 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Uncovering Political Hate Speech During Indian Election Campaign: A New Low-Resource Dataset and Baselines
Jun 27, 2023
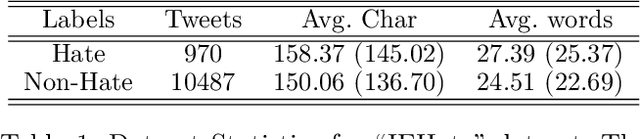
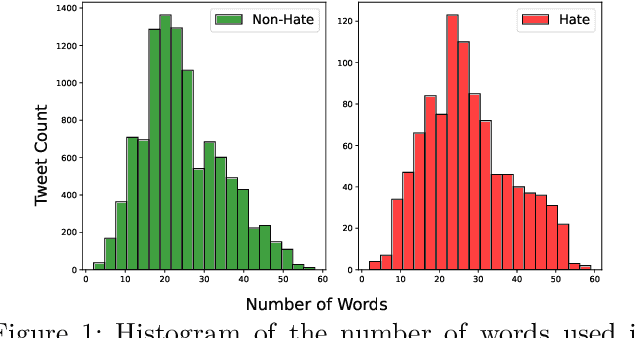

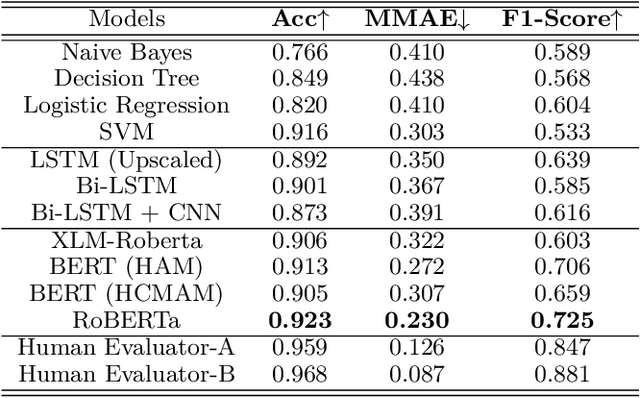
The detection of hate speech in political discourse is a critical issue, and this becomes even more challenging in low-resource languages. To address this issue, we introduce a new dataset named IEHate, which contains 11,457 manually annotated Hindi tweets related to the Indian Assembly Election Campaign from November 1, 2021, to March 9, 2022. We performed a detailed analysis of the dataset, focusing on the prevalence of hate speech in political communication and the different forms of hateful language used. Additionally, we benchmark the dataset using a range of machine learning, deep learning, and transformer-based algorithms. Our experiments reveal that the performance of these models can be further improved, highlighting the need for more advanced techniques for hate speech detection in low-resource languages. In particular, the relatively higher score of human evaluation over algorithms emphasizes the importance of utilizing both human and automated approaches for effective hate speech moderation. Our IEHate dataset can serve as a valuable resource for researchers and practitioners working on developing and evaluating hate speech detection techniques in low-resource languages. Overall, our work underscores the importance of addressing the challenges of identifying and mitigating hate speech in political discourse, particularly in the context of low-resource languages. The dataset and resources for this work are made available at https://github.com/Farhan-jafri/Indian-Election.
Fake the Real: Backdoor Attack on Deep Speech Classification via Voice Conversion
Jun 28, 2023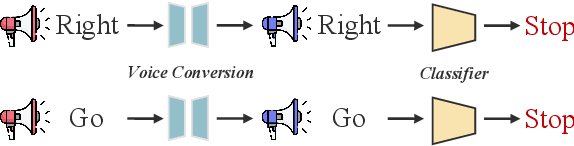
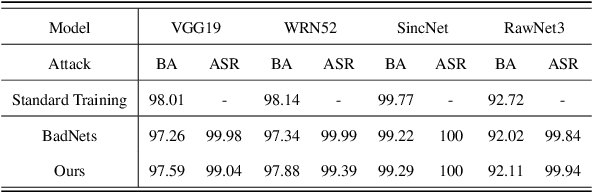
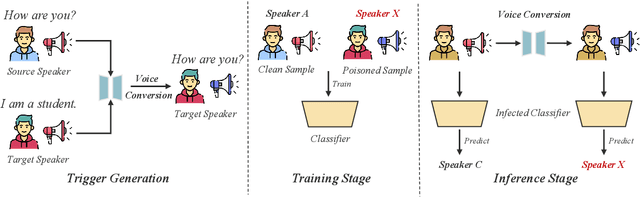

Deep speech classification has achieved tremendous success and greatly promoted the emergence of many real-world applications. However, backdoor attacks present a new security threat to it, particularly with untrustworthy third-party platforms, as pre-defined triggers set by the attacker can activate the backdoor. Most of the triggers in existing speech backdoor attacks are sample-agnostic, and even if the triggers are designed to be unnoticeable, they can still be audible. This work explores a backdoor attack that utilizes sample-specific triggers based on voice conversion. Specifically, we adopt a pre-trained voice conversion model to generate the trigger, ensuring that the poisoned samples does not introduce any additional audible noise. Extensive experiments on two speech classification tasks demonstrate the effectiveness of our attack. Furthermore, we analyzed the specific scenarios that activated the proposed backdoor and verified its resistance against fine-tuning.
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
Jun 25, 2023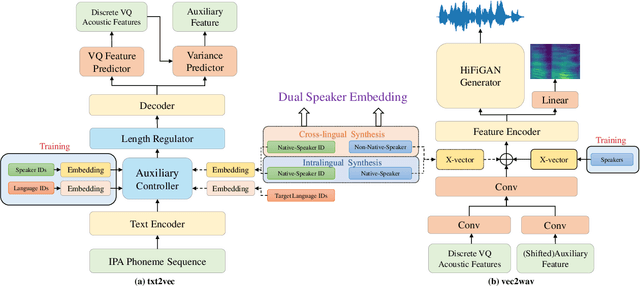
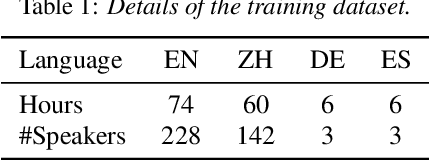
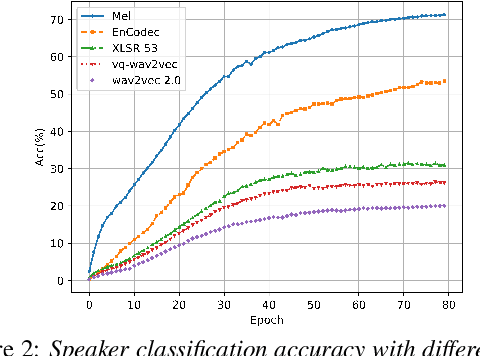
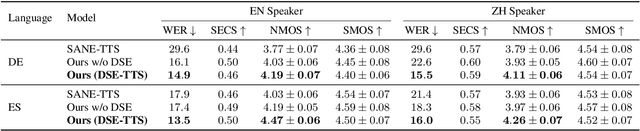
Although high-fidelity speech can be obtained for intralingual speech synthesis, cross-lingual text-to-speech (CTTS) is still far from satisfactory as it is difficult to accurately retain the speaker timbres(i.e. speaker similarity) and eliminate the accents from their first language(i.e. nativeness). In this paper, we demonstrated that vector-quantized(VQ) acoustic feature contains less speaker information than mel-spectrogram. Based on this finding, we propose a novel dual speaker embedding TTS (DSE-TTS) framework for CTTS with authentic speaking style. Here, one embedding is fed to the acoustic model to learn the linguistic speaking style, while the other one is integrated into the vocoder to mimic the target speaker's timbre. Experiments show that by combining both embeddings, DSE-TTS significantly outperforms the state-of-the-art SANE-TTS in cross-lingual synthesis, especially in terms of nativeness.
Adapting Text-based Dialogue State Tracker for Spoken Dialogues
Aug 30, 2023
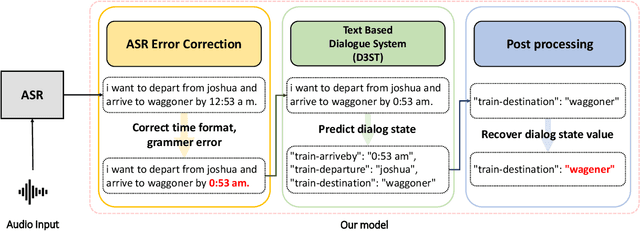
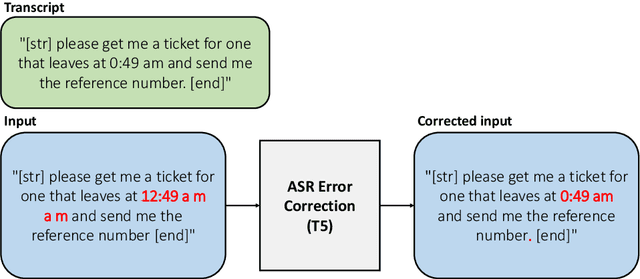

Although there have been remarkable advances in dialogue systems through the dialogue systems technology competition (DSTC), it remains one of the key challenges to building a robust task-oriented dialogue system with a speech interface. Most of the progress has been made for text-based dialogue systems since there are abundant datasets with written corpora while those with spoken dialogues are very scarce. However, as can be seen from voice assistant systems such as Siri and Alexa, it is of practical importance to transfer the success to spoken dialogues. In this paper, we describe our engineering effort in building a highly successful model that participated in the speech-aware dialogue systems technology challenge track in DSTC11. Our model consists of three major modules: (1) automatic speech recognition error correction to bridge the gap between the spoken and the text utterances, (2) text-based dialogue system (D3ST) for estimating the slots and values using slot descriptions, and (3) post-processing for recovering the error of the estimated slot value. Our experiments show that it is important to use an explicit automatic speech recognition error correction module, post-processing, and data augmentation to adapt a text-based dialogue state tracker for spoken dialogue corpora.
Employing Real Training Data for Deep Noise Suppression
Sep 05, 2023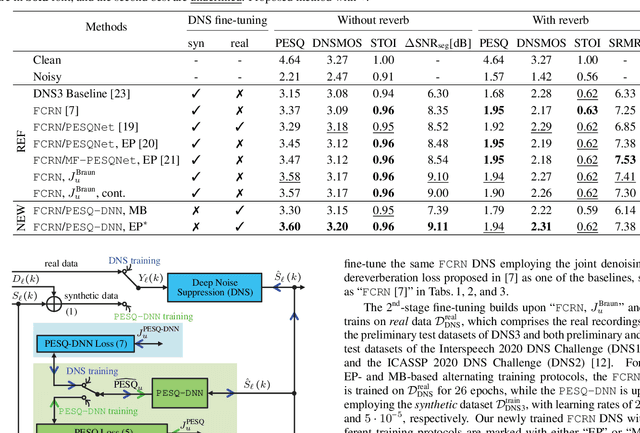
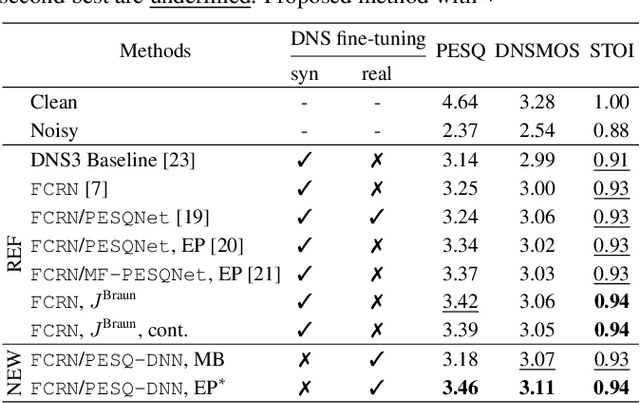
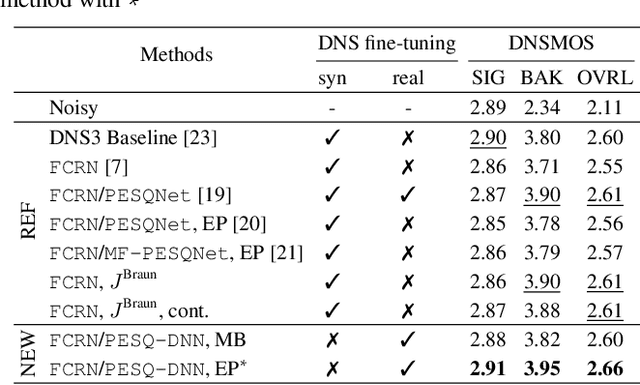
Most deep noise suppression (DNS) models are trained with reference-based losses requiring access to clean speech. However, sometimes an additive microphone model is insufficient for real-world applications. Accordingly, ways to use real training data in supervised learning for DNS models promise to reduce a potential training/inference mismatch. Employing real data for DNS training requires either generative approaches or a reference-free loss without access to the corresponding clean speech. In this work, we propose to employ an end-to-end non-intrusive deep neural network (DNN), named PESQ-DNN, to estimate perceptual evaluation of speech quality (PESQ) scores of enhanced real data. It provides a reference-free perceptual loss for employing real data during DNS training, maximizing the PESQ scores. Furthermore, we use an epoch-wise alternating training protocol, updating the DNS model on real data, followed by PESQ-DNN updating on synthetic data. The DNS model trained with the PESQ-DNN employing real data outperforms all reference methods employing only synthetic training data. On synthetic test data, our proposed method excels the Interspeech 2021 DNS Challenge baseline by a significant 0.32 PESQ points. Both on synthetic and real test data, the proposed method beats the baseline by 0.05 DNSMOS points - although PESQ-DNN optimizes for a different perceptual metric.
The Art of Embedding Fusion: Optimizing Hate Speech Detection
Jun 26, 2023
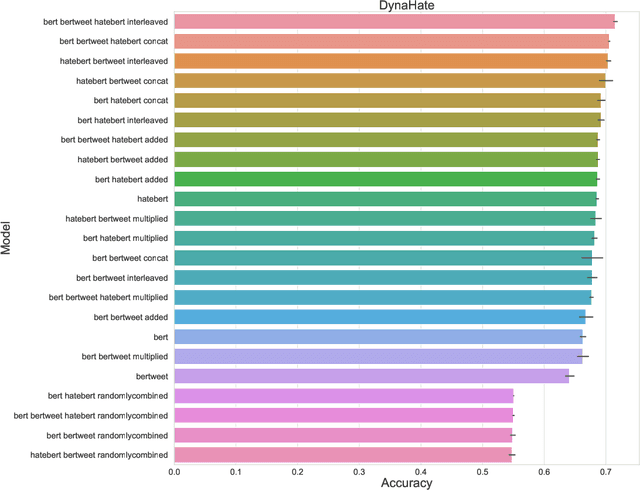


Hate speech detection is a challenging natural language processing task that requires capturing linguistic and contextual nuances. Pre-trained language models (PLMs) offer rich semantic representations of text that can improve this task. However there is still limited knowledge about ways to effectively combine representations across PLMs and leverage their complementary strengths. In this work, we shed light on various combination techniques for several PLMs and comprehensively analyze their effectiveness. Our findings show that combining embeddings leads to slight improvements but at a high computational cost and the choice of combination has marginal effect on the final outcome. We also make our codebase public at https://github.com/aflah02/The-Art-of-Embedding-Fusion-Optimizing-Hate-Speech-Detection .
Simultaneously Learning Speaker's Direction and Head Orientation from Binaural Recordings
Sep 26, 2023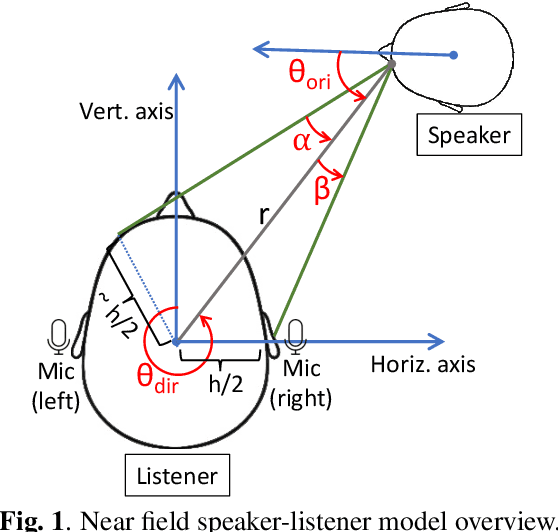
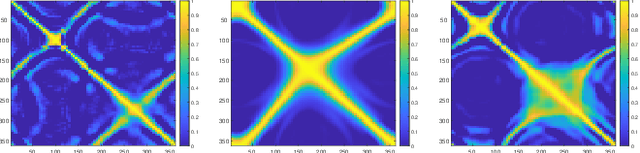
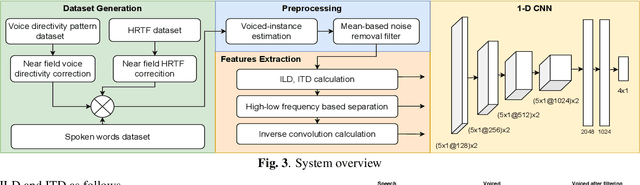
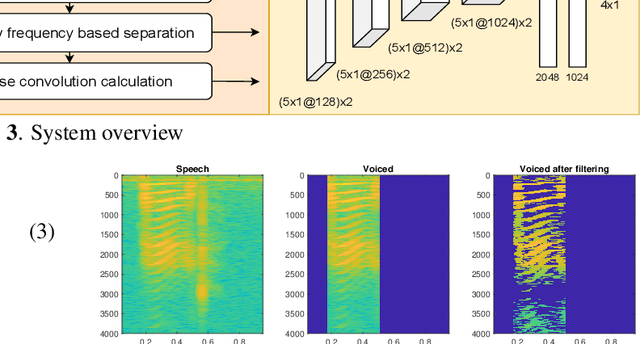
Estimation of a speaker's direction and head orientation with binaural recordings can be a critical piece of information in many real-world applications with emerging `earable' devices, including smart headphones and AR/VR headsets. However, it requires predicting the mutual head orientations of both the speaker and the listener, which is challenging in practice. This paper presents a system for jointly predicting speaker-listener head orientations by leveraging inherent human voice directivity and listener's head-related transfer function (HRTF) as perceived by the ear-mounted microphones on the listener. We propose a convolution neural network model that, given binaural speech recording, can predict the orientation of both speaker and listener with respect to the line joining the two. The system builds on the core observation that the recordings from the left and right ears are differentially affected by the voice directivity as well as the HRTF. We also incorporate the fact that voice is more directional at higher frequencies compared to lower frequencies.
A multi-modal approach for identifying schizophrenia using cross-modal attention
Sep 26, 2023This study focuses on how different modalities of human communication can be used to distinguish between healthy controls and subjects with schizophrenia who exhibit strong positive symptoms. We developed a multi-modal schizophrenia classification system using audio, video, and text. Facial action units and vocal tract variables were extracted as low-level features from video and audio respectively, which were then used to compute high-level coordination features that served as the inputs to the audio and video modalities. Context-independent text embeddings extracted from transcriptions of speech were used as the input for the text modality. The multi-modal system is developed by fusing a segment-to-session-level classifier for video and audio modalities with a text model based on a Hierarchical Attention Network (HAN) with cross-modal attention. The proposed multi-modal system outperforms the previous state-of-the-art multi-modal system by 8.53% in the weighted average F1 score.
Big model only for hard audios: Sample dependent Whisper model selection for efficient inferences
Sep 22, 2023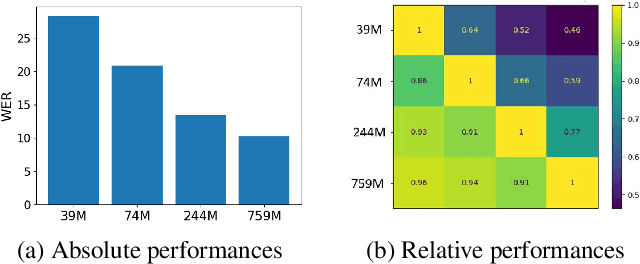

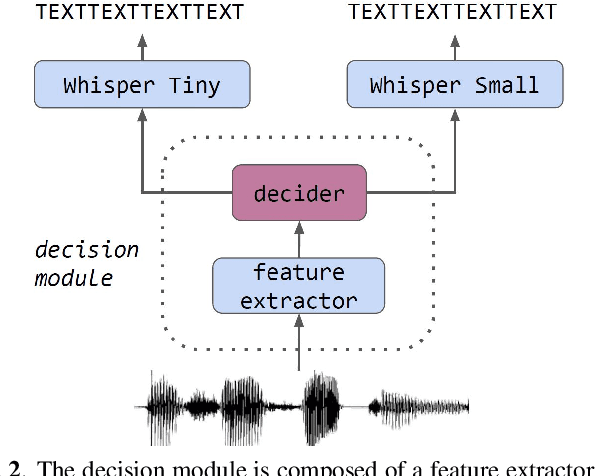
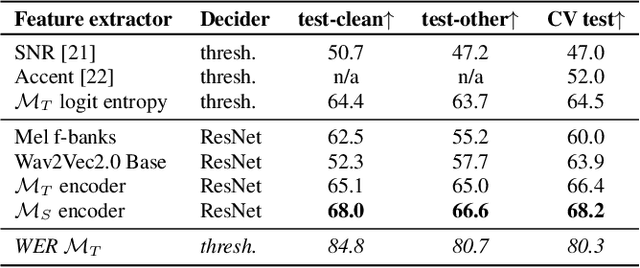
Recent progress in Automatic Speech Recognition (ASR) has been coupled with a substantial increase in the model sizes, which may now contain billions of parameters, leading to slow inferences even with adapted hardware. In this context, several ASR models exist in various sizes, with different inference costs leading to different performance levels. Based on the observation that smaller models perform optimally on large parts of testing corpora, we propose to train a decision module, that would allow, given an audio sample, to use the smallest sufficient model leading to a good transcription. We apply our approach to two Whisper models with different sizes. By keeping the decision process computationally efficient, we build a decision module that allows substantial computational savings with reduced performance drops.
Masked Modeling Duo for Speech: Specializing General-Purpose Audio Representation to Speech using Denoising Distillation
May 23, 2023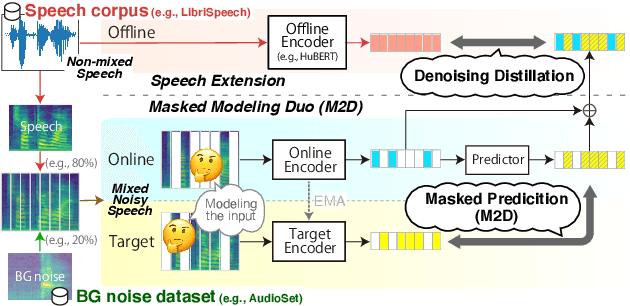

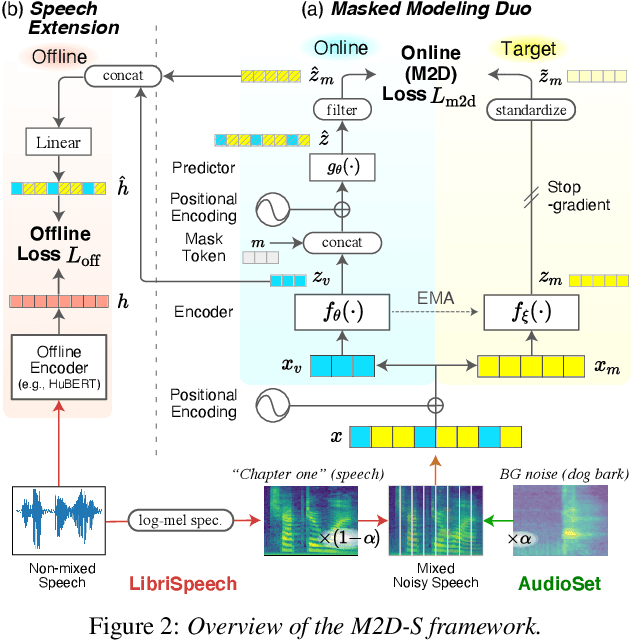
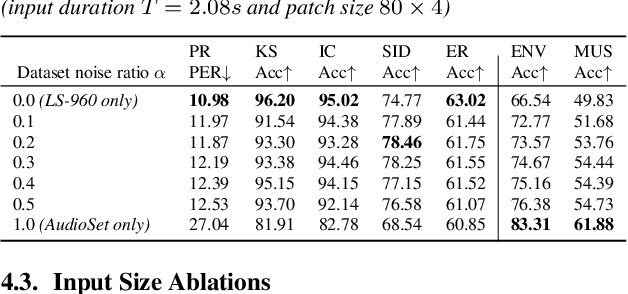
Self-supervised learning general-purpose audio representations have demonstrated high performance in a variety of tasks. Although they can be optimized for application by fine-tuning, even higher performance can be expected if they can be specialized to pre-train for an application. This paper explores the challenges and solutions in specializing general-purpose audio representations for a specific application using speech, a highly demanding field, as an example. We enhance Masked Modeling Duo (M2D), a general-purpose model, to close the performance gap with state-of-the-art (SOTA) speech models. To do so, we propose a new task, denoising distillation, to learn from fine-grained clustered features, and M2D for Speech (M2D-S), which jointly learns the denoising distillation task and M2D masked prediction task. Experimental results show that M2D-S performs comparably to or outperforms SOTA speech models on the SUPERB benchmark, demonstrating that M2D can specialize in a demanding field. Our code is available at: https://github.com/nttcslab/m2d/tree/master/speech