 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Use of Speech Impairment Severity for Dysarthric Speech Recognition
May 18, 2023
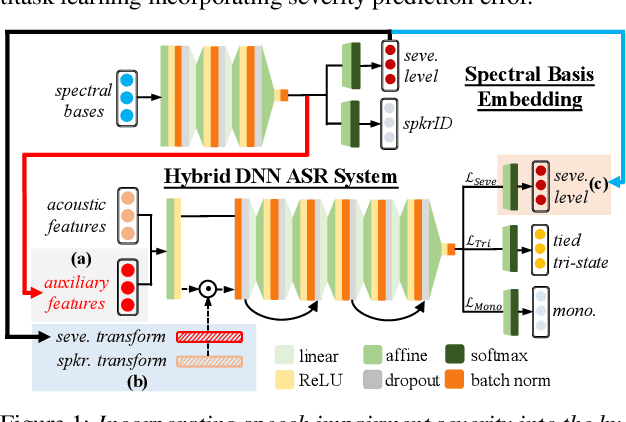

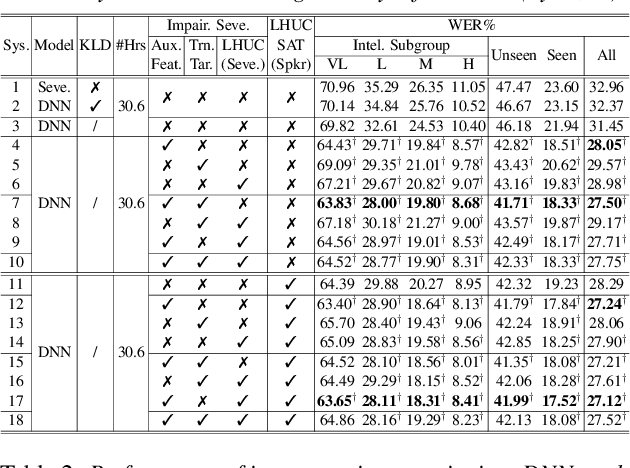
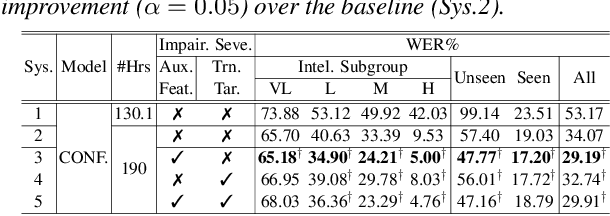
A key challenge in dysarthric speech recognition is the speaker-level diversity attributed to both speaker-identity associated factors such as gender, and speech impairment severity. Most prior researches on addressing this issue focused on using speaker-identity only. To this end, this paper proposes a novel set of techniques to use both severity and speaker-identity in dysarthric speech recognition: a) multitask training incorporating severity prediction error; b) speaker-severity aware auxiliary feature adaptation; and c) structured LHUC transforms separately conditioned on speaker-identity and severity. Experiments conducted on UASpeech suggest incorporating additional speech impairment severity into state-of-the-art hybrid DNN, E2E Conformer and pre-trained Wav2vec 2.0 ASR systems produced statistically significant WER reductions up to 4.78% (14.03% relative). Using the best system the lowest published WER of 17.82% (51.25% on very low intelligibility) was obtained on UASpeech.
SpeechGLUE: How Well Can Self-Supervised Speech Models Capture Linguistic Knowledge?
Jun 14, 2023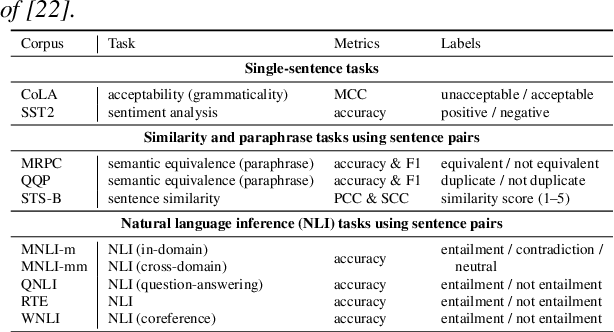
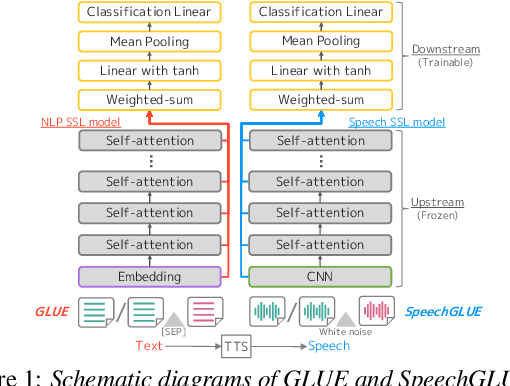
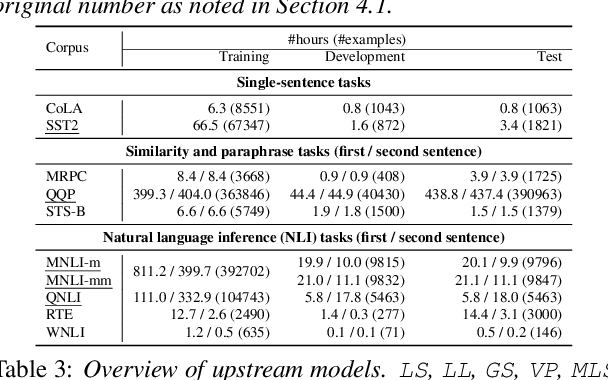
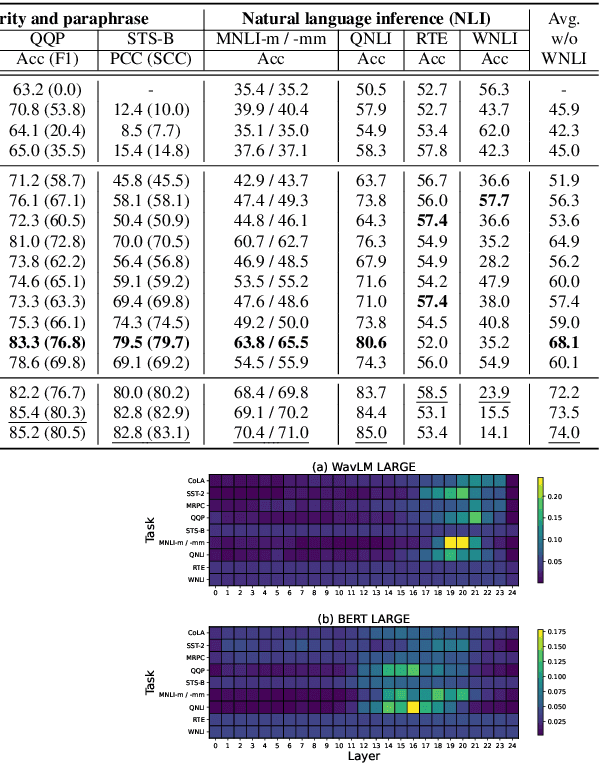
Self-supervised learning (SSL) for speech representation has been successfully applied in various downstream tasks, such as speech and speaker recognition. More recently, speech SSL models have also been shown to be beneficial in advancing spoken language understanding tasks, implying that the SSL models have the potential to learn not only acoustic but also linguistic information. In this paper, we aim to clarify if speech SSL techniques can well capture linguistic knowledge. For this purpose, we introduce SpeechGLUE, a speech version of the General Language Understanding Evaluation (GLUE) benchmark. Since GLUE comprises a variety of natural language understanding tasks, SpeechGLUE can elucidate the degree of linguistic ability of speech SSL models. Experiments demonstrate that speech SSL models, although inferior to text-based SSL models, perform better than baselines, suggesting that they can acquire a certain amount of general linguistic knowledge from just unlabeled speech data.
3D-Speaker: A Large-Scale Multi-Device, Multi-Distance, and Multi-Dialect Corpus for Speech Representation Disentanglement
Jun 28, 2023
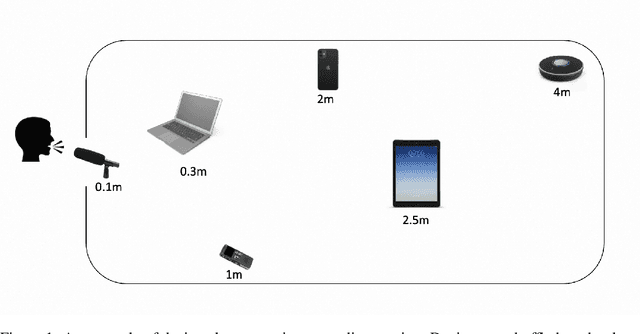
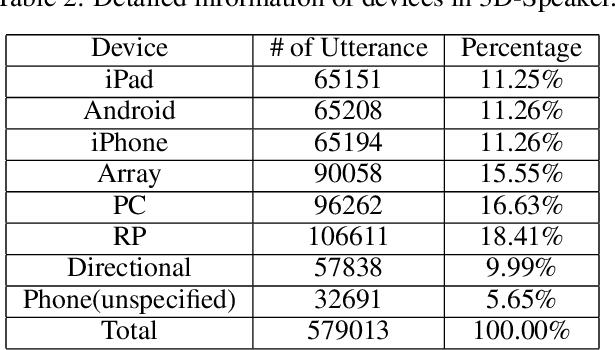
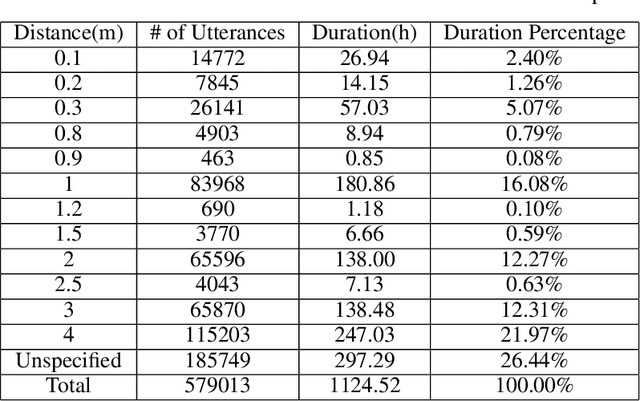
Disentangling uncorrelated information in speech utterances is a crucial research topic within speech community. Different speech-related tasks focus on extracting distinct speech representations while minimizing the affects of other uncorrelated information. We present a large-scale speech corpus to facilitate the research of speech representation disentanglement. 3D-Speaker contains over 10,000 speakers, each of whom are simultaneously recorded by multiple Devices, locating at different Distances, and some speakers are speaking multiple Dialects. The controlled combinations of multi-dimensional audio data yield a matrix of a diverse blend of speech representation entanglement, thereby motivating intriguing methods to untangle them. The multi-domain nature of 3D-Speaker also makes it a suitable resource to evaluate large universal speech models and experiment methods of out-of-domain learning and self-supervised learning. https://3dspeaker.github.io/
HK-LegiCoST: Leveraging Non-Verbatim Transcripts for Speech Translation
Jun 20, 2023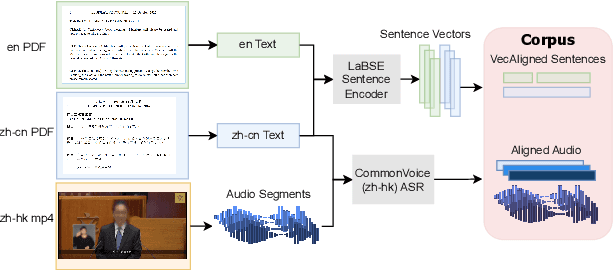
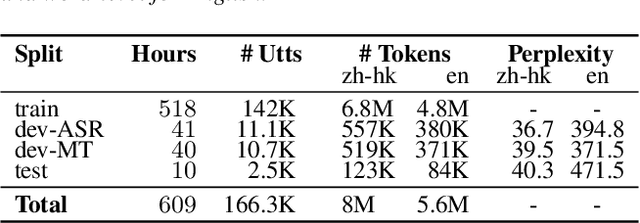
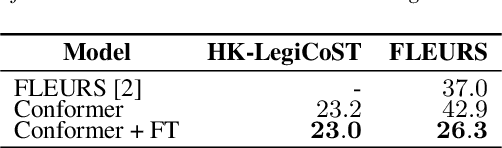

We introduce HK-LegiCoST, a new three-way parallel corpus of Cantonese-English translations, containing 600+ hours of Cantonese audio, its standard traditional Chinese transcript, and English translation, segmented and aligned at the sentence level. We describe the notable challenges in corpus preparation: segmentation, alignment of long audio recordings, and sentence-level alignment with non-verbatim transcripts. Such transcripts make the corpus suitable for speech translation research when there are significant differences between the spoken and written forms of the source language. Due to its large size, we are able to demonstrate competitive speech translation baselines on HK-LegiCoST and extend them to promising cross-corpus results on the FLEURS Cantonese subset. These results deliver insights into speech recognition and translation research in languages for which non-verbatim or ``noisy'' transcription is common due to various factors, including vernacular and dialectal speech.
Cross-modal Alignment with Optimal Transport for CTC-based ASR
Sep 24, 2023Temporal connectionist temporal classification (CTC)-based automatic speech recognition (ASR) is one of the most successful end to end (E2E) ASR frameworks. However, due to the token independence assumption in decoding, an external language model (LM) is required which destroys its fast parallel decoding property. Several studies have been proposed to transfer linguistic knowledge from a pretrained LM (PLM) to the CTC based ASR. Since the PLM is built from text while the acoustic model is trained with speech, a cross-modal alignment is required in order to transfer the context dependent linguistic knowledge from the PLM to acoustic encoding. In this study, we propose a novel cross-modal alignment algorithm based on optimal transport (OT). In the alignment process, a transport coupling matrix is obtained using OT, which is then utilized to transform a latent acoustic representation for matching the context-dependent linguistic features encoded by the PLM. Based on the alignment, the latent acoustic feature is forced to encode context dependent linguistic information. We integrate this latent acoustic feature to build conformer encoder-based CTC ASR system. On the AISHELL-1 data corpus, our system achieved 3.96% and 4.27% character error rate (CER) for dev and test sets, respectively, which corresponds to relative improvements of 28.39% and 29.42% compared to the baseline conformer CTC ASR system without cross-modal knowledge transfer.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 08, 2023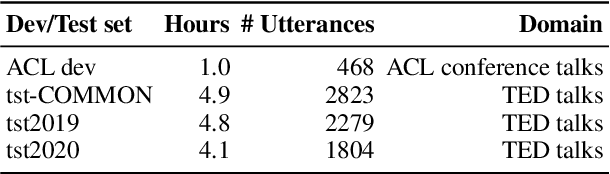
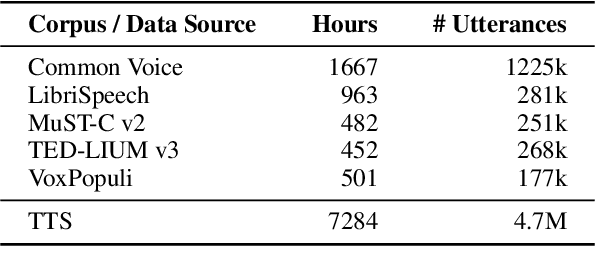
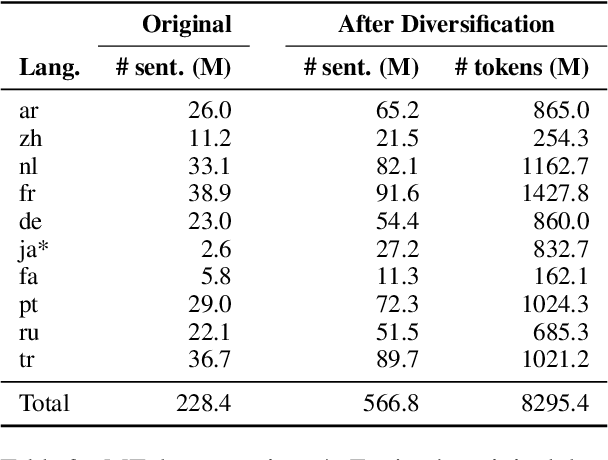
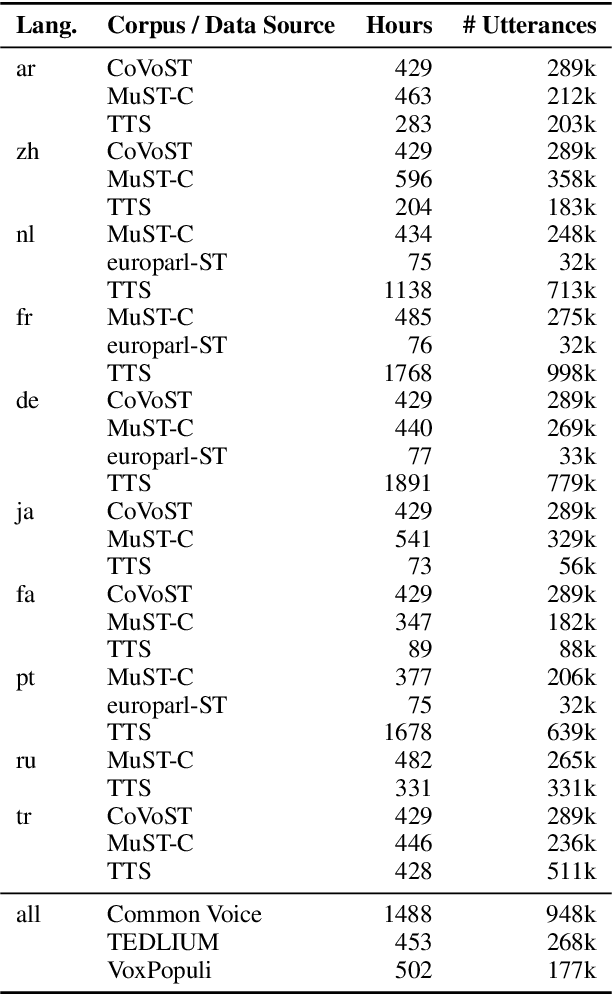
Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which focuses on the translation of scientific conference talks. The test condition features accented input speech and terminology-dense contents. The tasks requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Multi-Channel MOSRA: Mean Opinion Score and Room Acoustics Estimation Using Simulated Data and a Teacher Model
Sep 21, 2023Previous methods for predicting room acoustic parameters and speech quality metrics have focused on the single-channel case, where room acoustics and Mean Opinion Score (MOS) are predicted for a single recording device. However, quality-based device selection for rooms with multiple recording devices may benefit from a multi-channel approach where the descriptive metrics are predicted for multiple devices in parallel. Following our hypothesis that a model may benefit from multi-channel training, we develop a multi-channel model for joint MOS and room acoustics prediction (MOSRA) for five channels in parallel. The lack of multi-channel audio data with ground truth labels necessitated the creation of simulated data using an acoustic simulator with room acoustic labels extracted from the generated impulse responses and labels for MOS generated in a student-teacher setup using a wav2vec2-based MOS prediction model. Our experiments show that the multi-channel model improves the prediction of the direct-to-reverberation ratio, clarity, and speech transmission index over the single-channel model with roughly 5$\times$ less computation while suffering minimal losses in the performance of the other metrics.
Multilingual context-based pronunciation learning for Text-to-Speech
Jul 31, 2023



Phonetic information and linguistic knowledge are an essential component of a Text-to-speech (TTS) front-end. Given a language, a lexicon can be collected offline and Grapheme-to-Phoneme (G2P) relationships are usually modeled in order to predict the pronunciation for out-of-vocabulary (OOV) words. Additionally, post-lexical phonology, often defined in the form of rule-based systems, is used to correct pronunciation within or between words. In this work we showcase a multilingual unified front-end system that addresses any pronunciation related task, typically handled by separate modules. We evaluate the proposed model on G2P conversion and other language-specific challenges, such as homograph and polyphones disambiguation, post-lexical rules and implicit diacritization. We find that the multilingual model is competitive across languages and tasks, however, some trade-offs exists when compared to equivalent monolingual solutions.
Wiki-En-ASR-Adapt: Large-scale synthetic dataset for English ASR Customization
Sep 29, 2023We present a first large-scale public synthetic dataset for contextual spellchecking customization of automatic speech recognition (ASR) with focus on diverse rare and out-of-vocabulary (OOV) phrases, such as proper names or terms. The proposed approach allows creating millions of realistic examples of corrupted ASR hypotheses and simulate non-trivial biasing lists for the customization task. Furthermore, we propose injecting two types of ``hard negatives" to the simulated biasing lists in training examples and describe our procedures to automatically mine them. We report experiments with training an open-source customization model on the proposed dataset and show that the injection of hard negative biasing phrases decreases WER and the number of false alarms.
Sparse Finetuning for Inference Acceleration of Large Language Models
Oct 10, 2023We consider the problem of accurate sparse finetuning of large language models (LLMs), that is, finetuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based finetuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse finetuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.