 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
AutoAD II: The Sequel -- Who, When, and What in Movie Audio Description
Oct 10, 2023

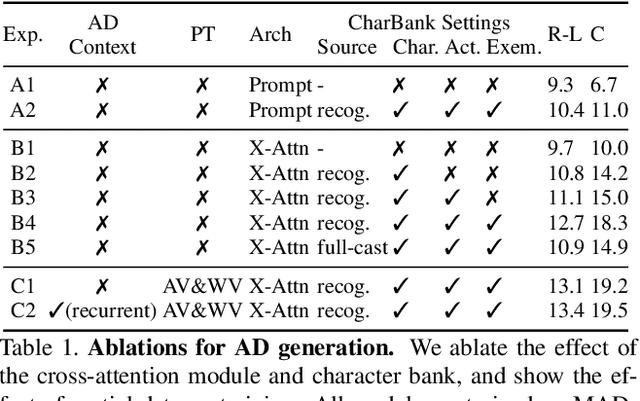
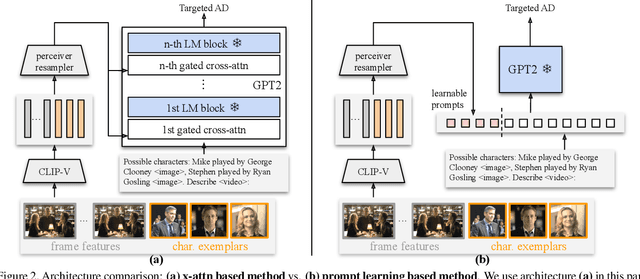

Audio Description (AD) is the task of generating descriptions of visual content, at suitable time intervals, for the benefit of visually impaired audiences. For movies, this presents notable challenges -- AD must occur only during existing pauses in dialogue, should refer to characters by name, and ought to aid understanding of the storyline as a whole. To this end, we develop a new model for automatically generating movie AD, given CLIP visual features of the frames, the cast list, and the temporal locations of the speech; addressing all three of the 'who', 'when', and 'what' questions: (i) who -- we introduce a character bank consisting of the character's name, the actor that played the part, and a CLIP feature of their face, for the principal cast of each movie, and demonstrate how this can be used to improve naming in the generated AD; (ii) when -- we investigate several models for determining whether an AD should be generated for a time interval or not, based on the visual content of the interval and its neighbours; and (iii) what -- we implement a new vision-language model for this task, that can ingest the proposals from the character bank, whilst conditioning on the visual features using cross-attention, and demonstrate how this improves over previous architectures for AD text generation in an apples-to-apples comparison.
Sparse Finetuning for Inference Acceleration of Large Language Models
Oct 10, 2023We consider the problem of accurate sparse finetuning of large language models (LLMs), that is, finetuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based finetuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse finetuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Tim
Aug 02, 2023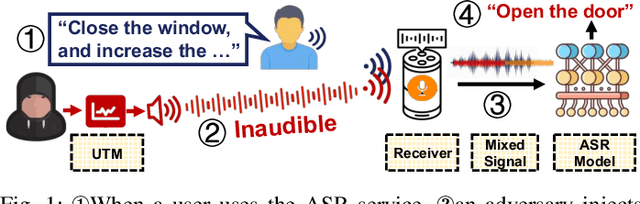
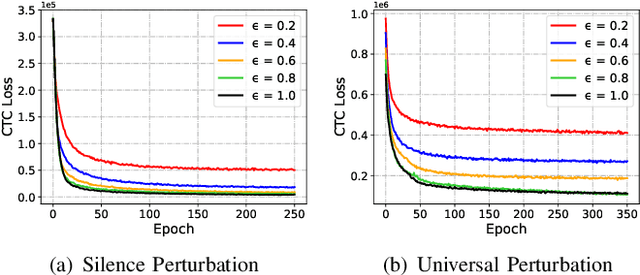
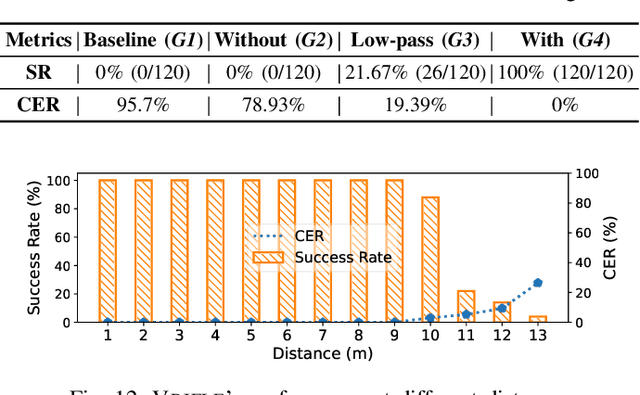
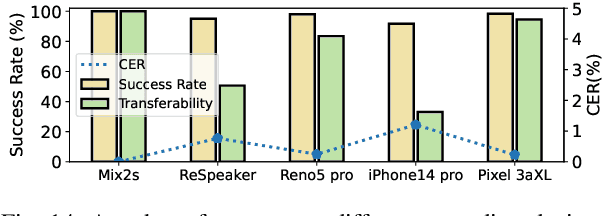
Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Cross-modal Alignment with Optimal Transport for CTC-based ASR
Sep 24, 2023Temporal connectionist temporal classification (CTC)-based automatic speech recognition (ASR) is one of the most successful end to end (E2E) ASR frameworks. However, due to the token independence assumption in decoding, an external language model (LM) is required which destroys its fast parallel decoding property. Several studies have been proposed to transfer linguistic knowledge from a pretrained LM (PLM) to the CTC based ASR. Since the PLM is built from text while the acoustic model is trained with speech, a cross-modal alignment is required in order to transfer the context dependent linguistic knowledge from the PLM to acoustic encoding. In this study, we propose a novel cross-modal alignment algorithm based on optimal transport (OT). In the alignment process, a transport coupling matrix is obtained using OT, which is then utilized to transform a latent acoustic representation for matching the context-dependent linguistic features encoded by the PLM. Based on the alignment, the latent acoustic feature is forced to encode context dependent linguistic information. We integrate this latent acoustic feature to build conformer encoder-based CTC ASR system. On the AISHELL-1 data corpus, our system achieved 3.96% and 4.27% character error rate (CER) for dev and test sets, respectively, which corresponds to relative improvements of 28.39% and 29.42% compared to the baseline conformer CTC ASR system without cross-modal knowledge transfer.
Wiki-En-ASR-Adapt: Large-scale synthetic dataset for English ASR Customization
Sep 29, 2023We present a first large-scale public synthetic dataset for contextual spellchecking customization of automatic speech recognition (ASR) with focus on diverse rare and out-of-vocabulary (OOV) phrases, such as proper names or terms. The proposed approach allows creating millions of realistic examples of corrupted ASR hypotheses and simulate non-trivial biasing lists for the customization task. Furthermore, we propose injecting two types of ``hard negatives" to the simulated biasing lists in training examples and describe our procedures to automatically mine them. We report experiments with training an open-source customization model on the proposed dataset and show that the injection of hard negative biasing phrases decreases WER and the number of false alarms.
Multi-Channel MOSRA: Mean Opinion Score and Room Acoustics Estimation Using Simulated Data and a Teacher Model
Sep 21, 2023Previous methods for predicting room acoustic parameters and speech quality metrics have focused on the single-channel case, where room acoustics and Mean Opinion Score (MOS) are predicted for a single recording device. However, quality-based device selection for rooms with multiple recording devices may benefit from a multi-channel approach where the descriptive metrics are predicted for multiple devices in parallel. Following our hypothesis that a model may benefit from multi-channel training, we develop a multi-channel model for joint MOS and room acoustics prediction (MOSRA) for five channels in parallel. The lack of multi-channel audio data with ground truth labels necessitated the creation of simulated data using an acoustic simulator with room acoustic labels extracted from the generated impulse responses and labels for MOS generated in a student-teacher setup using a wav2vec2-based MOS prediction model. Our experiments show that the multi-channel model improves the prediction of the direct-to-reverberation ratio, clarity, and speech transmission index over the single-channel model with roughly 5$\times$ less computation while suffering minimal losses in the performance of the other metrics.
Acoustic-to-Articulatory Speech Inversion Features for Mispronunciation Detection of /r/ in Child Speech Sound Disorders
May 25, 2023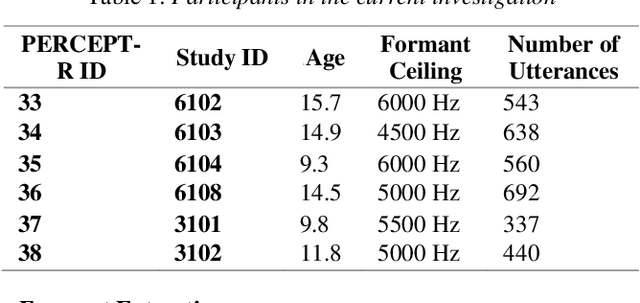

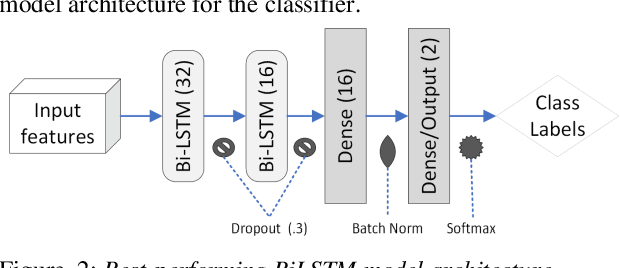
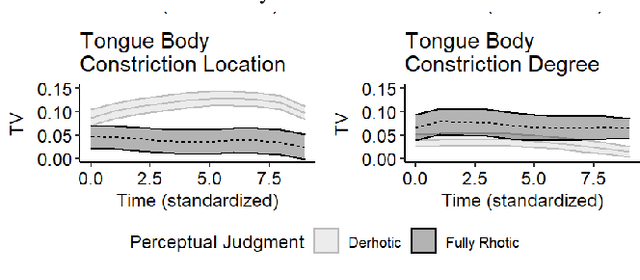
Acoustic-to-articulatory speech inversion could enhance automated clinical mispronunciation detection to provide detailed articulatory feedback unattainable by formant-based mispronunciation detection algorithms; however, it is unclear the extent to which a speech inversion system trained on adult speech performs in the context of (1) child and (2) clinical speech. In the absence of an articulatory dataset in children with rhotic speech sound disorders, we show that classifiers trained on tract variables from acoustic-to-articulatory speech inversion meet or exceed the performance of state-of-the-art features when predicting clinician judgment of rhoticity. Index Terms: rhotic, speech sound disorder, mispronunciation detection
Gesper: A Restoration-Enhancement Framework for General Speech Reconstruction
Jun 14, 2023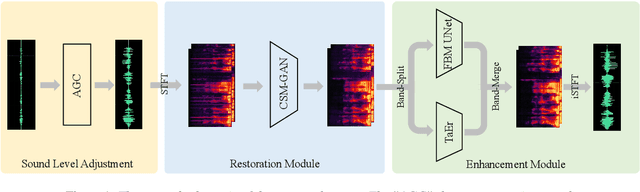
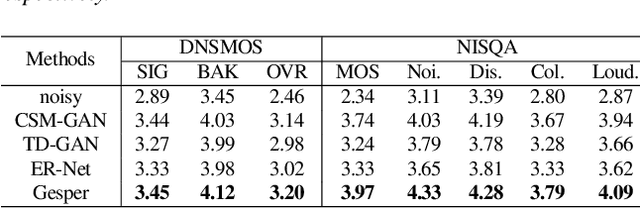
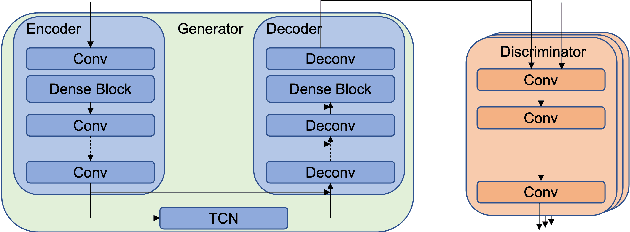
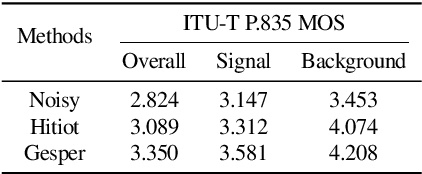
This paper describes a real-time General Speech Reconstruction (Gesper) system submitted to the ICASSP 2023 Speech Signal Improvement (SSI) Challenge. This novel proposed system is a two-stage architecture, in which the speech restoration is performed, and then cascaded by speech enhancement. We propose a complex spectral mapping-based generative adversarial network (CSM-GAN) as the speech restoration module for the first time. For noise suppression and dereverberation, the enhancement module is performed with fullband-wideband parallel processing. On the blind test set of ICASSP 2023 SSI Challenge, the proposed Gesper system, which satisfies the real-time condition, achieves 3.27 P.804 overall mean opinion score (MOS) and 3.35 P.835 overall MOS, ranked 1st in both track 1 and track 2.
Don't Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters
Jul 02, 2023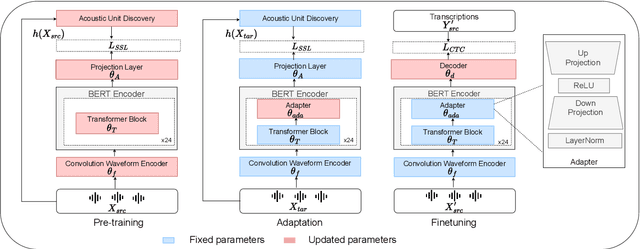
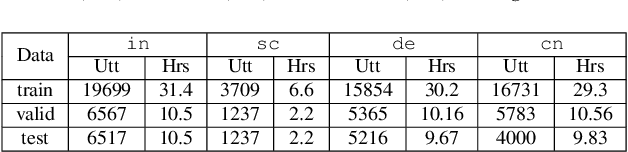
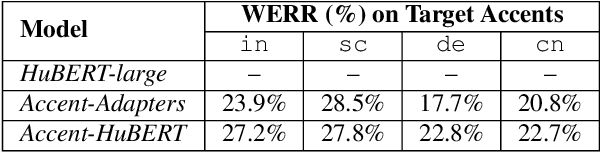
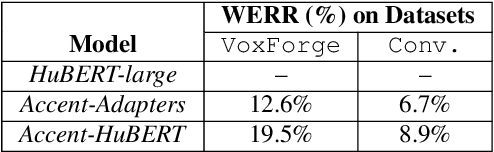
Speech representations learned in a self-supervised fashion from massive unlabeled speech corpora have been adapted successfully toward several downstream tasks. However, such representations may be skewed toward canonical data characteristics of such corpora and perform poorly on atypical, non-native accented speaker populations. With the state-of-the-art HuBERT model as a baseline, we propose and investigate self-supervised adaptation of speech representations to such populations in a parameter-efficient way via training accent-specific residual adapters. We experiment with 4 accents and choose automatic speech recognition (ASR) as the downstream task of interest. We obtain strong word error rate reductions (WERR) over HuBERT-large for all 4 accents, with a mean WERR of 22.7% with accent-specific adapters and a mean WERR of 25.1% if the entire encoder is accent-adapted. While our experiments utilize HuBERT and ASR as the downstream task, our proposed approach is both model and task-agnostic.
A comparative study of Grid and Natural sentences effects on Normal-to-Lombard conversion
Sep 19, 2023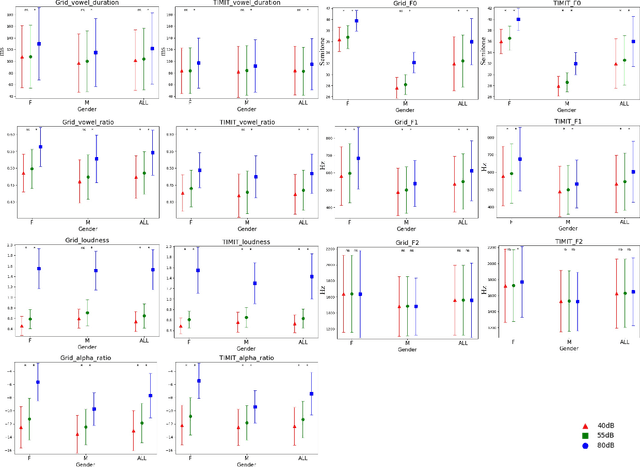

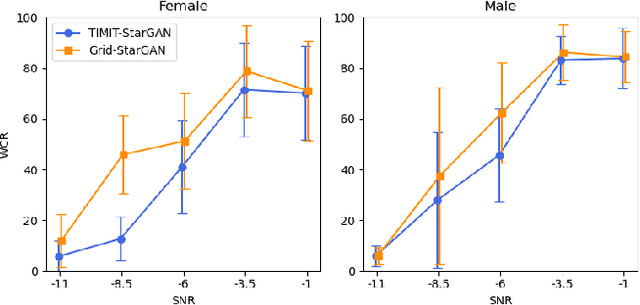
Grid sentence is commonly used for studying the Lombard effect and Normal-to-Lombard conversion. However, it's unclear if Normal-to-Lombard models trained on grid sentences are sufficient for improving natural speech intelligibility in real-world applications. This paper presents the recording of a parallel Lombard corpus (called Lombard Chinese TIMIT, LCT) extracting natural sentences from Chinese TIMIT. Then We compare natural and grid sentences in terms of Lombard effect and Normal-to-Lombard conversion using LCT and Enhanced MAndarin Lombard Grid corpus (EMALG). Through a parametric analysis of the Lombard effect, We find that as the noise level increases, both natural sentences and grid sentences exhibit similar changes in parameters, but in terms of the increase of the alpha ratio, grid sentences show a greater increase. Following a subjective intelligibility assessment across genders and Signal-to-Noise Ratios, the StarGAN model trained on EMALG consistently outperforms the model trained on LCT in terms of improving intelligibility. This superior performance may be attributed to EMALG's larger alpha ratio increase from normal to Lombard speech.