 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Semantic enrichment towards efficient speech representations
Jul 03, 2023
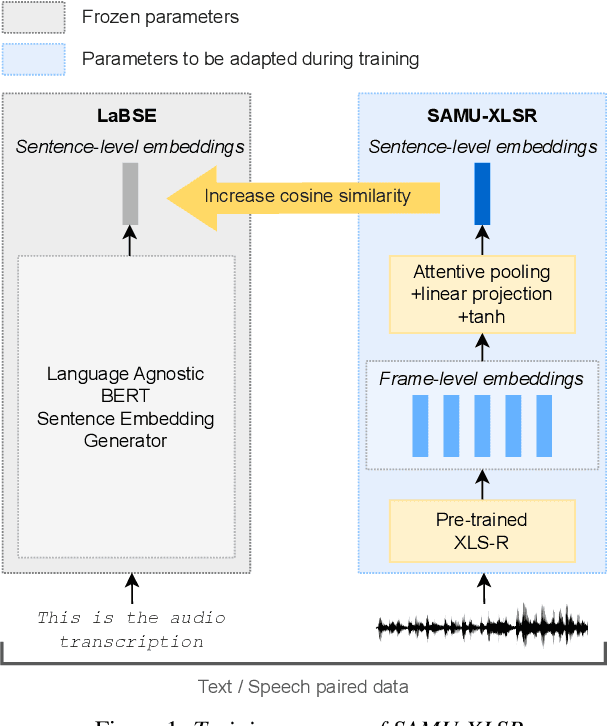
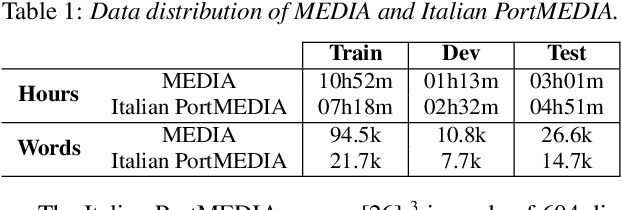
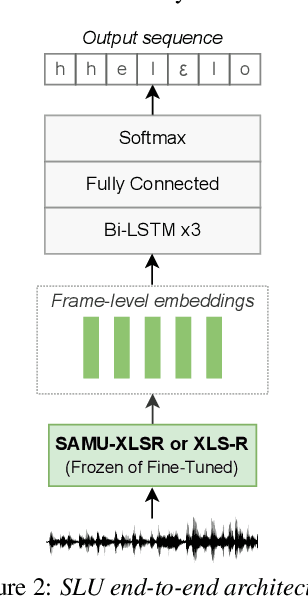
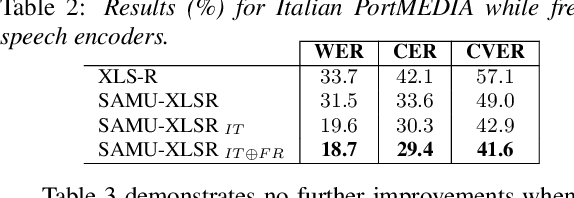
Over the past few years, self-supervised learned speech representations have emerged as fruitful replacements for conventional surface representations when solving Spoken Language Understanding (SLU) tasks. Simultaneously, multilingual models trained on massive textual data were introduced to encode language agnostic semantics. Recently, the SAMU-XLSR approach introduced a way to make profit from such textual models to enrich multilingual speech representations with language agnostic semantics. By aiming for better semantic extraction on a challenging Spoken Language Understanding task and in consideration with computation costs, this study investigates a specific in-domain semantic enrichment of the SAMU-XLSR model by specializing it on a small amount of transcribed data from the downstream task. In addition, we show the benefits of the use of same-domain French and Italian benchmarks for low-resource language portability and explore cross-domain capacities of the enriched SAMU-XLSR.
Prompt Packer: Deceiving LLMs through Compositional Instruction with Hidden Attacks
Oct 16, 2023Recently, Large language models (LLMs) with powerful general capabilities have been increasingly integrated into various Web applications, while undergoing alignment training to ensure that the generated content aligns with user intent and ethics. Unfortunately, they remain the risk of generating harmful content like hate speech and criminal activities in practical applications. Current approaches primarily rely on detecting, collecting, and training against harmful prompts to prevent such risks. However, they typically focused on the "superficial" harmful prompts with a solitary intent, ignoring composite attack instructions with multiple intentions that can easily elicit harmful content in real-world scenarios. In this paper, we introduce an innovative technique for obfuscating harmful instructions: Compositional Instruction Attacks (CIA), which refers to attacking by combination and encapsulation of multiple instructions. CIA hides harmful prompts within instructions of harmless intentions, making it impossible for the model to identify underlying malicious intentions. Furthermore, we implement two transformation methods, known as T-CIA and W-CIA, to automatically disguise harmful instructions as talking or writing tasks, making them appear harmless to LLMs. We evaluated CIA on GPT-4, ChatGPT, and ChatGLM2 with two safety assessment datasets and two harmful prompt datasets. It achieves an attack success rate of 95%+ on safety assessment datasets, and 83%+ for GPT-4, 91%+ for ChatGPT (gpt-3.5-turbo backed) and ChatGLM2-6B on harmful prompt datasets. Our approach reveals the vulnerability of LLMs to such compositional instruction attacks that harbor underlying harmful intentions, contributing significantly to LLM security development. Warning: this paper may contain offensive or upsetting content!
Understanding writing style in social media with a supervised contrastively pre-trained transformer
Oct 17, 2023Online Social Networks serve as fertile ground for harmful behavior, ranging from hate speech to the dissemination of disinformation. Malicious actors now have unprecedented freedom to misbehave, leading to severe societal unrest and dire consequences, as exemplified by events such as the Capitol assault during the US presidential election and the Antivaxx movement during the COVID-19 pandemic. Understanding online language has become more pressing than ever. While existing works predominantly focus on content analysis, we aim to shift the focus towards understanding harmful behaviors by relating content to their respective authors. Numerous novel approaches attempt to learn the stylistic features of authors in texts, but many of these approaches are constrained by small datasets or sub-optimal training losses. To overcome these limitations, we introduce the Style Transformer for Authorship Representations (STAR), trained on a large corpus derived from public sources of 4.5 x 10^6 authored texts involving 70k heterogeneous authors. Our model leverages Supervised Contrastive Loss to teach the model to minimize the distance between texts authored by the same individual. This author pretext pre-training task yields competitive performance at zero-shot with PAN challenges on attribution and clustering. Additionally, we attain promising results on PAN verification challenges using a single dense layer, with our model serving as an embedding encoder. Finally, we present results from our test partition on Reddit. Using a support base of 8 documents of 512 tokens, we can discern authors from sets of up to 1616 authors with at least 80\% accuracy. We share our pre-trained model at huggingface (https://huggingface.co/AIDA-UPM/star) and our code is available at (https://github.com/jahuerta92/star)
L1-aware Multilingual Mispronunciation Detection Framework
Sep 14, 2023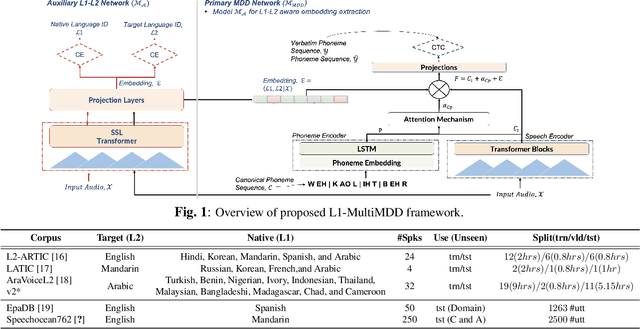
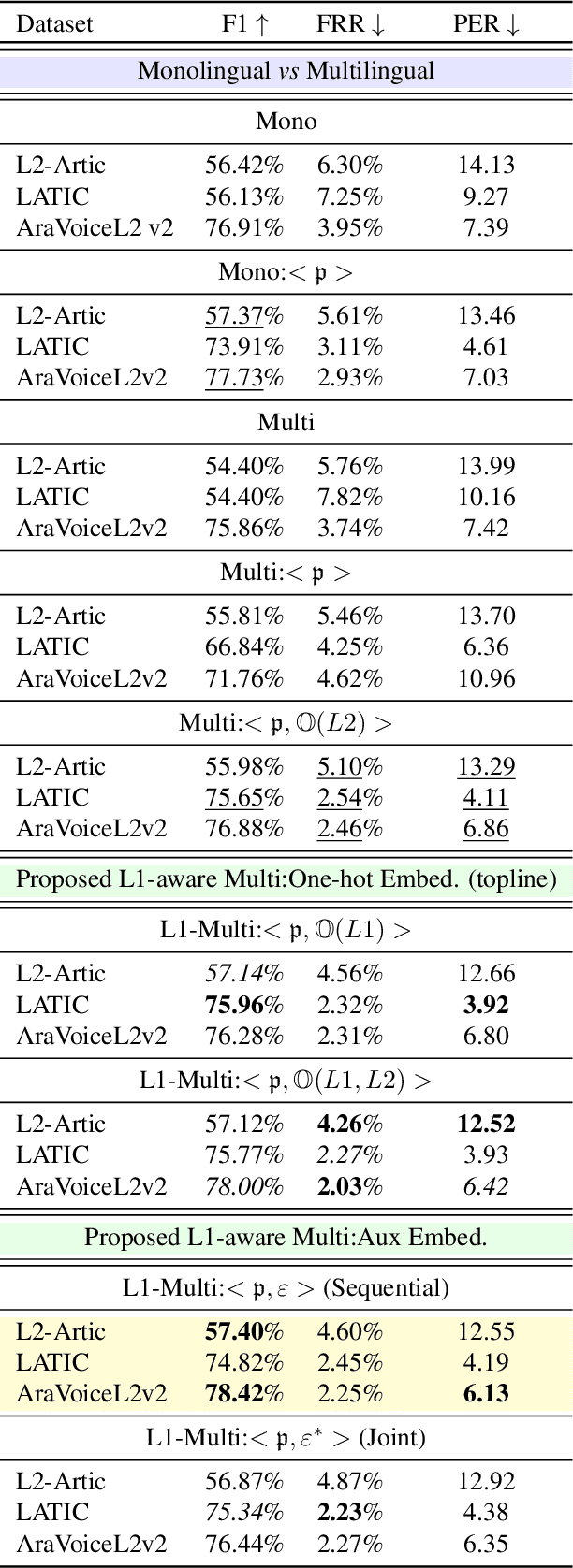
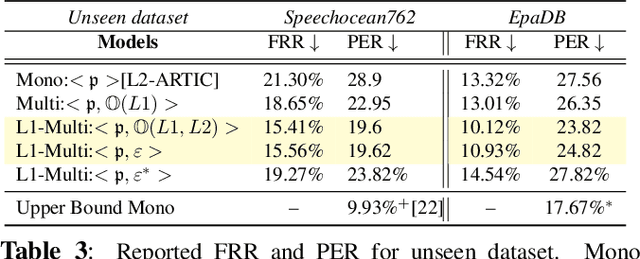
The phonological discrepancies between a speaker's native (L1) and the non-native language (L2) serves as a major factor for mispronunciation. This paper introduces a novel multilingual MDD architecture, L1-MultiMDD, enriched with L1-aware speech representation. An end-to-end speech encoder is trained on the input signal and its corresponding reference phoneme sequence. First, an attention mechanism is deployed to align the input audio with the reference phoneme sequence. Afterwards, the L1-L2-speech embedding are extracted from an auxiliary model, pretrained in a multi-task setup identifying L1 and L2 language, and are infused with the primary network. Finally, the L1-MultiMDD is then optimized for a unified multilingual phoneme recognition task using connectionist temporal classification (CTC) loss for the target languages: English, Arabic, and Mandarin. Our experiments demonstrate the effectiveness of the proposed L1-MultiMDD framework on both seen -- L2-ARTIC, LATIC, and AraVoiceL2v2; and unseen -- EpaDB and Speechocean762 datasets. The consistent gains in PER, and false rejection rate (FRR) across all target languages confirm our approach's robustness, efficacy, and generalizability.
Weakly-Supervised Speech Pre-training: A Case Study on Target Speech Recognition
May 25, 2023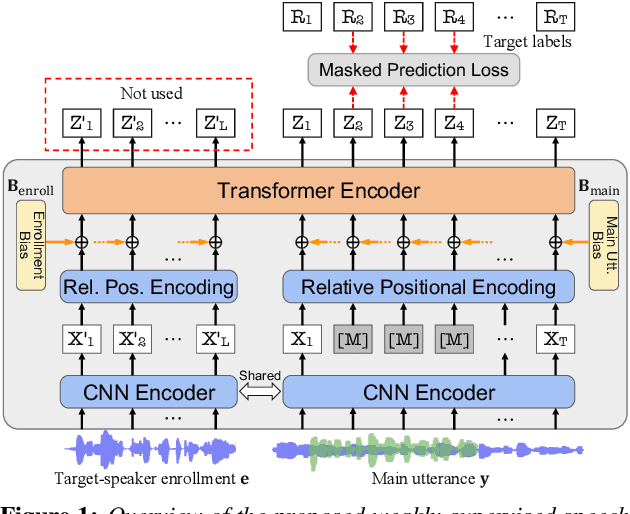
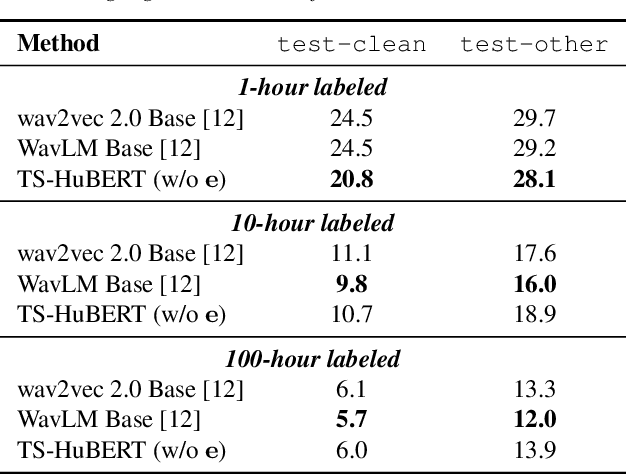
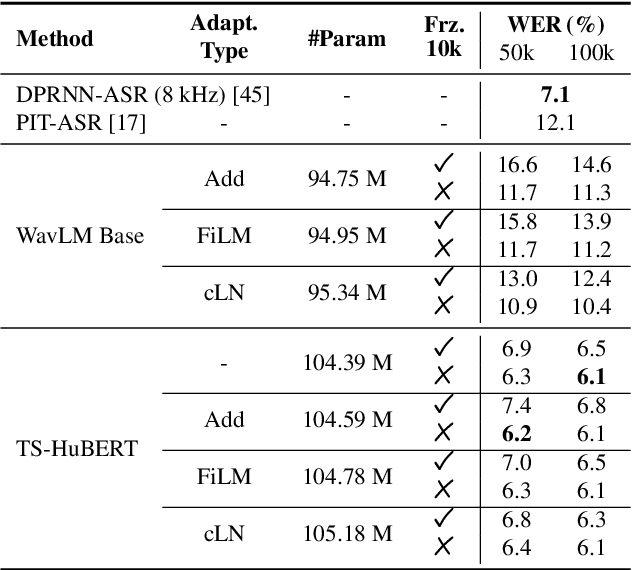
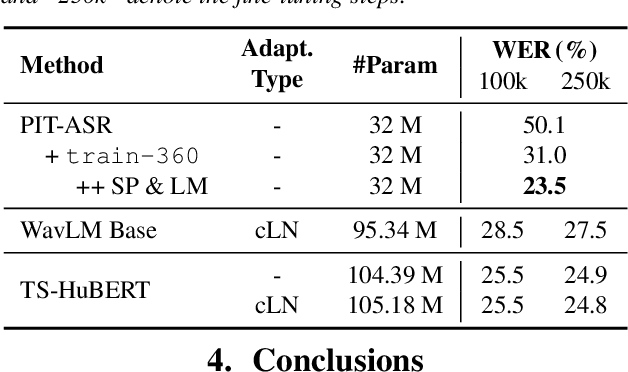
Self-supervised learning (SSL) based speech pre-training has attracted much attention for its capability of extracting rich representations learned from massive unlabeled data. On the other hand, the use of weakly-supervised data is less explored for speech pre-training. To fill this gap, we propose a weakly-supervised speech pre-training method based on speaker-aware speech data. It adopts a similar training procedure to the widely-used masked speech prediction based SSL framework, while incorporating additional target-speaker enrollment information as an auxiliary input. In this way, the learned representation is steered towards the target speaker even in the presence of highly overlapping interference, allowing potential applications to tasks such as target speech recognition. Our experiments on Libri2Mix and WSJ0-2mix datasets show that the proposed model achieves significantly better ASR performance compared to WavLM, the state-of-the-art SSL model with denoising capability.
Severity Classification of Parkinson's Disease from Speech using Single Frequency Filtering-based Features
Aug 17, 2023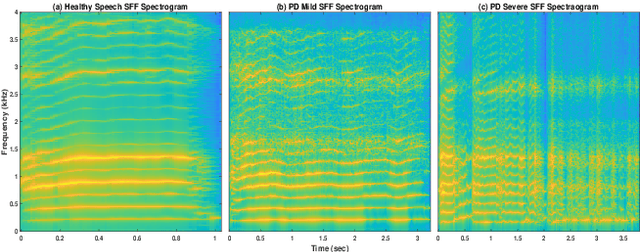
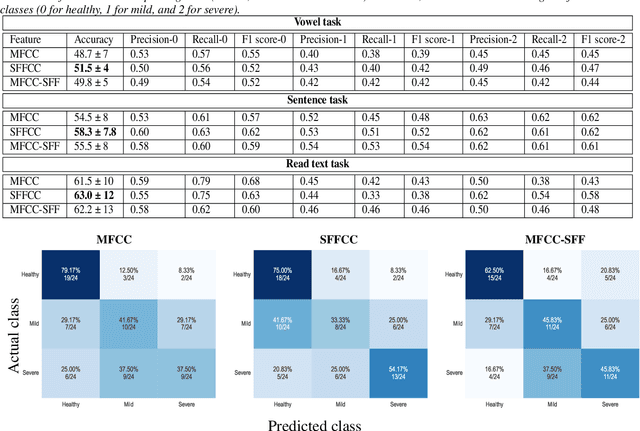
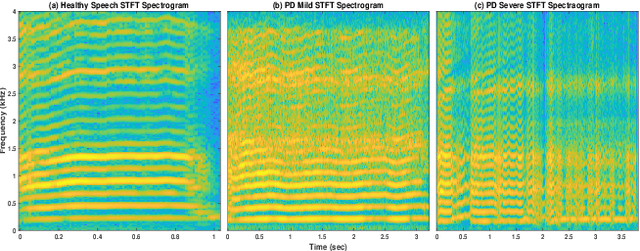
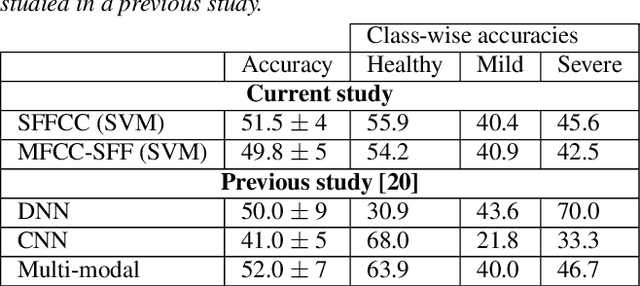
Developing objective methods for assessing the severity of Parkinson's disease (PD) is crucial for improving the diagnosis and treatment. This study proposes two sets of novel features derived from the single frequency filtering (SFF) method: (1) SFF cepstral coefficients (SFFCC) and (2) MFCCs from the SFF (MFCC-SFF) for the severity classification of PD. Prior studies have demonstrated that SFF offers greater spectro-temporal resolution compared to the short-time Fourier transform. The study uses the PC-GITA database, which includes speech of PD patients and healthy controls produced in three speaking tasks (vowels, sentences, text reading). Experiments using the SVM classifier revealed that the proposed features outperformed the conventional MFCCs in all three speaking tasks. The proposed SFFCC and MFCC-SFF features gave a relative improvement of 5.8% and 2.3% for the vowel task, 7.0% & 1.8% for the sentence task, and 2.4% and 1.1% for the read text task, in comparison to MFCC features.
Sparse Fine-tuning for Inference Acceleration of Large Language Models
Oct 13, 2023We consider the problem of accurate sparse fine-tuning of large language models (LLMs), that is, fine-tuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based fine-tuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse fine-tuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
Emo-DNA: Emotion Decoupling and Alignment Learning for Cross-Corpus Speech Emotion Recognition
Aug 04, 2023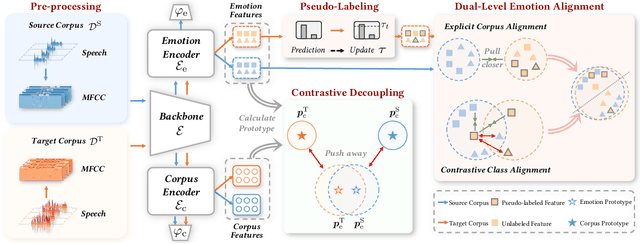
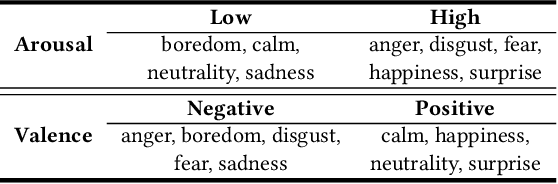
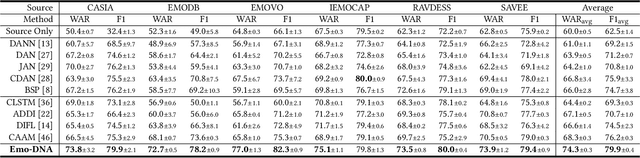
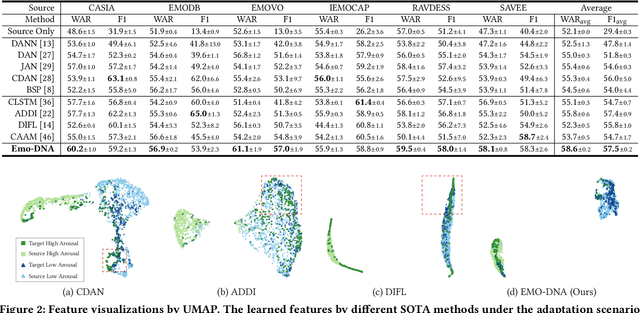
Cross-corpus speech emotion recognition (SER) seeks to generalize the ability of inferring speech emotion from a well-labeled corpus to an unlabeled one, which is a rather challenging task due to the significant discrepancy between two corpora. Existing methods, typically based on unsupervised domain adaptation (UDA), struggle to learn corpus-invariant features by global distribution alignment, but unfortunately, the resulting features are mixed with corpus-specific features or not class-discriminative. To tackle these challenges, we propose a novel Emotion Decoupling aNd Alignment learning framework (EMO-DNA) for cross-corpus SER, a novel UDA method to learn emotion-relevant corpus-invariant features. The novelties of EMO-DNA are two-fold: contrastive emotion decoupling and dual-level emotion alignment. On one hand, our contrastive emotion decoupling achieves decoupling learning via a contrastive decoupling loss to strengthen the separability of emotion-relevant features from corpus-specific ones. On the other hand, our dual-level emotion alignment introduces an adaptive threshold pseudo-labeling to select confident target samples for class-level alignment, and performs corpus-level alignment to jointly guide model for learning class-discriminative corpus-invariant features across corpora. Extensive experimental results demonstrate the superior performance of EMO-DNA over the state-of-the-art methods in several cross-corpus scenarios. Source code is available at https://github.com/Jiaxin-Ye/Emo-DNA.
The complementary roles of non-verbal cues for Robust Pronunciation Assessment
Sep 14, 2023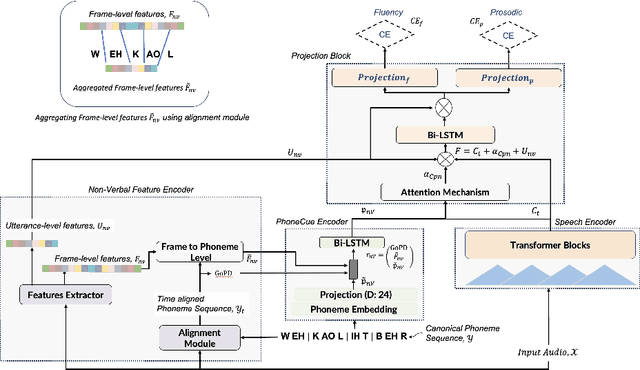
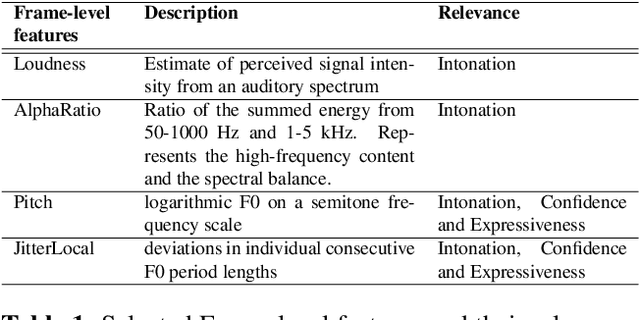
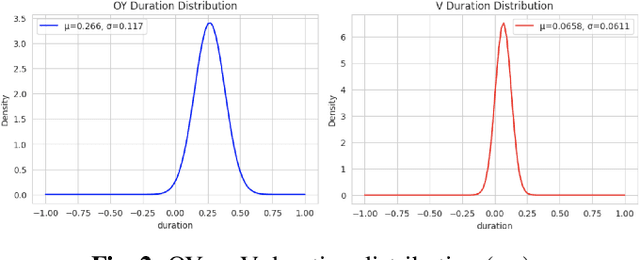
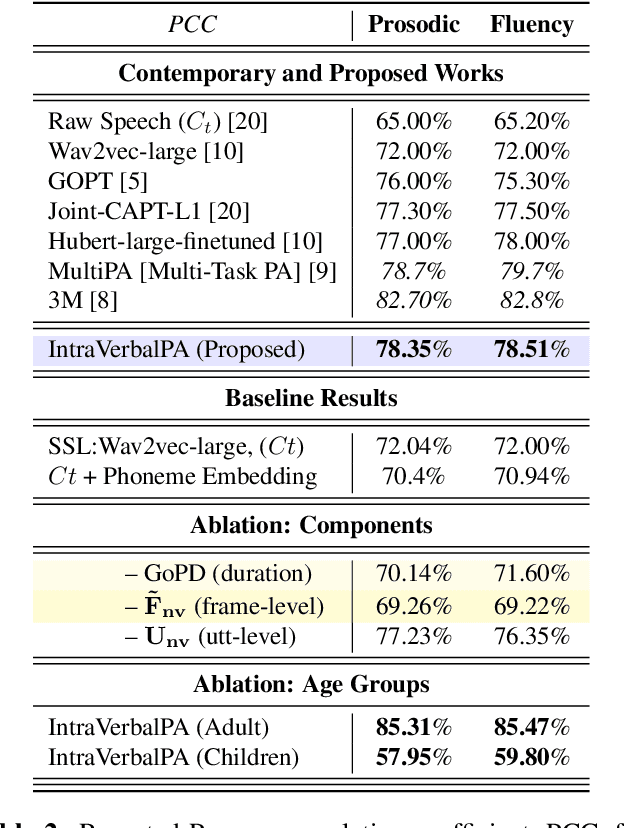
Research on pronunciation assessment systems focuses on utilizing phonetic and phonological aspects of non-native (L2) speech, often neglecting the rich layer of information hidden within the non-verbal cues. In this study, we proposed a novel pronunciation assessment framework, IntraVerbalPA. % The framework innovatively incorporates both fine-grained frame- and abstract utterance-level non-verbal cues, alongside the conventional speech and phoneme representations. Additionally, we introduce ''Goodness of phonemic-duration'' metric to effectively model duration distribution within the framework. Our results validate the effectiveness of the proposed IntraVerbalPA framework and its individual components, yielding performance that either matches or outperforms existing research works.
CB-Whisper: Contextual Biasing Whisper using TTS-based Keyword Spotting
Sep 18, 2023
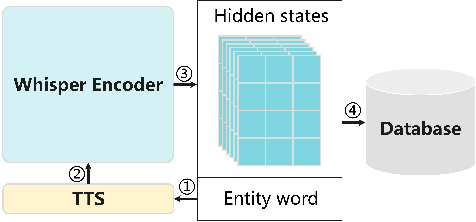
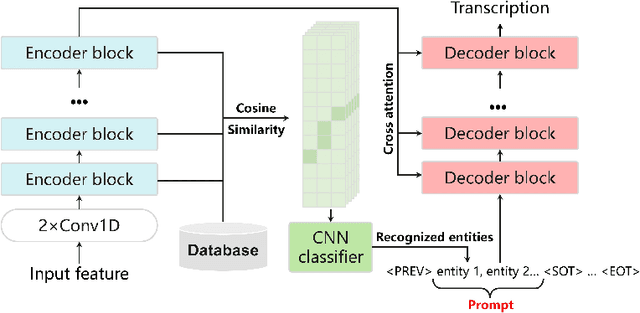
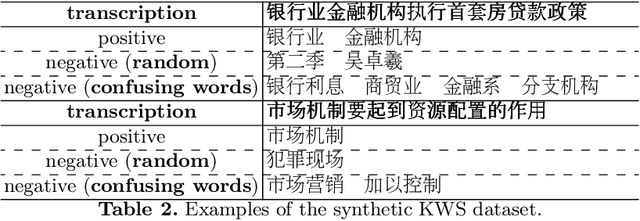
End-to-end automatic speech recognition (ASR) systems often struggle to recognize rare name entities, such as personal names, organizations, or technical terms that are not frequently encountered in the training data. This paper presents Contextual Biasing Whisper (CB-Whisper), a novel ASR system based on OpenAI's Whisper model that performs keyword-spotting (KWS) before the decoder. The KWS module leverages text-to-speech (TTS) techniques and a convolutional neural network (CNN) classifier to match the features between the entities and the utterances. Experiments demonstrate that by incorporating predicted entities into a carefully designed spoken form prompt, the mixed-error-rate (MER) and entity recall of the Whisper model is significantly improved on three internal datasets and two open-sourced datasets that cover English-only, Chinese-only, and code-switching scenarios.