 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Distilling HuBERT with LSTMs via Decoupled Knowledge Distillation
Sep 18, 2023
Much research effort is being applied to the task of compressing the knowledge of self-supervised models, which are powerful, yet large and memory consuming. In this work, we show that the original method of knowledge distillation (and its more recently proposed extension, decoupled knowledge distillation) can be applied to the task of distilling HuBERT. In contrast to methods that focus on distilling internal features, this allows for more freedom in the network architecture of the compressed model. We thus propose to distill HuBERT's Transformer layers into an LSTM-based distilled model that reduces the number of parameters even below DistilHuBERT and at the same time shows improved performance in automatic speech recognition.
Hyper-parameter Adaptation of Conformer ASR Systems for Elderly and Dysarthric Speech Recognition
Jun 27, 2023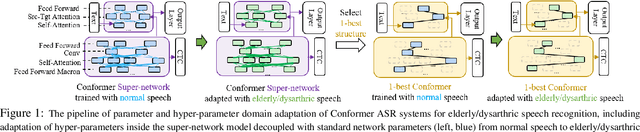
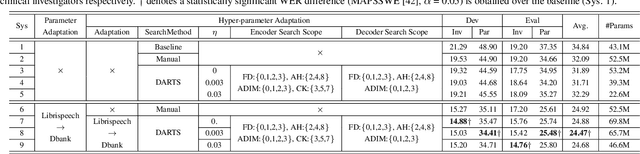
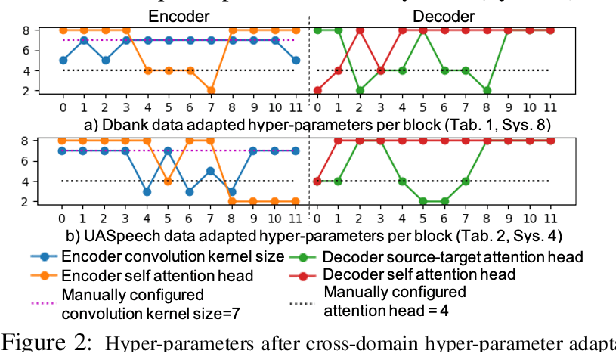

Automatic recognition of disordered and elderly speech remains highly challenging tasks to date due to data scarcity. Parameter fine-tuning is often used to exploit the large quantities of non-aged and healthy speech pre-trained models, while neural architecture hyper-parameters are set using expert knowledge and remain unchanged. This paper investigates hyper-parameter adaptation for Conformer ASR systems that are pre-trained on the Librispeech corpus before being domain adapted to the DementiaBank elderly and UASpeech dysarthric speech datasets. Experimental results suggest that hyper-parameter adaptation produced word error rate (WER) reductions of 0.45% and 0.67% over parameter-only fine-tuning on DBank and UASpeech tasks respectively. An intuitive correlation is found between the performance improvements by hyper-parameter domain adaptation and the relative utterance length ratio between the source and target domain data.
NTT speaker diarization system for CHiME-7: multi-domain, multi-microphone End-to-end and vector clustering diarization
Sep 22, 2023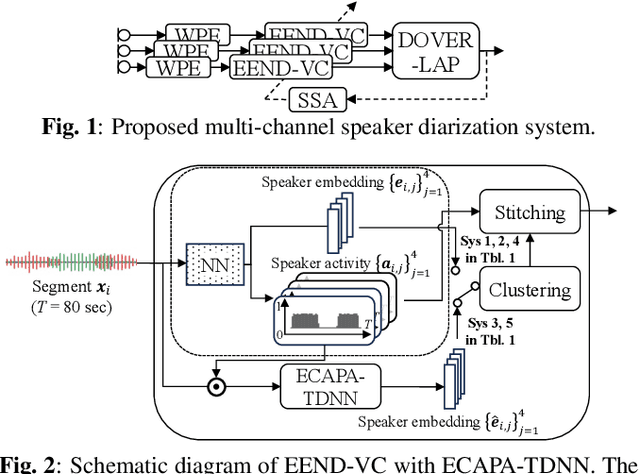
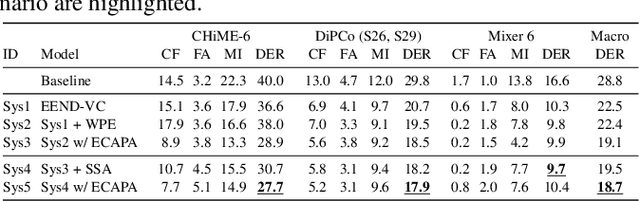
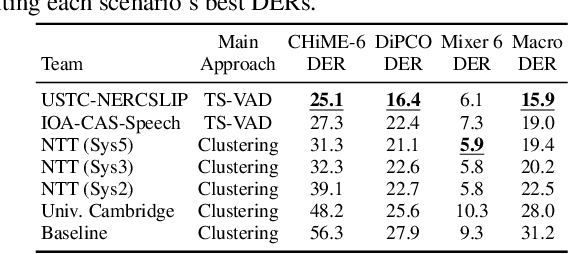
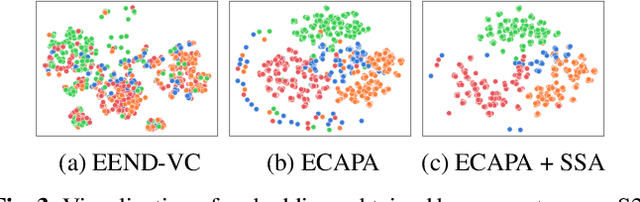
This paper details our speaker diarization system designed for multi-domain, multi-microphone casual conversations. The proposed diarization pipeline uses weighted prediction error (WPE)-based dereverberation as a front end, then applies end-to-end neural diarization with vector clustering (EEND-VC) to each channel separately. It integrates the diarization result obtained from each channel using diarization output voting error reduction plus overlap (DOVER-LAP). To harness the knowledge from the target domain and results integrated across all channels, we apply self-supervised adaptation for each session by retraining the EEND-VC with pseudo-labels derived from DOVER-LAP. The proposed system was incorporated into NTT's submission for the distant automatic speech recognition task in the CHiME-7 challenge. Our system achieved 65 % and 62 % relative improvements on development and eval sets compared to the organizer-provided VC-based baseline diarization system, securing third place in diarization performance.
Investigating End-to-End ASR Architectures for Long Form Audio Transcription
Sep 20, 2023
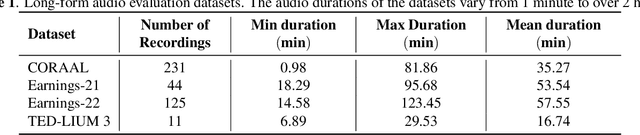


This paper presents an overview and evaluation of some of the end-to-end ASR models on long-form audios. We study three categories of Automatic Speech Recognition(ASR) models based on their core architecture: (1) convolutional, (2) convolutional with squeeze-and-excitation and (3) convolutional models with attention. We selected one ASR model from each category and evaluated Word Error Rate, maximum audio length and real-time factor for each model on a variety of long audio benchmarks: Earnings-21 and 22, CORAAL, and TED-LIUM3. The model from the category of self-attention with local attention and global token has the best accuracy comparing to other architectures. We also compared models with CTC and RNNT decoders and showed that CTC-based models are more robust and efficient than RNNT on long form audio.
Evaluating raw waveforms with deep learning frameworks for speech emotion recognition
Jul 06, 2023
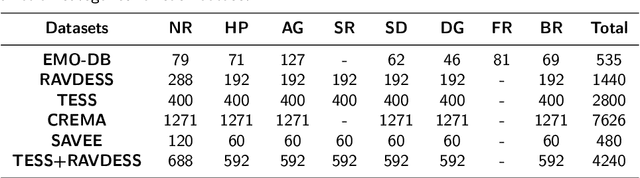
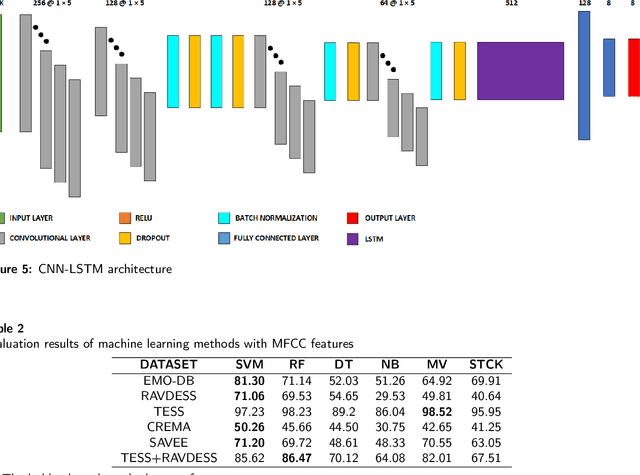
Speech emotion recognition is a challenging task in speech processing field. For this reason, feature extraction process has a crucial importance to demonstrate and process the speech signals. In this work, we represent a model, which feeds raw audio files directly into the deep neural networks without any feature extraction stage for the recognition of emotions utilizing six different data sets, EMO-DB, RAVDESS, TESS, CREMA, SAVEE, and TESS+RAVDESS. To demonstrate the contribution of proposed model, the performance of traditional feature extraction techniques namely, mel-scale spectogram, mel-frequency cepstral coefficients, are blended with machine learning algorithms, ensemble learning methods, deep and hybrid deep learning techniques. Support vector machine, decision tree, naive Bayes, random forests models are evaluated as machine learning algorithms while majority voting and stacking methods are assessed as ensemble learning techniques. Moreover, convolutional neural networks, long short-term memory networks, and hybrid CNN- LSTM model are evaluated as deep learning techniques and compared with machine learning and ensemble learning methods. To demonstrate the effectiveness of proposed model, the comparison with state-of-the-art studies are carried out. Based on the experiment results, CNN model excels existent approaches with 95.86% of accuracy for TESS+RAVDESS data set using raw audio files, thence determining the new state-of-the-art. The proposed model performs 90.34% of accuracy for EMO-DB with CNN model, 90.42% of accuracy for RAVDESS with CNN model, 99.48% of accuracy for TESS with LSTM model, 69.72% of accuracy for CREMA with CNN model, 85.76% of accuracy for SAVEE with CNN model in speaker-independent audio categorization problems.
UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
Jun 18, 2023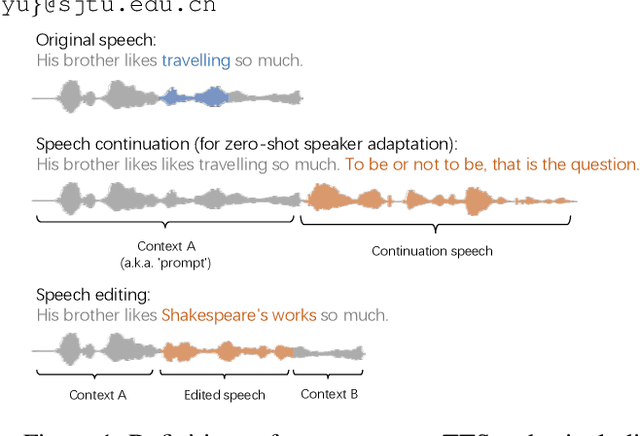

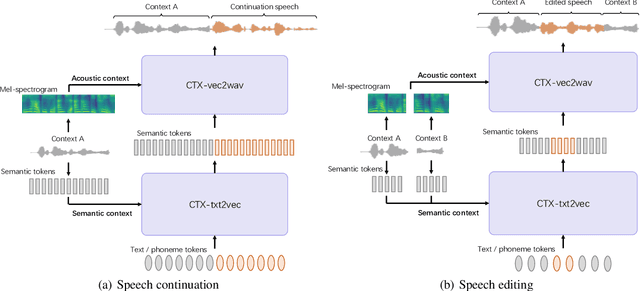

The utilization of discrete speech tokens, divided into semantic tokens and acoustic tokens, has been proven superior to traditional acoustic feature mel-spectrograms in terms of naturalness and robustness for text-to-speech (TTS) synthesis. Recent popular models, such as VALL-E and SPEAR-TTS, allow zero-shot speaker adaptation through auto-regressive (AR) continuation of acoustic tokens extracted from a short speech prompt. However, these AR models are restricted to generate speech only in a left-to-right direction, making them unsuitable for speech editing where both preceding and following contexts are provided. Furthermore, these models rely on acoustic tokens, which have audio quality limitations imposed by the performance of audio codec models. In this study, we propose a unified context-aware TTS framework called UniCATS, which is capable of both speech continuation and editing. UniCATS comprises two components, an acoustic model CTX-txt2vec and a vocoder CTX-vec2wav. CTX-txt2vec employs contextual VQ-diffusion to predict semantic tokens from the input text, enabling it to incorporate the semantic context and maintain seamless concatenation with the surrounding context. Following that, CTX-vec2wav utilizes contextual vocoding to convert these semantic tokens into waveforms, taking into consideration the acoustic context. Our experimental results demonstrate that CTX-vec2wav outperforms HifiGAN and AudioLM in terms of speech resynthesis from semantic tokens. Moreover, we show that UniCATS achieves state-of-the-art performance in both speech continuation and editing.
Improved Cross-Lingual Transfer Learning For Automatic Speech Translation
Jun 01, 2023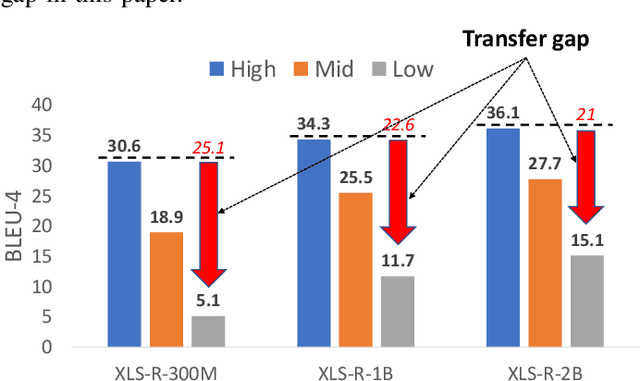
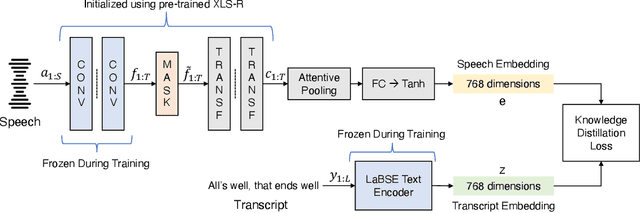
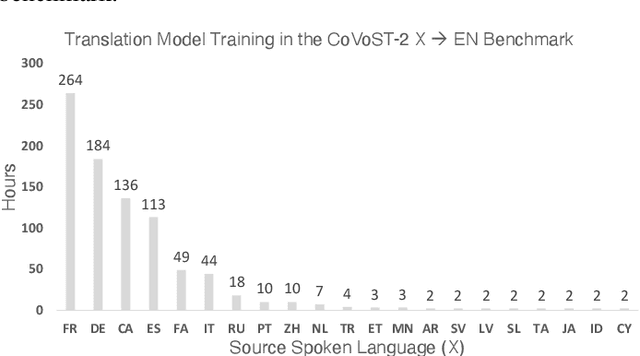
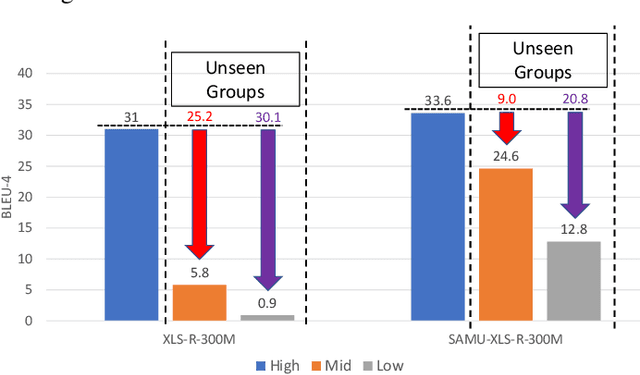
Research in multilingual speech-to-text translation is topical. Having a single model that supports multiple translation tasks is desirable. The goal of this work it to improve cross-lingual transfer learning in multilingual speech-to-text translation via semantic knowledge distillation. We show that by initializing the encoder of the encoder-decoder sequence-to-sequence translation model with SAMU-XLS-R, a multilingual speech transformer encoder trained using multi-modal (speech-text) semantic knowledge distillation, we achieve significantly better cross-lingual task knowledge transfer than the baseline XLS-R, a multilingual speech transformer encoder trained via self-supervised learning. We demonstrate the effectiveness of our approach on two popular datasets, namely, CoVoST-2 and Europarl. On the 21 translation tasks of the CoVoST-2 benchmark, we achieve an average improvement of 12.8 BLEU points over the baselines. In the zero-shot translation scenario, we achieve an average gain of 18.8 and 11.9 average BLEU points on unseen medium and low-resource languages. We make similar observations on Europarl speech translation benchmark.
EMoG: Synthesizing Emotive Co-speech 3D Gesture with Diffusion Model
Jun 20, 2023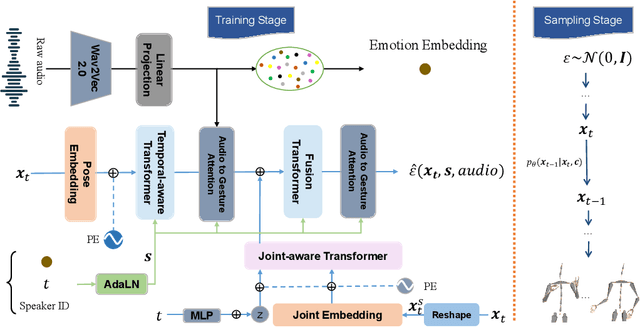
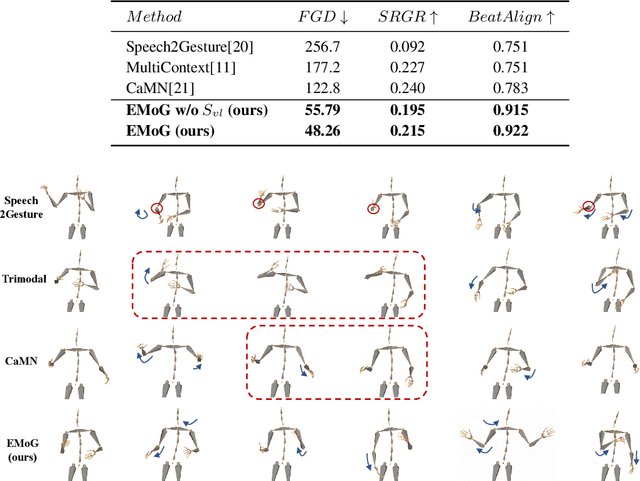
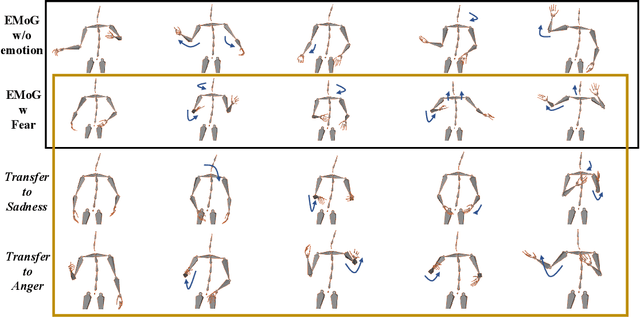
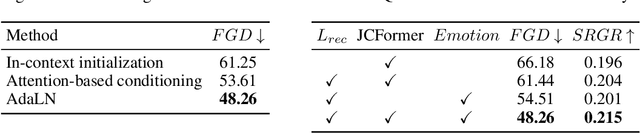
Although previous co-speech gesture generation methods are able to synthesize motions in line with speech content, it is still not enough to handle diverse and complicated motion distribution. The key challenges are: 1) the one-to-many nature between the speech content and gestures; 2) the correlation modeling between the body joints. In this paper, we present a novel framework (EMoG) to tackle the above challenges with denoising diffusion models: 1) To alleviate the one-to-many problem, we incorporate emotion clues to guide the generation process, making the generation much easier; 2) To model joint correlation, we propose to decompose the difficult gesture generation into two sub-problems: joint correlation modeling and temporal dynamics modeling. Then, the two sub-problems are explicitly tackled with our proposed Joint Correlation-aware transFormer (JCFormer). Through extensive evaluations, we demonstrate that our proposed method surpasses previous state-of-the-art approaches, offering substantial superiority in gesture synthesis.
MiniSUPERB: Lightweight Benchmark for Self-supervised Speech Models
May 30, 2023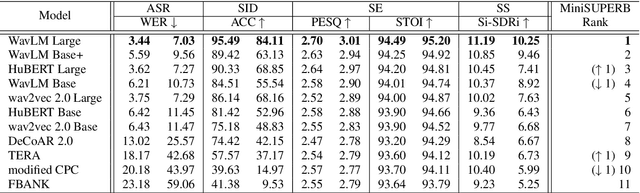
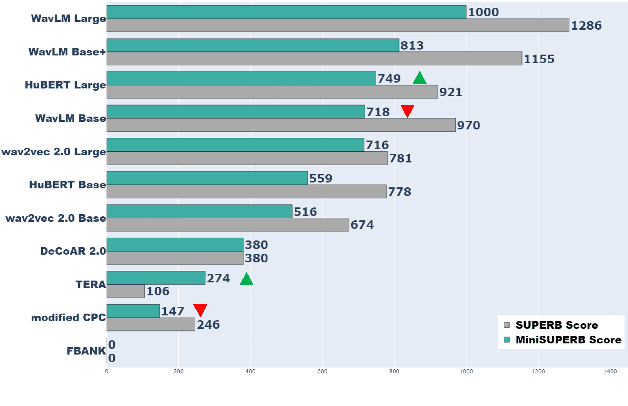
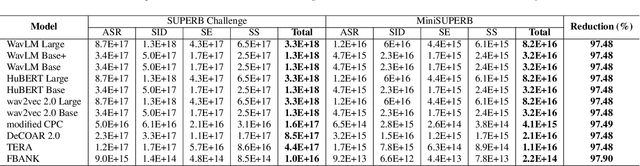
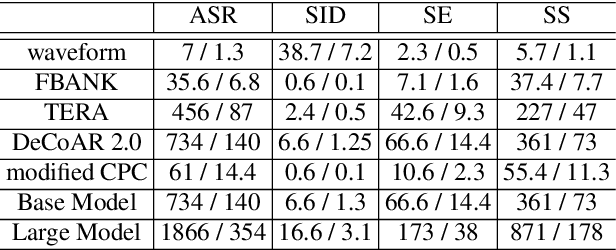
Self-supervised learning (SSL) is a popular research topic in speech processing. Successful SSL speech models must generalize well. SUPERB was proposed to evaluate the ability of SSL speech models across many speech tasks. However, due to the diversity of tasks, the evaluation process requires huge computational costs. We present MiniSUPERB, a lightweight benchmark that efficiently evaluates SSL speech models with comparable results to SUPERB while greatly reducing the computational cost. We select representative tasks and sample datasets and extract model representation offline, achieving 0.954 and 0.982 Spearman's rank correlation with SUPERB Paper and SUPERB Challenge, respectively. In the meanwhile, the computational cost is reduced by 97% in regard to MACs (number of Multiply-ACcumulate operations) in the tasks we choose. To the best of our knowledge, this is the first study to examine not only the computational cost of a model itself but the cost of evaluating it on a benchmark.
In-Ear-Voice: Towards Milli-Watt Audio Enhancement With Bone-Conduction Microphones for In-Ear Sensing Platforms
Sep 05, 2023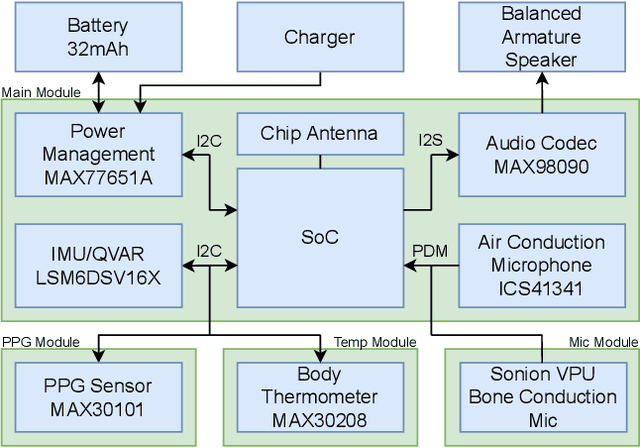
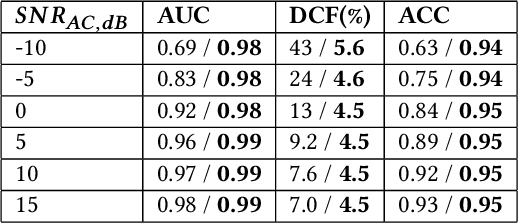
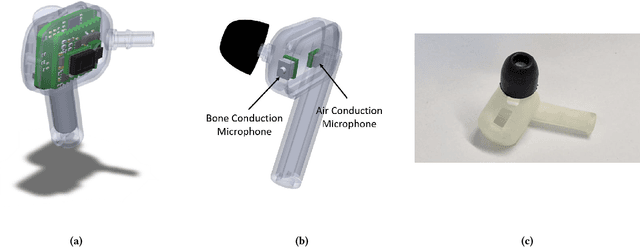
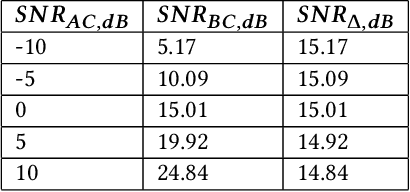
The recent ubiquitous adoption of remote conferencing has been accompanied by omnipresent frustration with distorted or otherwise unclear voice communication. Audio enhancement can compensate for low-quality input signals from, for example, small true wireless earbuds, by applying noise suppression techniques. Such processing relies on voice activity detection (VAD) with low latency and the added capability of discriminating the wearer's voice from others - a task of significant computational complexity. The tight energy budget of devices as small as modern earphones, however, requires any system attempting to tackle this problem to do so with minimal power and processing overhead, while not relying on speaker-specific voice samples and training due to usability concerns. This paper presents the design and implementation of a custom research platform for low-power wireless earbuds based on novel, commercial, MEMS bone-conduction microphones. Such microphones can record the wearer's speech with much greater isolation, enabling personalized voice activity detection and further audio enhancement applications. Furthermore, the paper accurately evaluates a proposed low-power personalized speech detection algorithm based on bone conduction data and a recurrent neural network running on the implemented research platform. This algorithm is compared to an approach based on traditional microphone input. The performance of the bone conduction system, achieving detection of speech within 12.8ms at an accuracy of 95\% is evaluated. Different SoC choices are contrasted, with the final implementation based on the cutting-edge Ambiq Apollo 4 Blue SoC achieving 2.64mW average power consumption at 14uJ per inference, reaching 43h of battery life on a miniature 32mAh li-ion cell and without duty cycling.