 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Non-verbal information in spontaneous speech -- towards a new framework of analysis
Mar 06, 2024
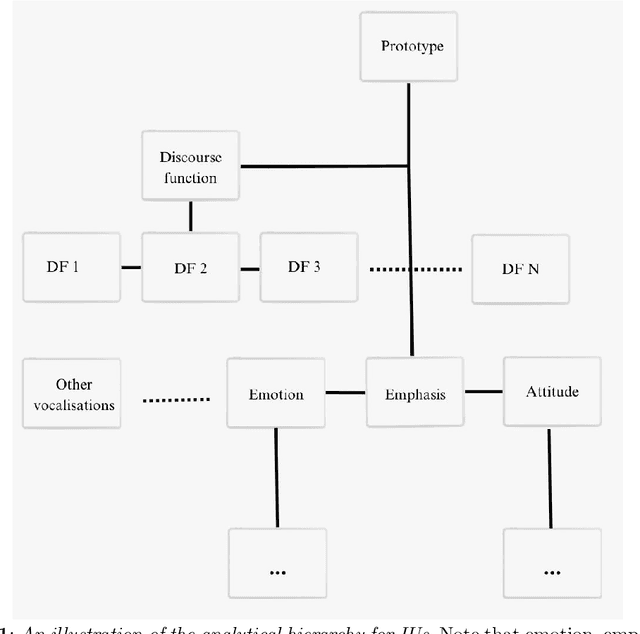
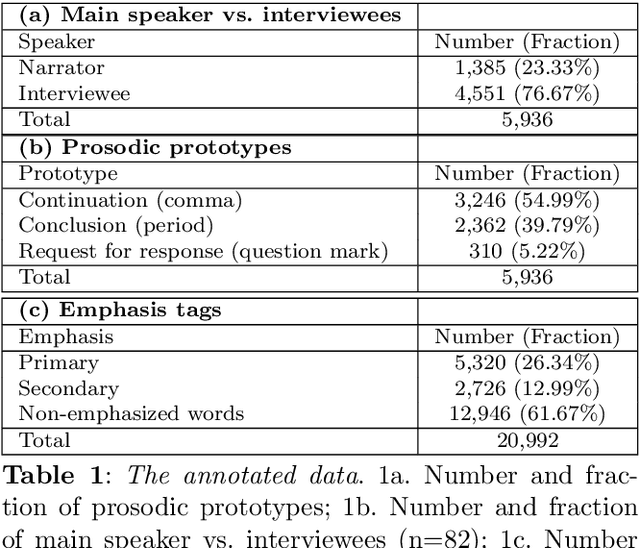
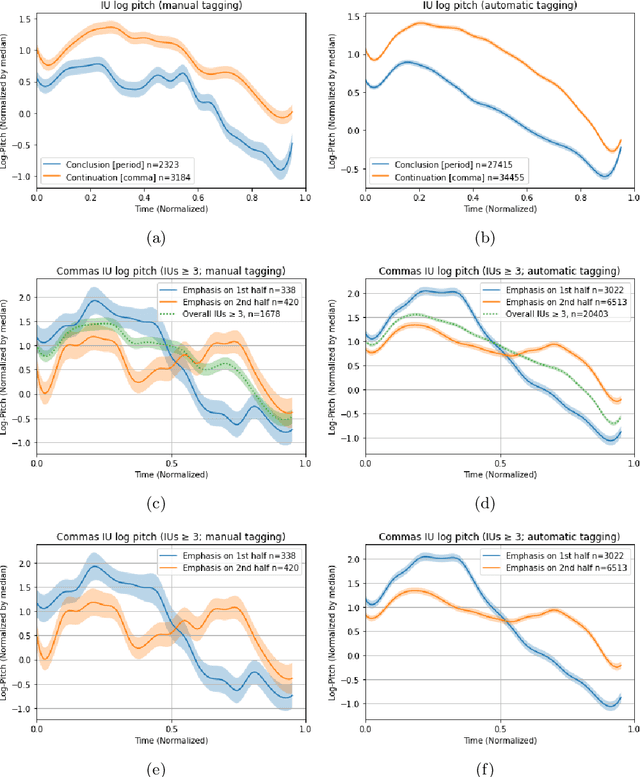
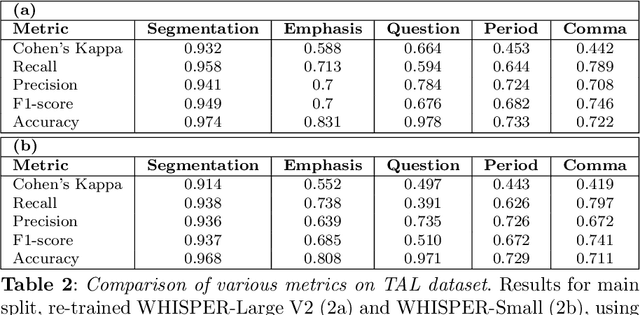
Non-verbal signals in speech are encoded by prosody and carry information that ranges from conversation action to attitude and emotion. Despite its importance, the principles that govern prosodic structure are not yet adequately understood. This paper offers an analytical schema and a technological proof-of-concept for the categorization of prosodic signals and their association with meaning. The schema interprets surface-representations of multi-layered prosodic events. As a first step towards implementation, we present a classification process that disentangles prosodic phenomena of three orders. It relies on fine-tuning a pre-trained speech recognition model, enabling the simultaneous multi-class/multi-label detection. It generalizes over a large variety of spontaneous data, performing on a par with, or superior to, human annotation. In addition to a standardized formalization of prosody, disentangling prosodic patterns can direct a theory of communication and speech organization. A welcome by-product is an interpretation of prosody that will enhance speech- and language-related technologies.
An image speaks a thousand words, but can everyone listen? On translating images for cultural relevance
Apr 01, 2024Given the rise of multimedia content, human translators increasingly focus on culturally adapting not only words but also other modalities such as images to convey the same meaning. While several applications stand to benefit from this, machine translation systems remain confined to dealing with language in speech and text. In this work, we take a first step towards translating images to make them culturally relevant. First, we build three pipelines comprising state-of-the-art generative models to do the task. Next, we build a two-part evaluation dataset: i) concept: comprising 600 images that are cross-culturally coherent, focusing on a single concept per image, and ii) application: comprising 100 images curated from real-world applications. We conduct a multi-faceted human evaluation of translated images to assess for cultural relevance and meaning preservation. We find that as of today, image-editing models fail at this task, but can be improved by leveraging LLMs and retrievers in the loop. Best pipelines can only translate 5% of images for some countries in the easier concept dataset and no translation is successful for some countries in the application dataset, highlighting the challenging nature of the task. Our code and data is released here: https://github.com/simran-khanuja/image-transcreation.
Enhancing Real-World Active Speaker Detection with Multi-Modal Extraction Pre-Training
Apr 01, 2024Audio-visual active speaker detection (AV-ASD) aims to identify which visible face is speaking in a scene with one or more persons. Most existing AV-ASD methods prioritize capturing speech-lip correspondence. However, there is a noticeable gap in addressing the challenges from real-world AV-ASD scenarios. Due to the presence of low-quality noisy videos in such cases, AV-ASD systems without a selective listening ability are short of effectively filtering out disruptive voice components from mixed audio inputs. In this paper, we propose a Multi-modal Speaker Extraction-to-Detection framework named `MuSED', which is pre-trained with audio-visual target speaker extraction to learn the denoising ability, then it is fine-tuned with the AV-ASD task. Meanwhile, to better capture the multi-modal information and deal with real-world problems such as missing modality, MuSED is modelled on the time domain directly and integrates the multi-modal plus-and-minus augmentation strategy. Our experiments demonstrate that MuSED substantially outperforms the state-of-the-art AV-ASD methods and achieves 95.6% mAP on the AVA-ActiveSpeaker dataset, 98.3% AP on the ASW dataset, and 97.9% F1 on the Columbia AV-ASD dataset, respectively. We will publicly release the code in due course.
Towards Accurate Lip-to-Speech Synthesis in-the-Wild
Mar 02, 2024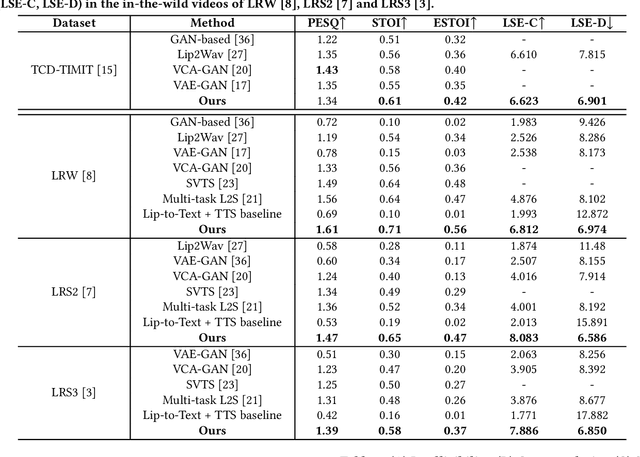
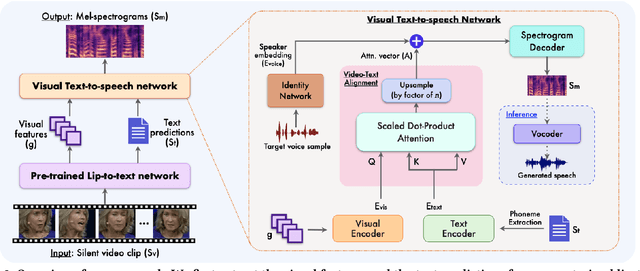
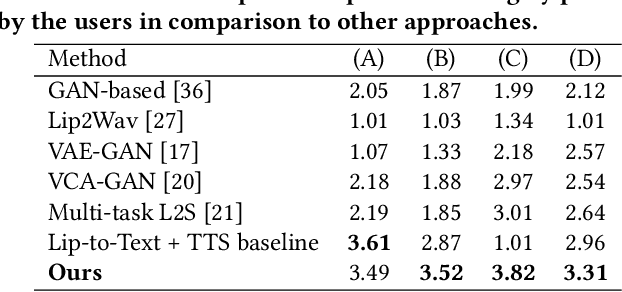
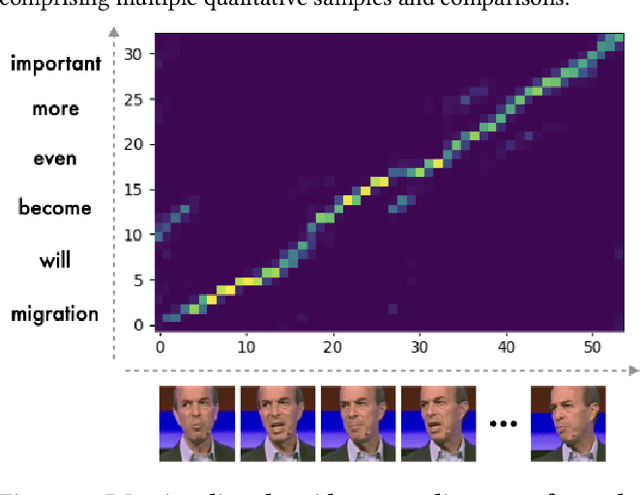
In this paper, we introduce a novel approach to address the task of synthesizing speech from silent videos of any in-the-wild speaker solely based on lip movements. The traditional approach of directly generating speech from lip videos faces the challenge of not being able to learn a robust language model from speech alone, resulting in unsatisfactory outcomes. To overcome this issue, we propose incorporating noisy text supervision using a state-of-the-art lip-to-text network that instills language information into our model. The noisy text is generated using a pre-trained lip-to-text model, enabling our approach to work without text annotations during inference. We design a visual text-to-speech network that utilizes the visual stream to generate accurate speech, which is in-sync with the silent input video. We perform extensive experiments and ablation studies, demonstrating our approach's superiority over the current state-of-the-art methods on various benchmark datasets. Further, we demonstrate an essential practical application of our method in assistive technology by generating speech for an ALS patient who has lost the voice but can make mouth movements. Our demo video, code, and additional details can be found at \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/ms-l2s-itw}.
* 8 pages of content, 1 page of references and 4 figures
FFSTC: Fongbe to French Speech Translation Corpus
Mar 08, 2024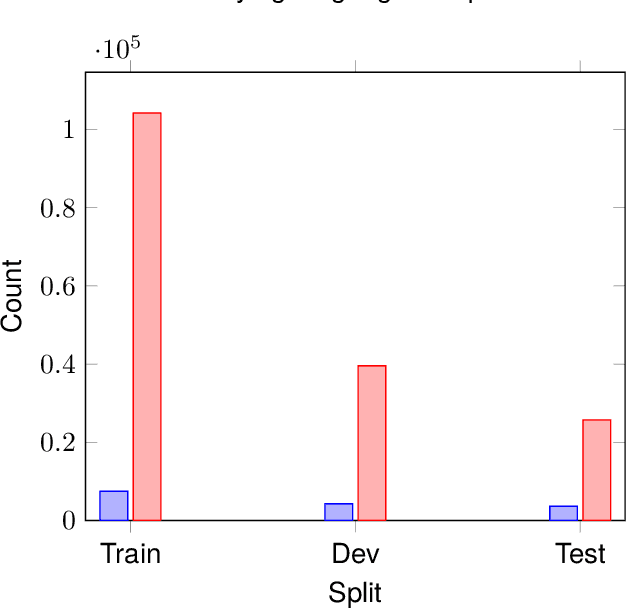
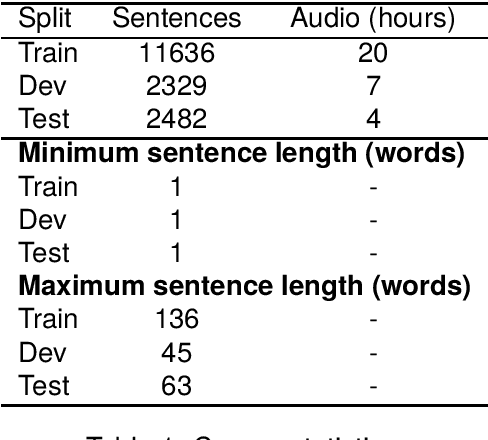
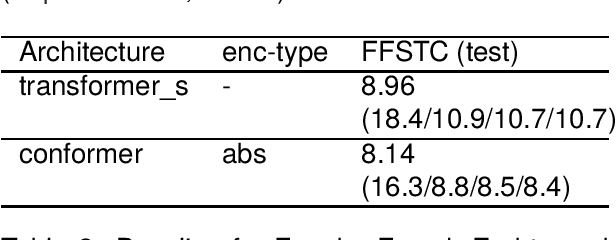
In this paper, we introduce the Fongbe to French Speech Translation Corpus (FFSTC) for the first time. This corpus encompasses approximately 31 hours of collected Fongbe language content, featuring both French transcriptions and corresponding Fongbe voice recordings. FFSTC represents a comprehensive dataset compiled through various collection methods and the efforts of dedicated individuals. Furthermore, we conduct baseline experiments using Fairseq's transformer_s and conformer models to evaluate data quality and validity. Our results indicate a score of 8.96 for the transformer_s model and 8.14 for the conformer model, establishing a baseline for the FFSTC corpus.
HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling
Mar 09, 2024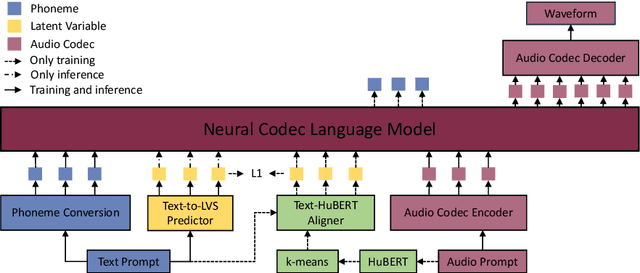
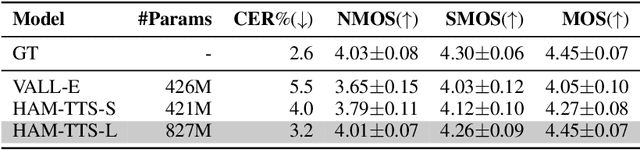
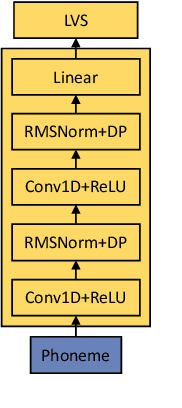
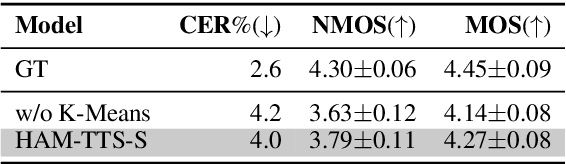
Token-based text-to-speech (TTS) models have emerged as a promising avenue for generating natural and realistic speech, yet they grapple with low pronunciation accuracy, speaking style and timbre inconsistency, and a substantial need for diverse training data. In response, we introduce a novel hierarchical acoustic modeling approach complemented by a tailored data augmentation strategy and train it on the combination of real and synthetic data, scaling the data size up to 650k hours, leading to the zero-shot TTS model with 0.8B parameters. Specifically, our method incorporates a latent variable sequence containing supplementary acoustic information based on refined self-supervised learning (SSL) discrete units into the TTS model by a predictor. This significantly mitigates pronunciation errors and style mutations in synthesized speech. During training, we strategically replace and duplicate segments of the data to enhance timbre uniformity. Moreover, a pretrained few-shot voice conversion model is utilized to generate a plethora of voices with identical content yet varied timbres. This facilitates the explicit learning of utterance-level one-to-many mappings, enriching speech diversity and also ensuring consistency in timbre. Comparative experiments (Demo page: https://anonymous.4open.science/w/ham-tts/)demonstrate our model's superiority over VALL-E in pronunciation precision and maintaining speaking style, as well as timbre continuity.
Houston we have a Divergence: A Subgroup Performance Analysis of ASR Models
Mar 31, 2024The Fearless Steps APOLLO Community Resource provides unparalleled opportunities to explore the potential of multi-speaker team communications from NASA Apollo missions. This study focuses on discovering the characteristics that make Apollo recordings more or less intelligible to Automatic Speech Recognition (ASR) methods. We extract, for each audio recording, interpretable metadata on recordings (signal-to-noise ratio, spectral flatness, presence of pauses, sentence duration), transcript (number of words spoken, speaking rate), or known a priori (speaker). We identify subgroups of audio recordings based on combinations of these metadata and compute each subgroup's performance (e.g., Word Error Rate) and the difference in performance (''divergence'') w.r.t the overall population. We then apply the Whisper model in different sizes, trained on English-only or multilingual datasets, in zero-shot or after fine-tuning. We conduct several analyses to (i) automatically identify and describe the most problematic subgroups for a given model, (ii) examine the impact of fine-tuning w.r.t. zero-shot at the subgroup level, (iii) understand the effect of model size on subgroup performance, and (iv) analyze if multilingual models are more sensitive than monolingual to subgroup performance disparities. The insights enhance our understanding of subgroup-specific performance variations, paving the way for advancements in optimizing ASR systems for Earth-to-space communications.
A Closer Look at Wav2Vec2 Embeddings for On-Device Single-Channel Speech Enhancement
Mar 03, 2024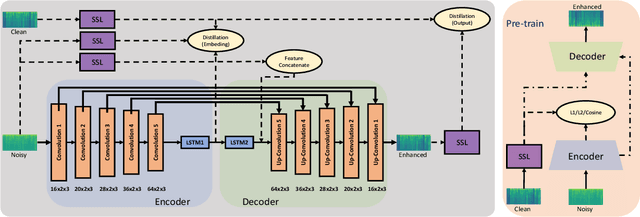
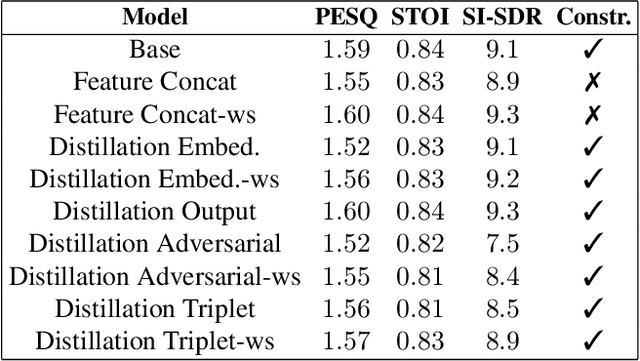
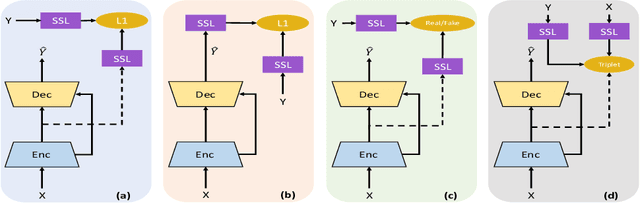
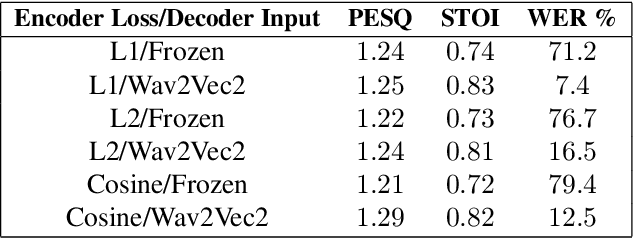
Self-supervised learned models have been found to be very effective for certain speech tasks such as automatic speech recognition, speaker identification, keyword spotting and others. While the features are undeniably useful in speech recognition and associated tasks, their utility in speech enhancement systems is yet to be firmly established, and perhaps not properly understood. In this paper, we investigate the uses of SSL representations for single-channel speech enhancement in challenging conditions and find that they add very little value for the enhancement task. Our constraints are designed around on-device real-time speech enhancement -- model is causal, the compute footprint is small. Additionally, we focus on low SNR conditions where such models struggle to provide good enhancement. In order to systematically examine how SSL representations impact performance of such enhancement models, we propose a variety of techniques to utilize these embeddings which include different forms of knowledge-distillation and pre-training.
ChatGPT v.s. Media Bias: A Comparative Study of GPT-3.5 and Fine-tuned Language Models
Mar 29, 2024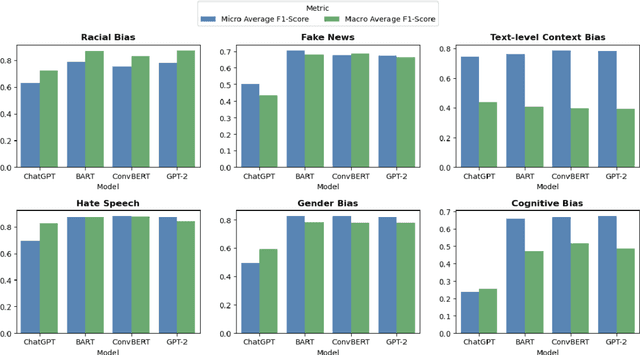
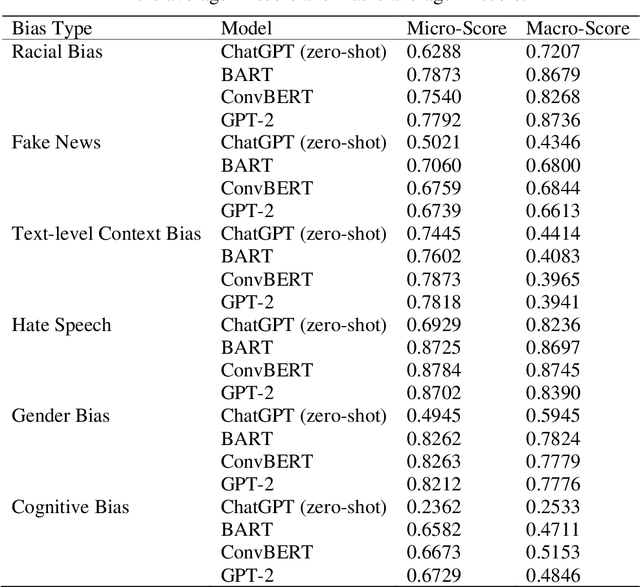
In our rapidly evolving digital sphere, the ability to discern media bias becomes crucial as it can shape public sentiment and influence pivotal decisions. The advent of large language models (LLMs), such as ChatGPT, noted for their broad utility in various natural language processing (NLP) tasks, invites exploration of their efficacy in media bias detection. Can ChatGPT detect media bias? This study seeks to answer this question by leveraging the Media Bias Identification Benchmark (MBIB) to assess ChatGPT's competency in distinguishing six categories of media bias, juxtaposed against fine-tuned models such as BART, ConvBERT, and GPT-2. The findings present a dichotomy: ChatGPT performs at par with fine-tuned models in detecting hate speech and text-level context bias, yet faces difficulties with subtler elements of other bias detections, namely, fake news, racial, gender, and cognitive biases.
* 9 pages, 1 figure, published on Applied and Computational Engineering
Skipformer: A Skip-and-Recover Strategy for Efficient Speech Recognition
Mar 13, 2024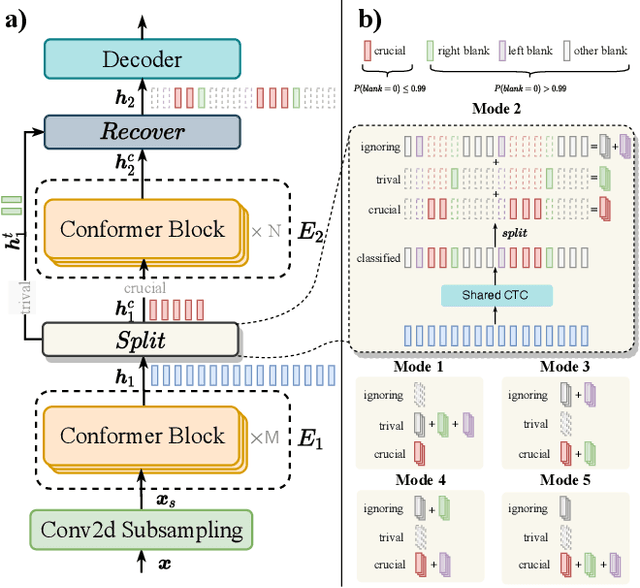
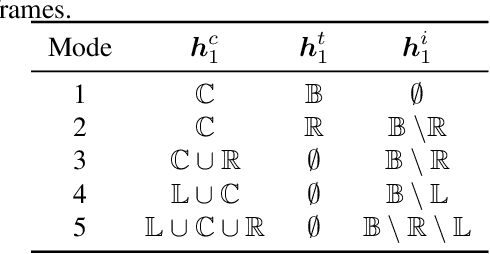
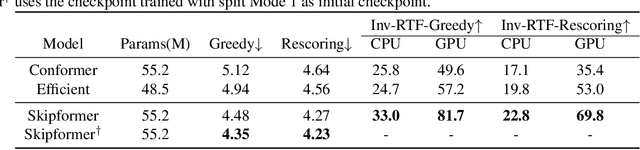
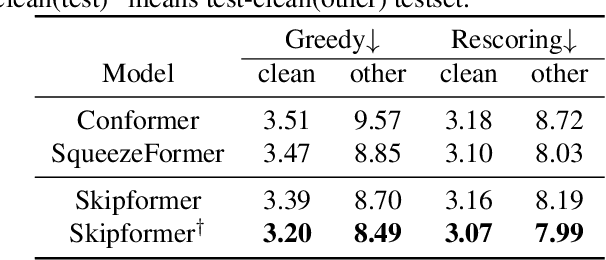
Conformer-based attention models have become the de facto backbone model for Automatic Speech Recognition tasks. A blank symbol is usually introduced to align the input and output sequences for CTC or RNN-T models. Unfortunately, the long input length overloads computational budget and memory consumption quadratically by attention mechanism. In this work, we propose a "Skip-and-Recover" Conformer architecture, named Skipformer, to squeeze sequence input length dynamically and inhomogeneously. Skipformer uses an intermediate CTC output as criteria to split frames into three groups: crucial, skipping and ignoring. The crucial group feeds into next conformer blocks and its output joint with skipping group by original temporal order as the final encoder output. Experiments show that our model reduces the input sequence length by 31 times on Aishell-1 and 22 times on Librispeech corpus. Meanwhile, the model can achieve better recognition accuracy and faster inference speed than recent baseline models. Our code is open-sourced and available online.