 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Hybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
Sep 14, 2023

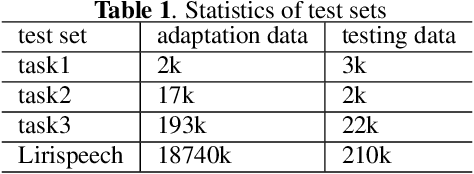
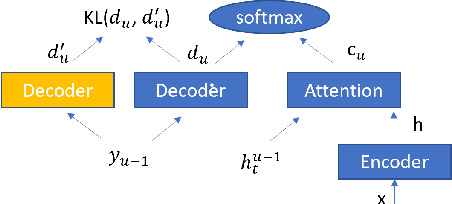
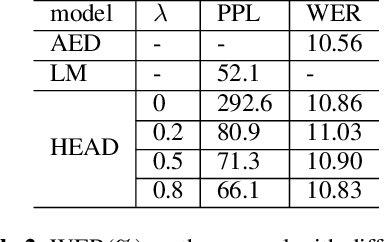
Attention-based encoder-decoder (AED) speech recognition model has been widely successful in recent years. However, the joint optimization of acoustic model and language model in end-to-end manner has created challenges for text adaptation. In particular, effectively, quickly and inexpensively adapting text has become a primary concern for deploying AED systems in industry. To address this issue, we propose a novel model, the hybrid attention-based encoder-decoder (HAED) speech recognition model that preserves the modularity of conventional hybrid automatic speech recognition systems. Our HAED model separates the acoustic and language models, allowing for the use of conventional text-based language model adaptation techniques. We demonstrate that the proposed HAED model yields 21\% Word Error Rate (WER) improvements in relative when out-of-domain text data is used for language model adaptation, and with only a minor degradation in WER on a general test set compared with conventional AED model.
Language-Routing Mixture of Experts for Multilingual and Code-Switching Speech Recognition
Jul 12, 2023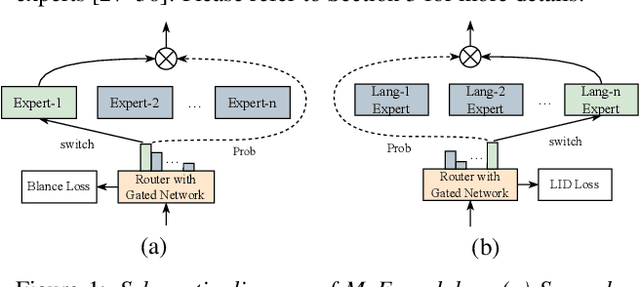
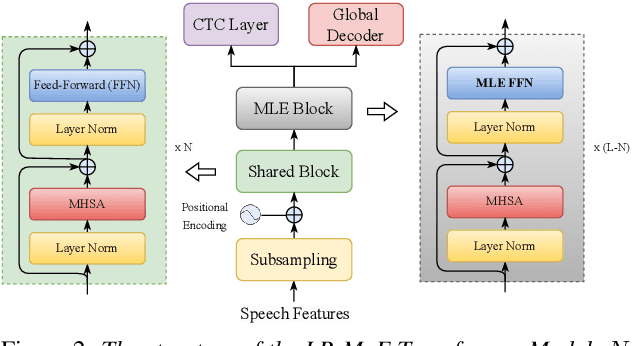
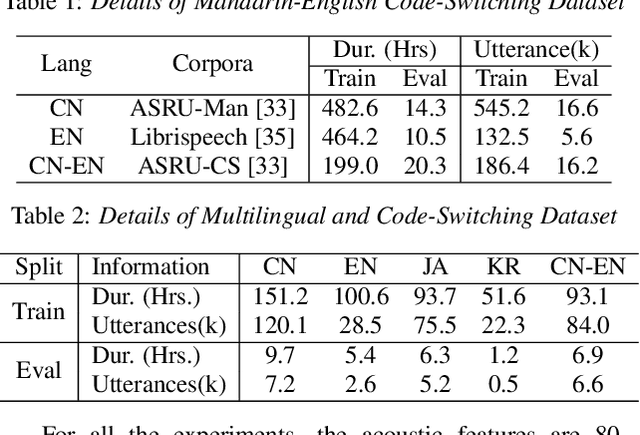
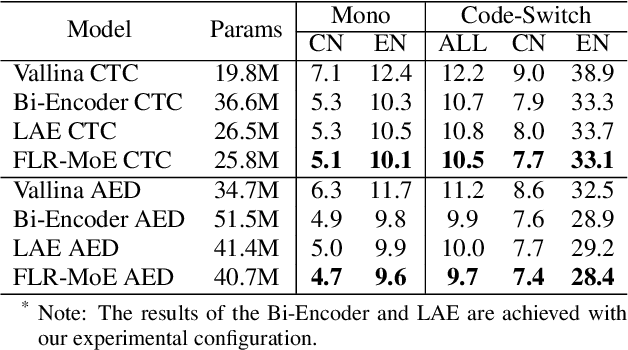
Multilingual speech recognition for both monolingual and code-switching speech is a challenging task. Recently, based on the Mixture of Experts (MoE), many works have made good progress in multilingual and code-switching ASR, but present huge computational complexity with the increase of supported languages. In this work, we propose a computation-efficient network named Language-Routing Mixture of Experts (LR-MoE) for multilingual and code-switching ASR. LR-MoE extracts language-specific representations through the Mixture of Language Experts (MLE), which is guided to learn by a frame-wise language routing mechanism. The weight-shared frame-level language identification (LID) network is jointly trained as the shared pre-router of each MoE layer. Experiments show that the proposed method significantly improves multilingual and code-switching speech recognition performances over baseline with comparable computational efficiency.
Controllable Emphasis with zero data for text-to-speech
Jul 13, 2023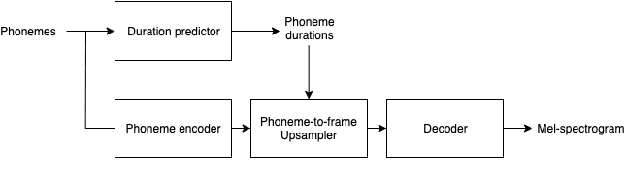

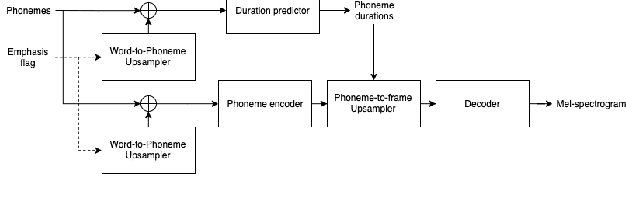
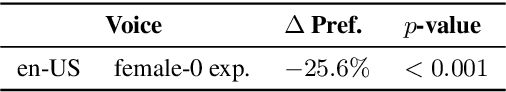
We present a scalable method to produce high quality emphasis for text-to-speech (TTS) that does not require recordings or annotations. Many TTS models include a phoneme duration model. A simple but effective method to achieve emphasized speech consists in increasing the predicted duration of the emphasised word. We show that this is significantly better than spectrogram modification techniques improving naturalness by $7.3\%$ and correct testers' identification of the emphasized word in a sentence by $40\%$ on a reference female en-US voice. We show that this technique significantly closes the gap to methods that require explicit recordings. The method proved to be scalable and preferred in all four languages tested (English, Spanish, Italian, German), for different voices and multiple speaking styles.
SpatialNet: Extensively Learning Spatial Information for Multichannel Joint Speech Separation, Denoising and Dereverberation
Jul 31, 2023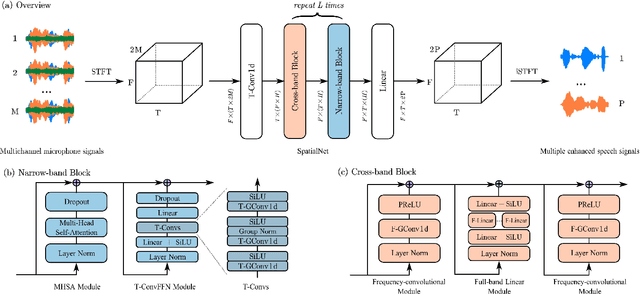

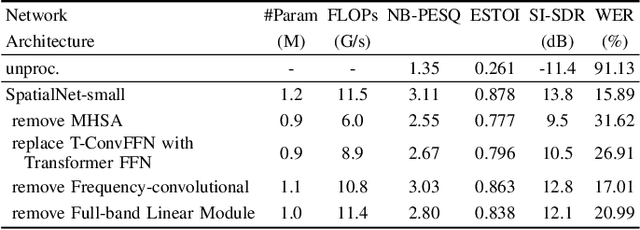
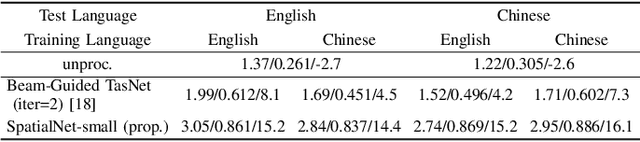
This work proposes a neural network to extensively exploit spatial information for multichannel joint speech separation, denoising and dereverberation, named SpatialNet.In the short-time Fourier transform (STFT) domain, the proposed network performs end-to-end speech enhancement. It is mainly composed of interleaved narrow-band and cross-band blocks to respectively exploit narrow-band and cross-band spatial information. The narrow-band blocks process frequencies independently, and use self-attention mechanism and temporal convolutional layers to respectively perform spatial-feature-based speaker clustering and temporal smoothing/filtering. The cross-band blocks processes frames independently, and use full-band linear layer and frequency convolutional layers to respectively learn the correlation between all frequencies and adjacent frequencies. Experiments are conducted on various simulated and real datasets, and the results show that 1) the proposed network achieves the state-of-the-art performance on almost all tasks; 2) the proposed network suffers little from the spectral generalization problem; and 3) the proposed network is indeed performing speaker clustering (demonstrated by attention maps).
Cordyceps@LT-EDI: Patching Language-Specific Homophobia/Transphobia Classifiers with a Multilingual Understanding
Sep 24, 2023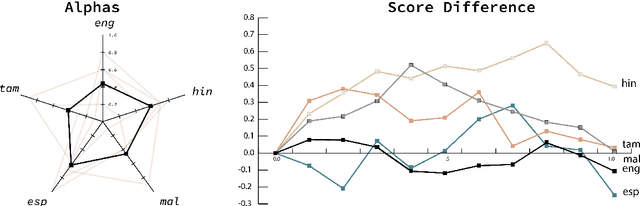
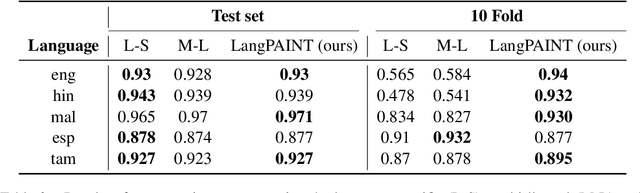
Detecting transphobia, homophobia, and various other forms of hate speech is difficult. Signals can vary depending on factors such as language, culture, geographical region, and the particular online platform. Here, we present a joint multilingual (M-L) and language-specific (L-S) approach to homophobia and transphobic hate speech detection (HSD). M-L models are needed to catch words, phrases, and concepts that are less common or missing in a particular language and subsequently overlooked by L-S models. Nonetheless, L-S models are better situated to understand the cultural and linguistic context of the users who typically write in a particular language. Here we construct a simple and successful way to merge the M-L and L-S approaches through simple weight interpolation in such a way that is interpretable and data-driven. We demonstrate our system on task A of the 'Shared Task on Homophobia/Transphobia Detection in social media comments' dataset for homophobia and transphobic HSD. Our system achieves the best results in three of five languages and achieves a 0.997 macro average F1-score on Malayalam texts.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 15, 2023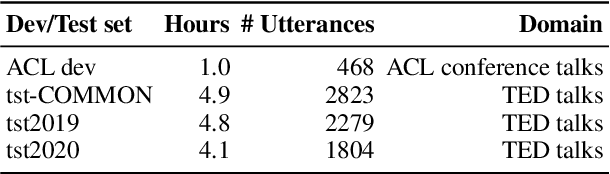
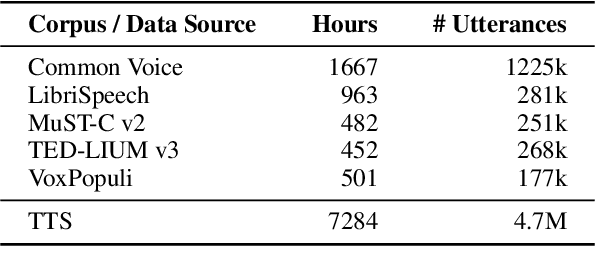
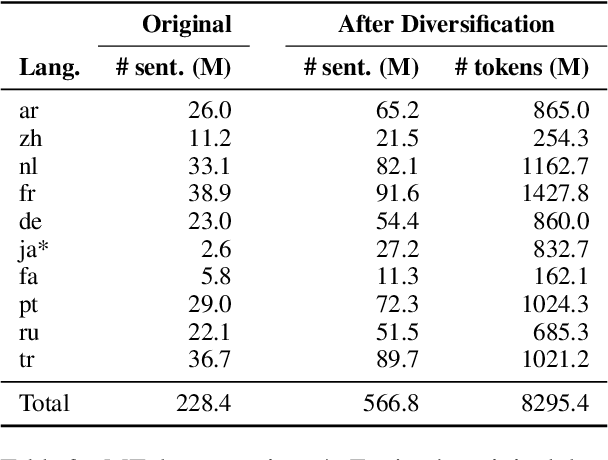
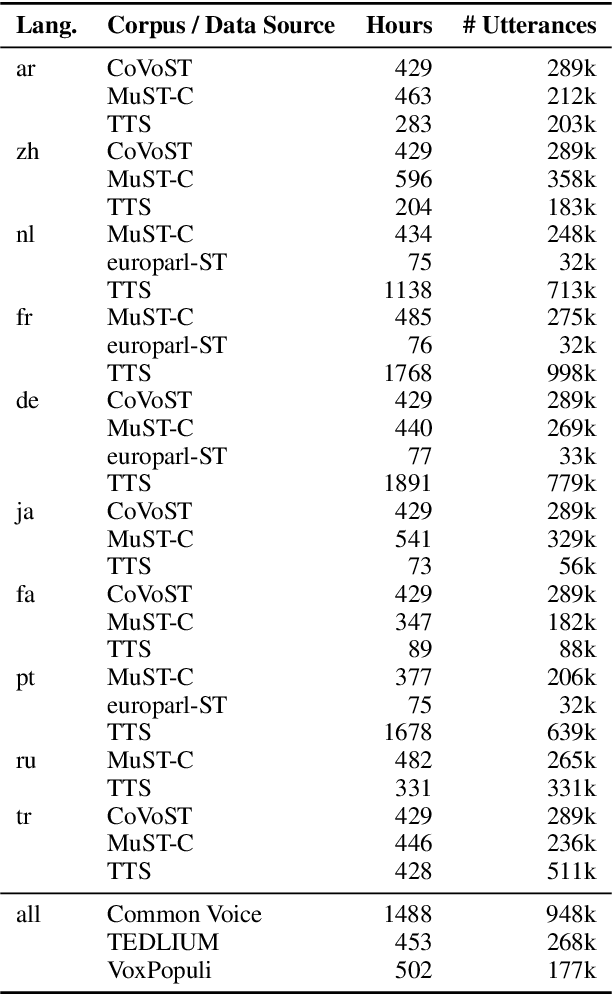
Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which evaluates translation quality on scientific conference talks. The test condition features accented input speech and terminology-dense contents. The task requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Semantic enrichment towards efficient speech representations
Jul 03, 2023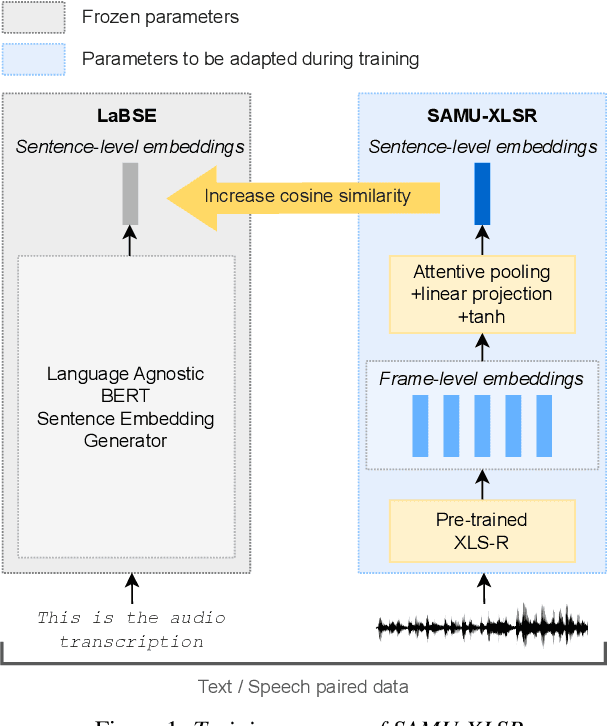
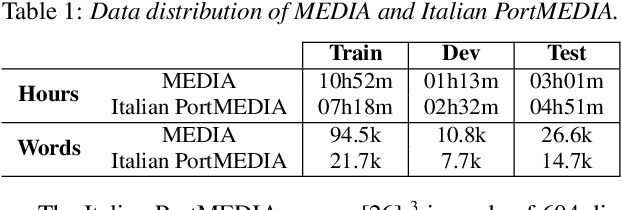
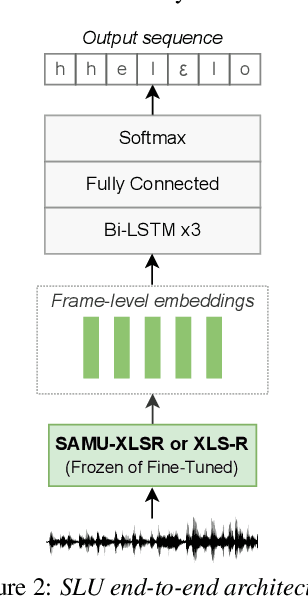
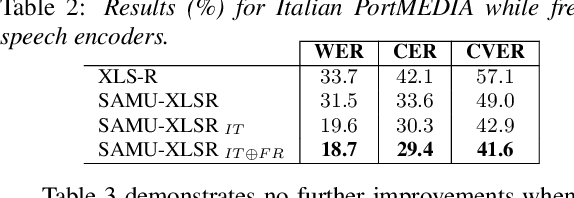
Over the past few years, self-supervised learned speech representations have emerged as fruitful replacements for conventional surface representations when solving Spoken Language Understanding (SLU) tasks. Simultaneously, multilingual models trained on massive textual data were introduced to encode language agnostic semantics. Recently, the SAMU-XLSR approach introduced a way to make profit from such textual models to enrich multilingual speech representations with language agnostic semantics. By aiming for better semantic extraction on a challenging Spoken Language Understanding task and in consideration with computation costs, this study investigates a specific in-domain semantic enrichment of the SAMU-XLSR model by specializing it on a small amount of transcribed data from the downstream task. In addition, we show the benefits of the use of same-domain French and Italian benchmarks for low-resource language portability and explore cross-domain capacities of the enriched SAMU-XLSR.
VIC-KD: Variance-Invariance-Covariance Knowledge Distillation to Make Keyword Spotting More Robust Against Adversarial Attacks
Sep 22, 2023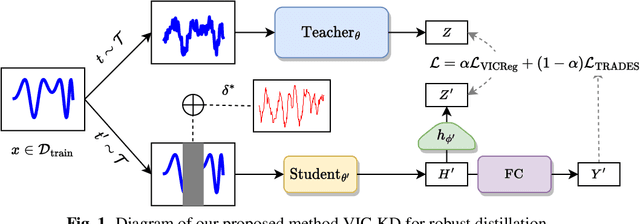
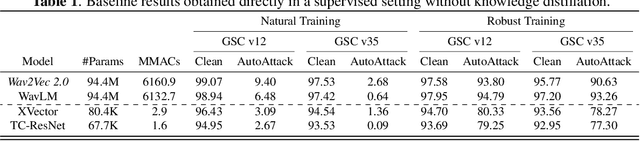
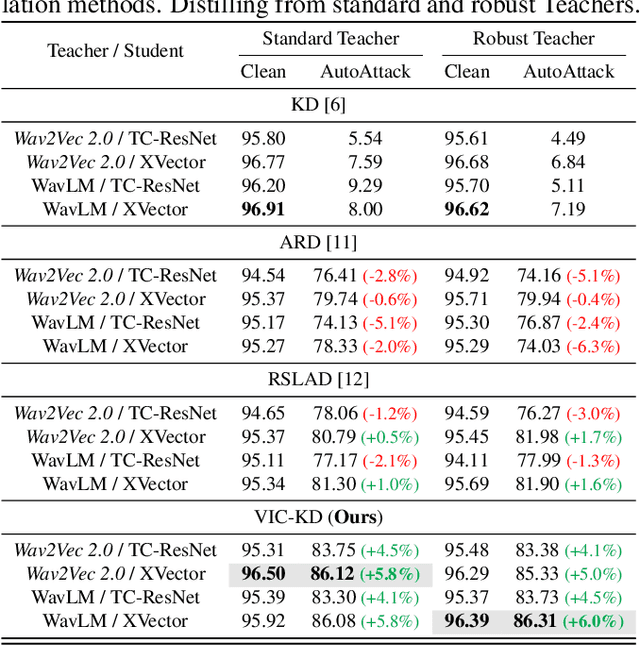
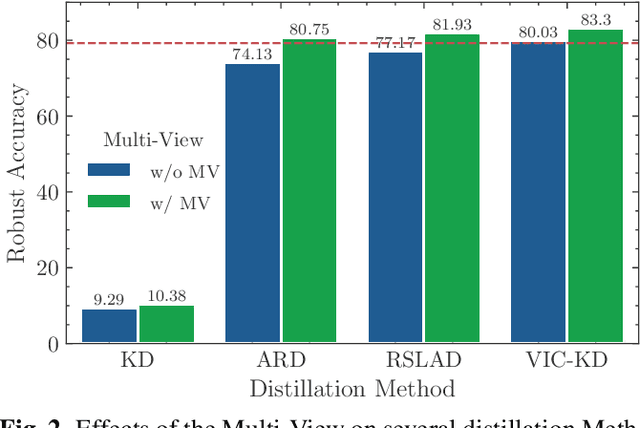
Keyword spotting (KWS) refers to the task of identifying a set of predefined words in audio streams. With the advances seen recently with deep neural networks, it has become a popular technology to activate and control small devices, such as voice assistants. Relying on such models for edge devices, however, can be challenging due to hardware constraints. Moreover, as adversarial attacks have increased against voice-based technologies, developing solutions robust to such attacks has become crucial. In this work, we propose VIC-KD, a robust distillation recipe for model compression and adversarial robustness. Using self-supervised speech representations, we show that imposing geometric priors to the latent representations of both Teacher and Student models leads to more robust target models. Experiments on the Google Speech Commands datasets show that the proposed methodology improves upon current state-of-the-art robust distillation methods, such as ARD and RSLAD, by 12% and 8% in robust accuracy, respectively.
Attentive Multi-Layer Perceptron for Non-autoregressive Generation
Oct 14, 2023Autoregressive~(AR) generation almost dominates sequence generation for its efficacy. Recently, non-autoregressive~(NAR) generation gains increasing popularity for its efficiency and growing efficacy. However, its efficiency is still bottlenecked by quadratic complexity in sequence lengths, which is prohibitive for scaling to long sequence generation and few works have been done to mitigate this problem. In this paper, we propose a novel MLP variant, \textbf{A}ttentive \textbf{M}ulti-\textbf{L}ayer \textbf{P}erceptron~(AMLP), to produce a generation model with linear time and space complexity. Different from classic MLP with static and learnable projection matrices, AMLP leverages adaptive projections computed from inputs in an attentive mode. The sample-aware adaptive projections enable communications among tokens in a sequence, and model the measurement between the query and key space. Furthermore, we marry AMLP with popular NAR models, deriving a highly efficient NAR-AMLP architecture with linear time and space complexity. Empirical results show that such marriage architecture surpasses competitive efficient NAR models, by a significant margin on text-to-speech synthesis and machine translation. We also test AMLP's self- and cross-attention ability separately with extensive ablation experiments, and find them comparable or even superior to the other efficient models. The efficiency analysis further shows that AMLP extremely reduces the memory cost against vanilla non-autoregressive models for long sequences.
Generative Spoken Language Model based on continuous word-sized audio tokens
Oct 08, 2023In NLP, text language models based on words or subwords are known to outperform their character-based counterparts. Yet, in the speech community, the standard input of spoken LMs are 20ms or 40ms-long discrete units (shorter than a phoneme). Taking inspiration from word-based LM, we introduce a Generative Spoken Language Model (GSLM) based on word-size continuous-valued audio embeddings that can generate diverse and expressive language output. This is obtained by replacing lookup table for lexical types with a Lexical Embedding function, the cross entropy loss by a contrastive loss, and multinomial sampling by k-NN sampling. The resulting model is the first generative language model based on word-size continuous embeddings. Its performance is on par with discrete unit GSLMs regarding generation quality as measured by automatic metrics and subjective human judgements. Moreover, it is five times more memory efficient thanks to its large 200ms units. In addition, the embeddings before and after the Lexical Embedder are phonetically and semantically interpretable.