 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Controllable Data Generation Via Iterative Data-Property Mutual Mappings
Oct 11, 2023
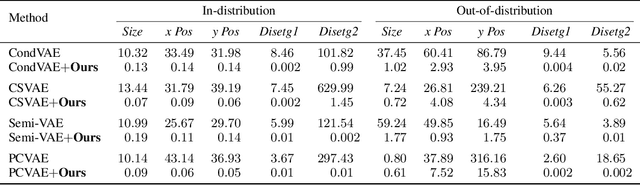
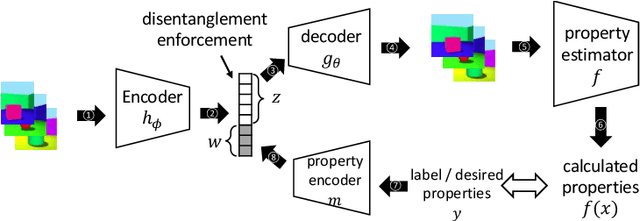
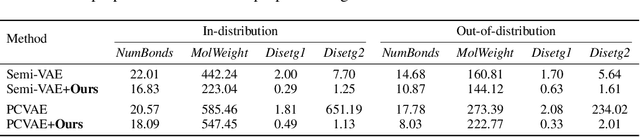
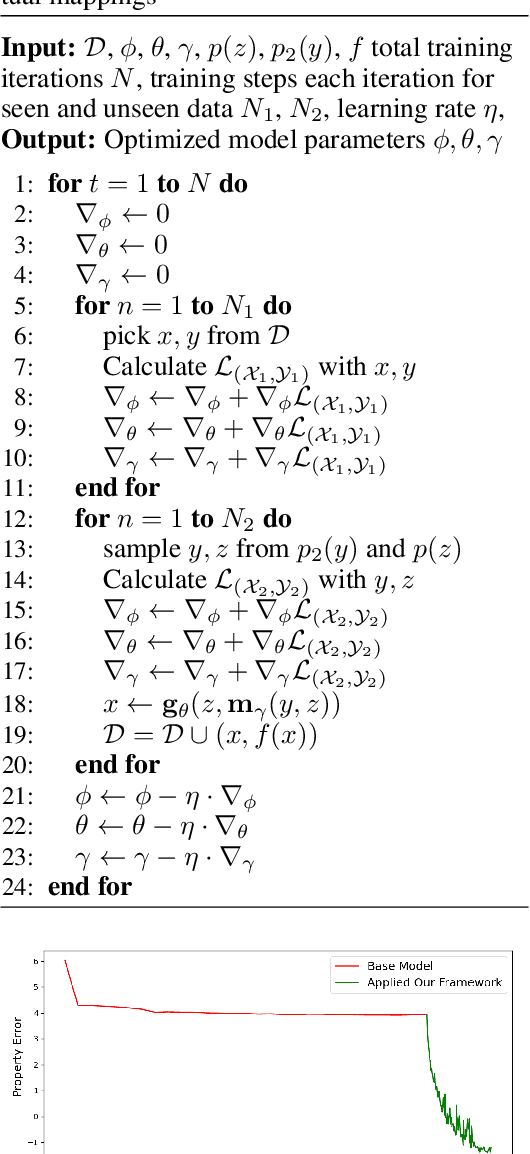
Deep generative models have been widely used for their ability to generate realistic data samples in various areas, such as images, molecules, text, and speech. One major goal of data generation is controllability, namely to generate new data with desired properties. Despite growing interest in the area of controllable generation, significant challenges still remain, including 1) disentangling desired properties with unrelated latent variables, 2) out-of-distribution property control, and 3) objective optimization for out-of-distribution property control. To address these challenges, in this paper, we propose a general framework to enhance VAE-based data generators with property controllability and ensure disentanglement. Our proposed objective can be optimized on both data seen and unseen in the training set. We propose a training procedure to train the objective in a semi-supervised manner by iteratively conducting mutual mappings between the data and properties. The proposed framework is implemented on four VAE-based controllable generators to evaluate its performance on property error, disentanglement, generation quality, and training time. The results indicate that our proposed framework enables more precise control over the properties of generated samples in a short training time, ensuring the disentanglement and keeping the validity of the generated samples.
UniAudio: An Audio Foundation Model Toward Universal Audio Generation
Oct 11, 2023
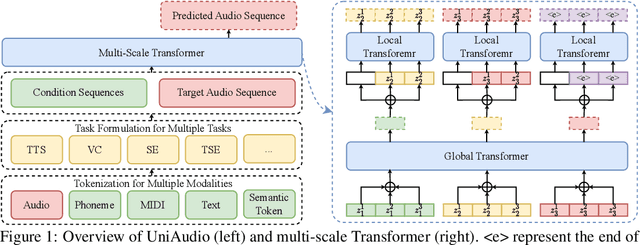
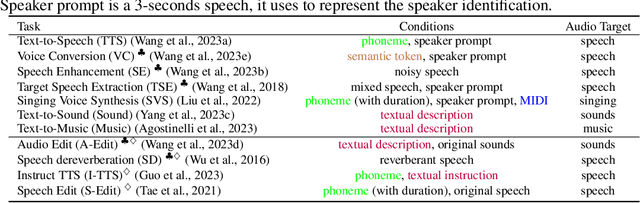
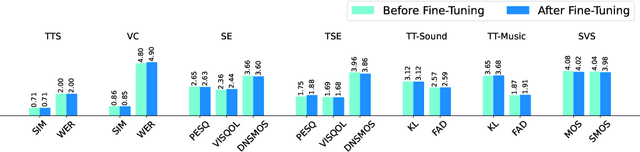
Large Language models (LLM) have demonstrated the capability to handle a variety of generative tasks. This paper presents the UniAudio system, which, unlike prior task-specific approaches, leverages LLM techniques to generate multiple types of audio (including speech, sounds, music, and singing) with given input conditions. UniAudio 1) first tokenizes all types of target audio along with other condition modalities, 2) concatenates source-target pair as a single sequence, and 3) performs next-token prediction using LLM. Also, a multi-scale Transformer model is proposed to handle the overly long sequences caused by the residual vector quantization based neural codec in tokenization. Training of UniAudio is scaled up to 165K hours of audio and 1B parameters, based on all generative tasks, aiming to obtain sufficient prior knowledge not only in the intrinsic properties of audio but also the inter-relationship between audio and other modalities. Therefore, the trained UniAudio model has the potential to become a foundation model for universal audio generation: it shows strong capability in all trained tasks and can seamlessly support new audio generation tasks after simple fine-tuning. Experiments demonstrate that UniAudio achieves state-of-the-art or at least competitive results on most of the 11 tasks. Demo and code are released at https://github.com/yangdongchao/UniAudio
CB-Whisper: Contextual Biasing Whisper using TTS-based Keyword Spotting
Sep 18, 2023
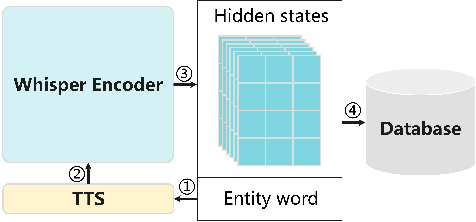
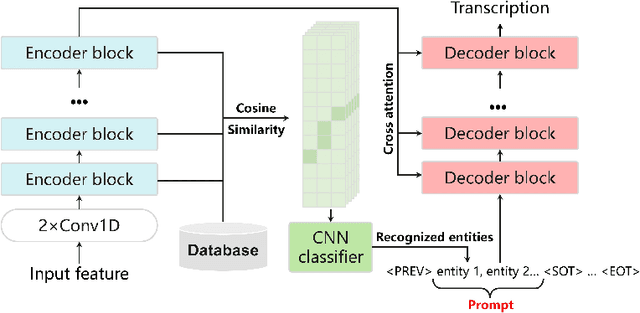
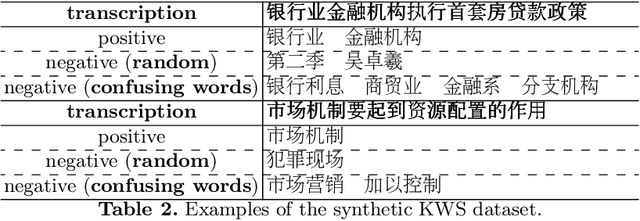
End-to-end automatic speech recognition (ASR) systems often struggle to recognize rare name entities, such as personal names, organizations, or technical terms that are not frequently encountered in the training data. This paper presents Contextual Biasing Whisper (CB-Whisper), a novel ASR system based on OpenAI's Whisper model that performs keyword-spotting (KWS) before the decoder. The KWS module leverages text-to-speech (TTS) techniques and a convolutional neural network (CNN) classifier to match the features between the entities and the utterances. Experiments demonstrate that by incorporating predicted entities into a carefully designed spoken form prompt, the mixed-error-rate (MER) and entity recall of the Whisper model is significantly improved on three internal datasets and two open-sourced datasets that cover English-only, Chinese-only, and code-switching scenarios.
The complementary roles of non-verbal cues for Robust Pronunciation Assessment
Sep 14, 2023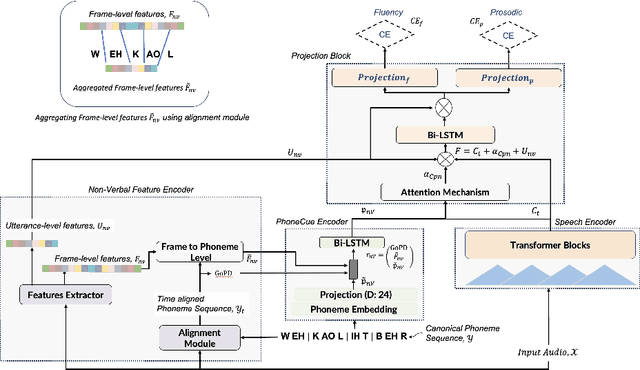
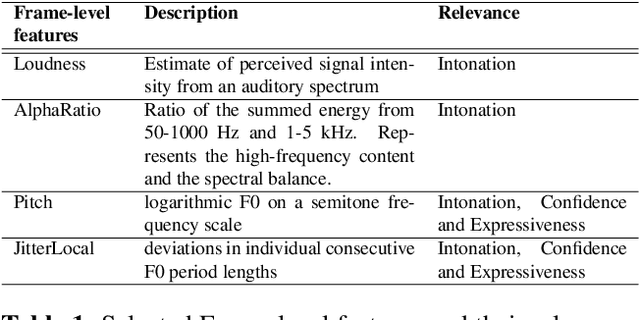
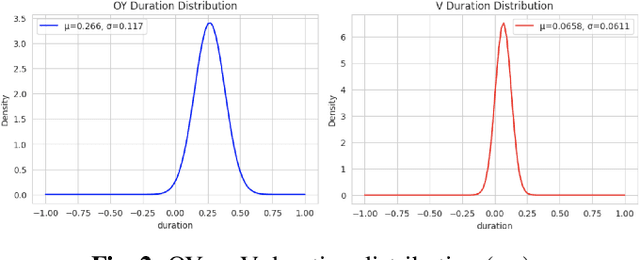
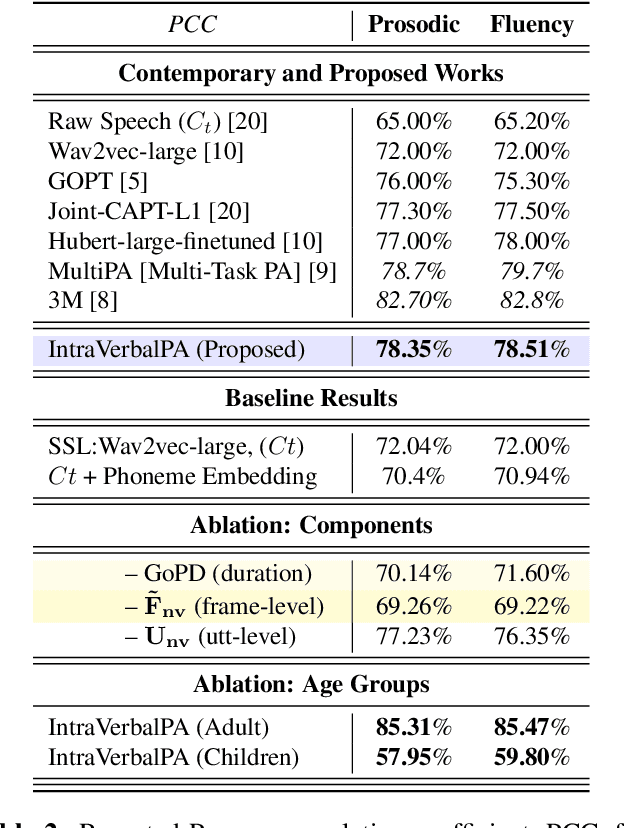
Research on pronunciation assessment systems focuses on utilizing phonetic and phonological aspects of non-native (L2) speech, often neglecting the rich layer of information hidden within the non-verbal cues. In this study, we proposed a novel pronunciation assessment framework, IntraVerbalPA. % The framework innovatively incorporates both fine-grained frame- and abstract utterance-level non-verbal cues, alongside the conventional speech and phoneme representations. Additionally, we introduce ''Goodness of phonemic-duration'' metric to effectively model duration distribution within the framework. Our results validate the effectiveness of the proposed IntraVerbalPA framework and its individual components, yielding performance that either matches or outperforms existing research works.
Semantic enrichment towards efficient speech representations
Jul 03, 2023
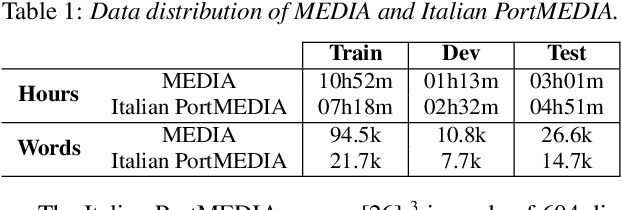
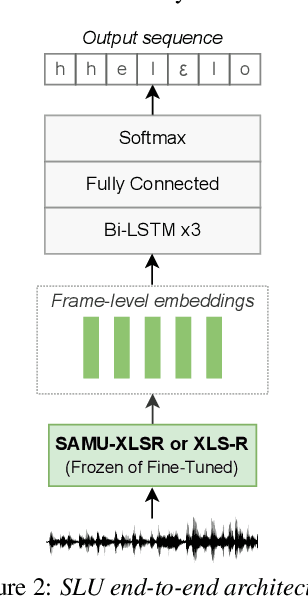
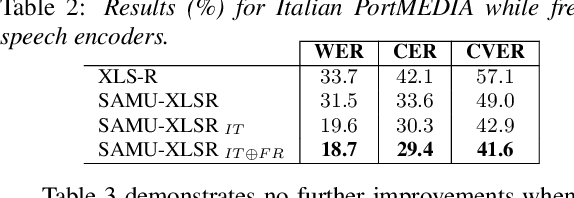
Over the past few years, self-supervised learned speech representations have emerged as fruitful replacements for conventional surface representations when solving Spoken Language Understanding (SLU) tasks. Simultaneously, multilingual models trained on massive textual data were introduced to encode language agnostic semantics. Recently, the SAMU-XLSR approach introduced a way to make profit from such textual models to enrich multilingual speech representations with language agnostic semantics. By aiming for better semantic extraction on a challenging Spoken Language Understanding task and in consideration with computation costs, this study investigates a specific in-domain semantic enrichment of the SAMU-XLSR model by specializing it on a small amount of transcribed data from the downstream task. In addition, we show the benefits of the use of same-domain French and Italian benchmarks for low-resource language portability and explore cross-domain capacities of the enriched SAMU-XLSR.
KIT's Multilingual Speech Translation System for IWSLT 2023
Jun 15, 2023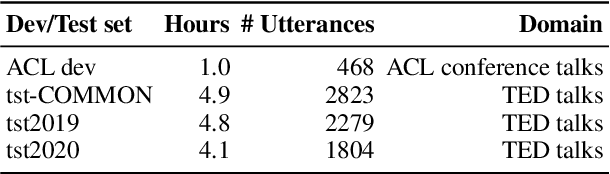
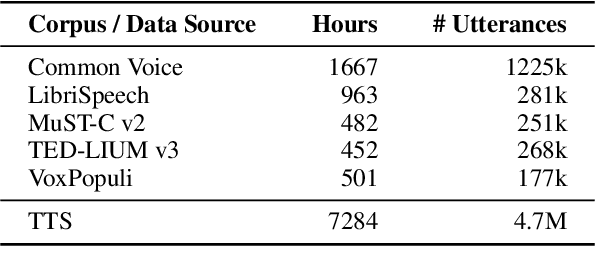
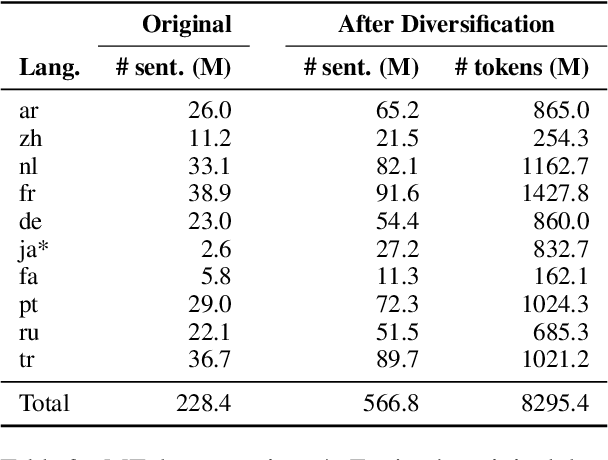
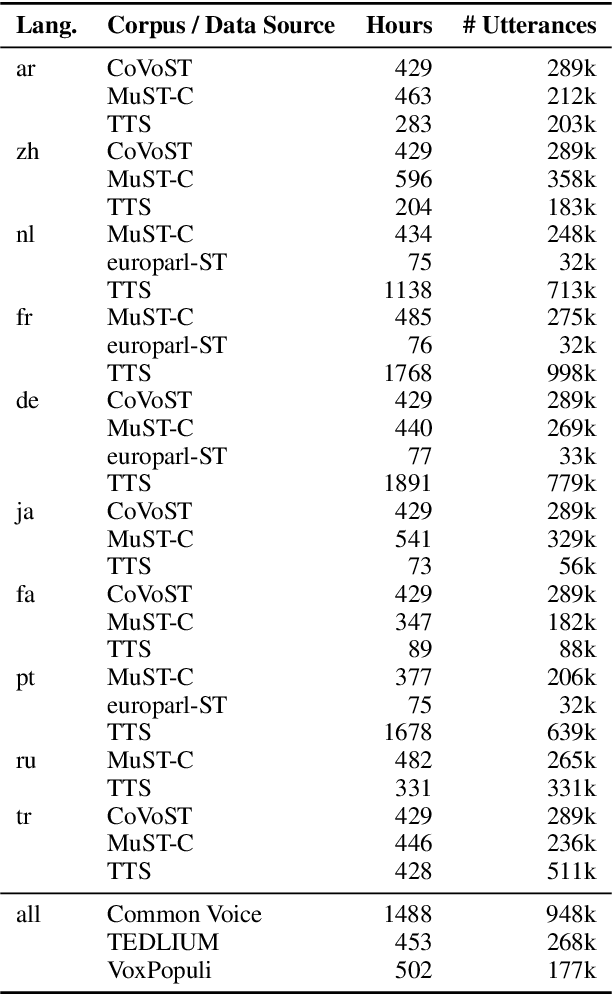
Many existing speech translation benchmarks focus on native-English speech in high-quality recording conditions, which often do not match the conditions in real-life use-cases. In this paper, we describe our speech translation system for the multilingual track of IWSLT 2023, which evaluates translation quality on scientific conference talks. The test condition features accented input speech and terminology-dense contents. The task requires translation into 10 languages of varying amounts of resources. In absence of training data from the target domain, we use a retrieval-based approach (kNN-MT) for effective adaptation (+0.8 BLEU for speech translation). We also use adapters to easily integrate incremental training data from data augmentation, and show that it matches the performance of re-training. We observe that cascaded systems are more easily adaptable towards specific target domains, due to their separate modules. Our cascaded speech system substantially outperforms its end-to-end counterpart on scientific talk translation, although their performance remains similar on TED talks.
Leveraging Label Information for Multimodal Emotion Recognition
Sep 05, 2023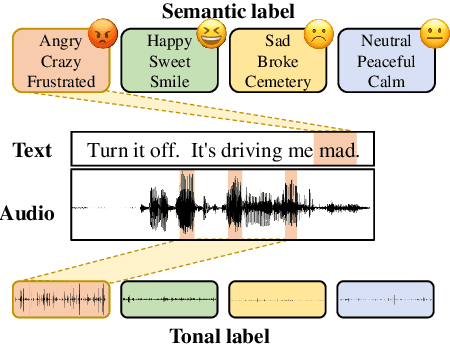

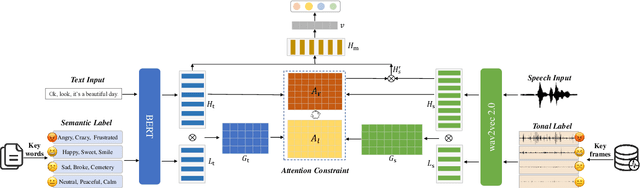
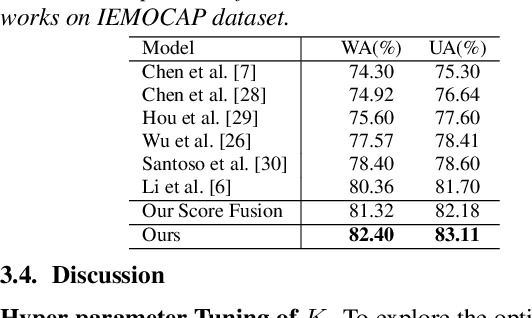
Multimodal emotion recognition (MER) aims to detect the emotional status of a given expression by combining the speech and text information. Intuitively, label information should be capable of helping the model locate the salient tokens/frames relevant to the specific emotion, which finally facilitates the MER task. Inspired by this, we propose a novel approach for MER by leveraging label information. Specifically, we first obtain the representative label embeddings for both text and speech modalities, then learn the label-enhanced text/speech representations for each utterance via label-token and label-frame interactions. Finally, we devise a novel label-guided attentive fusion module to fuse the label-aware text and speech representations for emotion classification. Extensive experiments were conducted on the public IEMOCAP dataset, and experimental results demonstrate that our proposed approach outperforms existing baselines and achieves new state-of-the-art performance.
Severity Classification of Parkinson's Disease from Speech using Single Frequency Filtering-based Features
Aug 17, 2023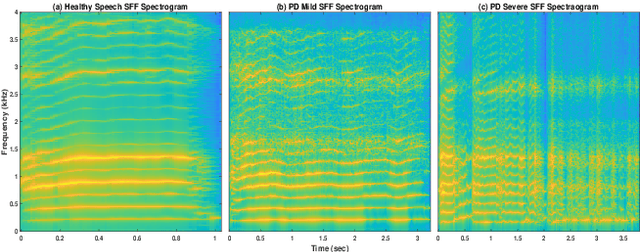
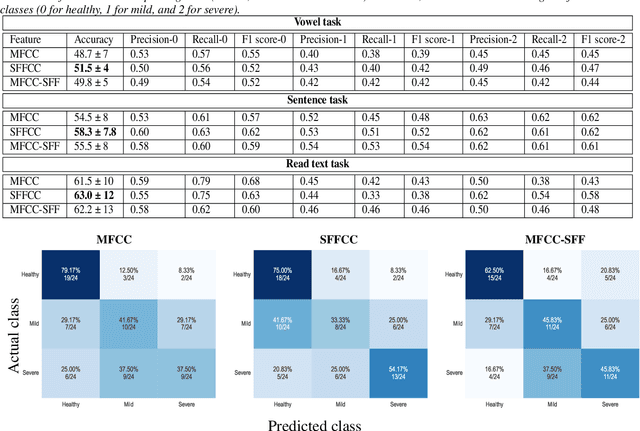
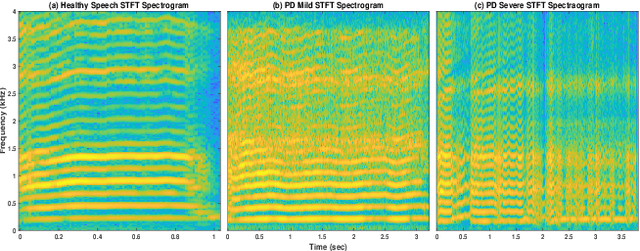
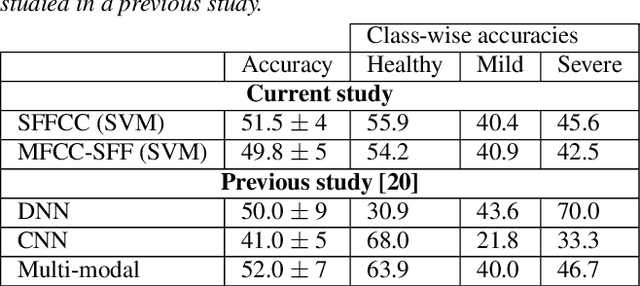
Developing objective methods for assessing the severity of Parkinson's disease (PD) is crucial for improving the diagnosis and treatment. This study proposes two sets of novel features derived from the single frequency filtering (SFF) method: (1) SFF cepstral coefficients (SFFCC) and (2) MFCCs from the SFF (MFCC-SFF) for the severity classification of PD. Prior studies have demonstrated that SFF offers greater spectro-temporal resolution compared to the short-time Fourier transform. The study uses the PC-GITA database, which includes speech of PD patients and healthy controls produced in three speaking tasks (vowels, sentences, text reading). Experiments using the SVM classifier revealed that the proposed features outperformed the conventional MFCCs in all three speaking tasks. The proposed SFFCC and MFCC-SFF features gave a relative improvement of 5.8% and 2.3% for the vowel task, 7.0% & 1.8% for the sentence task, and 2.4% and 1.1% for the read text task, in comparison to MFCC features.
An Effective Transformer-based Contextual Model and Temporal Gate Pooling for Speaker Identification
Sep 10, 2023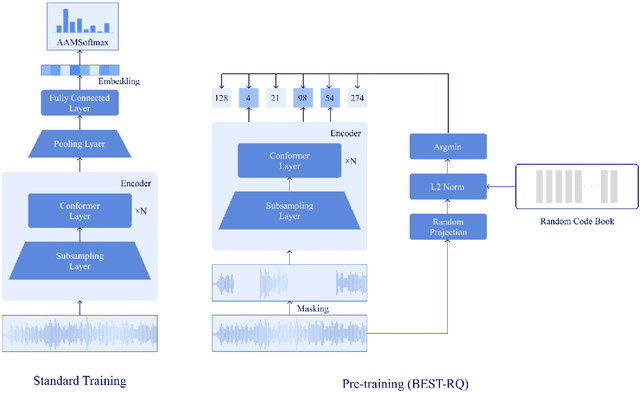
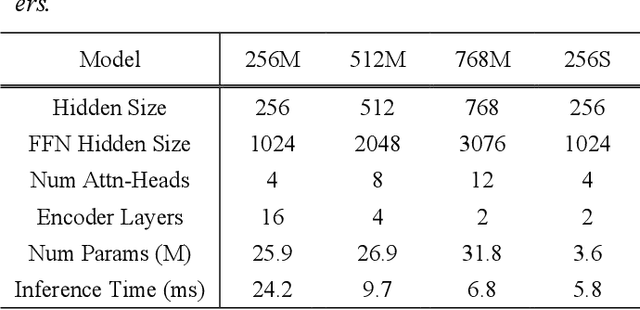
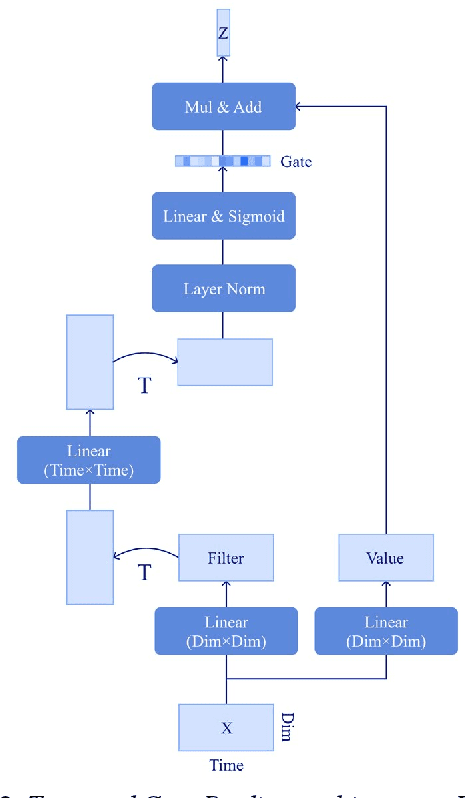
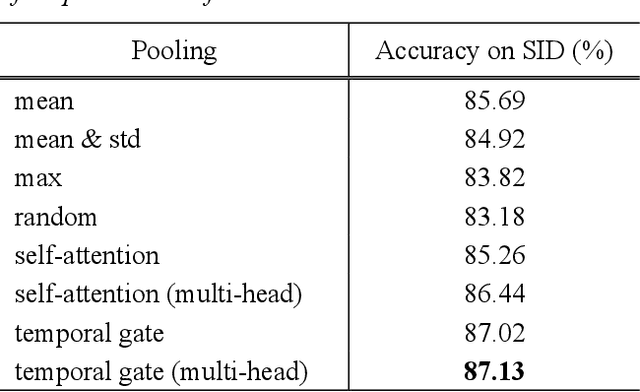
Wav2vec2 has achieved success in applying Transformer architecture and self-supervised learning to speech recognition. Recently, these have come to be used not only for speech recognition but also for the entire speech processing. This paper introduces an effective end-to-end speaker identification model applied Transformer-based contextual model. We explored the relationship between the hyper-parameters and the performance in order to discern the structure of an effective model. Furthermore, we propose a pooling method, Temporal Gate Pooling, with powerful learning ability for speaker identification. We applied Conformer as encoder and BEST-RQ for pre-training and conducted an evaluation utilizing the speaker identification of VoxCeleb1. The proposed method has achieved an accuracy of 87.1% with 28.5M parameters, demonstrating comparable precision to wav2vec2 with 317.7M parameters. Code is available at https://github.com/HarunoriKawano/speaker-identification-with-tgp.
Generative Speech Recognition Error Correction with Large Language Models
Sep 27, 2023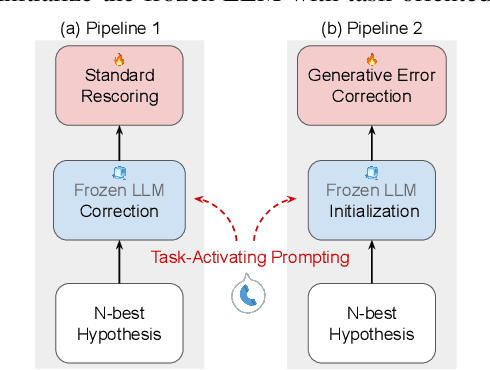
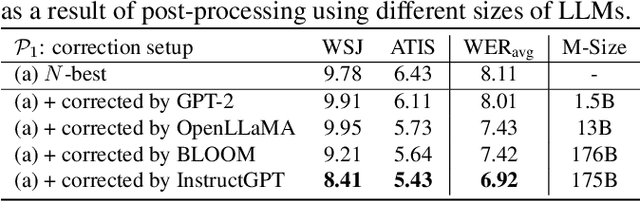
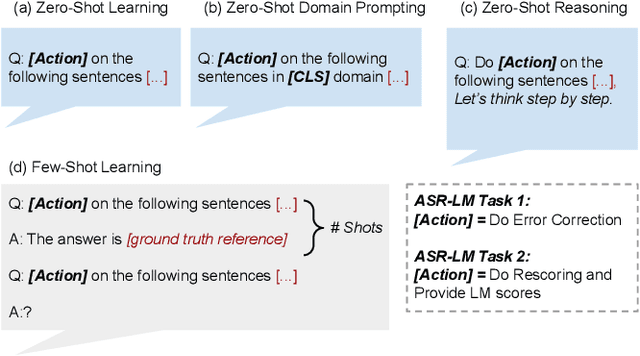
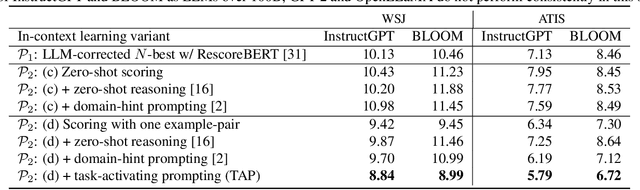
We explore the ability of large language models (LLMs) to act as ASR post-processors that perform rescoring and error correction. Our focus is on instruction prompting to let LLMs perform these task without fine-tuning, for which we evaluate different prompting schemes, both zero- and few-shot in-context learning, and a novel task-activating prompting (TAP) method that combines instruction and demonstration. Using a pre-trained first-pass system and rescoring output on two out-of-domain tasks (ATIS and WSJ), we show that rescoring only by in-context learning with frozen LLMs achieves results that are competitive with rescoring by domain-tuned LMs. By combining prompting techniques with fine-tuning we achieve error rates below the N-best oracle level, showcasing the generalization power of the LLMs.