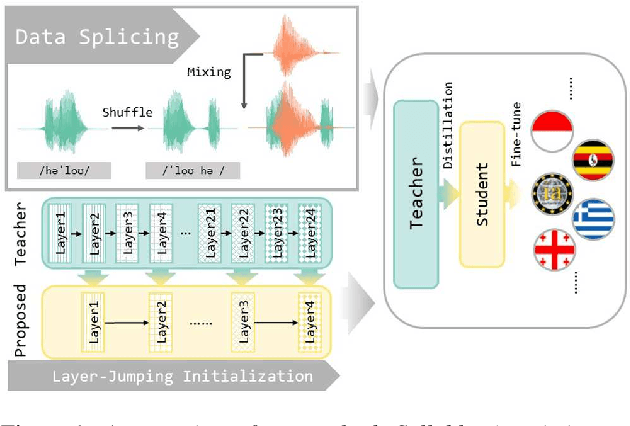
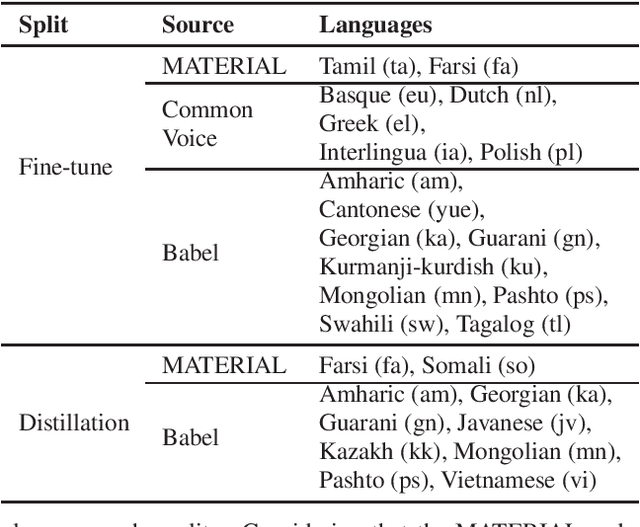
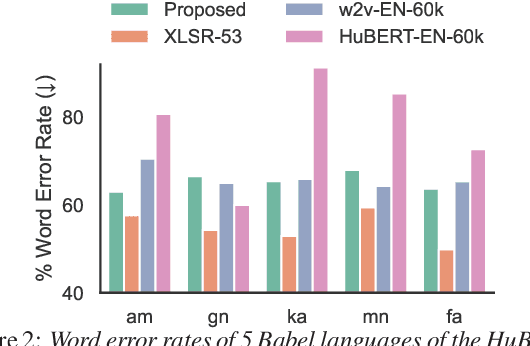
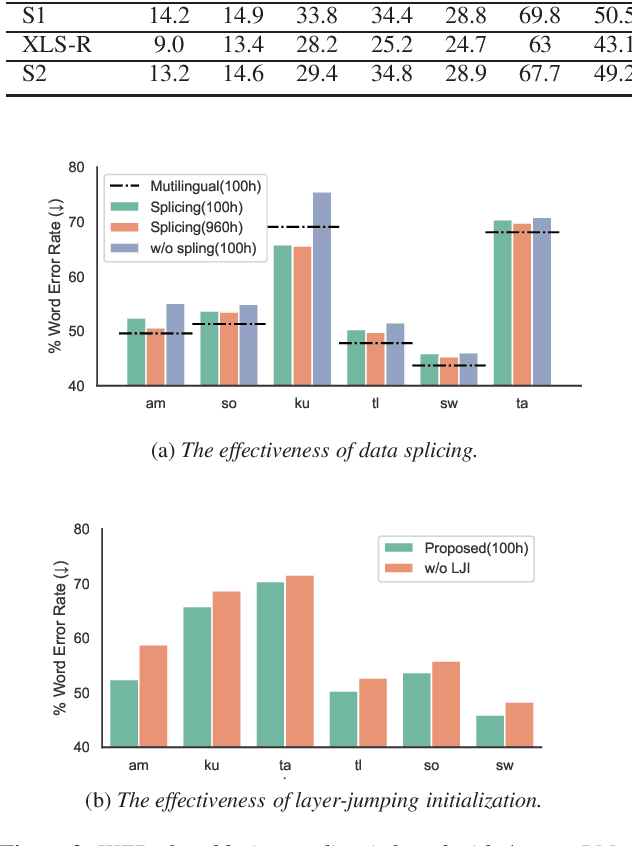
Multilingual self-supervised speech representation models have greatly enhanced the speech recognition performance for low-resource languages, and the compression of these huge models has also become a crucial prerequisite for their industrial application. In this paper, we propose DistilXLSR, a distilled cross-lingual speech representation model. By randomly shuffling the phonemes of existing speech, we reduce the linguistic information and distill cross-lingual models using only English data. We also design a layer-jumping initialization method to fully leverage the teacher's pre-trained weights. Experiments on 2 kinds of teacher models and 15 low-resource languages show that our method can reduce the parameters by 50% while maintaining cross-lingual representation ability. Our method is proven to be generalizable to various languages/teacher models and has the potential to improve the cross-lingual performance of the English pre-trained models.