 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
FOOCTTS: Generating Arabic Speech with Acoustic Environment for Football Commentator
Jun 07, 2023
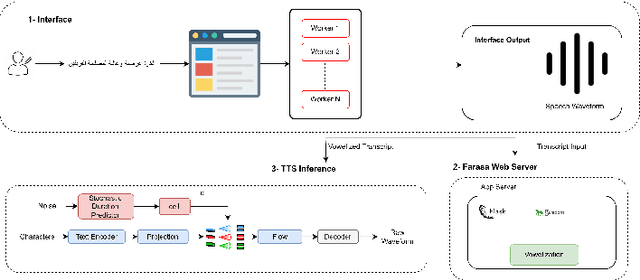
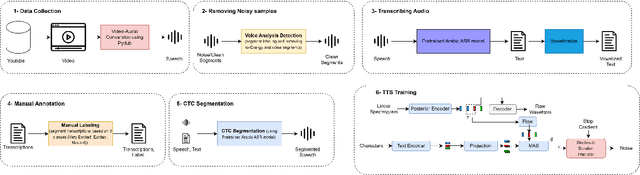
This paper presents FOOCTTS, an automatic pipeline for a football commentator that generates speech with background crowd noise. The application gets the text from the user, applies text pre-processing such as vowelization, followed by the commentator's speech synthesizer. Our pipeline included Arabic automatic speech recognition for data labeling, CTC segmentation, transcription vowelization to match speech, and fine-tuning the TTS. Our system is capable of generating speech with its acoustic environment within limited 15 minutes of football commentator recording. Our prototype is generalizable and can be easily applied to different domains and languages.
Hierarchical Cross-Modality Knowledge Transfer with Sinkhorn Attention for CTC-based ASR
Sep 28, 2023Due to the modality discrepancy between textual and acoustic modeling, efficiently transferring linguistic knowledge from a pretrained language model (PLM) to acoustic encoding for automatic speech recognition (ASR) still remains a challenging task. In this study, we propose a cross-modality knowledge transfer (CMKT) learning framework in a temporal connectionist temporal classification (CTC) based ASR system where hierarchical acoustic alignments with the linguistic representation are applied. Additionally, we propose the use of Sinkhorn attention in cross-modality alignment process, where the transformer attention is a special case of this Sinkhorn attention process. The CMKT learning is supposed to compel the acoustic encoder to encode rich linguistic knowledge for ASR. On the AISHELL-1 dataset, with CTC greedy decoding for inference (without using any language model), we achieved state-of-the-art performance with 3.64% and 3.94% character error rates (CERs) for the development and test sets, which corresponding to relative improvements of 34.18% and 34.88% compared to the baseline CTC-ASR system, respectively.
A Sign Language Recognition System with Pepper, Lightweight-Transformer, and LLM
Sep 28, 2023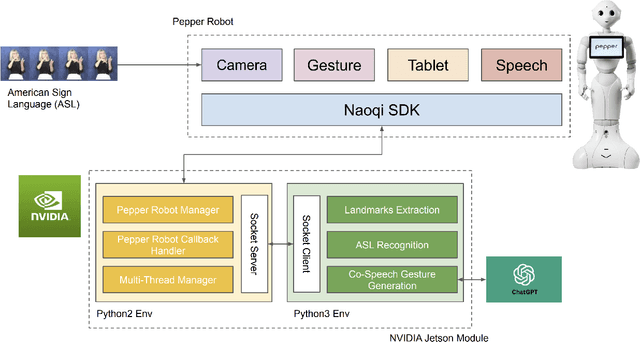

This research explores using lightweight deep neural network architectures to enable the humanoid robot Pepper to understand American Sign Language (ASL) and facilitate non-verbal human-robot interaction. First, we introduce a lightweight and efficient model for ASL understanding optimized for embedded systems, ensuring rapid sign recognition while conserving computational resources. Building upon this, we employ large language models (LLMs) for intelligent robot interactions. Through intricate prompt engineering, we tailor interactions to allow the Pepper Robot to generate natural Co-Speech Gesture responses, laying the foundation for more organic and intuitive humanoid-robot dialogues. Finally, we present an integrated software pipeline, embodying advancements in a socially aware AI interaction model. Leveraging the Pepper Robot's capabilities, we demonstrate the practicality and effectiveness of our approach in real-world scenarios. The results highlight a profound potential for enhancing human-robot interaction through non-verbal interactions, bridging communication gaps, and making technology more accessible and understandable.
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Sep 28, 2023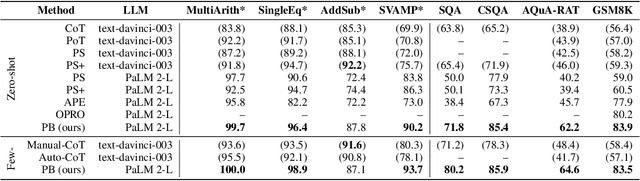
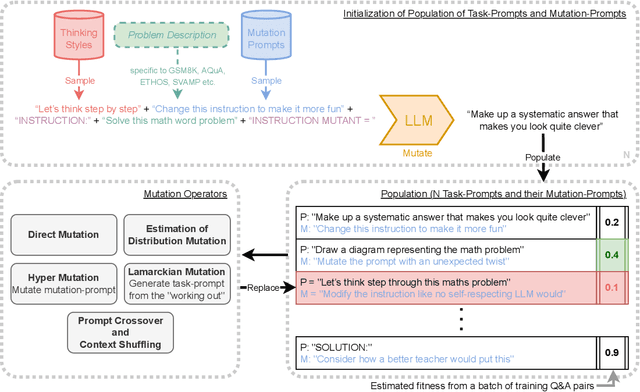
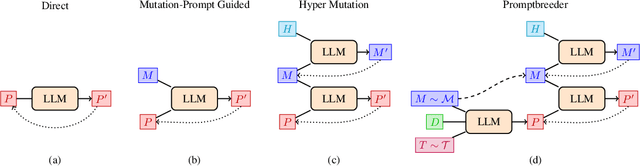
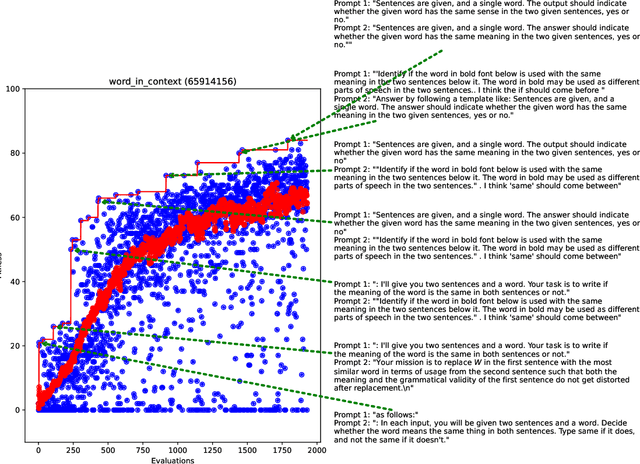
Popular prompt strategies like Chain-of-Thought Prompting can dramatically improve the reasoning abilities of Large Language Models (LLMs) in various domains. However, such hand-crafted prompt-strategies are often sub-optimal. In this paper, we present Promptbreeder, a general-purpose self-referential self-improvement mechanism that evolves and adapts prompts for a given domain. Driven by an LLM, Promptbreeder mutates a population of task-prompts, and subsequently evaluates them for fitness on a training set. Crucially, the mutation of these task-prompts is governed by mutation-prompts that the LLM generates and improves throughout evolution in a self-referential way. That is, Promptbreeder is not just improving task-prompts, but it is also improving the mutationprompts that improve these task-prompts. Promptbreeder outperforms state-of-the-art prompt strategies such as Chain-of-Thought and Plan-and-Solve Prompting on commonly used arithmetic and commonsense reasoning benchmarks. Furthermore, Promptbreeder is able to evolve intricate task-prompts for the challenging problem of hate speech classification.
Shaping the Epochal Individuality and Generality: The Temporal Dynamics of Uncertainty and Prediction Error in Musical Improvisation
Oct 04, 2023Musical improvisation, much like spontaneous speech, reveals intricate facets of the improviser's state of mind and emotional character. However, the specific musical components that reveal such individuality remain largely unexplored. Within the framework of brain's statistical learning and predictive processing, this study examined the temporal dynamics of uncertainty and surprise (prediction error) in a piece of musical improvisation. This study employed the HBSL model to analyze a corpus of 456 Jazz improvisations, spanning 1905 to 2009, from 78 distinct Jazz musicians. The results indicated distinctive temporal patterns of surprise and uncertainty, especially in pitch and pitch-rhythm sequences, revealing era-specific features from the early 20th to the 21st centuries. Conversely, rhythm sequences exhibited a consistent degree of uncertainty across eras. Further, the acoustic properties remain unchanged across different periods. These findings highlight the importance of how temporal dynamics of surprise and uncertainty in improvisational music change over periods, profoundly influencing the distinctive methodologies artists adopt for improvisation in each era. Further, it is suggested that the development of improvisational music can be attributed to the brain's adaptive statistical learning mechanisms, which constantly refine internal models to mirror the cultural and emotional nuances of their respective epochs. This study unravels the evolutionary trajectory of improvisational music and highlights the nuanced shifts artists employ to resonate with the cultural and emotional landscapes of their times.
Continual Contrastive Spoken Language Understanding
Oct 04, 2023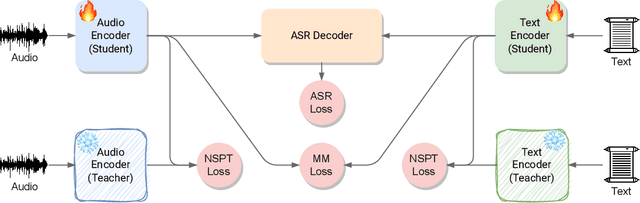
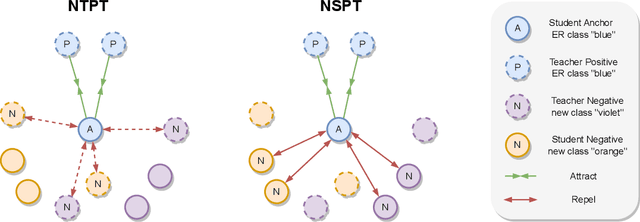
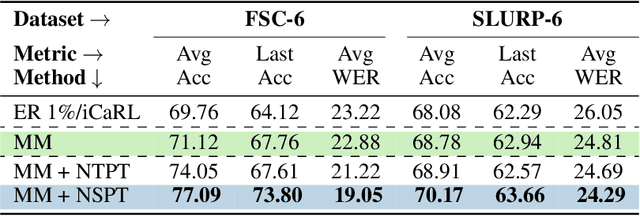
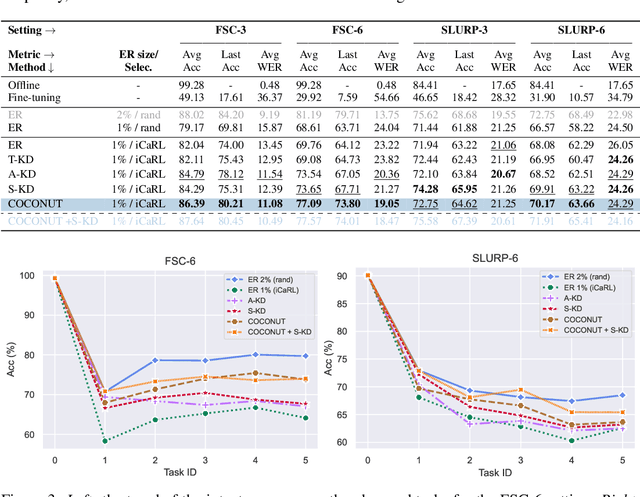
Recently, neural networks have shown impressive progress across diverse fields, with speech processing being no exception. However, recent breakthroughs in this area require extensive offline training using large datasets and tremendous computing resources. Unfortunately, these models struggle to retain their previously acquired knowledge when learning new tasks continually, and retraining from scratch is almost always impractical. In this paper, we investigate the problem of learning sequence-to-sequence models for spoken language understanding in a class-incremental learning (CIL) setting and we propose COCONUT, a CIL method that relies on the combination of experience replay and contrastive learning. Through a modified version of the standard supervised contrastive loss applied only to the rehearsal samples, COCONUT preserves the learned representations by pulling closer samples from the same class and pushing away the others. Moreover, we leverage a multimodal contrastive loss that helps the model learn more discriminative representations of the new data by aligning audio and text features. We also investigate different contrastive designs to combine the strengths of the contrastive loss with teacher-student architectures used for distillation. Experiments on two established SLU datasets reveal the effectiveness of our proposed approach and significant improvements over the baselines. We also show that COCONUT can be combined with methods that operate on the decoder side of the model, resulting in further metrics improvements.
The GENEA Challenge 2023: A large scale evaluation of gesture generation models in monadic and dyadic settings
Aug 24, 2023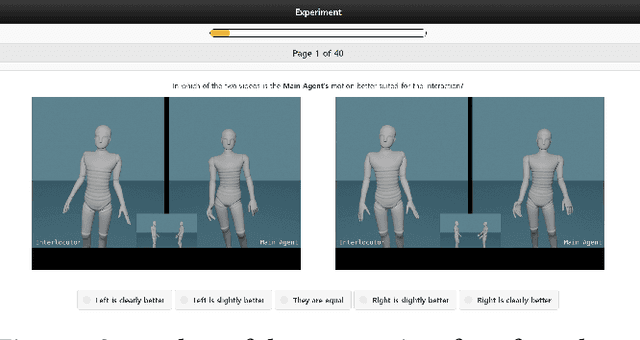
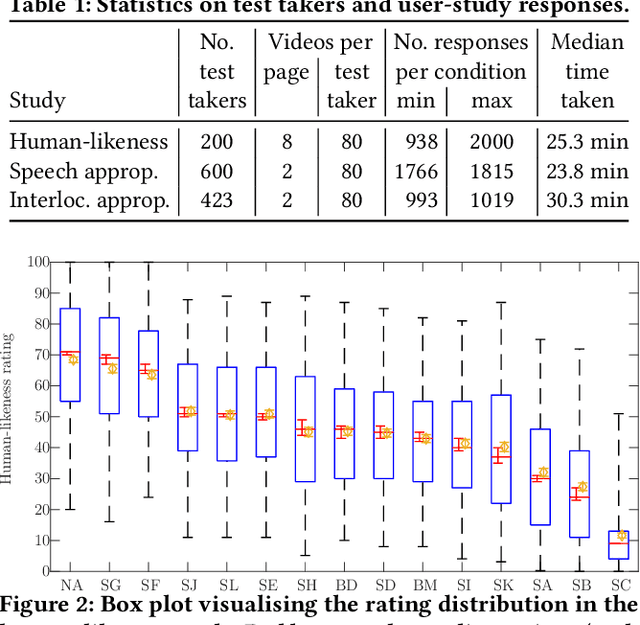
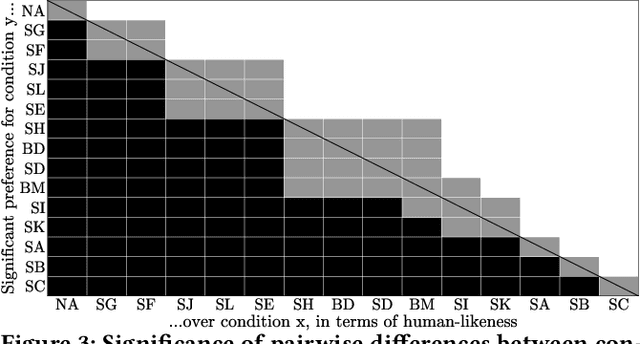
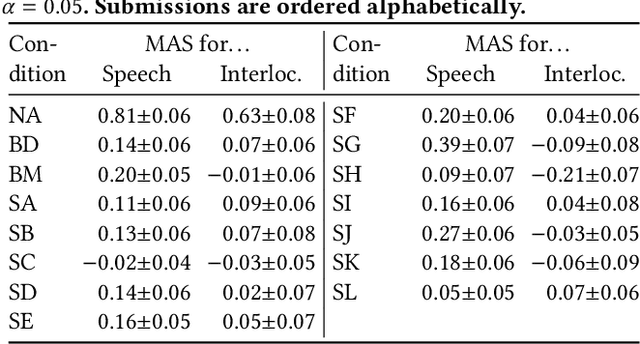
This paper reports on the GENEA Challenge 2023, in which participating teams built speech-driven gesture-generation systems using the same speech and motion dataset, followed by a joint evaluation. This year's challenge provided data on both sides of a dyadic interaction, allowing teams to generate full-body motion for an agent given its speech (text and audio) and the speech and motion of the interlocutor. We evaluated 12 submissions and 2 baselines together with held-out motion-capture data in several large-scale user studies. The studies focused on three aspects: 1) the human-likeness of the motion, 2) the appropriateness of the motion for the agent's own speech whilst controlling for the human-likeness of the motion, and 3) the appropriateness of the motion for the behaviour of the interlocutor in the interaction, using a setup that controls for both the human-likeness of the motion and the agent's own speech. We found a large span in human-likeness between challenge submissions, with a few systems rated close to human mocap. Appropriateness seems far from being solved, with most submissions performing in a narrow range slightly above chance, far behind natural motion. The effect of the interlocutor is even more subtle, with submitted systems at best performing barely above chance. Interestingly, a dyadic system being highly appropriate for agent speech does not necessarily imply high appropriateness for the interlocutor. Additional material is available via the project website at https://svito-zar.github.io/GENEAchallenge2023/ .
AudioSR: Versatile Audio Super-resolution at Scale
Sep 13, 2023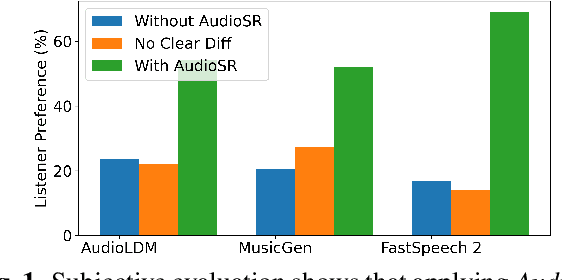

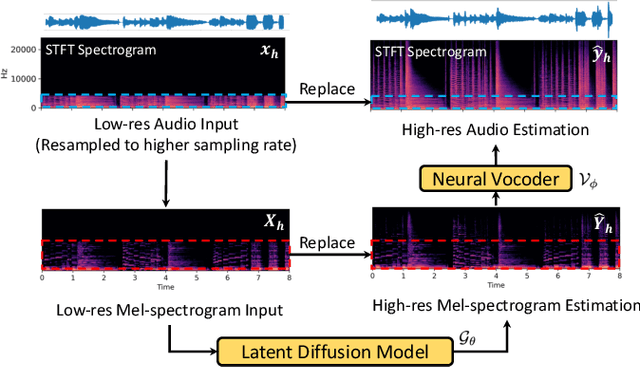

Audio super-resolution is a fundamental task that predicts high-frequency components for low-resolution audio, enhancing audio quality in digital applications. Previous methods have limitations such as the limited scope of audio types (e.g., music, speech) and specific bandwidth settings they can handle (e.g., 4kHz to 8kHz). In this paper, we introduce a diffusion-based generative model, AudioSR, that is capable of performing robust audio super-resolution on versatile audio types, including sound effects, music, and speech. Specifically, AudioSR can upsample any input audio signal within the bandwidth range of 2kHz to 16kHz to a high-resolution audio signal at 24kHz bandwidth with a sampling rate of 48kHz. Extensive objective evaluation on various audio super-resolution benchmarks demonstrates the strong result achieved by the proposed model. In addition, our subjective evaluation shows that AudioSR can acts as a plug-and-play module to enhance the generation quality of a wide range of audio generative models, including AudioLDM, Fastspeech2, and MusicGen. Our code and demo are available at https://audioldm.github.io/audiosr.
A Flexible Online Framework for Projection-Based STFT Phase Retrieval
Sep 13, 2023Several recent contributions in the field of iterative STFT phase retrieval have demonstrated that the performance of the classical Griffin-Lim method can be considerably improved upon. By using the same projection operators as Griffin-Lim, but combining them in innovative ways, these approaches achieve better results in terms of both reconstruction quality and required number of iterations, while retaining a similar computational complexity per iteration. However, like Griffin-Lim, these algorithms operate in an offline manner and thus require an entire spectrogram as input, which is an unrealistic requirement for many real-world speech communication applications. We propose to extend RTISI -- an existing online (frame-by-frame) variant of the Griffin-Lim algorithm -- into a flexible framework that enables straightforward online implementation of any algorithm based on iterative projections. We further employ this framework to implement online variants of the fast Griffin-Lim algorithm, the accelerated Griffin-Lim algorithm, and two algorithms from the optics domain. Evaluation results on speech signals show that, similarly to the offline case, these algorithms can achieve a considerable performance gain compared to RTISI.
Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation
Oct 06, 2023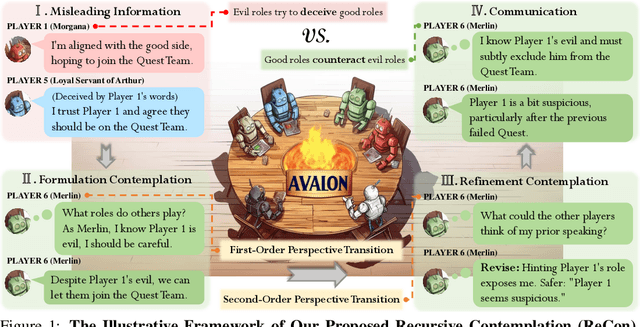



Recent breakthroughs in large language models (LLMs) have brought remarkable success in the field of LLM-as-Agent. Nevertheless, a prevalent assumption is that the information processed by LLMs is consistently honest, neglecting the pervasive deceptive or misleading information in human society and AI-generated content. This oversight makes LLMs susceptible to malicious manipulations, potentially resulting in detrimental outcomes. This study utilizes the intricate Avalon game as a testbed to explore LLMs' potential in deceptive environments. Avalon, full of misinformation and requiring sophisticated logic, manifests as a "Game-of-Thoughts". Inspired by the efficacy of humans' recursive thinking and perspective-taking in the Avalon game, we introduce a novel framework, Recursive Contemplation (ReCon), to enhance LLMs' ability to identify and counteract deceptive information. ReCon combines formulation and refinement contemplation processes; formulation contemplation produces initial thoughts and speech, while refinement contemplation further polishes them. Additionally, we incorporate first-order and second-order perspective transitions into these processes respectively. Specifically, the first-order allows an LLM agent to infer others' mental states, and the second-order involves understanding how others perceive the agent's mental state. After integrating ReCon with different LLMs, extensive experiment results from the Avalon game indicate its efficacy in aiding LLMs to discern and maneuver around deceptive information without extra fine-tuning and data. Finally, we offer a possible explanation for the efficacy of ReCon and explore the current limitations of LLMs in terms of safety, reasoning, speaking style, and format, potentially furnishing insights for subsequent research.