 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading
Jul 03, 2023
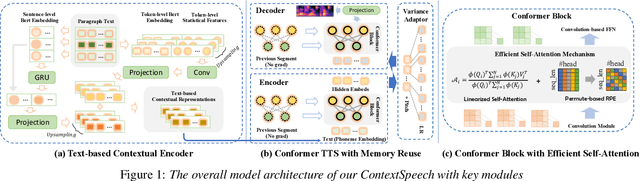

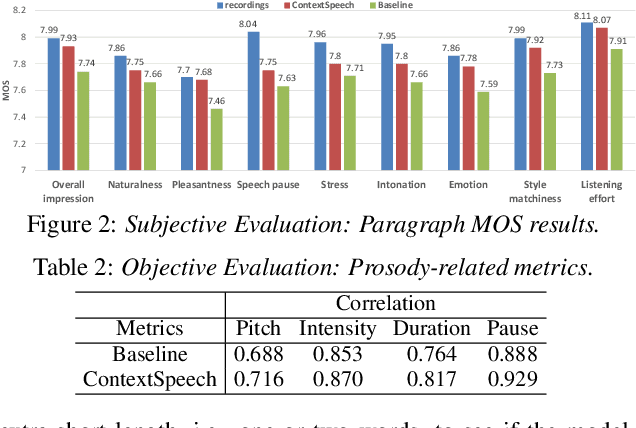
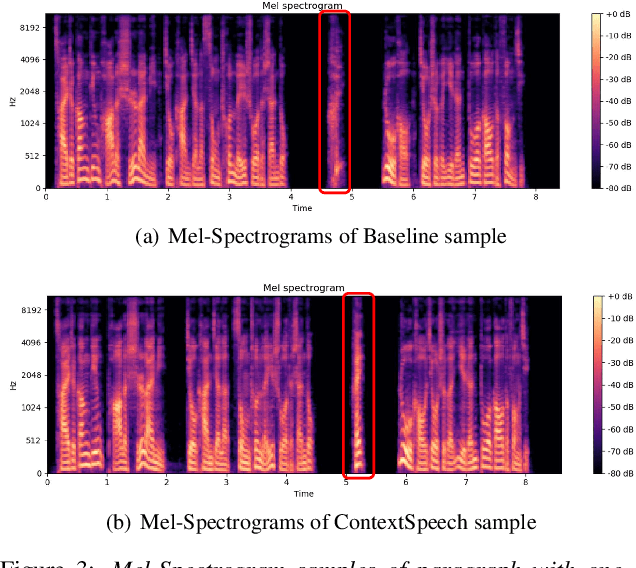
While state-of-the-art Text-to-Speech systems can generate natural speech of very high quality at sentence level, they still meet great challenges in speech generation for paragraph / long-form reading. Such deficiencies are due to i) ignorance of cross-sentence contextual information, and ii) high computation and memory cost for long-form synthesis. To address these issues, this work develops a lightweight yet effective TTS system, ContextSpeech. Specifically, we first design a memory-cached recurrence mechanism to incorporate global text and speech context into sentence encoding. Then we construct hierarchically-structured textual semantics to broaden the scope for global context enhancement. Additionally, we integrate linearized self-attention to improve model efficiency. Experiments show that ContextSpeech significantly improves the voice quality and prosody expressiveness in paragraph reading with competitive model efficiency. Audio samples are available at: https://contextspeech.github.io/demo/
Sparse Fine-tuning for Inference Acceleration of Large Language Models
Oct 13, 2023We consider the problem of accurate sparse fine-tuning of large language models (LLMs), that is, fine-tuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based fine-tuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse fine-tuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
Vesper: A Compact and Effective Pretrained Model for Speech Emotion Recognition
Jul 20, 2023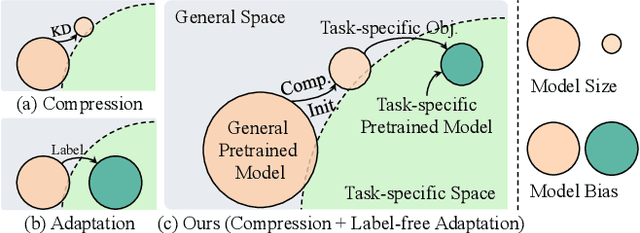
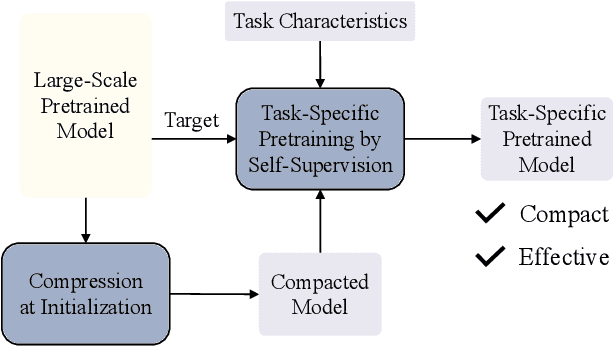
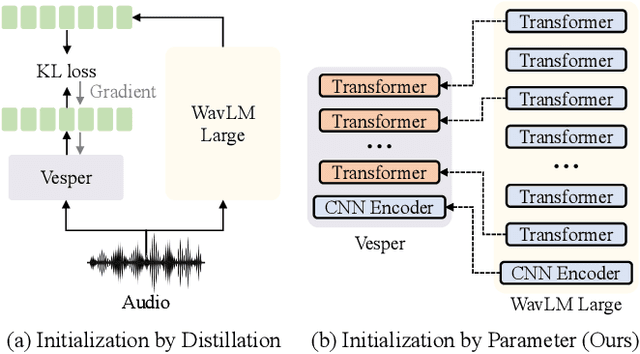
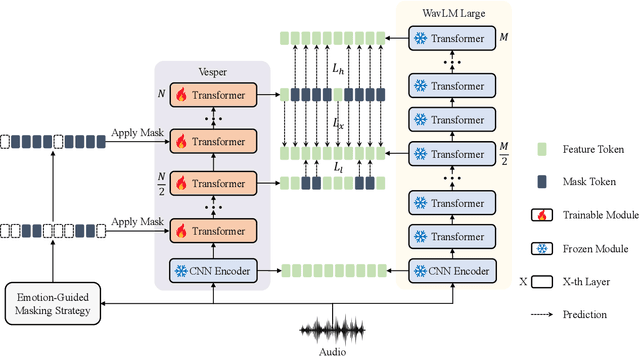
This paper presents a paradigm that adapts general large-scale pretrained models (PTMs) to speech emotion recognition task. Although PTMs shed new light on artificial general intelligence, they are constructed with general tasks in mind, and thus, their efficacy for specific tasks can be further improved. Additionally, employing PTMs in practical applications can be challenging due to their considerable size. Above limitations spawn another research direction, namely, optimizing large-scale PTMs for specific tasks to generate task-specific PTMs that are both compact and effective. In this paper, we focus on the speech emotion recognition task and propose an improved emotion-specific pretrained encoder called Vesper. Vesper is pretrained on a speech dataset based on WavLM and takes into account emotional characteristics. To enhance sensitivity to emotional information, Vesper employs an emotion-guided masking strategy to identify the regions that need masking. Subsequently, Vesper employs hierarchical and cross-layer self-supervision to improve its ability to capture acoustic and semantic representations, both of which are crucial for emotion recognition. Experimental results on the IEMOCAP, MELD, and CREMA-D datasets demonstrate that Vesper with 4 layers outperforms WavLM Base with 12 layers, and the performance of Vesper with 12 layers surpasses that of WavLM Large with 24 layers.
Developing Speech Processing Pipelines for Police Accountability
Jun 09, 2023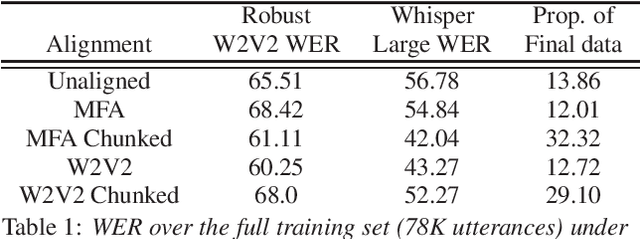
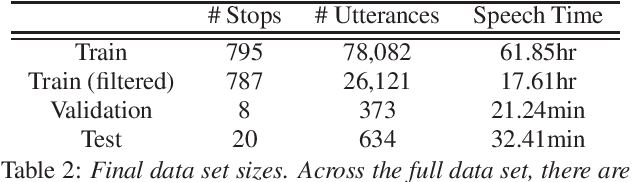
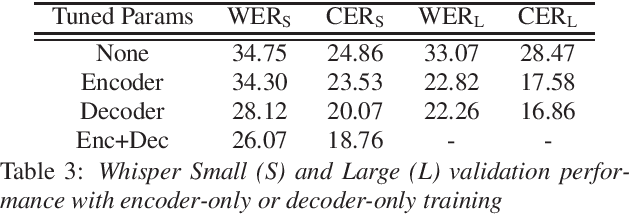
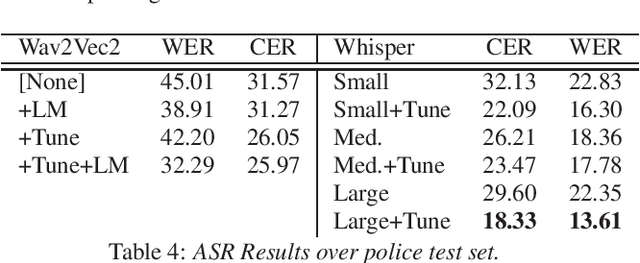
Police body-worn cameras have the potential to improve accountability and transparency in policing. Yet in practice, they result in millions of hours of footage that is never reviewed. We investigate the potential of large pre-trained speech models for facilitating reviews, focusing on ASR and officer speech detection in footage from traffic stops. Our proposed pipeline includes training data alignment and filtering, fine-tuning with resource constraints, and combining officer speech detection with ASR for a fully automated approach. We find that (1) fine-tuning strongly improves ASR performance on officer speech (WER=12-13%), (2) ASR on officer speech is much more accurate than on community member speech (WER=43.55-49.07%), (3) domain-specific tasks like officer speech detection and diarization remain challenging. Our work offers practical applications for reviewing body camera footage and general guidance for adapting pre-trained speech models to noisy multi-speaker domains.
Language-Routing Mixture of Experts for Multilingual and Code-Switching Speech Recognition
Jul 14, 2023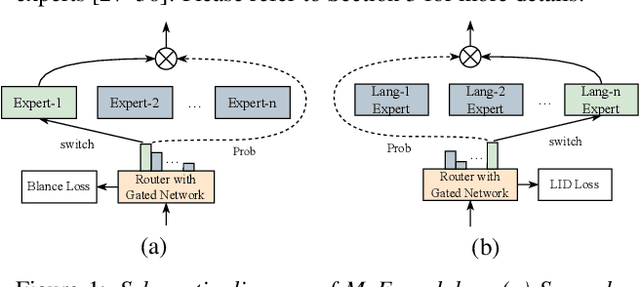
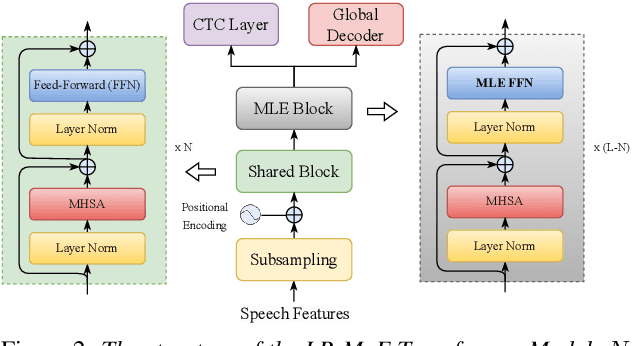
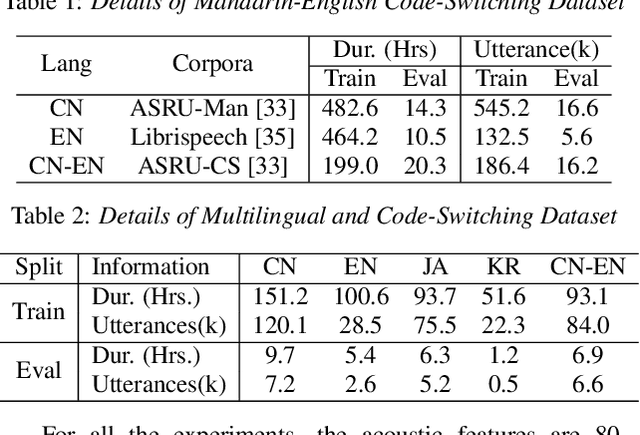
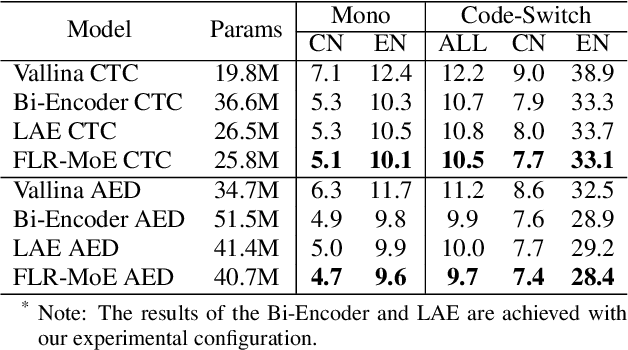
Multilingual speech recognition for both monolingual and code-switching speech is a challenging task. Recently, based on the Mixture of Experts (MoE), many works have made good progress in multilingual and code-switching ASR, but present huge computational complexity with the increase of supported languages. In this work, we propose a computation-efficient network named Language-Routing Mixture of Experts (LR-MoE) for multilingual and code-switching ASR. LR-MoE extracts language-specific representations through the Mixture of Language Experts (MLE), which is guided to learn by a frame-wise language routing mechanism. The weight-shared frame-level language identification (LID) network is jointly trained as the shared pre-router of each MoE layer. Experiments show that the proposed method significantly improves multilingual and code-switching speech recognition performances over baseline with comparable computational efficiency.
Comparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Jul 31, 2023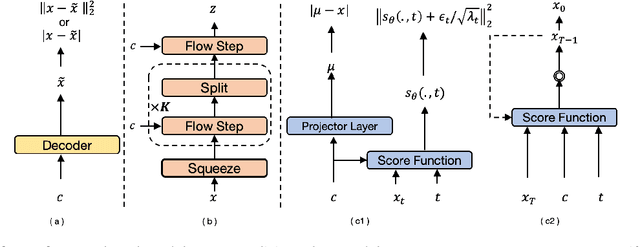
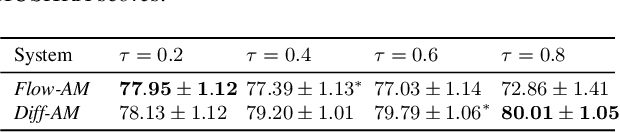
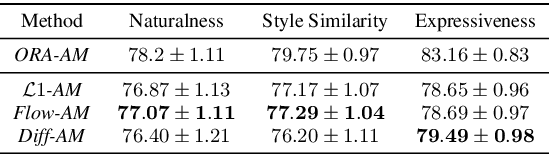
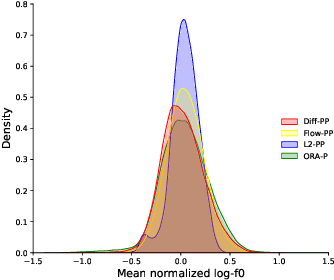
Neural text-to-speech systems are often optimized on L1/L2 losses, which make strong assumptions about the distributions of the target data space. Aiming to improve those assumptions, Normalizing Flows and Diffusion Probabilistic Models were recently proposed as alternatives. In this paper, we compare traditional L1/L2-based approaches to diffusion and flow-based approaches for the tasks of prosody and mel-spectrogram prediction for text-to-speech synthesis. We use a prosody model to generate log-f0 and duration features, which are used to condition an acoustic model that generates mel-spectrograms. Experimental results demonstrate that the flow-based model achieves the best performance for spectrogram prediction, improving over equivalent diffusion and L1 models. Meanwhile, both diffusion and flow-based prosody predictors result in significant improvements over a typical L2-trained prosody models.
Leveraging Visemes for Better Visual Speech Representation and Lip Reading
Jul 19, 2023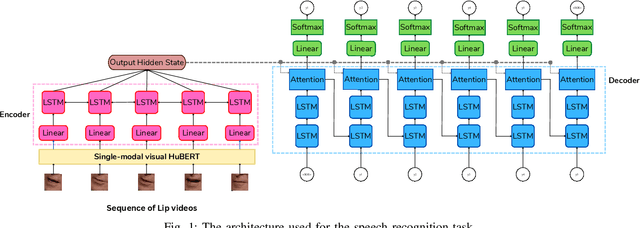
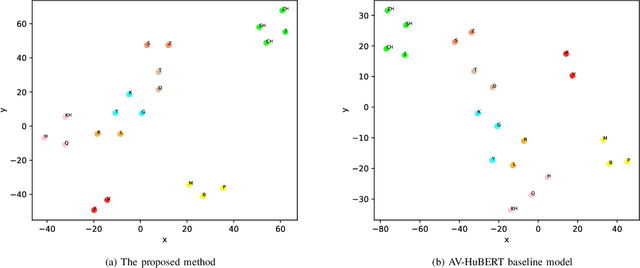
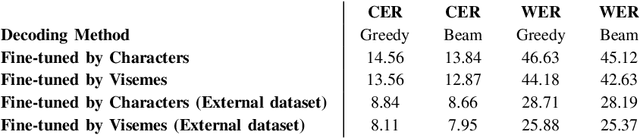
Lip reading is a challenging task that has many potential applications in speech recognition, human-computer interaction, and security systems. However, existing lip reading systems often suffer from low accuracy due to the limitations of video features. In this paper, we propose a novel approach that leverages visemes, which are groups of phonetically similar lip shapes, to extract more discriminative and robust video features for lip reading. We evaluate our approach on various tasks, including word-level and sentence-level lip reading, and audiovisual speech recognition using the Arman-AV dataset, a largescale Persian corpus. Our experimental results show that our viseme based approach consistently outperforms the state-of-theart methods in all these tasks. The proposed method reduces the lip-reading word error rate (WER) by 9.1% relative to the best previous method.
DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers
Oct 05, 2023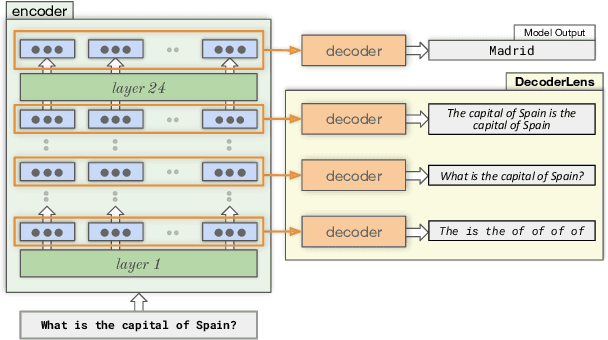
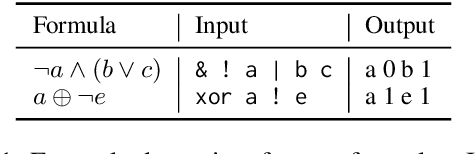
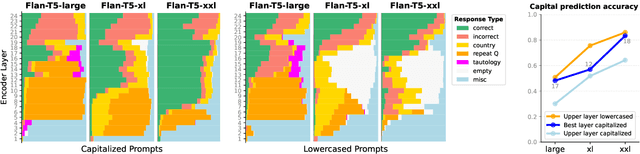

In recent years, many interpretability methods have been proposed to help interpret the internal states of Transformer-models, at different levels of precision and complexity. Here, to analyze encoder-decoder Transformers, we propose a simple, new method: DecoderLens. Inspired by the LogitLens (for decoder-only Transformers), this method involves allowing the decoder to cross-attend representations of intermediate encoder layers instead of using the final encoder output, as is normally done in encoder-decoder models. The method thus maps previously uninterpretable vector representations to human-interpretable sequences of words or symbols. We report results from the DecoderLens applied to models trained on question answering, logical reasoning, speech recognition and machine translation. The DecoderLens reveals several specific subtasks that are solved at low or intermediate layers, shedding new light on the information flow inside the encoder component of this important class of models.
StyleS2ST: Zero-shot Style Transfer for Direct Speech-to-speech Translation
Jun 01, 2023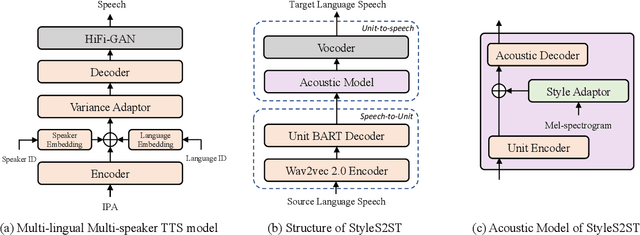
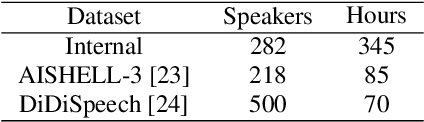
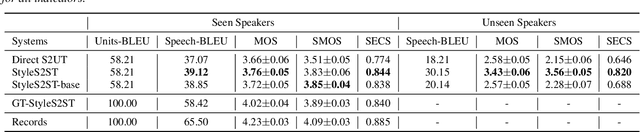
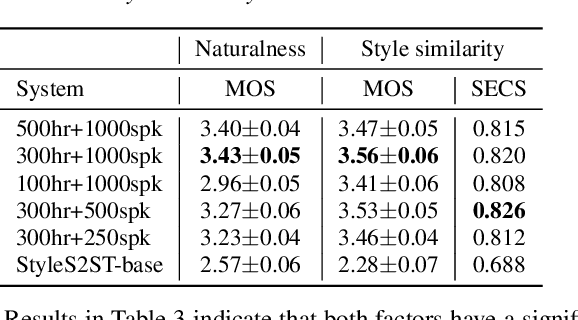
Direct speech-to-speech translation (S2ST) has gradually become popular as it has many advantages compared with cascade S2ST. However, current research mainly focuses on the accuracy of semantic translation and ignores the speech style transfer from a source language to a target language. The lack of high-fidelity expressive parallel data makes such style transfer challenging, especially in more practical zero-shot scenarios. To solve this problem, we first build a parallel corpus using a multi-lingual multi-speaker text-to-speech synthesis (TTS) system and then propose the StyleS2ST model with cross-lingual speech style transfer ability based on a style adaptor on a direct S2ST system framework. Enabling continuous style space modeling of an acoustic model through parallel corpus training and non-parallel TTS data augmentation, StyleS2ST captures cross-lingual acoustic feature mapping from the source to the target language. Experiments show that StyleS2ST achieves good style similarity and naturalness in both in-set and out-of-set zero-shot scenarios.
The timing bottleneck: Why timing and overlap are mission-critical for conversational user interfaces, speech recognition and dialogue systems
Jul 28, 2023
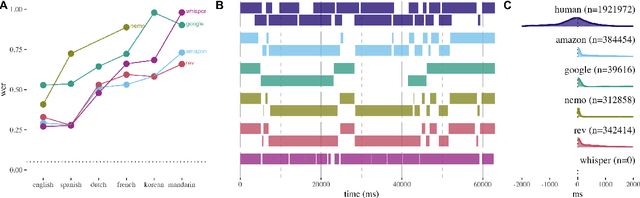
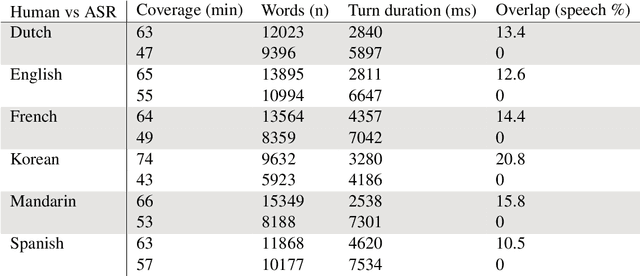
Speech recognition systems are a key intermediary in voice-driven human-computer interaction. Although speech recognition works well for pristine monologic audio, real-life use cases in open-ended interactive settings still present many challenges. We argue that timing is mission-critical for dialogue systems, and evaluate 5 major commercial ASR systems for their conversational and multilingual support. We find that word error rates for natural conversational data in 6 languages remain abysmal, and that overlap remains a key challenge (study 1). This impacts especially the recognition of conversational words (study 2), and in turn has dire consequences for downstream intent recognition (study 3). Our findings help to evaluate the current state of conversational ASR, contribute towards multidimensional error analysis and evaluation, and identify phenomena that need most attention on the way to build robust interactive speech technologies.